自然语言处理(29:(终章Attention 5.)Attention的应用)(完结)
系列文章目录
终章 1:Attention的结构
终章 2:带Attention的seq2seq的实现
终章 3:Attention的评价
终章 4:关于Attention的其他话题
终章 5:Attention的应用
目录
系列文章目录
前言
一、GNMT
二、Transformer
三、NTM
总结
前言
到目前为止,我们仅将Attention应用在了seq2seq上,但是Attention 这一想法本身是通用的,在应用上还有更多的可能性。实际上,在近些年 的深度学习研究中,作为一种重要技巧,Attention出现在了各种各样的场景中。本节我们将介绍3个使用了Attention的前沿研究,以使读者感受到 Attention 的重要性和可能性。
还请麻烦各位大佬贡献一下自己的三连加关注!!!
一、GNMT
回看机器翻译的历史,我们可以发现主流方法随着时代的变迁而演变。 具体来说,就是从“基于规则的翻译”到“基于用例的翻译”,再到“基于统计的翻译”。现在,神经机器翻译(Neural Machine Translation)取代了这些过往的技术,获得了广泛关注。(比如某度翻译)
(神经机器翻译这个术语是出于与之前的基于统计的翻译进行对比而 使用的,现在已经成为使用了seq2seq的机器翻译的统称)
从2016年开始,谷歌翻译就开始将神经机器翻译用于实际的服务,其机器翻译系统称为GNMT(Google Neural Machine Translation,谷歌神经机器翻译系统)。关于GNMT的技术细节,问Deepseek或者查询文献。这里,我们以层结构为中心来看一下GNMT的架构,如下图所示。
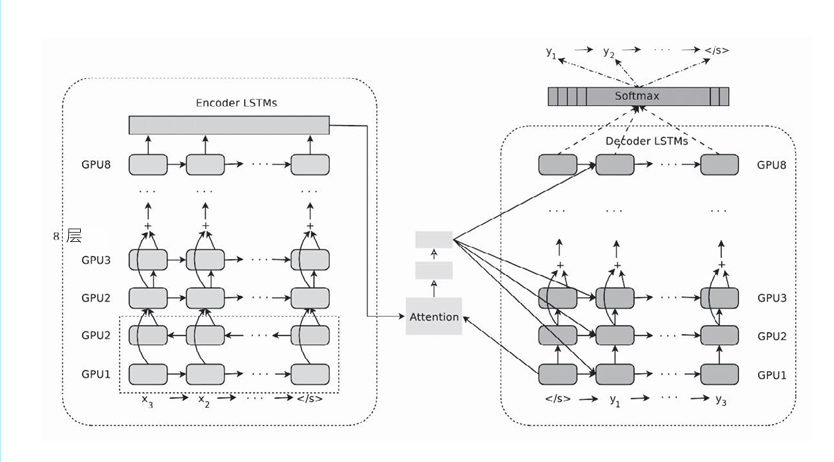
GNMT和本章实现的带Attention的seq2seq一样,由编码器、解码器和Attention 构成。不过,与我们的简单模型不同,这里可以看到许多为了提高翻译精度而做的改进,比如LSTM层的多层化、双向LSTM(仅编码器的第1层)和skip connection等。另外,为了提高学习速度,还进行了多个GPU上的分布式学习。 除了上述在架构上下的功夫之外,GNMT还进行了低频词处理、用于加速推理的量化(quantization)等工作。利用这些技巧,GNMT获得了非 常好的结果,实际报告出来的结果如下图所示。
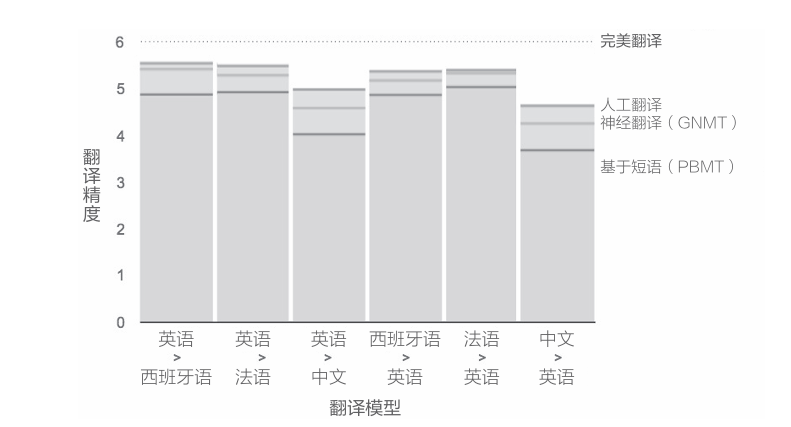
如上图所示,与基于短语的机器翻译(基于统计的机器翻译的一种) 这种传统方法相比,GNMT成功地提高了翻译精度,其精度进一步接近了人工翻译的精度。像这样,GNMT给出了出色的结果,充分展示了神经翻译的实用性和可能性。不过,但凡用过谷歌翻译的人都知道,它仍存在许多 不自然的翻译以及人绝对不会犯的错误。机器翻译的研究仍在继续。实际上,GNMT只是一个开始,目前围绕神经翻译的研究非常活跃。
(实现GNMT需要大量的数据和计算资源。根据相关文献,GNMT使用了大量的训练数据,(1个模型)在将近100个GPU上学习了6天。 另外,GNMT也在设法基于可以并行学习8个模型的集成学习和强化学习等技术进一步提高精度。虽然这些事情不是一个人可以完成的, 但是我们已经学习了需要用到的技术的核心部分。)
你就说6不6?
二、Transformer
到目前为止,我们在各种地方使用了RNN(LSTM)。从语言模型到 文本生成,从seq2se到带Attention的seq2seq及其组成部分,RNN都会 出现。使用RNN可以很好地处理可变长度的时序数据,(在大多数情况下)能够获得良好的结果。但是,RNN也有缺点,比如并行处理的问题。 RNN需要基于上一个时刻的计算结果逐步进行计算,因此(基本)不 可能在时间方向上并行计算RNN。在使用了GPU的并行计算环境下进行深 度学习时,这一点会成为很大的瓶颈,于是我们就有了避开RNN的动机。 在这样的背景下,现在关于去除RNN的研究(可以并行计算的 RNN的研究)很活跃,其中一个著名的模型是Transformer模型。 Transformer 是在“Attention is all you need”这篇论文中提出来的方法。 如论文标题所示,Transformer不用RNN,而用Attention进行处理。这里,我们简单地看一下这个Transformer。
Transformer 是基于Attention构成的,其中使用了Self-Attention 技巧,这一点很重要。Self-Attention直译为“自己对自己的Attention”, 也就是说,这是以一个时序数据为对象的Attention,旨在观察一个时序数 据中每个元素与其他元素的关系。用Time Attention层来说明的话,Self Attention 如下图所示。
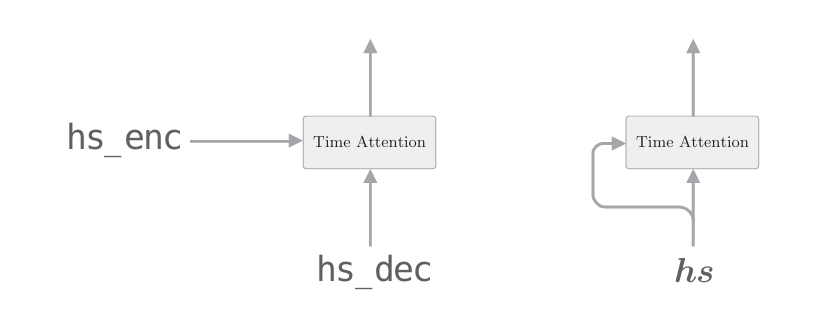
在此之前,我们用Attention求解了翻译这种两个时序数据之间的对应关系。如上图的左图所示,Time Attention层的两个输入中输入的是不同的时序数据。与之相对,如上图的右图所示,Self-Attention的两个输入中输入的是同一个时序数据。像这样,可以求得一个时序数据内各个元素 之间的对应关系。 至此,对Self-Attention 的说明就结束了,下面我们看一下Transformer 的层结构,如下图所示。
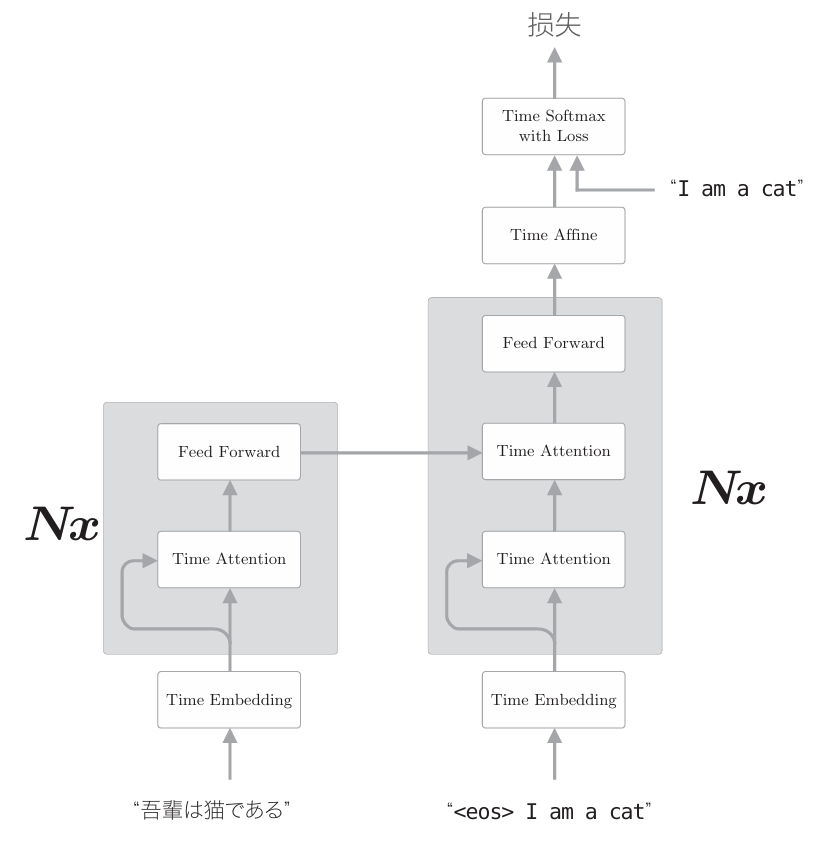
Transformer 中用Attention 代替了RNN。实际上,由上图可知, 编码器和解码器两者都使用了Self-Attention。上图中的Feed Forward 层表示前馈神经网络(在时间方向上独立的网络)。具体而言,使用具有一个隐藏层、激活函数为ReLU的全连接的神经网络。另外,图中的Nx表示灰色背景包围的元素被堆叠了N次。
使用Transformer 可以控制计算量,充分利用GPU并行计算带来的好处。其结果是,与GNMT相比,Transformer的学习时间得以大幅减少。 在翻译精度方面,如下图所示,也实现了精度提升。
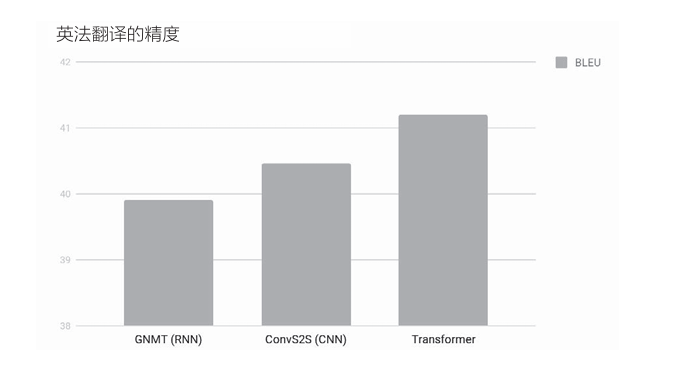
上图比较了3种方法。结果是,使用卷积层的seq2seq(图中记为 ConvS2S)比GNMT精度高,而Transformer比使用卷积层的seq2seq还要高。如此,不仅仅是计算量,从精度的角度来看,Attention也是很有前途的技术。
我们之前组合使用了Attention和RNN,但是由这个研究可知, Attention其实可以用来替换RNN。这样一来,利用Attention的机会可能会进一步增加。
三、NTM
我们在解决复杂问题时,经常使用纸和笔。从另一个角度来看,这可以 解释为基于纸和笔这样的“外部存储装置”,我们的能力获得了延伸。同样 地,利用外部存储装置,神经网络也可以获得额外的能力。本节我们讨论的主题就是“基于外部存储装置的扩展”。
在带Attention的seq2seq 中,编码器对输入语句进行编码。然后,解码器通过Attention使用被编码的信息。这里需要注意的仍是Attention的 存在。基于Attention,编码器和解码器实现了计算机中的“内存操作”。换句话说,这可以解释为,编码器将必要的信息写入内存,解码器从内存中读 取必要的信息。 可见计算机的内存操作可以通过神经网络复现。我们可以立刻想到一个方法:在RNN的外部配置一个存储信息的存储装置,并使用Attention向这个存储装置读写必要的信息。实际上,这样的研究有好几个,NTM (Neural Turing Machine,神经图灵机) 就是其中比较有名的一个。
(NTM是DeepMind团队进行的一项研究,后来被改进成名为DNC(Differentiable Neural Computers,可微分神经计算机)的方法。关于DNC的论文发表在了学术期刊《自然》上。DNC可以认为是强化了内存操作的NTM,但它们的核心技术是一样的。)
在解释NTM的内容之前,我们先来看一下NTM的整体框架。下图这张有趣的图片非常适合用于这一目的。这是NTM所进行的处理的概念表示,很好地总结了NTM的精髓(准确地说,这是发展了NTM的DNC的 一篇解说文章中用到的图)。

现在我们看一下上图这个NTM概念图。这里需要注意的是图中间的一个被称为“控 制器”的模块。这是处理信息的模块,我们假定它使用神经网络(或者 RNN)。从图中可以看出,数据“0”和“1”一个接一个地流入这个控制 器,控制器对其进行处理并输出新的数据。 这里重要的是,在这个控制器的外侧有一张“大纸”(内存)。基于这个内存,控制器获得了计算机(图灵机)的能力。具体来说,这个能力是指, 在这张“大纸”上写入必要的信息、擦除不必要的信息,以及读取必要信息的能力。顺便说一下,因为上图的“大纸”是卷式的,所以各个节点可以在需要的地方读写数据。换句话说,就是可以移动到目标地点。 像这样,NTM在读写外部存储装置的同时处理时序数据。NTM的有 趣之处在于使用“可微分”的计算构建了这些内存操作。因此,它可以从数据中学习内存操作的顺序。
NTM像计算机一样读写外部存储装置,其层结构可以简单地绘制成下图所示。
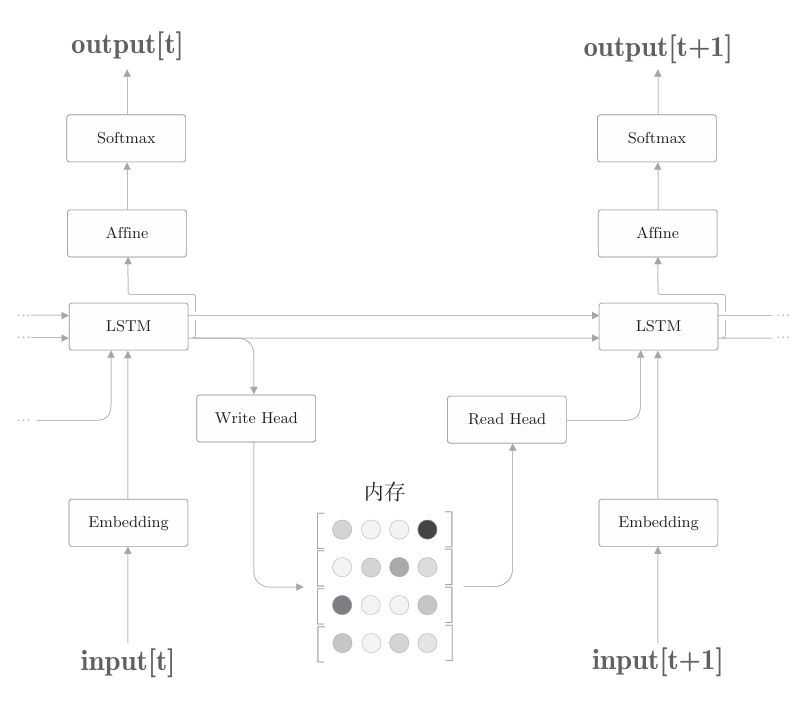
上图是简化版的NTM的层结构。这里LSTM层是控制器,执行NTM的主要处理。Write Head层接收LSTM层各个时刻的隐藏状态,将必要的信息写入内存。Read Head层从内存中读取重要信息,并传递给下 一个时刻的LSTM层。 那么,上图的Write Head层和Read Head层如何进行内存操作呢? 当然是使用Attention。
为了模仿计算机的内存操作,NTM的内存操作使用了两个Attention, 分别是“基于内容的Attention”和“基于位置的Attention”。基于内容的 Attention 和我们之前介绍的Attention一样,用于从内存中找到某个向量 (查询向量)的相似向量。 而基于位置的Attention用于从上一个时刻关注的内存地址(内存的各 个位置的权重)前后移动。这里我们省略对其技术细节的探讨,具体可以通 过一维卷积运算实现。基于内存位置的移动功能,可以再现“一边前进(一 个内存地址)一边读取”这种计算机特有的活动。
通过自由地使用外部存储装置,NTM获得了强大的能力。实际上,对于seq2seq 无法解决的复杂问题,NTM取得了惊人的成绩。具体而言,NTM成功解决了长时序的记忆问题、排序问题(从大到小排列数字)等。 如此,NTM借助外部存储装置获得了学习算法的能力,其中Attention作为一项重要技术而得到了应用。基于外部存储装置的扩展技术和Attention会越来越重要,今后将被应用在各种地方。
总结
本章我们学习了Attention的结构,并实现了Attention层。然后,使用Attention实现了seq2seq,并通过简单的实验,确认了Attention的出色效果。另外,我们对模型推理时的Attention的权重(概率)进行了可视化。从结果可知,具有Attention的模型以与人类相同的方式将注意力放在了必要的信息上。 另外,本章还介绍了有关Attention的前沿研究。从多个例子可知, Attention 扩展了深度学习的可能性。Attention是一种非常有效的技术, 具有很大潜力。在深度学习领域,今后Attention自己也将吸引更多的“注意力”。
最后终于完结了,希望能得到各位大佬的三连加关注!!