EI复现:蜣螂优化算法变体合集上新,改进正弦算法引导的蜣螂优化算法
1 DBO算法
1.1 滚球蜣螂
蜣螂有一个有趣的习惯,把粪便做成球,然后把它滚到理想位置,在滚动过程中,蜣螂需要通过天体线索(太阳位置或风向等)来保持粪球在直线上滚动。为了模拟滚球行为,蜣螂需要在整个搜索空间中沿给定方向移动。在滚动过程中,滚动球的蜣螂的位置会更新,滚动数学模型可以表示为:
{ x i ( t + 1 ) = x i ( t ) + a × k × x i ( t − 1 ) + b × Δ r Δ r = ∣ x i ( t ) − X w ∣ (1) \begin{cases} x_i(t+1) = x_i(t) + a \times k \times x_i(t-1) + b \times \Delta r \\ \Delta r = |x_i(t) - X^w| \end{cases} \tag{1} {xi(t+1)=xi(t)+a×k×xi(t−1)+b×ΔrΔr=∣xi(t)−Xw∣(1)
其中, i i i表示当前迭代次数, x i ( t ) x_i(t) xi(t)表示第 i i i只蜣螂在第 t t t次迭代时的位置信息, k ∈ ( 0 , 0.2 ] k \in (0, 0.2] k∈(0,0.2]表示偏转系数的常量, b b b表示属于(0, 1)的常量, a a a是一个自然系数,赋值为-1或1(参见算法1)。 X w X^w Xw表示全局最差位置, Δ r \Delta r Δr用于模拟光强的变化。
算法1
α
\alpha
α的选择策略
输入:概率值
λ
\lambda
λ。
输出:自然系数
α
\alpha
α。
- η = rand ( 1 ) \eta = \text{rand}(1) η=rand(1)
- if η > λ \eta > \lambda η>λ then
- α = 1 \alpha = 1 α=1;
- else
- α = − 1 \alpha = -1 α=−1;
- end if
当蜣螂遇到障碍物而无法前进时,它需要通过跳舞来调整自己的方向,以获得新的路线。使用切线函数来模拟蜣螂的舞蹈行为,获得新的滚动方向。一旦蜣螂成功地确定了一个新的方向,它就会继续向前滚动球。因此,蜣螂跳舞行为的位置被定义如下:
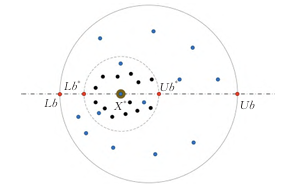
图1 边界选择策略的概念模型
Fig.1 Conceptual model of boundary selection strategy
x
i
(
t
+
1
)
=
x
i
(
t
)
+
tan
θ
⋅
∣
x
i
(
t
)
−
x
i
(
t
−
1
)
∣
(2)
x_i(t+1) = x_i(t) + \tan \theta \cdot |x_i(t) - x_i(t-1)| \tag{2}
xi(t+1)=xi(t)+tanθ⋅∣xi(t)−xi(t−1)∣(2)
其中, θ ∈ [ 0 , π ] \theta \in [0, \pi] θ∈[0,π],如果 θ \theta θ 等于 0 0 0、 π / 2 \pi/2 π/2 或 π \pi π 时,将不会更新蜣螂的位置。
1.2 繁育蜣螂(繁育球)
在自然界中,粪球被滚到安全的地方,并被蜣螂藏起来。为了给它们的后代提供一个安全的环境,选择合适的产卵地点对蜣螂来说至关重要。受上述讨论的启发,提出了一种边界选择策略来模拟雌性蜣螂产卵的区域,该策略为:
{ L B b = max ( X b × ( 1 − R ) , L B ) U B b = min ( X b × ( 1 + R ) , U B ) (3) \begin{cases} LB^b = \max(X^b \times (1-R), LB) \\ UB^b = \min(X^b \times (1+R), UB) \end{cases} \tag{3} {LBb=max(Xb×(1−R),LB)UBb=min(Xb×(1+R),UB)(3)
其中, X b X^b Xb 表示当前局部最佳位置, L B b LB^b LBb 和 U B b UB^b UBb 分别表示产卵区的下界和上界, R = 1 − t / T max R = 1 - t/T_{\max} R=1−t/Tmax, T max T_{\max} Tmax 表示最大迭代次数, L B LB LB 和 U B UB UB 分别表示优化问题的下界和上界。
一旦确定了产卵区,雌性蜣螂就会选择这个区域的繁育球产卵。应该提到的是,对于DBO算法,每只雌性蜣螂在每次迭代中只产一个卵。此外,从式中可以清楚地看出,产卵区的边界范围是动态变化的,这主要由 R R R 值决定。因此,繁育球的位置在迭代过程中也是动态的,迭代过程表示为:
B i ( t + 1 ) = X b + b 1 × ( B i ( t ) − L B b ) + b 2 × ( B i ( t ) − U B b ) (4) B_i(t+1) = X^b + b_1 \times (B_i(t) - LB^b) + b_2 \times (B_i(t) - UB^b) \tag{4} Bi(t+1)=Xb+b1×(Bi(t)−LBb)+b2×(Bi(t)−UBb)(4)
其中, B i ( t ) B_i(t) Bi(t) 是第 i i i 次迭代时第 i i i 个繁育球的位置信息, b 1 b_1 b1 和 b 2 b_2 b2 表示两个大小为 1 × D 1 \times D 1×D 的独立随机向量, D D D 表示优化问题的维数。繁育球的位置被严格限制在一定范围内,即产卵区(参见算法2)。
算法2 繁育球位置更新策略
输入:最大迭代次数
T
max
T_{\max}
Tmax,繁育球数量
N
N
N,当前迭代次数
t
t
t;
输出:第
i
i
i 个繁育球
B
i
B_i
Bi 的位置。
- R = 1 − t / T max R = 1 - t/T_{\max} R=1−t/Tmax
- for i ← 1 i \leftarrow 1 i←1 to n n n do
- 用公式更新繁育球的位置;
- for j ← 1 j \leftarrow 1 j←1 to D D D do
- if B i j > U B b B_{ij} > UB^b Bij>UBb then
- B i j ← U B b B_{ij} \leftarrow UB^b Bij←UBb
- end if
- if B i j < L B b B_{ij} < LB^b Bij<LBb then
- B i j ← L B b B_{ij} \leftarrow LB^b Bij←LBb
- end if
- end for
- end for
如图1所示,蓝色的点代表滚球蜣螂的位置,当前局部最佳位置 X b X^b Xb 使用一个棕色的大圆圈来表示,而 X b X^b Xb 周围的黑色小圆圈表示繁育球。每个繁育球中都有一个蜣螂的卵。此外,红色的小圆圈表示边界的上限和下限。
1.3 小蜣螂
一些已经长成成虫的蜣螂从地里爬出来寻找食物,称它们为小蜣螂。此外,还需要建立最佳觅食区来引导蜣螂觅食,这模拟了这些蜣螂在自然界中的觅食过程。具体而言,最佳觅食区域的边界定义如下:
L B b = max ( X b × ( 1 − R ) , L B ) (5) LB^b = \max(X^b \times (1-R), LB) \tag{5} LBb=max(Xb×(1−R),LB)(5)
U B b = min ( X b × ( 1 + R ) , U B ) UB^b = \min(X^b \times (1+R), UB) UBb=min(Xb×(1+R),UB)
其中, X b X^b Xb表示全局最佳位置, L B b LB^b LBb和 U B b UB^b UBb分别表示最佳觅食区域的下界和上界,其他参数在公式中定义。因此,小蜣螂的位置更新如下:
x i ( t + 1 ) = x i ( t ) + C i × ( x i ( t ) − L B b ) + C s × ( x i ( t ) − U B b ) (6) x_i(t+1) = x_i(t) + C_i \times (x_i(t) - LB^b) + C_s \times (x_i(t) - UB^b) \tag{6} xi(t+1)=xi(t)+Ci×(xi(t)−LBb)+Cs×(xi(t)−UBb)(6)
其中, x i ( t ) x_i(t) xi(t)表示第 i i i只小蜣螂在第 t t t次迭代的位置信息, C i C_i Ci表示服从正态分布的随机数, C s C_s Cs表示属于(0, 1)的随机向量。
1.4 偷窃蜣螂
一些被称为小偷的蜣螂从其他蜣螂那里偷粪球。从式中可以看出, X w X^w Xw是最佳的食物来源。因此,可以假设 X w X^w Xw附近是争夺食物的最佳地点。在迭代过程中,偷窃蜣螂的位置信息被更新,可以描述如下:
x i ( t + 1 ) = X w + S × g × ( ∣ x i ( t ) − X w ∣ + ∣ x i ( t ) − X w ∣ ) (7) x_i(t+1) = X^w + S \times g \times (|x_i(t) - X^w| + |x_i(t) - X^w|) \tag{7} xi(t+1)=Xw+S×g×(∣xi(t)−Xw∣+∣xi(t)−Xw∣)(7)
其中, x i ( t ) x_i(t) xi(t)表示第 i i i只偷窃蜣螂在第 t t t次迭代时的位置信息, g g g是服从正态分布的大小为1× D D D的随机向量, S S S表示一个常量。
2 蜣螂优化器算法改进
2.1 改进动机
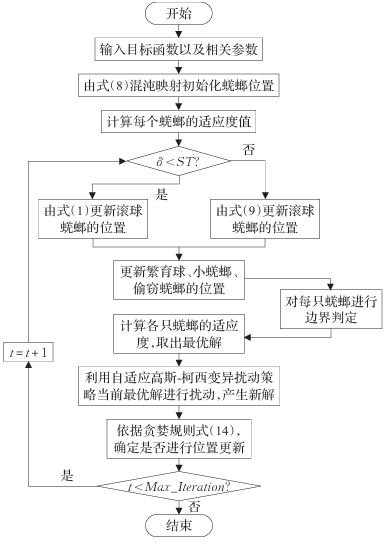
在优化问题上,DBO算法优于其他算法。然而,对于DBO来说,获得理想的最优解仍然极具挑战性。此外,它解决复杂问题的能力也不尽如人意。蜣螂优化算法虽然具有寻优能力强、收敛速度快的特点,但同时也存在全局探索和局部开发能力不平衡,容易陷入局部最优,且全局探索能力较弱的缺点。因此,为了提高DBO的搜索性能,本章提出了3种加强DBO的策略。原有的DBO算法无法很好地平衡探索和开发两个阶段。MSADBO算法通过Bernoulli映射策略、嵌入改进正弦算法策略和自适应的高斯-柯西变异扰动来改善这种不平衡。本章将具体介绍这些策略。
2.2 混沌映射初始化种群
混沌映射是一种确定性和随机性相结合的方法,混沌具有随机性、非周期性等特点[28]。由于混沌变量在初始化位置更新过程中取代了智能算法运行过程中的随机变量,混沌映射策略对解空间的搜索范围比随机搜索策略更广。因此,对于随机初始化过程,混沌初始化可以提高优化算法的搜索广度。
蜣螂优化算法是在搜索空间中随机初始化种群的位置,但是该方法有3个主要缺点:
(1)蜣螂个体的位置分布不均匀;
(2)全局探索能力较弱;
(3)种群多样性低而容易陷入局部最优。
为了提高种群初始解的多样性,在DBO的种群初始化阶段使用混沌映射来生成高度多样化的初始种群。目前存在多种不同的混沌映射[29],主要有Singer映射、Chebyshev映射、Bernoulli映射、Gaussian映射、PWLCM映射等。其中Bernoulli映射属于混沌映射的一种,常被用来产生混沌序列,其具有非线性、遍历性、随机性等特征。在优化领域替代随机数初始化种群,会影响算法的整个过程,同时能获得比随机数更好的寻优效果[30]。此外Saito等[28]研究表明,Bernoulli映射的遍历均匀性和收敛速度适合作为混沌种群初始化,并通过合理的参数设置,证明了Bernoulli映射可以用于产生优化算法的初始种群,Bernoulli映射对混沌序列分布如图3所示。因此本文采用Bernoulli映射初始化蜣螂个体位置,先利用Bernoulli映射关系将所得的值投影到混沌变量空间内,然后将产生的混沌值通过线性变换映射到算法初始空间中。Bernoulli映射具体表达式为:
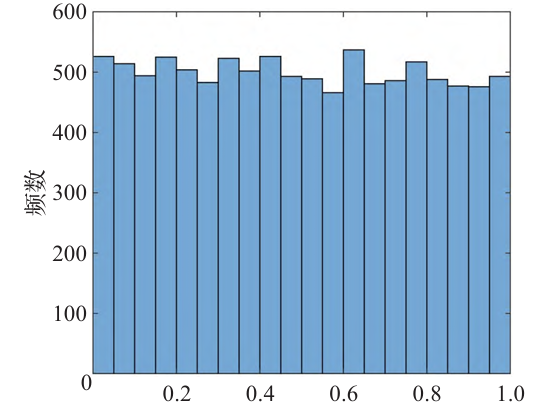
图3 Bernoulli映射混沌序列分布
Fig.3 Distribution of chaos values for Bernoulli map
z n + 1 = { z n 1 − β , 0 ≤ z n ≤ 1 − β z n − ( 1 − β ) β , 1 − β < z n ≤ 1 (8) z_{n+1} = \begin{cases} \frac{z_n}{1-\beta}, & 0 \leq z_n \leq 1-\beta \\ \frac{z_n - (1-\beta)}{\beta}, & 1-\beta < z_n \leq 1 \end{cases} \tag{8} zn+1={1−βzn,βzn−(1−β),0≤zn≤1−β1−β<zn≤1(8)
其中, β \beta β是映射参数, β ∈ ( 0 , 1 ) \beta \in (0, 1) β∈(0,1)。文中设置 β = 0.518 \beta = 0.518 β=0.518, z 0 = 0.326 z_0 = 0.326 z0=0.326,以达到最好的取值效果。
2.3 利用改进正弦算法
改进正弦算法(MSA)[38]策略是受到正余弦算法(sine cosine algorithm, SCA)[39]、正弦算法(sine algorithm, SA)[40]和指数正余弦算法(exponential sine cosine algorithm, ESCA)函数[41]以及改进的正弦余弦算法(improved sine cosine algorithm, ISCA)[42]等各类与SCA相关算法的启发,利用数学中的正弦函数进行迭代寻优,具有较强的全局搜索能力。同时在位置更新过程中引入自适应的可变惯性权重系数 ω \omega ω,使算法能够对局部区域进行充分搜索,使全局探索和局部开发能力达到良好的平衡。改进正弦算法位置更新公式如下所示:
x i ( t + 1 ) = ω t x i ( t ) + r 1 × sin r 2 × [ p i ( t ) − x i ( t ) ] (9) x_i(t+1) = \omega_t x_i(t) + r_1 \times \sin r_2 \times [p_i(t) - x_i(t)] \tag{9} xi(t+1)=ωtxi(t)+r1×sinr2×[pi(t)−xi(t)](9)
其中, t t t为当前迭代次数, ω t \omega_t ωt是惯性权重, x i ( t ) x_i(t) xi(t)为个体 X X X在第 i i i次迭代中的第 i i i个位置分量, p i ( t ) p_i(t) pi(t)为第 i i i次迭代中最佳个体位置变量的第 i i i个分量, r 1 r_1 r1为非线性递减函数, r 2 r_2 r2是区间[0, 2 π \pi π]上的随机数, r 3 r_3 r3是区间[-2, 2]上的随机数。
使用非线性递减模式来设置 r 1 r_1 r1的值,并使用0到 π \pi π之间的余弦函数来确定 r 1 r_1 r1值的变化:
r 1 = ω max − ω min 2 cos π t T max + ω max + ω min 2 (10) r_1 = \frac{\omega_{\max} - \omega_{\min}}{2} \cos \frac{\pi t}{T_{\max}} + \frac{\omega_{\max} + \omega_{\min}}{2} \tag{10} r1=2ωmax−ωmincosTmaxπt+2ωmax+ωmin(10)
其中, ω max \omega_{\max} ωmax和 ω min \omega_{\min} ωmin表示 ω t \omega_t ωt的最大值和最小值, t t t表示当前迭代次数, T max T_{\max} Tmax表示最大迭代次数。
采用了自适应的可变惯性权重策略,其中惯性权重随着迭代次数的增加线性减小:
ω t = ω max − ( ω max − ω min ) × t T max (11) \omega_t = \omega_{\max} - (\omega_{\max} - \omega_{\min}) \times \frac{t}{T_{\max}} \tag{11} ωt=ωmax−(ωmax−ωmin)×Tmaxt(11)
为进一步改进DBO算法协调全局探索与局部开发的能力,本文引入了正弦引导机制,MSA作为替代蜣螂正切跳舞的策略嵌入DBO算法,即在滚球阶段对整个蜣螂个体进行正弦的操作引导蜣螂位置更新。改进后的公式如下:
x i ( t + 1 ) = { x i ( t ) + a × k × x i ( t − 1 ) + b × Δ x i , δ < S T ω × x i ( t ) + r 1 × sin r 2 × [ p i ( t ) − x i ( t ) ] , δ > S T (12) x_i(t+1) = \begin{cases} x_i(t) + a \times k \times x_i(t-1) + b \times \Delta x_i, \delta < ST \\ \omega \times x_i(t) + r_1 \times \sin r_2 \times [p_i(t) - x_i(t)], \delta > ST \end{cases} \tag{12} xi(t+1)={xi(t)+a×k×xi(t−1)+b×Δxi,δ<STω×xi(t)+r1×sinr2×[pi(t)−xi(t)],δ>ST(12)
其中, δ = rand ( 1 ) \delta = \text{rand}(1) δ=rand(1), S T ∈ ( 0.5 , 1 ] ST \in (0.5, 1] ST∈(0.5,1]。改进后的位置更新公式中,当 δ < S T \delta < ST δ<ST时,表明蜣螂有目标地进行滚动,处于正常全局探索阶段,而当 δ > S T \delta > ST δ>ST时,代表蜣螂没有明确的滚动目标,但是会通过正弦函数的方式进行搜索移动。
这种改进正弦指引机制的引入,一方面可以极大地改善DBO算法位置更新策略过于随机的缺陷。这是由于加入MSA策略后,蜣螂个体会与当前最优个体 p i ( t ) p_i(t) pi(t)进行信息交流,促进信息在种群中快速传播,改善了原算法中缺乏个体间信息交流的缺陷。
另一方面,针对原算法容易陷入局部最优的问题,MSA的指引机制使得蜣螂个体可以自由在算法给定的区域范围内进行全局探索和局部寻优,在一定程度上扩大了搜索空间,并逐渐收敛于一个最优解即目标函数值,从而提升算法的全局寻优能力。同时由公式可以看出, r 1 r_1 r1控制蜣螂的搜索距离和方向,优化了DBO算法的寻优方式,并且自适应系数 ω \omega ω,逐步缩小了搜索空间,随着迭代次数的增加,惯性权值减小。在算法迭代前期相对较大惯性权值能够使算法拥有较强的全局搜索能力,而迭代后期相对较小的惯性权值则有助于提高其局部开发能力。
2.4 自适应高斯-柯西混合变异扰动
在基本蜣螂算法迭代的后期,蜣螂个体快速同化,蜣螂群体迅速聚集到当前的最优位置附近,其值近似于最优解。因此,如果当前最优位置不是全局最优的点,那么蜣螂种群会集中在当前最优位置附近搜索,导致无法发现真正的最优位置,出现搜索停滞的情况。为解决这一问题,一般采用变异扰动操作对个体进行干扰以增加种群多样性,跳出局部最优。执行变异扰动操作能够提高蜣螂种群多样性,使算法能够跳出局部最优解,进入解空间的其他区域继续进行勘探,直至最终找到全局最优解。
在智能优化算法中引入变异算子,既可以增强种群的多样性,又可以使算法避免陷入局部极小。柯西变异和高斯变异是智能优化算法中两种较常见的变异算子,这两种变异算子都有各自的优缺点。柯西变异的搜索范围要比高斯变异的搜索范围大,但其过大的步长容易跳出最优值而产生较差的后代;而高斯变异在小范围内具有良好的搜索能力,这是因为其能以较大的概率产生较小的变异值。所以提出了一种融合柯西变异和高斯变异各自优点的自适应高斯-柯西混合扰动变异策略。扰动策略。
由于变异扰动操作的结果具有随机性,若对所有蜣螂均进行变异扰动操作必然会增加算法的复杂度,因此本文仅对最优个体进行变异扰动,然后比较其变异前后的位置,选择较好的位置进入下一次迭代,充分增加蜣螂的多样性,扩大种群搜索范围。具体公式如下:
H ∗ ( t ) = X ∗ ( t ) × ( 1 + μ 1 × Gauss ( σ ) + μ 2 × Cauchy ( σ ) ) (13) H^*(t) = X^*(t) \times (1 + \mu_1 \times \text{Gauss}(\sigma) + \mu_2 \times \text{Cauchy}(\sigma)) \tag{13} H∗(t)=X∗(t)×(1+μ1×Gauss(σ)+μ2×Cauchy(σ))(13)
其中, X ∗ ( t ) X^*(t) X∗(t)为个体 X X X在第 t t t次迭代中的最优位置, H ∗ ( t ) H^*(t) H∗(t)为第 t t t次迭代中的最优位置 X ∗ ( t ) X^*(t) X∗(t)在高斯-柯西混合扰动后的位置, Gauss ( σ ) \text{Gauss}(\sigma) Gauss(σ)为高斯变异算子, Cauchy ( σ ) \text{Cauchy}(\sigma) Cauchy(σ)为柯西变异算子, μ 1 = t / T max \mu_1 = t/T_{\max} μ1=t/Tmax, μ 2 = 1 − t / T max \mu_2 = 1 - t/T_{\max} μ2=1−t/Tmax。变异算子的权重系数 μ 1 , μ 2 \mu_1, \mu_2 μ1,μ2以一种一维线性的方式逐步变动,目的是保证每一次的迭代扰动均衡平滑。
在算法迭代过程中对蜣螂个体进行变异扰动,算法迭代初期,由于种群分布比较分散,算法主要通过柯西分布函数对个体进行较大幅度变异扰动,从而产生多样性个体,既充分利用了当前位置信息,又增加了随机干扰信息,使算法能够进行全局探索,快速收敛;随着算法迭代的不断进行,蜣螂大多数个体位置不会发生太大变化,此时算法主要通过高斯分布函数系数对种群进行扰动,从而帮助算法能够跳出局部自度,同时克服了高维问题下的维间干扰问题。总而言之,自适应高斯-柯西混合变异扰动策略,使用了柯西和高斯分布函数的特性来产生新的个体,增强了蜣螂的多样性,增强了算法协调其局部开发和全局探索的能力。
自适应高斯-柯西混合扰动变异策略虽然能增强算法全局搜索和跳出局部最优的能力,但是没法确定变异扰动之后得到的新位置一定比原位置的适应度更好,因此在进行变异扰动更新后,加入贪婪规则,通过比较新旧两个位置的适应度值,确定是否要更新位置。贪婪规则如下所示, f ( x ) f(x) f(x)表示 x x x位置的适应度值。
X
∗
=
{
H
∗
(
t
)
,
f
[
H
∗
(
t
)
]
<
f
[
X
∗
(
t
)
]
X
∗
(
t
)
,
f
[
H
∗
(
t
)
]
≥
f
[
X
∗
(
t
)
]
(14)
X^* = \begin{cases} H^*(t), & f[H^*(t)] < f[X^*(t)] \\ X^*(t), & f[H^*(t)] \geq f[X^*(t)] \end{cases} \tag{14}
X∗={H∗(t),X∗(t),f[H∗(t)]<f[X∗(t)]f[H∗(t)]≥f[X∗(t)](14)
[1]潘劲成,李少波,周鹏,等.改进正弦算法引导的蜣螂优化算法[J].计算机工程与应用,2023,59(22):92-110.