本周大模型新动向!即插即用知识模块,人机交互新趋势,检索增强技术深度解析
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Training Plug-n-Play Knowledge Modules with Deep Context Distillation
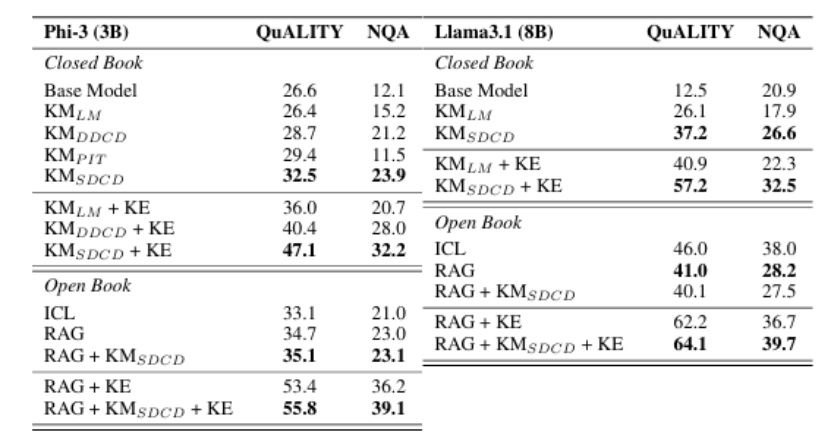
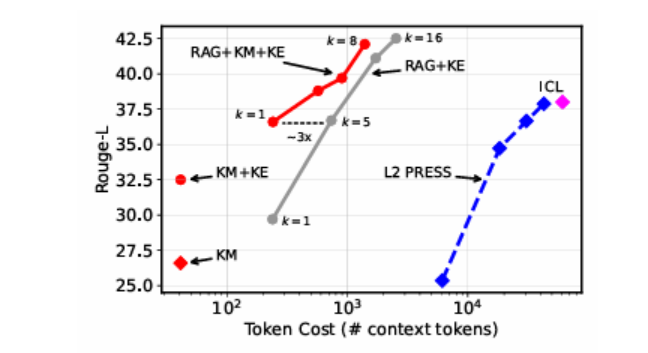
动态集成(大型)语言模型预训练后的新信息或快速演变信息仍然具有挑战性,尤其是在数据稀缺的情况下或处理私有和专业文档时。上下文学习和检索增强生成(RAG)存在局限性,包括其高昂的推理成本以及无法捕捉全局文档信息。本文提出一种通过训练文档级知识模块(KMs)来模块化知识的方法。KMs是轻量级组件,以参数高效的LoRA模块形式实现,能够存储新文档的信息,并可以按需插入模型中。
本文表明,将下一个标记预测作为KMs的训练目标表现不佳。相反,我们提出了深度上下文蒸馏(Deep Context Distillation):我们学习KMs的参数,使其能够模拟将文档置于上下文中的教师模型的隐藏状态和logits。我们的方法在两个数据集上优于标准的下一个标记预测和预指令训练技术。最后,我们强调了KMs与检索增强生成之间的协同作用。
文章链接:
https://arxiv.org/abs/2503.08727
02
Sometimes Painful but Certainly Promising: Feasibility and Trade-offs of Language Model Inference at the Edge
语言模型(LMs)的迅速崛起扩展了自然语言处理的能力,从文本生成到复杂决策都发挥了作用。尽管最先进的语言模型通常拥有数千亿参数,主要部署在数据中心,但近期趋势显示,人们越来越关注紧凑型模型(通常少于100亿参数),这得益于量化和其他模型压缩技术。这种转变使得语言模型在边缘设备上的部署成为可能,潜在优势包括增强隐私、降低延迟和改善数据主权。然而,即使是这些较小模型的固有复杂性,加上边缘硬件有限的计算资源,引发了在云外执行语言模型推理的实际权衡问题。为解决这些挑战,本文对代表性基于CPU和GPU加速的边缘设备上的生成式语言模型推理进行了全面评估。研究测量了各种设备配置下的关键性能指标,包括内存使用、推理速度和能耗。此外,本文还考察了吞吐量-能耗权衡、成本考量以及可用性,并对模型性能进行了定性评估。虽然量化有助于缓解内存开销,但并未完全消除资源瓶颈,尤其是对于较大模型。本文的研究结果量化了实际部署中必须考虑的内存和能耗限制,为模型大小、推理性能和效率之间的权衡提供了具体见解。语言模型在边缘端的探索仍处于早期阶段,作者希望本研究能为未来的研究提供基础,指导模型的改进、推理效率的提升以及以边缘为中心的AI系统的发展。
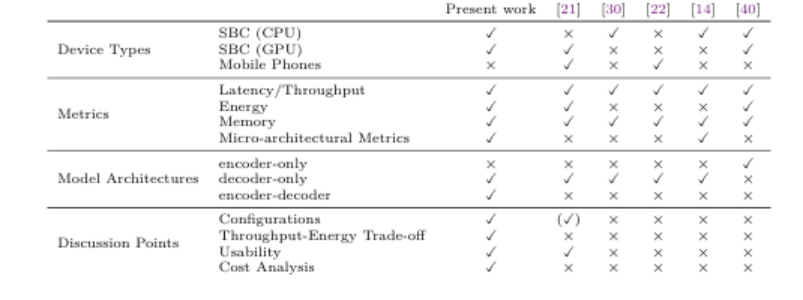
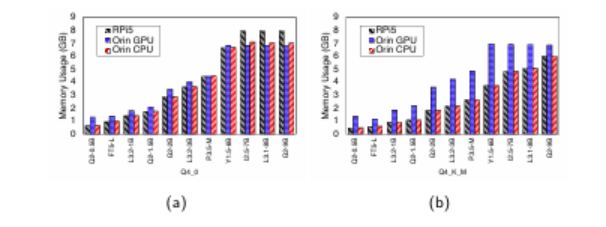
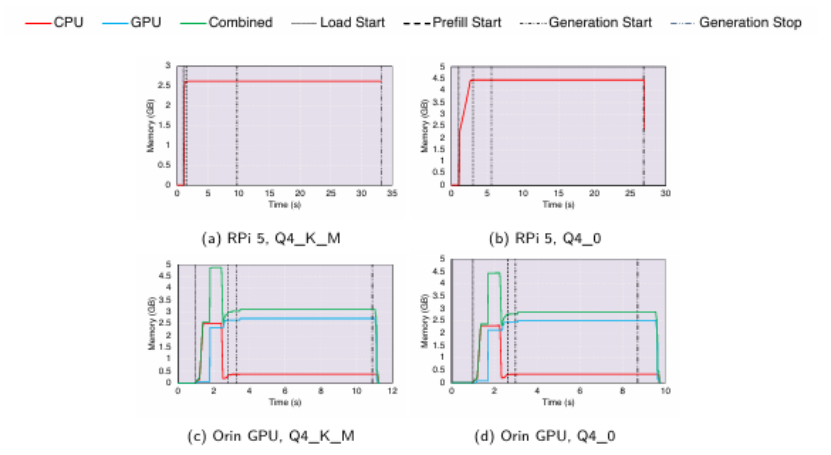
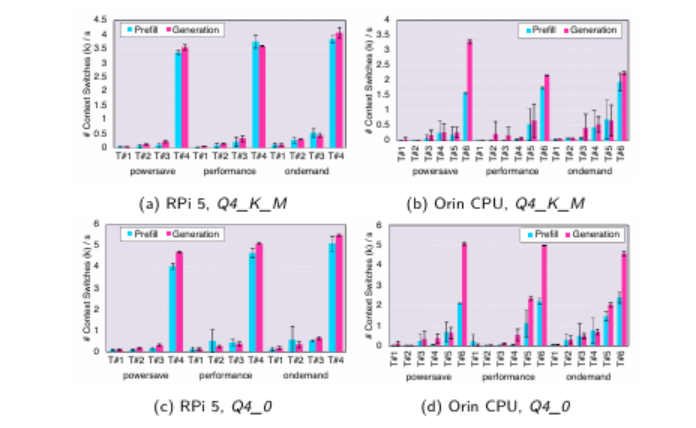
文章链接:
https://arxiv.org/abs/2503.09114
03
MindGYM: Enhancing Vision-Language Models via Synthetic Self-Challenging Questions
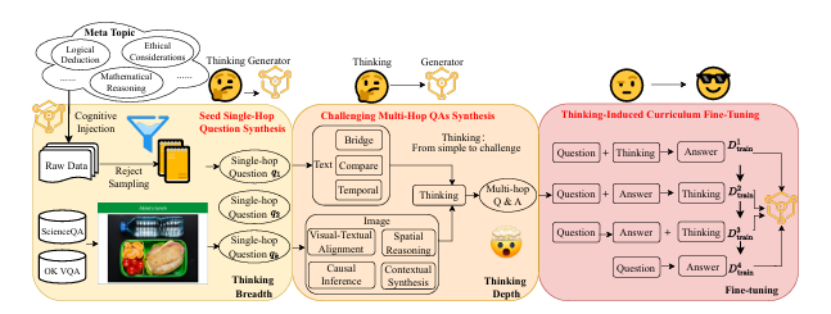
大型视觉-语言模型(VLMs)在实现稳健、可转移的推理能力方面面临挑战,主要是因为依赖于劳动密集型的手动指令数据集或计算成本高昂的自监督方法。为了解决这些问题,本文介绍了MindGYM,这是一个通过合成自挑战问题增强VLMs的框架,包括三个阶段:
(1)种子单跳问题合成,生成跨越文本(例如,逻辑推理)和多模态上下文(例如,基于图的查询)的认知问题,涵盖伦理分析等八个语义领域;
(2)挑战性多跳问题合成,通过多样化原则(如桥接、视觉-文本对齐)结合种子问题,创建需要更深层次推理的多步骤问题;
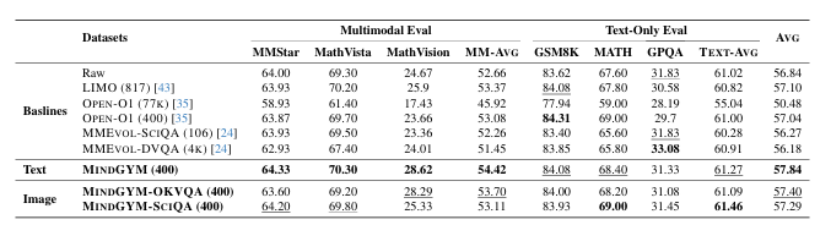
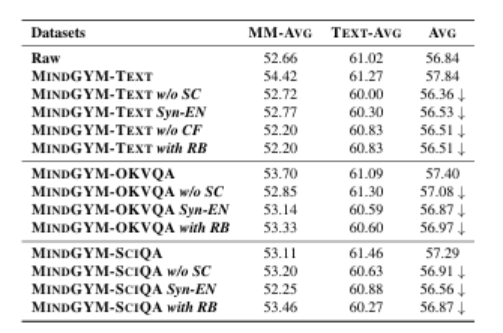
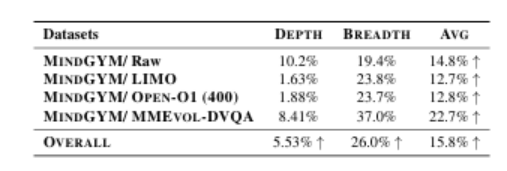
(3)思维诱导课程微调,一个结构化管道,逐步训练模型从支架推理到独立推理。通过利用模型的自我合成能力,MindGYM实现了高数据效率(例如,在MathVision-Mini上仅用400个样本就获得了16%的增益),计算效率(降低了训练和推理成本),以及跨任务的稳健泛化。在七个基准上的广泛评估表明,MindGYM在推理深度和广度方面优于强大的基线,通过基于GPT的评分验证了显著改进(胜率提高了15.77%)。MindGYM强调了自挑战在最小化人类干预和资源需求的同时,精炼VLM能力的可能性。代码和数据已经发布,以推进多模态推理研究。

文章链接:
https://arxiv.org/abs/2503.09499
04
NVP-HRI: Zero Shot Natural Voice and Posture-based Human-Robot Interaction via Large Language Model
有效的人机交互(HRI)对于未来服务机器人在老龄化社会中至关重要。现有的解决方案偏向于仅针对训练良好的对象,这在处理新对象时产生了差距。目前,使用预定义的手势或语言标记进行预训练对象的HRI系统对所有个体,尤其是老年人,提出了挑战。这些挑战包括在回忆命令、记忆手势和学习新名称方面的困难。本文介绍了NVP-HRI,这是一种直观的多模态HRI范式,它结合了语音命令和示意姿态。NVP-HRI利用Segment Anything Model(SAM)分析视觉线索和深度数据,实现对新对象的精确结构化对象表示。通过预训练的SAM网络,NVP-HRI允许与新对象进行零样本预测,甚至在没有先验知识的情况下。NVP-HRI还与大型语言模型(LLM)集成,用于多模态命令,实时协调它们与对象选择和场景分布,以实现无碰撞轨迹解决方案。我们还通过必要的控制语法调节动作序列,以降低LLM幻觉风险。使用通用机器人进行的多样化真实世界任务评估显示,与传统手势控制相比,效率提高了高达59.2%。
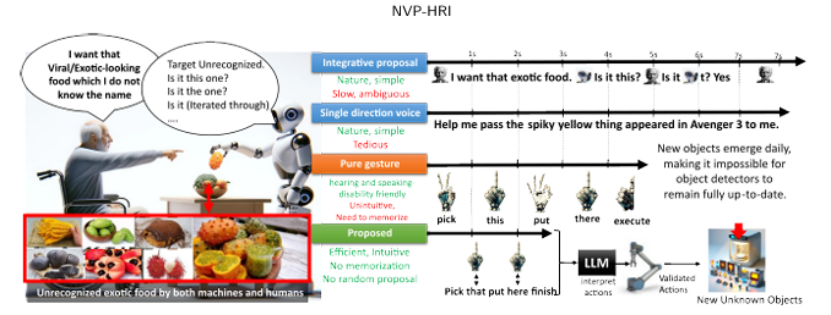
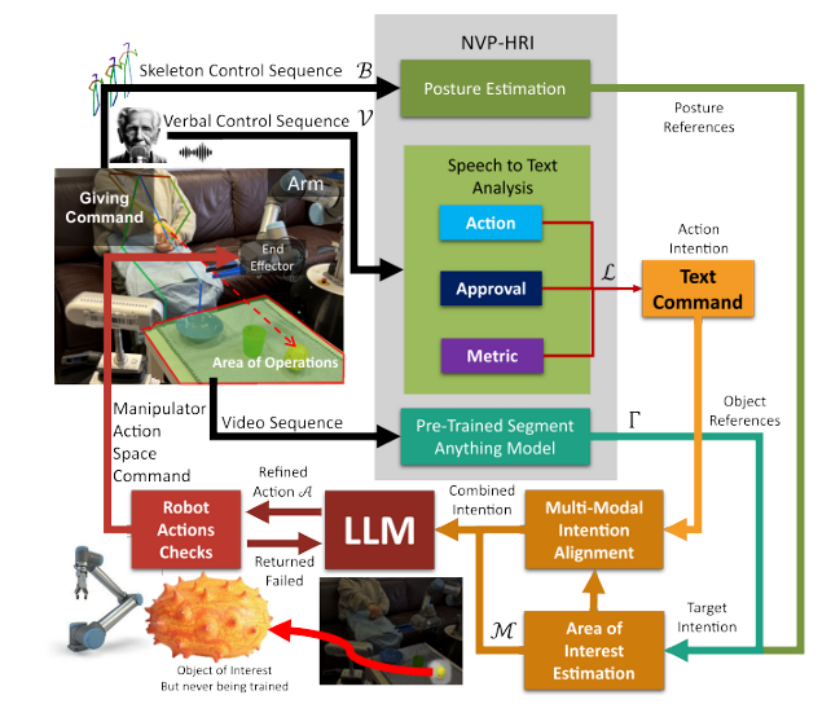
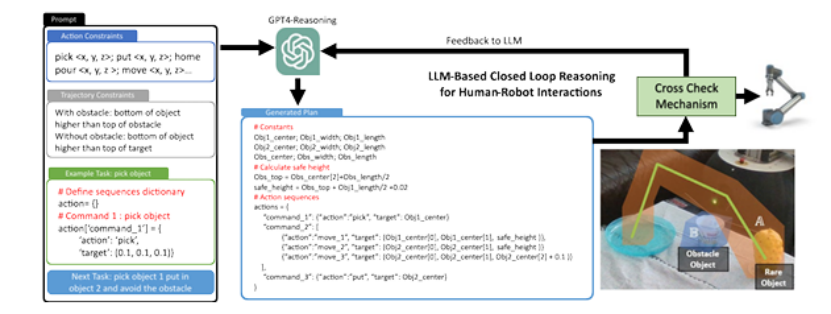
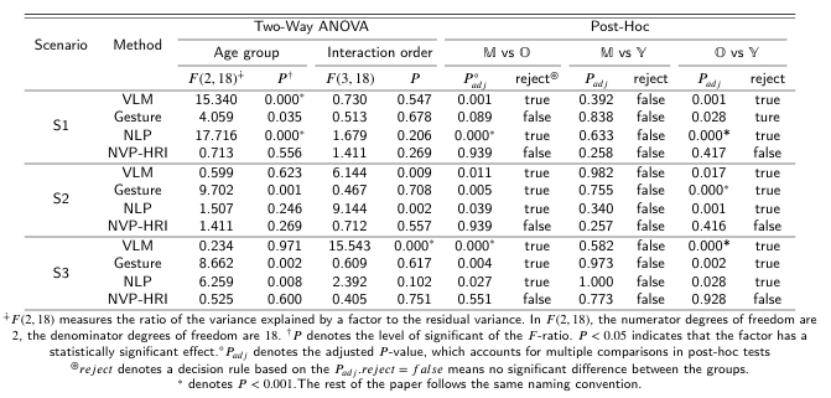
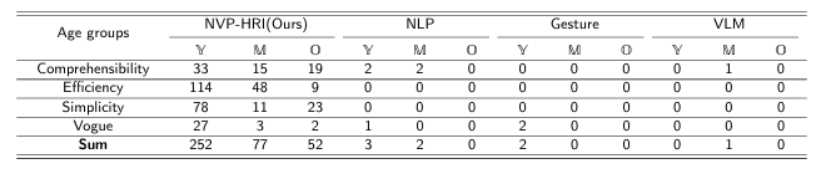
文章链接:
https://arxiv.org/abs/2503.09335
05
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
有效地获取外部知识和最新信息对于大型语言模型(LLMs)进行有效推理和文本生成至关重要。检索增强和工具使用训练方法中,将搜索引擎视为一种工具,缺乏复杂的多轮检索灵活性或需要大规模的监督数据。在推理过程中,通过提示先进的LLMs以使用搜索引擎并不是最优的,因为LLM没有学习如何最优地与搜索引擎交互。本文介绍了SEARCH-R1,它是DeepSeek-R1模型的扩展,其中LLM仅通过强化学习(RL)自主生成(多个)搜索查询,在实时检索中进行逐步推理。SEARCH-R1通过检索标记掩蔽优化LLM推出,利用检索标记掩蔽进行稳定的RL训练,并采用简单的基于结果的奖励函数。在七个问答数据集上的实验表明,SEARCH-R1通过26%(Qwen2.5-7B)、21%(Qwen2.5-3B)和10%(LLaMA3.2-3B)超过了SOTA基线。
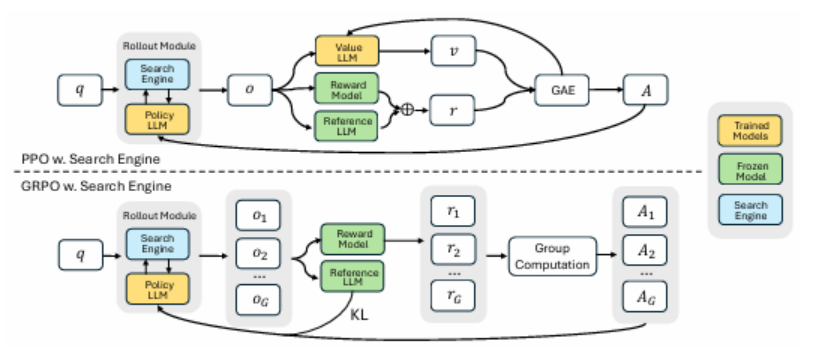

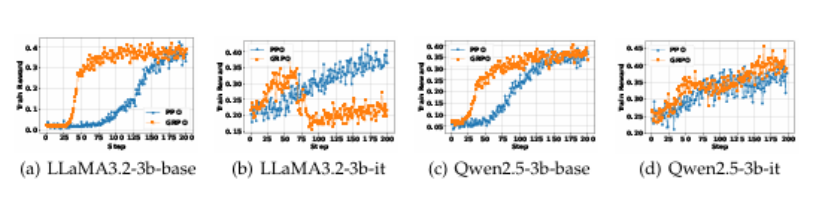
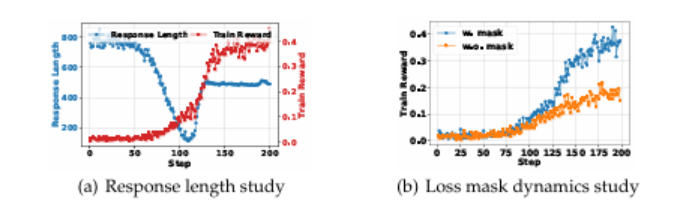
文章链接:
https://arxiv.org/pdf/2503.09516
06
Considering Length Diversity in Retrieval-Augmented Summarization
本研究探讨检索增强摘要的长度限制下,具体检查样本摘要长度的影响,不包括以前的工作。我们提出了一种多样的长度感知最大边缘相关性(DL-MMR)算法,以更好地控制摘要长度。该算法结合检索增强摘要的查询相关性与不同的目标长度。与需要使用MMR进行详尽的范例范例相关性比较的先前方法不同,DL-MMR还考虑了范例目标长度,并且避免了将范例彼此进行比较,从而在范例池的构建期间降低了计算成本并节省了存储器。实验结果表明,DL-MMR,它考虑了长度的多样性,与原始的MMR算法相比,有效性。DL-MMR还显示了在保持相同信息量水平的同时,节省781,513次内存和减少500,092次计算成本的有效性。
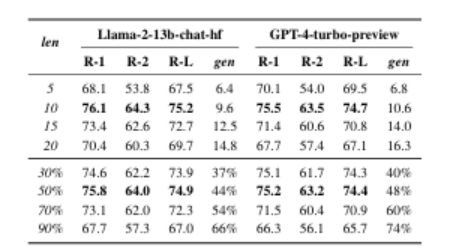
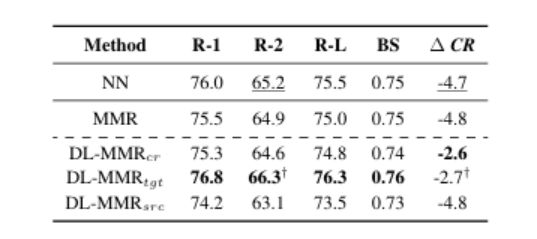
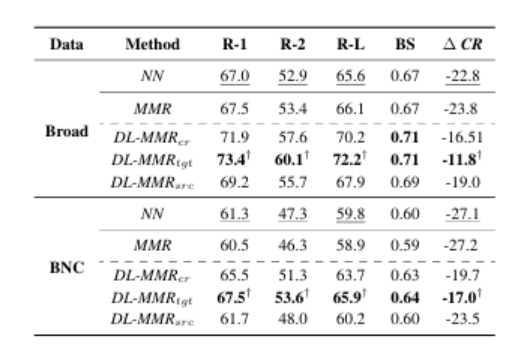
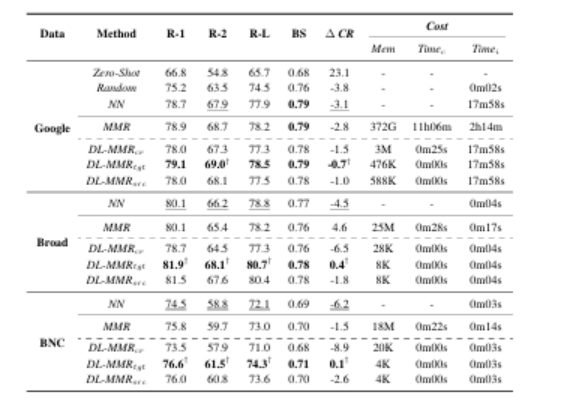
文章链接:
https://arxiv.org/pdf/2503.09249
07
Cost-Optimal Grouped-Query Attention for Long-Context LLMs
构建高效且有效的基于Transformer的大型语言模型(LLMs)已成为当前的研究热点,目标是在最小化训练和部署成本的同时最大化模型的语言能力。以往的研究主要关注模型性能、参数规模和数据规模之间的复杂关系,并寻找最优的计算资源分配以训练LLMs。然而,这些研究忽略了上下文长度和分组查询注意力配置(即分组查询注意力中查询头和键值头的数量)对训练和推理的影响。本文系统地比较了不同参数规模、上下文长度和注意力头配置的模型在性能、计算成本和内存成本方面的表现,并扩展了现有的仅基于参数规模和训练计算的扩展方法,以指导在训练和推理阶段构建成本最优的LLMs。本研究的量化扩展研究表明,在处理足够长的序列时,更大的模型使用更少的注意力头可以在更低的计算和内存成本下实现更低的损失。这些发现为开发实用的LLMs,尤其是在长文本上下文处理场景中,提供了宝贵的见解。
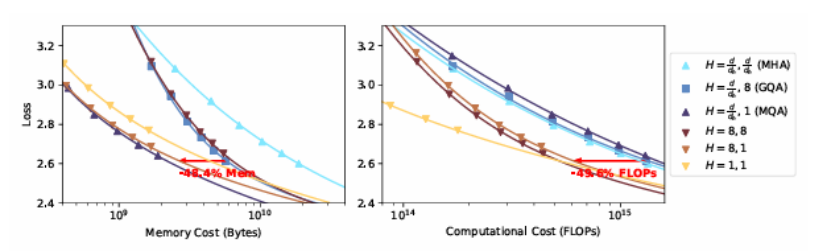
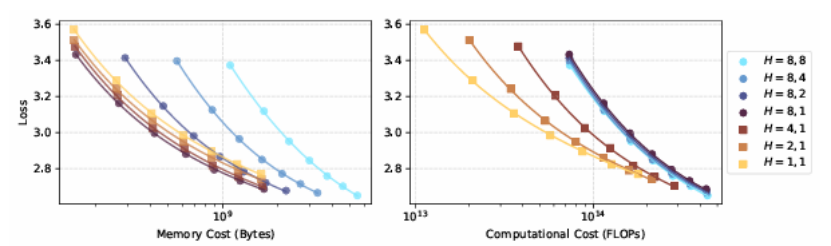
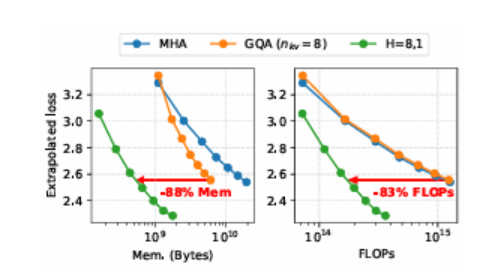
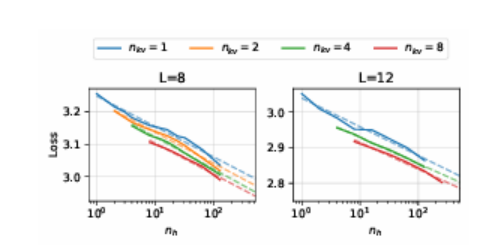
文章链接:
https://arxiv.org/pdf/2503.09579
本期文章由陈研整理
往期精彩活动分享

CVPR 2025一作讲者招募中,欢迎新老朋友来预讲会相聚!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看更多!