爬虫:基本流程和robots协议
基本流程:

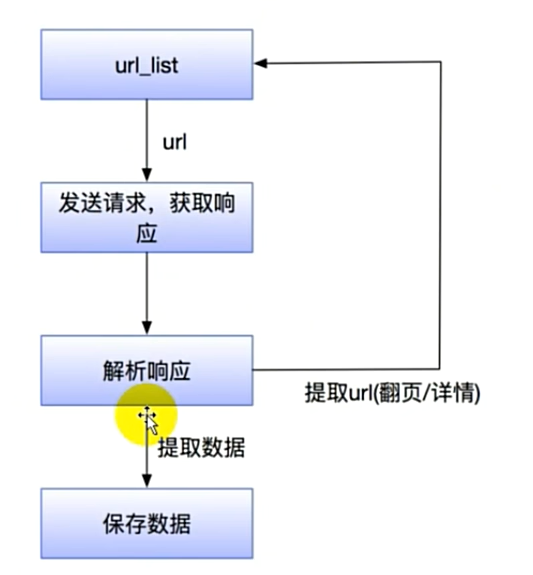
1.确认目标:url:www.baidu.com
2.发送请求:发送网络请求,获取到特定的服务端给你的响应
3.提取数据:从响应中提取特定的数据
4.保存数据:本地(html,json,txt),数据库
获取到的响应中,有可能会提取到还需要继续发送请求的url,可以拿着解析到的url继续发送请求
robots协议:并不是规范,只是约定俗成的,是一种通过简单文本文件(robots.txt)来规范搜索引擎爬虫等网络机器人对网站内容访问行为的协议。
User - Agent: 用于指定适用的爬虫名称,*代表所有爬虫。Disallow: 后面跟禁止访问的路径,例如/private/表示禁止访问所有以/private/开头的目录。Allow: 用于允许访问特定路径,常常和Disallow配合使用。Sitemap: 可指定网站地图文件的位置,方便爬虫快速发现网站内容。