从零构建大语言模型全栈开发指南:第三部分:训练与优化技术-3.2.1模型并行与数据并行策略(ZeRO优化器与混合精度训练)
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- 3.2.1 模型并行与数据并行策略(`ZeRO`优化器与混合精度训练)
-
- 1. 分布式训练核心策略对比
-
- 1.1 数据并行(`Data Parallelism`)
- 1.2 模型并行(`Model Parallelism`)
- 2. 混合并行策略与ZeRO优化器
-
- 2.1 ZeRO(Zero Redundancy Optimizer)原理
- 2.2 ZeRO-3实现架构
- 3. 混合精度训练优化
-
- 3.1 `FP16/BF16`精度对比
- 3.2 混合精度实现流程
- 4. 通信优化技术
-
- 4.1 通信原语优化
- 4.2 3D并行策略
- 5. 工程实践与性能调优
-
- 5.1 `DeepSpeed`配置示例
- 5.2 性能调优检查表
- 6. 典型案例分析
-
- 6.1 `GPT-3 175B`训练配置
- 6.2 千卡集群训练优化成果
- 总结:分布式训练的黄金法则
3.2.1 模型并行与数据并行策略(ZeRO优化器与混合精度训练)
1. 分布式训练核心策略对比
1.1 数据并行(Data Parallelism)
-
实现原理:
- 每个GPU持有完整模型副本
- 批量数据分片到不同设备
- 通过AllReduce同步梯度
-
数学表达:
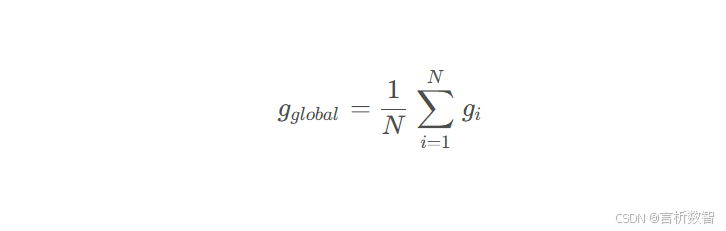
-
表1:数据并行性能分析(8×A100 GPU)
模型规模单卡Batch Size 吞吐量(samples/s)显存