Kubernetes service 基于工作原理的实验
1.ClusterIP 实验
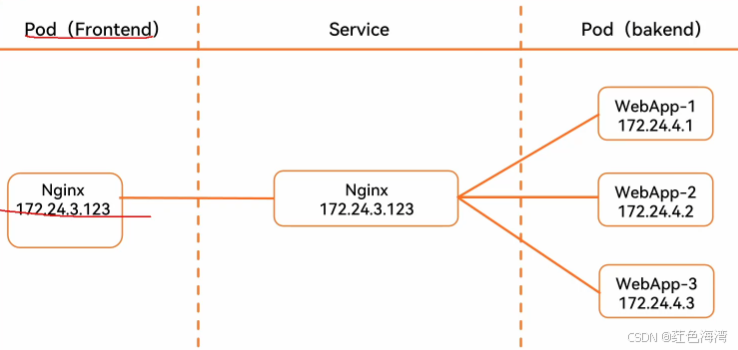

元数据 当前service的名字
命名空间 default
期望:
工作模式 ClusterIP 默认 ClusterIP
标签选择器 : pod 的标签 做子集运算 selector 必须是pod的 子集就可以 匹配上
然后定义我们当前你的负载均衡集群端口
端口给个名字 :http
集群端口 80
后端真实服务器的端口 80
1.IPVS多种工作方式
1.NAT模式
这种模式好处在于 后端端口跟集群端口可以不一样,缺点在于我们当前的流量,还必须要经过ipvs的调度器本身 不管是入栈还是出栈
2.DR模式 直接路由模式
它的好处在于回程流量不需要经过负载接收器,本身压力会更小 缺点在于 它可能需要对我们当前的ARP的响应和通况行为做设定 而且后端端口和集群负载均衡的端口 必须一致
3.TUN隧道模式
这个缺点在于 当前它的性能会比较低,因为需要跨多个物理公网环境,而且还需要做数据报文的二次封装
优点在于 可以跨公网网络进行集聚化的组建
4.fullnat 模式
当前kubeproxy 默认是以ipvs 的 NAT模式 进行工作的
大家可以明确的发现 当前我们kubernetes集群创建的service 它的集群端口和后端真实服务器端口可以不一致
大家会有一个疑问,NAT没有DR性能那么强吗,为什么不用DR
其实每一个机器上的ipvs的规则 只会被当前机器的客户端所访问,如果客户端要访问服务器端的话它会借助本地的ipvs规则,去导向到它到它 那如果这个节点的客户端,它不会访问到我节点的ipvs
再加上每个kubernetes 节点最大pod 数量,所以我们可以确认每个机器的ipvs集群,它的规模访问根本不会超过300个,那在这种情况下 你说我不管是nat模式好还是DR模式也好,有多少性能影响呢,
2.开始实验
kubectl create svc clusterip myapp --tcp=80:80 --dry-run -o yaml这是以前的创建模式
测试创建导出资源清单

这样创建的方式默认是以自己service名字 为值 app 为key 作为pod 选择器

1.创建deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-clusterip-deploy
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp
release: stabel
svc: clusterip
template:
metadata:
labels:
app: myapp
release: stabel
env: test
svc: clusterip
spec:
containers:
- name: myapp-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
readinessProbe:
httpGet:
port: 80
path: /index1.html
initialDelaySeconds: 1
periodSeconds: 3ports 端口 设置name就是给 80起了一个别名 仅此而已 可以让service 访问 一个叫 http 的端口仅此而已
再给我们的mainC 加上就绪探测
kubectl apply -f myapp-deploy.yaml
发现未就绪
1.svc 选中pod的逻辑
- pod初一就绪状态
- svc标签是pod标签的子集 (同一个名称空间下)
2.创建svc
apiVersion: v1
kind: Service
metadata:
name: myapp-clusterip
namespace: default
spec:
type: ClusterIP
selector:
app: myapp
release: stabel
svc: clusterip
ports:
- name: http
port: 80
targetPort: 80ports
port 定义当前service负载均衡的端口
targetPort 是后端真实服务器的端口
windows部署kubectl
参考以下链接
https://cloudmessage.top/archives/k8s-zai-windowszhong-shi-yong-kubectllian-jie-ji-qun
10.3.57.76这就是ipvs集群的 虚拟IP 也叫VIP 或叫集群IP
3.未就绪原因
定义deployment 里面的pod 的规格的时候 去定义了就绪探测,http形式,访问的是pod的80端口里面的index1.html文件,但是在镜像中 故意 没有这个文件,所以无法就绪
因为不满足就绪
![]()
所以访问集群是访问不通的
我们可以看一下ipvs集群
ipvsadm -Ln 
这里会有一个TCP的 集群 地址是10.3.57.76 和上面 svc 分配的 地址是一样的 算法 rr 轮询的方式负载均衡
真实服务器为空 原因很简单 达到我的要求的没有
标签虽然都达到了,但是pod未就绪 所以不满足我的规则

往我们一个pod中加入index1.html文件 让其中一个就绪
由于我们给第一个添加了index1.html 文件

所以它就绪了

这时候已经能够访问到了
![]()
看一下负载均衡结果
 4.我们又给第二个加上 index1.html文件
4.我们又给第二个加上 index1.html文件

5.访问svc方式
1.通过cluseterip
kubectl get svc2.通过DNS插件
每一个service创建完成后都会去有一个DNS的域名在我们的插件中被解析 解析的结果就是当前此IP
1.安装一个工具 bind-utils
yum -y install bind-utilsbind 就是伯克利大学的 名字解析服务 utils 是他的工具包 我们可以得到一个DNS的测试工具
dig -t A myapp-clusterip.default.svc.cluster.local. @10.0.0.10dig 后面跟-t 代表tcp进行解析 A 代表A记录 当前svc的名字.当前所在的名称空间.svc.默认域名
默认域名是在我们集群内部去用的改不改其实说实话影响不大
这时候我们在后面 加上一个 @ 跟上我们另一个 IP 这个是 就是你要把这个域名进行A记录解析
找谁解析呢 那我们这边很显然找的是我们集群内部的DNS插件 我们可以通过
kubectl get pod -n kube-system | grep dns
大家就会发现有两个出现了
当然我们可以加上 -o wide 看一下ip地址
kubectl get pod -n kube-system -o wide | grep dns
然后我们在看一下 ipvs 集群规则
ipvsadm -Ln
特别注意一下 kubernetes 已经帮我们创建了一个 ipvs 集群 已经被添加成了一个 10.0.0.10:53 的负载均衡集群了,别人帮你写好了 甚至底下还有UDP的
那对于DNS来说 默认一般tcp用于数据同步 UDP 用于我们的解析 当然如果多次采用UDP 解析不通过的话 也会允许到tcp解析 当然现在还有很多厂商呢 在基于http 协议封装的DNS解析过程 这种我们就不再赘述了
回到我们默认情况下,那也就意味着如果我们想要访问DNS服务的话 没必要去找这两个pod的IP,而是直接向10.0.0.10发起解析即可 反正有负载均衡帮我们找到最后的 两个DNS插件的 pod IP上
当然由于你集群设置的参数可能不一样,那这个值也可能有所区别所以建议大家自己先按上面步骤查询一下

解析成功了

解析完全一致
当然也有人担心 那我创建的pod 能用这两个DNS服务器吗 别忘我们的物理机的DNS是我们自己指定的 但kubernetes及其内部的pod 它的默认DNS 都是只想到这两个DNS插件的IP上的,所以不需要我们配置 它就可以解析通过
2.找个pod来试一下
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
namespace: default
labels:
app: myapp
spec:
containers:
- name: busybox-1
image: wangyanglinux/tools:busybox
command:
- "/bin/sh"
- "-c"
- "sleep 3600"这个镜像里是由我们对应的curl命令的

跑起来了 我们以它当客户端去访问一下当前的域名
kubectl exec -it pod-demo -- /bin/wget http://myapp-clusterip.default.svc.cluster.local./hostname.html && cat hostname.html && rm -rf hostname.html
在我们pod内部本身默认就把我们的 DNS指向到了 我们的dns插件上了,所以你的域名是可以直接使用的 不需要再像dig 一样解析域名指向 我们的DNS插件 @哪个DNS服务器
这就是我们两种访问当前service的方式
3.各有利弊
service没有创建 访问域名就可以知道它的ip地址 通过访问域名可以不需要知道IP
6.策略方式


默认为Cluster类型
Local类型 与 Cluster类型
kubectl edit svc myapp-clusterip 改成Local
改成Local
1.进入我们测试pod的内部 再访问

会发现进入pod内部用 域名访问可以
但是出来后用 ip访问被拒绝了
我们说一下Local的含义
只会路由你访问节点地址的Pod 由于我们是在master节点上面 调用 ip
master上面根本没有允许pod 所以这样的流量会被丢弃掉
注意官方特别强调 Drop
那如果学习过防火墙的 netfilter 的 你可以知道 我们不想让他访问 有两种处理方式 一种是Reject 一种是 Drop, Reject是 直接拒绝 Drop是直接丢弃 不让进 这里采用的是Drop方式直接把流量丢弃掉
到node01 上面执行就能访问到了 而且只能访问 node01 上面的pod

3.进阶理解
之前我们在自己学习ipvs或LVS的时候,我们应该有了解过其中的一个特性,我们叫持久化连接,
对于持久化连接它的作用是什么呢,可以将我们的用户请求 定向再一台机器上,当然我们需要加一个前缀 就在有限的时间内 将用户的请求定向到同一台机器 那当然有人可能会问 那这个跟 lvs的 SH算法有什么区别呢? 原地址散列,不也是将一个同样的客户请求 定向到同一台机器吗 但SH比较呆板 只要我们对于的hash表没有被清理 那这样的用户始终会被定向到同一台机器 根本不会去考虑它的重复的访问 包括负载是否均衡 可能会有这方面的问题
但是我们的持久化连接呢 它会在有限的时间内 我们会在定义持久化连接的时候 加一个-p 的选项
比如这条命令应该是这样的
ipvsadm -A -t 192.168.72.100:80 -s rr -p120
-s 指定负载均衡算法
-p 指定持久化连接的时间 秒
那这样我们可以添加一个持久化连接
把客户定向到目标机器的有效时间 就是120 秒
当我们通过LVS去访问后端服务器的 比如 rs1 rs2 ,我们第一次过来访问的时候 我们持久化连接虽然开了 但在我的LVS里 没有你客户端和真实服务器的对应关系 那第一个我可能根据我的rr算法帮你定向在了rs1 的机器 定向完成后 我就会把你的客户端的标记 比如地址和端口 与真实服务器的进行绑定 进行映射 当然后面会出现一个有限时间 120秒 那这个秒会逐渐衰弱 119 118 倒计时 直到0 时 这条记录就被清除 如果衰减到60秒 客户端再一次来访问 我们是有此纪录的 所以根据记录 我会直接定向到rs1 的机器 如果衰减为 0 的话就被清楚 ,我就相当于第一次过来,又被负载均衡算法分配到某个机器上面又开始120 秒的倒计时
所以是在有限时间内将 源定向到同一台机器 这么一种的模式
相对我们的SH算法来说 会更灵活 更有效 目前主要的应用场景就是在于https的 请求里
我们知道https如果要建立连接的话 前面需要比较多的一个沟通的过程比如确定我们SSL的版本
确定我们的加密算法 确定我们的密钥 后续才能进行加密访问 当我刚开始跟你建立了加密访问
结果我发生了一个请求以后 下一次我被定向到了一个台新的机器 我跟新的机器又需要重复的进行https的这么一个加密过程 是比较浪费资源的 所以在https的集群中 如果需要做负载均衡集群的话 那我们是完全可以 通过ipvs的持久化连接 去实现对应的功能 会更好用一些
那这样的持久化功能 我们当时应该也学过对应的分类是吧 比如基于客户端持久化连接 基于端口连接 基于防火墙标记连接 那么这里我们就不再赘述了
如果想把lvs的持久化连接 引入到当前kubernetes集群内部的话 那这里会出现一个叫 会话亲和性
说白了底层就是在使用ipvs的持久化连接 去实现 比较我们知道当前的service 它的4层实现 底层就是基于ipvs实现的
4.基于ipvs实现持久化连接(实验)

1.先展示不加 这个持久化连接的结果

先把上面改成Local的 配置改回来
 这是他会负载到三个pod都去访问
这是他会负载到三个pod都去访问
也就是我们所谓的没有加 ipvs的持久化连接的结果
2.会话保持
如果加了 就叫会话保持

找到这个 默认 是None
 改成 ClientIP
改成 ClientIP
如果我们要设置它的 持久化连接时间

这个对象 下的这个字段 默认是3 小时 值必须要大于0 &&<=86400 一天

改完以后再次访问,他就持久化定向到了同一个机器上
不像刚才我们是不是在第一个和第二个反复横跳 因为当前的默认的算法是 rr
当然我们也可以从底层的原理去看一下
ipvsadm -Ln
其他没有被持久化的 ip 是不是没有加 persistent 10800
代表我们当前的 这个 svc开启持久化连接了
你可以将持久化时间调节低一点 但是有些不同内核版本的 ipvs 对于秒数比较低的支持不是那么理想
那么第一种工作模式就讲完了
2.NodePort 类型 实验
主要就是把集群内部的服务暴露给集群以外

如果是集群内部的互相沟通 我们更建议大家通过clusterip 去使用 原因很简单 nodeport 是一种升级版的cluseterip 不仅可以做到 clusterip 拥有的功能 还支持在当前的物理网卡上 去绑定一个物理端口 以此去实现外部访问 但是功能越多 相当于它消耗的代价就会越高 但如果你不需要集群外部的访问 又消耗了更多的一些额外资源 它肯定是不理想的
1.实验前的准备
1.创建service NodePort 类型
nodeport 对于物理网卡上面的端口 一般要大于30000 但是可以在apiserver启动的时候 配置 来调节最小的端口
apiVersion: v1
kind: Service
metadata:
name: myapp-nodeport
namespace: default
spec:
type: NodePort
selector:
app: myapp
release: stabel
svc: nodeport
ports:
- name: http
port: 80
targetPort: 80
nodePort: 30010如果ports 设置多个
那么每个port 的name值 端口值 后端端口值 nodeport值必须一样 否则会引起冲突
port 代表是通过集群内部访问这个负载调度器 这个负载调度器的端口是多少
targetPort 后端的真实服务器的端口号
nodePort 那这个代表的是我们当前的物理网卡上绑定的物理的端口号 当然默认情况下我们说过很多次了 最好是大于 30000以上 而且官方强烈不建议你去通过nodeport 手动去指定这个端口号
你若不写官方会帮你自动去分配 这种是更理想的一种状态 防止我们端口号冲突 好那这就是一个nodeport的资源清单的一个解释
2.创建deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-nodeport-deploy
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp
release: stabel
svc: nodeport
template:
metadata:
labels:
app: myapp
release: stabel
env: test
svc: nodeport
spec:
containers:
- name: myapp-container
image: wangyanglinux/myapp:v1.0
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 802.访问测试


下面是对内部的 上面是对外部

在内部访问没有问题
pod内部用DNS访问 也没有问题
wget myapp-nodeport.default.svc.cluster.local./hostname.html && cat hostname.html && rm -rf hostname.html
它相当于是支持我们当前 svc clusterip 类型的 所有功能 那额外的功能在哪里呢 就来自于物理网卡的此端口的集群 以外的访问
它是怎么去实现的呢 其实原理很简单
我们看一下ipvs 集群
ipvsadm -Ln
他把我当前的物理网卡 192.168.72.11的30010 做了一个负载均衡集群 负载到的依然是当前的每个节点真实的服务器
把172.17.0.1也做了 docker0的网卡
这都是我们当前可以的网卡信息
如果你机器有多块网卡的话它会把当前机器的每一块可用网卡的地址 都帮你写一个ipvs集群
ipvsadm -Ln 看到是本机的 ipvs集群
通过外界访问 依然能够访问到


好像默认开启了持久化 对外界浏览器,但在内部还不是持久化
每一个节点的物理网络的这个端口 都可以对此进行访问在真正的生产环境中 我们可能需要在外部再加一个调度器去负载到当前的每一个节点
以此保证当前任何一个节点死亡不会造成我们用户的访问中断 那万一你把用户直接定向过来了
节点死了,那不是造成不可用了嘛
3.注意

nodeport 有个和 clusterip 很像的 配置 就是 externalTrafficPolicy 默认是 Cluster 可以负载均衡到任意node,改成 Local 就会变成 只能访问当前node 下的pod
在ClusterIP 类型 中 internalTrafficPolicy 叫这个 是指 在 node 内部 访问 service,只能访问 当前node下的 pod
如果比如你要访问 master 但我master根本没有pod 那我就会把你的请求进行 Drop 掉 丢弃掉
好 我们的 NodePort 就讲完了
3.LoadBalancer 结构 类型 实验
我们说过 对于纯粹的 nodeport 它没有办法给我们解决高可用的问题

一般我们会在前面架一个调度器 可以是4层 可以是 7层
可以用 F5 可以用 IPVS 可以用 nginx
有没有更加方便的方案呢 有但是 有个前提 必须工作在云的环境中 比如 阿里云 比如 百度云

这种方式只能以云的方式去使用
这是阿里云的

仅适用于公网的 云中
4.ExternalName结构

前面三种类型都需要依赖于底层的 ipvs 参与 但是这个 特别 ,不需要ipvs的参与,仅仅只是靠我们的DNS的插件
CNAME的别名机制去实现DNS的转换 我们只需要去找DNS插件去进行一个固定域名解析 ,他就可以帮我们解析到外部的这个服务的对应的具体的ip或域名上,当然如果外部的Mysql 的IP 或域名修改了 那我们只需要修改这个externalname 的 CNAME 的记录就可以了 后续所有的Tomcat 的pod 都不需要你去更改 相当于解耦了
kind: Service
apiVersion: v1
metadata:
name: my-service-1
namespace: default
spec:
type: ExternalName
externalName: www.baidu.com当pod内部请求 这个service 的域名 也就是 my-service-1.default.svc.cluster.local. 的时候 会解析成www.baidu.com

那百度的解析结果给我


当然很显然一定是集群内部的pod 或者是集群上的工具去访问的 ,一定不能在集群以外使用
集群以外的客户端并不会把他的DNS 指向到你集群内部的这么一个DNS插件上
 查看ipvs 的持久化记录
查看ipvs 的持久化记录
ipvsadm -lnc