图片解释git的底层工作原理
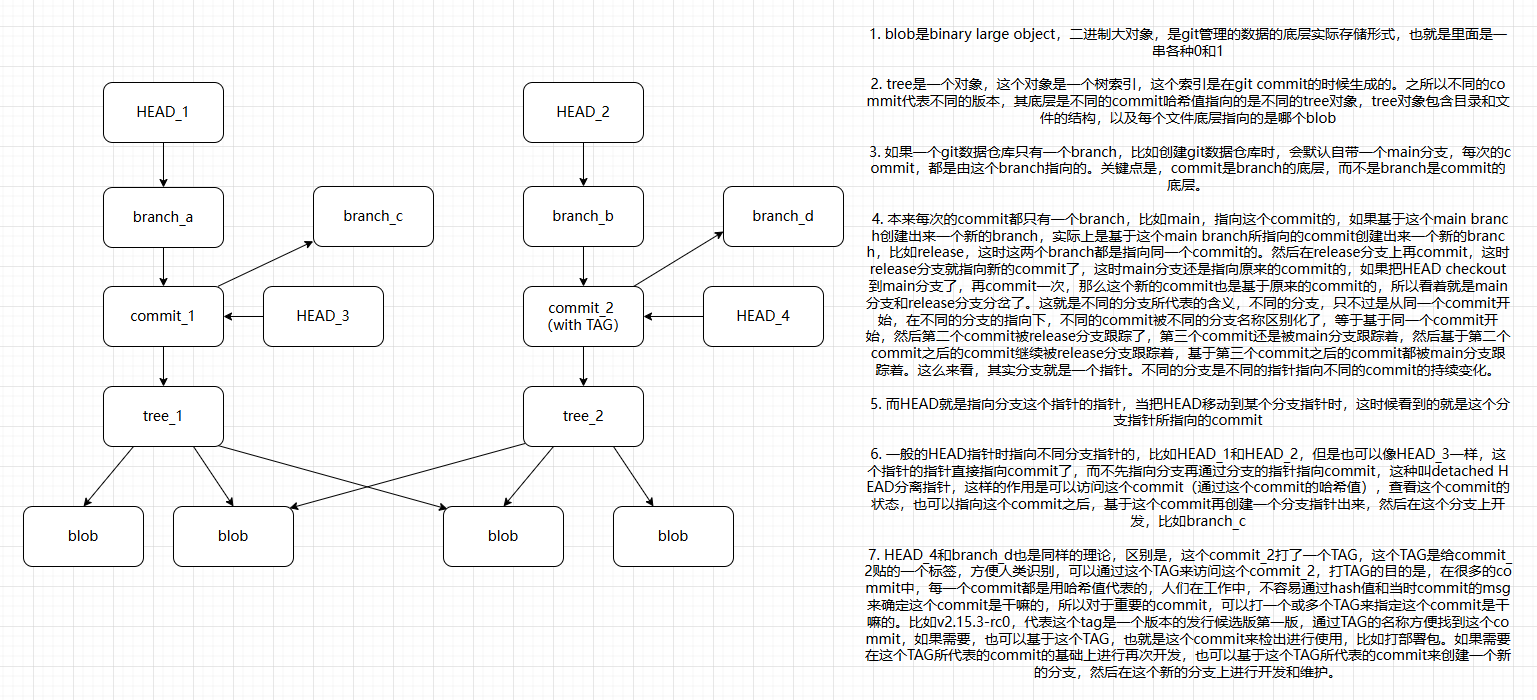
(图片来源:自己画的)
基于同一个commit创建新分支
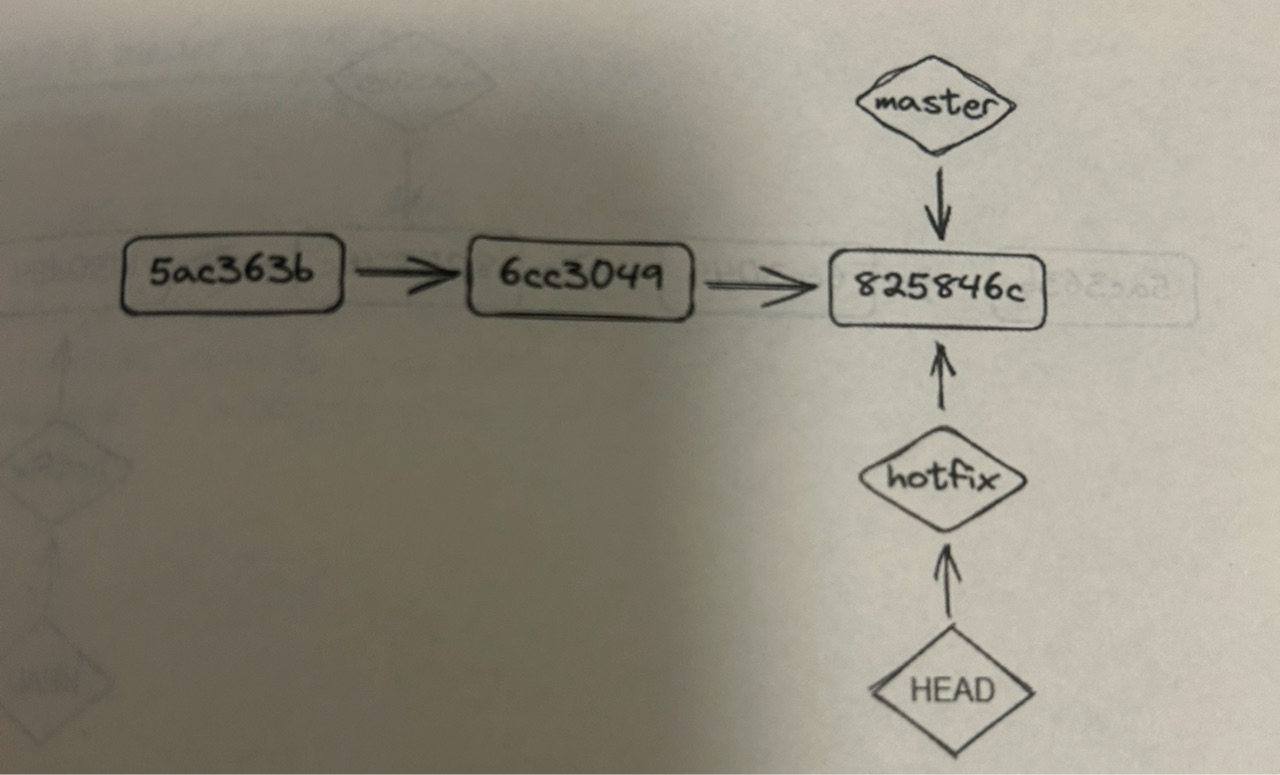
(图片来源:书籍《Linux运维之道》 ISBN 9787121461811)
在新分支上修改然后commit一次
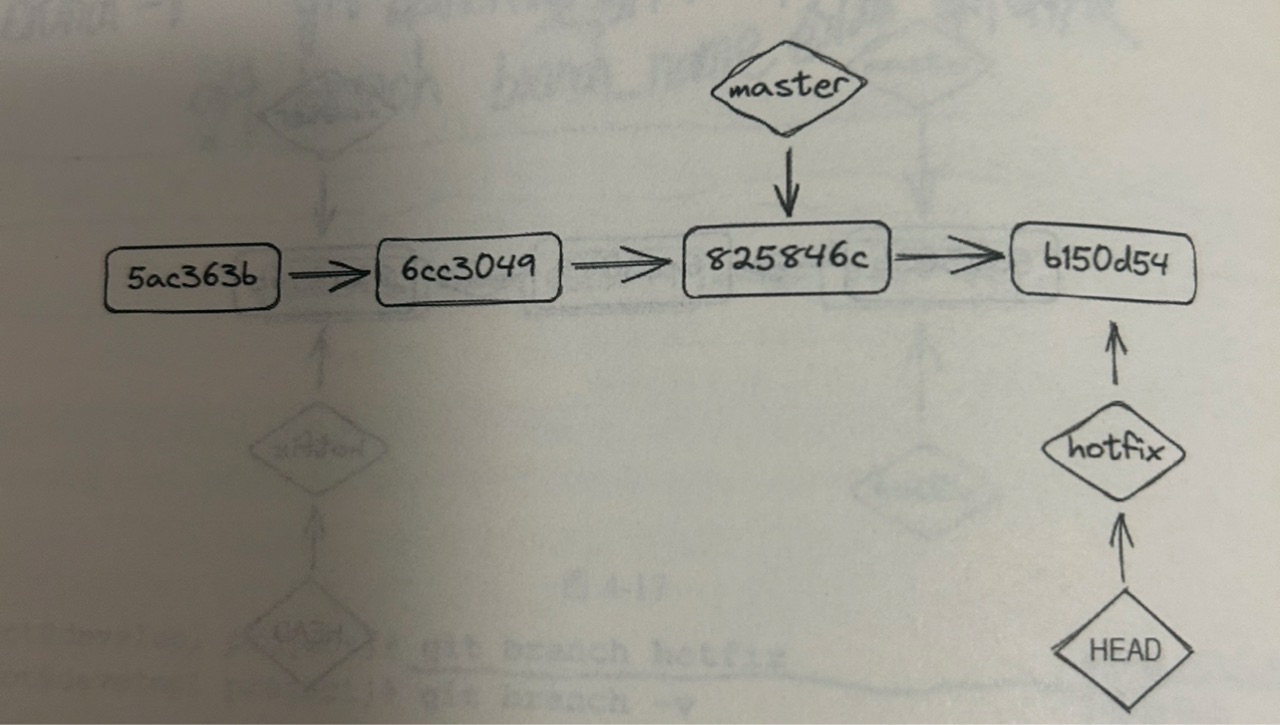
(图片来源:书籍《Linux运维之道》 ISBN 9787121461811)
在旧分支上也修改并commit一次
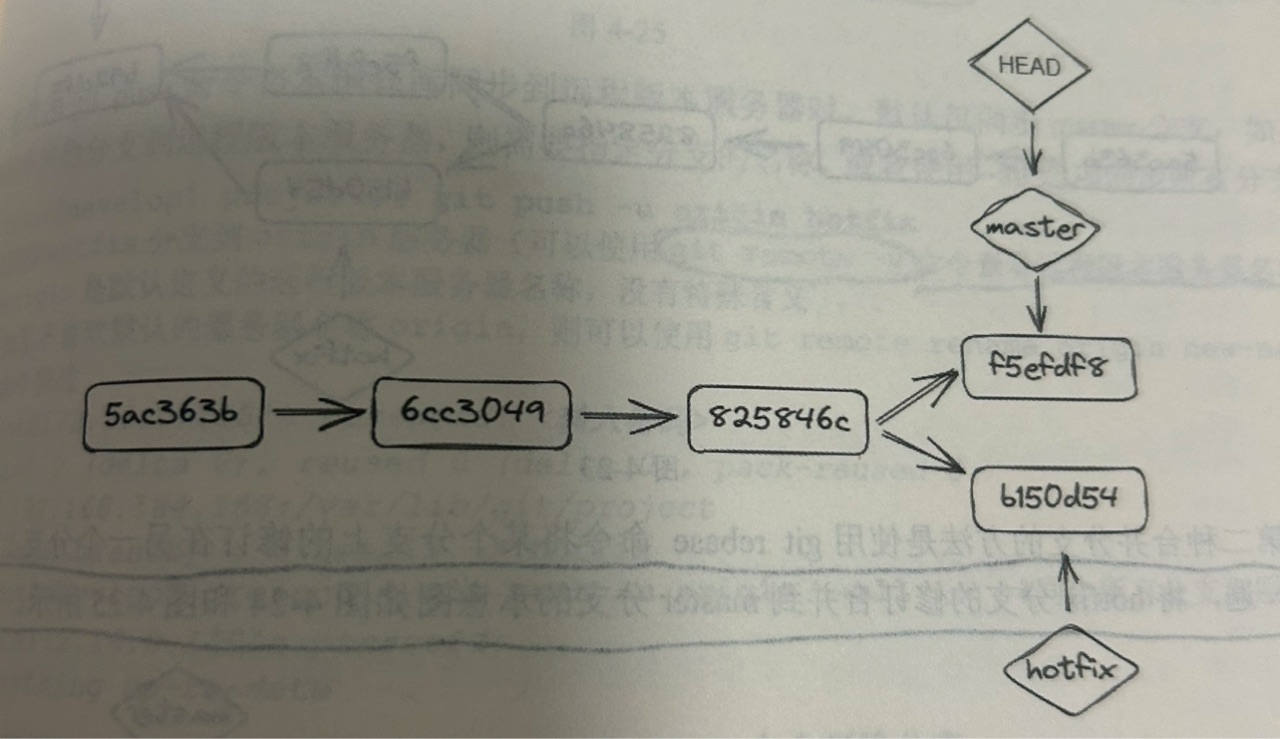
(图片来源:书籍《Linux运维之道》 ISBN 9787121461811)
1. blob是binary large object,二进制大对象,是git管理的数据的底层实际存储形式,也就是里面是一串各种0和1
2. tree是一个对象,这个对象是一个树索引,这个索引是在git commit的时候生成的。之所以不同的commit代表不同的版本,其底层是不同的commit哈希值指向的是不同的tree对象,tree对象包含目录和文件的结构,以及每个文件底层指向的是哪个blob
3. 如果一个git数据仓库只有一个branch,比如创建git数据仓库时,会默认自带一个main分支,每次的commit,都是由这个branch指向的。关键点是,commit是branch的底层,而不是branch是commit的底层。
4. 本来每次的commit都只有一个branch,比如main,指向这个commit的,如果基于这个main branch创建出来一个新的branch,实际上是基于这个main branch所指向的commit创建出来一个新的branch,比如release,这时这两个branch都是指向同一个commit的。然后在release分支上再commit,这时release分支就指向新的commit了,这时main分支还是指向原来的commit的,如果把HEAD checkout到main分支了,再commit一次,那么这个新的commit也是基于原来的commit的,所以看着就是main分支和release分支分岔了。这就是不同的分支所代表的含义,不同的分支,只不过是从同一个commit开始,在不同的分支的指向下,不同的commit被不同的分支名称区别化了,等于基于同一个commit开始,然后第二个commit被release分支跟踪了,第三个commit还是被main分支跟踪着,然后基于第二个commit之后的commit继续被release分支跟踪着,基于第三个commit之后的commit都被main分支跟踪着。这么来看,其实分支就是一个指针。不同的分支是不同的指针指向不同的commit的持续变化。
5. 而HEAD就是指向分支这个指针的指针,当把HEAD移动到某个分支指针时,这时候看到的就是这个分支指针所指向的commit
6. 一般的HEAD指针时指向不同分支指针的,比如HEAD_1和HEAD_2,但是也可以像HEAD_3一样,这个指针的指针直接指向commit了,而不先指向分支再通过分支的指针指向commit,这种叫detached HEAD分离指针,这样的作用是可以访问这个commit(通过这个commit的哈希值),查看这个commit的状态,也可以指向这个commit之后,基于这个commit再创建一个分支指针出来,然后在这个分支上开发,比如branch_c
7. HEAD_4和branch_d也是同样的理论,区别是,这个commit_2打了一个TAG,这个TAG是给commit_2贴的一个标签,方便人类识别,可以通过这个TAG来访问这个commit_2,打TAG的目的是,在很多的commit中,每一个commit都是用哈希值代表的,人们在工作中,不容易通过hash值和当时commit的msg来确定这个commit是干嘛的,所以对于重要的commit,可以打一个或多个TAG来指定这个commit是干嘛的。比如v2.15.3-rc0,代表这个tag是一个版本的发行候选版第一版,通过TAG的名称方便找到这个commit,如果需要,也可以基于这个TAG,也就是这个commit来检出进行使用,比如打部署包。如果需要在这个TAG所代表的commit的基础上进行再次开发,也可以基于这个TAG所代表的commit来创建一个新的分支,然后在这个新的分支上进行开发和维护。