Pytorch学习笔记(六)Learn the Basics - Automatic Differentiation
这篇博客瞄准的是 pytorch 官方教程中 Learn the Basics 章节的 Automatic Differentiation 部分。
- 官网链接:https://pytorch.org/tutorials/beginner/basics/autogradqs_tutorial.html
完整网盘链接: https://pan.baidu.com/s/1L9PVZ-KRDGVER-AJnXOvlQ?pwd=aa2m 提取码: aa2m
Automatic Differentiation with torch.autograd
在训练神经网络时,最常用的算法是反向传播,参数根据损失函数相对于给定参数的梯度进行调整。PyTorch 有一个内置的微分引擎,称为 torch.autograd 支持自动计算任何计算图的梯度。
Step1. 定义一个网络
以最简单的单层神经网络,输入 x、参数 w 和 b 以及一些损失函数。它可以按以下方式在 PyTorch 中定义:
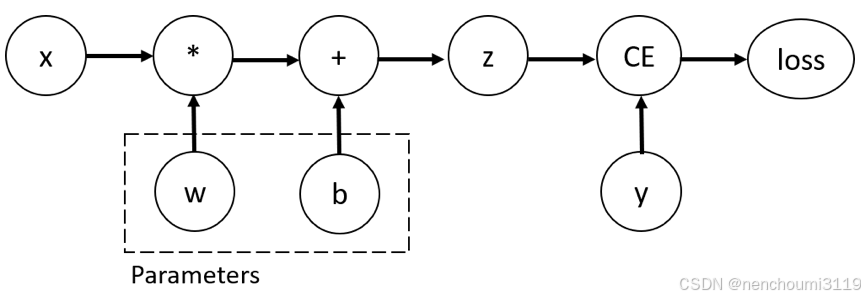
在这个网络中,w 和 b 是待优化的参数,需要能够计算损失函数相对于这些变量的梯度,通过设置Tensor的 require_grad 属性让其能够使用梯度进行训练:
import torch
x = torch.ones(5)
y = torch.zeros(3)
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x,w) + b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z,y)
pytorch中构建的计算图函数实际上是 Function 类的对象。该对象知道如何计算前向传播,以及后向传播步骤中的导数。对反向传播函数的引用存储在Tensor的 grad_fn 属性中。
print(f"Gradient function for z = {z.grad_fn}")
print(f"Gradient function for loss = {loss.grad_fn}")
Step2. 进行一次反向传播
可以对网络中的一个节点进行一次反向传播然后观察参数的梯度与偏置值,默认状态下计算图在这次之行后自动删除,通过设置参数 retain_graph=True 让计算图在反向传播后保留下来:
loss.backward() # loss.backward(retain_graph=True)
print(w.grad)
print(b.grad)
Step3. 取消梯度跟踪
默认情况下,所有Tensor都会跟踪其计算历史并支持梯度计算。 但是有些情况下不需要这样做,例如,当已经训练了模型并且只想将其进行推理时(即只希望进行前向传播)或者在训练模型时想要冻结一部分参数 ,可以通过增加 torch.no_grad() 块来停止跟踪计算:
z = torch.matmul(x, w) + b
print(z.requires_grad)
with torch.no_grad():
z = torch.matmul(x, w) + b
print(z.requires_grad)
More on Computational Graphs
autograd 在由 Function 对象组成的有向无环图 (DAG) 中保存Tensor、所有执行的操作、生成的新Tensor。在 DAG 中,叶子是输入Tensor,根是输出Tensor。通过从根到叶子跟踪此图可以使用链式法则自动计算梯度。
在前向传递中,autograd 同时执行两件事:
- 运行请求的操作以计算结果Tensor;
- 在 DAG 中维护操作的梯度函数;
在 DAG 根节点上调用 .backward() 时反向传播就开始了,autograd 然后从每个 .grad_fn 计算梯度,使用链式法则将它们累积在相应Tensor的 .grad 属性中,一直传播到叶子节点的Tensor。
Tensor Gradients and Jacobian Products
在许多情况下,有一个标量loss function,需要计算关于某些参数的梯度。然而有些情况下输出函数是任意Tensor。在这种情况下,PyTorch 允许计算雅可比积,而不是实际梯度。
inp = torch.eye(4,5, requires_grad=True)
out = (inp + 1).pow(2).t()
out.backward(torch.ones_like(out), retain_graph=True)
print(f"First call:\n{inp.grad}")
out.backward(torch.ones_like(out), retain_graph=True)
print(f"Second call:\n{inp.grad}")
inp.grad.zero_()
out.backward(torch.ones_like(out), retain_graph=True)
print(f"Call after zeroing gradients:\n{inp.grad}")