LUMOS: Language-Conditioned Imitation Learning with World Models
LUMOS:基于世界模型的语言条件模仿学习框架
伊曼·内马托拉希1,布兰顿·德莫西2,阿克沙伊·L·钱德拉1,尼克·霍斯2,沃尔夫拉姆·布尔加德3,英格玛·波斯纳2
1弗莱堡大学。2牛津大学。3纽伦堡技术大学
摘要 — 我们介绍了 LUMOS,这是一个用于机器人的语言条件多任务模仿学习框架。LUMOS 通过在学习到的世界模型的潜在空间中进行多次长时域的 rollout 来学习技能,并将这些技能零样本地迁移到真实机器人上。通过在学习到的世界模型的潜在空间中进行策略学习,我们的算法减轻了大多数离线模仿学习方法所遭受的策略诱导分布偏移。LUMOS 从无结构的玩耍数据中学习,其中少于 1% 的数据有事后语言注释,但在测试时可以用语言命令进行引导。我们通过在训练中结合潜在规划以及基于图像和语言的事后目标重标记,并通过优化在世界模型的潜在空间中定义的内在奖励来实现连贯的长时域性能,有效地减少了协变量偏移。在 CALVIN 基准测试的实验中,LUMOS 在链式多任务评估中优于先前基于学习的方法。据我们所知,我们是第一个在离线世界模型中为真实世界机器人学习语言条件连续视觉运动控制的人。视频、数据集和代码可在 http://lumos.cs.uni-freiburg.de 查看。
I. 引言 构建能够执行由自然语言指定的长时域任务的系统是机器人学的一个长期目标 [1] _{CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks}。当完整的任务规范可用时,可以使用强化学习(RL)方法通过试错来产生策略。然而,典型的 RL 算法可能需要数百万个 episode 来学习良好的策略,这对于许多机器人任务来说是不切实际的。此外,许多任务难以作为奖励函数来指定,仅依靠 RL 需要大量的工程工作才能产生合理的学到的技能。模仿学习提供了一种替代方案,通过直接从任务演示中学习。像行为克隆 [2] _{ALVINN: An Autonomous Land Vehicle in a Neural Network} 这样的简单方法根据演示数据从状态预测动作,并在部署时应用它们。然而,这些方法忽略了决策的顺序性。由于每个观察都依赖于前一个动作,标准统计机器学习中的独立性假设被打破了。罗斯和巴格内尔 [3] _{Efficient Reductions for Imitation Learning} 表明,具有误差 ϵ 的行为克隆策略的预期遗憾 expected regret为 ![]() ,随着决策时域 T 的增加呈二次方增长。直观地说,由于行为克隆策略不是在其自身的分布下进行训练的,小的预测误差会累积,将策略拉出分布到未见状态,这对于长时域任务来说尤其成问题,因为遗憾呈二次方增长。
,随着决策时域 T 的增加呈二次方增长。直观地说,由于行为克隆策略不是在其自身的分布下进行训练的,小的预测误差会累积,将策略拉出分布到未见状态,这对于长时域任务来说尤其成问题,因为遗憾呈二次方增长。
图 1:LUMOS 在学习到的世界模型的潜在空间中学习通用的语言条件视觉运动策略。通过优化内在奖励以匹配专家表现,它能够在多个时间步骤中从自身的错误中恢复过来,并减少协变量偏移。因此,LUMOS 可以在真实世界场景中处理复杂的、长时域的机器人任务,而无需在线学习或微调。

一种缓解离线策略学习中分布偏移的方法是在环境的模拟中进行策略训练。然而,模拟器可能不可用,或者会受到 sim2real 问题的影响,即在模拟中表现良好的策略由于“现实差距”——现实和模拟动态之间的不匹配——而无法推广到现实世界 [4] _{Learning Agile and Dynamic Motor Skills for Legged Robots}。
世界模型提供了一种有前景的替代手工制作的模拟器的方法 [5] _{World Models},通过预测真实轨迹上的状态或观察条件下的动作来近似动态。通过将观察压缩成能够捕捉时间上下文的潜在表示,当代世界模型 [6] _{Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model},[7] _{Mastering Diverse Domains through World Models} 在数千个时间步骤上实现了高保真度的预测。在世界模型的潜在空间中进行学习使得策略能够进行在线策略和长时域学习,减轻分布偏移,并避免由于模拟器指定不当而导致的现实差距。
为了实现语言条件的、长时域的、多任务策略,我们引入了 LUMOS,这是一个语言条件模仿学习框架。LUMOS 使用世界模型来学习一个多任务策略,该策略可以完全离线地通过自由形式的自然语言指令进行引导,并且能够零样本地迁移到现实世界。它利用 DITTO [8] _{Ditto: Offline Imitation Learning with World Models} 提出的潜在匹配内在奖励,在世界模型的潜在空间中,使其演员 - 评论家代理能够在没有任何在线交互的情况下恢复专家表现。为了进一步增强演员 - 评论家代理的长时域性能,我们基于最近在模仿学习 [9] _{Learning Latent Plans from Play},[10] _{What Matters in Language Conditioned Robotic Imitation Learning over Unstructured Data} 中的进展,并为 LUMOS 增加了一个潜在规划网络。该网络在训练中利用事后 hindsight 的好处,将关于未来轨迹的预测信息蒸馏成一个“潜在计划”。我们证明了 LUMOS 可以仅在世界模型的潜在空间中学习模仿策略,实现零样本迁移到现实世界。在 CALVIN 基准测试和真实世界场景中的广泛测试表明,我们的算法在处理自然语言指定的多目标、长时域任务方面表现出色,优于先前基于学习的方法。
我们的贡献如下:1)改进的长时域模仿学习:LUMOS 通过结合基于世界模型的探索和潜在规划,减少了协变量偏移并增强了长时域性能,使代理能够在模拟的长时域中使用完整的演示轨迹来练习技能。消融研究表明,在潜在空间中的多步练习显著优于单步行为克隆。2)语言目标条件学习:我们的语言条件模仿学习框架在具有挑战性的 CALVIN 基准测试中,测试由语言指令引导的长时域操作任务时,优于先前具有可比方法的方法。3)零样本现实世界迁移:我们成功地实现了在世界模型中完全离线学习的语言条件策略的零样本迁移到现实环境。
II. 相关工作
机器人学中的语言条件模仿学习:
Lynch 等人 [11] _{Language Conditioned Imitation Learning Over Unstructured Data} 引入了 MCIL,它使用无结构的机器人玩耍数据训练行为克隆代理。他们对 1% 的轨迹进行了人工语言注释,使策略能够在测试时通过自然语言命令进行引导。Mees 等人 [1] _{CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks} 引入了开源的 CALVIN 环境,这是一个用于评估语言条件的、长时域多任务机器人操作的基准。它包括一个模拟器,其中有约 24 小时的遥控玩耍数据和 20K 语言任务注释。HULC [10] _{What Matters in Language Conditioned Robotic Imitation Learning over Unstructured Data} 引入了一个层次化的语言条件模仿学习框架,使用对比学习将语言指令与机器人动作对齐,以及其他改进,例如使用多模态变换器编码器(下文讨论)。HULC 在 CALVIN 基准测试中优于 MCIL [12] _{Language-conditioned imitation learning with base skill priors under unstructured data}。HULC++ [13] _{Grounding Language with Visual Affordances over Unstructured Data} 通过将能力和运动规划整合到控制循环中,进一步增强了长时域性能,仅在末端执行器靠近操作目标时才将控制权交给学习到的 HULC 控制器。SPIL [12] _{Language-conditioned imitation learning with base skill priors under unstructured data} 通过对数据集中的所有动作进行标记,并根据它们的幅度将它们概率性地分配给一个基础技能(平移、旋转、抓取),从而改进了现有技术。在本工作中,我们没有纳入关于动作维度与特定技能之间语义关系的先验知识,因为我们旨在保持一个 7 自由度的连续动作空间。扩散生成模型在机器人学中的策略表示方面获得了关注,从高斯噪声中扩散动作 [14] - [16]。它们可以根据语言目标获得多样化的动作 [17] - [19]。最新的多模态扩散变换器(MDT)[20] _{Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals} 使用掩蔽生成性远见和对比潜在对齐来提升长时域任务中的性能。尽管这种方法与我们的工作是正交的,但我们承认扩散模型在世界建模和行为学习中的潜力。
然而,在本文中,我们旨在研究如何在学习到的世界模型的潜在空间中训练策略。使用潜在规划改进行为克隆:Lynch 等人 [9] _{Learning Latent Plans from Play} 引入了 GCBC,它通过基于图像的目标条件增强了标准行为克隆。GCBC 进一步引入了一个规划模块,该模块仅根据当前和目标状态训练一个计划预测器,以预测由规划模块产生的潜在变量,而该规划模块可以访问整个专家轨迹。在测试时,从计划预测器中采样的潜在变量用于条件策略以实现改进的长时域性能。这项工作的局限性在于依赖于目标图像来条件计划预测器。Zhang 等人 [21] _{Language Control Diffusion: Efficiently Scaling through Space, Time, and Tasks} 通过用扩散模型替换 GCBC 中的离散潜在计划嵌入模型,改进了 GCBC 中的潜在规划器。他们通过语言条件的 U-Net 逐步去噪潜在计划,实现了优于 GCBC 的长时域性能。使用世界模型进行学习:世界模型最近作为一种有前景的数据驱动模拟方法出现。Ha 和 Schmidhuber [5] _{World Models} 的开创性工作表明,直接从像素观察中学习世界模型以预测未来的观察,然后在学习到的模型的潜在空间中学习策略是有效的。在此基础上,Dreamer 系列工作 [22] _{Dream to Control: Learning Behaviors by Latent Imagination},[23] _{Mastering Atari with Discrete World Models} 引入了一种基于世界模型的强化学习算法,在 Atari 基准测试中取得了 SOTA 性能,并且最近成为第一个在 Minecraft 中产生钻石的算法,这需要在数千个时间步骤上连贯地行动 [7]。DayDreamer [24] _{Daydreamer: World Models for Physical Robot Learning} 将 Dreamer 算法应用于在真实机器人上在线学习四足行走,证明了在世界模型中训练的策略对迁移到真实环境的鲁棒性。我们的工作主要基于 DITTO [8] _{Ditto: Offline Imitation Learning with World Models},这是一种基于世界模型的模仿学习算法,它在世界模型的潜在空间中惩罚与专家轨迹的策略差异。具体来说,它在潜在空间中定义了一个内在奖励,用于衡量代理 rollout 与专家演示之间的差异,然后使用演员 - 评论家强化学习来优化这个内在奖励。优化这个内在奖励可以诱导对长时域 rollout 中的错误具有鲁棒性的模仿学习,有效地减轻协变量偏移。
III. 问题表述
我们在部分可观测马尔可夫决策过程(POMDP)中研究目标条件模仿学习,该过程具有连续动作和来自未知环境的高维观察。我们使用目标增强的 POMDP ![]() 来模拟环境与目标条件策略之间的互动,其中 S 是状态 - 观察空间,A 是动作空间,R(s, a) 是奖励函数,
来模拟环境与目标条件策略之间的互动,其中 S 是状态 - 观察空间,A 是动作空间,R(s, a) 是奖励函数,![]() 定义状态转移动态,
定义状态转移动态,![]() 是目标空间,γ ∈ (0, 1) 是折扣因子。代理接收视觉观察而不是直接的状态访问,并且旨在最大化预期折扣的外部奖励总和
是目标空间,γ ∈ (0, 1) 是折扣因子。代理接收视觉观察而不是直接的状态访问,并且旨在最大化预期折扣的外部奖励总和 ![]() ,这是它无法直接观察到的。我们使用一个庞大、未标记且无向的固定玩耍数据集
,这是它无法直接观察到的。我们使用一个庞大、未标记且无向的固定玩耍数据集 ![]() 进行离线学习。这个数据集被重新标记为长时域的状态 - 动作流 [25] _{Hindsight Experience Replay}。每个访问过的状态都被视为一个“达到的目标状态”,从而产生一个轨迹数据集
进行离线学习。这个数据集被重新标记为长时域的状态 - 动作流 [25] _{Hindsight Experience Replay}。每个访问过的状态都被视为一个“达到的目标状态”,从而产生一个轨迹数据集 ![]() 。这种转换 transformation 创建了
。这种转换 transformation 创建了 ![]() ,将每个目标状态 sg 与相应的演示轨迹 τ 配对。我们采用 Lynch 等人 [11] _{Language Conditioned Imitation Learning Over Unstructured Data} 的多上下文模仿学习方法,利用语言注释。这种方法表明,结合一些随机窗口与基于语言的事后指令有助于学习一个统一的语言条件视觉运动策略,用于各种机器人任务。自由形式的语言指令
,将每个目标状态 sg 与相应的演示轨迹 τ 配对。我们采用 Lynch 等人 [11] _{Language Conditioned Imitation Learning Over Unstructured Data} 的多上下文模仿学习方法,利用语言注释。这种方法表明,结合一些随机窗口与基于语言的事后指令有助于学习一个统一的语言条件视觉运动策略,用于各种机器人任务。自由形式的语言指令![]() 指导策略,提供灵活且自然的任务描述。
指导策略,提供灵活且自然的任务描述。
IV. LUMOS
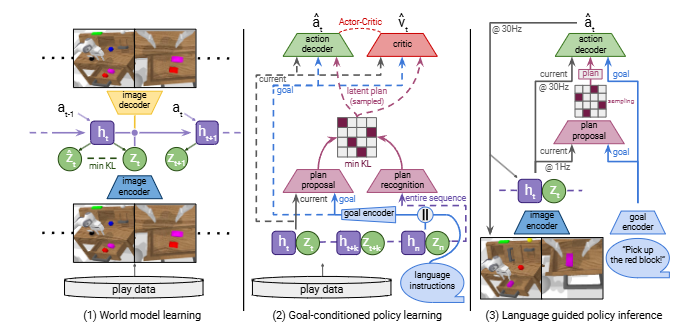
在本节中,我们介绍 LUMOS。训练包括两个阶段:首先,从未标记的玩耍数据集 D 中学习世界模型。接下来,在这个学到的世界模型中训练一个演员 - 评论家代理,以获取一个目标条件策略,通过引导想象的潜在模型状态序列来匹配专家演示的潜在轨迹。在推理过程中,完全在世界模型的潜在空间中训练的语言条件策略![]() 成功地迁移到真实环境中。 图 2 展示了该方法的概述。
成功地迁移到真实环境中。 图 2 展示了该方法的概述。
Lumos在世界模型的潜在空间中学习了语言引导的通用政策。 (1)包含图像编码器的世界模型,用于动态dynamics 的 Recurrent State-Space Mode(RSSM)和图像解码器,将播放数据集经验转换为一个预测模型,该模型可以在潜在状态空间中进行行为学习。 (2)目标条件的政策采样潜在轨迹,并使用语言注释或最终潜在状态作为目标,并有计划识别 plan recognition 和建议网络 proposal networks一起被训练以识别和组织潜在计划空间中的行为。通过与专家的潜在轨迹相匹配,该动作解码器本质上是奖励的。 (3)在推断期间,该政策基于当前观察结果推断出的世界模型的潜在状态,并由用户的语言命令指导
A. 世界模型学习
世界模型将代理的经验捕捉到一个预测模型中,使得无需直接与环境交互即可进行行为学习。通过将高维图像转换为紧凑的状态表示,它们允许在潜在空间中高效、并行地进行长期预测。尽管我们的方法对于世界模型架构的选择是不可知的,但我们将 DITTO 采用的 DreamerV2 架构 [23] _{Mastering Atari with Discrete World Models} 作为 LUMOS 的骨干。它包括一个图像编码器、一个用于学习转换动态的循环状态空间模型(RSSM)以及一个从潜在状态重建观察的解码器。为了学习机器人操作技能,我们使用来自静态和夹持器安装的相机的观察,分别为它们使用单独的 CNN 编码器和转置 CNN 解码器。在传递给 RSSM 之前,这些编码被连接起来,RSSM 生成一个确定性的循环状态序列 ![]() 。每个状态定义了两个随机隐藏状态的分布:随机后验状态 zt,由当前观察 xt 和循环状态 ht 确定,以及随机先验状态 ẑt,训练其近似后验而不使用当前观察。通过预测 ẑt,模型学习环境动态。结合的模型状态,包括确定性和随机成分
。每个状态定义了两个随机隐藏状态的分布:随机后验状态 zt,由当前观察 xt 和循环状态 ht 确定,以及随机先验状态 ẑt,训练其近似后验而不使用当前观察。通过预测 ẑt,模型学习环境动态。结合的模型状态,包括确定性和随机成分![]() ,重建观察。RSSM 包括以下模块:
,重建观察。RSSM 包括以下模块:

先前和后验模型预测分类分布,并使用直通梯度估计值进行了优化
所有模块均使用神经网络实现,参数为 ϕ,并通过最小化负变分下界 [27] _{Auto-Encoding Variational Bayes} 联合优化:
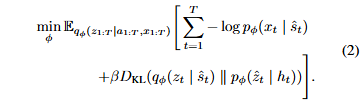
在训练后,世界模型可以在不输入观察的情况下运行,使用先验 ẑ 代替后验 z。这使得模型能够生成无限的想象轨迹,形式为![]() ,其中 H 是想象的时间范围。
,其中 H 是想象的时间范围。
B. 行为学习
LUMOS 使用一个演员 - 评论家代理在世界模型的潜在空间中学习长时域、语言条件的行为。它从数据集 ![]() 中学习一个目标条件策略
中学习一个目标条件策略 ![]() 和一个价值函数
和一个价值函数 ![]() ,其中 st 表示当前潜在状态,
,其中 st 表示当前潜在状态,![]() 表示自由形式的语言指令
表示自由形式的语言指令 或潜在目标状态
。在本节中,我们概述了我们模型的设计选择,解释如何通过内在奖励函数在轨迹上奖励代理以匹配专家潜在状态 - 动作对,并详细说明演员和评论家的优化过程。
观察和动作空间
我们的目标达成策略基于 Mees 等人 [10] _{What Matters in Language Conditioned Robotic Imitation Learning over Unstructured Data} 的 HULC 架构,增强了从无结构数据中进行语言条件模仿学习的能力。与使用高维图像观察的 HULC 不同,我们的方法利用世界模型的潜在空间来获取其紧凑的表示。除了编码来自静态和夹持器相机的 RGB 图像外,LUMOS 还编码从当前到目标状态的潜在轨迹的紧凑状态。动作空间是一个 7 自由度的连续空间,包括相对 XYZ 位置、欧拉角和夹持器动作。
潜在计划编码
从自由形式的模仿数据中学习控制面临着连接相同 ![]() 对的多个有效轨迹的挑战。为了解决这一问题,我们使用序列到序列条件变分自编码器(seq2seq CVAE)[9] _{Learning Latent Plans from Play} 将上下文潜在轨迹编码到潜在“计划”空间中。这个空间由两个随机编码器决定:一个用于在训练中识别计划,另一个用于在推理中提出计划。计划识别编码器识别整个序列中执行的行为,而计划提议编码器从初始和最终状态生成可能的行为(见图 2 的第二列)。最小化这两个编码器之间的 KL 散度,称为 LKL,确保计划提议编码器准确反映观察到的行为。与 HULC 类似,我们使用多模态变换器编码器来开发潜在轨迹的上下文化表示,将其映射到多个潜在分类变量的向量中,并使用直通梯度进行优化。
对的多个有效轨迹的挑战。为了解决这一问题,我们使用序列到序列条件变分自编码器(seq2seq CVAE)[9] _{Learning Latent Plans from Play} 将上下文潜在轨迹编码到潜在“计划”空间中。这个空间由两个随机编码器决定:一个用于在训练中识别计划,另一个用于在推理中提出计划。计划识别编码器识别整个序列中执行的行为,而计划提议编码器从初始和最终状态生成可能的行为(见图 2 的第二列)。最小化这两个编码器之间的 KL 散度,称为 LKL,确保计划提议编码器准确反映观察到的行为。与 HULC 类似,我们使用多模态变换器编码器来开发潜在轨迹的上下文化表示,将其映射到多个潜在分类变量的向量中,并使用直通梯度进行优化。
潜在轨迹与语言的语义对齐
解决符号接地问题 [28] _{The Symbol Grounding Problem} 需要将语言指令与机器人的感知和动作联系起来。将指令与视觉观察对齐对于区分类似物体(如彩色积木)至关重要。与将视觉特征与语言特征对齐的 HULC 不同,我们对齐世界模型的潜在特征与语言特征。这涉及到在最大化潜在轨迹和语言特征之间的余弦相似性的同时,最小化与不相关指令的相似性,使用类似于 CLIP [29] _{Learning Transferable Visual Models from Natural Language Supervision} 的对比损失,并结合批量内负样本进行高效训练。我们将这个目标表示为 ![]() 。
。
奖励
与依赖于监督动作标签进行训练的行为克隆方法不同,LUMOS 利用一个简单的内在奖励函数,该函数在世界模型的潜在空间内定义,以解决协变量偏移问题。为了使代理的行为与专家对齐,我们采用了 DeMoss 等人 [8] _{Ditto: Offline Imitation Learning with World Models} 提出的奖励函数,该函数鼓励代理在潜在空间中匹配专家的状态 - 动作对。这个内在奖励定义为潜在状态表示上的修改内积,鼓励相似性而不要求完全匹配。这使得代理能够在世界模型的潜在空间中探索不同的轨迹,同时在整个训练时域内将其行为与演示者对齐。每个步骤 t 的奖励由以下公式给出:
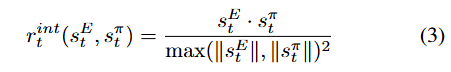
动作和价值模型
我们的随机演员,参数为 θ,根据当前潜在状态 st 和潜在目标 g 采样动作,旨在最大化预期奖励(公式 3)。确定性的评论家,参数为 ψ,预测预期的折扣未来奖励,为相同的潜在状态和目标提供价值估计。这些模型定义如下:
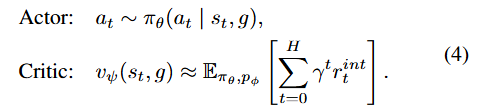
我们使用全连接神经网络作为演员和评论家。动作模型输出一个 tanh - 变换的高斯分布 [30] _{Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor},便于进行反向传播的重参数化采样。在行为学习过程中,世界模型保持固定,确保代理梯度不会改变其表示。
学习目标
评论家的训练目标是将计算出的价值估计回归到 λ - 目标 [31] _{Reinforcement Learning: An Introduction},记作 ![]() (具体定义可参考 [23] _{Mastering Atari with Discrete World Models}):
(具体定义可参考 [23] _{Mastering Atari with Discrete World Models}):
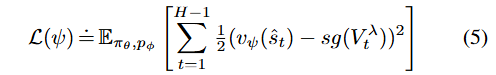
其中,sg(⋅) 是停止梯度操作符。此外,我们使用目标网络,其权重更新缓慢,以提供稳定的值引导目标 [32] _{Human-level control through deep reinforcement learning}。 演员的目标函数通过反向传播通过学到的动态来最大化价值估计,同时最小化计划编码器之间的 KL 散度以及对齐潜在轨迹与语言的对比损失。对于没有语言注释的采样窗口,省略对比损失: