Logit-Laplace 分布:解决图像生成中像素值范围匹配问题的创新分布
Logit-Laplace 分布:解决图像生成中像素值范围匹配问题的创新分布
在深度学习领域,尤其是在图像生成任务中,重建损失的选择对模型性能至关重要。传统的 Laplace 分布和 Gaussian 分布因其数学上的简洁性被广泛使用,但它们都存在一个显著问题:支持域与图像像素值的实际范围不匹配。针对这一问题,《Zero-Shot Text-to-Image Generation》论文提出了一种新颖的 logit-Laplace 分布,其概率密度函数为:
f ( x ∣ μ , b ) = 1 2 b x ( 1 − x ) exp ( − ∣ logit ( x ) − μ ∣ b ) f(x \mid \mu, b) = \frac{1}{2 b x (1 - x)} \exp \left( -\frac{|\operatorname{logit}(x) - \mu|}{b} \right) f(x∣μ,b)=2bx(1−x)1exp(−b∣logit(x)−μ∣)
这种分布定义在 (0, 1) 区间,非常适合建模归一化后的像素值。本文将详细介绍 logit-Laplace 分布的定义、特性,以及它如何解决传统分布的支持域问题,面向对概率分布和图像生成感兴趣的深度学习研究者。
论文链接:https://arxiv.org/pdf/2102.12092
传统分布的局限性
在图像生成任务中,像素值通常被归一化为 [0, 1] 或 [0, 255] 的范围。以 [0, 1] 为例,这是变分自编码器(VAE)等模型常用的输入范围。然而,传统重建损失对应的分布却与此不完全匹配:
-
Gaussian 分布:
- 概率密度函数:( f ( x ∣ μ , σ ) = 1 2 π σ 2 exp ( − ( x − μ ) 2 2 σ 2 ) f(x \mid \mu, \sigma) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp \left( -\frac{(x - \mu)^2}{2\sigma^2} \right) f(x∣μ,σ)=2πσ21exp(−2σ2(x−μ)2) )
- 支持域:(( − ∞ , + ∞ ) -\infty, +\infty) −∞,+∞))
- 问题:Gaussian 分布假定数据可以取任意实数值,但像素值被限制在 [0, 1] 内。这意味着模型会为超出范围的值(如负值或大于 1)分配非零概率,导致似然估计不准确,且可能生成超出范围的无效像素值。
-
Laplace 分布:
- 概率密度函数:( f ( x ∣ μ , b ) = 1 2 b exp ( − ∣ x − μ ∣ b ) f(x \mid \mu, b) = \frac{1}{2b} \exp \left( -\frac{|x - \mu|}{b} \right) f(x∣μ,b)=2b1exp(−b∣x−μ∣) )
- 支持域:(( − ∞ , + ∞ ) -\infty, +\infty) −∞,+∞))
- 问题:与 Gaussian 类似,Laplace 分布的支持域也是整个实数轴。虽然它对异常值更鲁棒,但在像素值建模中仍会浪费概率质量在无效区域,且无法天然约束输出到 [0, 1]。
这种支持域与像素值范围的不匹配会导致以下问题:
- 似然浪费:模型为不可能的像素值分配概率,降低了有效范围内的似然估计精度。
- 生成质量下降:解码器可能生成超出 [0, 1] 的值,需要额外裁剪(如
torch.clamp),引入不必要的后处理步骤。 - 数值稳定性:在边界(如 0 或 1)附近,传统分布的密度可能趋于零,导致数值计算问题。
Logit-Laplace 分布的定义与特性
Logit-Laplace 分布通过对 Laplace 分布施加 logit 变换,巧妙地将其支持域限制在 (0, 1) 区间。其概率密度函数为:
f ( x ∣ μ , b ) = 1 2 b x ( 1 − x ) exp ( − ∣ logit ( x ) − μ ∣ b ) f(x \mid \mu, b) = \frac{1}{2 b x (1 - x)} \exp \left( -\frac{|\operatorname{logit}(x) - \mu|}{b} \right) f(x∣μ,b)=2bx(1−x)1exp(−b∣logit(x)−μ∣)
其中:
- ( x ∈ ( 0 , 1 ) x \in (0, 1) x∈(0,1)):表示归一化后的像素值。
- ( μ \mu μ):分布的中心参数,通常由解码器预测,对应 logit 空间中的位置参数。
- ( b b b):尺度参数,控制分布的分散程度。
- ( logit ( x ) = ln ( x 1 − x ) \operatorname{logit}(x) = \ln \left( \frac{x}{1 - x} \right) logit(x)=ln(1−xx)):将 (0, 1) 映射到 ( ( − ∞ , + ∞ ) (-\infty, +\infty) (−∞,+∞)) 的变换。
推导过程
Logit-Laplace 分布可以通过变量变换从标准 Laplace 分布导出:
- 假设 ( Y ∼ Laplace ( μ , b ) Y \sim \text{Laplace}(\mu, b) Y∼Laplace(μ,b)),其密度为 ( f Y ( y ) = 1 2 b exp ( − ∣ y − μ ∣ b ) f_Y(y) = \frac{1}{2b} \exp \left( -\frac{|y - \mu|}{b} \right) fY(y)=2b1exp(−b∣y−μ∣) )。
- 定义 ( X = sigmoid ( Y ) = 1 1 + e − Y X = \text{sigmoid}(Y) = \frac{1}{1 + e^{-Y}} X=sigmoid(Y)=1+e−Y1),则 ( Y = logit ( X ) Y = \operatorname{logit}(X) Y=logit(X))。
- 使用变量变换公式,计算 (
X
X
X) 的密度:
- 雅可比行列式:( d d x logit ( x ) = 1 x ( 1 − x ) \frac{d}{dx} \operatorname{logit}(x) = \frac{1}{x(1 - x)} dxdlogit(x)=x(1−x)1)。
- ( f X ( x ) = f Y ( logit ( x ) ) ⋅ ∣ d d x logit ( x ) ∣ = 1 2 b exp ( − ∣ logit ( x ) − μ ∣ b ) ⋅ 1 x ( 1 − x ) f_X(x) = f_Y(\operatorname{logit}(x)) \cdot \left| \frac{d}{dx} \operatorname{logit}(x) \right| = \frac{1}{2b} \exp \left( -\frac{|\operatorname{logit}(x) - \mu|}{b} \right) \cdot \frac{1}{x(1 - x)} fX(x)=fY(logit(x))⋅ dxdlogit(x) =2b1exp(−b∣logit(x)−μ∣)⋅x(1−x)1)。
最终得到上述密度函数。
特性
- 支持域:(0, 1),完美匹配归一化像素值的范围。
- 形状:类似于 Laplace 分布的双尾特性,但在 logit 空间中对称,映射回 (0, 1) 后呈非对称形状,边界处密度较高。
- 参数意义:
- (\mu) 控制分布的峰值位置(通过 sigmoid 变换映射到 (0, 1))。
- (b) 控制分布的宽度,(b) 越小,分布越集中。
如何解决支持域不匹配问题
Logit-Laplace 分布通过以下方式解决了传统分布的局限性:
-
限制支持域到 (0, 1):
- 通过 logit 变换,分布天然约束在 (0, 1) 内,避免了为无效值(如负值或大于 1)分配概率。
- 相比之下,Gaussian 和 Laplace 分布需要额外的截断或裁剪,而 logit-Laplace 无需后处理即可生成有效像素值。
-
匹配像素值范围:
- 图像生成中,像素值通常归一化为 [0, 1](或通过线性变换映射到其他范围)。Logit-Laplace 的支持域与此一致,确保似然计算只关注有效范围。
- 在论文中,像素值被映射到 (( ϵ \epsilon ϵ), ( 1 − ϵ 1 - \epsilon 1−ϵ)(如 ( ϵ = 0.1 \epsilon = 0.1 ϵ=0.1)),以避免 ( x = 0 x = 0 x=0) 或 ( 1 1 1) 时的数值不稳定性,logit-Laplace 配合这种映射依然适用。
-
保留 Laplace 的鲁棒性:
- 与 Gaussian 相比,Laplace 分布对异常值更鲁棒(指数衰减而非平方衰减)。Logit-Laplace 继承了这一特性,同时通过 logit 变换适配像素值范围。
- 这使得它在重建损失中能更好地处理图像中的噪声或异常像素。
-
数值稳定性:
- 传统分布在边界(如 ( x = 0 x = 0 x=0) 或 ( 1 1 1))附近密度趋于零,可能导致梯度消失或数值溢出。Logit-Laplace 的 ( 1 x ( 1 − x ) \frac{1}{x(1 - x)} x(1−x)1) 项在边界附近增加密度,配合 ( ϵ \epsilon ϵ) 偏移,避免了这些问题。
在图像生成中的应用
在论文中,logit-Laplace 分布被用作 dVAE 的重建损失,具体实现如下:
- 输入处理:像素值从 [0, 255] 线性映射到 (( ϵ \epsilon ϵ), ( 1 − ϵ 1 - \epsilon 1−ϵ)),公式为 ( φ ( x ) = 1 − 2 ϵ 255 x + ϵ \varphi(x) = \frac{1 - 2\epsilon}{255} x + \epsilon φ(x)=2551−2ϵx+ϵ)。这避免了 ( x = 0 x = 0 x=0) 或 ( 1 1 1) 时 ( 1 x ( 1 − x ) \frac{1}{x(1 - x)} x(1−x)1) 的数值问题。
- 解码器输出:dVAE 解码器预测 ( μ \mu μ) 和 ( ln b \ln b lnb)(每个像素两个参数),用于计算 logit-Laplace 的似然。
- 损失计算:对数似然为:
ln f ( x ∣ μ , b ) = − ln ( 2 b ) − ln x − ln ( 1 − x ) − ∣ logit ( x ) − μ ∣ b \ln f(x \mid \mu, b) = -\ln (2b) - \ln x - \ln (1 - x) - \frac{|\operatorname{logit}(x) - \mu|}{b} lnf(x∣μ,b)=−ln(2b)−lnx−ln(1−x)−b∣logit(x)−μ∣
总重建损失是对所有像素的对数似然取平均。 - 图像重建:生成时忽略 ( b b b),直接用 ( x ^ = φ − 1 ( sigmoid ( μ ) ) \hat{x} = \varphi^{-1}(\text{sigmoid}(\mu)) x^=φ−1(sigmoid(μ))) 重建图像。
这种设计确保了重建损失与像素值范围一致,提升了 dVAE 的重建质量。
总结
Logit-Laplace 分布通过将 Laplace 分布的鲁棒性与 logit 变换的范围约束相结合,解决了传统 Gaussian 和 Laplace 分布支持域与像素值范围不匹配的问题。其支持域 (0, 1) 天然适配归一化像素值,避免了似然浪费和无效生成,同时保留了对异常值的鲁棒性。在图像生成任务中,这一创新分布为 VAE 等模型提供了更精确的重建目标,值得研究者在类似场景中进一步探索和应用。
图像
以下是使用 Python(依赖 NumPy 和 Matplotlib)实现的代码,用于绘制标准 Laplace 分布和 Logit-Laplace 分布的概率密度函数图像。通过对比两者的形状和支持域,可以直观理解它们之间的差异。
import numpy as np
import matplotlib.pyplot as plt
# 定义 Laplace 分布的概率密度函数
def laplace_pdf(x, mu, b):
return 1 / (2 * b) * np.exp(-np.abs(x - mu) / b)
# 定义 Logit-Laplace 分布的概率密度函数
def logit_laplace_pdf(x, mu, b):
# 避免 x = 0 或 1 时的数值问题,限制 x 在 (1e-6, 1-1e-6)
x = np.clip(x, 1e-6, 1 - 1e-6)
logit_x = np.log(x / (1 - x)) # logit(x)
return 1 / (2 * b * x * (1 - x)) * np.exp(-np.abs(logit_x - mu) / b)
# 参数设置
mu = 0.0 # 中心参数
b = 1.0 # 尺度参数
# 生成 x 轴数据
x_laplace = np.linspace(-5, 5, 1000) # Laplace 的支持域 (-∞, ∞)
x_logit_laplace = np.linspace(0, 1, 1000) # Logit-Laplace 的支持域 (0, 1)
# 计算概率密度
laplace_density = laplace_pdf(x_laplace, mu, b)
logit_laplace_density = logit_laplace_pdf(x_logit_laplace, mu, b)
# 绘制图像
plt.figure(figsize=(12, 5))
# 绘制 Laplace 分布
plt.subplot(1, 2, 1)
plt.plot(x_laplace, laplace_density, label=f'Laplace (μ={mu}, b={b})', color='blue')
plt.title('Laplace Distribution')
plt.xlabel('x')
plt.ylabel('Density')
plt.grid(True)
plt.legend()
# 绘制 Logit-Laplace 分布
plt.subplot(1, 2, 2)
plt.plot(x_logit_laplace, logit_laplace_density, label=f'Logit-Laplace (μ={mu}, b={b})', color='orange')
plt.title('Logit-Laplace Distribution')
plt.xlabel('x')
plt.ylabel('Density')
plt.grid(True)
plt.legend()
# 调整布局并显示
plt.tight_layout()
plt.show()
代码说明
-
依赖库:
numpy:用于数值计算。matplotlib:用于绘图。
-
函数定义:
laplace_pdf(x, mu, b):实现标准 Laplace 分布的概率密度函数 ( f ( x ∣ μ , b ) = 1 2 b exp ( − ∣ x − μ ∣ b ) f(x \mid \mu, b) = \frac{1}{2b} \exp \left( -\frac{|x - \mu|}{b} \right) f(x∣μ,b)=2b1exp(−b∣x−μ∣) )。logit_laplace_pdf(x, mu, b):实现 Logit-Laplace 分布的概率密度函数 ( f ( x ∣ μ , b ) = 1 2 b x ( 1 − x ) exp ( − ∣ logit ( x ) − μ ∣ b ) f(x \mid \mu, b) = \frac{1}{2 b x (1 - x)} \exp \left( -\frac{|\operatorname{logit}(x) - \mu|}{b} \right) f(x∣μ,b)=2bx(1−x)1exp(−b∣logit(x)−μ∣) )。为避免 ( x = 0 x = 0 x=0) 或 ( 1 1 1) 时 ( 1 x ( 1 − x ) \frac{1}{x(1 - x)} x(1−x)1) 的数值溢出,使用np.clip将 ( x x x) 限制在 (1e-6, 1-1e-6)。
-
参数设置:
- ( μ = 0.0 \mu = 0.0 μ=0.0):分布的中心。
- ( b = 1.0 b = 1.0 b=1.0):尺度参数,控制分布的宽度。
-
数据生成:
- Laplace 分布:( x x x) 从 -5 到 5,覆盖其支持域 ( ( − ∞ , + ∞ ) (-\infty, +\infty) (−∞,+∞)) 的一部分。
- Logit-Laplace 分布:( x x x) 从 0 到 1,符合其支持域 ( ( 0 , 1 ) (0, 1) (0,1))。
-
绘图:
- 使用
plt.subplot创建两个子图,分别绘制 Laplace 和 Logit-Laplace 分布。 - 添加标题、标签、网格和图例,便于观察。
- 使用
运行结果
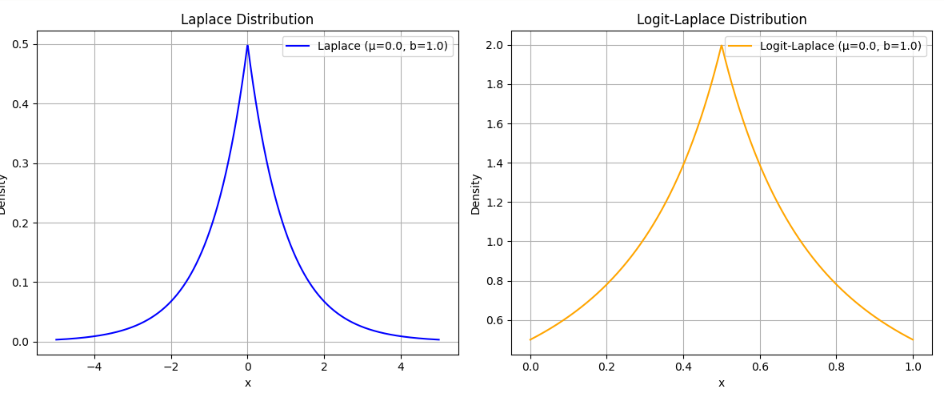
运行代码后,你将看到两个图:
- 左图(Laplace 分布):
- 形状是对称的双指数衰减曲线,中心在 ( μ = 0 \mu = 0 μ=0),支持域为整个实数轴。
- 密度在 ( x = 0 x = 0 x=0) 处达到峰值,向两侧逐渐衰减。
- 右图(Logit-Laplace 分布):
- 形状是非对称的,支持域严格限制在 (0, 1)。
- 由于 ( 1 x ( 1 − x ) \frac{1}{x(1 - x)} x(1−x)1) 的影响,密度在靠近 0 和 1 的边界处显著增加,形成“U”形曲线,中心由 ( μ \mu μ)(通过 logit 变换)控制。
结果分析
- 支持域差异:
- Laplace 分布覆盖 ( ( − ∞ , + ∞ ) (-\infty, +\infty) (−∞,+∞)),而 Logit-Laplace 限制在 (0, 1),直观展示了后者如何适配像素值范围 [0, 1]。
- 形状差异:
- Laplace 是简单的指数衰减,而 Logit-Laplace 因 logit 变换和归一化因子 ( 1 x ( 1 − x ) \frac{1}{x(1 - x)} x(1−x)1) 在边界处密度更高,反映了其对边界值的建模能力。
- 应用意义:
- 在图像生成中,Logit-Laplace 的支持域与归一化像素值一致,避免了 Laplace 分布为无效值(如负值)分配概率的问题。
使用方法
- 安装依赖:
pip install numpy matplotlib - 保存代码为
plot_laplace_vs_logit_laplace.py。 - 运行:
python plot_laplace_vs_logit_laplace.py。 - 可调整 (
μ
\mu
μ) 和 (
b
b
b) 参数,观察分布形状的变化。例如:
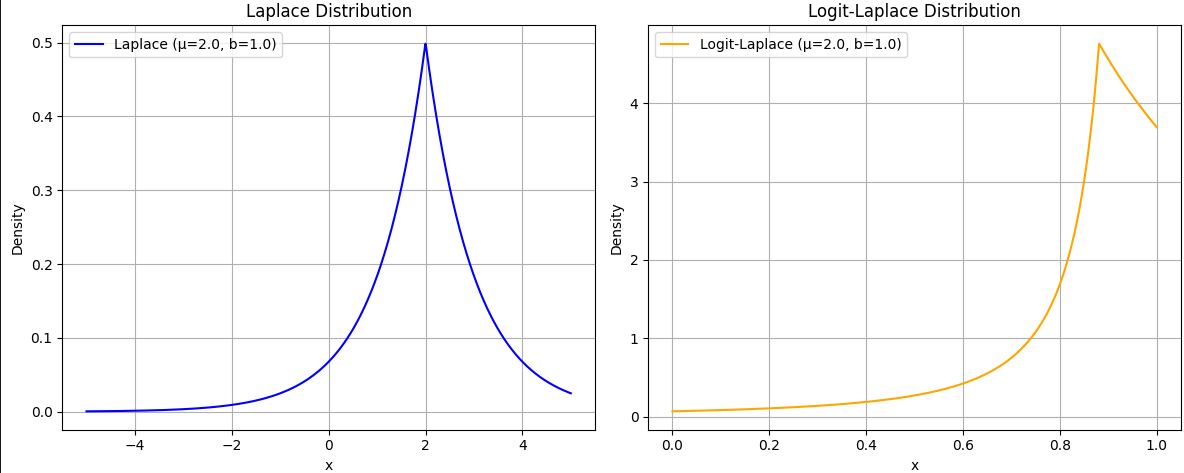
- 将 ( μ \mu μ) 改为 2.0,Logit-Laplace 的峰值会右移。
- 减小 ( b b b)(如 0.5),分布会更集中。
希望这段代码和图像能帮助你更直观地理解 Logit-Laplace 分布的特性及其在图像生成中的优势!
后记
2025年3月26日15点31分于上海,在grok 3大模型辅助下完成。