OPTICS聚类算法原理详解
OPTICS 是一种基于密度的聚类算法,是 DBSCAN 的扩展,能够处理不同密度的簇。
算法需要的参数:邻域半径ε,最小点数minPts。若需要提取簇,则需要参数ε',其取值≤ε。
概念定义:
核心距离:对于点x和参数minPts,核心距离dcore(x)是x到其第minPts个最近邻的距离。若x的邻居数|Nε(x)|<minPts,则dcore(x)=∞;若|Nε(x)|≥minPts,dcore(x)值取点x的第minPts个近邻的距离值。核心距离表示点x是否为核心点,核心点能生成簇。
可达距离:对于点x和其邻近点o,可达距离为:
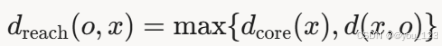
其中d(x,o)是点x和点o的欧式距离。可达距离表示从核心点x到点o的密度连接成本。
算法的执行原理流程如下:
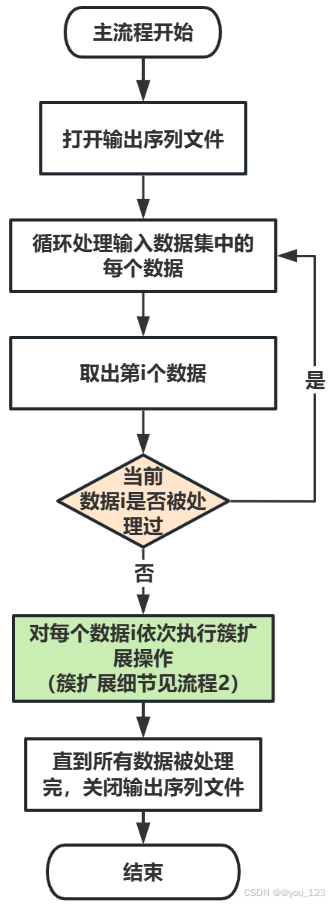
上述主流程中的簇扩展,其详细实现如下图:
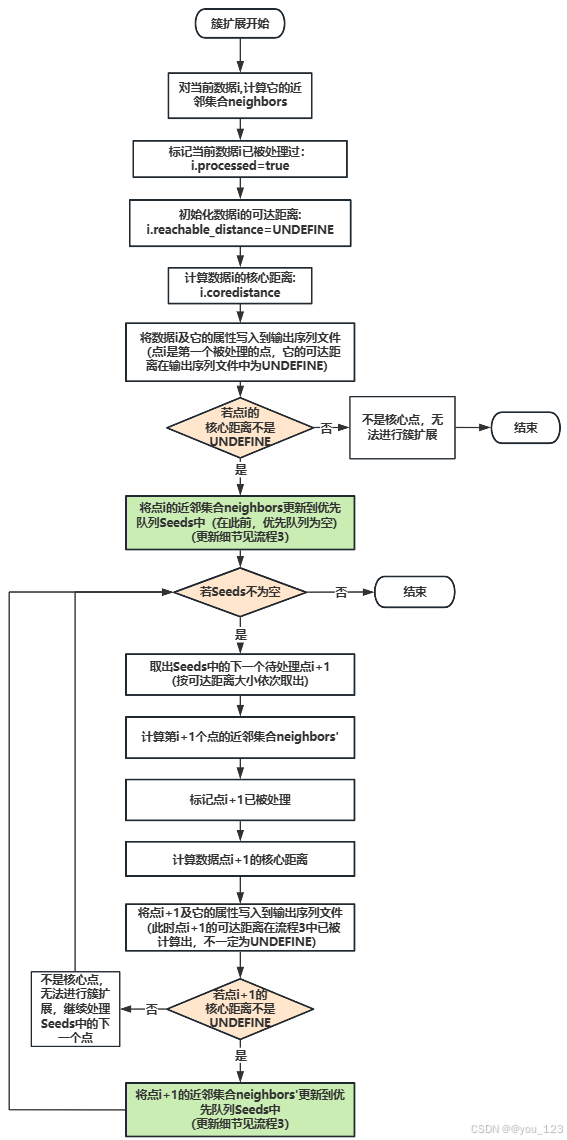
优先队列Seeds的更新步骤如下:
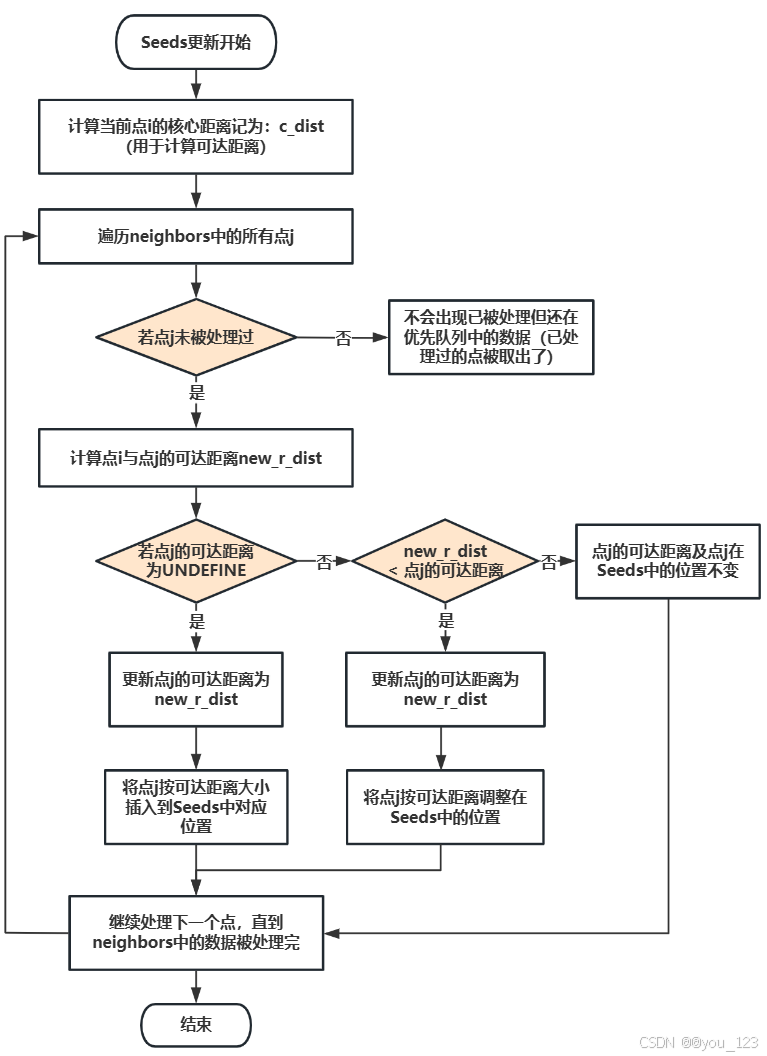
根据上述三个流程图,可以进行聚类算法的实现。
若需要进行簇提取,则执行下述流程:
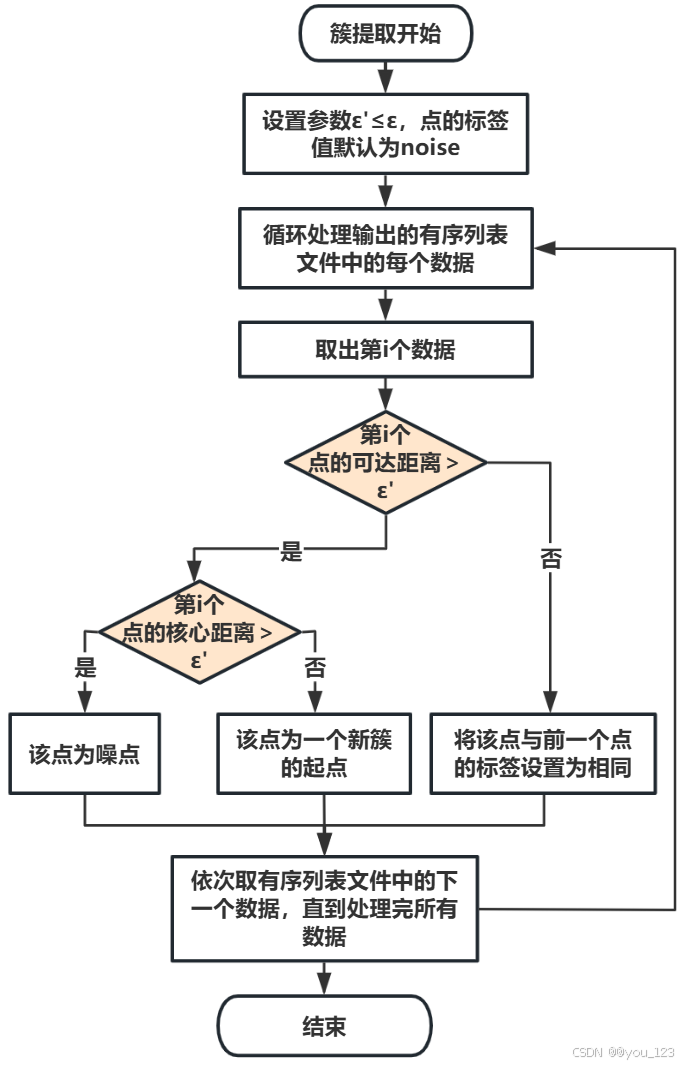
下面为了更详细的描述此算法,将举一个例子:
OPTICS聚类示例:
(1)输入:
假设有以下10个随机二维点:
X = [ (1, 1), (1, 2), (2, 1), (2, 2), (5, 5), (5, 6), (6, 5), (6, 6), (10, 10), (3, 8)]
设置参数 ε = 3,MinPts = 2。
(2)初始化:
已处理点集合:空集。
有序输出序列ordered_list:空列表。
有序输出序列d_reach_list:空列表。
有序输出序列d_core_list:空列表。
未处理点集合:包含所有点 X。
核心距离和可达距离:初始为未定义(∞)。
(3)随机选择一个未处理点:
从未处理点中随机选择 (1, 1) 开始。将 (1, 1) 标记为已处理,加入输出序列,ordered_list = [(1,1)],可达距离d_reach_list=[∞]。
计算核心距离:计算 (1, 1) 到所有点的欧几里得距离:
(1, 1) 到 (1, 2): 1,(1, 1) 到 (2, 1): 1,(1, 1) 到 (2, 2): ≈ 1.41,(1, 1) 到 (5, 5): ≈ 5.66(超出 ε),其他点距离更大。
则在 ε = 3 内,邻居有 (1, 2), (2, 1), (2, 2),共 3 个。邻居数≥ MinPts ,则点(1, 1) 是核心点。计算核心距离=到第2个最近邻的距离 = 1。核心距离d_core_list=[1]
计算可达距离并更新种子集合:对 (1, 1) 的邻居 (1, 2), (2, 1), (2, 2) 计算可达距离:
可达距离 = max(核心距离, 到 (1, 1) 的距离)。
(1, 2): max(1, 1) = 1
(2, 1): max(1, 1) = 1
(2, 2): max(1, 1.41) = 1.41
将这些点加入种子集合(Seeds),并按可达距离排序:
Seeds:[(1, 2, 1), (2, 1, 1), (2, 2, 1.41)]。
处理种子集合:
取出可达距离最小的点 (1, 2)(可达距离 = 1)。
将 (1, 2) 标记为已处理,加入输出序列:ordered_list =[(1, 1), (1, 2)],可达距离d_reach_list=[∞,1]。
检查 (1, 2) 是否为核心点:
它的邻居有:(1, 1), (2, 1), (2, 2) 。
核心距离 = 到第2个最近邻的距离 = 1,核心距离d_core_list=[1,1]。
更新邻居的可达距离:
(1,1)已被处理过,不用再计算可达距离。
(2, 1): max(1, 1.41) = 1.41(之前是1,更新为 1.41)。
(2, 2): max(1, 1) = 1(之前是 1.41,更新为 1)。
更新种子集合:Seeds=[(2, 2, 1), (2, 1, 1.41)]。
继续处理:
取出可达距离最小的点 (2, 2)(可达距离 = 1)。
将 (2, 2) 标记为已处理,加入输出序列:ordered_list =[(1, 1), (1, 2), (2, 2)],可达距离d_reach_list=[∞,1,1]。
检查 (2, 2) 是否为核心点:
它的邻居有:(1, 1), (1, 2) , (2, 1)。
核心距离 = 1,核心距离d_core_list=[1,1,1]。
更新邻居的可达距离:max(1, 1) = 1(之前是1.41,更新为 1)。
更新种子集合:Seeds=[(2, 1, 1)]。
处理种子集合中的点[(2, 1)]:
将 (2, 1) 标记为已处理,加入输出序列:ordered_list =[(1, 1), (1, 2), (2, 2), (2, 1)],可达距离d_reach_list=[∞,1,1,1]。
检查 (2, 1) 是否为核心点:
邻居点(1, 1), (1, 2), (2, 2)
核心距离=1,核心距离d_core_list=[1,1,1,1]。
邻居已被处理,且无新点加入种子集合,此时种子集合Seeds已为空。
(4)选择新的未处理点:
未处理点:(5, 5), (5, 6), (6, 5), (6, 6), (10, 10), (3, 8)。
随机选 (5, 5),加入输出序列:ordered_list =[(1, 1), (1, 2), (2, 2), (2, 1), (5, 5)],可达距离d_reach_list=[∞,1,1,1,∞]。
计算 (5, 5) 到所有点的欧几里得距离:
(5, 5)到(5, 6):1, (5, 5)到(6, 5) :1,(5, 5)到 (6, 6): 1.41,(5,5)为核心点,核心距离 = 1,d_core_list = [1, 1, 1, 1, 1]。
更新种子集合:Seeds=[(5, 6, 1), (6, 5, 1), (6, 6, 1.41)]。
后续依次处理,按照第一个种子集合的方式。
…
(5)最终得到输出序列:
1、ordered_list =[(1, 1), (1, 2), (2, 2), (2, 1), (5, 5), (5, 6), (6, 5), (6, 6), (10, 10), (3, 8)]
2、可达距离d_reach_list=[∞, 1, 1, 1,∞, 1, 1, 1,∞, ∞]
3、核心距离d_core_list = [1, 1, 1, 1, 1, 1, 1, 1, ∞, ∞]
簇提取后可以得到两个簇[(1, 1), (1, 2), (2, 2), (2, 1)],[(5, 5), (5, 6), (6, 5), (6, 6)]以及两个离群点 (10, 10), (3, 8)
参考wiki百科中对OPTICS算法的描述以及原论文。