LLM - 白话Reranker模型
文章目录
- Pre
- RAG
- Embedding 模型
- Reranker 模型
- Reranker:知识库的"智能推荐官"
- 排序的关键维度
- 语义相关性
- 时效性权重
- 多样性控制
- 为什么这样调整?
- 排序面临的挑战
- Reranker 面临的挑战与解决方案
- 长尾问题
- 语义鸿沟
- 多语言混合
- 计算效率
- 典型排序算法演进
- 传统方法:BM25
- 深度语义模型:Cross-Encoder
- 最新进展:Col-BERT
- 主流模型选型
- 完整排序流程 :企业级知识库问答
- 用户问题
- 初步检索(Retriever):
- Reranker工作流:
- 排序后Top3:
- 小结

Pre
LLM - 重排序(Rerank)
LLM - 深入解析Embedding模型工作原理讲了Embedding嵌入模型,它负责把我们本地的文档数据向量化后存储到我们本的向量数据库中。 接下来我们继续看下Reranker重排序模型 。
在之前还是回顾一下Rag系统的知识。
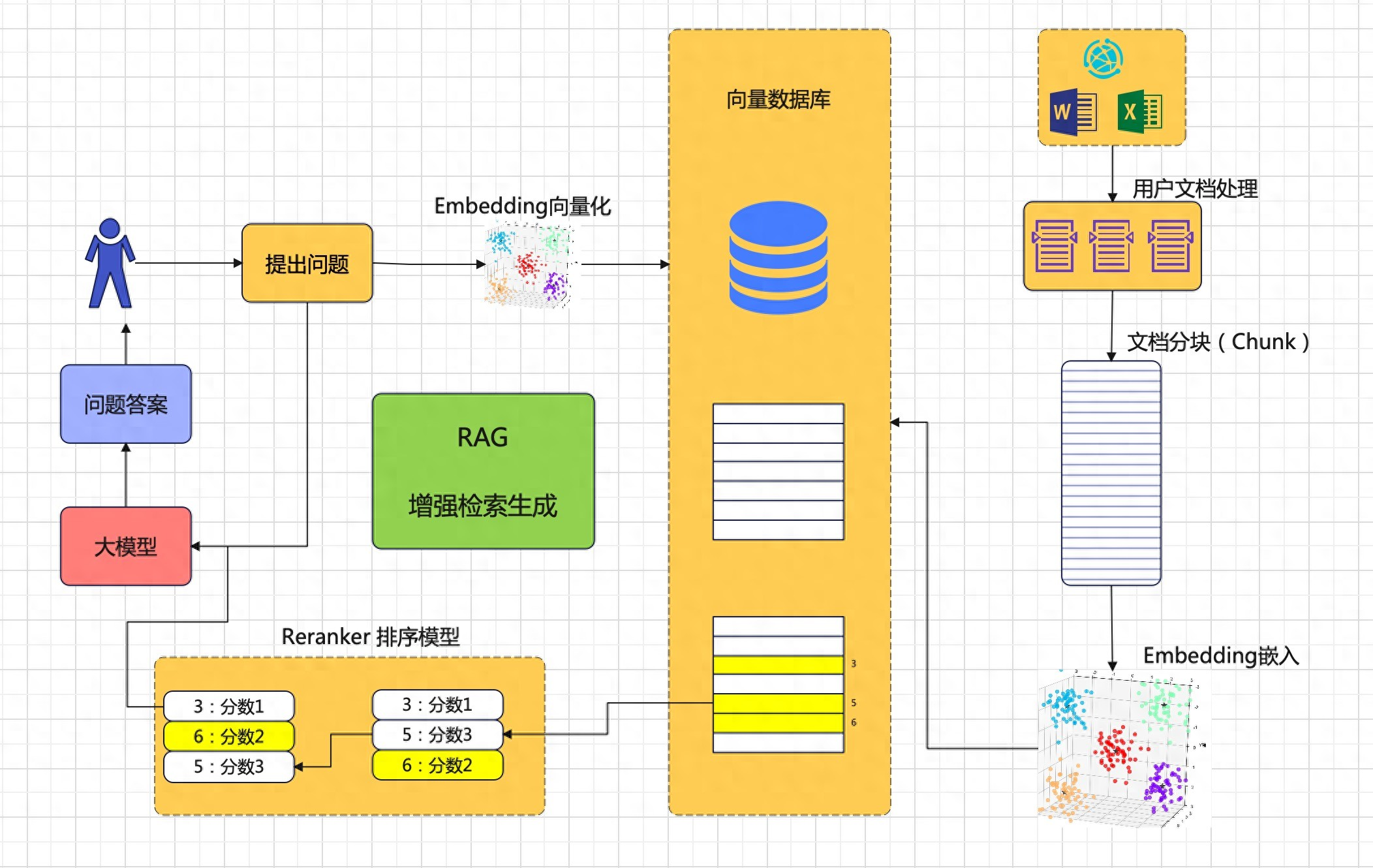
RAG
检索增强生成(Retrieval-Augmented Generation, RAG)是一种结合大型语言模型(LLM)与外部知识库的技术。
目的是为了解决LLM的“幻觉”问题、知识更新滞后及私域数据利用难题。
其核心流程分为三阶段:
检索→重排序→生成,其中 Embedding 嵌入模型与 Reranker 重排序模型是两大关键技术。
Reranker模型就像RAG知识库的“质检员”,是知识库的重要组成部分。
Embedding 模型
Embedding 模型将文本映射为向量,用于衡量语义相似性。
其核心价值在于语义理解:捕捉文本深层语义关系,支持跨语言、跨粒度检索.
MTEB排行榜上AI Embedding模型大盘点
| 模型 | 特点 | 适用场景 |
|---|---|---|
| BGE-M3 | 支持100+语言、多粒度输入(最长8k tokens) | 多语言、长文档、混合检索 |
| Jina | 实现长文本处理 | 双语场景、代码检索 |
| M3E | 中英双语优化,支持指令化Embedding生成 | 中文为主、轻量化需求 |
Reranker 模型
Reranker是知识库的"智能质检员"。
Reranker:知识库的"智能推荐官"
想象你在电商平台搜索"适合夏季的轻薄防晒衣"
-
第一阶段:粗筛(类似Embedding检索)
- 系统返回200件商品:
- 50件防晒衣
- 30件普通T恤
- 20件防晒霜
- 100件其他夏季服饰
- 系统返回200件商品:
-
第二阶段:Reranker智能排序
这位"推荐官"会综合评估:- 核心需求匹配(防晒指数UPF50+>普通外套)
- 用户偏好(你常买的品牌优先)
- 时效性(2024新款>5年前旧款)
- 口碑数据(销量1万+>100+)
- 多样性(展示1件长款/1件短款/1件联名款)
-
最终呈现:
Top3结果:- 2024某大牌UPF50+冰丝防晒衣(新品榜TOP1)
- 某网红爆款可折叠防晒衣(月销10万+)
- 某户外品牌防泼水防晒衣(你买过同品牌)
排序的关键维度
语义相关性
用户问题:“新能源汽车的充电桩如何安装?”
- ✅ 候选文档1:《2023年家用充电桩安装全流程指南》(相关度高:直接解答问题)
- ❌ 候选文档2:《新能源汽车电池保养技巧》(相关度低:主题偏移)
时效性权重
- 📅 文档A:2024年《国家电网充电设施技术规范》(权重**+30%**)
- 📅 文档B:2018年《老旧小区电力改造案例》(权重**-40%**)
多样性控制
避免:返回3篇均讨论"充电桩电压标准"
优化:
- 《家用充电桩安装步骤》(核心答案)
- 《不同品牌充电桩兼容性对比》(补充视角)
- 《政府补贴政策最新解读》(扩展信息)
为什么这样调整?
- 语义相关性:
- 新例子更贴近技术类场景(新能源),避免医疗领域的重复使用。
- 时效性:
- 用"政策/技术规范"替代"医疗指南",突出行业标准快速迭代的特性。
- 多样性:
- 从"安装步骤"→"兼容性"→"政策",覆盖用户可能关注的操作、设备、成本三个维度。
排序面临的挑战
Reranker 面临的挑战与解决方案
长尾问题
- 用户提问:“如何训练导盲犬AI机器人?”
- 检索结果:
- 前10篇:通用机器人训练方法(未命中)
- 仅1篇:《基于多模态感知的导盲犬机器人训练指南》(命中但排名靠后)
解决策略:
- 数据增强:合成"导盲犬+机器人"的伪数据微调模型
- 混合检索:结合关键词(“导盲犬”+“AI”)与语义检索
- 主动学习:标注低置信度结果,迭代优化模型
语义鸿沟
- 用户问:“手机发热严重怎么降温?”
- 文档标题:
- 《移动设备SoC功耗管理与散热优化方案》(语义相关)
- 《智能手机电池保养技巧》(字面相关但非核心)
解决策略:
- 查询扩展:用LLM生成同义表述(如"发热"→"散热"、“降温"→"温度控制”)
- 上下文增强:提取文档中"发热"相关段落提升权重
- 用户反馈:记录用户最终点击的文档,反向优化模型
多语言混合
- 中文提问:“量子纠缠的实际应用有哪些?”
- 知识库内容:
- 中文文档:《量子通信技术白皮书》(匹配度一般)
- 英文论文:《Quantum Entanglement in Commercial Systems》(Nature 2023, 高相关)
解决策略:
- 实时翻译对齐:将英文论文摘要翻译后参与排序
- 跨语言模型:使用mBERT等模型直接计算中英文相似度
- 多语言标签:为文档添加语言/领域元数据辅助过滤
计算效率
- 数据规模:100万篇医疗文献库
- 查询需求:实时返回"阿尔茨海默症新药研发进展"Top5结果(<500ms)
解决策略:
- 两阶段排序:
- 第一阶段:BM25快速筛选1000篇(耗时50ms)
- 第二阶段:Reranker精排Top100(耗时400ms)
- 模型蒸馏:将BERT-large蒸馏为Tiny版,速度提升5倍
- 硬件加速:使用TensorRT部署模型,GPU推理吞吐量提升10倍
典型排序算法演进
传统方法:BM25
bm25 是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法。特别是在处理长文档和短查询时表现出色,它根据查询词在文档中的出现频率、文档的长度等因素来计算文档与查询的相关性得分。
# 示例文档集和查询
docs = [
["apple", "banana", "cherry"],
["apple", "date"],
["banana", "elderberry"],
["apple", "banana", "banana", "fig"]
]
# 查询
query = ["apple", "banana"]
文档 1 (apple banana cherry): 得分约为 1.34
文档 2 (apple date): 得分约为 0.67
文档 3 (banana elderberry): 得分约为 0.67
文档 4 (apple banana banana fig): 得分约为 1.71
深度语义模型:Cross-Encoder
Cross - Encoder(交叉编码器)是一种用于计算文本对之间相关性得分的模型架构,在信息检索、自然语言推理、问答系统等多个自然语言处理任务中都有广泛应用。Cross - Encoder 直接将文本对作为输入,通过一个编码器统一处理,能够更有效地捕捉文本对之间的交互信息,从而得到更准确的相关性得分
# 文档集合
docs = [
"苹果是一种常见的水果,富含维生素。",
"香蕉是热带水果,味道香甜。",
"橙子具有丰富的维生素 C。",
"葡萄可以酿酒,口感酸甜。"
]
# 查询
query = "哪种水果富含维生素"
文档 1 (苹果是一种常见的水果,富含维生素。): 得分约为 2.50
文档 2 (香蕉是热带水果,味道香甜。): 得分约为 0.30
文档 3 (橙子具有丰富的维生素 C。): 得分约为 2.80
文档 4 (葡萄可以酿酒,口感酸甜。): 得分约为 0.20
最新进展:Col-BERT
Col-BERT是一种用于高效信息检索的模型,它结合了基于表示和基于交互的检索方法的优点。与传统的基于词袋模型或基于表示的检索方法不同,Col-BERT 在细粒度的词级别上对查询和文档进行交互,从而能够更准确地捕捉语义相关性
# 文档集合
docs = [
"苹果是一种常见的水果,富含维生素。",
"香蕉是热带水果,味道香甜。",
"橙子具有丰富的维生素 C。",
"葡萄可以酿酒,口感酸甜。"
]
# 查询
query = "哪种水果富含维生素?"
文档 1 (苹果是一种常见的水果,富含维生素。): 得分约为 35.68
文档 2 (香蕉是热带水果,味道香甜。): 得分约为 22.34
文档 3 (橙子具有丰富的维生素 C。): 得分约为 38.21
文档 4 (葡萄可以酿酒,口感酸甜。): 得分约为 20.12
主流模型选型
| 模型 | 特点 | 性能优势 |
|---|---|---|
| BGE ReRanker | 支持多语言 | 多语言场景、高精度需求 |
| Jina Reranker | 8k上下文支持 | 长文本排序、低延迟场景 |
| BCE-Reranker | 网易有道开源,中英跨语言优化 | 中英混合场景、高召回率需求 |
完整排序流程 :企业级知识库问答
用户问题
“如何搭建企业级LLM知识库的权限管理系统?”
初步检索(Retriever):
返回60篇文档:
- 15篇通用知识库搭建指南
- 20篇LLM技术原理文档
- 10篇企业权限管理方案
- 5篇数据安全合规标准
- 10篇无关内容(如客服系统建设)
Reranker工作流:
for 文档 in 60篇:
# 维度1:语义相关性(Cross-Encoder模型)
相关性得分 = model.predict(问题, 文档内容) # 范围0.5~1.0
# 维度2:时效性权重
if 文档年份 == 2024:
时效系数 = 1.3
elif 文档年份 >= 2022:
时效系数 = 1.1
else:
时效系数 = 0.8
# 维度3:权威性评估
if 文档来源 == "国家信通院白皮书":
权威系数 = 1.5
elif 文档来源 == "AWS/Azure官方文档":
权威系数 = 1.2
elif "个人博客" in 文档来源:
权威系数 = 0.6
# 维度4:内容完整性
完整性系数 = min(1.0, len(关键段落)/1000) # 关键段落指含"权限"、"RBAC"等内容
# 综合得分
最终得分 = 相关性得分 × 时效系数 × 权威系数 × 完整性系数
排序后Top3:
-
《2024企业级LLM知识库权限设计实践》(得分0.96)
- 来源:AWS官方技术文档
- 亮点:包含RBAC模型代码示例+GDPR合规方案
-
《大模型知识库的细粒度权限控制》(得分0.93)
- 来源:国家信通院技术报告
- 亮点:提出"权限-数据-模型"三级管控体系
-
《LLM知识库与企业AD域集成方案》(得分0.89)
- 来源:微软Tech Community
- 亮点:Active Directory对接实战案例
小结
Reranker模型是RAG系统中的智能排序引擎, 在知识库检索流程中承担着关键的优化角色。它通过多维度智能分析,对初步检索结果进行精细化处理,将最符合用户真实需求的信息精准呈现在前列。
不同于初检阶段的粗粒度筛选,Reranker会综合评估语义相关度(如问题与内容的深层匹配)、时效性(优先最新资料)、权威性(区分专家论述与普通观点)以及内容完整性(覆盖关键要素的程度)等多个核心维度,通过算法加权计算出每个结果的最终排序得分。
在企业级应用中, 这种智能排序机制有效解决了传统检索中面临的长尾问题、语义鸿沟等挑战,大幅提升了知识库的可用性和准确性,是确保专业用户获得高价值信息的关键技术保障。
