【深度学习笔记】深度学习训练技巧
深度学习训练技巧
1 优化器
-
随机梯度下降及动量
-
随机梯度下降算法对每批数据 ( X ( i ) , t ( i ) ) (X^{(i)},t^{(i)}) (X(i),t(i)) 进行优化
g = ∇ θ J ( θ ; x ( i ) , t ( i ) ) θ = θ − η g g=\nabla_\theta J(\theta;x^{(i)},t^{(i)})\\ \theta = \theta -\eta g g=∇θJ(θ;x(i),t(i))θ=θ−ηg
随机梯度下降算法的基本思想是,在每次迭代中,随机选择一个样本 i i i,计算该样本的梯度 g = ∇ θ J ( θ ; x ( i ) , t ( i ) ) g=\nabla_\theta J(\theta;x^{(i)},t^{(i)}) g=∇θJ(θ;x(i),t(i)),然后按照梯度的反方向更新参数 θ \theta θ,即 θ = θ − η g \theta = \theta -\eta g θ=θ−ηg,其中 η \eta η 是学习率,控制更新的步长。 -
基于动量的更新过程
为了改善随机梯度下降算法的收敛性,可以引入动量(momentum)的概念,即在更新参数时,考虑之前的更新方向和幅度,使得参数沿着一个平滑的轨迹移动。
v = γ v − η g θ = θ + v v=\gamma v-\eta g\\ \theta =\theta+v v=γv−ηgθ=θ+v
其中 v v v 是动量变量,初始为零向量, γ \gamma γ 是动量系数,控制之前更新的影响程度,一般取 0.9 0.9 0.9 左右的值。
-
-
Adagrad
Adagrad 是一种自适应学习率的梯度下降算法,它可以根据不同的参数调整不同的学习率,使得目标函数更快地收敛。
-
梯度记为 g = ∇ θ J ( θ ; x ( i ) , t ( i ) ) g=\nabla_\theta J(\theta;x^{(i)},t^{(i)}) g=∇θJ(θ;x(i),t(i))
-
更新过程
对于每个参数 θ i \theta_i θi,维护一个累积变量 c i c_i ci,初始为 0,然后每次将该参数的梯度平方 g i 2 g_i^2 gi2 累加到 c i c_i ci 上,即 c i = c i + g i 2 c_i=c_i+g_i^2 ci=ci+gi2。
c i = c i + g i 2 θ i = θ i − η c i + ϵ g i c_i=c_i+g_i^2\\ \theta_i=\theta_i-\frac{\eta}{\sqrt{c_i+\epsilon}}g_i ci=ci+gi2θi=θi−ci+ϵηgi
在更新该参数时,使用一个自适应的学习率 η c i + ϵ \frac{\eta}{\sqrt{c_i+\epsilon}} ci+ϵη,其中 η \eta η 是全局学习率, ϵ \epsilon ϵ 是一个小常数,用于防止除零错误。 -
工作原理
如果一个参数的梯度一直很大,那么它的 c i c_i ci 也会很大,从而降低它的学习率,防止过度更新;
如果一个参数的梯度一直很小,那么它的 c i c_i ci 也会很小,从而增加它的学习率,加快更新速度。这就实现了自适应的学习率调整,有利于加速收敛和避免震荡。
-
优点
计算简单,不需要手动调整学习率,适合处理稀疏数据和特征。
-
缺点
累积变量 c i c_i ci 会随着迭代次数增加而不断增大,导致学习率过小,甚至接近于零,使得后期训练缓慢或停滞。
-
-
RMSProp
RMSProp算法在Adagrad的基础上提出改进,以解决学习率单调下降的问题
-
基本思想
引入一个遗忘因子 γ \gamma γ 。对于每个参数 θ \theta θ,维护一个累积变量 c c c,初始为 0,然后每次将该参数的梯度平方 g 2 g^2 g2 乘以一个衰减系数 ( 1 − γ ) (1-\gamma) (1−γ),再加到 c c c 上,即 c = γ c + ( 1 − γ ) g 2 c=\gamma c+(1-\gamma)g^2 c=γc+(1−γ)g2。
c = γ c + ( 1 − γ ) g 2 θ = θ − η c + ϵ g c=\gamma c+(1-\gamma)g^2\\ \theta=\theta-\frac{\eta}{\sqrt{c+\epsilon}}g c=γc+(1−γ)g2θ=θ−c+ϵηg
γ \gamma γ 是一个介于 0 和 1 之间的常数,通常为0.9、0.99、0.999,用于控制历史信息的影响程度。 -
与Adagrad对比
c c c 不会随着迭代次数增加而无限增大,而是保持在一个合理的范围内,从而使得学习率下降得更加平稳。
-
-
Adam
Adam 算法是一种自适应学习率的梯度下降算法,它结合了 Momentum 和 RMSProp 的优点
-
简单形式
KaTeX parse error: Expected 'EOF', got '&' at position 26: …m+(1-\beta_1)g &̲ \text {(积攒历史梯度…
其中 β 1 \beta_1 β1 和 β 2 \beta_2 β2 是两个介于 0 和 1 之间的常数,用于控制历史信息的影响程度。一般取 β 1 = 0.9 \beta_1=0.9 β1=0.9 和 β 2 = 0.999 \beta_2=0.999 β2=0.999, ϵ = 1 0 − 8 \epsilon=10^{-8} ϵ=10−8。 -
完整形式
m = β 1 m + ( 1 − β 1 ) g , m t = m 1 − β 1 t c = β 2 c + ( 1 − β 2 ) g 2 , c t = c 1 − β 2 t θ = θ − η c t + ϵ m t m=\beta_1m+(1-\beta_1)g\ ,m_t=\frac{m}{1-\beta_1^t} \\ c=\beta_2c+(1-\beta_2)g^2\ ,c_t=\frac{c}{1-\beta_2^t} \\ \theta=\theta-\frac{\eta}{\sqrt{c_t+\epsilon}}m_t m=β1m+(1−β1)g ,mt=1−β1tmc=β2c+(1−β2)g2 ,ct=1−β2tcθ=θ−ct+ϵηmt
为了消除偏差,还需要对 m m m 和 c c c 进行偏差修正,即除以 1 − β 1 t 1-\beta_1^t 1−β1t 和 1 − β 2 t 1-\beta_2^t 1−β2t,其中 t t t 是迭代次数。
Adam 算法可以利用一阶矩和二阶矩的信息,实现自适应的学习率调整,使得参数在梯度方向上加速,而在垂直梯度方向上减速,从而避免参数在最优值附近的震荡,加快收敛速度。
-
关于优化器的更多细节:http://cs231n.github.io/neural-networks-3
2 处理过拟合
-
过拟合
-
定义:对训练集拟合得很好,但在验证集表现较差
神经网络 通常含有大量参数 (数百万甚至数十亿), 容易过拟合
-
处理策略:参数正则化、早停、随机失活、数据增强
-
-
早停
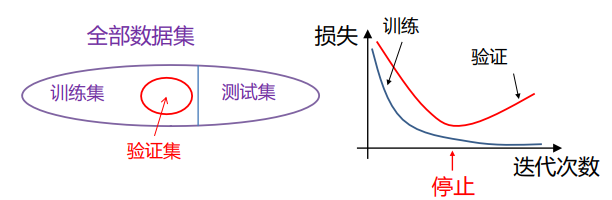
当发现训练损失逐渐下降,但验证集损失逐渐上升时,及时停止优化。
-
随机失活
-
训练过程
在训练迭代过程中,以 p p p(通常为0.5)的概率随机舍弃掉每个隐含层神经元(输出置零)
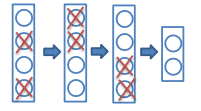
这些被置零的输出,将用于在反向传播中计算梯度
-
优点:
-
一个隐含层神经元不能依赖于其它存在的神经元,因此可以防止神经元出现复杂的相互协同(co-adaptations)
-
相当于在合理的时间内训练了大量不同的网络,并将其结果平均
-
-
测试过程
使用"平均网络(mean network)”,包含所有隐含层神经元
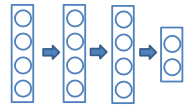
需要调整神经元输出的权重,用来弥补训练中只有一部分被激活的现象
- p=0.5时,将权重减半
- p=0.1,在权重上乘1-p,即0.9
实践中,p在低层设得较小,例如0.2,但在高层设得更大,例如0.5
这样得到的结果与在大量网络上做平均得到的结果类似
-
-
数据增强
数据增强(Data Augmentation)是一种用于优化深度学习模型的方法,它可以通过从现有数据生成新的训练数据来扩展原数据集,从而提高模型的泛化能力和防止过拟合。
数据增强的工具可以对数据进行各种操作和转换,如旋转、缩放、裁剪、翻转、调整亮度、对比度、颜色等,以生成新的、多样的、有代表性的样本。
-
随机翻转
通常只用左右翻转

-
随机缩放和裁剪

- 将测试图像缩放到模型要求的输入大小
- 剪裁一个区域(通常是中心区域)并输入到模型
- 剪裁多个并输入到模型,对输出作平均
-
随机擦除

测试时可以输入整张图像
-
3 批归一化
-
内部协变量偏移(Internal covariate shift)
当使用SGD时,不同迭代次数时输入到神经网络的数据不同,可能导致某些层输出的分布在不同迭代次数时不同。
ICS:训练中,深度神经网络中间节点分布的变化。可能增加优化难度。
-
通过归一化来减少ICS
对每个标量形式的特征单独进行归一化,使其均值为0,方差为1。
对于d维激活 x = ( x 1 , … , x d ) x=(x_1,…,x_d) x=(x1,…,xd),作如下归一化
x ^ i = x i − E [ x i ] Var [ x i ] \hat x_i=\frac{x_i-E[x_i]}{\sqrt{\text{Var}[x_i]}} x^i=Var[xi]xi−E[xi]
保持该层的表达能力
y i = γ i x ^ i + β i y_i=\gamma_i\hat x_i+\beta_i yi=γix^i+βi
若 γ i = Var [ x i ] \gamma_i=\sqrt{\text{Var}[x_i]} γi=Var[xi] 且 β i = E [ x i ] \beta_i=E[x_i] βi=E[xi] ,恢复到原来的激活值。 -
批归一化BN(Batch Normalization)
批归一化(Batch Normalization,BatchNorm)是一种用于优化深度神经网络的方法,它可以通过对每一层的输入数据进行标准化处理,使其均值为0,方差为1,从而减少每一层输入数据分布的变化,加快网络的收敛速度,提高网络的泛化能力和鲁棒性。
-
基本思想:
在每一层的输入数据上进行如下的变换:
x ~ i = x i − μ B σ B 2 + ϵ (归一化) y i = γ x ~ i + β (尺度变换和偏移) \tilde{x}_i=\frac{x_i-\mu_B}{\sqrt{\sigma_B^2+\epsilon}} \quad \text{(归一化)}\\ y_i=\gamma\tilde{x}_i+\beta \quad \text{(尺度变换和偏移)} x~i=σB2+ϵxi−μB(归一化)yi=γx~i+β(尺度变换和偏移)
其中, x i x_i xi 是第 i i i 个神经元的输入, μ B \mu_B μB 和 σ B 2 \sigma_B^2 σB2 是该层输入数据的均值和方差, ϵ \epsilon ϵ 是一个小常数,用于防止除零错误, x ~ i \tilde{x}_i x~i 是归一化后的输入, γ \gamma γ 和 β \beta β 是可学习的参数,用于调整数据的尺度和偏移, y i y_i yi 是最终的输出。 -
优点
- 可以选择较大的初始学习率,加快网络的收敛。
- 可以减少正则化参数的选择问题,如 Dropout、L2 正则项等。
- 可以把训练数据彻底打乱,防止每批训练的时候,某一个样本经常被挑选到。
- 可以缓解梯度消失或梯度爆炸的问题,使得网络可以使用更深的结构和更多的非线性激活函数。
-
缺点
- 增加了网络的计算量和内存消耗。
- 对于小批量的数据,可能会导致不稳定的结果。
- 对于某些任务,可能会降低网络的表达能力或性能。
-
-
其他归一化技巧
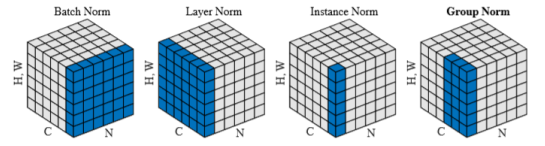
- 批归一化(Batch norm)用于CNN
- 层归一化(Layer norm)用于RNN
- 实例归一化(Instance norm)用于图像风格化
- 群归一化(Group norm)用于CNN处理批较小的情况
4 超参数选取
-
超参数
超参数: 控制算法行为,且不会被算法本身所更新,通常决定了一个模型的能力
对于一个深度学习模型, 超参数包括
- 层数,每层的神经元数目
- 正则化系数
- 学习率
- 参数衰减率(Weight decay rate)
- 动量项(Momentum rate)
-
如何选择深度学习模型的架构
- 熟悉数据集
- 与之前见过的数据/任务比较
- 样本数目
- 图像大小, 视频长度, 输入复杂度…
- 最好从在类似数据集或任务上表现良好的模型开始
-
如何选择其它超参数
由Fei-Fei Li & Justin Johnson & Serena Yeung(CS231n 2019,Stanford University)给出的建议
-
第1步:观察初始损失
- 确保损失的计算是正确的
- 将权重衰减设为零
-
第2步:在一组小样本上过拟合
- 在一组少量样本的训练集上训练,尝试达到100%训练准确率
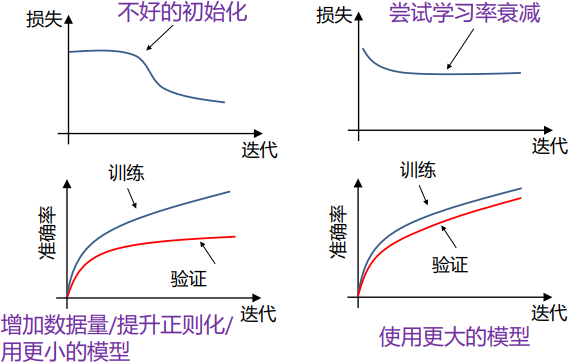
- 如果训练损失没有下降,说明是不好的初始化,学习率太小,模型太小
- 如果训练损失变成Inf或NaN,说明是不好的初始化,学习率太大
-
第3步:找到使损失下降的学习率
-
在全部数据上训练模型,并找到使损失值能够快速下降的学习率
当损失值下降较慢时,将学习率缩小10倍
使用较小的参数衰减
-
-
第4步:粗粒度改变学习率,训练1-5轮
- 在上一步的基础上,尝试一些比较接近的学习率和衰减率
- 常用的参数衰减率:1e-4,1e-5,0
-
第5步:细粒度改变学习率,训练更长时间
- 使用上一步找到的最好的学习率,并训练更长时间 (10-20 轮),期间不改变学习率
-
第6步:观察损失曲线
-
训练损失通常用滑动平均绘制,否则会有很多点聚集在一起
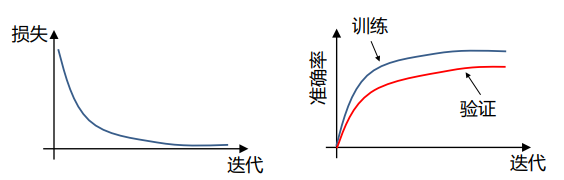
有问题的损失曲线:
-
-
延伸阅读:
- 各种深度学习模型的优化方法:http://cs231n.github.io/neural-networks-3/
- 关于不同正则化方法的讨论:https://www.cnblogs.com/LXP-
- Never/p/11566064.html Li,Chen,Hu,Yang,2019
Understanding the Disharmony Between Dropout and Batch Normalization by Variance Shift CVPR