数据结构概念
'''
什么是数据结构
**存储、组织数据的方式**
数据的种类有很多:字符串、整数、浮点..
同样的数据不同的组织方式就是数据结构
列表方式: 字典方式:
'''
#算法具有独立性和五大特性
'''
算法是计算机处理信息的本质,因为计算机程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务。
一般地,当算法在处理信息时,会从输入设备或数据的存储地址读取数据,把结果写入输出设备或某个存储地址供以后再调用。
> **算法是独立存在的一种解决问题的方法和思想.**
> 穷举法就是一种算法, 一种思想.
对于算法而言,实现的语言并不重要,重要的是思想。也就是说算法本身是独立于程序和各种编程语言的,而我们的程序只不过是对算法的一种表达和实现.
算法可以有不同的语言描述实现版本(如C描述、C++描述、Python描述等),我们现在是在用Python语言进行描述实现。
'''
#如果 a+b+c=1000,且 a^2+b^2=c^2(a,b,c 为自然数),如何求出所有a、b、c可能的组合
#这种问题就可以采用穷举法进行一一列举,最后筛选符合条件的组合
import time
t1=time.time()
for a in range(1001):
for b in range(1001):
for c in range(1001):
if a+b+c==1000 and a**2+b**2==c**2:
print(f'a={a},b={b},c={c}')
t2=time.time()
print(t2-t1)
# a=0,b=500,c=500
# a=200,b=375,c=425
# a=375,b=200,c=425
# a=500,b=0,c=500
# 312.4475281238556
'''
五大特性
1. **输入**: 算法具有0个或多个输入
2. **输出**: 算法至少有1个或多个输出
3. **有穷性**: 算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成
4. **确定性**:算法中的每一步都有确定的含义,不会出现二义性
5. **可行性**:算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成
'''
'''
我们如何用Python中的类型来保存一个班的学生信息? 如果想要快速的通过学生姓名获取其信息呢?
实际上当我们在思考这个问题的时候,我们已经用到了数据结构。
列表和字典都可以存储一个班的学生信息,但是想要在列表中获取一名同学的信息时,就要遍历这个列表,其时间复杂度为O(n),
而使用字典存储时,可将学生姓名作为字典的键,学生信息作为值,进而查询时不需要遍历便可快速获取到学生信息,其时间复杂度为O(1)。
我们为了解决问题,需要将数据保存下来,然后根据数据的存储方式来设计算法实现进行处理,那么数据的存储方式不同就会导致需要不同的算法进行处理。
我们希望算法解决问题的效率越快越好,于是我们就需要考虑数据究竟如何保存的问题,这就是数据结构。
在上面的问题中我们可以选择Python中的列表或字典来存储学生信息。列表和字典就是Python内建帮我们封装好的两种数据结构。
'''
'''
根据数据结构中数据之间的关系,将数据结构分类为:
- 线性结构
- 非线性结构
#### 线性结构
线性结构就是数据结构中各个结点具有线性关系
线性结构的特点:
①线性结构是非空集
②线性结构所有结点都最多只有一个直接前驱结点和一个直接后继结点
非线性结构
非线性结构就是数据结构中各个结点之间具有多个对应关系
非线性结构的特点:
①非线性结构是非空集
②非线性结构的一个结点可能有多个直接前驱结点和多个直接后继结点
'''
'''
线性表存储方式的分类
线性结构的实际存储方式,分为两种:
①顺序表: 将元素顺序地存放在一块连续的存储区里,元素间的顺序关系由它们的存储顺序自然表示
②链表: 将元素存放在通过链接构造起来的一系列存储块中 , 存储区是非连续的
顺序表的存储方式
顺序表元素顺序地存放在一块连续的存储区里,具体的存储方式的两种情况:
- 一体式结构
- 分离式结构
'''
算法时间效率衡量






#解题算法二:
import time
t1 = time.time()
for a in range(0,1001):
for b in range(0,1001):
c = 1000-a-b
if a**2 + b**2 == c**2:
print(f'输出结果{a},{b},{c}')
t2 = time.time()
print(t2-t1)
# 对于同一问题,我们给出了两种解决算法,在两种算法的实现中,我们对程序执行的时间进行了测算,
# 发现两段程序执行的时间相差悬殊(312.4475281238556秒相比于1.084791898727417秒),由此我们可以得出结论:
# 实现算法程序的执行时间可以反应出算法的效率,即算法的优劣。
# > 单靠时间值绝对可信吗?
# 假设我们将第二次尝试的算法程序运行在一台配置古老性能低下的计算机中,情况会如何?很可能运行的时间并不会比在我们的电脑中运行算法一的214.583347秒快多少。
# > 单纯依靠运行的时间来比较算法的优劣并不一定是客观准确的!
# 程序的运行离不开计算机环境(包括硬件和操作系统),这些客观原因会影响程序运行的速度并反应在程序的执行时间上。那么如何才能客观的评判一个算法的优劣呢?
'''
算法的时间效率衡量
我们假定计算机执行算法每一个基本操作的时间是固定的一个时间单位,那么有多少个基本操作就代表会花费多少时间单位。
显然对于不同的机器环境而言,确切的单位时间是不同的,但是对于算法进行多少个基本操作(即花费多少时间单位)在 规模数量级 上却是相同的,
由此可以忽略机器环境的影响而客观的反应算法的时间效率。
通过规模的不同,来计算时间总量T
总量为1000:
`T = 1001*1001*1001*10 次`
总量为2000:
`T = 2001*2001*2001*10 次`
总量为3000:
`T = 3001*3001*3001*10 次`
总量为n:
`T = n*n*n*10 次`
我们就将上面的算数,总结为一个表达式:
`T(n) = n*n*n*10`
我们把这个表达式称为:时间复杂度(针对这个例题)
具体可以见图
'''
'''
时间复杂度的计算规则
①基本操作
时间复杂度为O(1)
②顺序结构
时间复杂度按**加法**进行计算
③循环结构
时间复杂度按**乘法**进行计算
④分支结构
时间复杂度**取最大值**
⑤判断一个算法的效率时,往往只需要关注操作数量的**最高次项**,其它次要项和常数项可以忽略
⑥在没有特殊说明时,我们所分析的算法的时间复杂度都是指**最坏时间复杂度**
'''
'''
分析算法时,存在几种可能的考虑:
- 算法完成工作最少需要多少基本操作,即**最优时间复杂度**
- 算法完成工作最多需要多少基本操作,即**最坏时间复杂度**
- 算法完成工作平均需要多少基本操作,即**平均时间复杂度**
对于最优时间复杂度,其价值不大,因为它没有提供什么有用信息,其反映的只是最乐观最理想的情况,没有参考价值。
对于最坏时间复杂度,提供了一种保证,表明算法在此种程度的基本操作中一定能完成工作。
对于平均时间复杂度,是对算法的一个全面评价,因此它完整全面的反映了这个算法的性质。但另一方面,这种衡量并没有保证,不是每个计算都能在这个基本操作内完成。而且,对于平均情况的计算,也会因为应用算法的实例分布可能并不均匀而难以计算。
> **因此,我们主要关注算法的最坏情况,亦即最坏时间复杂度。**
'''
'''
常见的时间复杂度
| **执行次数函数举例** | **阶** | **非正式术语** |
| -------------------- | ------- | -------------- |
| 12 | O(1) | 常数阶 |
| 2n+3 | O(n) | 线性阶 |
| 3n2+2n+1 | O(n2) | 平方阶 |
| 5log2n+20 | O(logn) | 对数阶 |
| 6n3+2n2+3n+4 | O(n3) | 立方阶 |
'''
'''
空间复杂度
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的度量
类似于时间复杂度,一个算法的空间复杂度S(n)定义为该算法所耗费的存储空间,也使用大O记法。
和时间复杂度类似,空间复杂度一般常见的有:
O(1) < O(logn) < O(n) < O(n2) < O(n3)
#### 常数阶O(1)
普通常量、变量、对象、元素数量与输入数据大小 N 无关的集合,皆使用常数大小的空间。
'''
链表
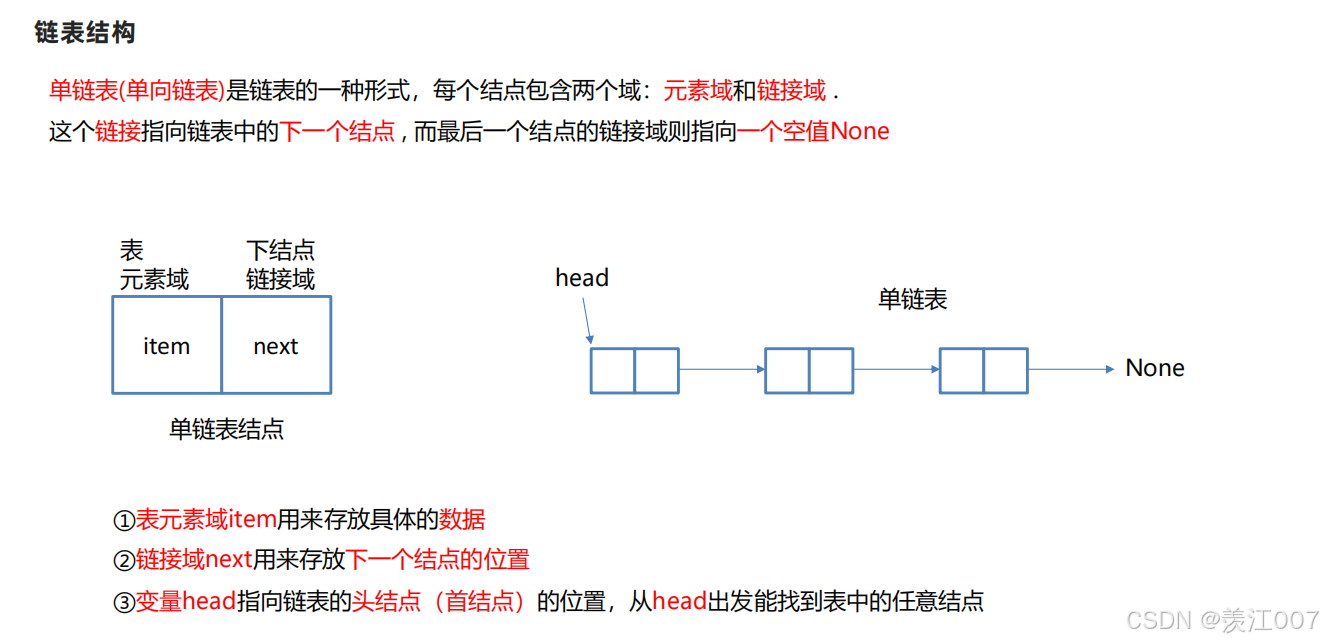


# 单向链表也叫单链表,是链表中最简单的一种形式,它的每个节点包含两个域,一个信息域(元素域)和一个链接域。
# 这个链接指向链表中的下一个节点,而最后一个节点的链接域则指向一个空值。
'''
- 表元素域item用来存放具体的数据。
- 链接域next用来存放下一个节点的位置(python中的标识)
- 变量p指向链表的头节点(首节点)的位置,从p出发能找到表中的任意节点。
'''
'''
单链表的操作
- is_empty() 链表是否为空
- length() 链表长度
- travel() 遍历整个链表
- add(item) 链表头部添加元素
- append(item) 链表尾部添加元素
- insert(pos, item) 指定位置添加元素
- remove(item) 删除节点
- search(item) 查找节点是否存在
'''
#定义单链表节点
class SingleNode(): #节点对象
def __init__(self,item=None):
#item存放数据元素
self.item=item
#next是指向下一个节点的表述
self.next=None #暂时没有
#将节点对象交给链表对象进行管理
#定义单向链表
class SingleLinkLine(): #链表对象
def __init__(self,node=None):
self.head=node
# is_empty()链表是否为空
def is_empty(self):
if self.head==None:
return True
else:
return False
# - length()链表长度
def length(self):
#计数器
count=0
cur=self.head
while cur!=None:
cur=cur.next
count+=1
return count
# - travel()遍历整个链表
def travel(self):
cur=self.head
cur_list=[]
while cur!=None:
cur_list.append(cur.item)
cur=cur.next
return cur_list
# - add(item)链表头部添加元素
def add(self,new_item):
#获取新节点的地址指针
new_cur=SingleNode(new_item)
print('new_cur=',new_cur)
#将旧头部的指针信息传给新节点的next,使得新头部指向旧头部
new_cur.next=self.head
print('new_cur.next=',self.head)
#再将链表头部指针指向新头部
self.head=new_cur
print(self.head)
pass
# - append(item)链表尾部添加元素
def append(self,new_item):
# 获取新节点的地址指针
new_cur = SingleNode(new_item)
# #判断是否是空链表
# if self.head==None:
# self.head=new_cur
# else:
#寻找链表尾
cur=self.head
while cur.next!=None:
cur=cur.next
#链表尾指向新的链表尾
cur.next=new_cur
# - insert(pos, item)指定位置添加元素
def insert(self,pos,new_item):
# 获取新节点的地址指针
new_cur = SingleNode(new_item)
#计数
count=0
#游标
cur=self.head
#判断是否在链表头
if pos<=0:
self.add()
#判断是否在链表尾
elif pos>=self.length():
self.append()
else:
while count<pos-1:
count+=1
cur=cur.next
new_cur.next=cur.next
cur.next=new_cur
# - remove(item)删除节点
def remove(self,item):
cur=self.head
pre=None
while cur is not None:
if cur.item==item:
if cur==self.head:
self.head=cur.next
else:
pre.next=cur.next
break
else:
pre=cur
cur=cur.next
# - search(item)查找节点是否存在
def search(self,item):
cur=self.head
while cur!=None:
if cur.item==item:
return True
cur=cur.next
print('节点不存在')
#链表实例化
def tast1():
mynode=SingleNode(1)
print('maynode=',mynode)
print('mynode.item=',mynode.item)
print('mynode.next=',mynode.next)
linklist=SingleLinkLine(mynode)#要手动继承
print('linklist=',linklist)
print('linklist.head=',linklist.head)
print('item=',linklist.head.item)#head指向节点,节点包括节点数据和下个节点的地址信息
print('next=',linklist.head.next)
#用于测试is_empty length taavel函数是否正常
def tast2():
mynode = SingleNode(9)
linklist = SingleLinkLine(mynode)
print(linklist.is_empty())
print(linklist.length())
print(linklist.travel())
#用于测试add append insert remove search函数是否正常
def tast3():
mynode = SingleNode('帅')
linklist = SingleLinkLine(mynode)
linklist.add('我')
linklist.append('哥')
linklist.insert(pos=1,new_item='是')
linklist.add(1)
linklist.remove(1)
# linklist.remove('是')
print(linklist.search(1))
print(linklist.travel())
if __name__=='__main__':
tast3()