XGBoost
XGBoost
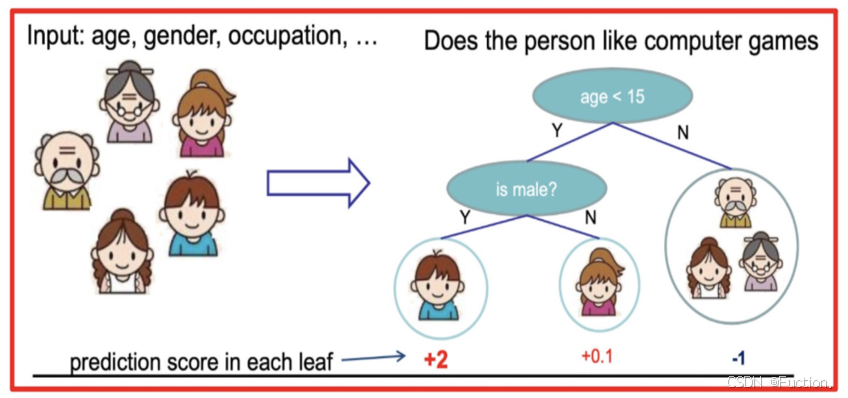
XGBoost算法思想
- 求解损失函数极值时使用泰勒二阶展开
- 在损失函数中加入了正则化项
- XGB 自创一个树节点分裂指标。这个分裂指标就是从损失函数推导出来的。XGB 分裂树时考虑到了树的复杂度。
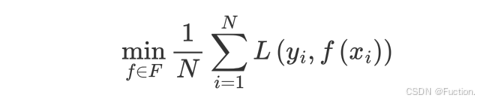
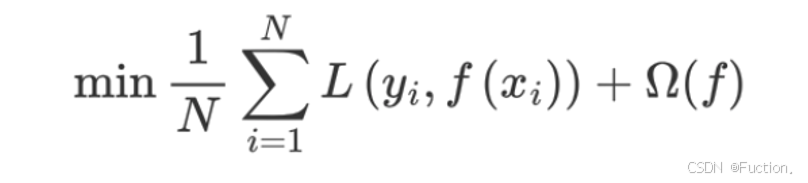
XGboost的目标函数
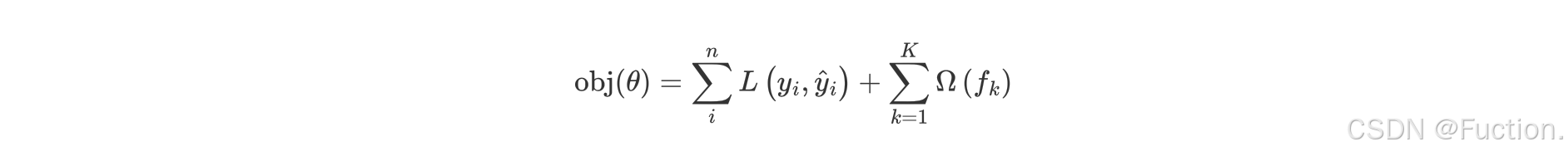
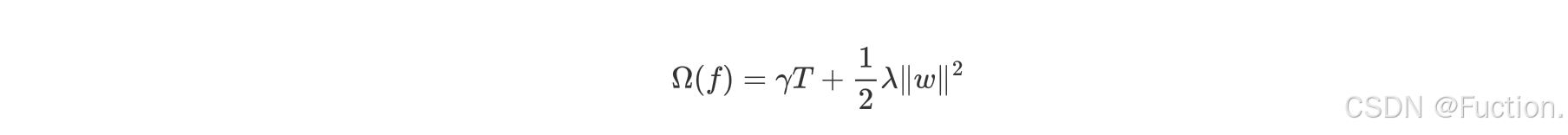
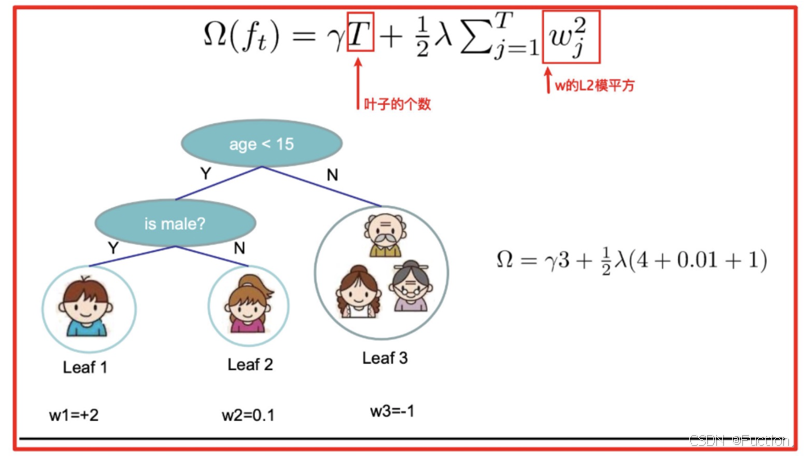
- γT 中的 T 表示一棵树的叶子结点数量,γ 是对该项的调节系数
- λ||w||
- 模型复杂度的介绍
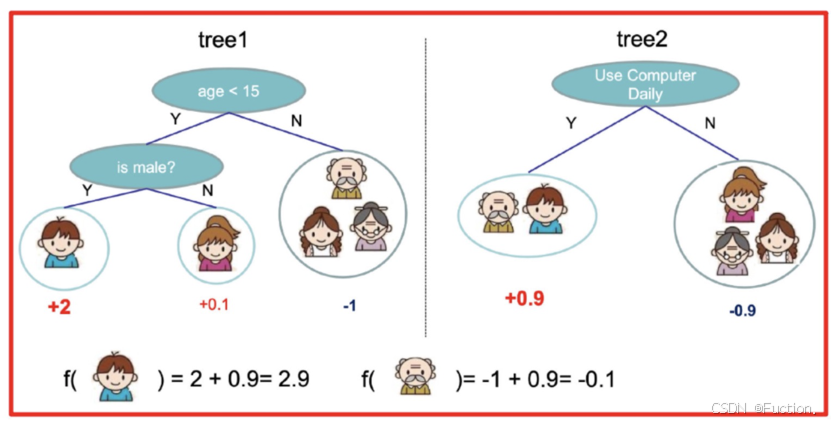
- 小男孩的预测分数就是两棵树中小孩所落到的结点的分数相加:2 + 0.9 = 2.9。
- 爷爷的预测分数同理:-1 + 0.9 = -0.1。
- 泰勒公式展开
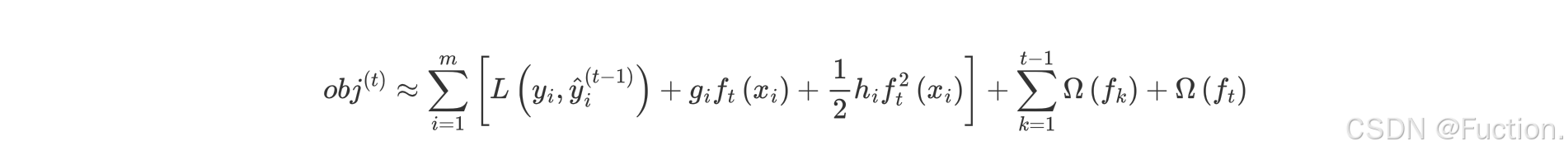
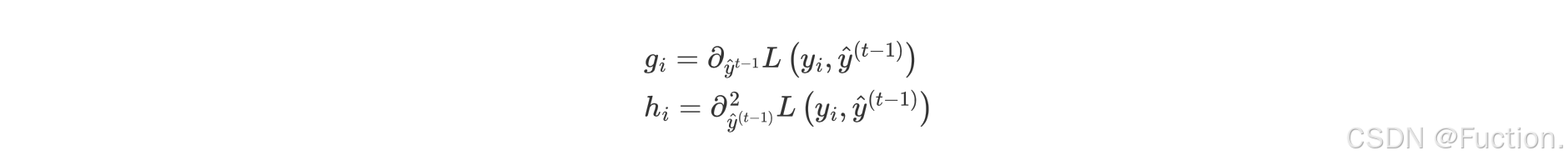
- 化简目标函数
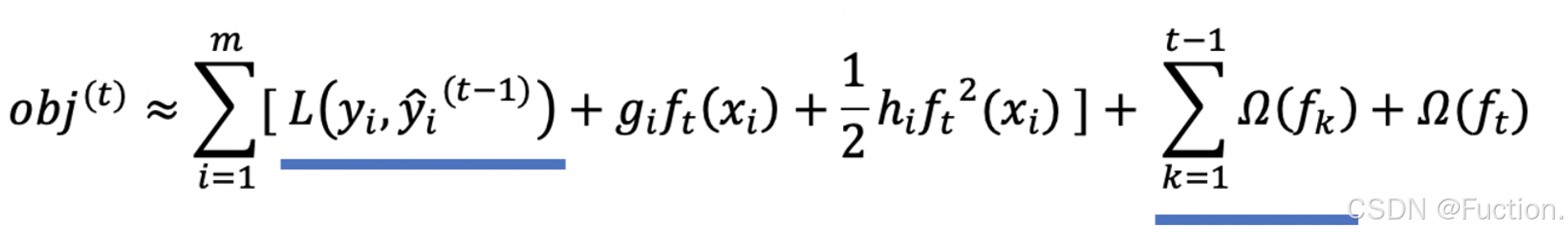
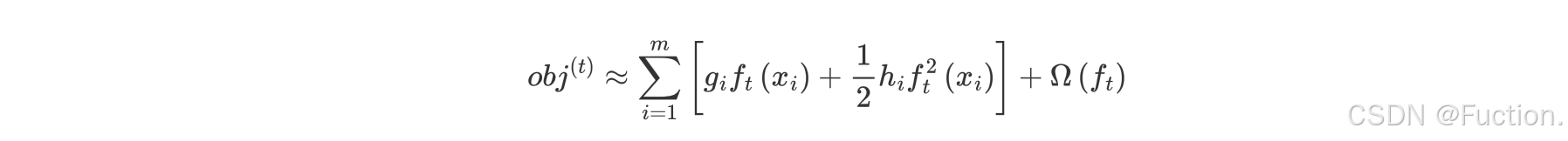
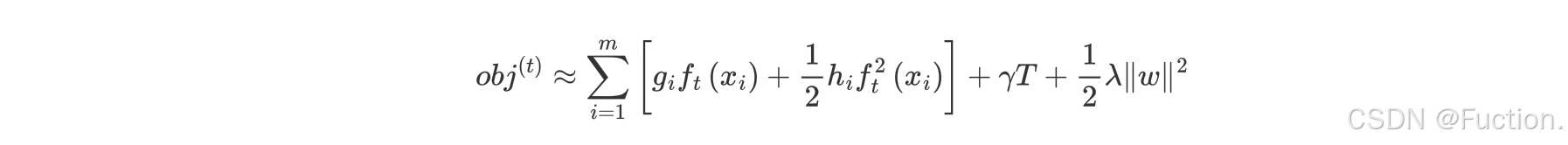
- 问题再次转换
- gi 表示每个样本的一阶导,hi 表示每个样本的二阶导
- ft(xi) 表示样本的预测值
- T 表示叶子结点的数目
- ||w||² 由叶子结点值组成向量的模
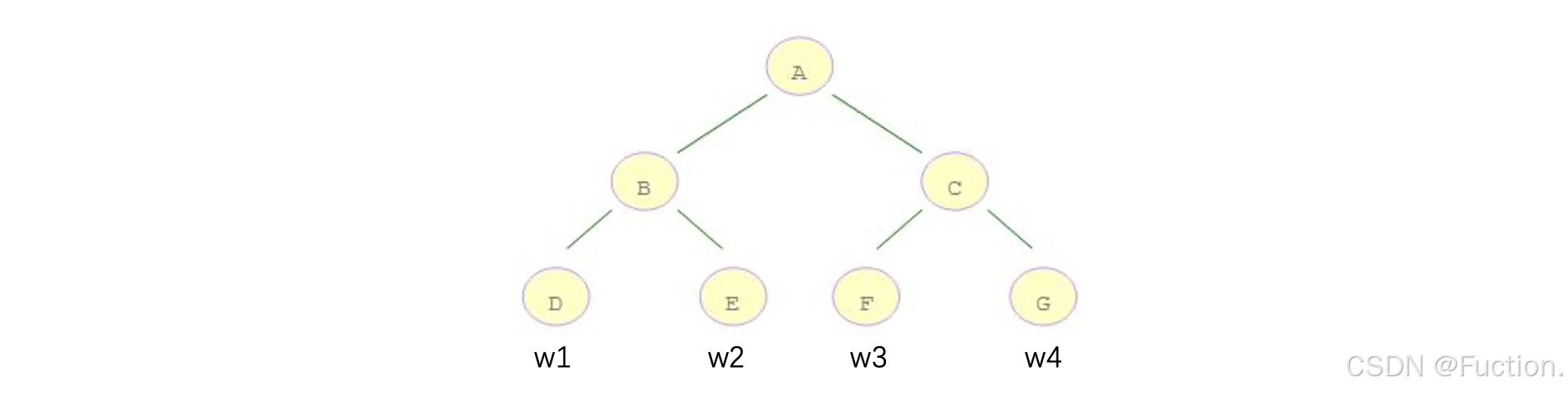
- D 结点计算: w1 * gi1 + w1 * gi2 + w1 * gi3 = (gi1 + gi2 + gi3) * w1
- E 结点计算: w2 * gi4 + w2 * gi5 = (gi4 + gi5) * w2
- F 结点计算: w3 * gi6 + w3 * gi6 = (gi6 + gi7) * w3
- G 节点计算:w4 * gi8 + w4 * gi9 + w4 * gi10 = (gi8 + gi9 + gi10) * w4
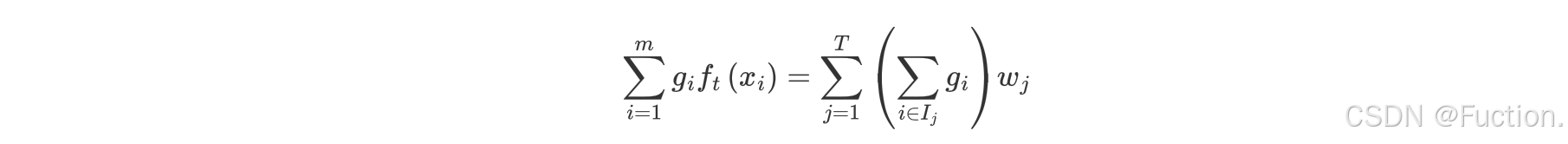
- wj 表示第 j 个叶子结点的值
- gi 表示每个样本的一阶导
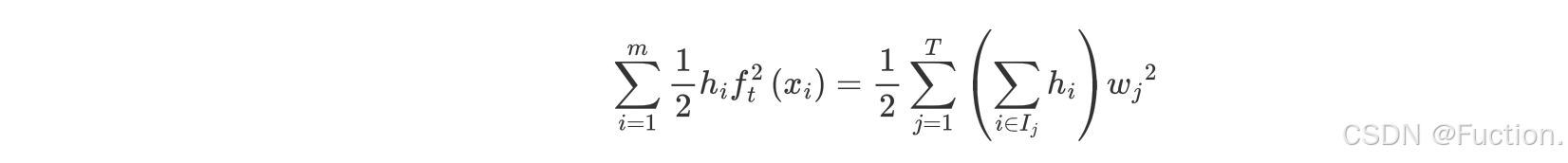
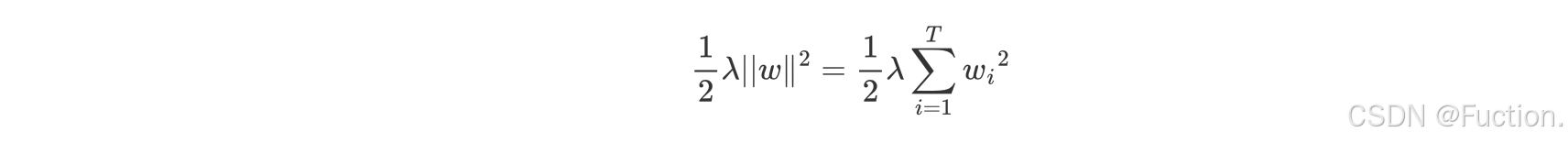
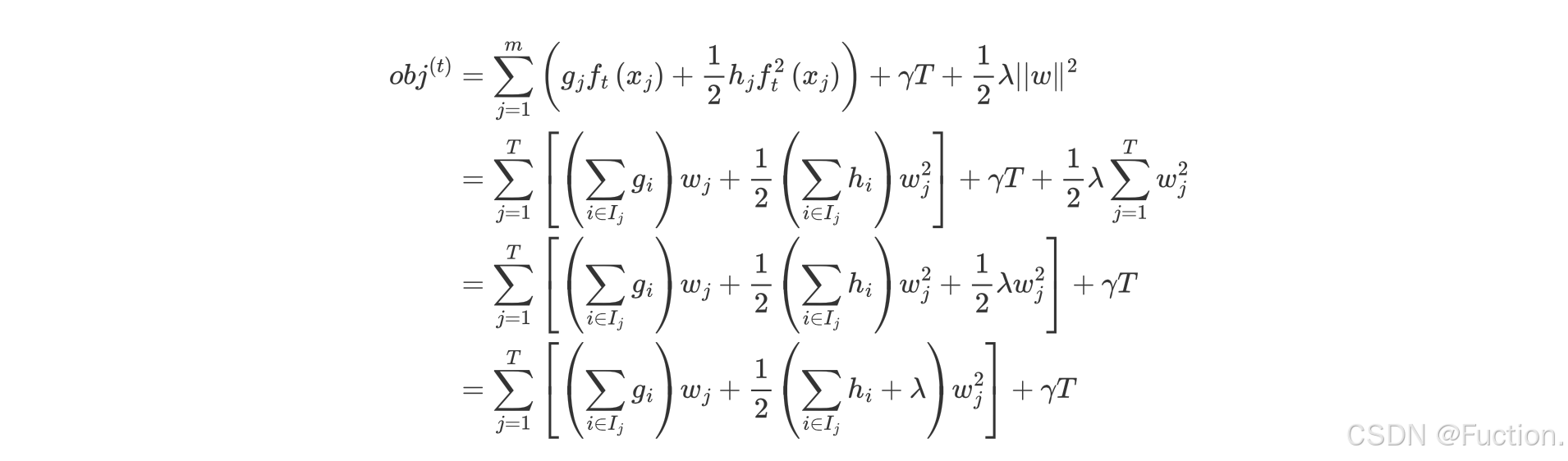
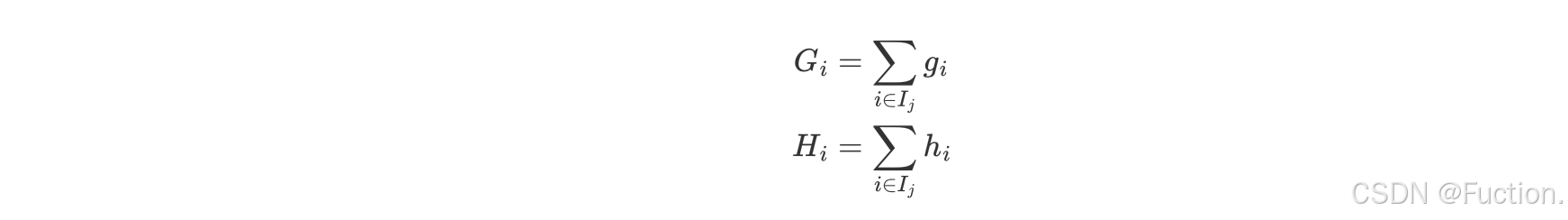
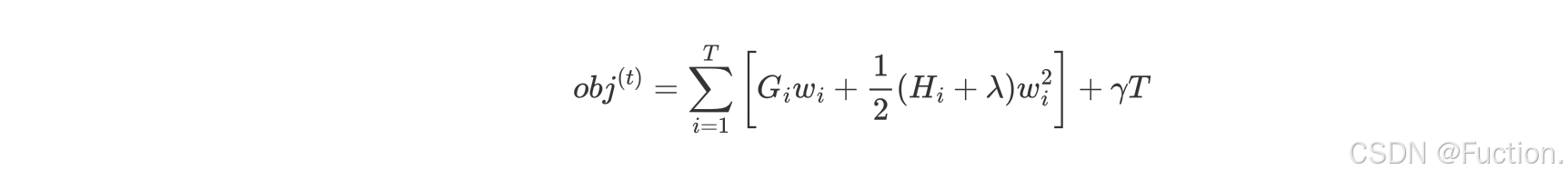
- 对叶子结点求导
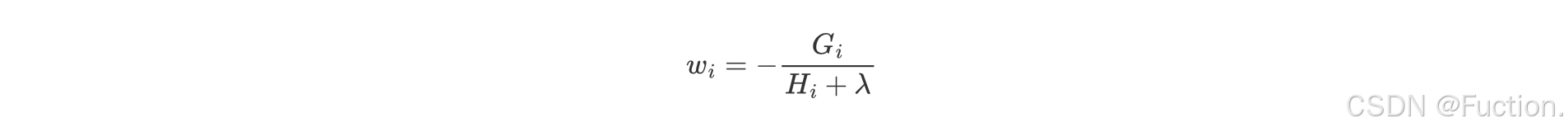
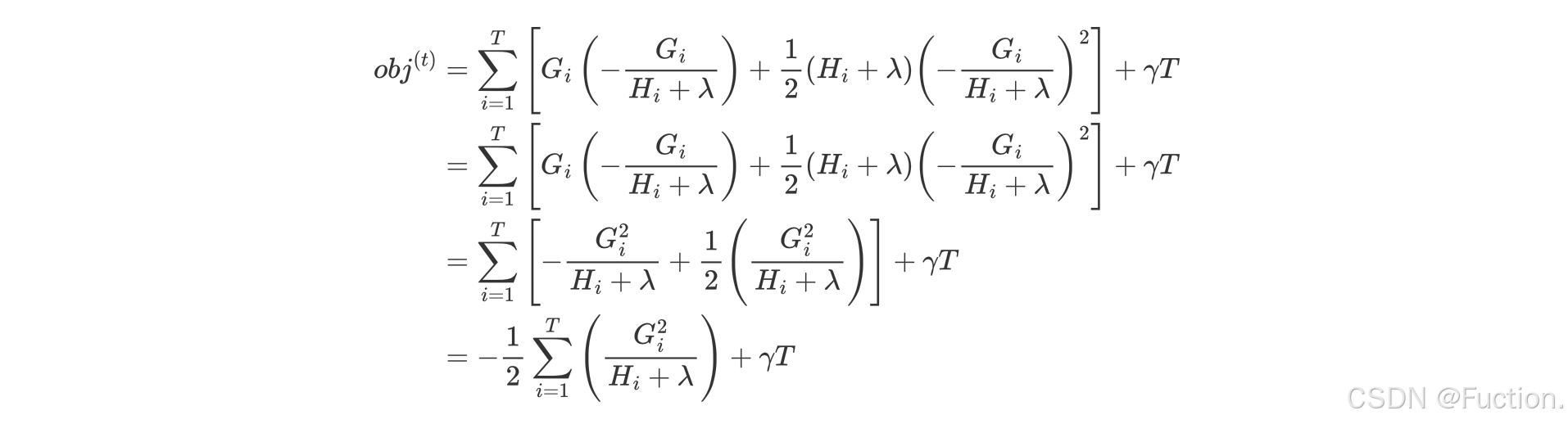
- XGBoost的树构建方法
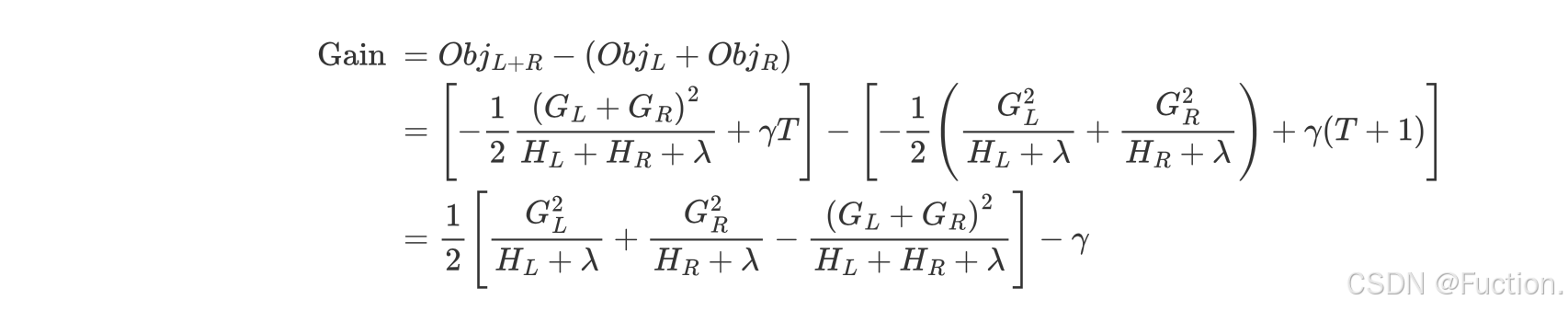
结论
- 对树中的每个叶子结点尝试进行分裂
- 计算分裂前 - 分裂后的分数:
- 如果gain > 0,则分裂之后树的损失更小,我们会考虑此次分裂
- 如果gain< 0,说明分裂后的分数比分裂前的分数大,此时不建议分裂
- 当触发以下条件时停止分裂:
- 达到最大深度
- 叶子结点样本数量低于某个阈值
- 等等...

XGboost API
- 支持非sklearn方式,也即是自己的风格
- 支持sklearn方式,调用方式保持sklearn的形式
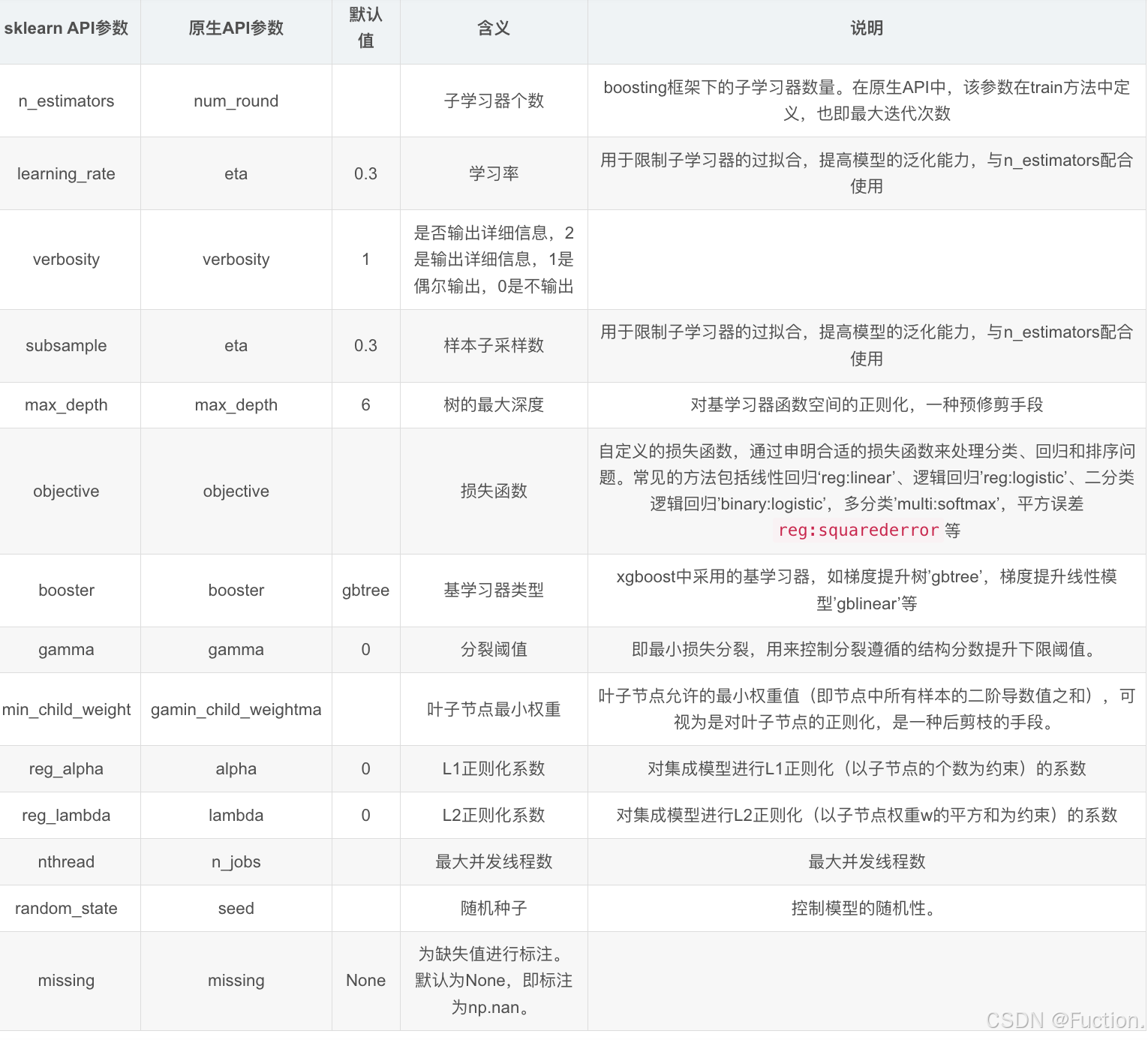
| sklearn API参数 | 原生API参数 | 默认值 | 含义 | 说明 |
| n_estimators | num_round | 子学习器个数 | boosting框架下的子学习器数量。在原生API中,该参数在train方法中定义,也即最大迭代次数 | |
| learning_rate | eta | 0.3 | 学习率 | 用于限制子学习器的过拟合,提高模型的泛化能力,与n_estimators配合使用 |
| verbosity | verbosity | 1 | 是否输出详细信息 | 2是输出详细信息,1是偶尔输出,0是不输出 |
| subsample | eta | 0.3 | 样本子采样数 | 用于限制子学习器的过拟合,提高模型的泛化能力,与n_estimators配合使用 |
| max_depth | max_depth | 6 | 树的最大深度 | 对基学习器函数空间的正则化,一种预修剪手段 |
| objective | objective | 损失函数 | 自定义的损失函数,通过申明合适的损失函数来处理分类、回归和排序问题 | |
| booster | booster | gbtree | 基学习器类型 | xgboost中采用的基学习器,如梯度提升树'gbtree',梯度提升线性模型'gblinear'等 |
| gamma | gamma | 0 | 分裂阈值 | 即最小损失分裂,用来控制分裂遵循的结构分数提升下限阈值。 |
| min_child_weight | min_child_weight | 叶子节点最小权重 | 叶子节点允许的最小权重值(即节点中所有样本的二阶导数值之和),可视为是对叶子节点的正则化,是一种后剪枝的手段。 | |
| reg_alpha | alpha | 0 | L1正则化系数 | 对集成模型进行L1正则化(以子节点的个数为约束)的系数 |
| reg_lambda | lambda | 0 | L2正则化系数 | 对集成模型进行L2正则化(以子节点权重w的平方和为约束)的系数 |
| nthread | n_jobs | 最大并发线程数 | 最大并发线程数 | |
| random_state | seed | 随机种子 | 控制模型的随机性。 | |
| missing | missing | None | 为缺失值进行标注 | 默认为None,即标注为np.nan。 |
红酒品质预测
数据集介绍
案例实现
import joblib
import numpy as np
import xgboost as xgb
import pandas as pd
import numpy as np
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.model_selection import StratifiedKFold- 数据基本处理
def test01():
# 1. 加载训练数据
data = pd.read_csv('data/红酒品质分类.csv')
x = data.iloc[:, :-1]
y = data.iloc[:, -1] - 3
# 2. 数据集分割
x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.2, stratify=y, random_state=22)
# 3. 存储数据
pd.concat([x_train, y_train], axis=1).to_csv('data/红酒品质分类-train.csv')
pd.concat([x_valid, y_valid], axis=1).to_csv('data/红酒品质分类-valid.csv')- 模型基本训练
def test02():
# 1. 加载训练数据
train_data = pd.read_csv('data/红酒品质分类-train.csv')
valid_data = pd.read_csv('data/红酒品质分类-valid.csv')
# 训练集
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
# 测试集
x_valid = valid_data.iloc[:, :-1]
y_valid = valid_data.iloc[:, -1]
# 2. XGBoost模型训练
estimator = xgb.XGBClassifier(n_estimators=100,
objective='multi:softmax',
eval_metric='merror',
eta=0.1,
use_label_encoder=False,
random_state=22)
estimator.fit(x_train, y_train)
# 3. 模型评估
y_pred = estimator.predict(x_valid)
print(classification_report(y_true=y_valid, y_pred=y_pred))
# 4. 模型保存
joblib.dump(estimator, 'model/xgboost.pth')- 模型参数调优
# 样本不均衡问题处理
from sklearn.utils import class_weight
classes_weights = class_weight.compute_sample_weight(class_weight='balanced',y=y_train)
# 训练的时候,指定样本的权重
estimator.fit(x_train, y_train,sample_weight = classes_weights)
y_pred = estimator.predict(x_valid)
print(classification_report(y_true=y_valid, y_pred=y_pred))
# 交叉验证,网格搜索
train_data = pd.read_csv('data/红酒品质分类-train.csv')
valid_data = pd.read_csv('data/红酒品质分类-valid.csv')
# 训练集
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
# 测试集
x_valid = valid_data.iloc[:, :-1]
y_valid = valid_data.iloc[:, -1]
# 分层采样(一般结合网格搜索+交叉验证一起使用) 目的:避免过拟合,采样时,会让采样数据的个分类比例 保持 和元数据的 个分类比例 保持近似一致。
# 参1:采样的次数(类似于折数),shuffle:是否打乱,random_state: 随机种子。
spliter = StratifiedKFold(n_splits=5, shuffle=True)
# 2. 定义超参数
param_grid = {'max_depth': np.arange(3, 5, 1),
'n_estimators': np.arange(50, 150, 50),
'eta': np.arange(0.1, 1, 0.3)}
estimator = xgb.XGBClassifier(n_estimators=100,
objective='multi:softmax',
eval_metric='merror',
eta=0.1,
use_label_encoder=False,
random_state=22)
cv = GridSearchCV(estimator,param_grid,cv=spliter)
y_pred = cv.predict(x_valid)
print(classification_report(y_true=y_valid, y_pred=y_pred))