MySQL 横向衍生表(Lateral Derived Tables)
前面我们介绍过MySQL中的衍生表(From子句中的子查询)和它的局限性,MySQL8.0.14引入了横向衍生表,可以在子查询中引用前面出现的表,即根据外部查询的每一行动态生成数据,这个特性在衍生表非常大而最终结果集不需要那么多数据的场景使用,可以大幅降低执行成本。
衍生表的基础介绍:
MySQL 衍生表(Derived Tables)
文章目录
- 一、横向衍生表用法示例
- 1.1 用法示例
- 1.2 使用建议
一、横向衍生表用法示例
横向衍生表适用于在需要通过子查询获取中间结果集的场景,相对于普通衍生表,横向衍生表可以引用在其之前出现过的表名,这意味着如果外部表上有高效的过滤条件,那么在生成衍生表时就可以利用这些条件,相当于将外层的条件提前应用到子查询中。
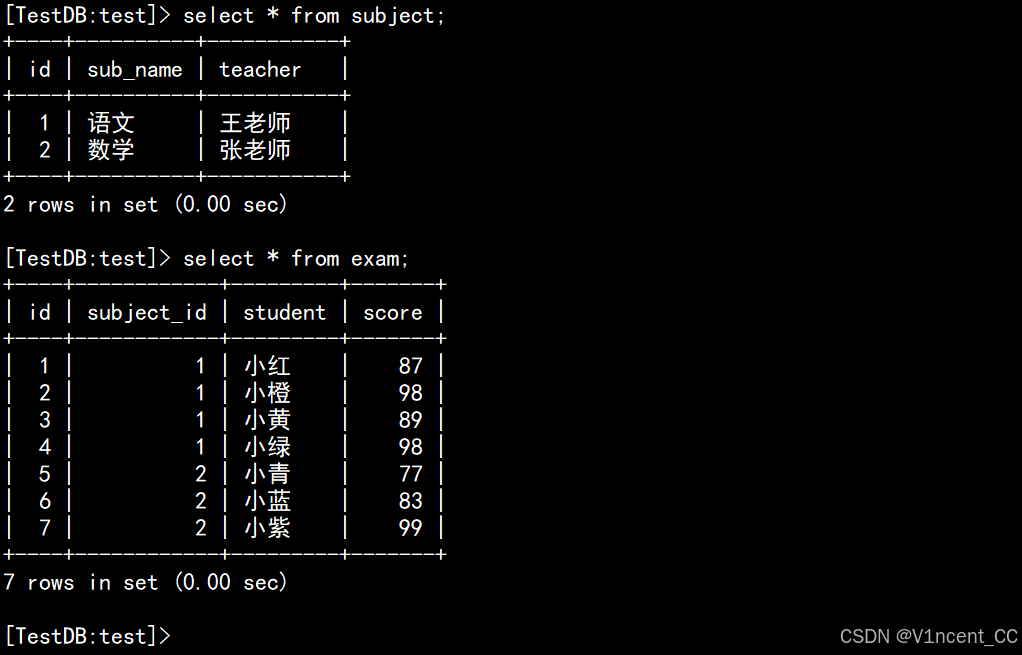
先创建示例数据,有2张表,一张存储科目和代课老师(Subject表),一张存储学生的成绩(Exam表) :
create table subject(
id int not null primary key,
sub_name varchar(12),
teacher varchar(12));
insert into subject values (1,'语文','王老师'),(2,'数学','张老师');
create table exam(
id int not null auto_increment primary key,
subject_id int,
student varchar(12),
score int);
insert into exam values(null,1,'小红',87);
insert into exam values(null,1,'小橙',98);
insert into exam values(null,1,'小黄',89);
insert into exam values(null,1,'小绿',98);
insert into exam values(null,2,'小青',77);
insert into exam values(null,2,'小蓝',83);
insert into exam values(null,2,'小紫',99);
select * from subject;
select * from exam;
1.1 用法示例
现需要查询每个代课老师得分最高的学生及分数。这个问题需要分为两步:
1.通过对exam表进行分组,找出每个科目的最高分数。
2.通过subject_id和最高分数,找到具体的学生和老师。
通过普通衍生表,SQL的写法如下:
select s.teacher,e.student,e.score
from subject s
join exam e on e.subject_id=s.id
join (select subject_id, max(score) highest_score from exam group by subject_id) best
on best.subject_id=e.subject_id and best.highest_score=e.score;
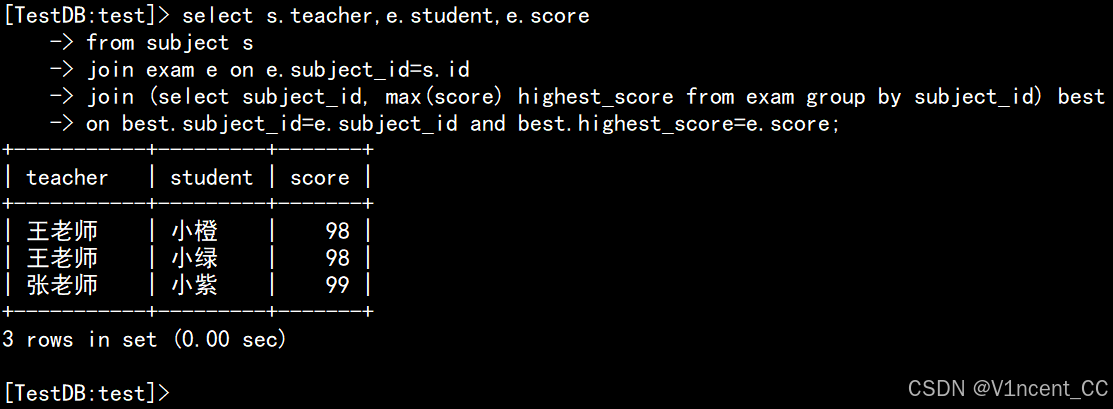
• 通过衍生表best,首先查出每个科目的最高最高分数。
• 将衍生表与原表连接,查出最高分数对应的学生和老师。
横向衍生表通过在普通衍生表前面添加lateral关键字,然后就可以引用在from子句之前出现的表,这个例子中具体的表现是在衍生表中和exam进行了关联。
select s.teacher,e.student,e.score
from subject s
join exam e on e.subject_id=s.id
join lateral (select subject_id, max(score) highest_score from exam where exam.subject_id=e.subject_id group by e.subject_id) best
on best.highest_score=e.score;

1.2 使用建议
横向衍生表特性作为普通衍生表的补充,其本质就是关联子查询,可以提升特定场景下查询性能。
上面的案例中:
- 如果exam表非常大,而查询结果仅涉及小部分科目,那么衍生表就没必要对全部的exam数据进行分组,利用横向生成衍生表时可以直接过滤出这小部分科目的数据,然后再分组,此时横向衍生表性能更优。
- 如果exam表比较小,或者查询结果覆盖了大部分科目,那么一次性生成中间结果集成本更低,那么普通衍生表性能更优。