redis事务
1. 认识redis事务
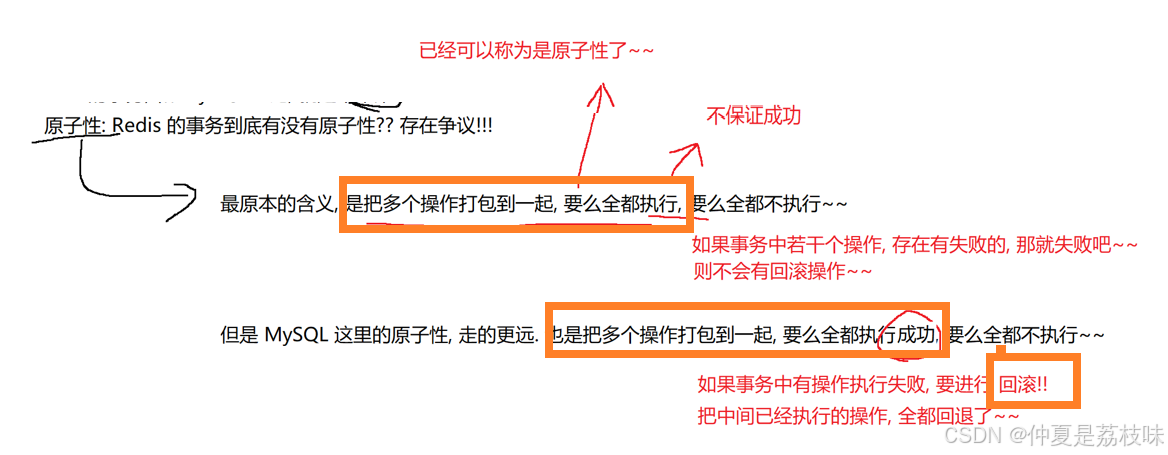 不具备一致性:redis没有约束,也没有回滚机制,事务执行过程中如果某个修改操作出现失败,就可能引起不一致的情况
不具备一致性:redis没有约束,也没有回滚机制,事务执行过程中如果某个修改操作出现失败,就可能引起不一致的情况
不具备持久性:Redis本身就是内存数据库,数据是存储在内存中的.虽然Redis也有持久化机制,但是这里的持久化机制,和事务没有啥直接关系。
不涉及隔离性:Redis是一个单线程模型的服务器程序.所有的请求/事务都是“串行”执行的。
Redis的事务,主要的意义,就是为了“打包”,避免其他客户端的命令,插队插到中间。
Redis中实现事务,是引入了队列(每个客户端都有一个),开启事务的时候,此时客户端输入的命令,就会发给服务器并且进入这个队列中(而不是立即执行),当遇到了“执行事务”命令的时候,此时就会把队列中的这些任务都按照顺序依次执行( Redis主线程中完成的,主线程会把事务中的操作都执行完,再处理别的客户端)
啥时候需要使用到Redis的事务呢?如果需要把多个操作打包进行,使用事务是比较合适的 。
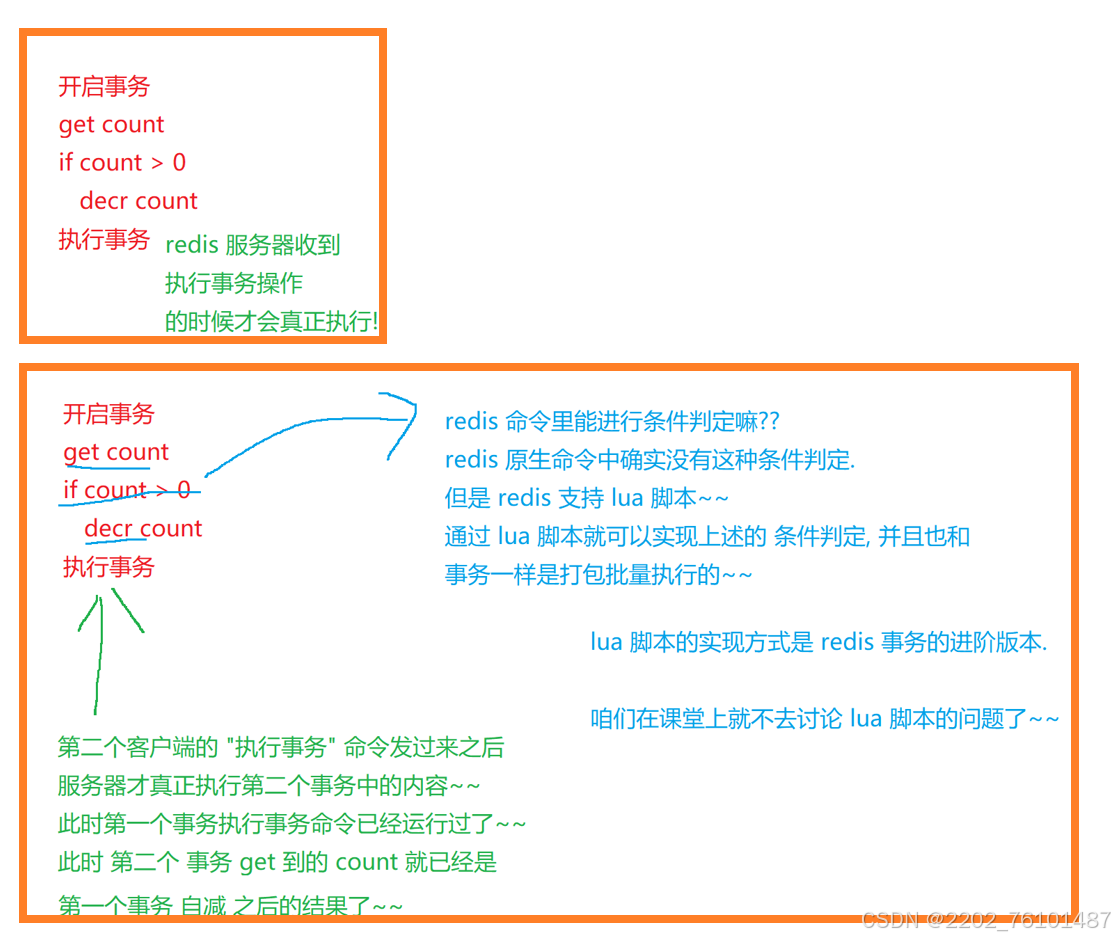
这个场景中,没加锁,也能解决决上述超卖问题,redis的事务的应用场景,确实没有mysl的事务那么多。
2. 事务相关的指令
开启事务 MULTI
执行事务 EXEC
放弃当前事务 DISCARD
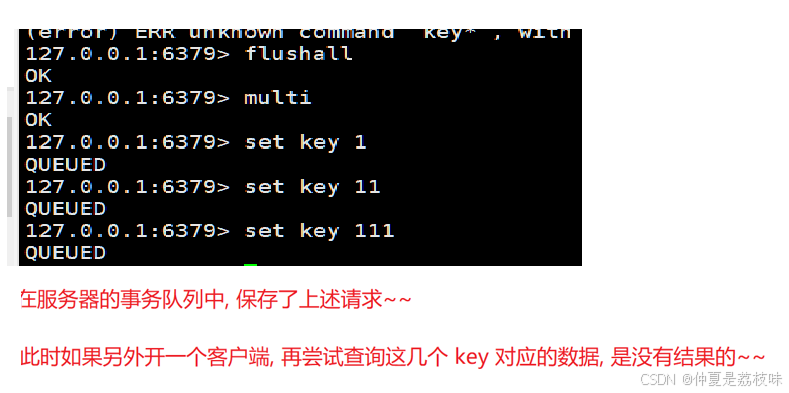
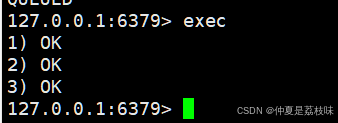
当开启事务,并且给服务器发送若个命令之后,此时服务器重启,此时的这个事务的效果其实就等同于discarc。

WATCH监控某个key是否在事务执行之前,发生了改变,刚才的场景中,就可以使用watch命令来监控这个key,看看这个key在事务的multi和exec之间,setkey之后,是否在外部被其他客户端修改了。
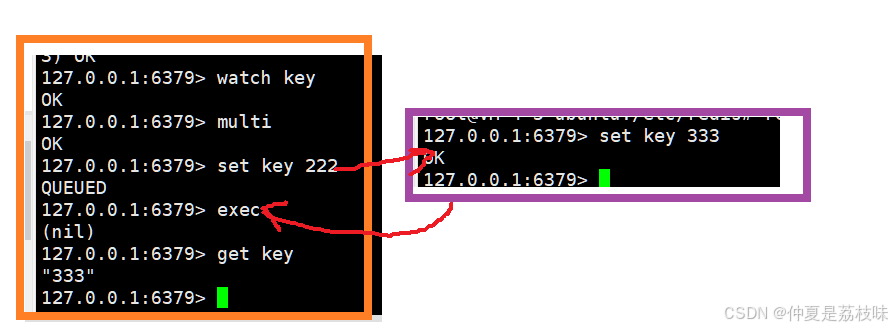
此时,exec在执行上述事务中的命令的时候,发现,key在外部有修改,(nil),于是真正执行setkey222的时候就没有真正执行。
3. watch的实现原理
watch的实现,类似于一个“乐观锁
乐观锁和悲观锁 :不是指某个具体的锁,而是指的是某一类锁的特性
乐观锁:加锁之前,就有一个心理预期,预期接下来锁冲突的概率比较低
悲观锁:加锁之前,也有一个心理预期,接下来锁冲突(两个线程针对同一个锁加锁, 一个能加锁成功,另一个就得阻塞等待)的概率比较高
Java的synchronized则是可以在悲观/乐观之间自适应
锁冲突概率高,和冲突概率低,接下来要做的工作是不一样的。
当执行watchkey的时候,就会给这个key安排一个版本号,版本号可以理解成一个“整数,每次在修改的时候,版本号都会“变大”。
原理过程如下:

4. 主从复制
分布式系统,涉及到一个非常关键的问题:单点问题。
如果某个服务器程序,只有一个节点(只搞一个物理服务器,来部署这个服务器程序)
1.可用性问题,如果这个机器挂了,意味着服务就中断了
2.性能/支持的并发量也是比较有限的。
引入分布式系统,主要也就是为了解决上述的单点问题。在分布式系统中,往往希望有多个服务器来部署redis服务,从而构成一个redis集群,此时就可以让这个集群给整个分布式系统中其他的服务,提供更稳定/更高效的数据存储功能。
在分布式系统中,希望使用多个服务器来部署redis,存在以下几种redis的部署方式~
1.主从模式
2.主从+哨兵模式
3.集群模式
4.1 主从模式
在若干个redis节点中,有的是“主”节点,有的是“从”节点”。假设有三个物理服务器(称为是三个节点)分别部署了一个redis-server进程~此时就可以把其中的一个节点,作为“主节点”,另外两个节点作为“从节点
从节点,得听主节点的(从节点上的数据要跟随主节点变化;从节点的数据要和主节点保持一致)。本来,在主节点上保存一堆数据.引入从节点之后,就是要把主节点上面的数据复制出来,放到从节点中。后续主节点这边对于数据有任何修改,都会把这样的修改给同步到从节点上(从节点,就是主节点的副本)
Redis主从模式中,从节点上的数据不允许修改,只能读取数据。
引入主从模式可以解决单点问题中存在的性能问题和可用性问题。
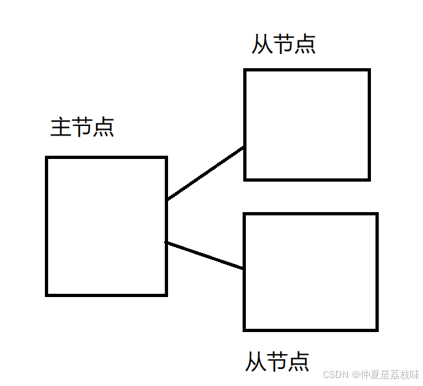
由于从节点的数据都是时刻和主节点保持一致的,因此其他的客户端从从节点这里读取数据,和从主节点这里读取数据,没有区别。
后续如果有客户端来读取数据了,就可以从上述节点中,随机挑一个节点,给这个客户端
是供读取数据的服务,由于引入了更多的计算资源,自然能够支撑的并发量也就大幅提高了。
上图如果是挂掉了某个从节点,没啥影响。此时继续从主节点或者其他从节点读取数据,得到的效果完全相同!
如果是挂掉了主节点,还是有一定影响的。从节点只能读数据。如果需要写数据,就没得写了。
主从模式,主要是针对“读操作,进行并发量&可用性的提高。而写操作的话,无论是可用性还是并发,都是非常依赖主节点。但是主节点又不能搞多个,实际业务场景中,读操作往往就是比写操作更频繁。
主从结果,是分布式系统中比较经典的一种结构。不仅仅是redis支持,像mysql等其他的常用组件也是支持的。
4.1 主从结构配置
配置redis主从结构,首先需要启动多个redis服务器,正常来说,每个redis服务器程序,应该在一个单独的主机上(才是分布式)。

从节点1修改下面配置参数:
改为



如上所示,两个节点成功配置。端口为6380和6381.

4.2 使用slaveof连接
要想配置成主从结构,就需要使用slaveof
1、在配置文件中加入slaveof {masterHos} {masterPort}随Redis启动生效 。修改了配置文件,一直持久生效的
2.在redis-server启动命令时加入--slaveof {masterHos} {masterPort}生效
3、直接使用redis命令:slaveof{masterHos} {masterPort}生效
# 加上主从结构的配置
slaveof 127.0.0.1 6379
修改完配置文件之后,重新启动服务器。
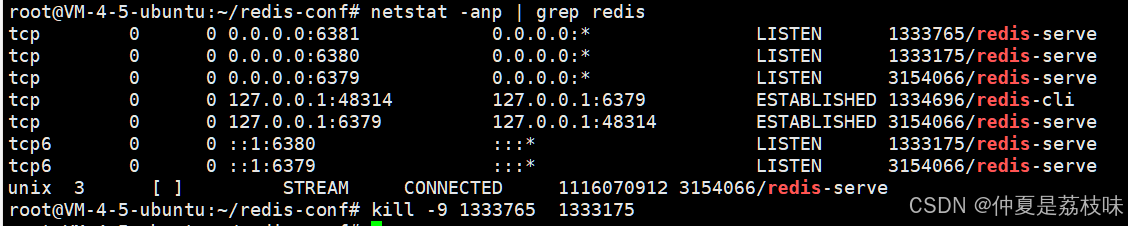

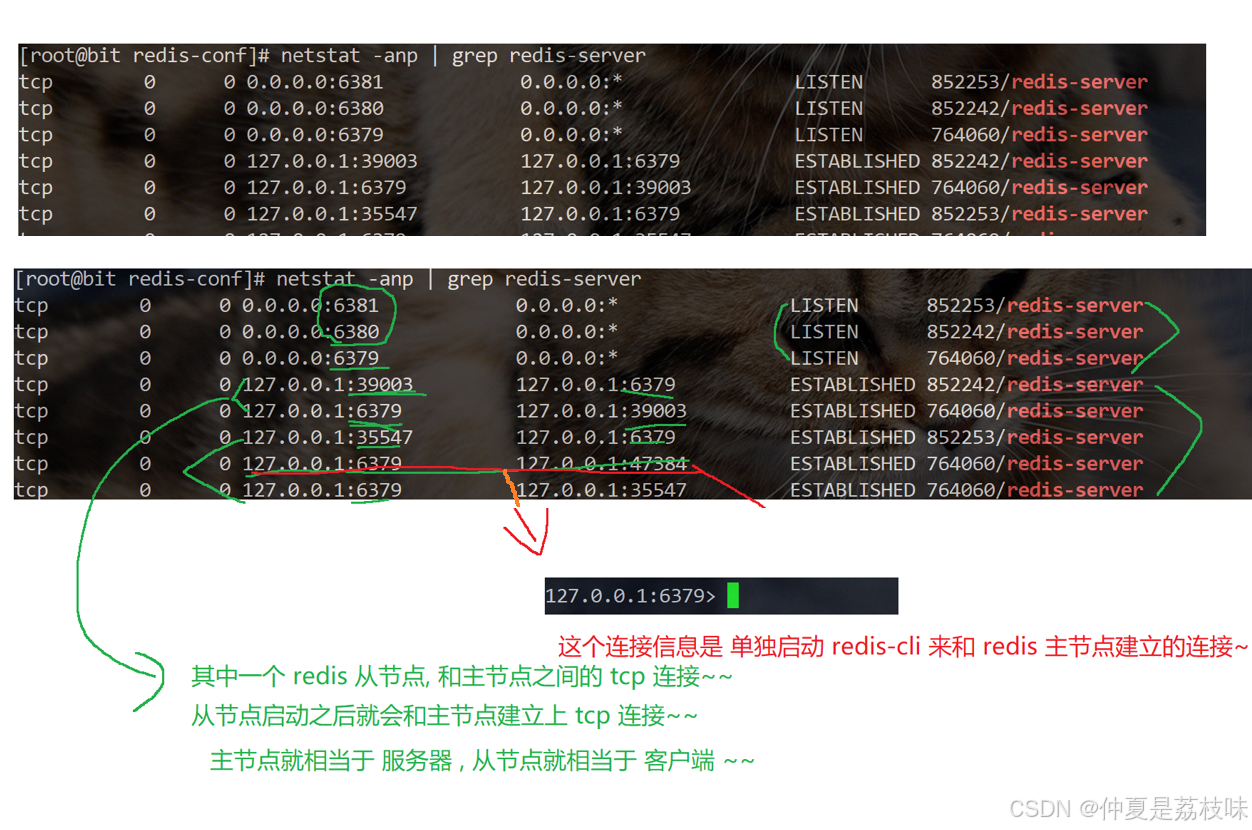
主节点这边数据产生任何的修改,从节点就能立即感知到。就是刚才看到的这些tcp连接起到的效果。

查看主从结构指令:info replication
slaveof no one (直接在redis客户端中的命令)
直接使用这个命令断开现有的主从复制关系,从节点断开主从关系,它就不再从属于其他节点了,里面已经有的数据,是不会抛弃的。但是,后续主节点如果针对数据做出修改,从节点就无法再自动同步数据了。
在当前客户端(6391)从新认主,slaveof 127.0.0.1 6380;结构如下所示:
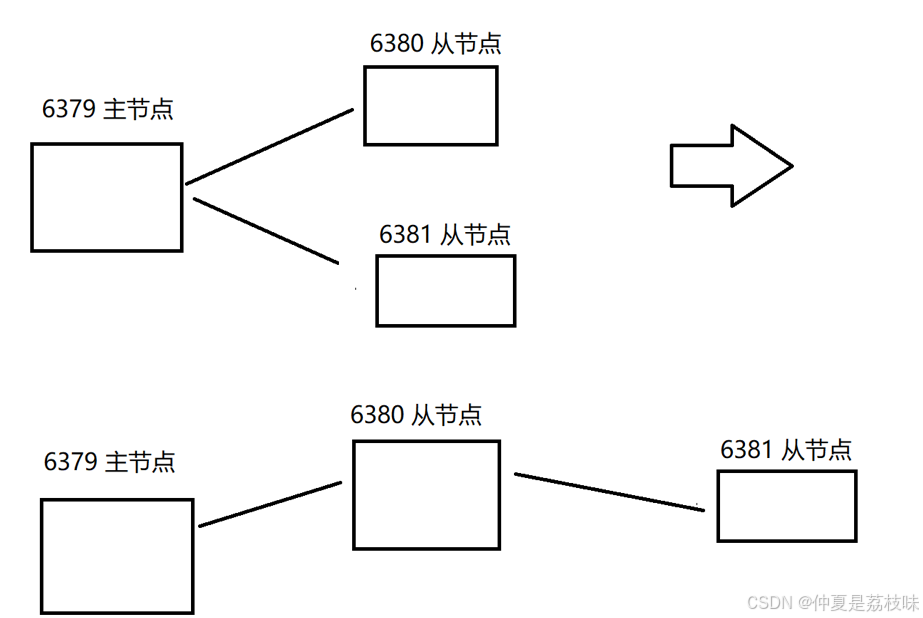
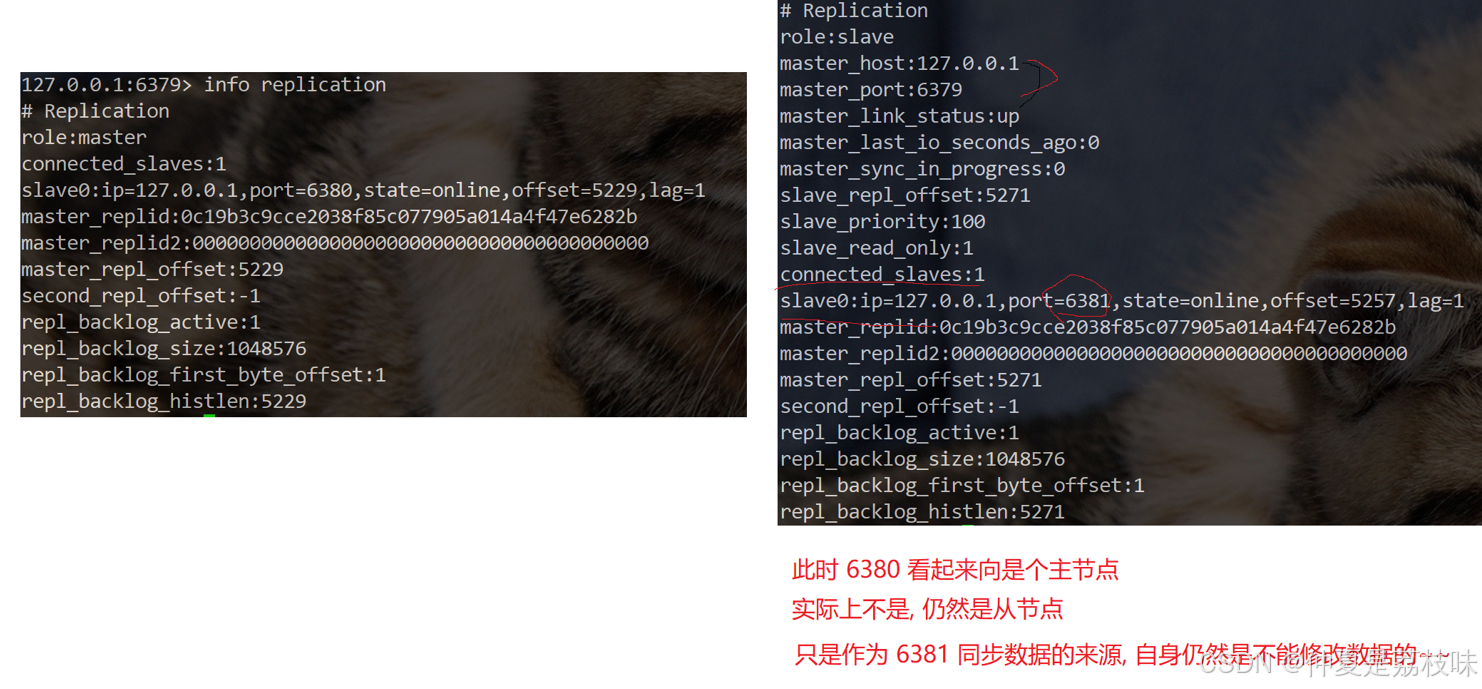
刚才通过slaveof是修改了主从结构,此处的修改是临时性的。如果重新启动了redis服务器,仍然会按照最初在配置文件中设置的内容来建立主从关系。
4.3 相关特性
安全性 :
对于数据⽐较重要的节点,主节点会通过设置requirepass参数进⾏密码验证,这时所有的客⼾ 端访问必须使⽤auth命令实⾏校验。从节点与主节点的复制连接是通过⼀个特殊标识的客⼾端来完 成,因此需要配置从节点的masterauth参数与主节点密码保持⼀致,这样从节点才可以正确地连接到 主节点并发起复制流程。
只读 :
默认情况下,从节点使⽤slave-read-only=yes配置为只读模式。由于复制只能从主节点到从节 点,对于从节点的任何修改主节点都⽆法感知,修改从节点会造成主从数据不⼀致。所以建议线上不 要修改从节点的只读模式。
传输延迟 :
主从节点⼀般部署在不同机器上,复制时的⽹络延迟就成为需要考虑的问题,Redis为我们提供 了repl-disable-tcp-nodelay 参数⽤于控制是否关闭TCP_NODELAY,默认为no,即开启tcp nodelay 功能,说明如下: • 当关闭时,主节点产⽣的命令数据⽆论⼤⼩都会及时地发送给从节点,这样主从之间延迟会变⼩, 但增加了⽹络带宽的消耗。适⽤于主从之间的⽹络环境良好的场景,如同机房部署。 • 当开启时,主节点会合并较⼩的TCP数据包从⽽节省带宽。默认发送时间间隔取决于Linux的内 核,⼀般默认为40毫秒。这种配置节省了带宽但增⼤主从之间的延迟。适⽤于主从⽹络环境复杂 的场景,如跨机房部署。

4.4 拓扑结构
Redis 的复制拓扑结构可以⽀持单层或多层复制关系,根据拓扑复杂性可以分为以下三种:⼀主⼀ 从、⼀主多从、树状主从结构。
⼀主⼀从结构
⼀主⼀从结构是最简单的复制拓扑结构,⽤于主节点出现宕机时从节点提供故障转移⽀持,如图 所⽰。当应⽤写命令并发量较⾼且需要持久化时,可以只在从节点上开启AOF,这样既可以保证数据 安全性同时也避免了持久化对主节点的性能⼲扰。但需要注意的是,当主节点关闭持久化功能时,如果主节点宕机要避免⾃动重启操作。
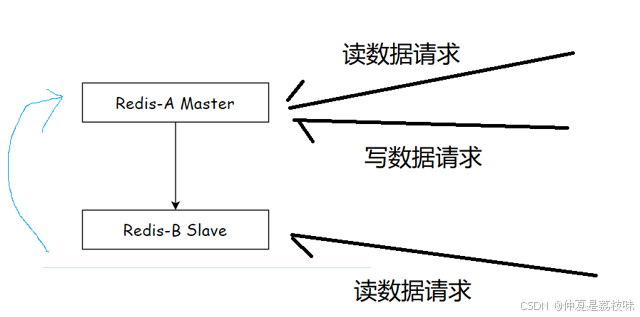
如果写数据请求太多,此时也是会给主节点造成一些压力。可以通过关闭主节点的AOF,只在从节点上开启AOF。但是,这种设定方式,主节点一旦挂了,不能让他自动重启...(如果自动重启此时没有AOF文件,就会丢失数据,进一步的主从同步,会把从节点的数据也给删了)。
改进办法,当主节点挂了之后,就需要让主节点从从节点这里获取到AOF的文件,再启动。
实际开发中,读请求,远远超过写请求。所以使用一主多从的结果。
⼀主多从结构
⼀主多从结构(星形结构)使得应⽤端可以利⽤多个从节点实现读写分离,如图5-3所⽰。对于 读⽐重较⼤的场景,可以把读命令负载均衡到不同的从节点上来分担压⼒。同时⼀些耗时的读命令可 以指定⼀台专⻔的从节点执⾏,避免破坏整体的稳定性。对于写并发量较⾼的场景,多个从节点会导 致主节点写命令的多次发送从⽽加重主节点的负载。
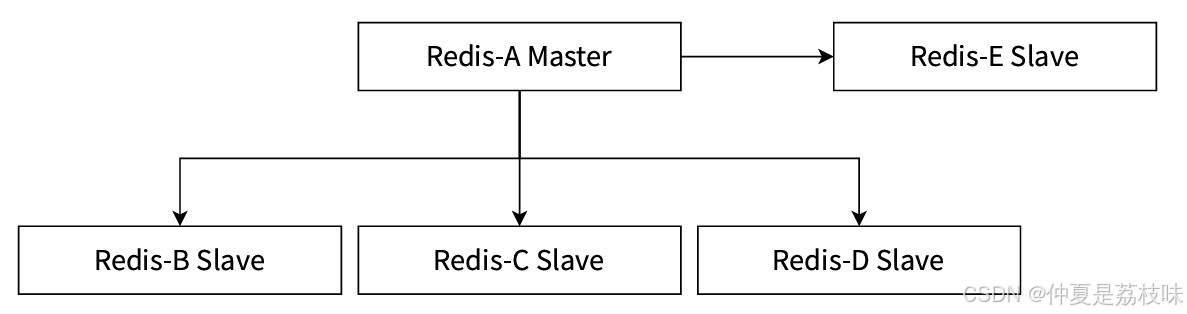
主节点上的数据发生改变,就会把改变的数据同时同步给所有的从节点。随着从节点个数的增加,同步一条数据,就需要传输多次。
树形主从结构
树形主从结构(分层结构)使得从节点不但可以复制主节点数据,同时可以作为其他从节点的主 节点继续向下层复制。通过引⼊复制中间层,可以有效降低住系欸按负载和需要传送给从节点的数据 量,如图6-4所⽰。数据写⼊节点A之后会同步给B和C节点,B节点进⼀步把数据同步给D和E节 点。当主节点需要挂载等多个从节点时为了避免对主节点的性能⼲扰,可以采⽤这种拓扑结构。(数据层层递进)
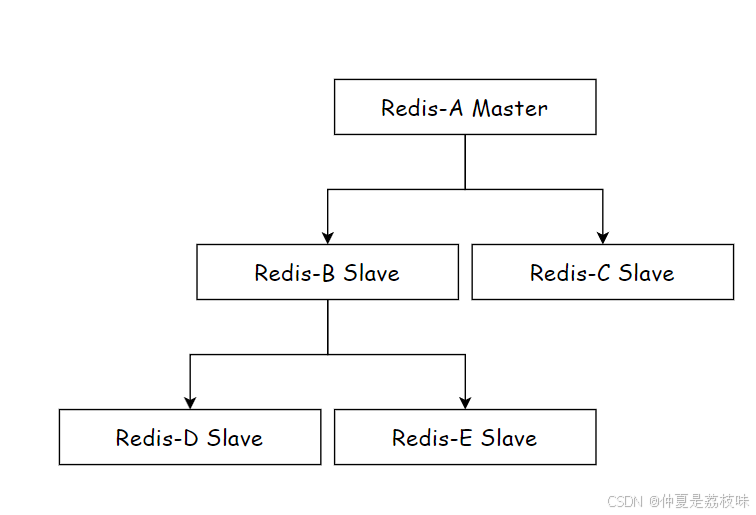
主节点就不需要那么高的网卡带宽了,一旦数据进行修改了,同步的延时是比刚才更长的~
4.5 主从复制执行流程
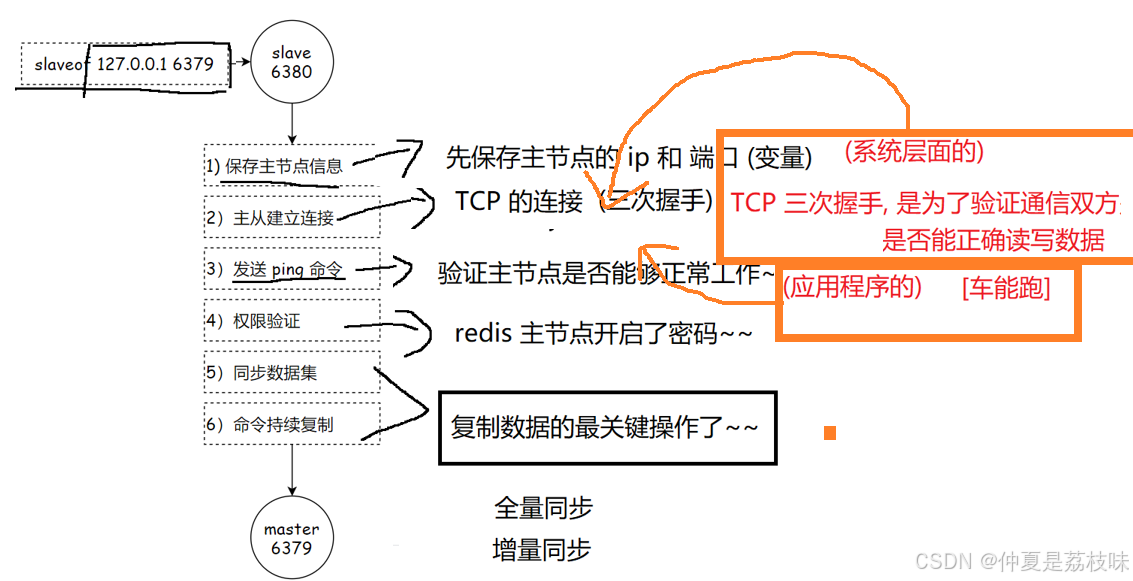
4.6 数据同步
redis提供了psync命令,完成数据同步的过程,psync不需要咱们手动执行,redis服务器会在建立好主从同步关系之后,自动执行psync.
从节点负责执行psync.从节点从主节点这边拉取数据。
PSYNC的语法格式 : PSYNC replicationid offset
replicationid是复制id,是主节点生成的,主节点启动的时候就会生成。 (即使是同一个主节点,每次重启生成的replicationid都是不同的),从节点普升成主节点的时候,也会生成。
从节点和主节点建立了复制关系,就会从主节点这边获取到replicationid。info replicationml可以获取到当前replicationid的值。
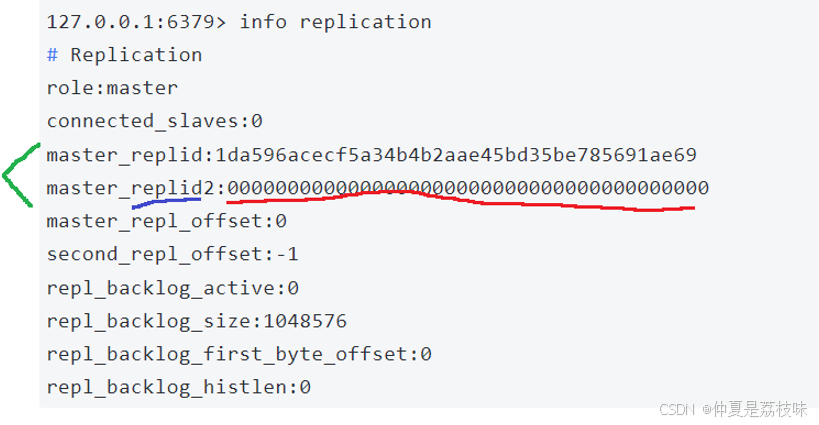
一般情况下replid2这个是用不上的,其使用场景如下:
有一个主节点A(生成replid),还有一个从节点B(获取到A的replic),如果A和B通信过程中出现了一些网络抖动,B可能就会认为A挂了,B就会自己成为主节点(给自己生成一个replid)
此时,B也会记得之前旧的replid,就是生成replid2记录旧的replid,等后续网络稳定了,B还可以根据replid2重新回到A的怀抱( 要手动干预哨兵机制,可以自动完成这个过程)
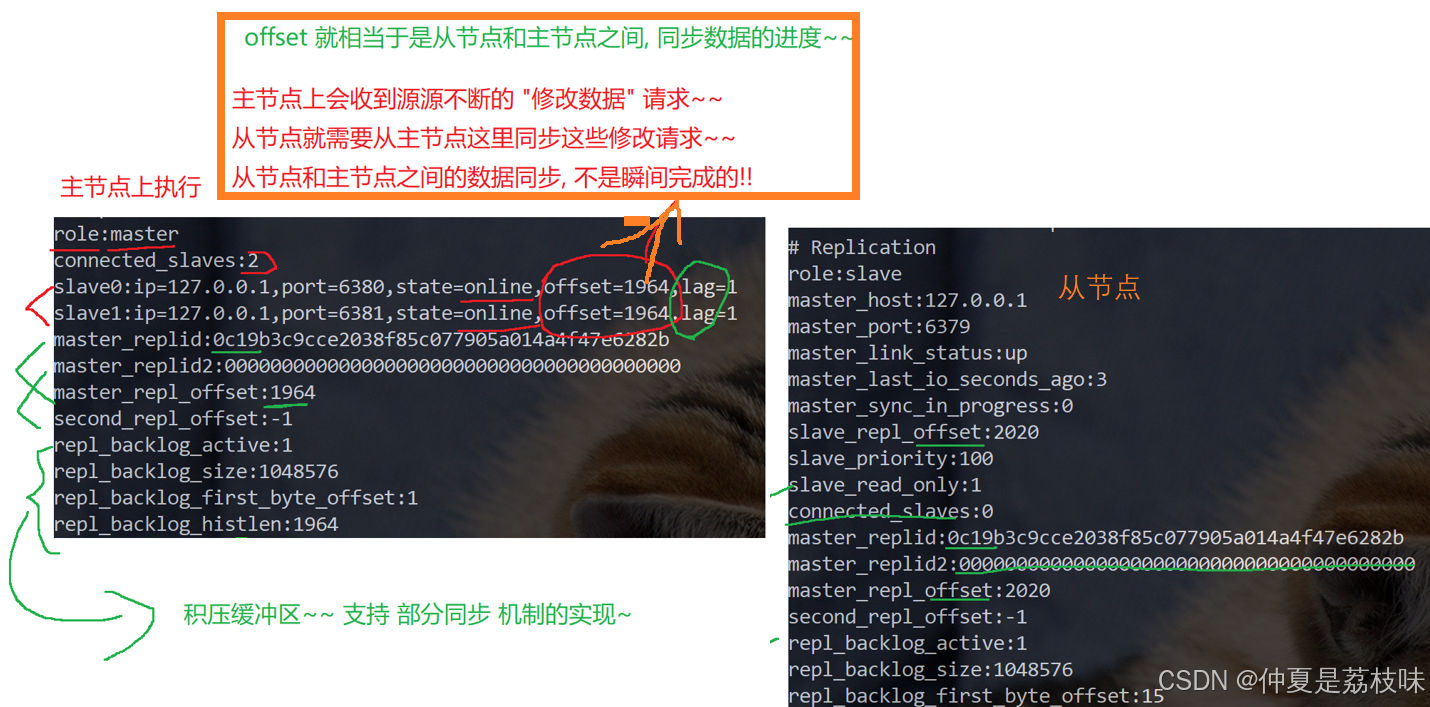
offset偏移量:
主节点和从节点上都会维护偏移量(整数),主节点的偏移量,主节点上会收到很多的修改操作的命令,每个命令都要占据几个字节,主节点会把这些修改命令,每个命令的字节数进行累加
从节点的偏移量,就描述了现在从节点这里数据同步到哪里了, 如果从节点这边的偏移量和主节点的偏移量一样了,说明主从数据同步进度一致。从节点(slave) 每秒钟上报自身的复制偏移量给主节点。
replicationid(主要理解为描述的数据来源)和offset共同描述了一个 数据集合,如果发现两个机器,replicationid一样,offset也一样,就可以认为这两个redis机器上存储的数据就是完全一样的。
4.7 psync运行流程
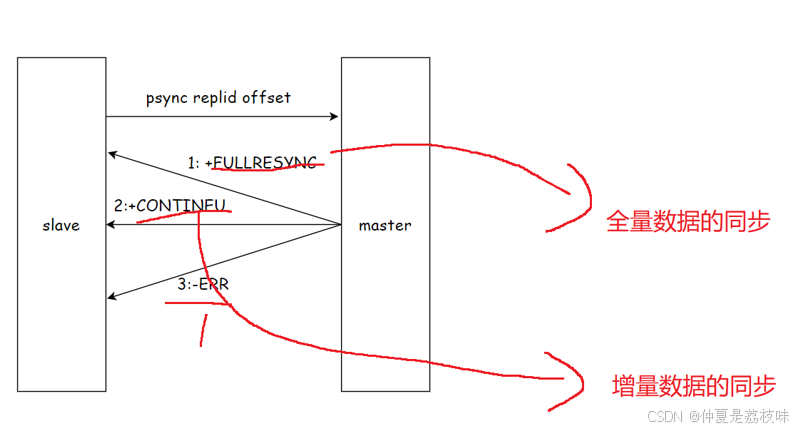
1)从节点发送psync命令给主节点,replid和offset的默认值分别是?和-1.
2)主节点根据psync参数和⾃⾝数据情况决定响应结果:
• 如果回复+FULLRESYNCreplidoffset,则从节点需要进⾏全量复制流程。
• 如果回复+CONTINEU,从节点进⾏部分复制流程。
• 如果回复-ERR,说明Redis主节点版本过低,不⽀持psync命令。从节点可以使⽤sync命令进⾏ 全量复制。
• psync⼀般不需要⼿动执⾏.Redis会在主从复制模式下⾃动调⽤执⾏.
• sync会阻塞redisserver处理其他请求.psync则不会。
啥时候进行部分复制
从节点之前已经从主节点上复制过数据了.因为网络抖动或者从节点重启了。 从节点需要重新从主节点这边同步数据,此时看看能不能只同步一小部分(大部分数据都是一致的)
全量复制
全量复制是Redis最早⽀持的复制⽅式,也是主从第⼀次建⽴复制时必须经历的阶段。全量复制的运 ⾏流程如图所⽰。
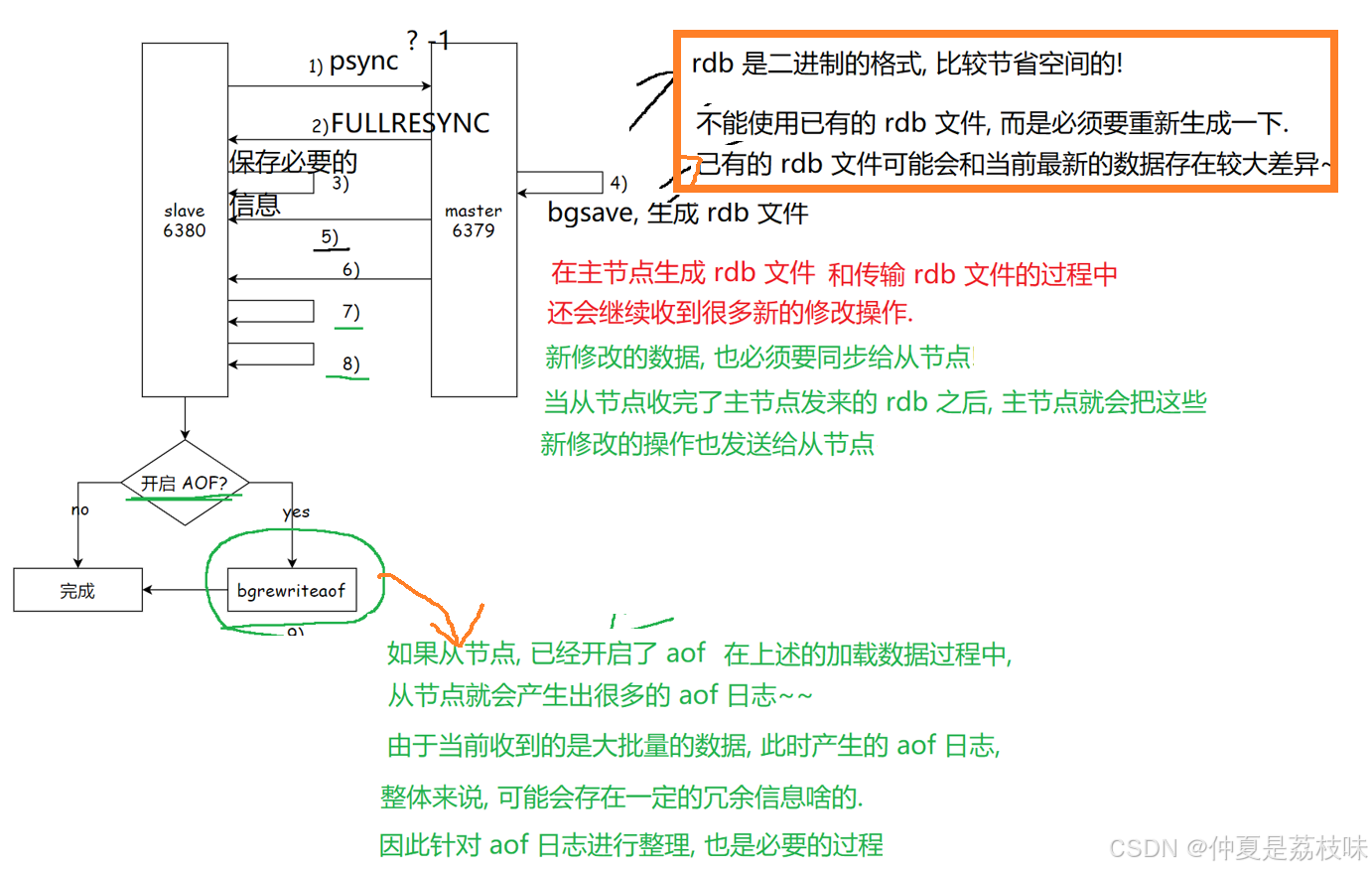
1)从节点发送psync命令给主节点进⾏数据同步,由于是第⼀次进⾏复制,从节点没有主节点的运 ⾏ID和复制偏移量,所以发送psync?-1。
2)主节点根据命令,解析出要进⾏全量复制,回复+FULLRESYNC响应。
3)从节点接收主节点的运⾏信息进⾏保存。
4)主节点执⾏bgsave进⾏RDB⽂件的持久化。
5)从节点发送RDB⽂件给从节点,从节点保存RDB数据到本地硬盘。
6)主节点将从⽣成RDB到接收完成期间执⾏的写命令,写⼊缓冲区中,等从节点保存完RDB⽂件 后,主节点再将缓冲区内的数据补发给从节点,补发的数据仍然按照rdb的⼆进制格式追加写⼊到收 到的rdb⽂件中.保持主从⼀致性。
7)从节点清空⾃⾝原有旧数据。
8)从节点加载RDB⽂件得到与主节点⼀致的数据。
9)如果从节点加载RDB完成之后,并且开启了AOF持久化功能,它会进⾏bgrewrite操作,得到最 近的AOF⽂件。
主节点,进行全量复制的时候,也支持“无硬盘模式(diskless)
主节点生成的rdb的二进制数据,不是直接保存到文件中了,而是直接进行网络传输了(省下了一系列读硬盘和写硬盘的操作)
从节点之前,也是先把收到的rdb数据写入到硬盘中,然后再加载。也可以省略这个过程,直接把收到的数据进行加载了。
即使引入了无硬盘模式,仍然整个操作是比较重量,比较耗时的.网络传输是没法省的(大规模数据(全量复制)),相比于网络传输来说,读写硬盘是小问题。
replication id / replid:
一个redis服务器上,replication id和run id是都存在的。两个不同的id,看起来非常像。

run id主要是用在支撑实现redis哨兵这个功能。
replication.c 这个代码是进行主从复制的逻辑,replid主要就是在主从复制中起到作用的。
4.8 部分复制
一般适用于出现网络抖动,主节点这边最近修改的数据可能就无法及时同步,更严重的,从节点已经感知不到主节点了。
网络抖动,一般都是“暂时的”,过一会就恢复了,此时就可以让从节点和主节点重新建立联系
当从节点和主节点重新建立连接之后,就需要进行数据的同步,psync带有具体的replid和offset值,主节点就要根据psync的参数进行判定,判定当前这次是按照全量复制合适还是部分复制合适。
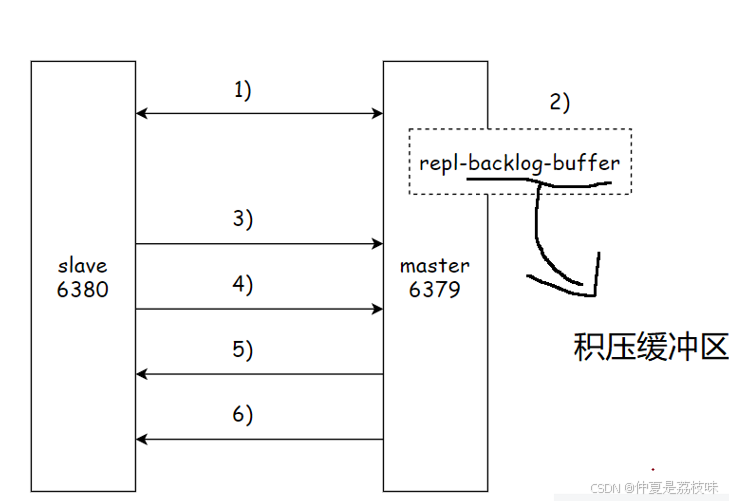

1)当主从节点之间出现⽹络中断时,如果超过repl-timeout时间,主节点会认为从节点故障并终端复制连接。
2)主从连接中断期间主节点依然响应命令,但这些复制命令都因⽹络中断⽆法及时发送给从节点,所 以暂时将这些命令滞留在复制积压缓冲区中。
3)当主从节点⽹络恢复后,从节点再次连上主节点。
4)从节点将之前保存的replicationId和复制偏移量作为psync的参数发送给主节点,请求进⾏部分 复制。
5)主节点接到psync请求后,进⾏必要的验证。随后根据offset去复制积压缓冲区查找合适的数据, 并响应+CONTINUE给从节点。
6)主节点将需要从节点同步的数据发送给从节点,最终完成⼀致性。
4.9 实时复制
实时复制:从节点已经和主节点,同步好了数据了(从节点这一时刻已经和主节点数据一致了)。但是之后,主节点这边会源源不断的收到新的修改数据的请求,主节点上的数据就会随之改变,也需要能够同步给从节点。
从节点和主节点之间会建立TCP的长连接。然后主节点把自己收到的修改数据的请求,通过上述连接,发给从节点 。从节点再根据这些修改请求,修改内存中的数据。
这个过程也是需要时间的,正常来说这个延时是比较短的,但是如果是多级从节点的树形结构,如果这里从节点的级别很多(有很多层),延时也就会上升。
在进行实时复制的时候,需要保证连接处于可用状态,使用心跳包机制
主节点:默认每隔10s给从节点发送一个ping命令,从节点收到就返回pong。(默认是60s)
从节点:默认每隔1s就给主节点发起一个特定的请求,就会上报当前从节点复制数据的进度(offset)。上面的秒数都是可以根据需要自己配置的。
从节点和主节点之间断开连接,有两种情况
1.从节点主动和主节点断开连接
slaveof no one,这个时候,从节点就能够晋升成主节点。
2.主节点挂了,这个时候从节点不会升成主节点的,必须通过人工干预的方式,恢复主节点。
ps:仅用来自己复习时的整体的笔记。