Langchain应用-rag优化
概述
RAG,Retrieval-Augmented Generation,中文名检索增强生成,是AI领域非常重要的一种技术方案。其核心作用是给LLM大模型外挂专门的知识库,指导大模型生成更准确的输出。
应用场景
-
通用问答系统:RAG可以根据检索到的相关信息生成准确的答案,帮助员工更快地获取所需信息,提高决策效率,比如搭建企业内部知识库、公司规章制度查询、新员工入职培训、公司合同资料解读和查询等。
-
智能客服系统:RAG可以结合产品资料知识库、聊天记录、用户反馈等数据,自动为用户提供更精准的回答,已经有非常多的初创公司选择用RAG技术构建新一代的智能客服系统。
-
智能数据分析:RAG可以结合外部数据源,如数据库、API、文件等,为用户提供更便捷的数据分析服务。传统企业的数据分析主要靠BI分析师,每天都需要写大量的SQL语句进行查询,而在RAG的支持下,企业的每个员工都能以自然对话的方式获取数据。比如门店店长直接用语音对话,“请帮我找出上周销量排名前10,但本周销量下滑最快的品类”,系统即可直接给出答复。
-
自动化文档处理:企业还可以利用RAG和LLM大模型自动化文档处理流程,例如自动生成合同、撰写周报、总结会议纪要等,节省时间和人力成本。
問題
第一,存在幻觉问题。LLM大模型的底层原理是基于数学概率进行预测,其模型输出本质上是一种概率预测的结果。所以LLM大模型有时候会出现胡言乱语,或者生成一些似是而非的答案,在大模型并不擅长的领域,幻觉问题会更加严重。使用者要区分幻觉问题是非常困难的,除非使用者本身就具备了相应领域的知识,但这里就会存在矛盾,已经具备相关知识的人是不会采用大模型生成的答案的。
第二,缺乏对生成结果的可解释性。LLM大模型本身就是一个黑盒,这个模型使用了什么数据进行训练,对齐策略是怎么样的,使用者都无从得知。所以对于大模型生成的答案,更加难以追踪溯源。
第三,缺乏对专业领域知识的理解。LLM大模型知识的获取严重依赖训练数据集的广度,但目前市面上大多数的数据训练集都来源于网络公开数据,对于企业内部数据、特定领域或高度专业化的知识,大模型无从学习。因此大模型的表现更像是一个及格的通才,但是在一些专业场景,比如企业内部的业务流,一个及格的通才是无法使用的,需要利用企业的专属数据进行喂养和训练,打造为优秀的专才。
第四,数据的安全性。这是对上面第三点的延伸,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。因此,完全依赖通用大模型自身能力的应用方案,在企业场景下是行不通的。
第五,知识的时效性不足。大模型的内在结构会被固化在其被训练完成的那一刻,但是当你询问大模型一些最新发生的事情,则难以给出答案。
基本实施
rag的基本实施可以分为下面几步
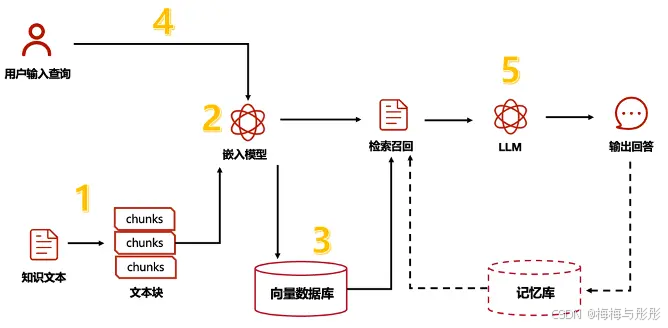
文档切片/分块
在RAG系统中,文档需要分割成多个文本块再进行向量嵌入。在不考虑大模型输入长度限制和成本问题情况下,其目的是在保持语义上的连贯性的同时,尽可能减少嵌入内容中的噪声,从而更有效地找到与用户查询最相关的文档部分。
如果分块太大,可能包含太多不相关的信息,从而降低了检索的准确性。相反,分块太小可能会丢失必要的上下文信息,导致生成的回应缺乏连贯性或深度。
第一阶段可先按固定字符拆分知识,并通过设置冗余字符来降低句子截断的问题,使一个完整的句子要么在上文,要么在下文。这种方式能尽量避免在句子中间断开的问题,且实现成本最低,非常适合在业务起步阶段。
嵌入模型
嵌入模型的核心任务是将文本转换为向量形式,这样我们就能通过简单的计算向量之间的差异性,来识别语义上相似的句子。
存入向量数据库
将文档切片和嵌入模型的结果存储进入向量数据库。向量数据库的主要优势在于,它能够根据数据的向量接近度或相似度,快速、精确地定位和检索数据,实现很多传统数据库无法实现的功能,比如根据旋律和节奏搜索出特定的歌曲、在电影中搜索浪漫的片段、在文档中找出意图相近的段落等等。
数据召回
可以先使用最简单的向量召回方式,找到在语义向量维度最近似的答案进行召回。这里需要注意的是,要找一个和自己业务比较契合的embedding模型和向量数据库。
召回结果的数量是另一个关键因素,更多的结果可以提供丰富的预料,有助于系统更好地理解问题的上下文和隐含细节。但是结果数量过多可能导致信息过载,降低回答准确性并增加系统的时间和资源成本。第一阶段我们可以先把召回数量设置为10。
内容生成
因为简单的数据召回环节只有基本向量召回,可以将召唤的数据直接交给大模型分析生成答案。
优化
文档切片/分块优化
使用模型动态分块
如果分块太大,可能包含太多不相关的信息,从而降低了检索的准确性。相反,分块太小可能会丢失必要的上下文信息,导致生成的回应缺乏连贯性或深度。
可以根据文本特征人工调节分片大小,也可针对需要分块的数据训练专门的文档切分模型。
如基于NLTK的文本切块NLTK提供了sent_tokenize方法,可以自动进行文本切分。该方法源自论文"Unsupervised Multilingual Sentence Boundary Detection",其基本思路是使用一个无监督的算法来为缩写词、搭配词和句子开头的词建立一个模型,然后使用该模型来找到句子边界。这种方法已被证明对许多欧洲语言都很有效。目前,NLTK官方并没有提供中文分句模型的预训练权重,需要自己训练,但提供了训练接口。大模型应用开发框架LangChain也集成了NLTK进行文本切分的方法,代码如下所示
from langchain.text_splitter import NLTKTextSplitter
text_splitter = NLTKTextSplitter()
text = "..."
docs = text_splitter.split_text(text)索引降噪
是根据业务特点,去除索引数据中的无效成分,突出其核心知识,从而降低噪音的干扰,保障核心知识的比重。比如原文档内容是“How can I download source code from github.com”,其核心内容是“download source code、github”,其他噪音可以忽略。
多级索引
是指创建两个索引,一个由文档摘要组成,另一个由文档块组成,并分两步搜索,首先通过摘要过滤掉相关文档,然后只在这个相关组内进行搜索。这种多重索引策略使RAG系统能够根据查询的性质和上下文,选择最合适的索引进行数据检索,从而提升检索质量和响应速度。但为了引入多重索引技术,我们还需配套加入多级路由机制,比如对于查询“最新发表的Rag论文推荐”,RAG系统首先将其路由至论文专题的索引,然后根据时间筛选最新的Rag相关论文。
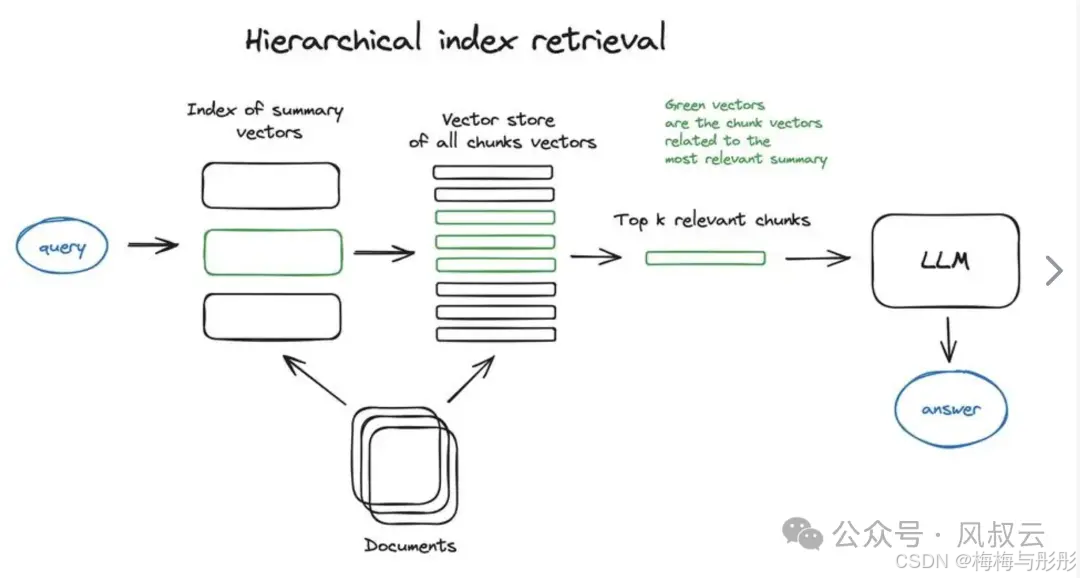
用户查询优化
Multi-Query与 Fusion
首先对用户的原始query进行扩充,即使用 LLM 模型对用户的初始查询,进行改写生成多个查询;然后对每个生成的查询进行基于向量的搜索,形成多路搜索召回;接着应用倒数排名融合算法,根据文档在多个查询中的相关性重新排列文档,生成最终输出。
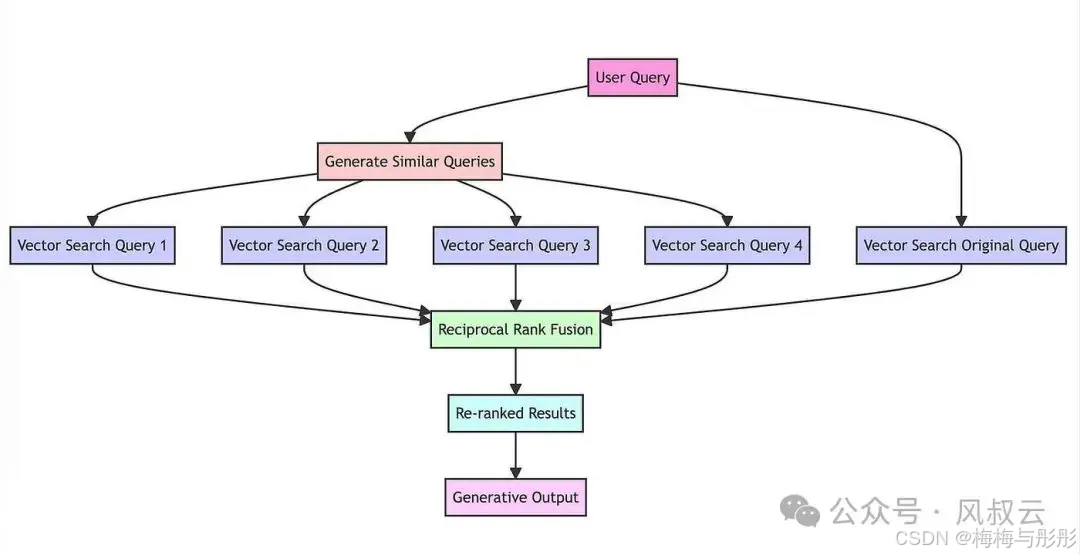 用户问题可能较为简单与非流程化,可在提示词中设置规则将用户的原始问题扩展为指定的多维度问题
用户问题可能较为简单与非流程化,可在提示词中设置规则将用户的原始问题扩展为指定的多维度问题
prompt = ChatPromptTemplate.from_template(
"""
你是一名智能助手。
您的任务是根据提供的问题,以不同的措辞和不同的视角生成4个问题,以便从向量数据库中检索相关文档。
通过为用户问题生成多个视角,您的目标是帮助用户克服基于距离的相似性搜索的一些限制。
以下是根据原始问题生成的替代问题,每个问题之间请用换行分隔。
原始问题:{question}
"""
)
generate_queries = (
{"question": RunnablePassthrough()}
| prompt
| glm4_air_model
| StrOutputParser()
| (lambda x: x.split("\n"))
)
res = generate_queries.invoke("工作满意度指数有哪些?")
print(res)
原始问题被我们拆分成了多个,因此召回的文件将分成多组,每组对应一个子问题
def get_context_union(docs: List[List]):
# 解释
# test_doc = dumps(docs[0][0])
# test_doc_after = loads(test_doc)
# print(test_doc_after.page_content)
# pass
all_docs = [dumps(d) for doc in docs for d in doc]
unique_docs = list(set(all_docs))
docs_content = [loads(doc).page_content for doc in unique_docs]
return docs_content
retrieval_chain = (
{'question': RunnablePassthrough()}
| generate_queries
| retriever.map()
| get_context_union
)
related_docs = retrieval_chain.invoke("工作满意度指数有哪些?")
print(related_docs)可使用倒数排名融合(Reciprocal Rank
Fusion,RRF)来对每个检索到的文档进行排名,然后再将它们作为上下文来回答我们的原始问
题。
# fusion
def rrf(results: List[List], k=60):
# 初始化一个字典,用于存储每个唯一文档的融合得分
fused_scores = {}
# 遍历每个排序列表的文档
for docs in results:
# 遍历列表中的每个文档及其排名(列表中的位置)
for rank, doc in enumerate(docs):
# 将文档转换为字符串格式以用作键(假设文档可以序列化为JSON)
doc_str = dumps(doc)
# 如果文档尚未在融合得分字典中,则添加它,初始得分为0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# 获取文档当前的得分,如果有的话
previous_score = fused_scores[doc_str]
# 使用RRF公式更新文档的得分:1 / (排名 + k)
fused_scores[doc_str] += 1 / (rank + k)
# 根据文档的融合得分降序排序,以获得最终的重新排序结果
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# 返回重新排序的结果,作为包含文档及其融合得分的元组列表
return reranked_results
fusion_retrieval_chain = (
{'question': RunnablePassthrough()}
| generate_queries
| retriever.map()
| rrf
)
res = fusion_retrieval_chain.invoke("工作满意度指数有哪些?")
print(res)
Least-to-most promting
该查询扩展纬度的思想也是将原始问题扩展为多个子问题,但将依次召回并解答拆分后的子问题。
且每次问题的分析将参考上一个问题的 提问+答案,适合需要拆分且需要逐步深入的问题。
decompostion_prompt = ChatPromptTemplate.from_template(
"""
你是一名能够将复杂问题分解为更简单部分的助手。\n
你的目标是将给定的问题分解为多个子问题,这些子问题可以单独解答,最终解答主问题。\n
请提供这些子问题,并用换行符分隔。\n
原始问题:{question}\n
修改后的问题 (3个):
"""
)
query_generation_chain = (
{"question": RunnablePassthrough()}
| decompostion_prompt
| glm4_air_model
| StrOutputParser()
| (lambda x: x.split("\n"))
)
questions = query_generation_chain.invoke("工作满意度指数有哪些?")
print(questions)
from operator import itemgetter
# Create the final prompt template to answer the question with provided context and background Q&A pairs
template = """这是你需要回答的问题:
\n --- \n {question} \n --- \n
以下是任何可用的背景问题+答案对:
\n --- \n {q_a_pairs} \n --- \n
这是与问题相关的额外上下文:
\n --- \n {context} \n --- \n
使用上述上下文以及任何背景问题+答案对来回答问题: \n {question}
"""
least_to_most_prompt = ChatPromptTemplate.from_template(template)
llm = glm4_air_model
least_to_most_chain = (
{'context': itemgetter('question') | retriever,
'q_a_pairs': itemgetter('q_a_pairs'),
'question': itemgetter('question'),
}
| least_to_most_prompt
| llm
| StrOutputParser()
)
q_a_pairs = ""
for q in questions:
answer = least_to_most_chain.invoke({"question": q, "q_a_pairs": q_a_pairs})
q_a_pairs += f"Question: {q}\n\nAnswer: {answer}\n\n"
res = least_to_most_chain.invoke({"question": "工作满意度指数有哪些?", "q_a_pairs": q_a_pairs})HYDE
全称是Hypothetical Document Embeddings,用LLM生成一个“假设”答案,将其和问题一起进行检索。HyDE的核心思想是接收用户提问后,先让LLM在没有外部知识的情况下生成一个假设性的回复。然后,将这个假设性回复和原始查询一起用于向量检索。假设回复可能包含虚假信息,但蕴含着LLM认为相关的信息和文档模式,有助于在知识库中寻找类似的文档。
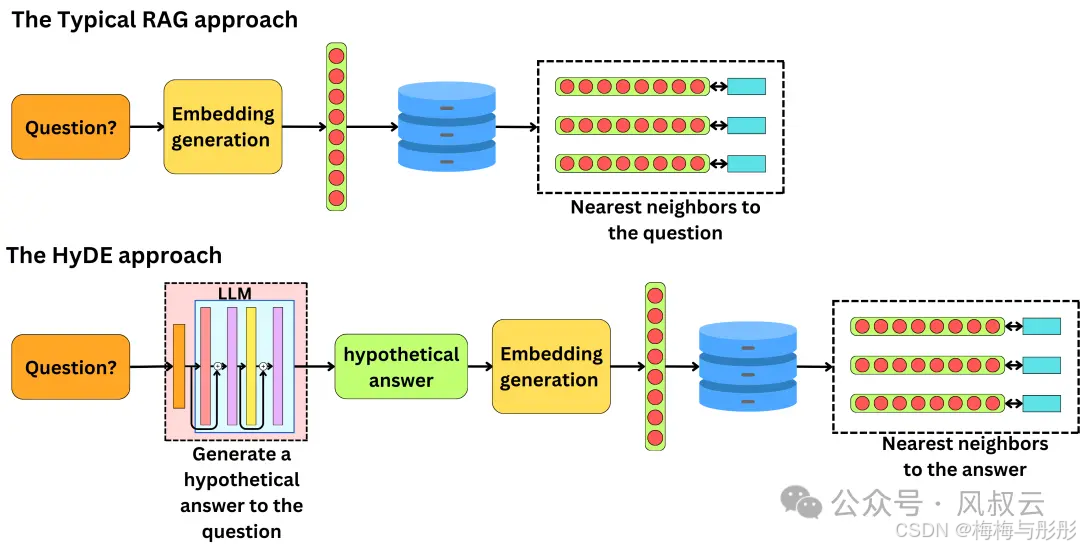
数据召回优化
分词召回
一种有效的稀疏搜索算法是最佳匹配25(BM25),它基于统计输入短语中的单词频率,频繁出现的单词得分较低,而稀有的词被视为关键词,得分会较高。我们可以结合稀疏和稠密搜索得出最终结果。
from langchain.retrievers import BM25Retriever, EnsembleRetriever
bm25_retriever = BM25Retriever.from_documents(
documents=splits
) #生成bm25检索器
bm25_retriever.k = 4 #BM25返回top4文档
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
retriever = vectordb.as_retriever(search_kwargs={"k": 4})#embedding的密集检索
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, retriever], weights=[0.5, 0.5]
)#两个检索器各自的权重都是0.5,大家均分
docs = ensemble_retriever.invoke("What is baichuan2 ?")多路召回
查考前文 Multi-Query 与Fusion章节中的多路问题以及问题融合的思路。
我们可以构建多维度的文档召回,召回后按照倒排名融合等方法将多维度召回的信息汇总融合

语义路由与逻辑路由
路由的思想是,先对用户的输入进行分析,识别其需要检索的类别,然后再根据识别到的问题到对应的向量数据库中召回。
如 对 烹饪菜单的召回,我们可以将菜分为川菜, 粤菜等等。当用户输入想烹饪的信息时先识别菜系再到对应类别的向量数据库中进行文档召回。
内容生成优化
文档合并去重
多路召回可能都会召回同一个结果,针对这部分数据要去重,否则对大模型输入的token数是一种浪费;其次,去重后的文档可以根据数据切分的血缘关系,做文档的合并。
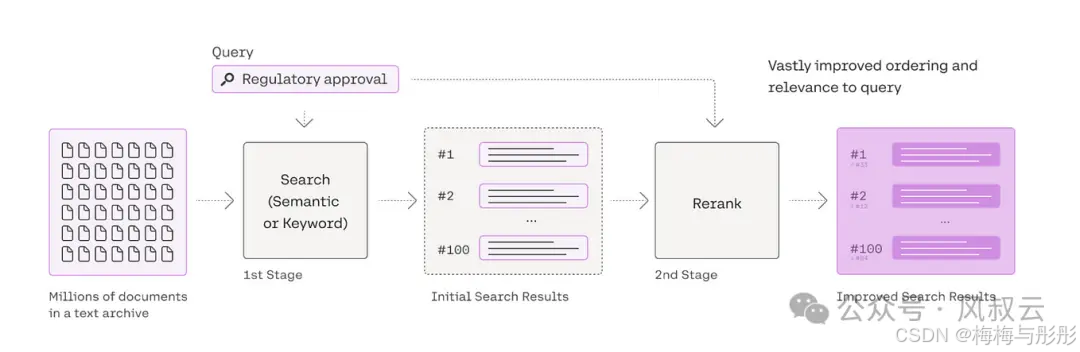
重排模型
重排模型通过对初始检索结果进行更深入的相关性评估和排序,确保最终展示给用户的结果更加符合其查询意图。这一过程通常由深度学习模型实现,如Cohere模型。这些模型会考虑更多的特征,如查询意图、词汇的多重语义、用户的历史行为和上下文信息等。
Self-rag
self-rag通过检索评分(令牌)和反思评分(令牌)来提高质量,主要分为三个步骤:检索、生成和批评。Self-RAG首先用检索评分来评估用户提问是否需要检索,如果需要检索,LLM将调用外部检索模块查找相关文档。接着,LLM分别为每个检索到的知识块生成答案,然后为每个答案生成反思评分来评估检索到的文档是否相关,最后将评分高的文档当作最终结果一并交给LLM。
参考文档
谈谈Rag的产生原因、基本原理与实施路径 – 人人都是产品经理
【RAG实战】核心技术与优化-CSDN博客
https://www.cnblogs.com/theseventhson/p/18261594