AGI大模型(1):大模型简介
1 什么是AI(Artificial Intelligence)?

⼈⼯智能发展史:1900~2023:https://zhuanlan.zhihu.com/p/703419161
2 AI1.0到2.0的变迁
2.1 AI1.0
定义:通常指的是⼈⼯智能的早期阶段,这个阶段的⼈⼯智能主要是基于规则的系统和早期的机器学习算法。
代表产品:
- 图像识别系统:基于CNN的图像分类和物体检测应⽤,如早期的⾯部识别技术。
- 语⾳识别助⼿:如早期版本的苹果Siri,利⽤语⾳识别和关键词匹配实现基本的语⾳交互。
- 推荐系统:如Amazon的推荐算法,提供个性化内容推荐。
2.2 AI2.0
定义:则指的是⼈⼯智能技术的现代阶段,这个阶段以深度学习、⼤数据和云计算的兴起为标志。
代表产品:
- ChatGPT:由OpenAI开发的⽣成式预训练模型,能够进⾏⾃然语⾔对话和⽂本⽣成。
- ⾃动驾驶系统:如特斯拉的全⾃动驾驶(FSD),利⽤深度学习和⼤规模数据实现⻋辆的⾃动驾驶功能。
3 大模型与通用人工智能
3.1 大模型定义
⼤模型,全称「⼤语⾔模型」,英⽂「Large Language Model」,缩写「LLM」。是⼀种基于机器学习和⾃然语⾔处理技术的模型,它通过对⼤量的⽂本数据进⾏训练,来学习服务⼈类语⾔理解和⽣成的能⼒。
下⾯是来⾃OpenCompass的⼤模型评测榜单,该榜单的性能指标综合了多项评测结果,包括MMLU,CMMLU等。
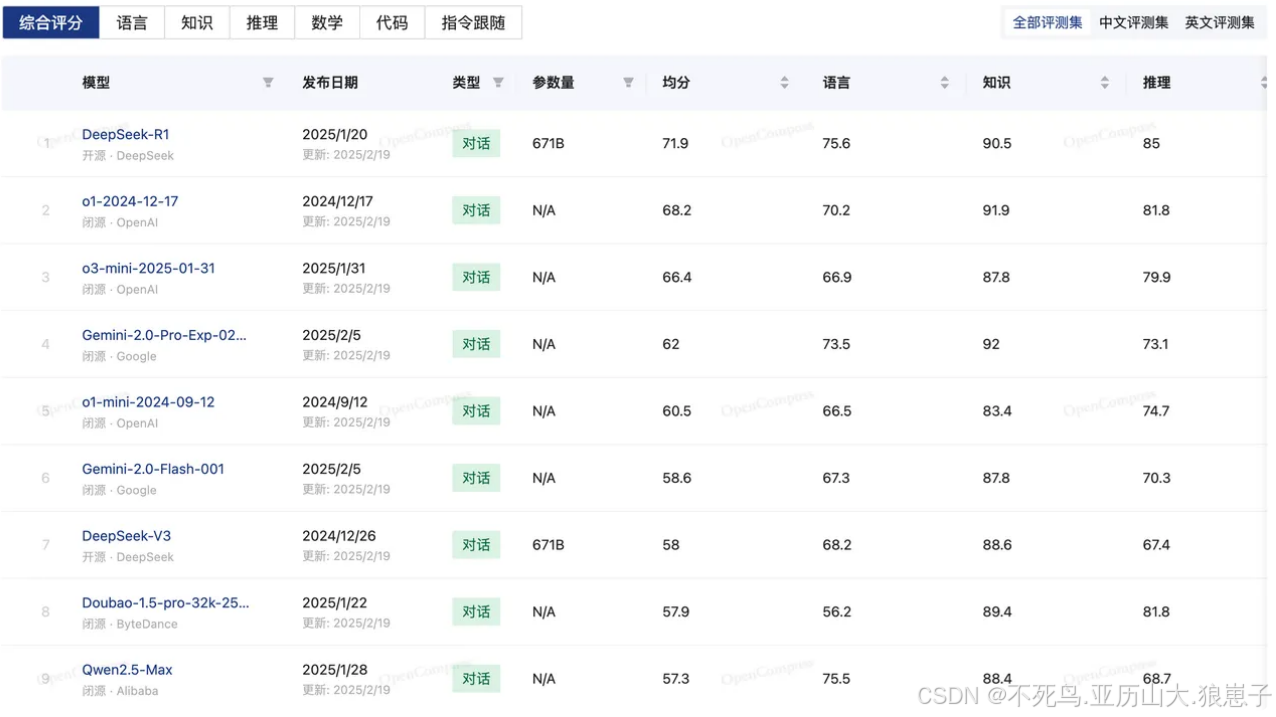
OpenCompass:https://opencompass.org.cn/home
注意点: 对话产品和基座⼤模型实际上是两个东⻄。
基座⼤模型这是⼀个通⽤的⼤型语⾔模型(LLM),如 GPT、LLaMA、Qwen等,它们经过⼤规模数据的预训练,具备强⼤的语⾔理解和⽣成能⼒。
对话产品这是基于基座⼤模型开发的具体应⽤,⽐如智能客服、AI 助⼿、问答系统等。
3.2 通用人工智能的定义
简称AGI,指的是⼀种智能,能够理解、学习和应⽤知识和技能,在任何⼈类智能能够执⾏的⼴泛任务上表现得和⼈类⼀样好,甚⾄更好。
AGI是⼀个未来的⽬标,⽬前尚未实现,它需要能够处理极其⼴泛的问题和环境,具有很⾼的适应性、⾃主性和创造性。
3.3 大模型与通用人工智能的联系
- 研究基础:当前的大模型是通向AGI的⼀种可能的研究途径。通过开发和训练大模型,研究者可以探索智能行为的各种方面,包括语⾔理解、问题解决和学习能⼒。例如,通过改进算法、增加模型的泛化能力,以及探索更有效的学习⽅法,⼤模型可以逐步接近AGI的特性。
- 技术搭桥:大模型在处理复杂任务时展示的能⼒可能为发展通⽤⼈⼯智能提供技术基础。
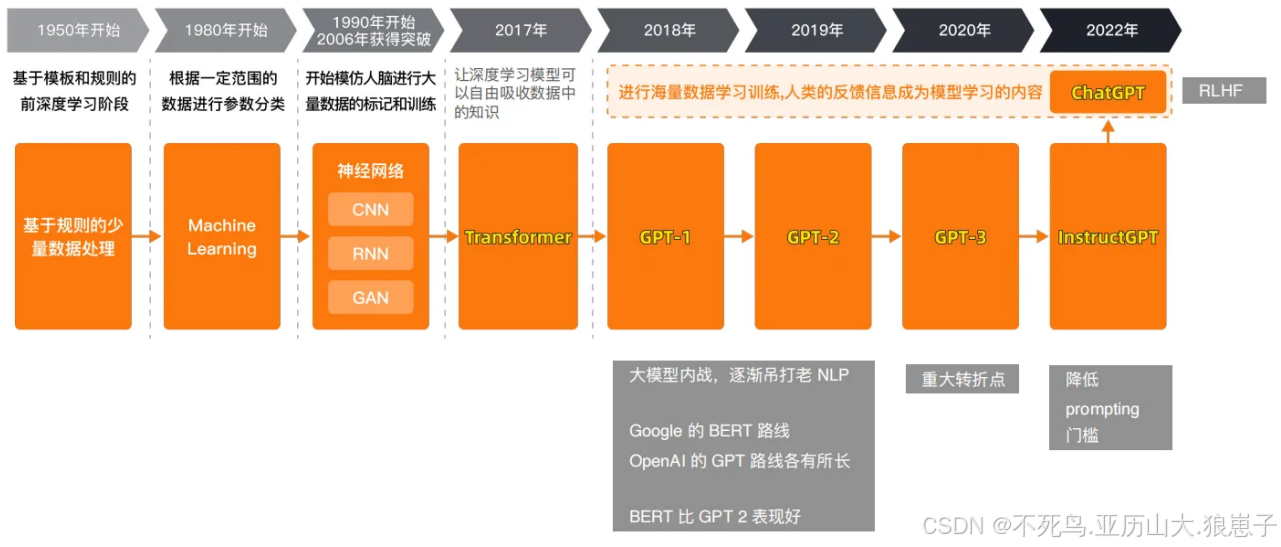
4 GPT模型的发展历程
4.1 GPT-1
发布时间: 2018年
模型概述: GPT-1是由OpenAI开发的⾸个GPT模型,基于Transformer架构。它标志着使用大规模预训练模型在⾃然语⾔处理领域的⼀个重要转变。该模型通过⽆监督学习从⼤量⽂本中预训练语⾔模型,然后通过有监督学习进⾏特定任务的微调。
关键特点: 该模型展示了通过预训练和微调相结合的⽅法,可以在多个⾃然语⾔理解任务上实现显著的性能提升。
4.2 GPT-2
发布时间: 2019年
模型概述: GPT-2在GPT-1的基础上显著扩展了模型⼤⼩和训练数据。具体来说,GPT-2使⽤了1.5亿个模型参数,远多于GPT-1的参数数量。
关键特点: GPT-2显示了出⾊的语⾔⽣成能⼒,能够产⽣连贯和引⼈⼊胜的⽂本段落。此外,OpenAI最初由于担⼼潜在的滥⽤⻛险,选择了不完全开放模型的访问。
4.3 GPT-3
发布时间: 2020年
模型概述: GPT-3是⼀个进⼀步扩⼤的模型,拥有1750亿个参数。这⼀巨⼤的扩展使GPT-3成为当时最⼤的语⾔模型之⼀。
关键特点: GPT-3的性能在多个⾃然语⾔处理任务上表现出⾊,包括翻译、问答和摘要等。GPT-3特别引⼊了“few-shot learning”,即模型能够在极少量的示例指导下快速适应新任务。
4.4 GPT-3.5与InstructGPT
发布时间:2022年
核心突破:引⼊⼈类反馈强化学习(RLHF),优化指令跟随能⼒。
技术细节:
- 基于GPT-3微调,结合⼈类标注数据调整输出偏好。
- 减少有害内容⽣成,提升对⽤户意图的理解。
4.5 GPT-4
发布时间: 2023年
模型概述: GPT-4进⼀步增强了模型的复杂性和多样性,包括改进的训练技术和更⼴泛的数据集。
关键特点: GPT-4在处理复杂的⽂本理解和⽣成任务时表现得更加精准,同时在逻辑推理和维持上下⽂连贯性⽅⾯也有显著改进。
5 国产大模型介绍
| 模型名称 | 发布公司 | 主要特点 | 关键技术 |
| 通义千问 | 阿⾥巴巴 | 开源⼤模型,⽀持中⽂理解与⽣成,具备强⼤的推理能⼒ | GPT-3架构优化 |
| 智谱清⾔ | 智谱科技 | 聚焦中⽂NLP,强⼤的跨⾏业能⼒ | ⾃监督学习、Transformer架构 |
| ⽂⼼⼀⾔ | 百度 | ⽣成式AI产品,强调多轮对话和情感理解,⽣成符合上下⽂的⽂本 | GPT-3架构、知识增强 |
| DeepSeek | 深度求索 | 专注于视觉与语⾔多模态结合,⽀持图像⽣成与推理 | 多模态学习、Transformer架构 |
| 讯⻜星⽕ | 科⼤讯⻜ | 认知智能⼤模型,集成多种NLP和机器学 习技术,⼴泛应⽤于教育、医疗等⾏业 | 语⾳识别、⽂本⽣成 |
| 盘古⼤模型 | 华为 | ⾃监督学习,强⼤的推理能⼒ | Transformer、BERT架构 |
| 混元⼤模型 | 腾讯 | 强⼤的中⽂创作能⼒,适⽤于复杂语境推理 | GPT-3优化、Transformer架构 |
6 大模型赋能⾏业分析
6.1 医疗行业
应⽤场景:
- 智能辅助诊断:大模型能够分析患者的症状、历史病历以及医学⽂献,辅助医⽣做出更准确的诊断。例如,通过对医学影像(如CT、X光)进⾏分析,提供初步诊断建议。
- 个性化治疗:结合患者的基因数据和医疗历史,⼤模型可以推荐个性化的治疗⽅案,提⾼治疗效果。
- 药物研发:大模型能够⾼效筛选药物候选分⼦,预测药物的作⽤机制,显著加速新药研发进程。
- 医学⽂献分析:大模型可以快速处理海量的医学⽂献,⾃动⽣成总结,帮助研究⼈员和医⽣及时了解最新的研究进展。
影响:
- 提⾼诊疗效率和准确性:降低误诊率,提升医疗服务质量。
- 优化医疗资源配置:缓解医⽣压⼒,提升医疗服务的可及性。
- 加速医学研究:推动药物发现和医学研究的创新。
“AI+医疗”深度融合,江苏加速医疗大模型落地应用
6.2 政务和法律行业
政务应⽤场景:
- 智能政务服务:大模型能够提升政府服务的效率和质量。例如,智能客服系统能帮助公众快速获取政务信息,解答常⻅问题。
- 政策分析与制定:大模型可以通过分析⼤量的政策⽂献、历史数据和社会反馈,帮助政府制定更加精准的政策,预测政策效果。
- 公共安全监控:在公共安全领域,大模型可以通过视频监控、舆情分析等⼿段,预测并预防潜在的社会⻛险。
法律⾏业应⽤场景:
- 法律⽂书⽣成与审查:大模型能够⾃动⽣成法律⽂书、合同,并帮助法律从业者审查合同条款,发现潜在法律⻛险。
- 智能法律咨询:通过大模型对法律条⽂、案例的理解,提供智能法律咨询服务,帮助⾮专业⼈⼠解决法律问题。
- 司法裁决分析:大模型可以分析历史裁决结果,辅助法官做出更加公正的判决,确保法律适⽤的⼀致性和公正性。
影响:
- 提⾼政务效率:优化资源配置,提升政府服务质量。
- 增强法律服务可及性:让公众和企业能够更⽅便、快捷地获取法律服务。
- 提升司法公正性:减少⼈为错误,确保法律适⽤的⼀致性。
河北多个政府部门政务系统接入DeepSeek,探索智慧政务新模式
7 大模型的趋势和挑战
7.1 发展趋势
- 模型规模的进⼀步扩⼤:随着硬件技术的进步和训练技术的改进,预计⼤模型的规模将继续增⻓。更⼤的模型可能带来更强的计算能⼒和更好的任务泛化能⼒。
- 模型效率的提升:⼤模型的能效和计算效率是未来的重要发展⽅向。通过算法优化、更⾼效的架构设计和更先进的硬件⽀持,模型将在消耗更少资源的同时提供更快的响应和更⾼的性能。
- 定制化和专⽤化:预计将出现更多针对特定领域或特定任务优化的模型,如GPTs系列。这些模型将提供更精准的服务,满⾜特定⾏业的需求。
- 多模态能⼒的增强:将⽂本、图像、⾳频等多种数据模态整合的多模态模型将是未来的⼀个重要发展⽅向,使模型能够更全⾯地理解和⽣成跨模态内容。
- 可解释性和透明性的提升:随着模型应⽤的扩展,⽤户和监管机构对模型的可解释性和透明性的要求也在增加。未来的模型将需要提供更好的理解和解释其决策过程的能⼒。
7.2 挑战
- 伦理和安全问题:随着模型能⼒的增强,如何确保它们的安全使⽤和防⽌滥⽤成为重⼤挑战。这包括数据隐私、偏⻅的减少和滥⽤⻛险的控制。
- 资源消耗和环境影响:⼤模型的训练和部署需要⼤量计算资源,这带来了显著的能源消耗和环境影响。如何降低这些模型的碳⾜迹是未来发展的重要考量。
- 数据和模型的治理:随着模型应⽤的⼴泛化,如何有效管理使⽤的数据、保护个⼈隐私、确保数据安全和合规是另⼀个挑战。
- 技术普及的不均衡:⼤模型技术的⾼成本可能导致技术普及的不均衡,使得资源丰富的机构和国家能够获得更多的好处,⽽资源较少的地区则可能落后。
- ⼈机协作的优化:随着AI能⼒的提升,如何设计机制使⼈与机器之间的协作更加⾼效和和谐,特别是在复杂和创造性的任务中,是⼀个持续的挑战。
