【GNN】第四章:图卷积层GCN
【GNN】第四章:图卷积层GCN
图神经网络和CNN网络一样:由基本的层+巧妙的架构设计 = 一个SOTA模型。所以我们的学习线路应该是先了解各种类型的层,然后学架构。但是由于内容较多,而且我个人认为GCN层最难理解,所以先把GCN层单独拿出来详讲,为后面学其他层热个身。
这个链接 torch_geometric.nn — pytorch_geometric documentation 是PyTorch Geometric的torch_geometric.nn模块的官网介绍:

上图左边是PyG官网罗列的GNN网络架构中的常见的各种层和计算公式,比如图卷积层(conv layer)、归一化层(normal layer)、池化层(pooling)等。
上图右边是PyG官网罗列的图卷积层的各种变体。就是光图卷积层就有几十种变体,其中比较有名的是GCN、GraphSAGE、GAT、GAE等图卷积层,本篇讲GCN。
一、GCN简单说明
1、这是GCN的论文:https://arxiv.org/pdf/1609.02907
2、GCN, Graph Convolutional Network, 图卷积网络,于2017年提出,它的到来标志着图神经网络时代的出现。
很多地方讲GCN时一直和图像卷积CNN放一起扯啊扯,我个人认为,二者实在没啥可比性,就好比苹果和橘子,没啥可比的,就各学各的,学GCN就把脑子里面的CNN给清空了,不然越搅越糊。CNN是处理图像数据(规则的通道数据)的,GCN是处理图数据(完全无规章的图graph)的,二者风马牛不相及,就别硬往一起凑。
二、GCN原理、架构、数据流、用PyG实现一个单层GCN
纯粹用文字实在不好表述清楚,所以本部分我打算用一个极简的小例子来说明:
1、构建一个极简的图数据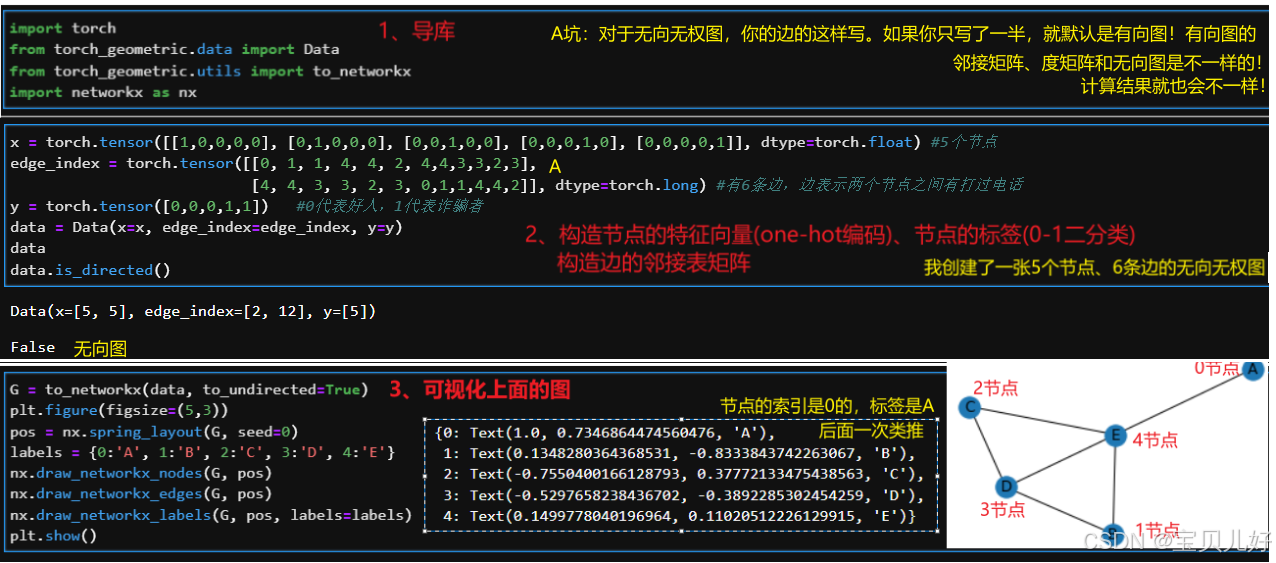
2、GCN原理
3、GCN网络的一般架构设计
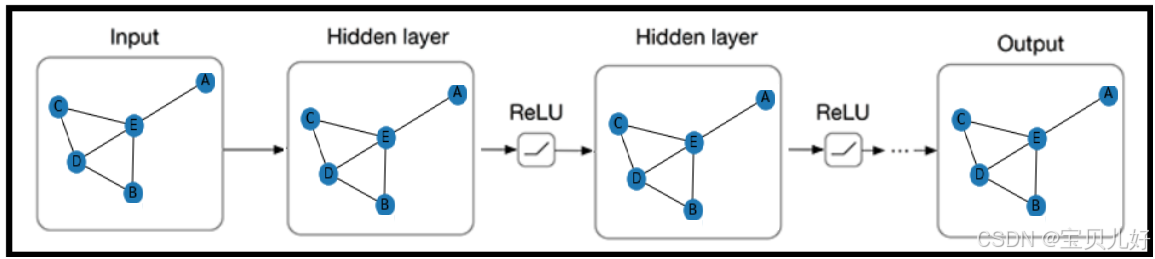
这是有多个隐藏层的架构。每个GCN层后面都跟一个非线性激活层。这是我们深度学习的常规设计,图神经网络也不例外。这里我想强调两点:
一是,在传统深度学习中,deeper is better, 所以我们一直追求更深更复杂的架构,也就是我们经常说的"在海量的数据上训练巨大的模型",所以现在很多模型动辄就是数亿参数,普通电脑根本没法训练,所以当下就是拼硬件的一个局面。但是图神经网络不是越深越好,最好3-4层即可。超过3、4层效果反而开始下降!有个埂说,这个世界只要你认识6个人,你就可以认识到世界上的所有人。意思就是,假如你是一个节点,你只需要通过6条边,你就可以关联到图中的任何其他节点。所以图神经网络不需要太多的层。
二是,激活函数。属性深度学习的对激活函数不陌生。各种激活函数的优劣点,在图神经网络中也一样。
4、在PyG中实现一个GCN层,看一看GCN层的参数情况
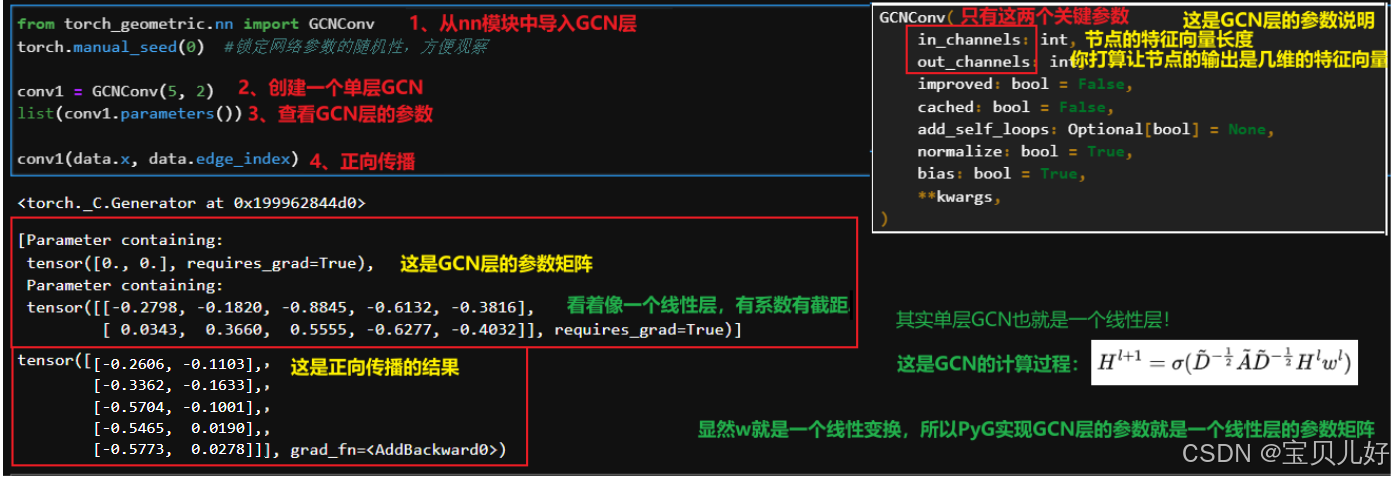

5、GCN的消息传递机制
也就是在GCN网络中,每个节点的特征向量是如何进行更新的?也就是GCN的消息传递机制,也就是我们经常说的网络中的数据流。
弄清GCN的数据流,我们首先要明确下面几点:
一是,GCN网络数据传递的目的是重构特征
一般情况,输入GCN网络的数据是一张图中所有节点的特征向量,而节点的特征向量一般都是one-hot编码。意思就是输入GCN网络前的节点特征都是没有语义的。GCN网络的目的是让这些没有语义的节点的特征向量,根据节点在图中的拓扑结构,更新出带语义的新的特征向量。这样我们就得到一张图中的所有节点的带语义的特征向量,那此时你想分类就用分类算法去分类,想回归就去回归好了。
二是,如何根据拓扑结构,更新节点的特征向量?
每个节点更新特征的时候,一方面要考虑自身的特征,另一方面要考虑与它相关的点的特征。这就是根据拓扑结构更新特征。
图的拓扑结构可以用邻接矩阵、度矩阵等来表示。所以邻接矩阵、度矩阵是要参与节点特征更新的计算的。
下面我们开始精解GCN论文中的公式 ,这个公式懂了,也就是GCN层你懂了。![]()
(1)公式中的A、D、H、w、σ的含义
(2)A漂、D漂、D漂的-1/2
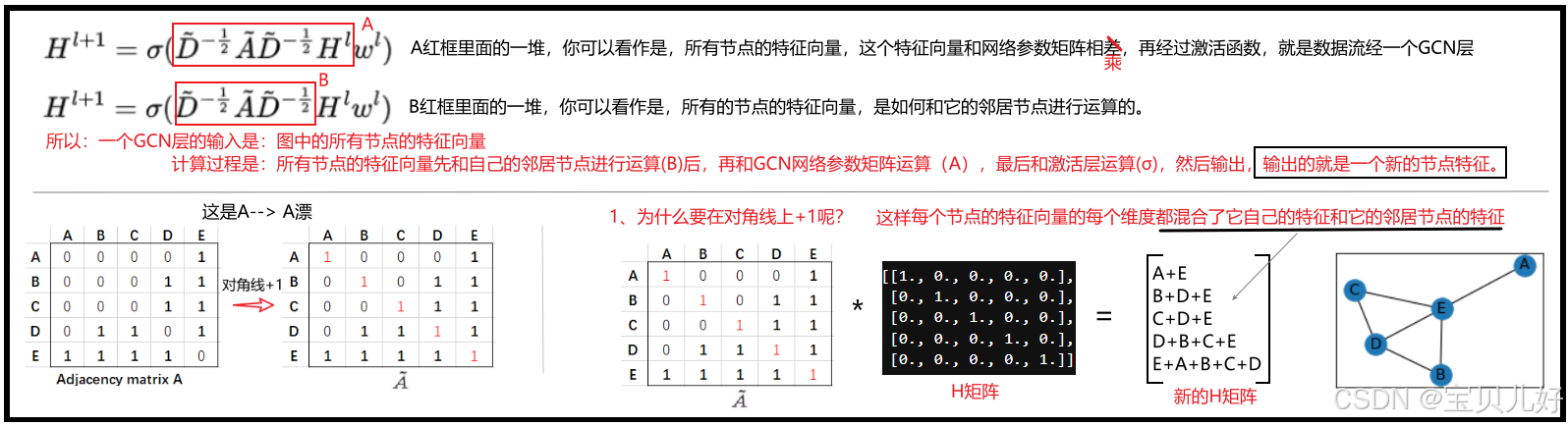
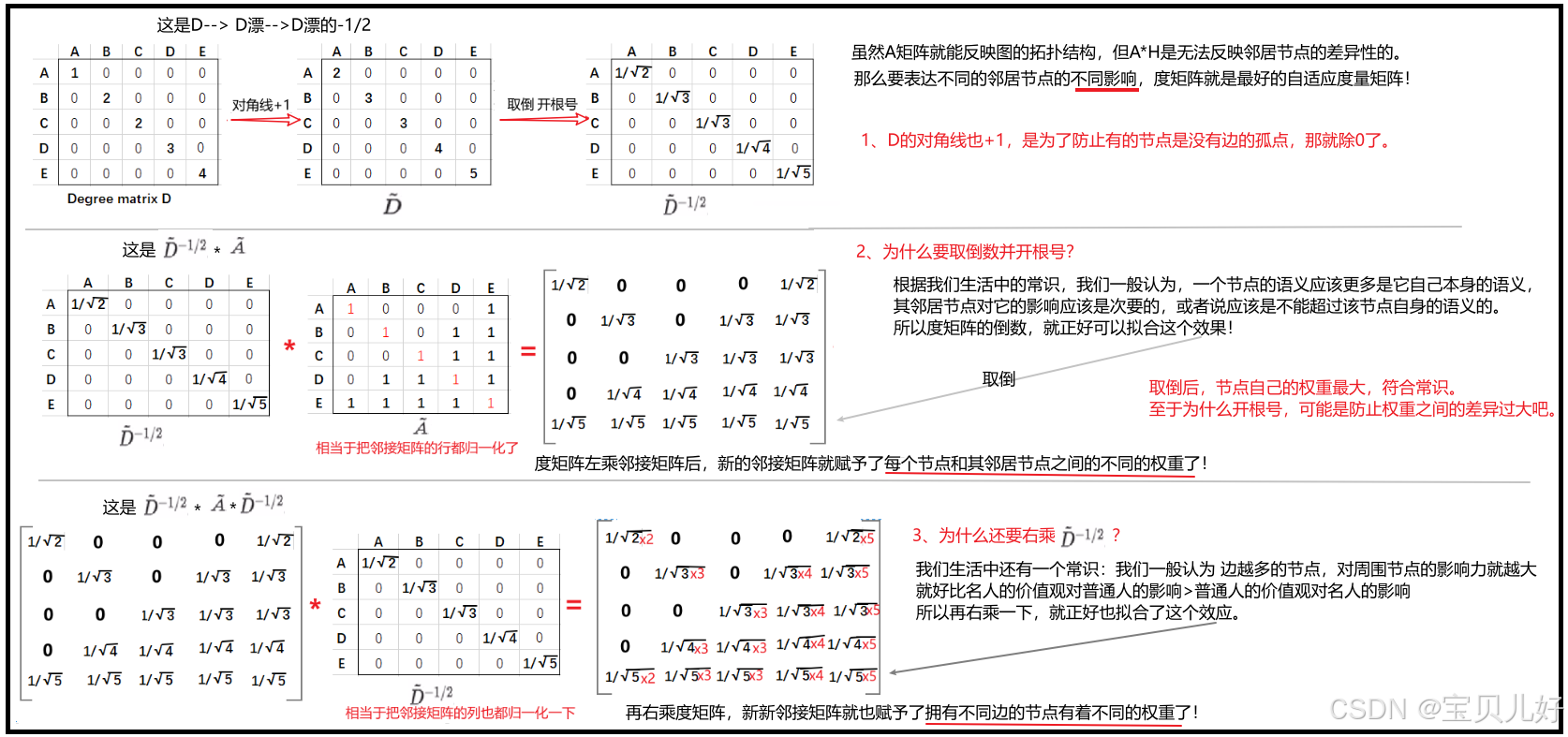
(3)GCN层中的数据流
下我们用PyG生成的那个单层GCN,手动计算一下数据流,看我们的计算结果和PyG一样不一样: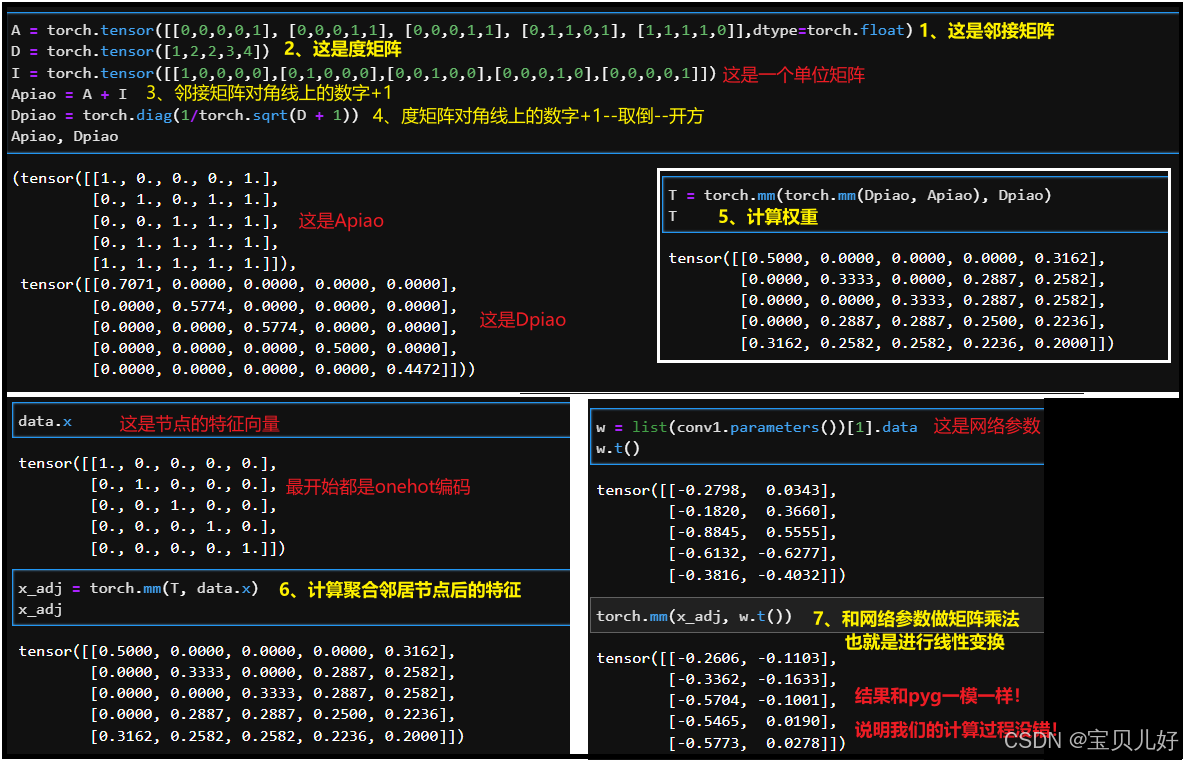
至此我们就把GCN的原理、架构、数据流都梳理了一遍。现在我再小结一下:
1、图神经网络GNN中的图卷积层有几十种变异结构,GCN层只是其中的一个变体,而且是最有名、最常用的变体。其他变体也有非常经典的,后面我会整理出来。
2、 图卷积层的目的是重构节点特征的。你节点的特征表达做得很好后,你想分类就分类想回归就回归。
3、 GCN层的输入是一张图的节点的特征向量矩阵+边的邻接表。
邻接表是告诉图卷积层,你的图的节点之间的链接情况。
节点的特征向量的初始化,你可以用onehot编码,也可以其他编码,你随意。反正网络要迭代的就是这些特征向量。
4、 GCN层的迭代过程是:先根据每个节点的邻居节点,聚合每个节点的特征。然后再对特征进行线性变换。
聚合特征时,邻居节点的权重是通过度矩阵左乘右乘邻接矩阵计算而来的。邻接矩阵和节点的特征向量矩阵相乘就可以混合节点和它的邻居节点。左乘邻接矩阵是考虑节点自身的权重要大于邻居节点的权重。右乘是考虑边多的节点应该有较大的权重、边少的节点应该有较小的权重。
线性变换就和普通的MLP一样,就是简单的线性变换,系数矩阵+截距。
5、一个GNN网络中,可以堆积多个图卷积层。
6、网络正向传播一个图卷积层,节点的特征就被聚合一次。而且每次聚合使用的权重矩阵都是一样的!因为邻接矩阵和度矩阵不会变嘛!也所以每次正向传播一个GCN层,新特征除了聚合一次,还要被GCN层线性变换一次。
也所以,GCN有几层,节点向量就会看到和它不相连的几步节点的信息。这个倒是可以类别CNN的感受野概念。据说6层GCN后,网络中的每个节点都会受到所有其他节点的影响。这个就看网络中的最长路径了。总之,层数越多,迭代的新的特征向量就越有全局的信息。但是多于6层,效果就会转差,所以GNN一般没有特别深的网络。 效果转差是因为:如果我们添加太多层或者迭代的次数太多,聚合会变得非常激烈,以至于所有节点嵌入最终看起来都一样,这种现象称为过度平滑,所有的节点看起来都没啥差别,自然效果也就变差了。
7、 网络反向传播,更新的是网络参数。网络正向传播更新的是节点的特征。
8、 很多图任务并不是纯的监督学习,大部分是Semi-supervised learning, 不需要全部标签,用少量标签也能训练,计算损失时只用有标签的。
三、案例:用GCN层搭建一个简单的GNN网络,分类Karate Club节点的类型
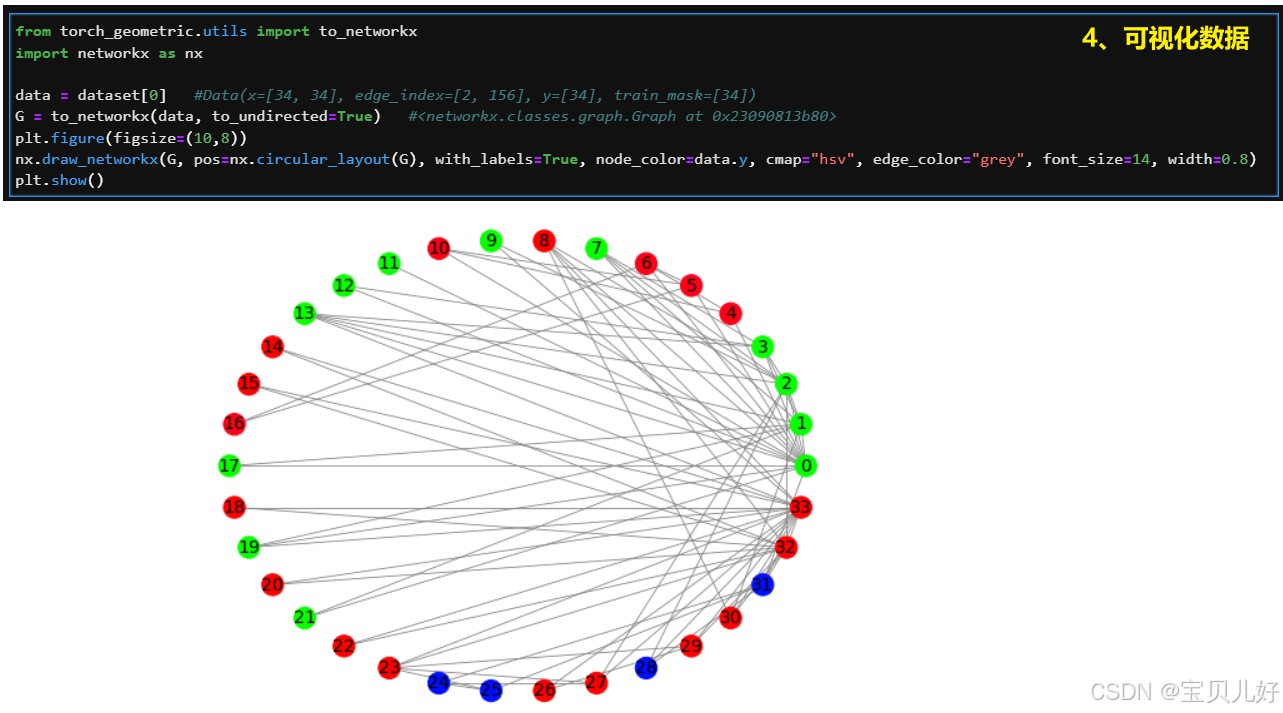
1、探索Karate Club数据集
Karate Club,Karate是空手道的意思,所以这就是一个空手道俱乐部的数据。这个数据集在GNN领域就相当于'hello world'级别的一个数据集。 这个数据集是由社会学家Wayne W. Zachary在1977年的论文《An Information Flow Model for Conflict and Fission in Small Groups》中提出的,基于他对一个美国大学空手道俱乐部的观察和记录。在收集数据的过程中,俱乐部的管理员和教练之间发生了冲突,导致俱乐部分裂为两个社区,一半成员跟随教练,另一半成员跟随管理员或离开俱乐部。Zachary利用图的结构信息,成功地预测了除了一个成员之外的所有成员的类别。
Karate Club数据集包含34个节点和78条无向无权边(156/2=78),每个节点代表一个空手道俱乐部的成员,每条边代表两个成员之间的社交关系。其中,结点分为4类(就是节点的标签喽),每个节点有34个特征(就是节点的one-hot编码的特征向量喽)。为啥节点的特征向量长度=图中所有节点的个数?因为节点的特征都是one-hot编码喽。下面我们来探索探索这个数据集: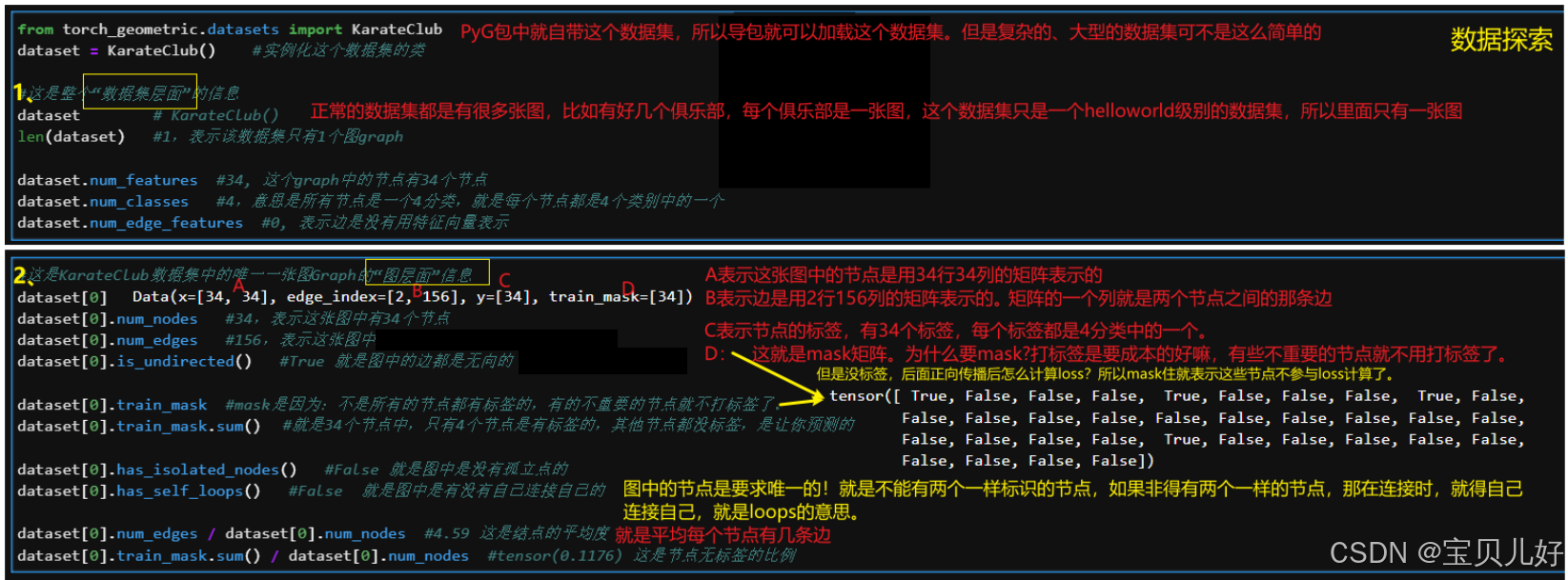
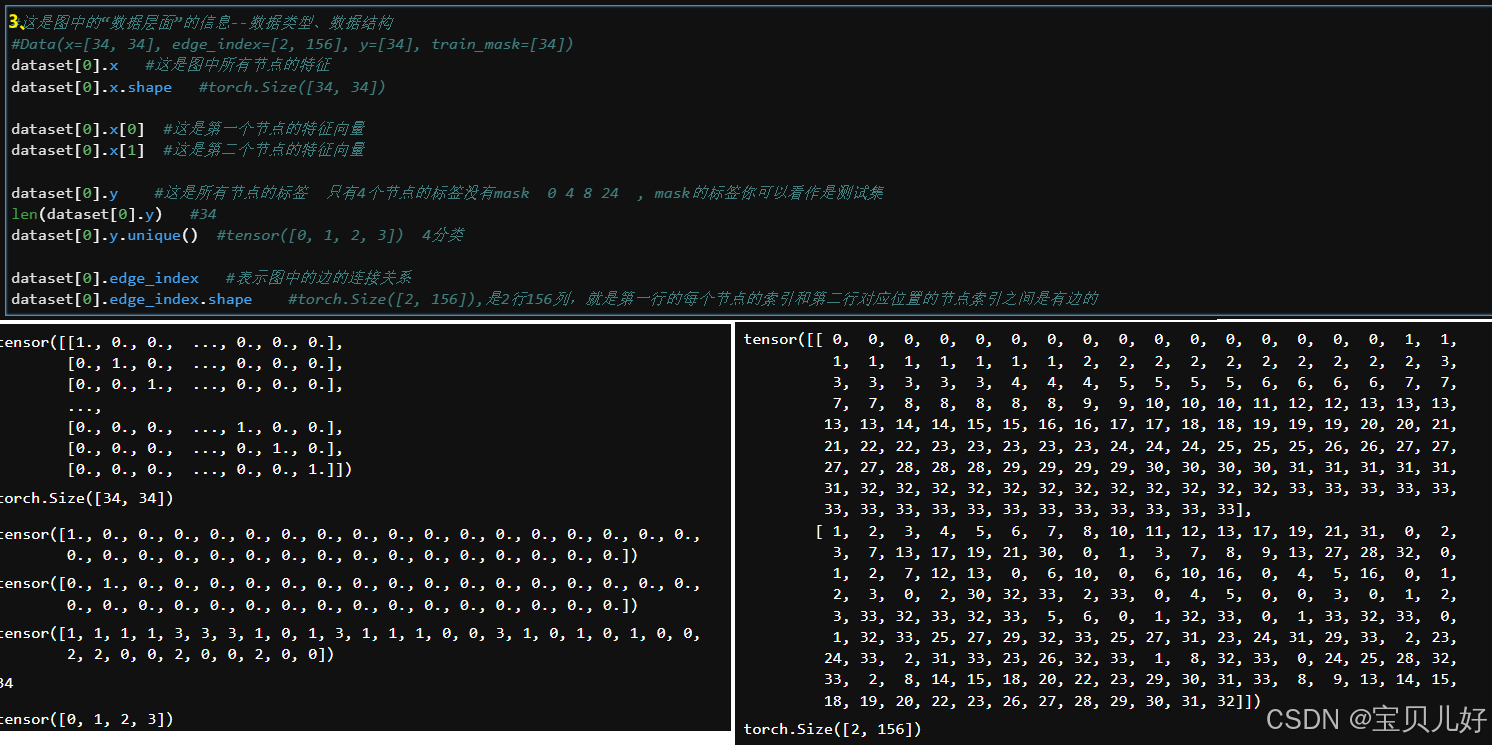
2、用GCN搭建网络、全监督训练模型
#1、加载数据
from torch_geometric.datasets import KarateClub
dataset = KarateClub()
data = dataset[0]
#2、搭建网络架构
import torch
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
torch.manual_seed(0)
self.conv1 = GCNConv(34, 24)
self.conv2 = GCNConv(24, 16)
self.conv3 = GCNConv(16, 8)
self.classifier = nn.Linear(8, 4)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x1 = torch.relu(self.conv1(x, edge_index))
x2 = torch.relu(self.conv2(x1, edge_index))
x3 = torch.relu(self.conv3(x2, edge_index))
x4 = self.classifier(x3)
return x4
#3、实例化模型、定义损失函数、定义优化器
net = GCN()
criterion=torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
#4、开始训练模型
net.train()
train_loss = []
train_acc = []
for epoch in range(100):
optimizer.zero_grad()
out = net(data)
#loss = criterion(out[data.train_mask], data.y[data.train_mask]) ## 仅基于4个训练节点计算损失 ----半监督学习
loss = criterion(out, data.y) #在全部标签上学习----监督学习
loss.backward()
optimizer.step()
train_loss.append(loss.data.item())
train_acc.append((out.argmax(dim=1) == data.y).sum() /len(data.y))
#5、查看训练效果
fig, axes = plt.subplots(1,2, figsize=(12,4))
axes[0].plot(range(100), train_loss)
axes[1].plot(range(100), train_acc)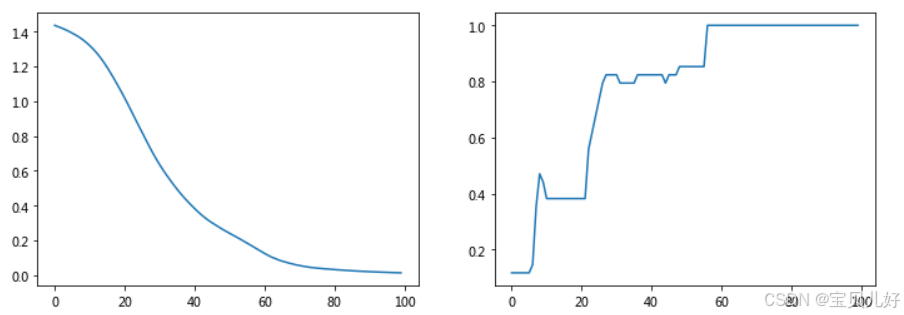
从上图可见,差不多60个epoch后,34个节点的标签就已经全部预测对了。但是这是基于损失函数是全部标签的情况下。下面我们看看如果损失函数只有4个标签的情况:
3、半监督训练模型
#半监督训练模型
net.train()
train_loss = []
train_acc = []
for epoch in range(100):
optimizer.zero_grad()
out = net(data)
loss = criterion(out[data.train_mask], data.y[data.train_mask]) ## 仅基于4个训练节点计算损失 ----半监督学习
#loss = criterion(out, data.y) #在全部标签上学习----监督学习
loss.backward()
optimizer.step()
train_loss.append(loss.data.item())
train_acc.append((out.argmax(dim=1) == data.y).sum() /len(data.y))
#查看训练效果
fig, axes = plt.subplots(1,2, figsize=(12,4))
axes[0].plot(range(100), train_loss)
axes[1].plot(range(100), train_acc)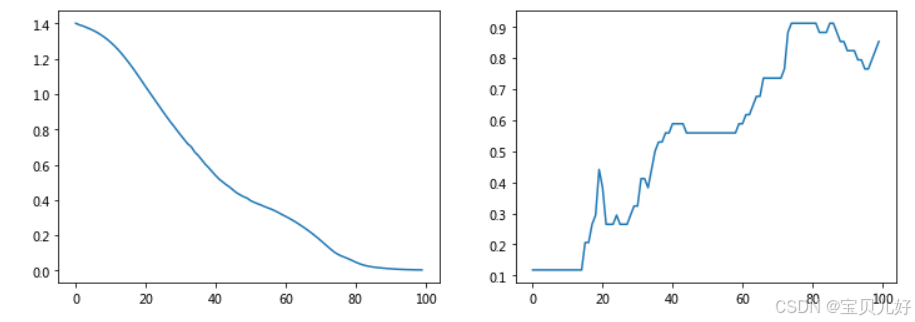
半监督训练就是我们只使用4个节点的标签来构建损失函数,所以整个图的损失函数只是没有mask住的那4个节点在牵引。上右图的accuracy是全部34个节点的准确率,所以我们训练100个epoch后,准确率最高也就是90%多一点,而且随着迭代次数的增加,准确率还出现了下降。这是因为,对于GNN来说,特征向量经过一个GCN层,特征向量就会根据网络的拓扑结构更新1次。所以:
GNN网络不仅会聚合来自每个节点的邻居节点的特征向量,还会聚合来自这些邻居的邻居的特征向量。
所以,如果我们堆叠多个GCN层、迭代多个epoch的话,就会聚合更多更远的值,这就会引发一个问题:如果我们添加太多层或者迭代的次数太多,聚合会变得非常激烈,以至于所有节点嵌入最终看起来都一样。这种现象称为过度平滑,当层数过多或迭代次数过多时,这可能会成为一个真正的问题。
对此,很多人的解决方法是,适当迭代后,不让GNN网络来对节点进行分类了,而是把GNN网络迭代后的特征向量拿出来,用其他分类器来分类,比如决策树、随机森林等分类器来分类,效果会在GNN基础上能再提升几个百分点。此时GNN网络就是不是一个分类器,而是一个embedding的作用,就是一个表征学习器。当GNN把所有节点的特征向量embedding得非常好的情况下,也就是每个节点的语义表达做的非常好的情况下,那不管什么分类器都可以分得很好。
但是话说回来,上面的半监督学习效果还是非常不错的,整张图有34个节点,我们只标注了4个节点的标签,就90%的准确率预测了所有节点,可见GCN还是非常强大的!只有4个标签的情况下,如果你让决策树、逻辑回归等传统的分类器来分类,这些分类器是完全无能为力的,因为它们都是监督学习模型,没有标签,它们是无法学习的。相比之下,GNN不但能够根据节点信息、邻接节点的信息和边的信息计算节点表征,还能利用图的拓扑结构信息计算节点表征,这样的优点是其他模型难以逾越的。
图神经网络的核心思想是将每个节点的特征与其周围节点的特征进行聚合,形成新的节点表示。这个过程是通过消息传递来实现,每个节点接收来自其邻居节点的消息,并将这些消息聚合成一个新的节点表示。这种方法可以反复迭代多次,以获取更全面的图结构信息。