【Go万字洗髓经】Golang内存模型与内存分配管理

本文目录
- 1. 操作系统中的虚拟内存
- 分页与进程管理
- 虚拟内存与内存隔离
- 2. Golang中的内存模型
- 内存分配流程
- 内存单元mspan
- 线程缓存mcache
- 中心缓存mcentral
- 全局堆缓存mheap
- heapArena
- 空闲页索引pageAlloc
- 3. Go对象分配
- mallocgc函数
- tiny对象分配内存
- 4.结合GMP模型来看内存模型
- tiny对象分配
- 5.总结
- 设计思想
- 一些问题?
- 为什么mcache与P绑定?
- span的等级到底是66级还是67级或者68级?
- 0级到底是什么?是更大对象吗?
- 6. 参考文章
1. 操作系统中的虚拟内存
虚拟内存是操作系统中一种重要的内存管理技术。它允许计算机系统使用硬盘空间来模拟额外的内存空间,从而扩展可用内存的范围。
从用户程序的角度来看,虚拟内存提供了一个比实际物理内存大得多的地址空间。操作系统通过将程序和数据分段存储在硬盘上的虚拟内存区域,并在需要时动态地将部分数据加载到物理内存中来实现这一功能。
这种方式使得大型程序能够在有限的物理内存环境中运行,同时也提高了内存的利用率。例如,当物理内存不足时,操作系统会将暂时不用的数据或程序代码移动到虚拟内存中,而当这些数据被访问时,再将其调回到物理内存。
虚拟内存的管理涉及到页面置换算法、段页式管理等多种技术,这些技术共同确保了虚拟内存的有效运行,并为用户提供了一个高效且透明的内存使用环境。
比如下面这个图,是一个简单的示意。虚拟内存可以通过页表来定位到真实数据到底位于哪里,从而进行访问数据。
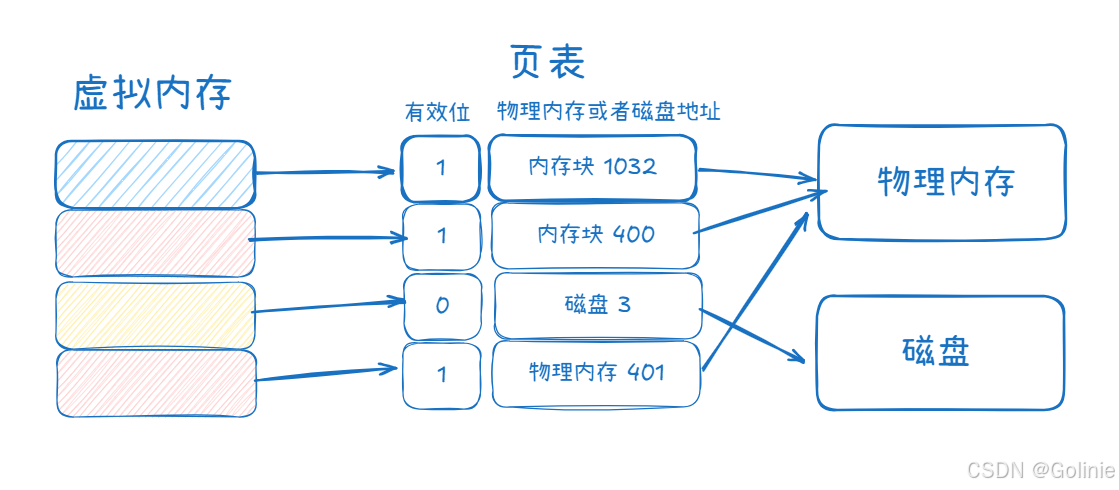
虚拟内存是以“页”进行单位进行管理,物理内存是“帧”。
操作系统中虚拟内存和物理内存被切割成固定尺寸的“页”和“帧”有其特定的意义和好处。首先,这样做可以提高内存空间的利用效率。当内存以页为粒度进行管理时,可以消除不稳定的外部碎片,取而代之的是相对可控的内部碎片。这意味着内存的使用更加高效,减少了浪费。(内部的碎片是指页内的碎片地址,比如说4k,只用了3k,所以多的1k是多余的。)
其次,将内存分割成页和帧可以提高内存与外部存储之间的交换效率。更细的粒度意味着更高的灵活性,操作系统可以更灵活地管理内存,从而提高内外存交换的效率。
此外,这种分割方式与虚拟内存机制相呼应,便于建立虚拟地址到物理地址的映射关系。这种映射关系是通过一种称为页表的数据结构来实现的,它聚合了映射关系,使得虚拟内存的管理和访问更加高效。
在Linux系统中,页或帧的大小是固定的,通常为4KB。这个大小实际上是由实践经验决定的。如果页或帧太大,会增加内存碎片率,导致内存利用不充分;如果太小,则会增加分配频率,影响系统效率。因此,4KB是一个平衡点,既能保证内存的有效利用,又能保持较高的系统效率。
所以总的来说,分页不仅是为了防止外部的内存碎片导致的内存浪费,也还是因为多进程时代内存可能溢出的问题,主要还是为了做进程管理。
另外就是虚拟内存不是只让用户看着空间更大,主要是为了解决内存隔离的问题。
这里简单提一下进程管理和内存隔离,不是本文重点。
分页与进程管理
进程管理是操作系统的一项基本功能,它涉及到进程的创建、调度、执行和终止。进程是操作系统进行资源分配和调度的基本单位。每个进程都有自己的地址空间,操作系统通过进程管理确保每个进程都能安全、有效地使用系统资源,并且与其他进程隔离开来。
内存泄露(Memory Leak)是指程序在申请内存后,未能在不需要时正确释放,导致随着时间的推移,大量内存无法被回收利用,最终可能导致程序或系统性能下降,甚至崩溃。内存泄露是编程中常见的问题,特别是在那些需要频繁动态分配内存的程序中。
分页是现代操作系统中常用的内存管理技术之一。通过将内存分割成固定大小的页(Page),操作系统可以更有效地管理内存,同时也为进程管理提供了便利。每个进程都有自己的一组页,这些页映射到物理内存中。这种隔离机制可以防止一个进程访问或修改另一个进程的内存,从而提高了系统的稳定性和安全性。分页机制不仅有助于防止恶意软件随意访问内存,也有助于防止进程因内存溢出而相互干扰。
虚拟内存与内存隔离
操作系统为每个进程提供了一个独立的虚拟地址空间,进程通过虚拟地址访问内存。操作系统使用页表将虚拟地址映射到物理内存地址,这个过程对进程是透明的。由于每个进程都有其独立的页表,因此它们无法访问其他进程的虚拟内存空间。
分页是实现内存隔离的一种技术,操作系统将内存分割成固定大小的页(Page),每个进程只能访问分配给它的页。如果进程尝试访问未分配给它的页,操作系统会阻止这种访问,从而防止进程之间的内存干扰。
2. Golang中的内存模型
有一个很核心的点是,以空间换时间,一次缓存,多次复用。
因为每次申请内存的代价比较大,所以可以多申请一些内存,方便后续程序不断地使用。如果长时间申请的内存都是闲置的,那么就可以归还给操作系统。
内存分配流程
从操作系统的角度来看,这是用户进程(golang程序)中缓存的内存。
从Go自己的角度来看,堆是所有对象的内存起源,所有的对象的内存都是“堆”申请到的内存。
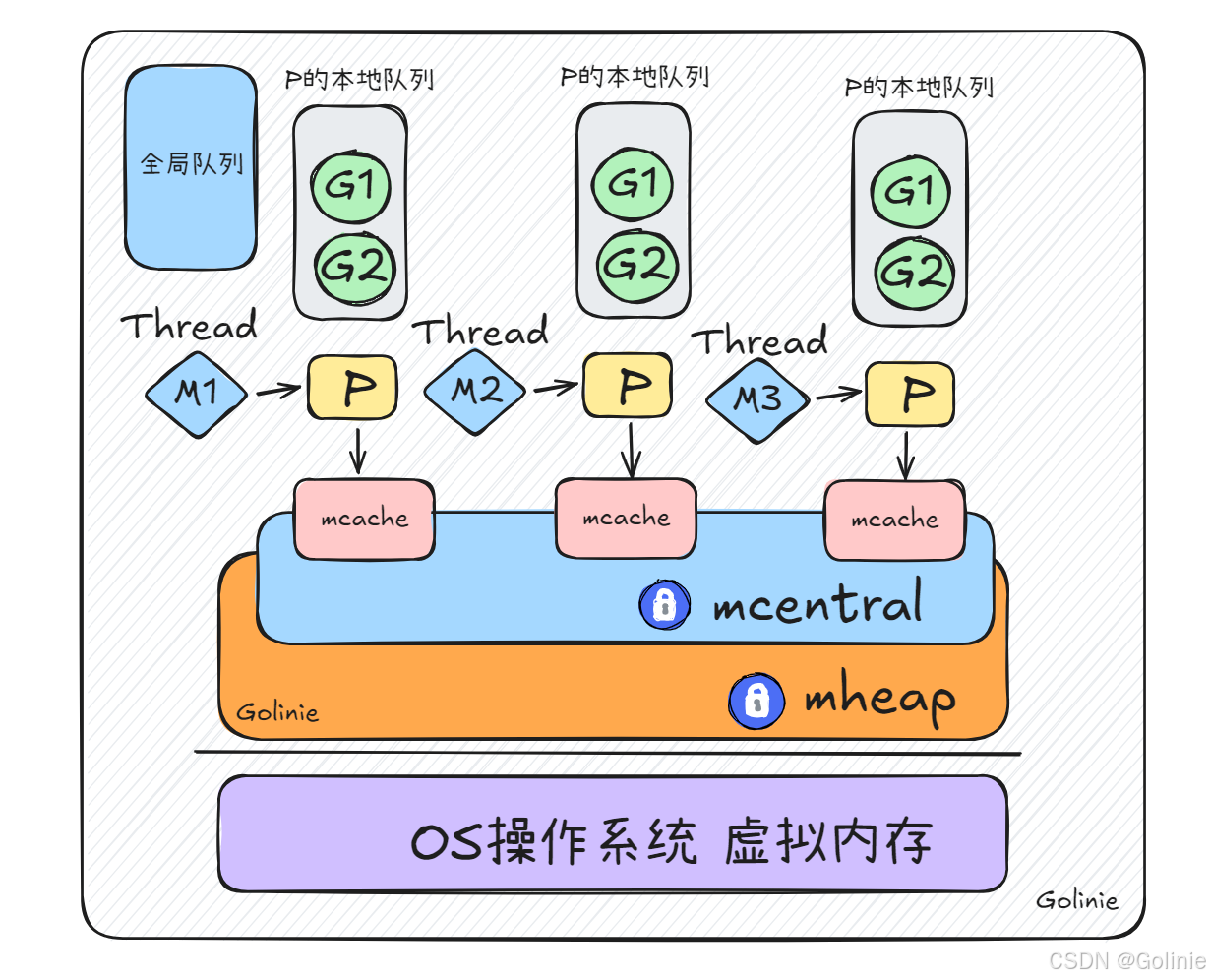
为了提高分配内存的效率,Go还设计了多级缓存,从而实现无锁化、细锁化粒度。
我们可以看看下面这个逻辑分层图,注意,是逻辑分层图。只是为了最开始方便理解内存模型,后边随着深入讲解,会不断地延伸。
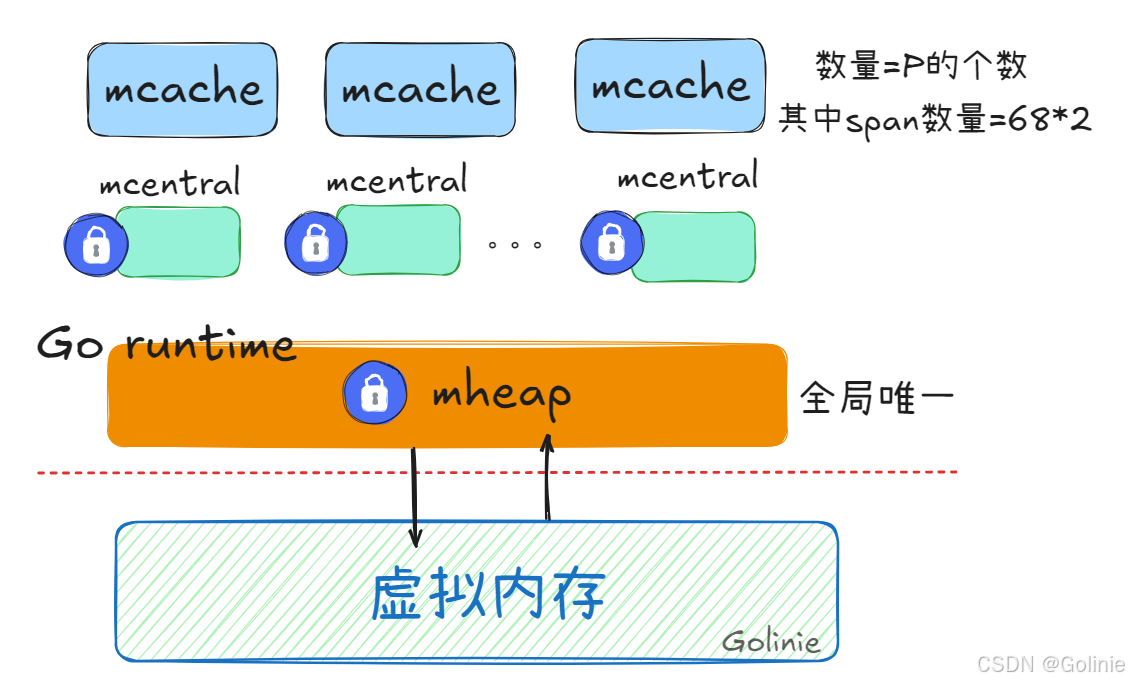
堆mheap是全局唯一的,如果要和mheap进行操作申请内存,需要加一个全局锁。因为堆是全局唯一的,所以这个锁也是全局锁,和进程(Go程序)一对一的。
在mheap上细化粒度,建立了有mcentral可以理解为一个等级集合的概念,根据最终需要创建的对象的大小区别,排了一个等级,当想要分配某个内存给某个对象实例的时候,会判断这个实例的大小,然后分配对应的mcentral。这样就把锁的粒度细化到了mcentral。也就是同一个大小等级内的所有对象,去竞争这个锁,优化了性能。
mcache就是GMP调度器中的处理器Process,mcache就是每一个处理器P独一份的、本地私有的缓存mcache,mcache中会冗余每一种等级的空间mspan,也就是会为每一个处理器去冗余一个内存空间。
当去获取内存的时候,先根据这个Process去查看其本地私有的mcache中有没有适合的内存空间使用,如果有,就直接获取使用,因为是 中私有的,所以不涉及并发,是无锁的,这是最理想的情况下。
如果说mcache没有空间,没有办法通过无锁的形式进行获取内存的行为,就会把这个行为升级,去mcentral中想办法分配内存。如果还是不行,就会继续升级,就回去mheap中获取内存空间。如果还是不行,就会发起系统调用的指令,去虚拟内存中申请更多的空间给mheap,然后再给我们的这次行为分配内存使用。
所以大概可以梳理个流程了。假设我们正在运行一个Go协程,该程序需要创建一个大小为128字节的对象。以下是分配这个对象可能经历的步骤:
- 本地缓存查找
(mcache)
程序首先检查它所属的处理器P的本地私有缓存mcache中是否有足够大的内存空间mspan来存放这个128字节的对象。mcache中为每种大小的对象都准备了冗余的内存空间,以减少锁的竞争和提高效率。
如果mcache中有合适大小的mspan,那么程序将直接从mcache中分配内存,这个过程是无锁的,因为每个处理器都有自己的mcache,不涉及并发问题。
- 中央缓存查找
(mcentral)
如果mcache中没有合适大小的mspan,程序将尝试从mcentral中获取。mcentral是一个按对象大小分类的中央缓存,它管理着相同大小对象的内存分配。
在mcentral中,程序会找到管理128字节对象的mcentral实例。由于mcentral是按大小分类的,所以这里的锁竞争仅限于相同大小的对象,这进一步细化了锁的粒度,提高了性能。
如果mcentral中有空闲的mspan,它将被分配给程序。如果没有,mcentral将尝试从mheap中获取新的内存空间。
- 堆内存分配
(mheap)
如果mcentral也无法提供内存,那么程序将直接向mheap申请内存。mheap是Go程序的全局堆内存,负责管理整个程序的内存分配。
由于mheap是全局唯一的,操作mheap需要加一个全局锁,以确保内存分配的原子性和一致性。这是整个内存分配过程中锁粒度最大的一步,但因为前面的步骤已经尽可能地减少了对mheap的直接操作,所以这种情况相对较少。
- 系统调用(如果必要)
如果mheap也没有足够的内存,那么程序将通过系统调用向操作系统请求更多的虚拟内存空间,然后将这部分空间添加到mheap中,再进行内存分配。
内存单元mspan
mcentral会以我们为某个实例对象所需要分配的内存的大小来建立不同的等级,那么这个大小等级是怎么划分的?
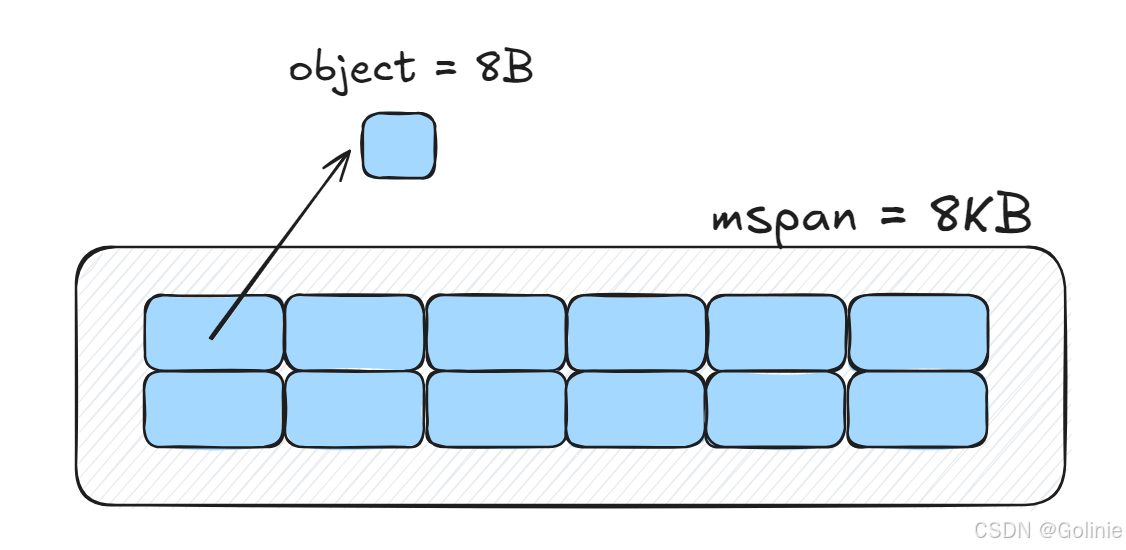
Golang中有两个概念,最小的存储单元-8KB:Page和最小的管理单元:mspan。
最小的存储单元也称为页,page,大小为8KB。
mspan里边的obj大小,从8B到32KB( 32,768 字节 B)被划分67种不同的规格【2025年3月10日,go源码最新确认是67种,大部分教程可能是两年前时候的,两年前是66种,https://github.com/golang/go/blob/master/src/runtime/sizeclasses.go ,Go仓库链接。】,分配对象的内存的时候,会根据大小映射到不同规格的mspan。(所以下面的图划错了,最高应该是32KB)
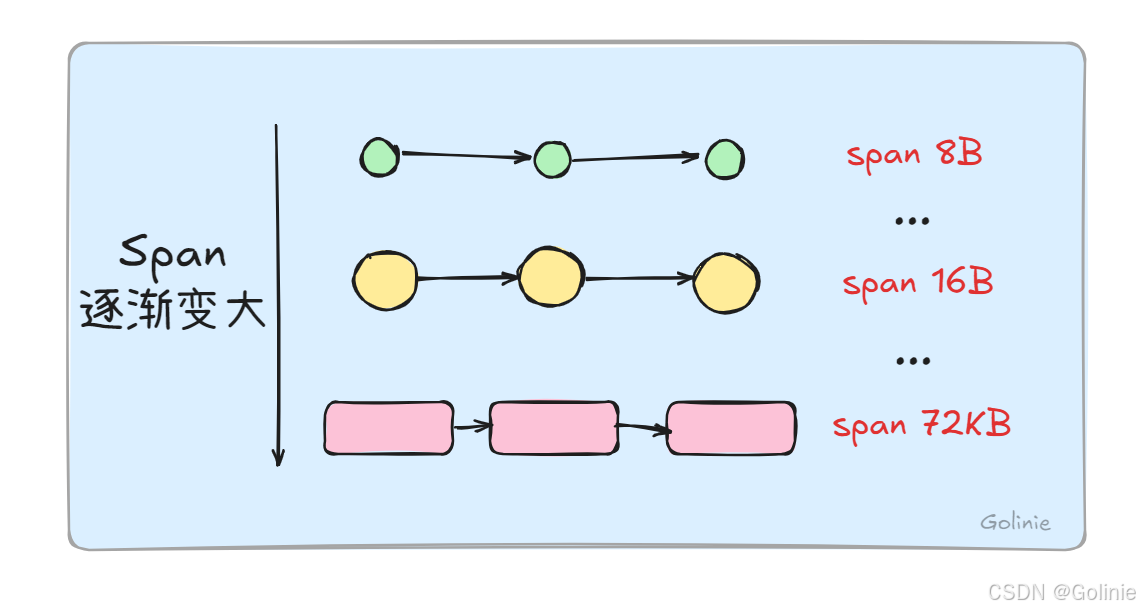
mcentral会根据不同mspan的等级,有不同的central的实例,每个实例会以一个双向链表的形式来管理mspan。
所以mspan的特性是如图下所示的。双向链表、起始page、page的页数等,用来连续标识。
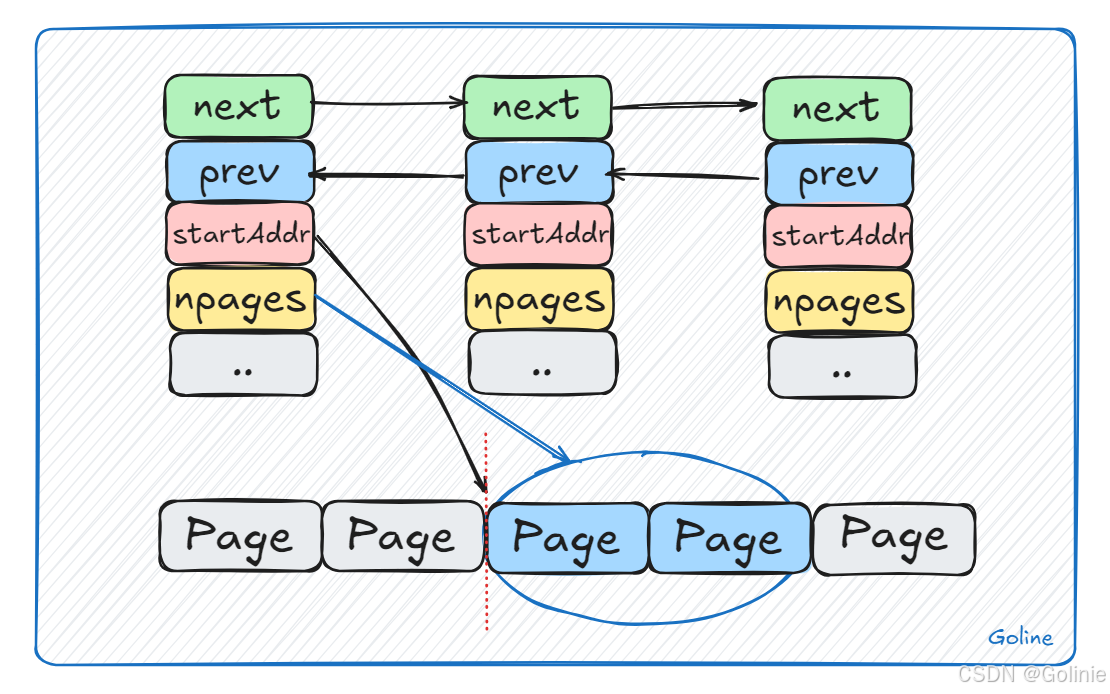
前面我们提到,mspan都是page的整数倍,page是8KB大小的,当mspan的obj等级为8B时,那么mspan里边就需要划分很多内存块object。mspan内部的页是连续的,至少在虚拟内存的视角中是这样,因为虚拟内存分配了连续的空间给go。
同等级的mspan会从属同一个mcentral,一个mcentral会把这些同等级的span构造成链表,所以上边是双向链表,有两个指针。并且使用一个锁进行互斥,来管理。
mspan会基于位图算法bitMap来快速找到对应的空闲块object,块大小对应等级的大小。使用的是ctz64算法。
也就是下面这个分配示意图,为0代表被占用,为1代表free可以分配出去。

mspan等级被划分为1-67,67级,此外还有个0级,用于处理特殊对象。
class1,就是8bytes,即8B,也就是一个8B的对象,mspan为8KB时,就代表这个mspan可以分配1024个对象出去。
当分配的对象为0-8B,都会使用calss1对应的span。而不是只有8B刚刚好时才进行分配。这也会导致有内存浪费。
这也会导致一个tail waste,末尾浪费,当class为3时,obj对象大小为24B,那么8KB=8192B的span会不能完全分配完obj,会造成末尾浪费,也就是8B,341x24+8=8192B。
除此之外还有max waste,代表了这个mspan分配的时候最多可能会造成的空间浪费。这个也很好理解,当所有对象为17B的时候,分配了341个出去,那么一共会造成total = (24-17)x341 + 8 空间的浪费,这个总共的空间除以 total / 8192 = 29%,这就是class为3时的 max waste 为 29%。
每个object还有个一个很重要的属性是nocan,也就是是否object包含了指针,在垃圾回收gc时是否需要展开对应的标记。
在go中,span class 和 nocan 两个部分信息会组成一个 uint8,形成完整的spanclass标识,8个bit中,高7位标识了span中一共66个等级,最低位标识nocan就可以了。
线程缓存mcache
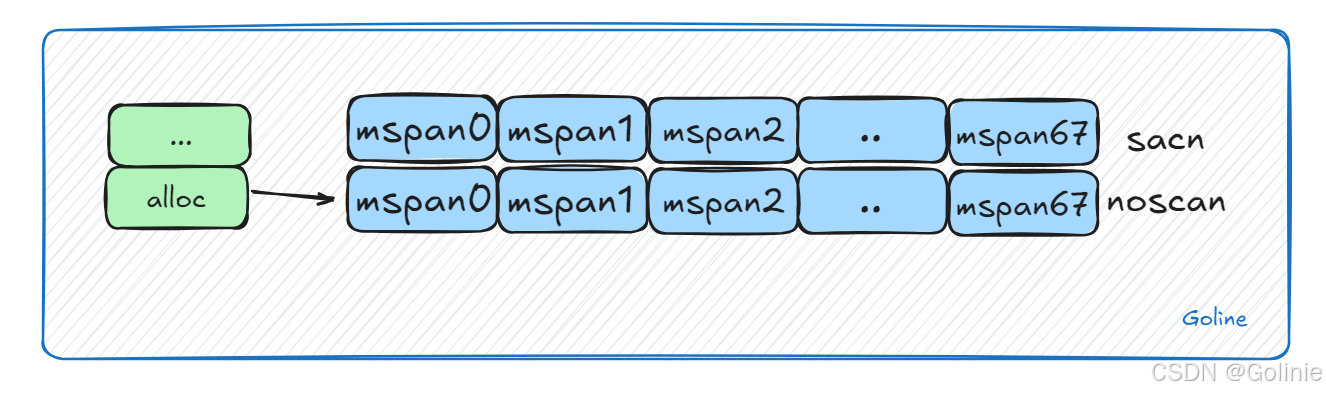
mcache是每个P独有的缓存,因此交互无锁。mcache将每种spanClass等级的mspan都各自缓存了一个,同时分为scan和nocan两个系列,也就是是否在gc时需要展开。一共是68*2=136个。
mcache还有一个tiny allocator微对象分配器,用于处理小于16B的对象内存分配。(参考了TCMalloc。)
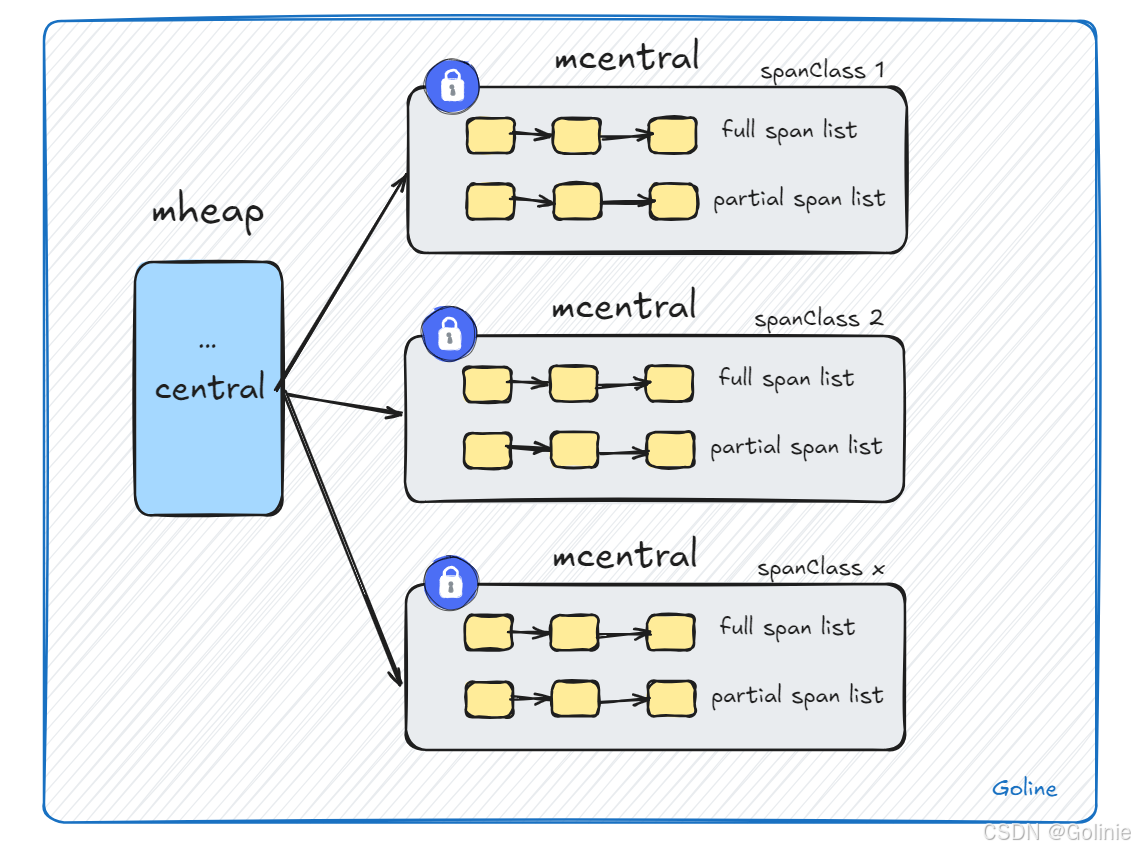
中心缓存mcentral
每个central会对应一种等级的spanClass,然后把spanclass分为两类,分别是有空间的mspan链表partial还有满空间mspan链表full。
每个central会有一把锁,这就是细化锁的粒度。可以把mcentral看成是mheap的一部分,只不过会优先从 MCentral 获取内存,如果没有 MCentral 会从 Arenas 中的某个 HeapArena 获取 Page。
全局堆缓存mheap
从go上层应用的角度来看,堆就是操作系统虚拟内存的抽象,可以看作是代言人。
mheap以页为单位,8KB大小,作为最小内存存储单元。注意与之前讲过的span的内存管理单元区分。
基于bitMap标识每个页的使用情况,每个bit对应一页,为0就是代表可以用,为1的话代表已经被mspan给分配走,但是不一定已经被obj对象使用了。
mheap有一个聚合页heapArena,有记录页到其所从属的mspan的映射信息。这是为了方便在gc时进行操作。
建立空闲页基数树索引radix tree index,帮助我们能够快速找到空闲页。因为我们刚刚说过,mspan中需要的page是连续的,所以如何通过bitMap来快速找到 连续+空闲 的页page,是需要考虑的,也就是这个的目的,能够找到符合我们需求数量的空闲页。
mheap是mcentral的持有者,持有所有spanClass下的mcentral,作为自身的缓存。可以把mcentral看成mheap更细化粒度的缓存。那么,我们应该如何理解这句话?
首先,mcentral可以看成是一次性从mheap中分配一系列的空间去给上层使用。
也就是说,mheap是mcentral的持有者,这意味着mheap负责管理所有的mcentral实例。每个mcentral实例对应一个特定的spanClass,用于缓存特定大小的内存块。
mcentral作为mheap的缓存,这意味着mheap通过mcentral来间接管理内存块。当需要分配内存时,首先会检查相应的mcentral是否有可用的内存块。如果有,就直接从mcentral中分配;如果没有,mheap会负责从操作系统申请新的内存,然后将其添加到相应的mcentral中。
当内存不够时,mheap会向操作系统申请,申请单位为heapArena,64M。
heapArena
通过下面这个图来快速知道heapArena的概念。(下面图中的单词拼多了一个a,应该为heapArena)
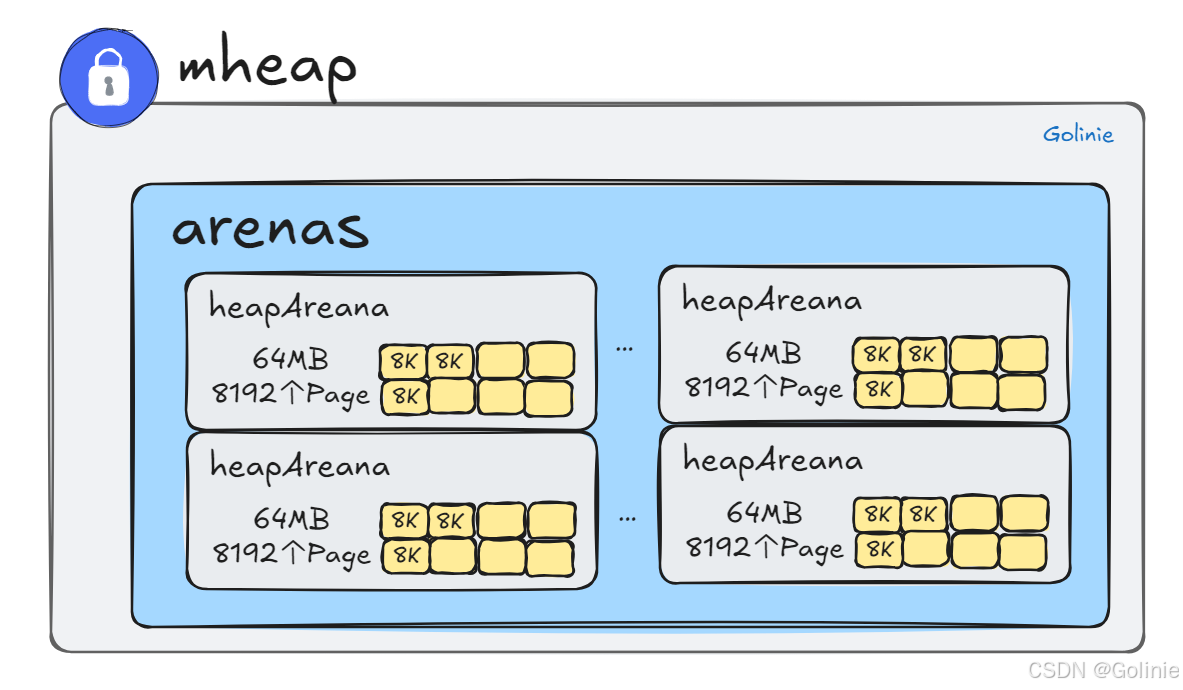
我们说过,mheap上游是mcentral,mcentral中的mspan如果不够了会向mheap申请,mheap下游就是直接跟操作系统虚拟内存对接,mheap如果还不够,就直接向虚拟内存申请了,一次性申请的大小是heapArena,也就是64MB,访问mheap的时候需要加锁,因为是全局唯一的。
mheap是对内存块的管理对象,通过page为最小内存存储单元进行管理。一系列的page组合成一个heapAreana。
所以,每个 heapArena 包含 8192 个页,大小为 8192 * 8KB = 64 MB。
heapArena 记录了页到 mspan 的映射. 因为 GC 时,通过地址偏移找到页很方便,但找到其所属的 mspan 不容易,所以我们需要通过这个映射信息进行辅助。
每个heapArena包含一个bitmap,标记当前这个heapArena的使用情况。主要是为了GC垃圾回收,bitmap有两种标记,一种是标记对应地址中是否存在对象,另一种标记这个对象是否被GC模块标记过,所以当前heapArena中所有的Page都会被bitmap标记。
空闲页索引pageAlloc
到这里已经有些比较绕了,再回顾一下这个图。注意这个只是逻辑图!
首先,pageAlloc是一种基于基数树(Radix Tree)的索引结构,它用于快速查找和分配空闲页。pageAlloc通过组织和管理空闲页的索引信息,优化了内存分配过程中的查找效率,从而提高了内存分配的性能。基数树是一种高效的数据结构,它能够快速地定位和检索数据,这使得pageAlloc能够迅速找到满足分配要求的连续页空间。在内存分配过程中,pageAlloc会根据需要分配的页数量,在基数树中查找合适的空闲页范围,如果找到合适的空闲页,就进行分配;如果没有找到,则可能需要触发垃圾回收或者向操作系统请求更多的内存资源。
3. Go对象分配
Go中分配对象的方式有几种常见的,比如new(T)、&T{}、make(T)等。这几种方法都会最终通过mallocgc方法进行分配。
Go会根据obj的大小,将对象分为3类,分别是tiny微对象(0,16B)、small小对象【16B,32KB】、large大对象(32KB以上)。
不同类型的对象,会有不同的分配策略,这些分配策略可以在mallocgc 方法中查看。
微对象的分配流程如下。
- 从P专属的
mcache的tiny分配器中取对应内存,这个过程是无锁的。 - 根据对应的
spanClass,从p专属mcache缓存的mspan中取内存,无锁。 - 根据对应的
spanClass从对应的mcentral中取msapn填充到mcache,然后从mspan中取内存,spanClass粒度的锁。 - 根据对应的
spanClass,从mheap的页分配器pageAlloc中取得足够数量空闲页组装成mspan填充到mcentral中,然后再填充到mcache中,然后从mspan中取内存,涉及到了mheap,所以是全局锁。 mheap向操作系统申请内存,更新页分配器的索引信息,然后重复步骤4.
小对象的分配流程就是跳过上述的步骤1,直接执行2-5即可。
对于大的对象,跳过步骤1-3,直接执行步骤4和5,因为大对象是0号等级,所以在mcentral里面找不到对应的spanClass等级,只能去从步骤4开始直接与堆进行交互操作。
mallocgc函数
进行对象实例的时候,都会进行mallocgc这个方法。
malloc是内存分配的意思,gc是垃圾回收的意思,这个函数不仅是进行内存分配,还是gc垃圾回收的入口,所以叫做mallocgc。
malloc.go代码如下。
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// ...
// 获取 m
mp := acquirem()
// 获取当前 p 对应的 mcache
c := getMCache(mp)
var span *mspan
var x unsafe.Pointer
// 根据当前对象是否包含指针,标识 gc 时是否需要展开扫描
noscan := typ == nil || typ.ptrdata == 0
// 是否是小于 32KB 的微、小对象
if size <= maxSmallSize {
// 小于 16 B 且无指针,则视为微对象
if noscan && size < maxTinySize {
// tiny 内存块中,从 offset 往后有空闲位置
off := c.tinyoffset
// 如果大小为 5 ~ 8 B,size 会被调整为 8 B,此时 8 & 7 == 0,会走进此分支
if size&7 == 0 {
// 将 offset 补齐到 8 B 倍数的位置
off = alignUp(off, 8)
// 如果大小为 3 ~ 4 B,size 会被调整为 4 B,此时 4 & 3 == 0,会走进此分支
} else if size&3 == 0 {
// 将 offset 补齐到 4 B 倍数的位置
off = alignUp(off, 4)
// 如果大小为 1 ~ 2 B,size 会被调整为 2 B,此时 2 & 1 == 0,会走进此分支
} else if size&1 == 0 {
// 将 offset 补齐到 2 B 倍数的位置
off = alignUp(off, 2)
}
// 如果当前 tiny 内存块空间还够用,则直接分配并返回
if off+size <= maxTinySize && c.tiny != 0 {
// 分配空间
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.tinyAllocs++
mp.mallocing = 0
releasem(mp)
return x
}
// 分配一个新的 tiny 内存块
span = c.alloc[tinySpanClass]
// 从 mCache 中获取
v := nextFreeFast(span)
if v == 0 {
// 从 mCache 中获取失败,则从 mCentral 或者 mHeap 中获取进行兜底
v, span, shouldhelpgc = c.nextFree(tinySpanClass)
}
// 分配空间
x = unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
size = maxTinySize
} else {
// 根据对象大小,映射到其所属的 span 的等级(0~66)
var sizeclass uint8
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[divRoundUp(size, smallSizeDiv)]
} else {
sizeclass = size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]
}
// 对应 span 等级下,分配给每个对象的空间大小(0~32KB)
size = uintptr(class_to_size[sizeclass])
// 创建 spanClass 标识,其中前 7 位对应为 span 的等级(0~66),最后标识表示了这个对象 gc 时是否需要扫描
spc := makeSpanClass(sizeclass, noscan)
// 获取 mcache 中的 span
span = c.alloc[spc]
// 从 mcache 的 span 中尝试获取空间
v := nextFreeFast(span)
if v == 0 {
// mcache 分配空间失败,则通过 mcentral、mheap 兜底
v, span, shouldhelpgc = c.nextFree(spc)
}
// 分配空间
x = unsafe.Pointer(v)
// ...
}
// 大于 32KB 的大对象
} else {
// 从 mheap 中获取 0 号 span
span = c.allocLarge(size, noscan)
span.freeindex = 1
span.allocCount = 1
size = span.elemsize
// 分配空间
x = unsafe.Pointer(span.base())
}
// ...
return x
}
tiny对象分配内存
P独有的mcache会有一个微对象分配器,基于offset偏移线性移动的方式对微对象进行分配,每16B是一个块,对象依据其大小,向上取整为2的整数次幂(2、4、8、16)进行空间补齐,然后进行分配。
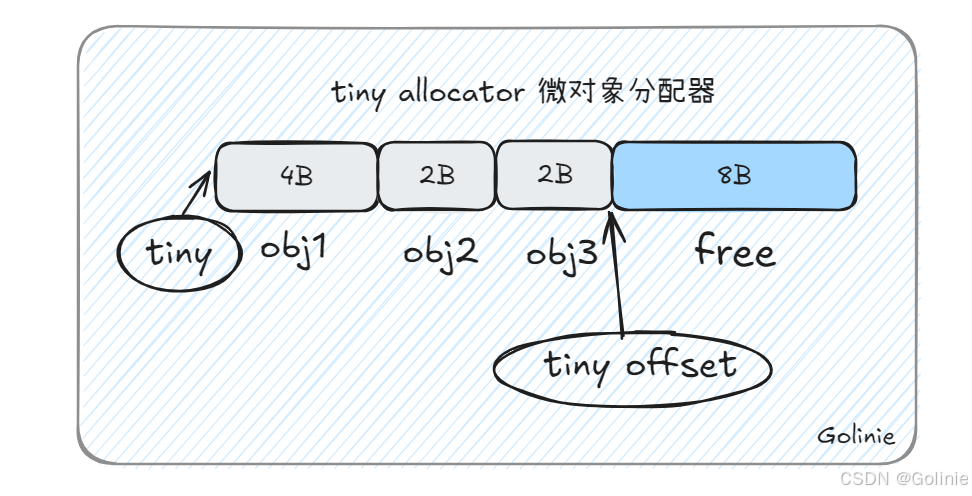
如果tiny对象分配器没有分配成功,那么就会到mcache分配。
首先根据对象的大小,映射给其所属的mspan的等级。对应span等级下,分配给每个对象的空间大小,尝试获取mcache中的span,如果分配失败,就通过mcentral、mheap继续。
// 根据对象大小,映射到其所属的 span 的等级
var sizeclass uint8
// get size class ....
// 对应 span 等级下,分配给每个对象的空间大小(0~32KB)
// 包含了noscan,组装在一起得到spanClass
spc := makeSpanClass(sizeclass, noscan)
// 获取 mcache 中的 span
span = c.alloc[spc]
// 从 mcache 的 span 中尝试获取空间
// 通过ctz64算法,在bit map上找到首个obj空位
// 也就是在mspan中,用ctz64算法,根据mspan.allocCache的bitmap信息快速找到空闲的object块并且返回。
v := nextFreeFast(span)
if v == 0 {
// mcache 分配空间失败,则通过 mcentral、mheap 继续
v, span, shouldhelpgc = c.nextFree(spc)
}
// 分配空间
x = unsafe.Pointer(v)
当mspan也没有可以分配的obj内存块的时候,会进入到mcache.nextFree方法进行继续获取空间的操作。
也就是上面代码中的。
if v == 0 {
// mcache 分配空间失败,则通过 mcentral、mheap 继续
v, span, shouldhelpgc = c.nextFree(spc)
}
从mcentral或者mheap中获取到了新的span之后,填充到mcache的alloc中的span集合当中去,然后再把对应的方法返回。
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) {
s = c.alloc[spc]
// ...
// 从 mcache 的 span 中获取 object 空位的偏移量
freeIndex := s.nextFreeIndex()
if freeIndex == s.nelems {
// ...
// 倘若 mcache 中 span 已经没有空位,则调用 refill 方法从 mcentral 或者 mheap 中获取新的 span
c.refill(spc)
// ...
// 再次从替换后的 span 中获取 object 空位的偏移量
s = c.alloc[spc]
freeIndex = s.nextFreeIndex()
}
// ...
v = gclinkptr(freeIndex*s.elemsize + s.base())
s.allocCount++
// ...
return
}
4.结合GMP模型来看内存模型
已经完整的对整个内存模型有了解了,接下来可以结合下GMP来看看内存模型,帮助我们更好的梳理。
再来回顾一下关键的一些概念,Page是Go中内存管理与虚拟内存交互内存的最小单元,8KB大小。mspan就是一组连续的Page,mspan的大小是page的整数倍。
mcache是与GMP模型中的P所绑定,而不是线程绑定,真正可运行的线程M的数量与P的数量一致,也就是GOMAXPROCS个。mcache与P绑定可以更节省内存空间的使用,保证每个G使用mcache的时候不需要加锁就可以获得内存。
实际上我们上层应用向go内存模型取内存,就是从span中分配一个obj出去。在上边我们已经提到过一次了。
span size class 是一块内存的所属规模大小,是针对obj size来计划分的,比如obj在1-8B之间的都属于 size class 1级别,obj大小在8B-16B之间的都数据size Class 2级别。
span size class是 针对span进行划分的,是span大小的级别,一个span size class 会对应两个span ,其中一个span存放需要GC扫描的对象,也就是包含了指针的对象,另一个span包含不需要GC的对象。
我们提到过mcache会冗余136个spanClass,也就是68x2,分别对应scan和noscan。
所以mcache的展开内部结构就是这样对应的关系。协程从mcache上获取内存不需要加锁,因为一个P只有一个M(线程)在上面运行,不可能出现竞争,所以没有锁的限制,加速了内存的分配。
mcache中每个span class都会对应一个mspan,不同的span class的mspan的总大小不一样,所以需要的page也不一样。如图所示,比较清晰能够看出其中关系。
go对内存规格为0的对象(也就是span class 为0 和1)申请做了特殊处理,也就是更大的内存或者真正的0内存对象,直接会返回一个固定地址,也就是直接跟mheap交互获得地址,而不会走正常的内存管理逻辑。
如果申请struct{}、[0]int,这种,就会直接返回一个固定地址。
这也是为什么通过channel做同步的时候,发送一个struct{}数据,不会申请任何内存,能够节省内存空间。

协程与mcache的内存交换单位是obj,mcache与mcentral的内存交换单位是span。
mcentral对于每个级别会存两个span list链表,一个是没有空间的span list,一个是空的span list。
表示还有可用空间的 Span 链表。链表中的所有 Span 都至少有 1 个空闲的 Object 空间。如果 mcentral 上游 MCache 退还 Span,会将退还的 Span 加入到 NonEmpty Span List 链表中。
tiny对象分配
int32、byte、bool这种tiny微对象如过没有tiny分配的情况下,会经常申请一个8B的空间,这样类似bool或者1个字节的byte,也都会独享这个8B的空间,会造成空间浪费。
如果协程申请的空间小于等于8B,那么会匹配的span size class = 1的8B空间。
而Tiny空间是从span size class =2 中获取一个16B的obj作为tiny的对象的分配空间。
当大量的微小对象都是用8B的时候会造成大量浪费,所以将小于16B的申请统一归为tiny微对象申请。然后以字节对齐的方式进行内存分配。
需要注意的是,如果申请的对象有指针,会进入小对象的申请流程(因为需要GC扫描流程),而没有指针,才会进入tiny微对象申请流程,如果tiny空间的16B没有多余的内存大小了,会从span size class = 2(也就是第一个noscan的mspan中)申请一个16B的object对象放在tiny空间中。
5.总结
设计思想
下次有机会再梳理一篇TCMalloc的文章。
无论是操作系统虚拟内存管理,还是 C++ 的 TCMalloc、Golang 内存模型,均有一个共同特点,就是分层的缓存机制。
针对不同的内存场景采用不同的独特解决方式,提高局部性逻辑和细微粒度内存的复用率。这也是程序设计的至高理念。
一些问题?
为什么mcache与P绑定?
这里查阅了一些资料包括GPT,按我的理解应该如下:
首先可以, 减少锁竞争:由于每个 P 都有自己的 MCache,当多个 goroutine 在不同的 P 上执行时,它们各自的 MCache 是隔离的,不需要加锁就能获得内存分配。
另外是,避免内存浪费:如果 MCache 直接与 M 绑定,那么每个线程的内存缓存会相对独立且会有较高的内存占用。并且最关键的是,真正可运行的线程M的数量与P的数量一致,如果mcache与线程绑定,那么很多线程是会空闲的,而不是真正可运行的。所以M可运行的数量因为=P的数量,那么与 P 绑定的话就可以通过合理共享内存缓存来节省内存空间。
span的等级到底是66级还是67级或者68级?
截止目前,3月5日,Go官方github中的代码注释是1-67种,算上0,一共是68种,可以看到源代码的相关参考如下。
[https://github.com/golang/go/blob/master/src/runtime/sizeclasses.go]官方地址如上,很多博客或者资料写的是1-66种,可能是因为两年前的版本,是1-66种,目前已经是67种了。
//go:generate go run mksizeclasses.go
package runtime
// class bytes/obj bytes/span objects tail waste max waste min align
// 1 8 8192 1024 0 87.50% 8
// 2 16 8192 512 0 43.75% 16
// 3 24 8192 341 8 29.24% 8
// 4 32 8192 256 0 21.88% 32
// 5 48 8192 170 32 31.52% 16
// 6 64 8192 128 0 23.44% 64
// 7 80 8192 102 32 19.07% 16
// 8 96 8192 85 32 15.95% 32
// 9 112 8192 73 16 13.56% 16
// 10 128 8192 64 0 11.72% 128
// 11 144 8192 56 128 11.82% 16
// 12 160 8192 51 32 9.73% 32
// 13 176 8192 46 96 9.59% 16
// 14 192 8192 42 128 9.25% 64
// 15 208 8192 39 80 8.12% 16
// 16 224 8192 36 128 8.15% 32
// 17 240 8192 34 32 6.62% 16
// 18 256 8192 32 0 5.86% 256
// 19 288 8192 28 128 12.16% 32
// 20 320 8192 25 192 11.80% 64
// 21 352 8192 23 96 9.88% 32
// 22 384 8192 21 128 9.51% 128
// 23 416 8192 19 288 10.71% 32
// 24 448 8192 18 128 8.37% 64
// 25 480 8192 17 32 6.82% 32
// 26 512 8192 16 0 6.05% 512
// 27 576 8192 14 128 12.33% 64
// 28 640 8192 12 512 15.48% 128
// 29 704 8192 11 448 13.93% 64
// 30 768 8192 10 512 13.94% 256
// 31 896 8192 9 128 15.52% 128
// 32 1024 8192 8 0 12.40% 1024
// 33 1152 8192 7 128 12.41% 128
// 34 1280 8192 6 512 15.55% 256
// 35 1408 16384 11 896 14.00% 128
// 36 1536 8192 5 512 14.00% 512
// 37 1792 16384 9 256 15.57% 256
// 38 2048 8192 4 0 12.45% 2048
// 39 2304 16384 7 256 12.46% 256
// 40 2688 8192 3 128 15.59% 128
// 41 3072 24576 8 0 12.47% 1024
// 42 3200 16384 5 384 6.22% 128
// 43 3456 24576 7 384 8.83% 128
// 44 4096 8192 2 0 15.60% 4096
// 45 4864 24576 5 256 16.65% 256
// 46 5376 16384 3 256 10.92% 256
// 47 6144 24576 4 0 12.48% 2048
// 48 6528 32768 5 128 6.23% 128
// 49 6784 40960 6 256 4.36% 128
// 50 6912 49152 7 768 3.37% 256
// 51 8192 8192 1 0 15.61% 8192
// 52 9472 57344 6 512 14.28% 256
// 53 9728 49152 5 512 3.64% 512
// 54 10240 40960 4 0 4.99% 2048
// 55 10880 32768 3 128 6.24% 128
// 56 12288 24576 2 0 11.45% 4096
// 57 13568 40960 3 256 9.99% 256
// 58 14336 57344 4 0 5.35% 2048
// 59 16384 16384 1 0 12.49% 8192
// 60 18432 73728 4 0 11.11% 2048
// 61 19072 57344 3 128 3.57% 128
// 62 20480 40960 2 0 6.87% 4096
// 63 21760 65536 3 256 6.25% 256
// 64 24576 24576 1 0 11.45% 8192
// 65 27264 81920 3 128 10.00% 128
// 66 28672 57344 2 0 4.91% 4096
// 67 32768 32768 1 0 12.50% 8192
0级到底是什么?是更大对象吗?
小徐先生1212教程中写道0级是为了更大对象的申请,可是更大对象的申请应该是直接跟mheap进行申请,并不是所谓的0级,在刘丹冰老师的博客中,验证了申请0级span class对象的时候,返回的地址都是一样的。所以我觉得0级应该是特殊对象,比如struct{}这种,用来做channel通道通信。
我们来看看malloc.go这部分的源码。可以很清楚的看到,当大于32KB的时候,直接从heap中申请。
而当size==0的时候,直接返回一个zerobase的地址,那么这个zerobase是什么呢?
// Al Allocate an object of size bytes.
// Sm Small objects are allocated from the per-P cache's free lists.
// La Large objects (> 32 kB) are allocated straight from the heap.
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// ……(省略部分代码)
if size == 0 {
return unsafe.Pointer(&zerobase)
}
//……(省略部分代码)
}
运行下面的测试代码,看看输出结果。
//第一篇/chapter3/MyGolang/zeroBase.go
package main
import (
"fmt"
)
func main() {
var (
//0内存对象
a struct{}
b [0]int
//100个0内存struct{}
c [100]struct{}
//100个0内存struct{},make申请形式
d = make([]struct{}, 100)
)
fmt.Printf("%p\n", &a)
fmt.Printf("%p\n", &b)
fmt.Printf("%p\n", &c[50]) //取任意元素
fmt.Printf("%p\n", &(d[50])) //取任意元素
}
运行结果如下,可以看到全部的 0 内存对象分配,返回的都是一个固定的地址。
go run zeroBase.go
0x11aac78
0x11aac78
0x11aac78
0x11aac78
6. 参考文章
本文撰写过程中主要有参考以下两位老师的文章教程,感谢:
刘丹冰老师的Go三关:https://learnku.com/articles/68142
小徐先生1212的教程:https://www.bilibili.com/video/BV1bv411c7bp