结构参数相关性分析
01 参数相关性研究的目的
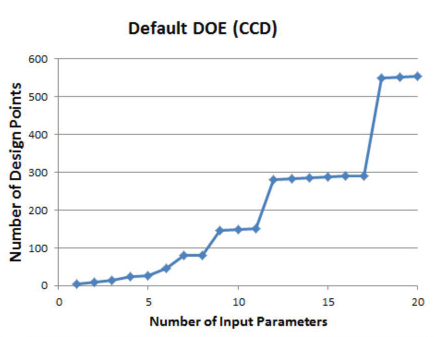
• 在 DOE 分析中, 设计点的数量随着输入参数的增加而迅速增加,这样将降低DOE分析的效率
• 因此,建议用户通过相关性分析剔除对DOE分析重要的样本,提高DOE分析的效率
• 下面的参数相关性工具可以识别重要的参数:相关性矩阵, 确定性矩阵, 相关性散点图和灵敏度图
• 当输入参数超过15个时,参数的相关性分析就非常必要
02 样本
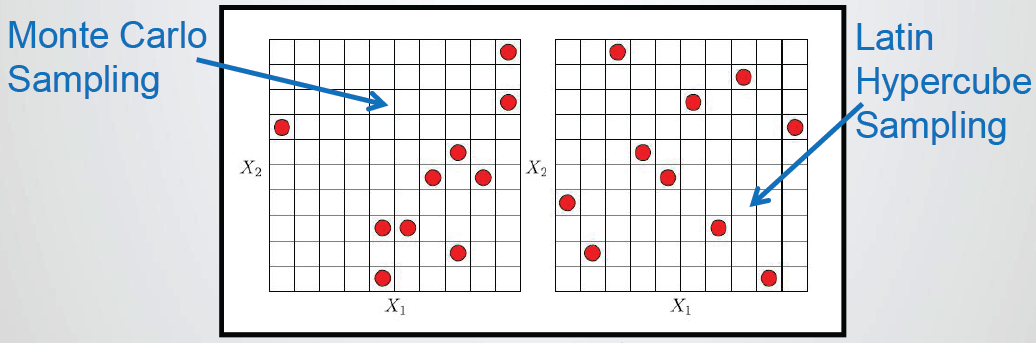
• 参数相关性分析基于设计空间的随机样本(如采用蒙特卡罗、拉丁超立方等方法生成样本)进行参数相关性计算,确定参数之间的关联性
• Latin hypercube – 设计点随机生成,且能保证在同一位置不会出现两个样本点。
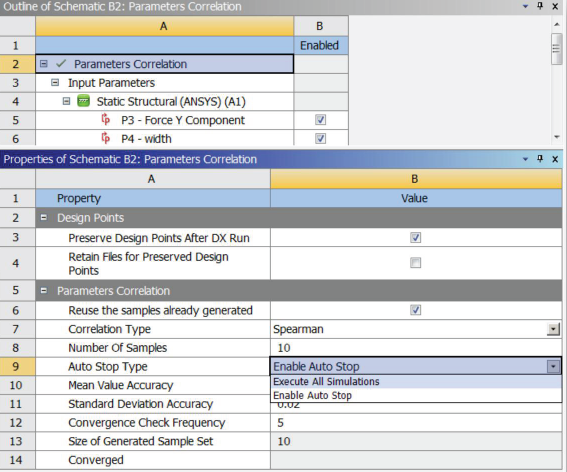
• 执行模拟计算用户可以指定样本数量
• 自动停止类型
当用户选择该类型后,会在其下方出现输入参数的平均值精度,标准方差精度和收敛的检查频率选项。每次迭代程序都会进行对其精度检查,如果满足设置的要求就会终止迭代计算,相对执行所有参数计算选项的效率更高,如果执行了设置样本数,还没有达到精度要求,程序也会终止计算。
03 相关系数的计算公式
• WB提供了两种相关系数计算方法:
1) Pearson’s linear correlation
• 采用实际数据评价相关性
• 寻找两个变量之间的线性关系
2) Spearman’s rank correlation
• 使用数据的秩
• 检查两个变量之间的单调关系
• 比线性关系限制少
• 一般认为该方法较为准确,推荐用户使用
• Pearson 相关系数(Pearson’s linear correlation)
皮尔逊相关系数是衡量变量间线性关联程度最常用的指标。对于给定的样本X和Y,Pearson 相关系数定义为:
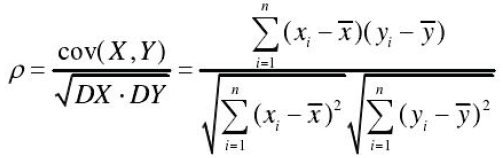

Pearson相关系数的取值范围是[-1,1],其绝对值越接近于1,说明两个变量之间的线性相关性越强;系数为正,表明两变量具有正相关关系;相反,负系数表示负相关关系。Pearson相关系数仅仅能够判断两个随机变量间是否存在线性相关关系,但有两个特殊关系需要格外注意:(1)相关系数为0只能表明两个变量线性无关,并不意味着两者相互独立。比如对于满足Y=X2的两个随机变量,虽然两者的线性相关系数为0,但是两者并不相互独立;(2)相关系数为1不能意味着两个变量之间一定存在线性关系。比如对于X服从[6, 8]上均匀分布并满足Y=X2的两个变量,两者相关系数为0.9999,但两变量间并不存在线性相关性。
• Pearson 相关系数(Pearson’s linear correlation)
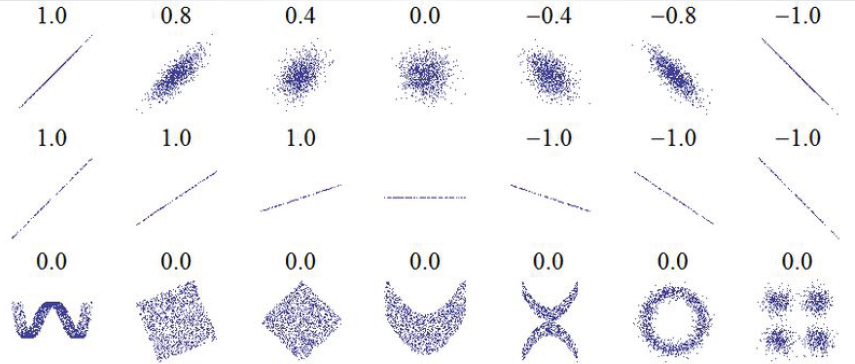
几种的(X,Y)点即相应的X,Y的相应系数
可以看出,相关反映线性关系分散程度和方向(第一行),但是不能反映线性关系时的斜率(第二行),也不能反映出非线性关系的许多方面(最底下一行)。注:图中第二行第四个小图的直线斜率是0,在这种情况下,相关系数是没有意义的,因为Y的方差是零。几种的(x,y)点即相应的x、y的相关系数。
• Pearson 相关系数(Pearson’s linear correlation)
许多学者都提出了通过相关系数大小判断变量相关性的标准。但是正Cohen(1988)所指出的一样,这些标准或多或少的有些武断,不应该过于严格地遵守。相同相关系数对相关性大小的判断取决于不同的背景和目的。同样是0.9的相关系数,在使用很精确的仪器验证物理定律的时候可能被认为是很低的,但是社会科学中,在评定许多复杂因素的贡献时,却可能被认为是很高的相关性。
相关系数与相关性的关系

• Spearman秩相关系数(Spearman’s rank correlation )
Pearson线性相关系数只是许多可能中的一种情况,为了使用Pearson线性相关系数必须假设数据是成对地从正态分布中取得的,并且数据至少在逻辑范畴内必须是等间距的数据。如果这两条件不符合,一种可能就是采用Spearman秩相关系数来代替Pearson线性相关系数。Spearman秩相关系数是一个非参数性质(与分布无关)的秩统计参数,由Spearman在1904年提出,用来度量两个变量之间联系的强弱(Lehmann and D'Abrera1998)。Spearman秩相关系数可以用于R检验,同样可以在数据的分布使得Pearson线性相关系数不能用来描述或是用来描述或导致错误的结论时,作为变量之间单调联系强弱的度量。
Spearman秩相关系数通常被认为是排列后的变量之间的Pearson线性相关系数,在实际计算中,有更简单的计算ρs的方法。假设原始的数据xi,yi已经按从大到小的顺序排列,记x’i,y’i为原xi,yi在排列后数据所在的位置,则x’i,y’i称为变量x’i,y’i的秩次,则di=x’i-y’i为xi,yi的秩次之差。
如果没有相同的秩次,则ρs可由下式计算
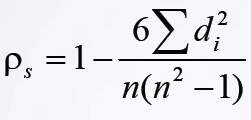
如果有相同的秩次存在,那么就需要计算秩次之间的Pearson的线性相关系数
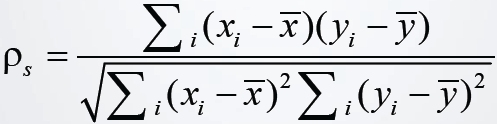
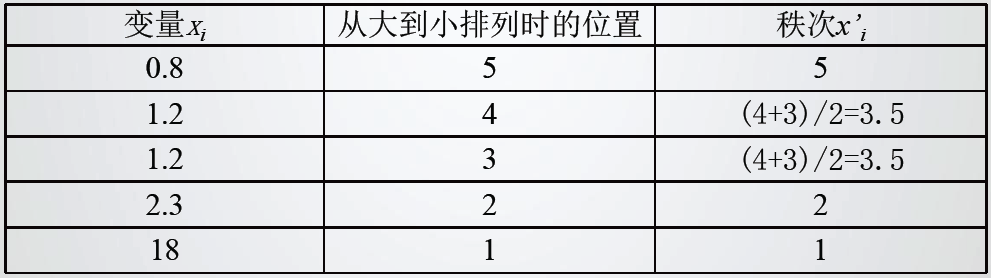
一个相同的值在一列数据中必须有相同的秩次,那么在计算中采用的秩次就是数值在按从大到小排列时所在位置的平均值。表1为一个球平均秩次的例子。注意在秩次相同时,用他们在排列后的数据中所在的位置的平均值作为秩次。
表1 有相同数值时秩次的计算
Spearman秩相关系数的符号表示X和Y之间联系的方向。如果Y随着X的增加而增加,那么Spearman秩相关系数是正的,反之,若果Y随着X的增加而减小,Spearman秩相关系数就是负的。Spearman秩相关系数为0表示随着X的增加,Y没有增大或减小的趋势。随着X和Y越来越接近严格单调的函数关系,Spearman秩相关系数在数值上越来越大。当X、Y有严格单增的关系是,它们之间的Spearman秩相关系数为1,反之,在X、Y有严格单减的关系时,Spearman秩相关系数为-1。严格单增的关系为对于任意的两对数据值Xi,Yi和Xj,Yj,Xi-Yi和Xj-Yj都具有相同的符号。严格单减则上述差值在任何时候都具有相反的符号。
Spearman秩相关系数经常被称为非参数相关系数,这具有两层含义:第一,只要在X和Y具有单调的函数关系的关系,那么X和Y就是完全Spearman相关的,这与Pearson相关性不同,后者只有在变量之间具有线性关系时才是完全相关的。两外一个关于Spearman秩相关系数的非参数性的理解就是样本之间精确的分布可以在不知道X和Y的联合概率密度函数时获得。
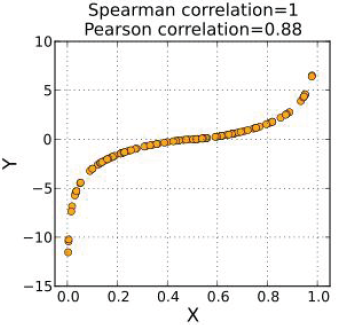
不管变量之间的关系是不是线性的,只要变量之间具有严格的单调增加的函数关系,变量之间的Spearman秩相关系数就是1,相同情况下,Pearson相关性在变量不是线性函数关系时,并不是完全相关的。
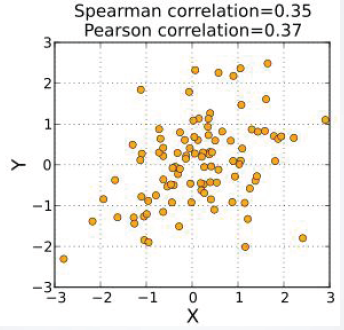
在数据大略地呈椭圆形分布,而且没有明显的外形轮廓的时候,Spearman秩相关系数和Pearson线性相关系数大小比较接近。
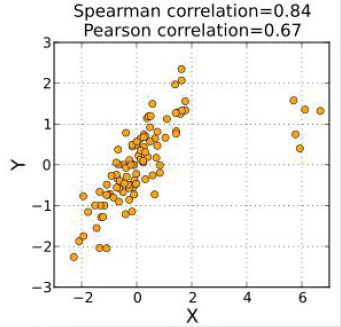
Spearman秩相关系数对样本的尾部与具有明显的外形轮廓样本偏离比较大的情况没有Pearson线性相关系数敏感。
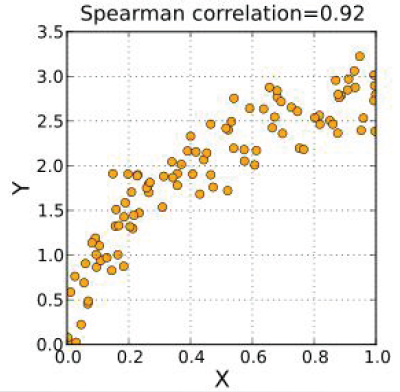
正的Spearman秩相关系数对应于X、Y之间单调增加的变化趋势,
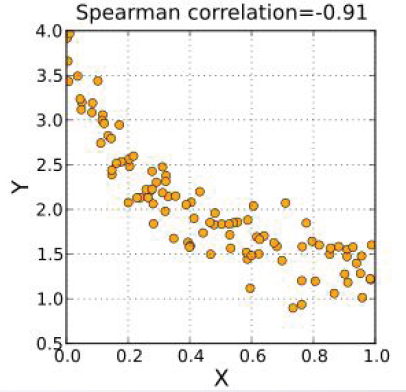
负的Spearman秩相关系数对应于X、Y之间单调减小的变化趋势。
• Spearman秩相关系数与Pearson 相关系数对比
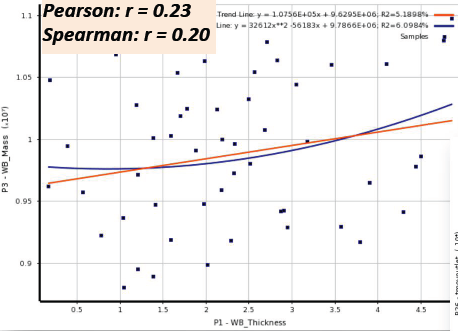
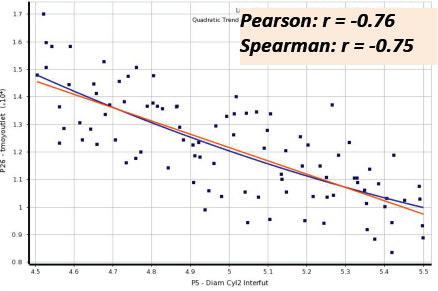
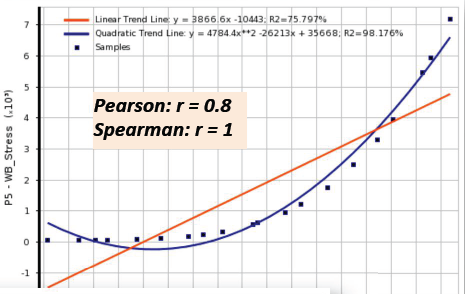
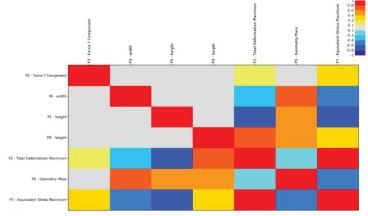
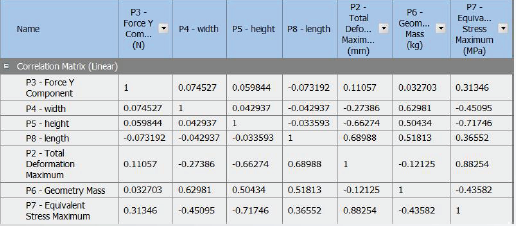
04相关矩阵和图表
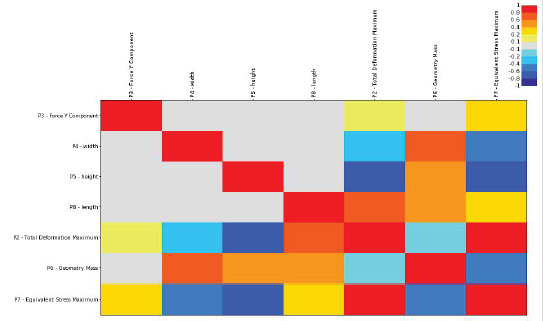
• 相关矩阵表明两个变量之间是否存在关系,以及参数之间的
关系是正值还是负值。
• DX提供矩阵和图表分析参数的相关性。
• 两个参数之间的相关系数越接近-1或1,相关性越强。
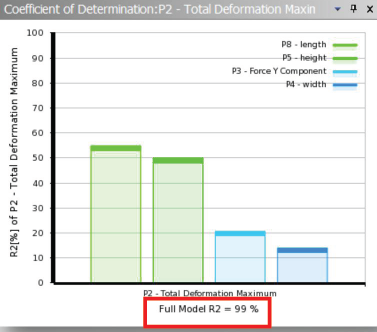
05确定性矩阵和图表
• 确定性矩阵输出参数之间的二次系数。
• 拟合优度(Goodness of Fit)是指回归直线对观测值的拟合程度,度量拟合优度的统计量是确定系数R2,R2的取值范围为(0,1),越接近1说明说明回归直线对观测值的拟合程度越好;反之,越接近0拟合程度越差。
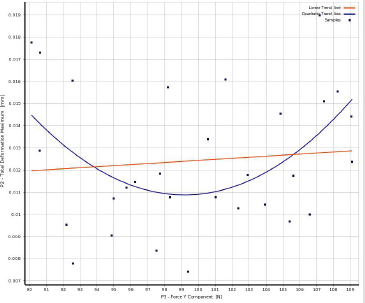
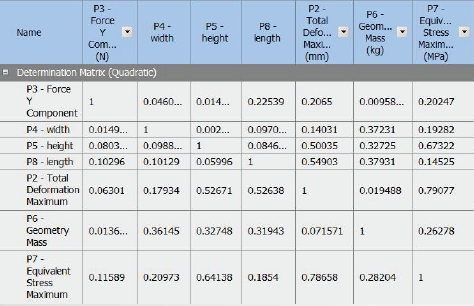
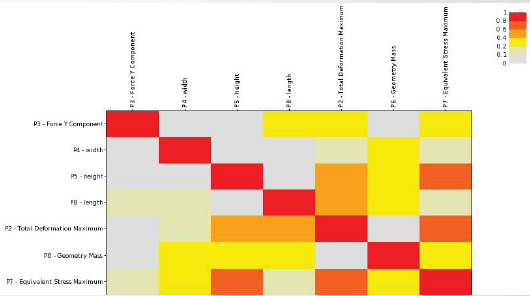
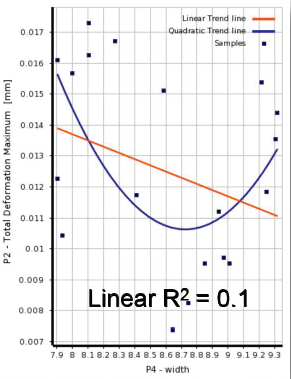
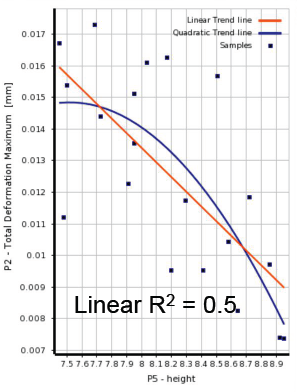
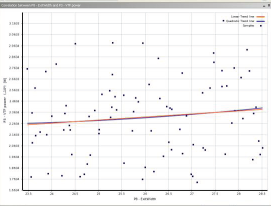
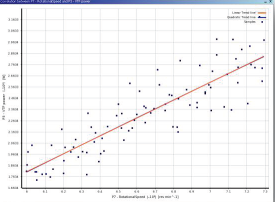
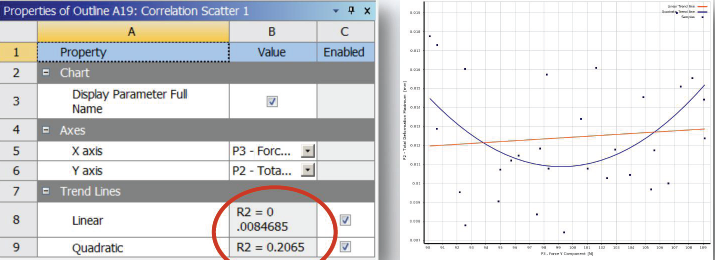
06相关性散点图
• Correlation scatter allows you to plot linear and quadratic trend lines for the samples and extractthe linear and quadratic coefficient of determination (R-square)
• The closer the samples will lie to the curve, the closer the coefficient of determination will be to 1
• If the relationship between parameters is more complex and can not be explained completely with a linear or quadratic correlation, it will be more difficult to build a Standard Response Surface (Full2nd order polynomial): in this case, it's advised to use other response surface types (Kriging, NonParametric Regression...)
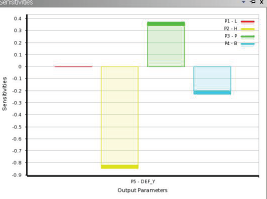
07参数关联性的其他评价工具
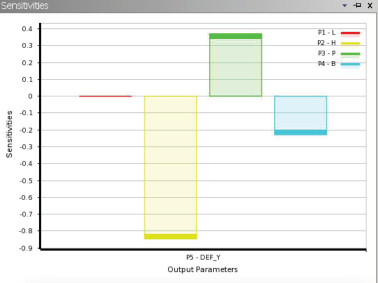
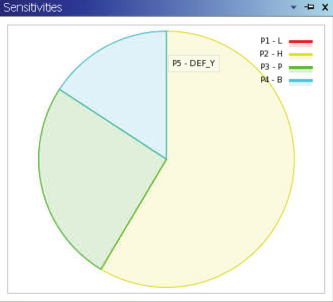
• 全局敏感性(灵敏度)图
• 显示输入参数对输出参数的影响程度
• +值表明输出参数随着输入参数的增加而增加
• -值表明输出参数随着输入参数的增加而减小
• 基于 Spearman-Rank Order Correlation coefficients的灵敏度计算方法可以在同时计算正负灵敏度。
• 确定性系数统计图
• Plot the linear or quadratic R-square for any output variable in relation to all input variables
• The closer the R-square is to 100%, the better the data will fit to linear/quadratic curves
• 如果R-square比较小,则无法正确解释输入与输出之间的系数关系。要考虑一些因素对结果的影响,如:数值噪声,网格误差和参数样本数量不足等。