视觉Transformer(DETR)
文章目录
- DETR总体流程
- DETR 中 transformer 结构
- encoder
- decoder
- Obeject Query
- HEAD
- FFN
- LOSS
- 正负样本分配
- 简单的demo
- 不足之处
DETR 是首次将 Transformer结构首次应用到视觉 目标检测中,实现 端到端的目标检测。
传统目标检测路线(yolo代表),大都是:
1、经过卷积模块生成多尺度特征图。
2、特征图上对预置的anchor框进行分类和回归任务。
3、对预测的冗余结果进行NMS处理。
以上流程看起里比较繁琐,为此如果能省去人为干预的预置anchor和后端的NMS,实现端到端,简化整体流程则是一件美妙的事情,DETR就是干这事的。
DETR总体流程
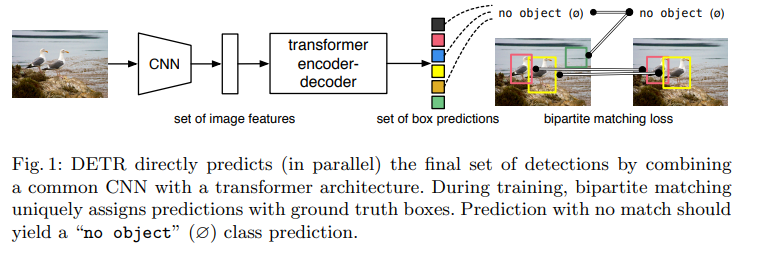
DETR总体流程如上:
1、图像经过CNN backbone 提取特征图。
2、特征展平送到Transformer结构网络中。有关Transformer介绍参考:Transformer理解
3、通过query object和匈牙利匹配的方式进行loss计算。
DETR 中 transformer 结构
对于经典Transformer 这里就不重复介绍。自注意公式为:
O = s o f t m a x ( Q ∗ K T / d k ) ∗ V O = softmax(Q* K^T / \sqrt{d_k}) * V O=softmax(Q∗KT/dk)∗V
当图像经过CNN backbone 卷积后生成的特征图,假设特征图大小为:H * W * C, 把特征展平为 (HW) * C, 就得到L=HW个特征点。把每个特征点当做一个词x,作为Transformer的输入,就等同于自然语言处理的Transformer。
 可以看到,经过self-attention 结构,所有的特征点之间都会计算自注意力权重。计算量则为
O
(
H
∗
W
∗
C
)
2
)
O(H*W*C)^2)
O(H∗W∗C)2)
可以看到,经过self-attention 结构,所有的特征点之间都会计算自注意力权重。计算量则为
O
(
H
∗
W
∗
C
)
2
)
O(H*W*C)^2)
O(H∗W∗C)2)
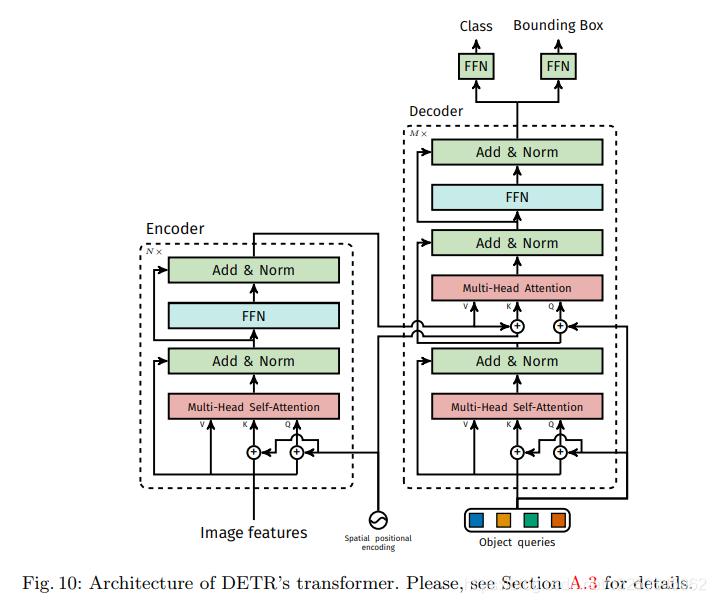
从结构上看,positional encoding在原本的transformer中是直接与input embeding相加,但是在DETR中,是加在特征的Q和K上。
在输出的分支上,DETR利用FFN引出了两个分支,一个做分类,一个做BBox的回归。
encoder
EncoderLayer由四个部分组成:多头注意力机制模块、Add & Norm模块、前向传播模块,一共有6层。
CNN backbone 输出特征图展平 : (B,L ,hidden_dim),B为batchsize, L = H*W 特征图大小,hidden_dim特征向量维度。
进入encoder 需要三个输入:
(1)、输入向量X (图像特征):shape=(B,L ,hidden_dim)
(2)、位置编码:shape=(B,L ,hidden_dim)
(3)、mask:shape=(B,L )
进入encoder:
1、将X分成三份,一份直接作为V值向量,其余两份与位置编码向量直接相加,分别作为K(键向量),Q(查询向量)。
2、将KVQ输入多头注意力模块,输出一个src1,shape=(B,L ,hidden_dim)
3、与原src直接相加短接;
4、进行第1次LN (层一化);
5、linear,Relu激活,dropout,linear还原维度,dropout,再与输入短接。
6、进行第2次LN (层一化);
7、进入下一个encoder。
8、N(N=6)个encoder 堆叠后输出。encoder 结束。
对于层归一化解释:
 层归一化(LN) 与批归一化(BN)区别:
层归一化(LN) 与批归一化(BN)区别:
BN : 在同一通道上对所有batch 做归一化,目的是让这个通道的数据分布均衡。
LN: 在同一batch上对所有通道做归一化,让网络更快、更稳定地收敛。
decoder
decoder 的结构和encoder 相似。在结构上decoder比encoder多一个多头注意力机制和Add & Norm,目的是对query embedding 和 query pos 进行学习。
decoder 的每一层输入除了上一层输出外,还要单独重新加入query pos 和 encoder 的positional encoding。
所以decoder 的输入包括:
query embedding 也就是 object query: shape=(B,num_queries ,hidden_dim)
query pos: shape=(B, num_queries,hidden_dim)
encoder的输出 : shape=(B,L ,hidden_dim)
encoder pos:shape=(B,L ,hidden_dim)
Obeject Query
什么是Obeject Query ?positional encodings是对feature的编码,类似,Obeject Query就相当对anchor 的编码,而且是一个可学习的。好比目标检测中的anchor, 只不过它的位置和大小都不是固定的,是一个学习的参数。训练初始化时是随机参数,但模型训练结束后,Obeject Query参数也就固定下来。
Obeject Query的具体表现形式是query embeding,在源代码中,这是一个torch.nn.Embedding的对象,官方介绍:一个保存了固定字典和大小的简单查找表。
进入 decoder:
1、类似encoder 的 X输入, query embedding(第一次输入是query embeding,第二次是上一层的输出out) 分为3份,其中两份与 query pos 相加得到Q, K;
2、将Q,K,V 送入第一个multihead attention 模块,得到第一个多头输出,shape = (B,num_queries ,hidden_dim)
3、将第一个多头输出进行dropout后与out相加,然后经过第一个LN输出,记为 O。
4、 将O 与query pos 相加作为第二个multihead 的Q, encoder 输出与 encoder pos 相加作为K,encoder 输出做为V。第二个多头与encoder 一模一样。得到输出作为下一个decoder 的query embedding。
5、重复N(N=6)次得到decoder 输出,shape=(B, num_queries,hidden_dim)
6、将output堆叠成一个(B, N, num_queries,hidden_dim)的向量后输出
HEAD
FFN
就是两个全连接层,分别进行分类和bbox坐标的回归。
分类全连接:(B, N, num_queries,hidden_dim) -> (B, N, num_queries,num_classs)
回归全连接:(B, N, num_queries,hidden_dim) -> (B, N, num_queries,4)
LOSS
分类loss:CEloss(交叉熵损失);
回归loss:包括预测框与GT的中心点和宽高的L1 loss以及GIoU loss
正负样本分配
匈牙利匹配:简单暴力。
预测出来的100个框与ground truth做二分类匹配,按照最小权重原则,没有匹配上的款当做背景负样本处理。
简单的demo
class DETRdemo(nn.Module):
"""
Demo DETR implementation.
Demo implementation of DETR in minimal number of lines, with the
following differences wrt DETR in the paper:
* learned positional encoding (instead of sine)
* positional encoding is passed at input (instead of attention)
* fc bbox predictor (instead of MLP)
The model achieves ~40 AP on COCO val5k and runs at ~28 FPS on Tesla V100.
Only batch size 1 supported.
"""
def __init__(self, num_classes, hidden_dim=256, nheads=8,
num_encoder_layers=6, num_decoder_layers=6):
super().__init__()
# create ResNet-50 backbone
self.backbone = resnet50() #backbone选择的是resnet50
del self.backbone.fc #去掉resnet50的全连接层
# create conversion layer
self.conv = nn.Conv2d(2048, hidden_dim, 1) #1*1卷积进行降维,形成hidden_dim个channel的特征向量
# create a default PyTorch transformer
self.transformer = nn.Transformer(
hidden_dim, nheads, num_encoder_layers, num_decoder_layers) #transformer模块
# prediction heads, one extra class for predicting non-empty slots
# note that in baseline DETR linear_bbox layer is 3-layer MLP
self.linear_class = nn.Linear(hidden_dim, num_classes + 1) #分为两个分支,一个分支预测类别(为什么加1呢,因为对与背景,实际上给了一个$的类别)
self.linear_bbox = nn.Linear(hidden_dim, 4) #预测bbox
# output positional encodings (object queries)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
# spatial positional encodings
# note that in baseline DETR we use sine positional encodings
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
# propagate inputs through ResNet-50 up to avg-pool layer
x = self.backbone.conv1(inputs)
x = self.backbone.bn1(x)
x = self.backbone.relu(x)
x = self.backbone.maxpool(x)
x = self.backbone.layer1(x)
x = self.backbone.layer2(x)
x = self.backbone.layer3(x)
x = self.backbone.layer4(x)
# convert from 2048 to 256 feature planes for the transformer
h = self.conv(x)
# construct positional encodings
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
# propagate through the transformer
h = self.transformer(pos + 0.1 * h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1)).transpose(0, 1)
# finally project transformer outputs to class labels and bounding boxes
return {'pred_logits': self.linear_class(h),
'pred_boxes': self.linear_bbox(h).sigmoid()}
不足之处
1、DETR 在检测大目标方面效果很好,但是对于小目标检测的效果不是很理想。
2、由于DETR在 HW特征图上做自注意力,当输入图像很大时,计算量很大, 为
(
H
W
)
2
(HW)^2
(HW)2,因此训练和推理非常消耗时间。
deformable DETR 就是要解决以上的问题。