Spring 原理(很多面试题)
本节目标
1. 掌握Bean的作⽤域和⽣命周期
2. 了解SpringBoot ⾃动配置流程
1. Bean的作用域
1.1 概念
在Spring IoC&DI阶段, 我们学习了Spring是如何帮助我们管理对象的.
1. 通过 @Controller , @Service , @Repository , @Component , @Configuration , @Bean 来声明Bean对象.(告诉spring 帮我管理对象)
2. 通过 ApplicationContext 或者 BeanFactory 来获取对象
3. 通过 @Autowired , Setter ⽅法或者构造⽅法等来为应⽤程序注⼊所依赖的Bean对象
我们来简单回顾⼀下
1. 通过 @Bean 声明bean , 把bean存在Spring容器中
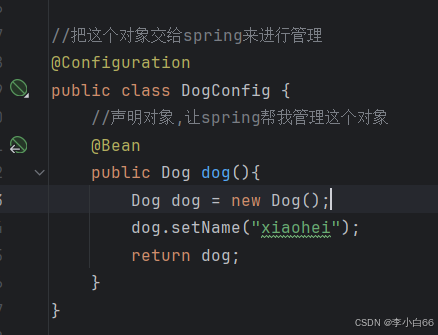
2. 从Spring容器中获取Bean
也可以通过在代码中直接注⼊ApplicationContext的⽅式来获取Spring容器
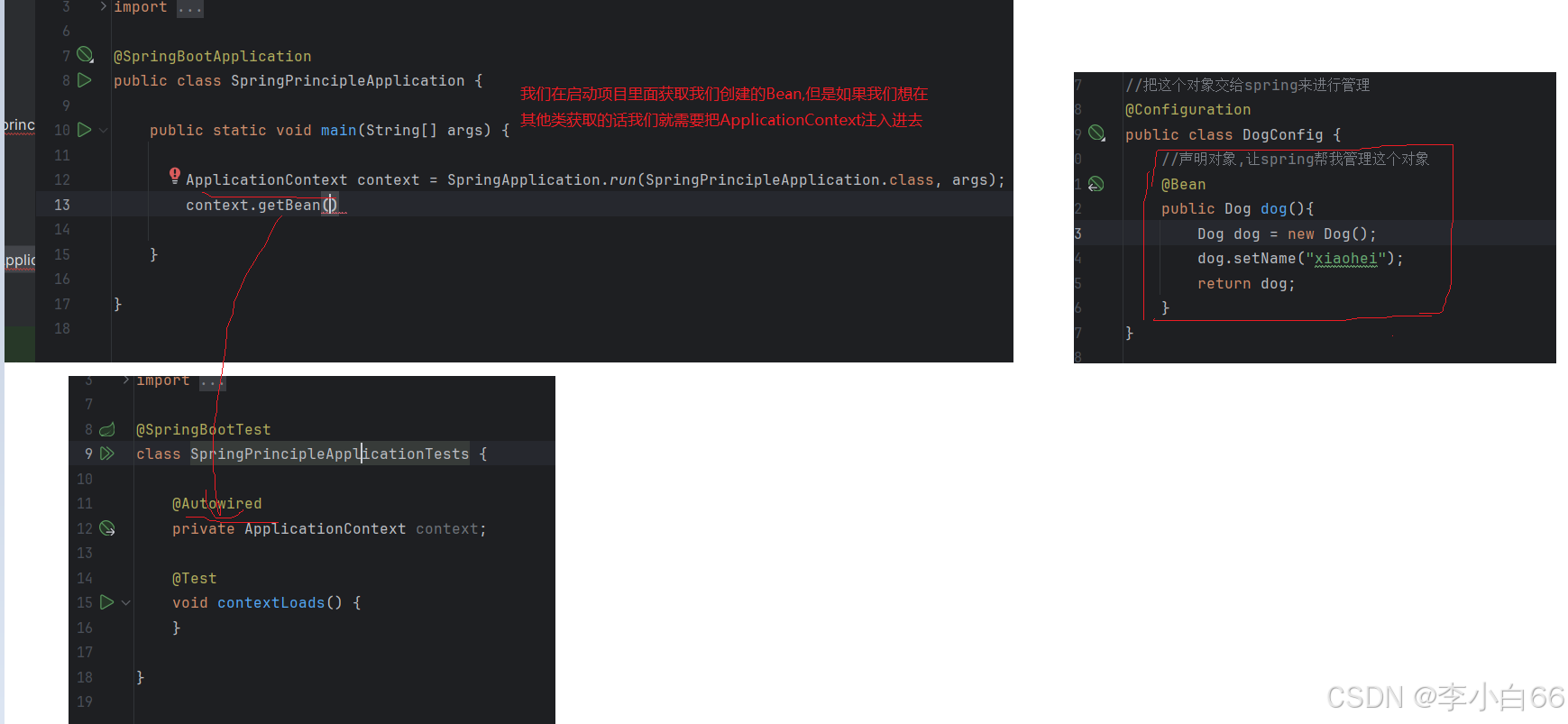
结果:获取成功
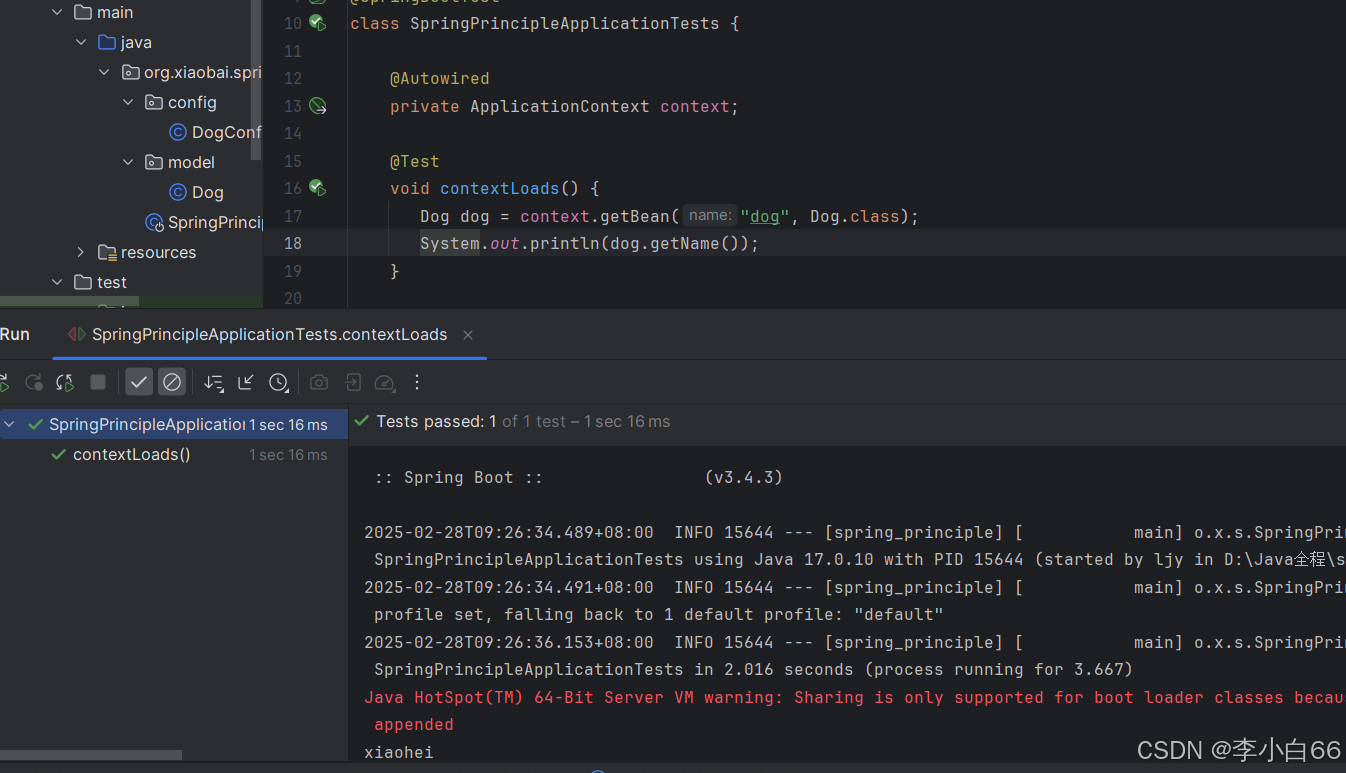
修改代码, 从Spring容器中多次获取Bean: 发现重新获取之后,打印的是修改后的,因此我们推测是同一个对象
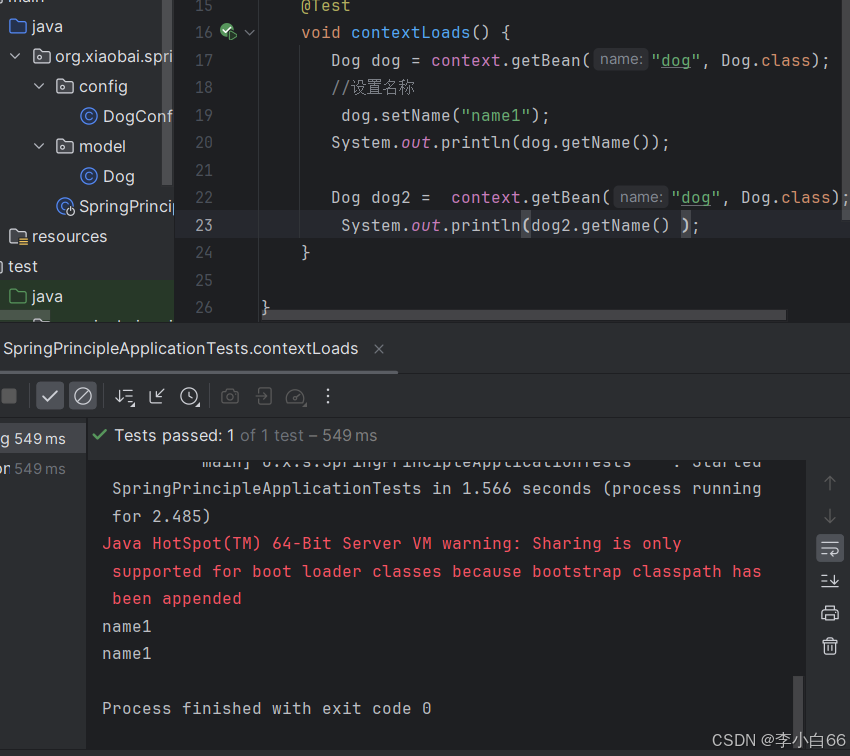
我们通过打印地址来进行比对: 发现一样,说明是一个对象
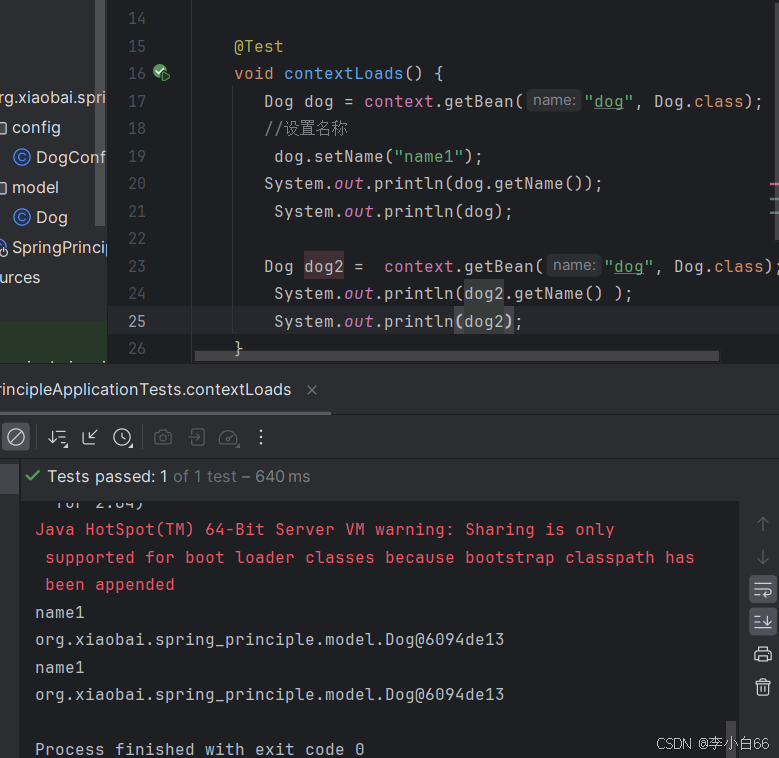
发现输出的bean对象地址值是⼀样的, 说明每次从Spring容器中取出来的对象都是同⼀个.
这也是"单例模式"
单例模式: 确保⼀个类只有⼀个实例,多次创建也不会创建出多个实例
默认情况下, Spring容器中的bean都是单例的, 这种⾏为模式, 我们就称之为Bean的作⽤域.
Bean 的作⽤域是指 Bean 在 Spring 框架中的某种⾏为模式.
⽐如单例作⽤域: 表⽰ Bean 在整个 Spring 中只有⼀份, 它是全局共享的. 那么当其他⼈修改了这个值之后, 那么另⼀个⼈读取到的就是被修改的值.
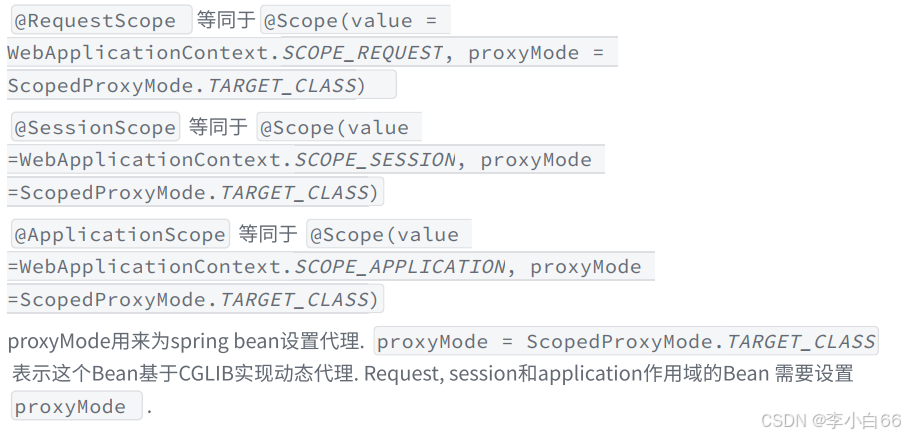
1.2 Bean的作用域
在Spring中⽀持6种作⽤域,后4种在Spring MVC环境才⽣效
1. singleton:单例作⽤域
2. prototype:原型作⽤域(多例作⽤域)
3. request:请求作⽤域
4. session:会话作⽤域
5. Application: 全局作⽤域
6. websocket:HTTP WebSocket 作⽤域
| 作⽤域 | 说明 |
| singleton | 每个Spring IoC容器内同名称的bean只有⼀个实例(单例)(默认) |
| prototype | 每次使⽤该bean时会创建新的实例(⾮单例)(只要我使用这个bean,就会创建新的bean,获取的对象不是一个对象) |
| request | 每个HTTP 请求⽣命周期内, 创建新的实例(web环境中, 了解)(一个请求里面,得到的是一个对象) |
| session | 每个HTTP Session⽣命周期内, 创建新的实例(web环境中, 了解)(在一个会话,得到的是一个对象,来来回回的称之为一个会话) |
| application | 每个ServletContext⽣命周期内, 创建新的实例(web环境中, 了解) |
| websocket | 每个WebSocket⽣命周期内, 创建新的实例(web环境中, 了解) |
范围从小到大.
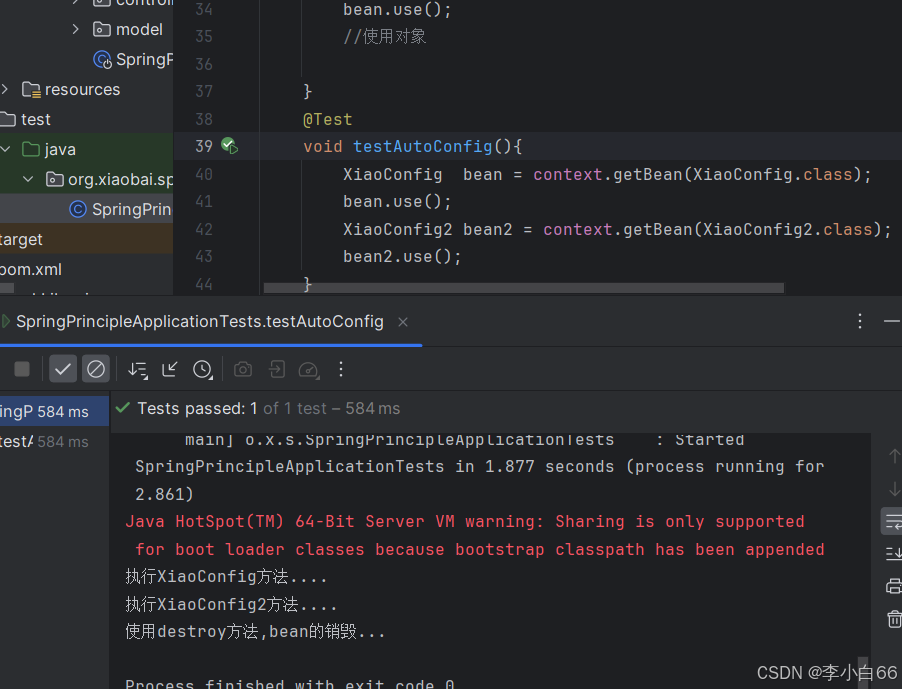
我们进行演示
单例的作用域
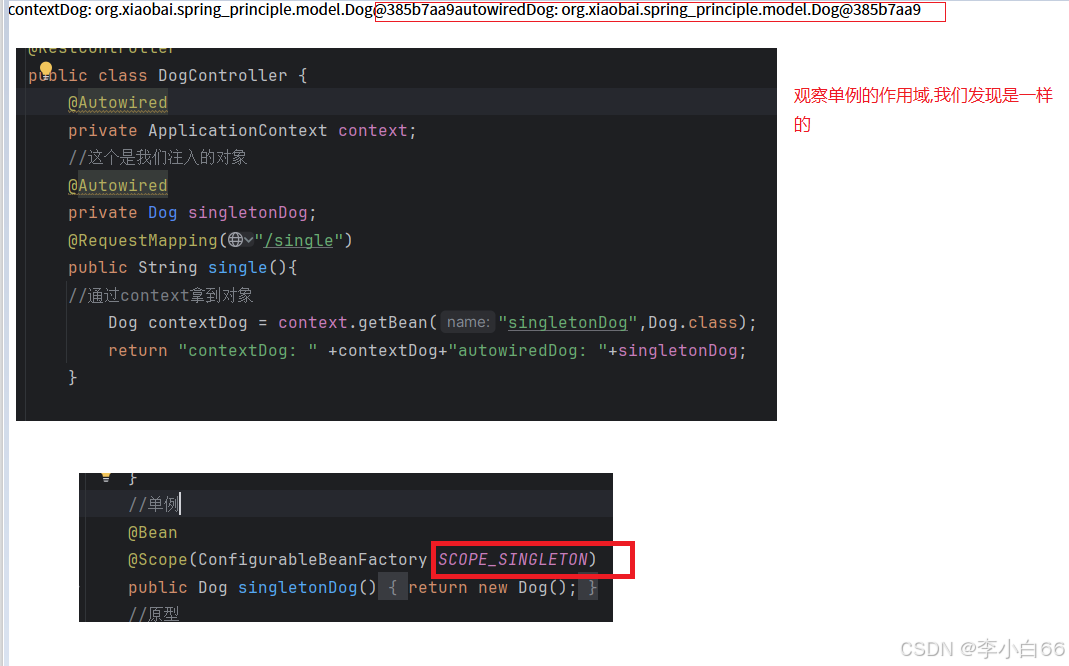
原型模型的作用域
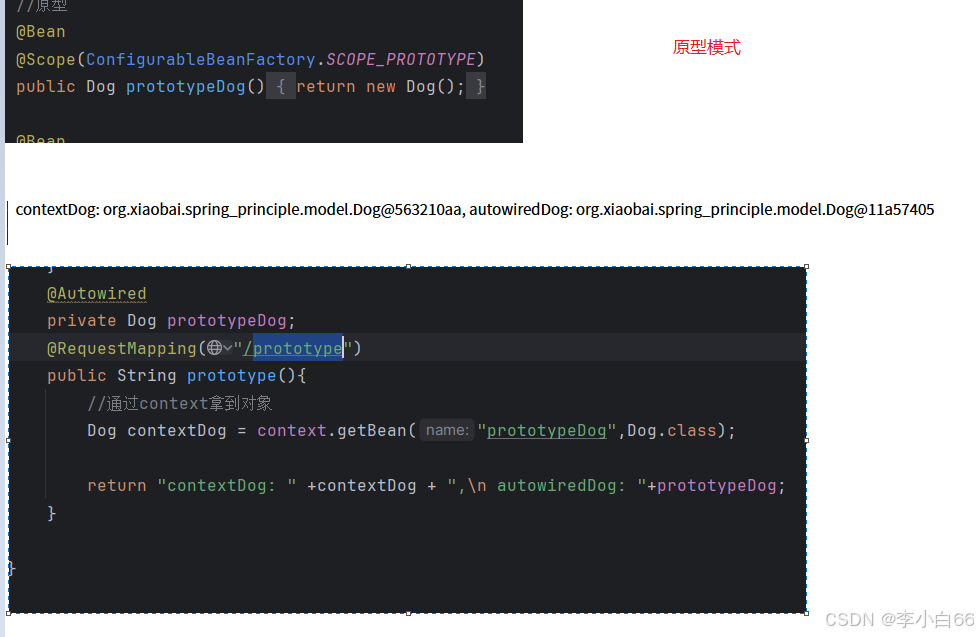 对象产生的时机
对象产生的时机
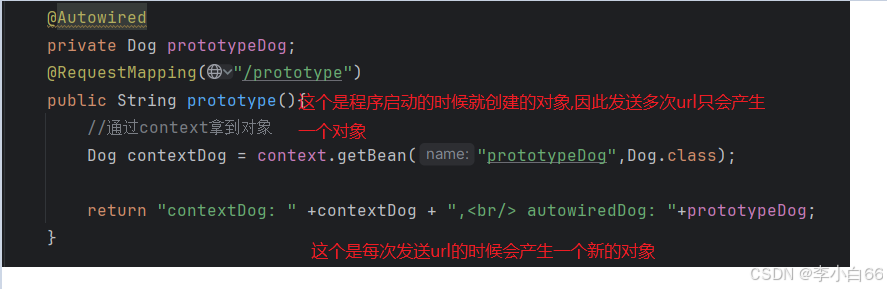
request请求: 同一个请求对象一样,反之不一样
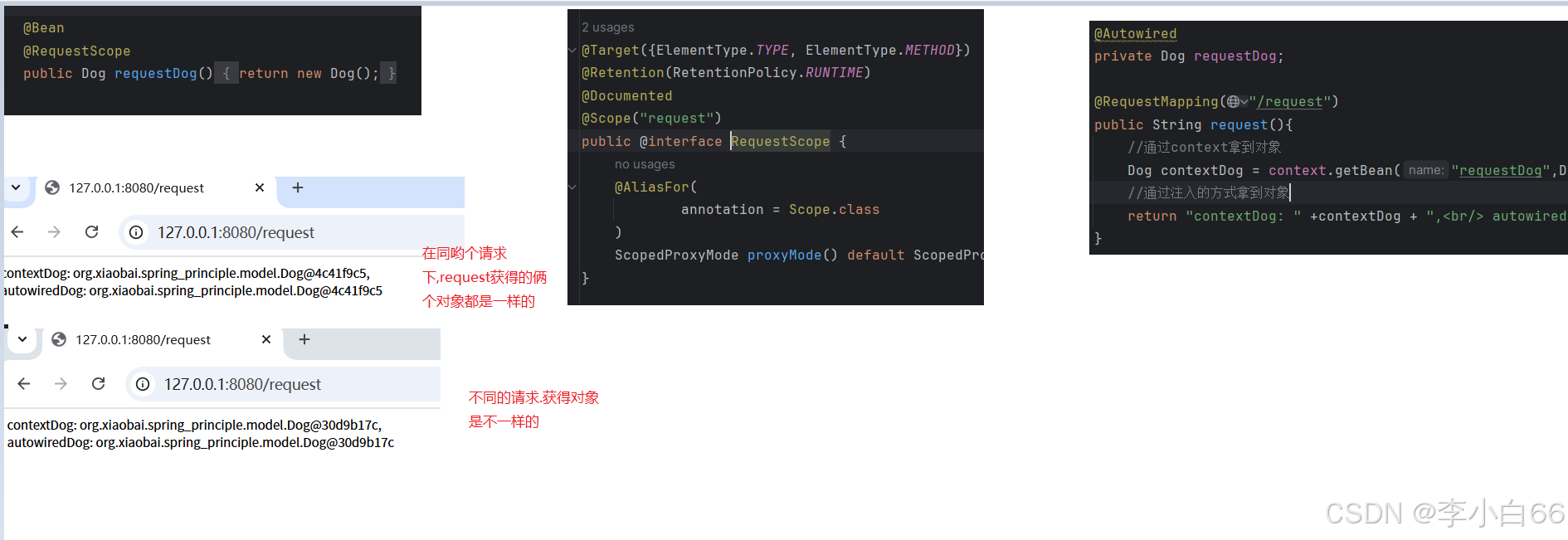
session: 同一个对话,(同一个浏览器,就说明是同一个用户)对象一样
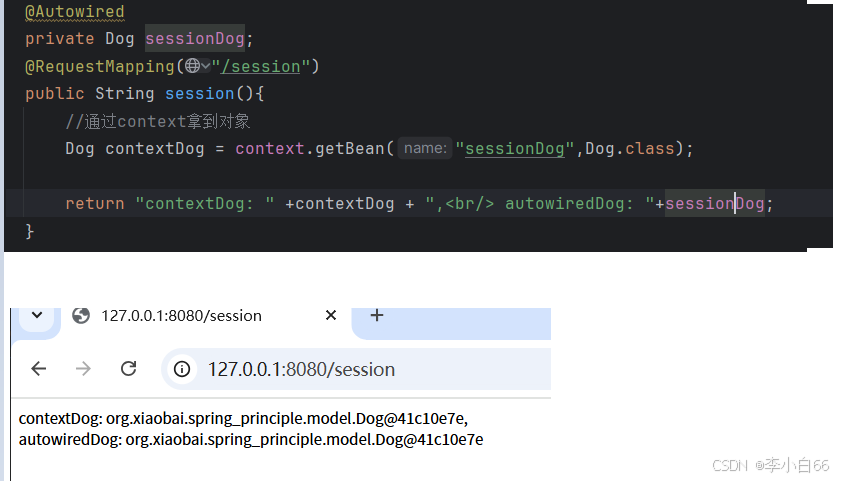
application: 在⼀个应⽤中, 多次访问都是同⼀个对象(和单例很像)
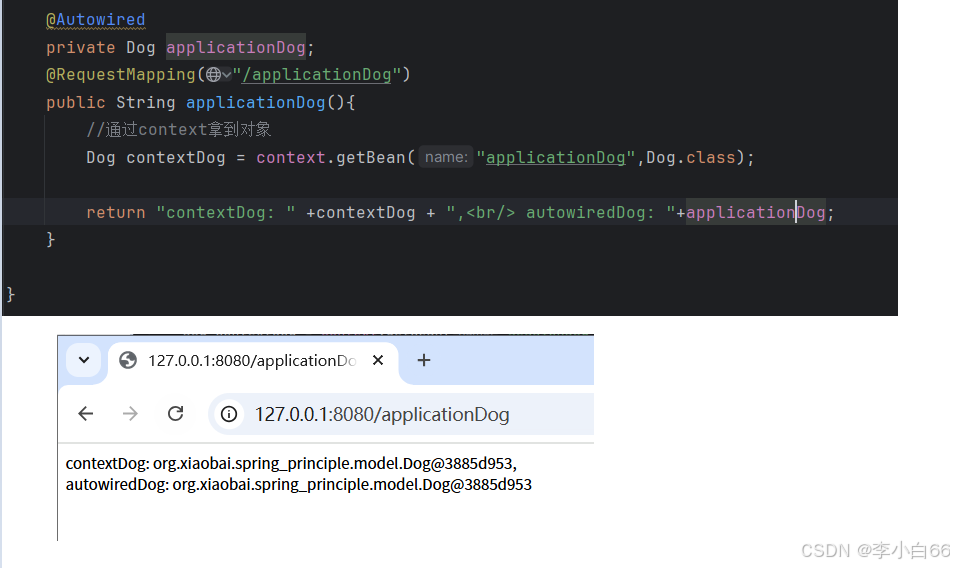
singleton和application的区别
Application scope就是对于整个web容器来说, bean的作⽤域是ServletContext级别的. 这个和singleton有点类似,区别在于: Application scope是ServletContext的单例, singleton是⼀个ApplicationContext的单例. 在⼀个web容器中ApplicationContext可以有多个. (web容器可以放多个web服务)
关于@AppliactionScop和其他的
2. Bean的生命周期
2.1 Bean的生命周期的概念(要毁结合源码来讲一下它的过程)
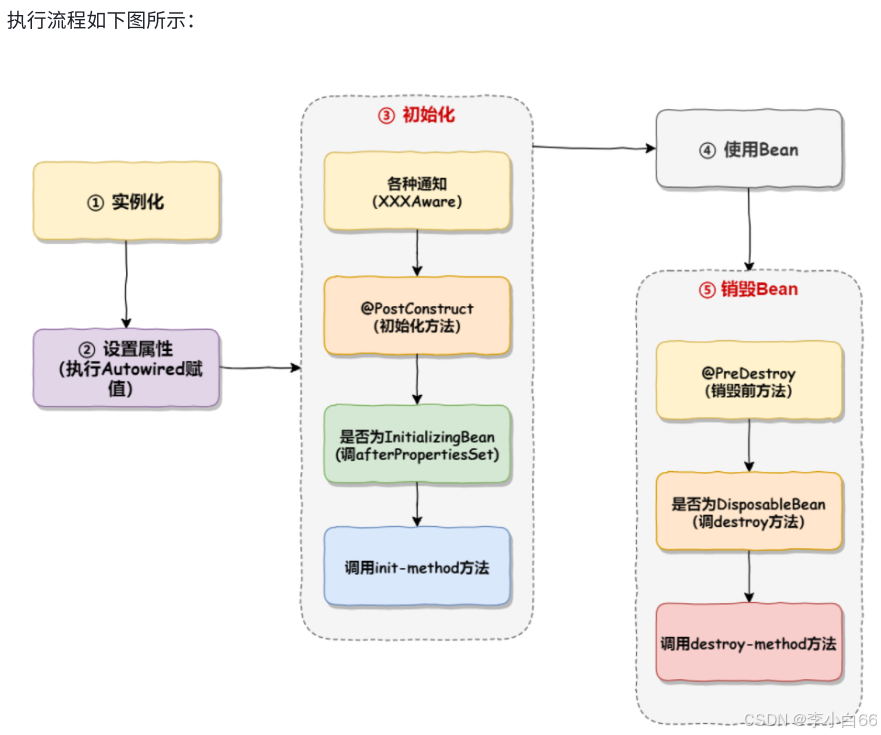
⽣命周期指的是⼀个对象从诞⽣到销毁的整个⽣命过程, 我们把这个过程就叫做⼀个对象的⽣命周期. Bean 的⽣命周期分为以下5个部分:(一般在Spring里面的对象才称之为Bean)
1. 实例化(为Bean分配内存空间)
2. 属性赋值(Bean注⼊和装配, ⽐如 @AutoWired )
3. 初始化(初始化里面的通知,好好理解一下)
a. 执⾏各种通知, 如 BeanNameAware , BeanFactoryAware ,ApplicationContextAware 的接⼝⽅法.
b. 执⾏初始化⽅法
▪ xml定义 init-method
▪ 使⽤注解的⽅式 @PostConstruct
▪ 执⾏初始化后置⽅法( BeanPostProcessor )
4. 使⽤Bean
5. 销毁Bean
a. 销毁容器的各种⽅法, 如 @PreDestroy , DisposableBean 接⼝⽅法, destroymethod.
实例化和属性赋值对应构造⽅法和setter⽅法的注⼊. 初始化和销毁是⽤⼾能⾃定义扩展的两个阶段, 可以在实例化之后, 类加载完成之前进⾏⾃定义"事件"处理.
⽐如我们现在需要买⼀栋房⼦, 那么我们的流程是这样的:
1. 先买房(实例化, 从⽆到有)
2. 装修(设置属性)
3. 买家电, 如洗⾐机, 冰箱, 电视, 空调等([各种]初始化,可以⼊住);
4. ⼊住(使⽤ Bean)
5. 卖房(Bean 销毁)
2.2 代码演示
package org.xiaobai.spring_principle.component;
import jakarta.annotation.PostConstruct;
import jakarta.annotation.PreDestroy;
import org.springframework.beans.factory.BeanNameAware;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.xiaobai.spring_principle.model.Dog;
@Component
public class BeanLifeComponent implements BeanNameAware {
private Dog singletonDog;
//1.实例化
public BeanLifeComponent(){
System.out.println("执行构造函数,实例化.....");
}
//2.属性赋值
@Autowired
public void setSingletonDog(Dog singletonDog){
this.singletonDog = singletonDog;
System.out.println("执行setSingletonDog,属性赋值....");
}
//3. 初始化
@Override
public void setBeanName(String name) {
System.out.println("setBeanName: "+name);
}
@PostConstruct
public void init(){
System.out.println("执行postConstruct, 初始化....");
}
//4. bean使用
public void use(){
System.out.println("使用use方法,bean的使用....");
}
//5. bean销毁(销毁前做的处理)
@PreDestroy
public void destroy(){
System.out.println("使用destroy方法,bean的销毁...");
}
}
我们执行方法
对应关系
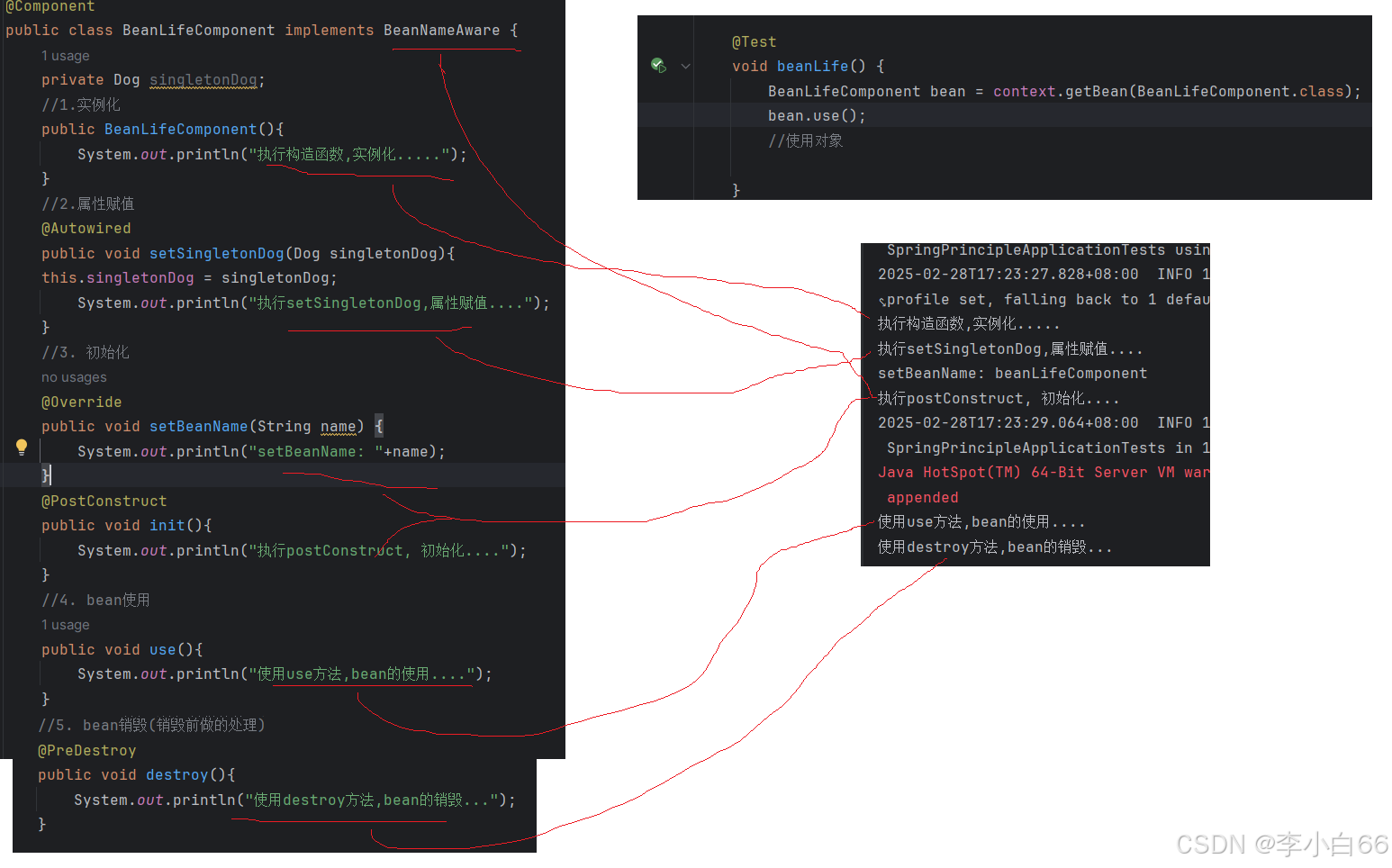
关于初始化的理解
(不加@autowired的对象)运行时生成的对象(动态生成)也可以放在init里面

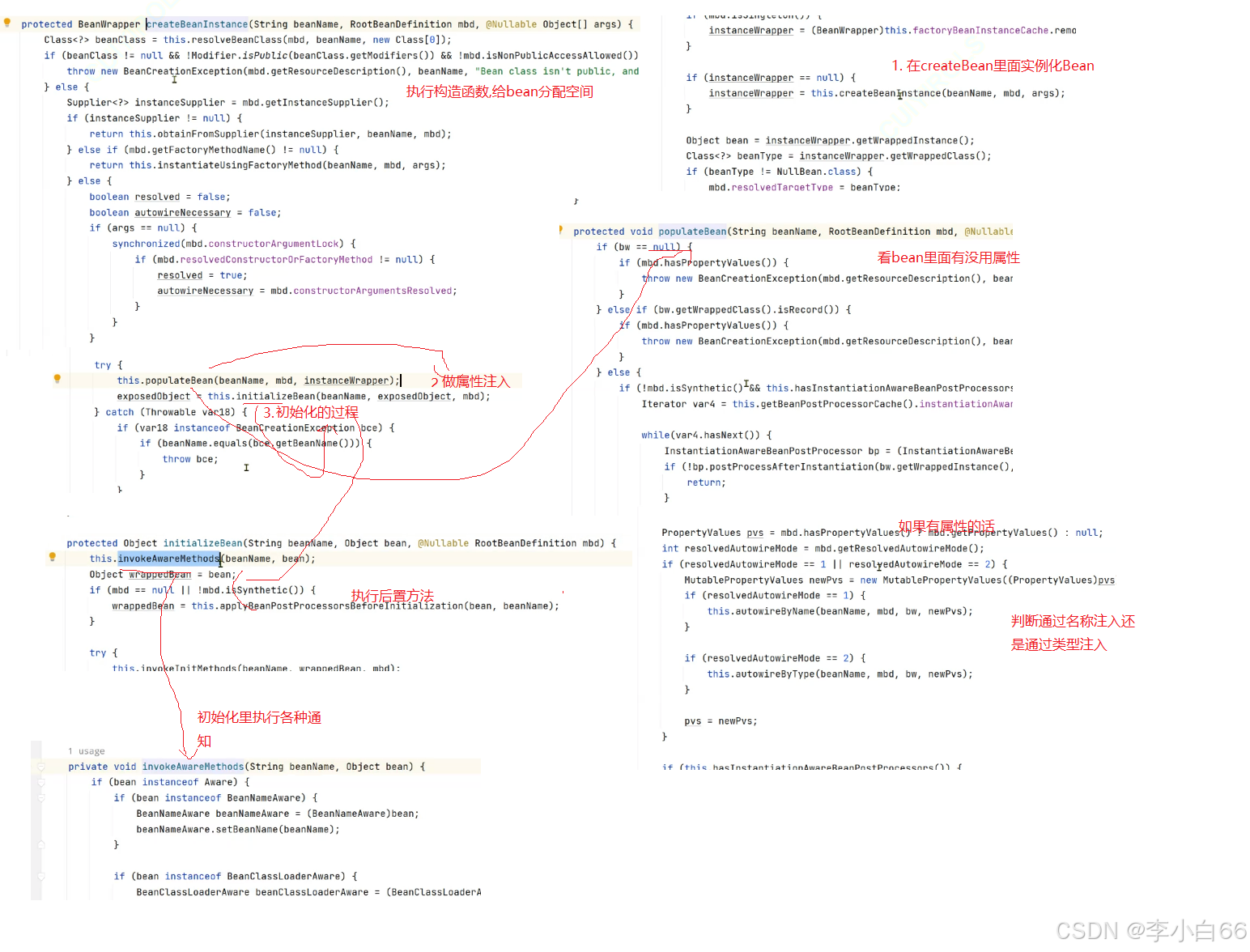
2.3 源码阅读
1. createBeanInstance() -> 实例化
2. populateBean() -> 属性赋值
3. initializeBean() -> 初始化
3. Spring Boot自动配置(最复杂的面试题)
SpringBoot的⾃动配置就是当Spring容器启动后, ⼀些配置类, bean对象等就⾃动存⼊到了IoC容器中, 不需要我们⼿动去声明, 从⽽简化了开发, 省去了繁琐的配置操作.
1> 自己声明的对象
2> 像事务那一块,spring里面内置的对象(比如这个)
我们关心他们是怎么被spring加载进来的
SpringBoot⾃动配置, 就是指SpringBoot是如何将依赖jar包中的配置类以及Bean加载到Spring IoC容器中的.
我们学习主要分以下两个⽅⾯:
1. Spring 是如何把对象加载到SpringIoC容器中的
2. SpringBoot 是如何实现的
3.1 Spring 加载Bean
3.1.1 问题描述
需求: 使⽤Spring管理第三⽅的jar包的配置
引⼊第三⽅的包, 其实就是在该项⽬下,引⼊第三⽅的代码, 我们采⽤在该项⽬下创建不同的⽬录来模拟第三⽅的代码引⼊
没有 rg.test.XiaoConfig 这个类型的Bean(下面图显示)
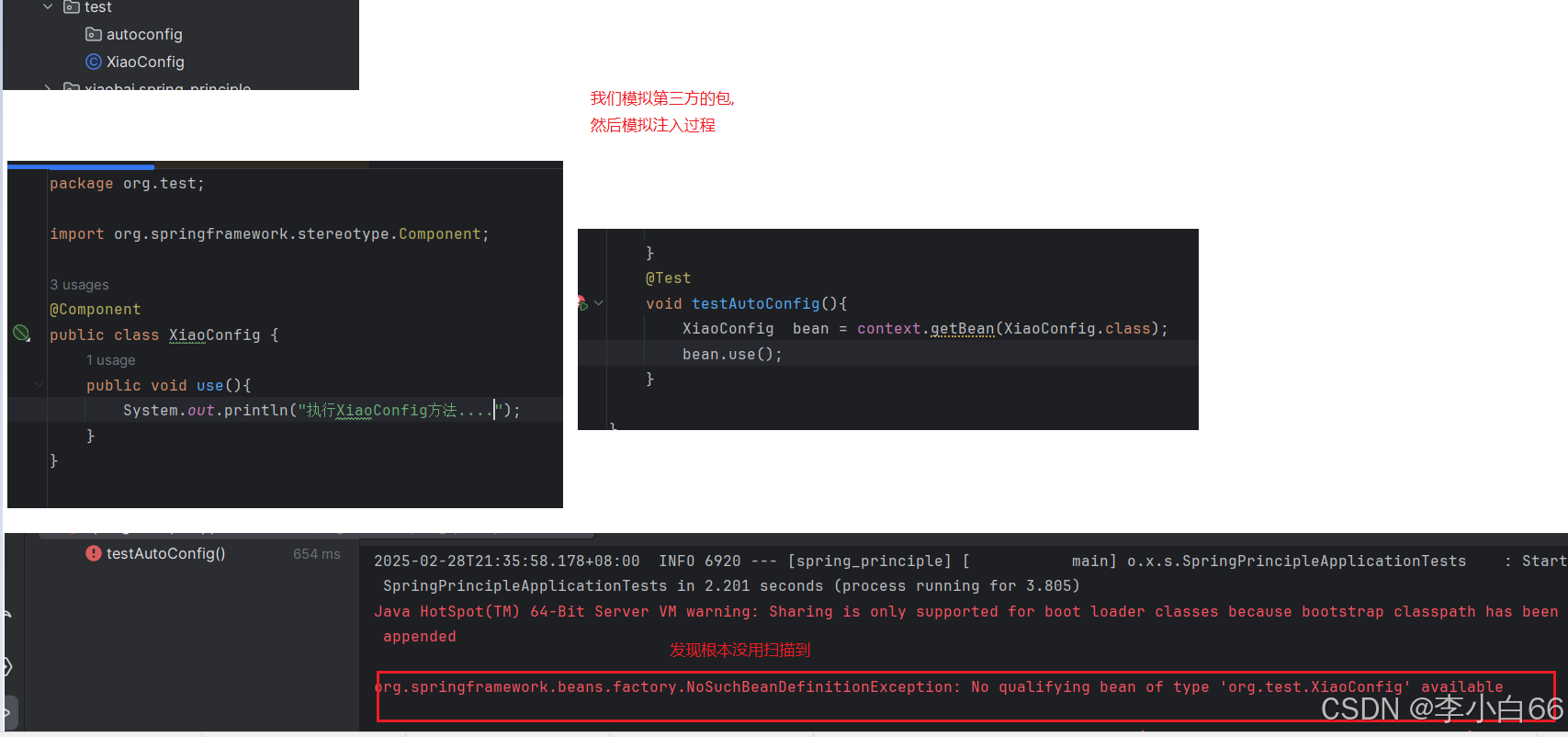
3.1.2 原因分析
Spring通过五⼤注解和 @Bean 注解可以帮助我们把Bean加载到SpringIoC容器中, 以上有个前提就是这些注解类需要和SpringBoot启动类在同⼀个⽬录下 ( @SpringBootApplication 标注的类 就是SpringBoot项⽬的启动类).
启动类所在⽬录为: com.example.demo , ⽽ XiaoConfig 这个类在rg.test.XiaoConfig 下, 所以SpringBoot并没有扫描到.
3.1.3 解决⽅案
我们需要指定路径或者引⼊的⽂件, 告诉Spring, 让Spring进⾏扫描到.
常⻅的解决⽅案有两种:
1. @ComponentScan 组件扫描
2. @Import 导⼊(使⽤@Import导⼊的类会被Spring加载到IoC容器中)
我们通过代码来看如何解决
3.1.3.1 加扫描组建
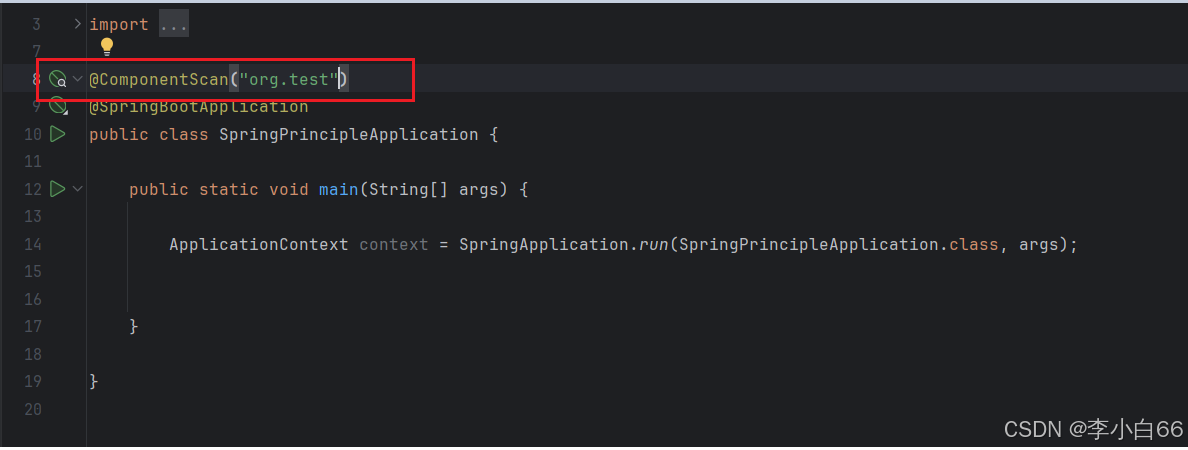
我们发现刚刚报错的代码执行成功了
但是我们的spring引入了很多的包,我们的spring难道都要通过组件一个一个加进来吗?
⾮常明显, 没有.(因为我们引⼊第三⽅框架时, 没有加扫描路径. ⽐如mybatis)
如果Spring Boot采⽤这种⽅式, 当我们引⼊⼤量的第三⽅依赖, ⽐如Mybatis, jackson等时, 就需要在启动类上配置不同
依赖需要扫描的包, 这种⽅式会⾮常繁琐.
3.1.3.2 @Import
@Import 导⼊主要有以下⼏种形式:
1. 导⼊类
2. 导⼊ ImportSelector 接⼝实现类
我们在启动类里面使用@Import注解把类到进去
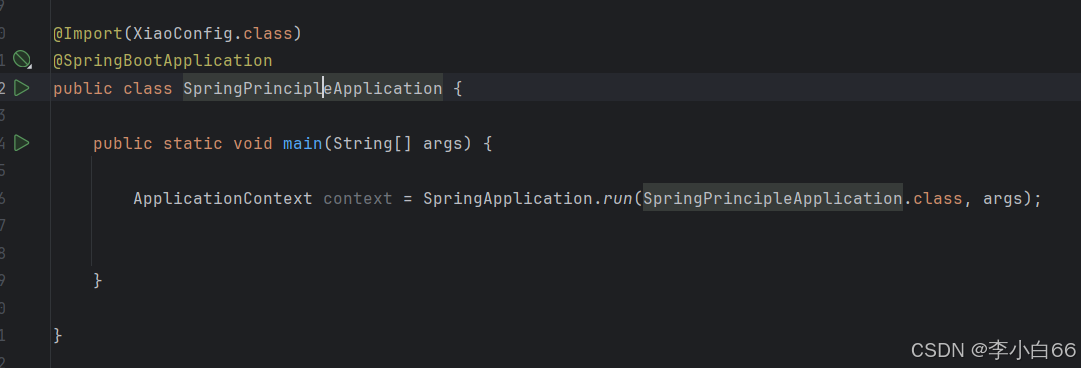
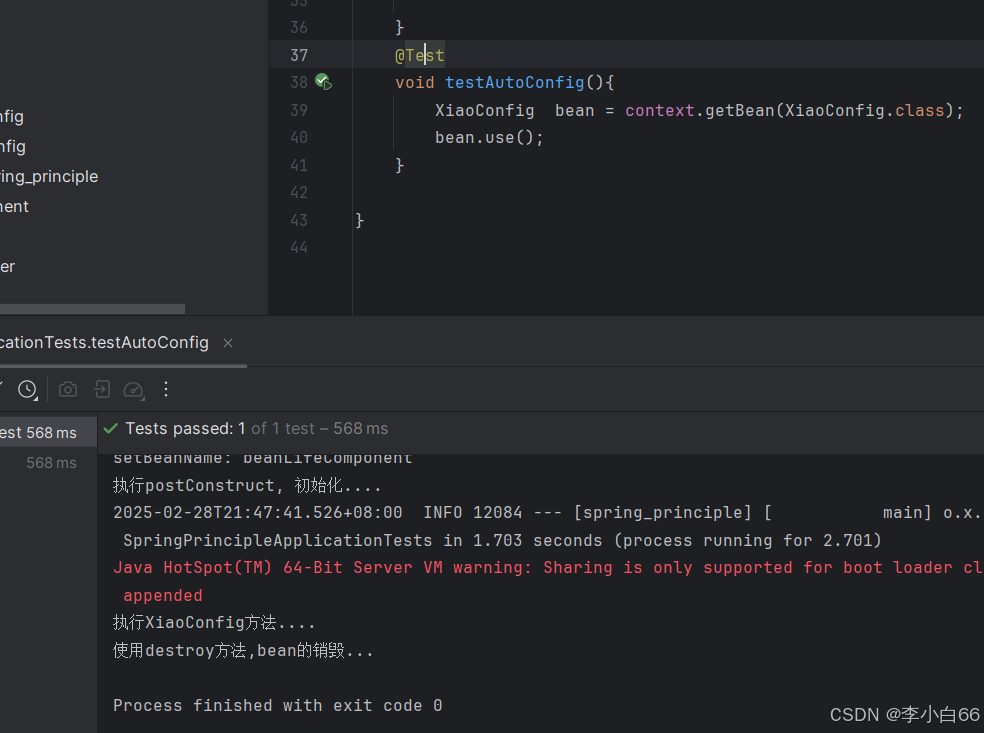
然后观察结果,是可以的
如果有多个类,我们也可以采用多类导入
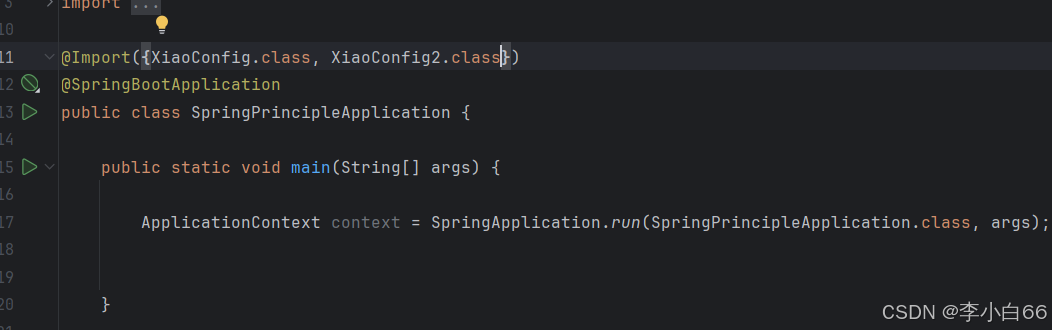
运行结果
很明显, 这种⽅式也很繁琐.
所以, SpringBoot依然没有采⽤.
2. 导⼊ImportSelector接⼝实现类
ImportSelector 接⼝实现类
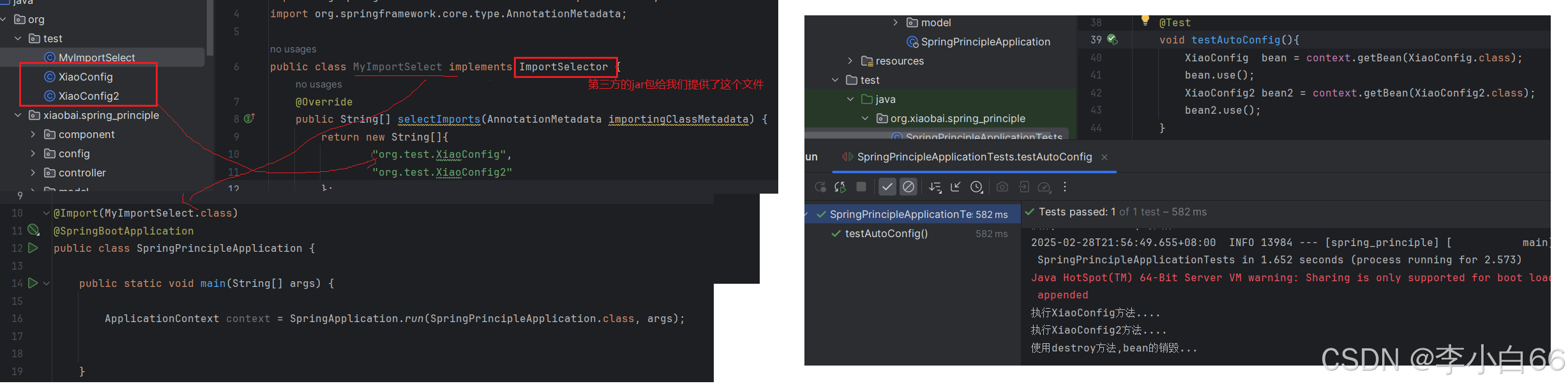
问题:
但是他们都有⼀个明显的问题, 就是使⽤者需要知道第三⽅依赖中有哪些Bean对象或配置类. 如果漏掉其中⼀些Bean, 很可能导致我们的项⽬出现⼤的事故.
这对程序员来说⾮常不友好.
依赖中有哪些Bean, 使⽤时需要配置哪些bean, 第三⽅依赖最清楚, 那能否由第三⽅依赖来做这件事呢?
• ⽐较常⻅的⽅案就是第三⽅依赖给我们提供⼀个注解, 这个注解⼀般都以@EnableXxxx开头的注解,
注解中封装的就是 @Import 注解
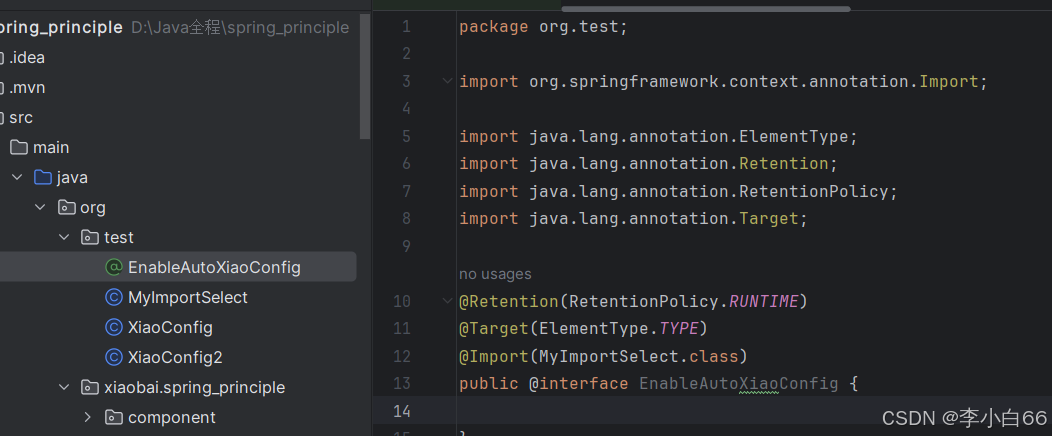
1. 第三⽅依赖提供注解
我们自己写一个注解
2. 在启动类上使⽤第三⽅提供的注解
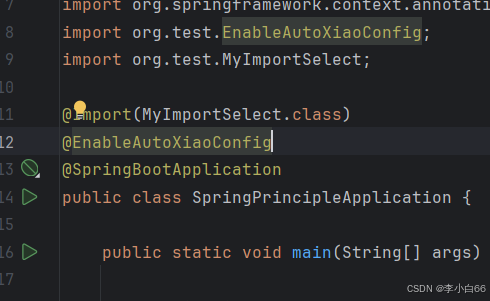
3. 运⾏程序
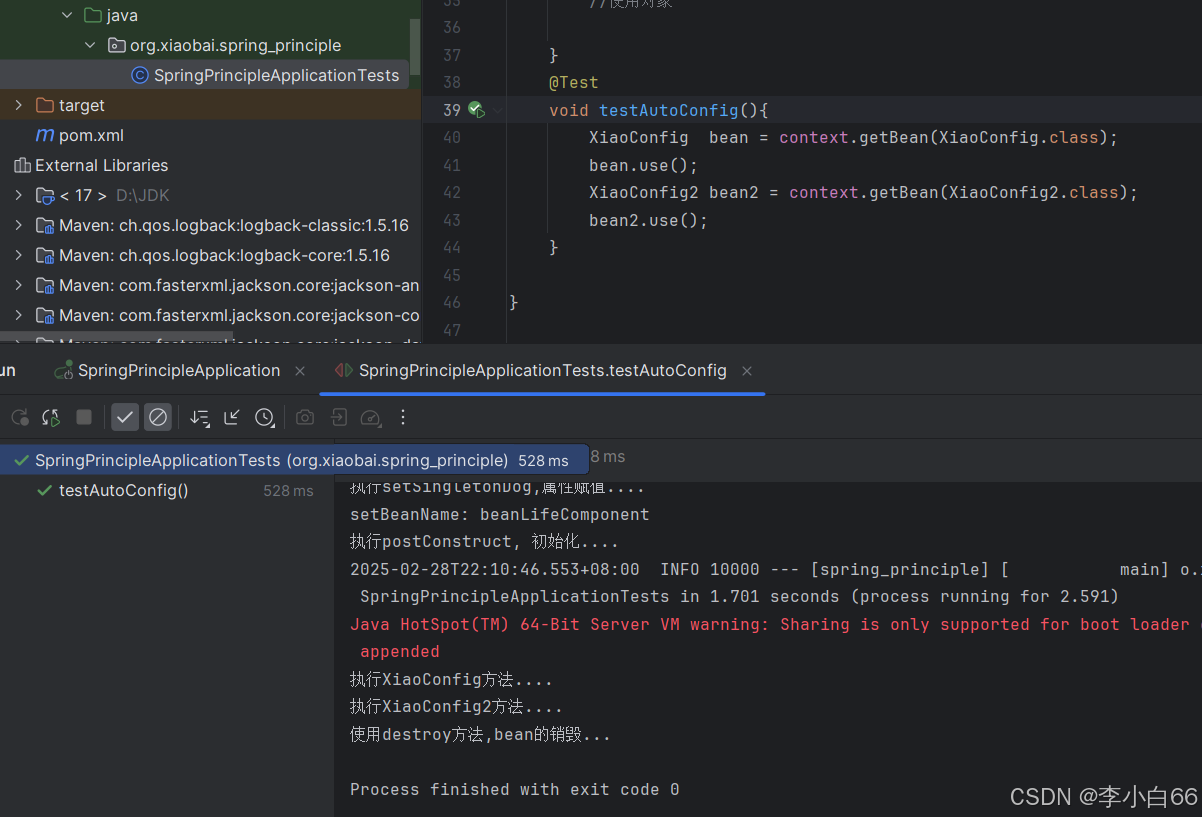
可以看到, 这种⽅式也可以导⼊第三⽅依赖提供的Bean. 并且这种⽅式更优雅⼀点. SpringBoot采⽤的也是这种⽅式
但是有时候我记不住注解,这该怎么解决?我们约定好放在一个地方,然后我要用就直接拿即可
这也就是为什么我们的启动类只用了一个@SpringBootApplication注解的就能够扫描到所有的类的原因.
我们来看看启动类注解里面的组成
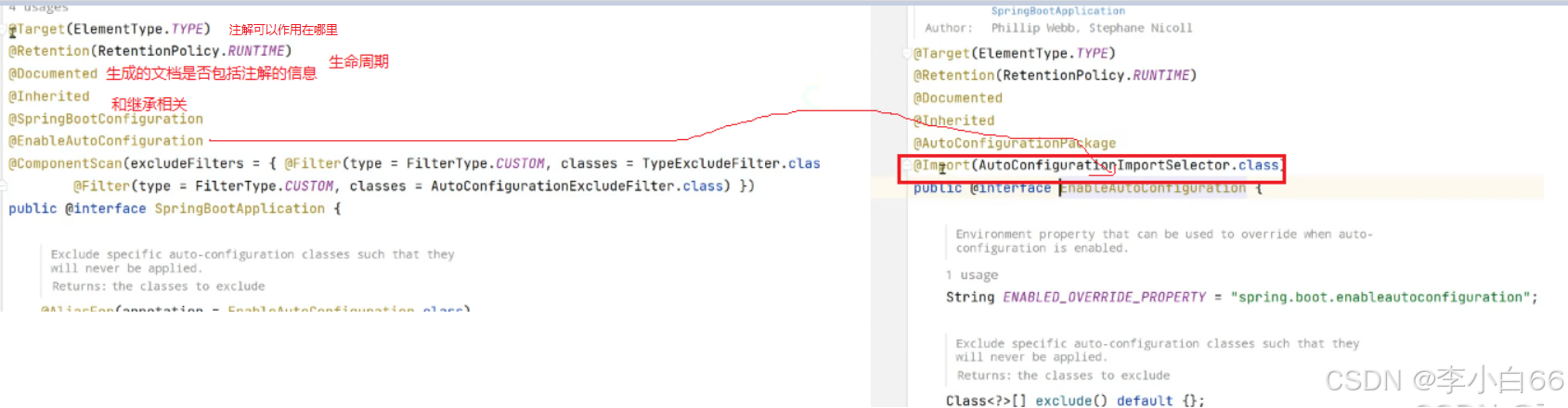
具体的解释: @SpringConfiguration @ComponentScan(这个是用力来扫描我们这个项目下面的包)
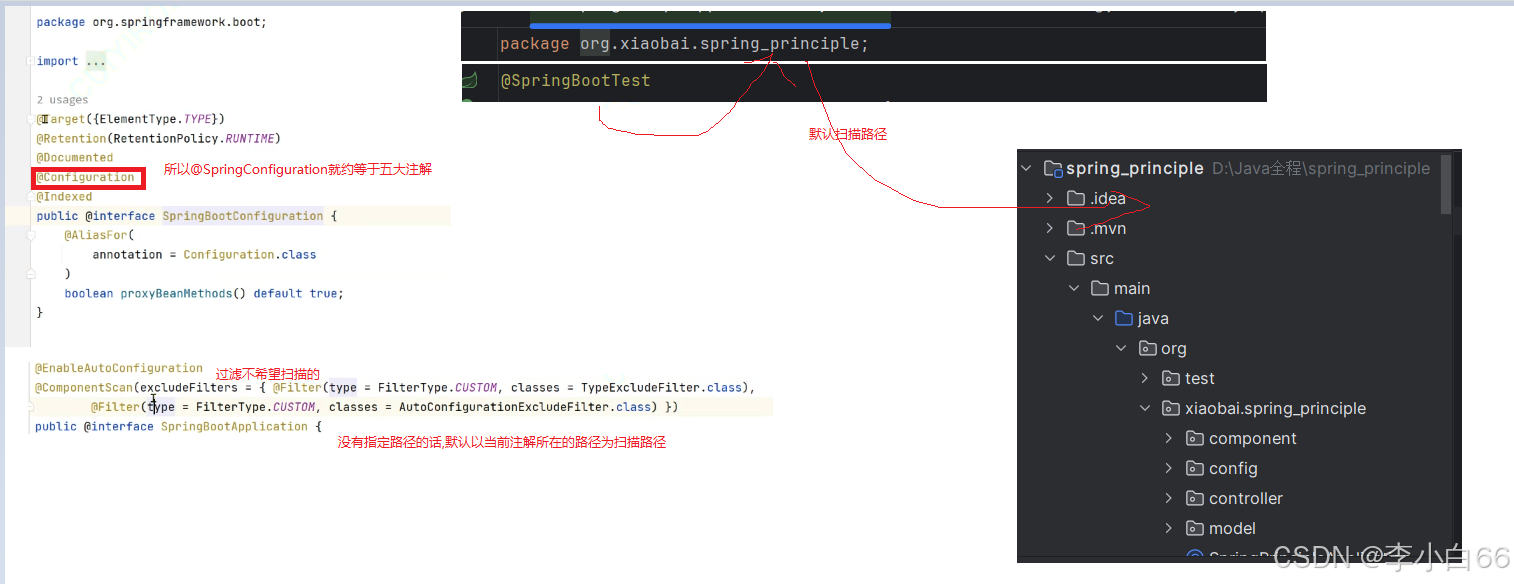
第三方包是: @SpringConfiguration和@EnableAutoConfiguration这俩个注解
@EnableAutoConfiguration
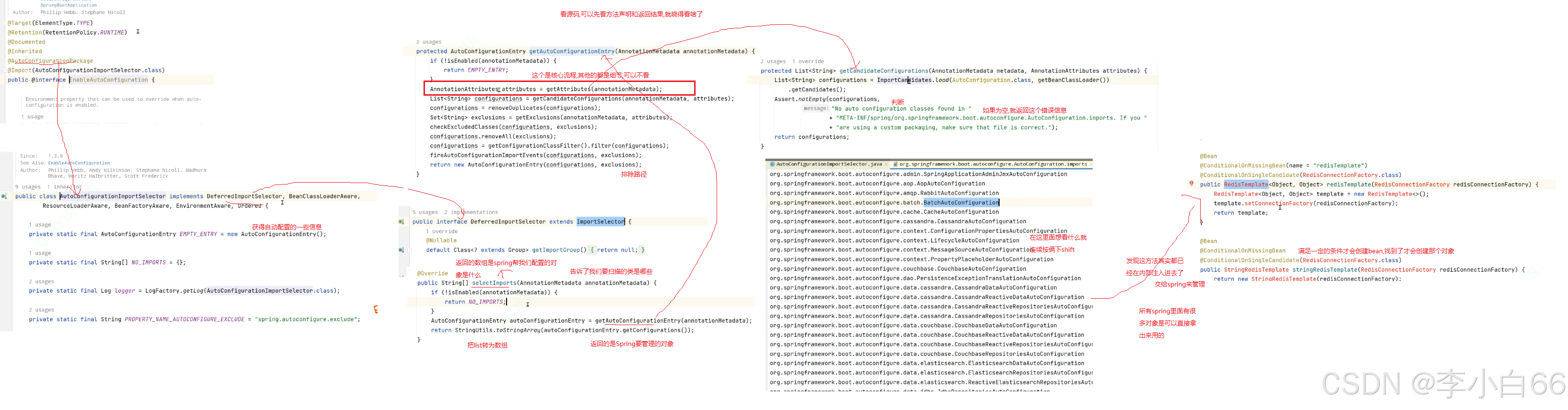
@AutoConfiguration( @EnableAutoConfiguration里面的嵌套注解)
我们来看一些更加具体的解释
@SpringBootApplication

@SpringBootApplication 是⼀个组合注解, 注解中包含了:
1. 元注解
JDK中提供了4个标准的⽤来对注解类型进⾏注解的注解类, 我们称之为 meta-annotation(元注解), 他们分别是:
• @Target 描述注解的使⽤范围(即被修饰的注解可以⽤在什么地⽅)
• @Retention 描述注解保留的时间范围
• @Documented 描述在使⽤ javadoc ⼯具为类⽣成帮助⽂档时是否要保留其注解信息
• @Inherited 使被它修饰的注解具有继承性(如果某个类使⽤了被@Inherited修饰的注解,则
其⼦类将⾃动具有该注解)
2. @SpringBootConfiguration
⾥⾯就是@Configuration, 标注当前类为配置类, 其实只是做了⼀层封装改了个名字⽽已. (@Indexed注解,是⽤来加速应⽤启动的, 不⽤关⼼)

3. @EnableAutoConfiguration (开启⾃动配置)
Spring⾃动配置的核⼼注解, 下⾯详细讲解
4. @ComponentScan (包扫描)
可以通过 basePackageClasses 或 basePackages 来定义要扫描的特定包, 如果没有定义特定的包, 将从声明该注解的类的包开始扫描, 这也是为什么SpringBoot项⽬声明的注解类必须要在启动类的⽬录下.
excludeFilters ⾃定义过滤器, 通常⽤于排除⼀些类, 注解等.
3.2.2 @EnableAutoConfiguration 详解
看下 @EnableAutoConfiguration 注解的实现:
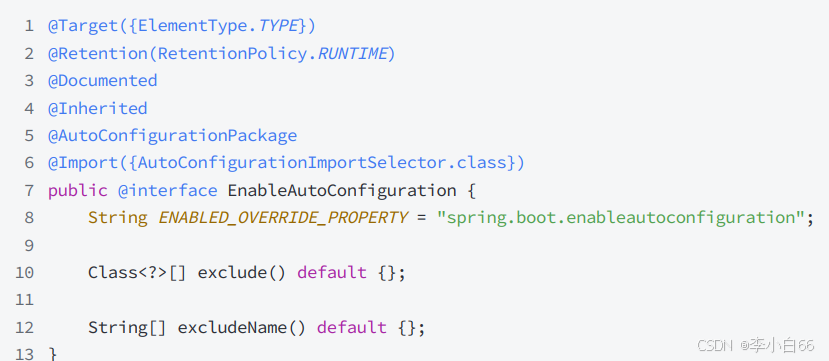
这个注解包含两部分:
1. @Import({AutoConfigurationImportSelector.class})
使⽤@Import注解,导⼊了实现ImportSelector接⼝的实现类.
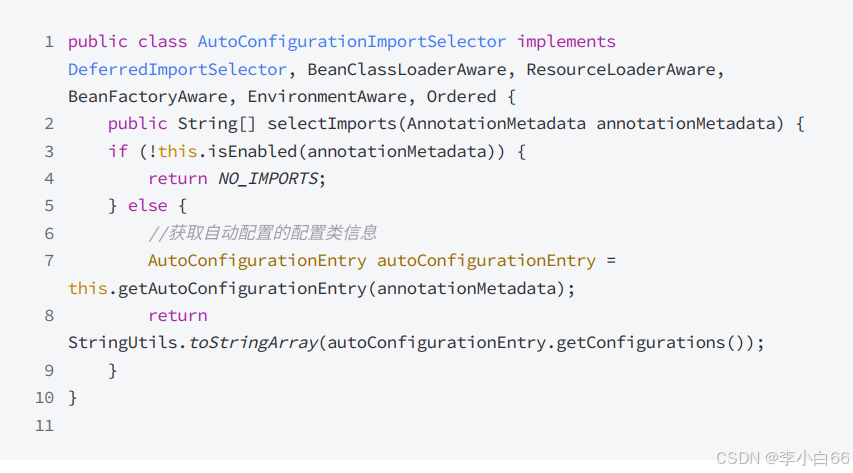
selectImports() ⽅法底层调⽤ getAutoConfigurationEntry() ⽅法, 获取可⾃动配置的配置类信息集合.

getAutoConfigurationEntry() ⽅法通过调⽤getCandidateConfigurations(annotationMetadata, attributes) ⽅法获取在配置⽂件中配置的所有⾃动配置类的集合

getCandidateConfigurations ⽅法的功能
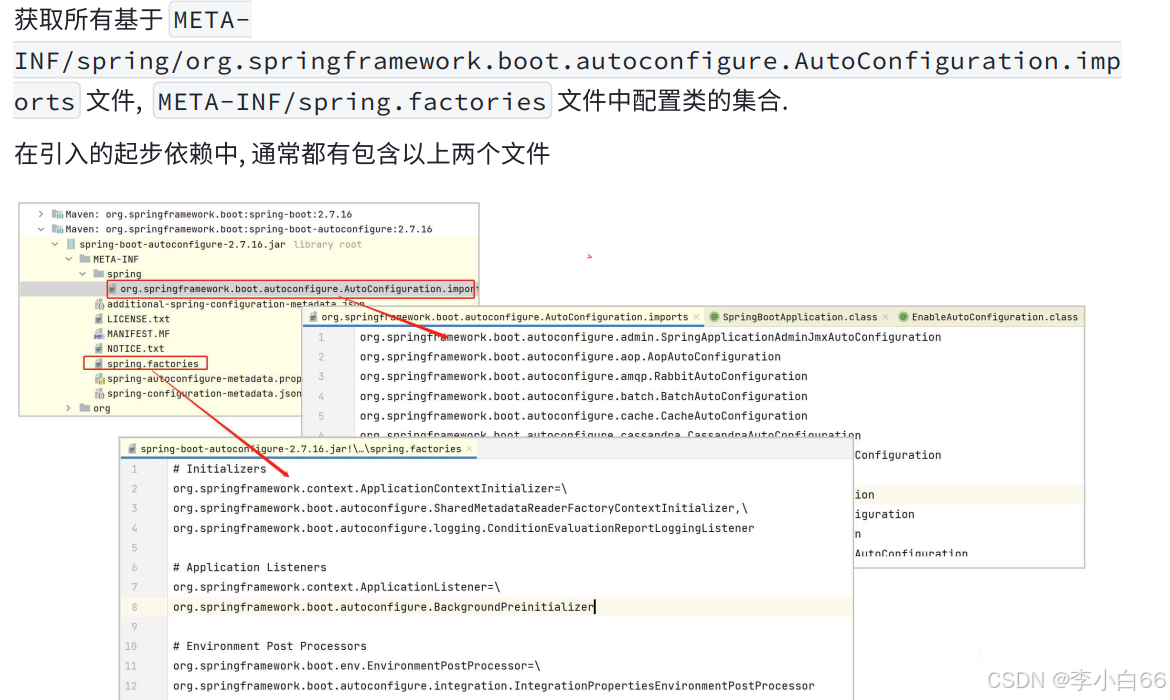
这⾥⾯包含了很多第三⽅依赖的配置⽂件(连续按两下shift可以查看对应的源码)
1. 在加载⾃动配置类的时候, 并不是将所有的配置全部加载进来, ⽽是通过@Conditional等注解的判断进⾏动态加载.
@Conditional是spring底层注解, 意思就是根据不同的条件, 来进⾏⾃⼰不同的条件判断,如果满⾜指定的条件,那么配置类⾥边的配置才会⽣效.
2. META-INF/spring.factories⽂件是Spring内部提供的⼀个约定俗成的加载⽅式, 只需要在模块的
META-INF/spring.factories⽂件中配置即可, Spring就会把相应的实现类注⼊到Spring容器中. 注: 会加载所有jar包下的classpath路径下的META-INF/spring.factories⽂件, 这样⽂件不⽌⼀个.
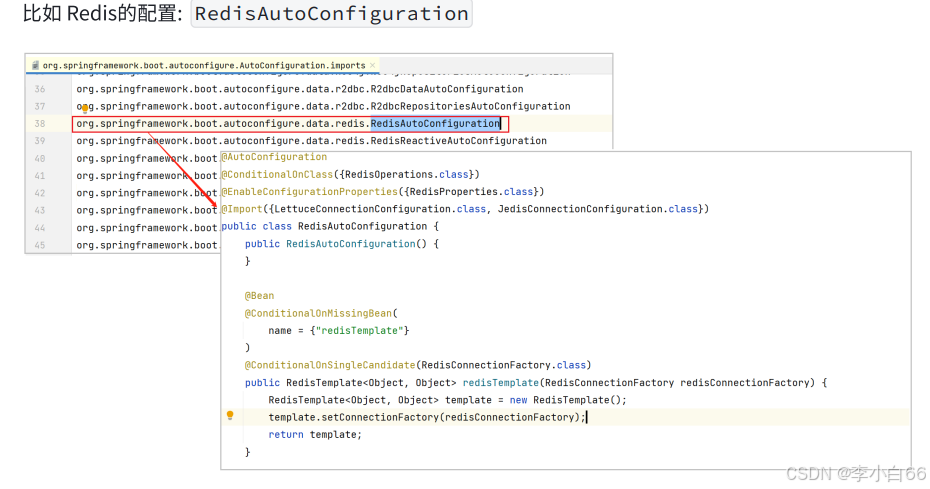
可以看到, 配置⽂件中使⽤ @Bean 声明了⼀些对象, spring就会⾃动调⽤配置类中使⽤ @Bean 标识的⽅法, 并把对象注册到Spring IoC容器中.
在加载⾃动配置类的时候, 并不是将所有的配置全部加载进来, ⽽是通过@Conditional等注解的判断进⾏动态加载
@Conditional是spring底层注解, 意思就是根据不同的条件, 来进⾏⾃⼰不同的条件判断,如果满⾜指定的条件,那么配置类⾥边的配置才会⽣效。
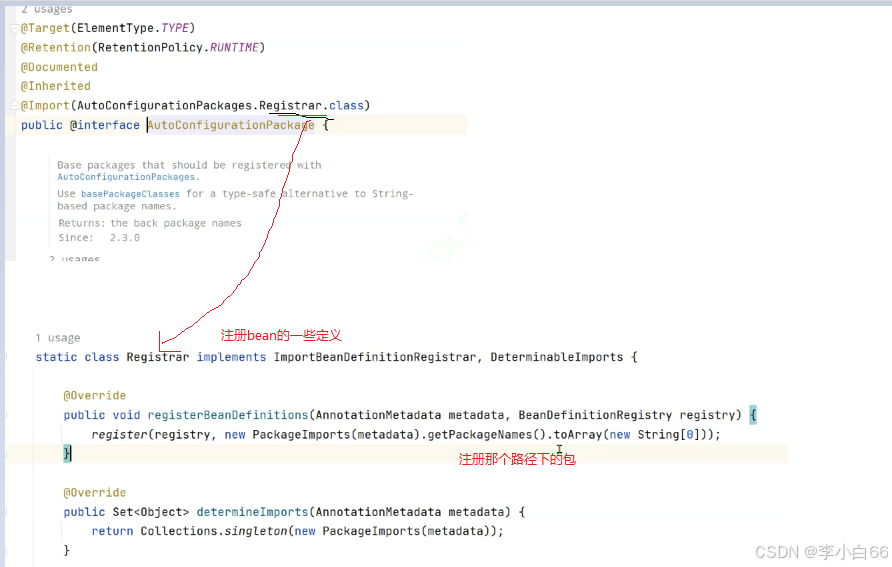
2. @AutoConfigurationPackage
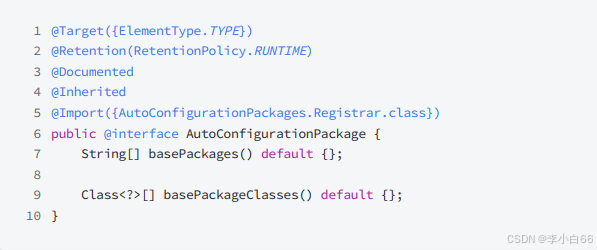
这个注解主要是导⼊⼀个配置⽂件 AutoConfigurationPackages.Registrar.class
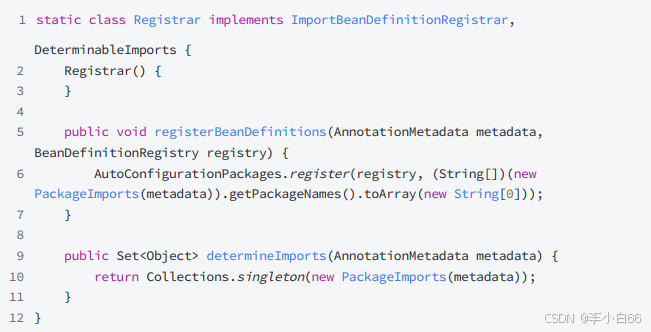
Registrar实现了 ImportBeanDefinitionRegistrar 类, 就可以被注解@Import导⼊到spring容器⾥.

3.2.3 总结
SpringBoot ⾃动配置原理的⼤概流程如下:
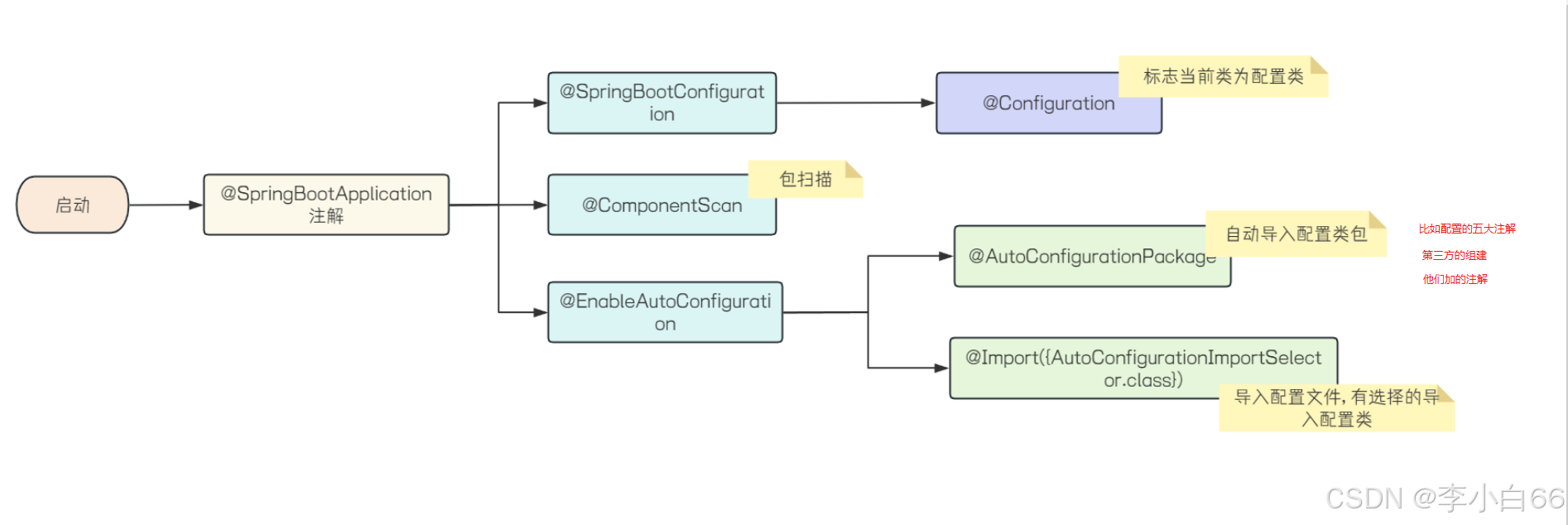
当SpringBoot程序启动时, 会加载配置⽂件当中所定义的配置类, 通过 @Import 注解将这些配置类全部加载到Spring的IOC容器中, 交给IOC容器管理.
4. 总结
1. Bean的作⽤域共分为6种: singleton, prototype, request, session, application和websocket.
2. Bean的⽣命周期共分为5⼤部分: 实例化, 属性复制, 初始化, 使⽤和销毁
3. SpringBoot的⾃动配置原理源码⼝是 @SpringBootApplication 注解, 这个注解封装了3个注
解
◦ @SpringBootConfiguration 标志当前类为配置类
◦ @ComponentScan 进⾏包扫描(默认扫描的是启动类所在的当前包及其⼦包)
◦ @EnableAutoConfiguration
▪ @Import 注解 : 读取当前项⽬下所有依赖jar包中 META-INF/spring.factories ,
METAINF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports俩个文件里面定义的配置类(配置类中定义了@Bean注解标识的方法)
▪ @AutoConfigurationPackage : 把启动类所在的包下⾯所有的组件都注⼊到 Spring容器中
5. 补充面试题
Spring中的事务什么时候失效?
1> 非public
2> 异常类型(非runtime)
3> 对象没有交给spring管理
4> 事务传播机制的设置
5> 数据库不支持事务
三级缓存
Spring是如何解决循环依赖的?答案即是Spring的三级缓存
这个问题或者换个问法:Spring是如何解决循环依赖的?答案即是Spring的三级缓存
什么是循环依赖
简单说,就是A对象依赖B对象,B对象⼜依赖A对象,类似的代码如下:
@Component
public class A{
@Autowired
private B b;
}
@Component
public class B{
@Autowired
private A a;
其他还有很多种⽅式,如A依赖B,B依赖C,C依赖A,或是A依赖A⾃⼰,只要产⽣了依赖关系的闭环,即造成了循环依赖。
那么,循环依赖会引发什么问题呢?理解这个问题先得理解Bean的⽣命周期,以下先回顾下
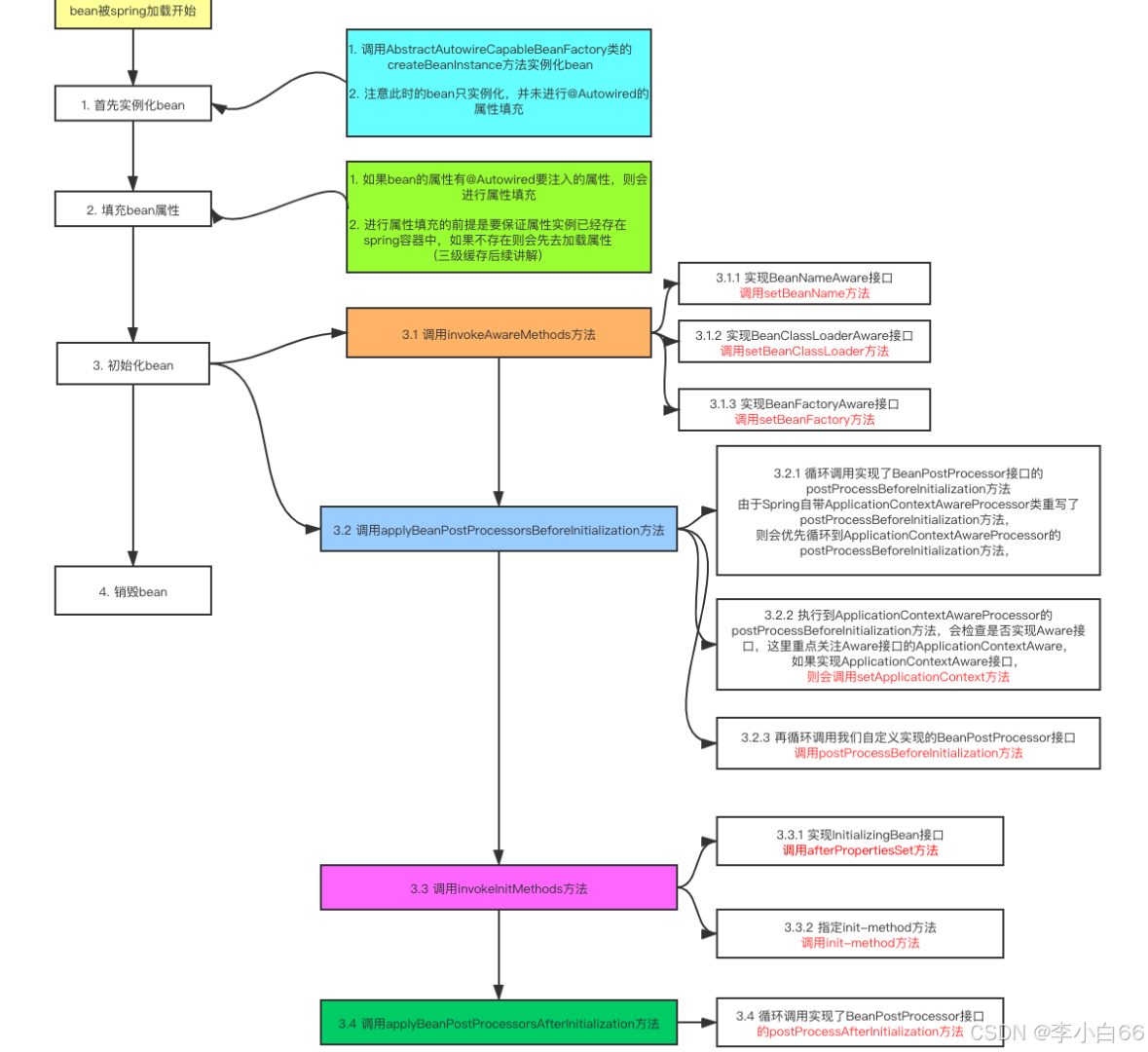
Bean的生命周期回顾
1. 启动容器:加载Bean
2. 实例化Bean对象
3. 依赖注⼊:装配Bean的属性
4. 初始化Bean:执⾏aware接⼝⽅法、预初始化⽅法、初始化⽅法、后初始化⽅法
5. 关闭容器:销毁Bean
在以上第四个步骤执⾏完毕,才算⼀个初始化完成的Bean,也即Spring容器中完整的Bean对象。
循环依赖的问题
Spring容器保存Bean的⽅式,是采取缓存的⽅式:使⽤ Map<String, Object> 的结构,key为Bean的名称,value为Bean对象。需要使⽤时直接从缓存获取。
如A、B互相依赖(循环依赖):
1. 容器中没有A对象,实例化A对象
2. 装配A中的B对象,发现B在容器中没有,需要先实例化B
3. 实例化B对象
4. 装配B中的A对象,发现A在容器中没有,需要先实例化A
5. 重复第⼀个步骤
这就套娃了, 你猜是先 StackOverflow 还是 OutOfMemory ?
[PS]
• Bean会依赖某些注⼊的Bean来完成初始化⼯作
• 由于Spring⽀持构造⽅法注⼊,属性/Setter注⼊的⽅式,所以不能简单的先把所有对象全部实例化,放到缓存中,再全部执⾏初始化。原因很简单,此时所有对象的引⽤都可以获取到,但属性都是null,执⾏初始化甚⾄构造⽅法都可能出现空指针异常。
那么我们说Spring能解决循环依赖,也不是所有的情况都可以解决,只有以下情况才⽀持。
Spring不支持的循环依赖
Spring框架在处理循环依赖时存在⼀些限制, 它不能解决所有类型的循环依赖问题 ⽐如以下循环依赖的场景, Spring并不⽀持(包含但不限于)
1. 构造器循环依赖:当两个Bean在它们的构造器中相互依赖时,Spring⽆法解决这种循环依赖。
Spring在创建Bean时会检查构造器中的循环依赖,并在发现时抛出BeanCurrentlyInCreationException 异常。
2. 原型Bean循环依赖:对于原型作⽤域(Prototype)的Bean,Spring不⽀持循环依赖。原型Bean的⽣命周期是短暂的,每次请求都会创建新实例,Spring容器不缓存原型Bean,因此⽆法提前暴露⼀个创建中的Bean来解决循环。
3. 复杂的AOP场景下的循环依赖:在⼀些复杂的AOP(⾯向切⾯编程)场景中,如果Bean之间存在循环依赖,并且这些Bean被⽤于AOP代理,Spring可能⽆法解决这种循环依赖。
Spring解决循环依赖
Spring是使⽤三级缓存的机制来解决循环依赖问题,以下为三级缓存的定义:
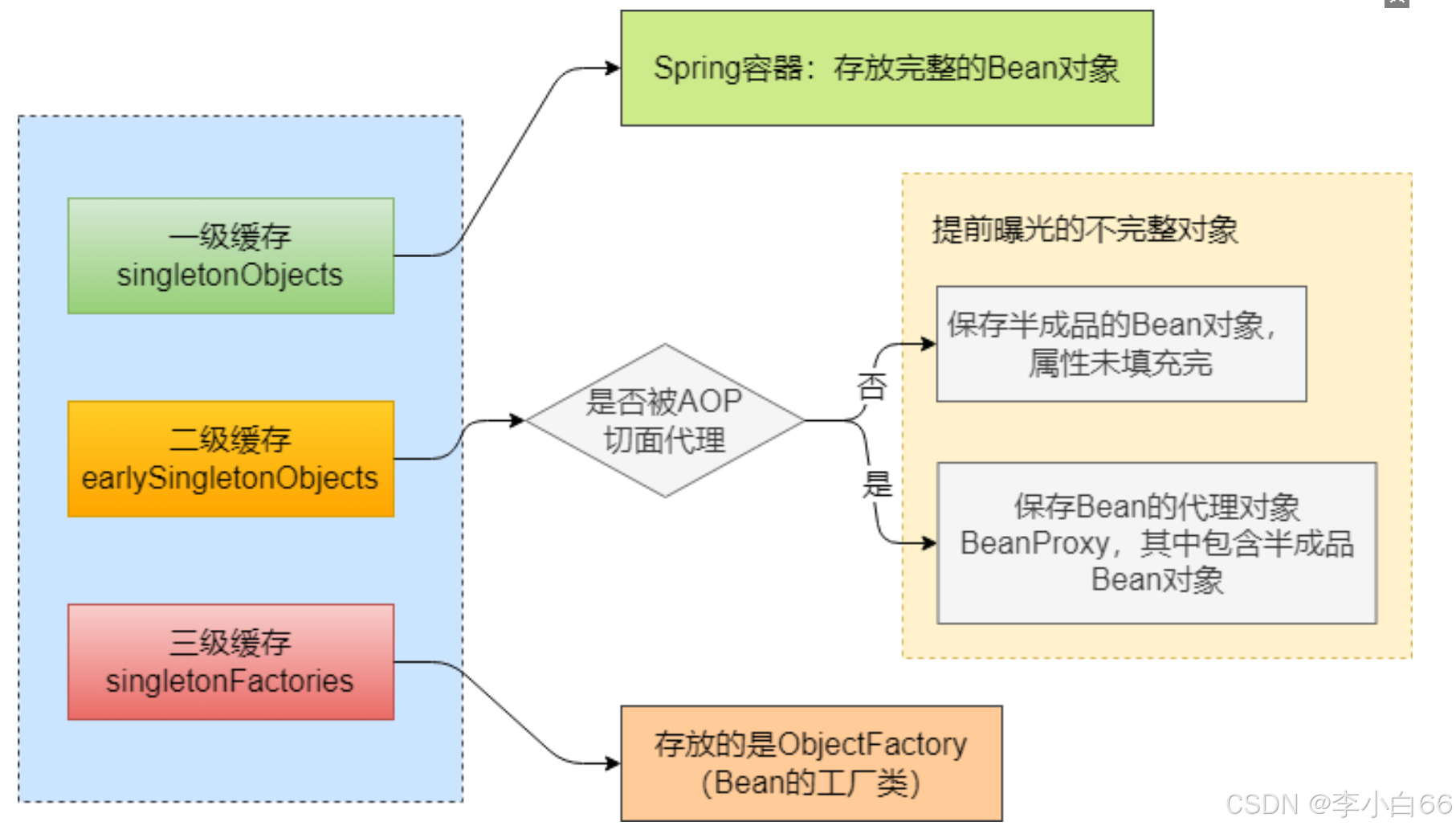
三级缓存就是三个map
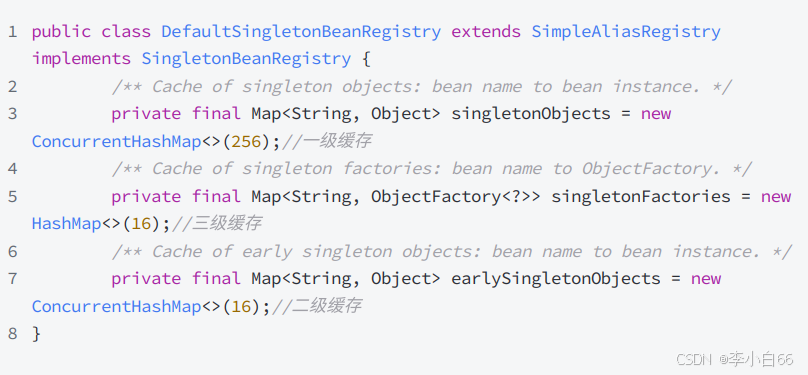
以下是部分说明:
• 三级缓存singletonFactories中保存的是ObjectFactory对象(Bean⼯⼚),其中包含了
BeanName,Bean对象,RootBeanDefinition,该⼯⼚可以⽣成Bean对象。
• 由于Bean可能被代理,此时注⼊到其他Bean属性中的也应该是代理Bean。
单例模式的A、B循环依赖执⾏流程如下:

为什么要使用三级缓存
依照以上三级缓存的流程,其实使⽤⼆级缓存也能满⾜循环依赖的注⼊:
• 普通的IoC容器使⽤⼀级缓存即可,但⽆法解决循环依赖问题。
• 解决循环依赖问题:使⽤⼆级缓存即可。⼀级缓存保存完整Bean,⼆级缓存保存提前曝光的不完整的Bean。
• 需要AOP代理Bean时,有两种实现思路:
(1)再加⼀级缓存
(2)只使⽤⼆级缓存,其中⼆级缓存保存Bean的代理对象,代理对象中引⽤不完整的原始对象即可
• Spring使⽤三级缓存保存ObjectFactory即Bean⼯⼚,在代码的层次设计及扩展性上都会更好。三级缓存的引⼊主要是为了解决代理相关的循环依赖问题,尤其是涉及到AOP时,代理对象的创建可能需要提前于Bean的完全初始化.
在Spring 3.6之前,Spring通过使⽤⼀级和⼆级缓存来解决单例Bean的循环依赖问题,⽽从3.6版本开始,通过引⼊三级缓存,Spring能够更全⾯地处理包括AOP在内的更复杂的循环依赖情况。
SpringMVC的流程(简要分析,有机会去翻翻源码)
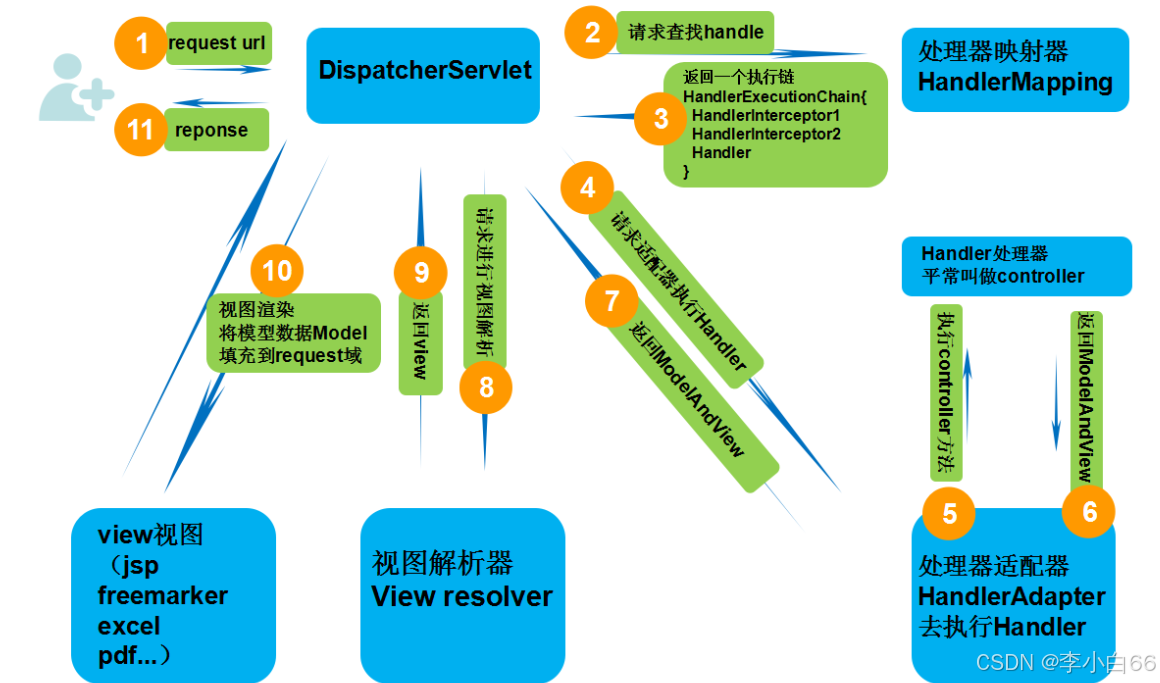
1> 发送request请求,然后通过dispathcherServlet去查找handle
2> 根据handle找适配器
3> 执行handle
4> 返回model and view
5> 解析视图,填充视图,然后再进行返回response
SpringMVC的请求响应步骤如下: 具体步骤:
• 第⼀步:(发起)发起请求到前端控制器(DispatcherServlet)
• 第⼆步:(查找)前端控制器请求HandlerMapping查找 Handler(可以根据xml配置、注解进⾏查找)
• 第三步:(返回)处理器映射器HandlerMapping向前端控制器返回Handler,HandlerMapping会把请求映射为HandlerExecutionChain对象(包含⼀个Handler处理器(⻚⾯控制器)对象,多个HandlerInterceptor拦截器对象),通过这种策略模式,很容易添加新的映射策略
• 第四步:(调⽤)前端控制器调⽤处理器适配器去执⾏Handler
• 第五步:(执⾏)处理器适配器HandlerAdapter将会根据适配的结果去执⾏Handler
• 第六步:(返回)Handler执⾏完成给适配器返回ModelAndView
• 第七步:(接收)处理器适配器向前端控制器返回ModelAndView (ModelAndView是SpringMVC框架的⼀个底层对象,包括 Model和view)
• 第⼋步:(解析)前端控制器请求视图解析器去进⾏视图解析 (根据逻辑视图名解析成真正的视图(jsp)),通过这种策略很容易更换其他视图技术,只需要更改视图解析器即可
• 第九步:(返回)视图解析器向前端控制器返回View
• 第⼗步:(渲染)前端控制器进⾏视图渲染 (视图渲染将模型数据(在ModelAndView对象中)填充到request域)
• 第⼗⼀步:(响应)前端控制器向⽤⼾响应结果
以下是对出现的⼀些组件的介绍:
(1) DispatcherServlet
作⽤:接收请求,响应结果,相当于转发器,中央处理器。有了DispatcherServlet减少了其它组件之间的耦合度。
(2) 处理器映射器HandlerMapping
作⽤:根据请求的url查找Handler
(3) 处理器适配器HandlerAdapter
作⽤:按照特定规则(HandlerAdapter要求的规则)去执⾏Handler。 (4) 处理器Handler(程序员开发)
注意:编写Handler时按照HandlerAdapter的要求去做,这样适配器才可以去正确执⾏Handler (5) 视图解析器ViewResolver
作⽤:进⾏视图解析,根据逻辑视图名解析成真正的视图(6) 视图View(程序员开发)
注意:View是⼀个接⼝,实现类⽀持不同的View类型(jsp、freemarker、pdfR) ps:不需要程序员开发的,需要程序员⾃⼰做⼀下配置即可