CMU15445(2024fall) Project #1 - Buffer Pool Manager踩坑大全
Never be a prisoner of your past.
It is just a lesson,
not a life sentence.
完整代码见:
SnowLegend-star/CMU15445-2024fall at 023b93655b28953a3c78bc66896640b3ed2c98e2
目录
Task #1 - LRU-K Replacement Policy
Task #2 - Disk Scheduler
Task #3 - Buffer Pool Manager
遇到的Bug
有一说一2023fall的BPM实现起来要比2024fall的流畅不少。2024fall版本的函数拆分粒度太高了,乍一看完全不知道每个函数到底是充当一种什么样的角色,更像是将一份优化过后的代码。相反2023fall的函数设计则较为合理,而且也专门将page guard拆分成了一个单独的task完成。接下来分析2024fall版本的BPM。
Task #1 - LRU-K Replacement Policy
此组件负责跟踪缓冲池中页面的使用情况,以确定要驱逐出内存并返回磁盘的候选页面帧。你将实现一个名为 LRUKReplacer 的类,位于文件 src/include/buffer/lru_k_replacer.h 中,并在 src/buffer/lru_k_replacer.cpp 中实现其对应的实现文件。请注意,LRUKReplacer 是一个独立的类,与任何其他替换器类无关。你只需要实现 LRU-K 替换策略,不需要实现 LRU 或 Clock 替换策略(尽管对应的文件存在)。
LRU-K 算法驱逐的帧是那些具有最大向后 k 距离的帧。向后 k 距离是通过计算当前时间戳与该帧第 k 次访问时间戳之间的差值来确定的。一个帧如果没有 k 次历史访问,则其向后 k 距离将被赋值为 +∞。如果多个帧的向后 k 距离为 +∞,则替换器将驱逐最早的帧(即最早访问的帧)。
LRUKReplacer 的最大大小与缓冲池的大小相同,因为它包含了所有缓冲池中的帧的占位符。然而,并不是所有的帧在任何时候都可以被视为可驱逐的。LRUKReplacer 的大小表示当前在替换器中可驱逐的帧数。LRUKReplacer 在初始化时不会包含任何帧。只有当一个帧被标记为可驱逐时,替换器的大小才会增加。同样,当一个帧被固定(pinned)或者不再使用时,替换器的大小会减少。
#replacer的大小会改变,和frame是否evictable()有关。
Task1的目的是让我们自己实现一个页面逐出算法lru-k,这里先简要介绍下lru-k比lru的优越之处。
LRU-K 是在 LRU 的基础上改进而来的算法,它的目标是提升缓存的命中率,特别是在一些数据的访问模式比较复杂,或者某些数据偶尔被访问但频繁访问时可能被误淘汰的场景中。LRU-K 算法在 LRU 的基础上增加了“历史访问次数”的概念。
核心思想: LRU-K 算法不仅记录数据的最近访问时间,还记录每个数据的访问历史,具体表现为:每个数据项的历史访问记录会被保存在一个队列中,表示它在过去的访问历史中到底被访问了多少次。如果某个数据被访问的次数没有达到设定的阈值 K,它会被认为是“弱访问”的数据,LRU-K 会优先淘汰这类数据。而访问次数达到阈值K后,该数据可以“飞升”至更高的层面,享有更长的声明周期。
下面来举一个具体的例子来帮助理解:我们假设这里k=3,从第一个frame被访问开始计时。
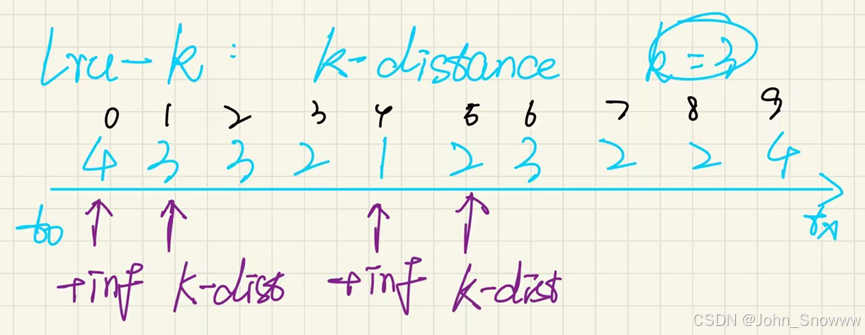
| Frame_id | 访问次数 | 重要程度 |
| 1 | 1 | 不重要,放在level1,访问时间t=4 |
| 2 | 4 | 重要,放在level2,在此基础上最近访问时间是t=5 |
| 3 | 3 | 重要,放在level2,在此基础上访问时间是t=1 |
| 4 | 2 | 不重要,放在level1,访问时间t=0 |
如果此时要将所有页面逐出,那逐出的顺序就是4132。
看懂到底为什么要选用lru-k后,我们就可以着手完成代码了。值得一提的是,我最近发现了一个新的解决问题方法论——在实际动手之前,先画出这个问题的大体执行流程。弄清楚流程之后再对照着要求一步步完成代码。
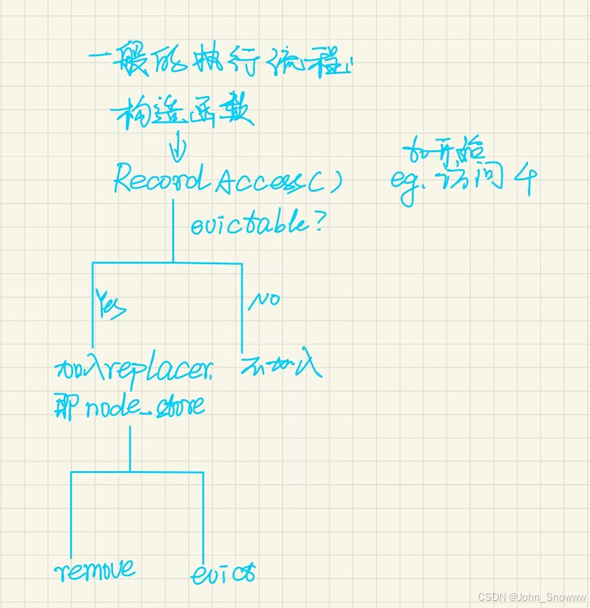
Task1重点就是理解到底怎么逐出frame,总结下来就是两句话:
1、当前frame访问次数<k,则视为不重要的(k-distance=inf),放在level1层,优先逐出这类frame。
2、当前frame访问次数>=k,“飞升”至level2境。在level1层的所有元素都被逐出的情况下,才考虑逐出level2层的元素。
理解这两句话后,task1就迎刃而解了。
Task #2 - Disk Scheduler
Task2主要是理解几个新的c++特性,实现反而是顺手的事。在这个部分,我们重点关注的是DiskManager和DiskScheduler之间的关系。
1. class DiskScheduler {
2. public:
3. explicit DiskScheduler(DiskManager *disk_manager);
4. ~DiskScheduler();
5.
6. /**
7. * TODO(P1): Add implementation
8. *
9. * @brief Schedules a request for the DiskManager to execute.
10. *
11. * @param r The request to be scheduled.
12. */
13. void Schedule(DiskRequest r);
14.
重点看构造函数,DiskScheduler直接是用DiskManager进行初始化的。好家伙,schedule等于是被manager夺舍了。这也就难怪在Buffer_pool_manager中,我想调用DiskManager来对磁盘进行读写的时候,发现manager和bufferpool并不存在friend的关系,仔细一看才发现是通过DiskScheduler来间接实现这点。
在bufferpool中,我们只需要向传入Request(读或写操作),DiskScheduler的background_thread_就会自动处理这个任务。
Task #3 - Buffer Pool Manager
这个bpm相比前两个task真的是复杂度陡增。面对这种稍显复杂的任务,我们可以选择从头问题入手,还是画出头文件的结构图,对bpm的工作流程有一个宏观上的把握。一定要动手把这些元素写下来,只看不动笔的话很容易写着写着把某个元素给忘了。
(图确实略显粗糙,不过我已经尽力了)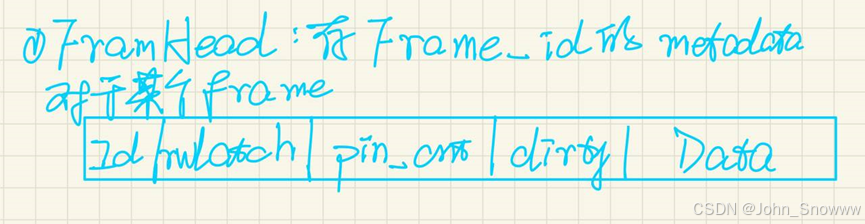

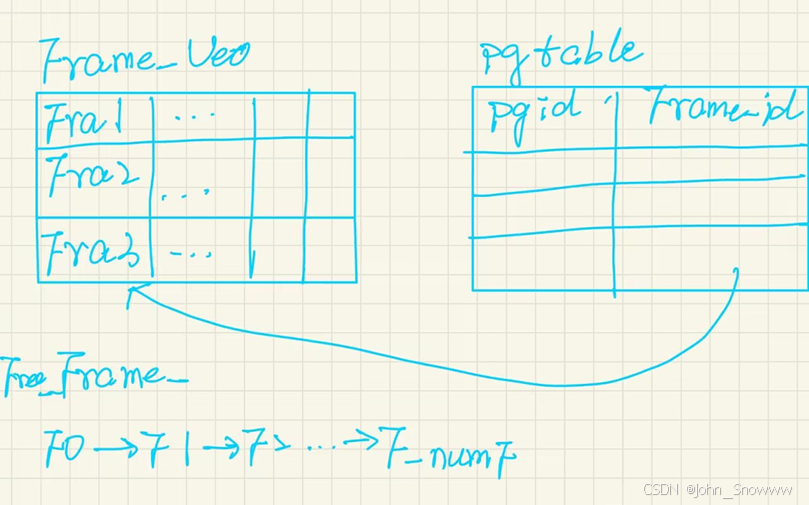
上面三张图就是我对bpm头文件的一个总结,接下里我们就要围绕这三张图对task3进行更深入的剖析。
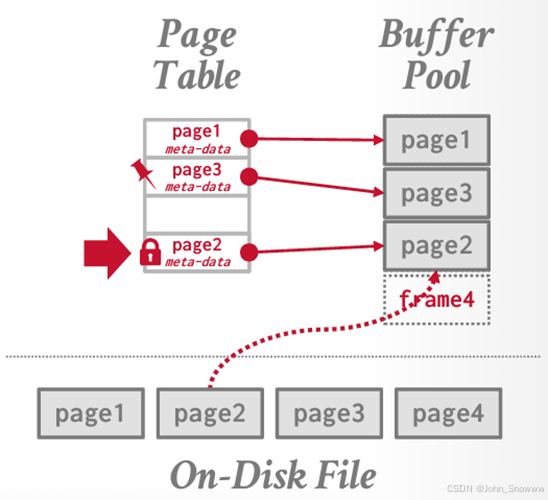
Q:page和frame的区别?
A:根据lecture 06中所说的,page是DiskPage存储的单位,而frame是BufferPool的存储单位。BufferPool从磁盘提取相应的page之后,把这个page放入自己的frame中,所以这里frame用槽(slot)来形容应该更恰当。如果frame都满了,就使用lru-k来进行evict。至于Page Table则是将page的meta-data进行存储。
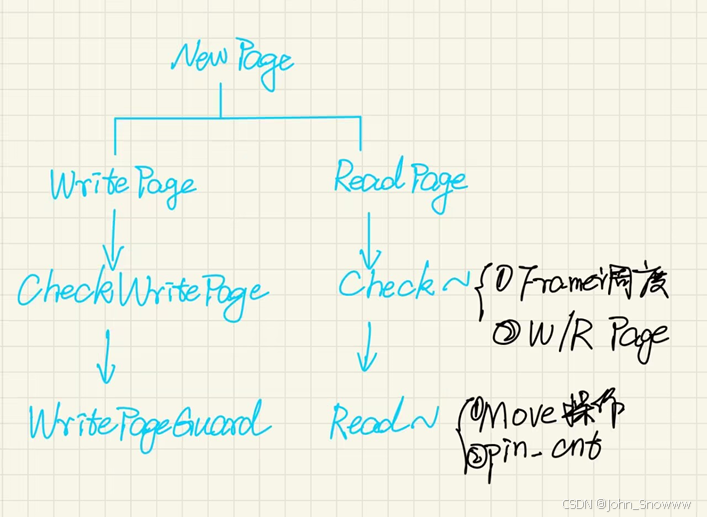
上图是对task3的一个大致总结,接下来分析进行代码实现时会遇到的概念性问题。
Q:如何理解replacer_与pin_count_的关系
A:pin_cnt≠0时,一定不可以evict()。若此时BPM中所有frames的pin_cnt大于>0,则应该报错out-of-memory。
Q:什么时候把page写回disk呢?
A:当某个frame被逐出,本质上是为了逐出存放在这个frame内部的page。为了避免逐出的page的数据丢失,所以在逐出这个page时应该把它修改的数据进行写回。如果page内部的数据没动,即is_dirty是false,可以直接逐出该page。
Q:BPM什么时候与replacer_进行交互呢?
A:调用WritePage/ReadPage时,会调用AccessRecord()。
需要逐出frame时,调用Evict()。
某个frame的pin_cnt=0时,调用SetEvictable()。
Q:BPM该如何与DiskManager进行交互呢?
A:通过DiskScheduler对DiskManager进行间接的交互。
Q:CheckedReadPage和CheckedWritePage该怎么着手呢?
A:正如注释中所提示的,可以分三种情况来实现这两个核心函数。
1、操作的page就存在于BPM中:可以直接构造一个page_guard进行相应的修改。
2、操作的page不在BPM中:我们从free_frames_中挑选一个新的frame,用这个新的frame来存放这个page。然后操作如上。
3、操作的page不在BPM中,且BPM没有多余的free_frames_了。这个时候我们需要调用replacer_来evict某个page,这样就空出了一个新的frame。此时如果frame为脏页,将内容写回,最后再进行步骤2即可。
Q: bpm_latch和rwlatch_怎么理解,进程如果要读/写页面,应该先获得哪个锁呢?
A: bpm_latch:保护整个 BufferPoolManager 级别的资源,用来确保对 BufferPoolManager 资源的互斥访问。
rwlatch_:保护单个frame的读写锁,用来控制并发的读写操作。读操作使用共享锁,写操作使用独占锁。
Q:对死锁这个测试的分析
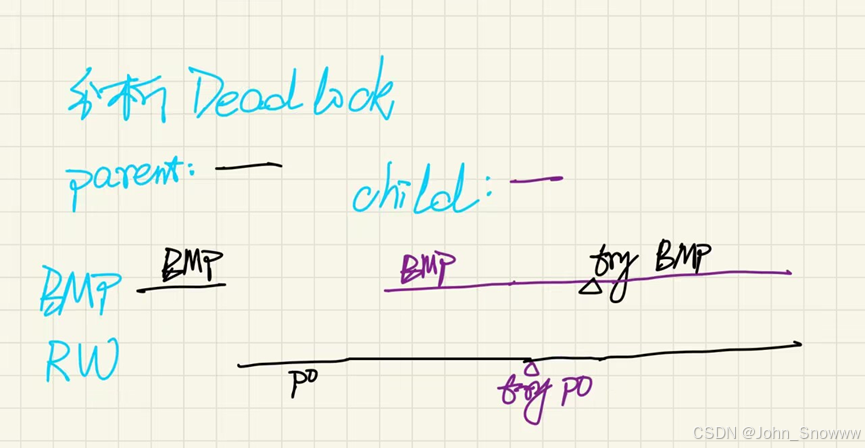
1、parent先获得bpm这把大锁,再获得page0的rwlatch。Parent对page0写入成功后,由于没有释放这个PageGuard,所以仍然占有page0的rwlatch。
2、child获得bpm锁后,尝试获得page0的rwlatch。由于无法获得rwlatch,所以在持有bpm锁的状态下一直等待。
3、parent尝试写p1,却发现无法获得bpm锁,故一直处于等待状态。
4、parent和child形成循环等待,故死锁。
解决方案就是一句话:frame获得了bpm锁后,一定要保证对frame的操作流程可以正常进行下去,否则主动释放bpm锁。
1. /*
2. 看能不能获得RW锁
3. */
4. auto BufferPoolManager::AcquireRWLock(frame_id_t frame_id) -> bool {
5. if (frames_[frame_id]->rwlatch_.try_lock()) {
6. frames_[frame_id]->rwlatch_.unlock();
7. return true;
8. }
9. bpm_latch_->unlock();
10. return false;
11. }
12.
Q:PagePinEasyTest这个测试点我不是很理解啊,这里pageid0的内容不是已经被写入到磁盘里面去了吗?再重新用pageid0给新的页面初始化,那这个新的页面怎么会存pageid0之前的数据呢难道还要从磁盘中把pageid0的内容再读取回来吗?
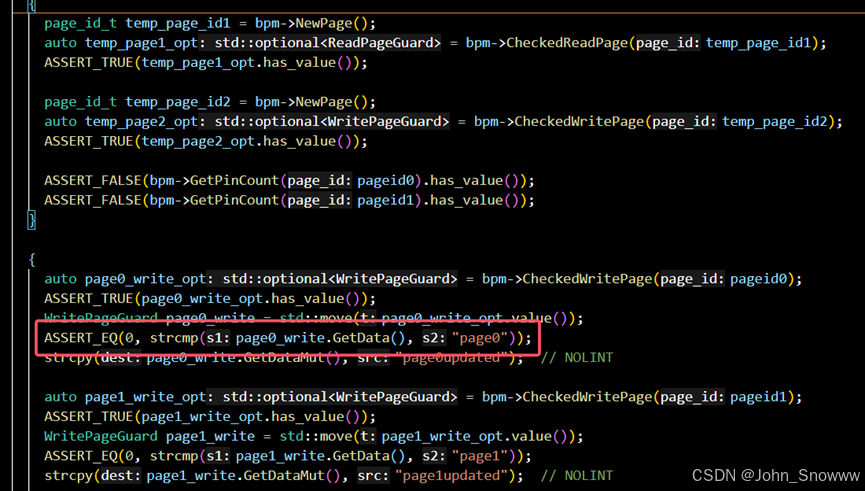
A:确实是得重新读回来。
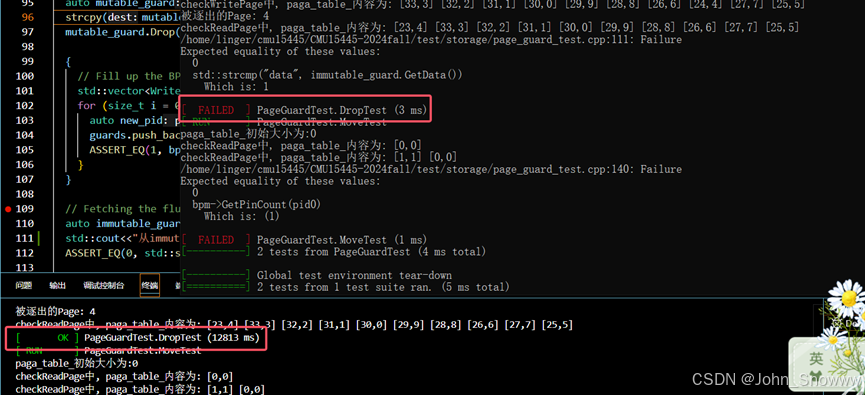
遇到的Bug
①这里index_min会基于level1继续累计,应该在进入level2循环的时候重置index_min。
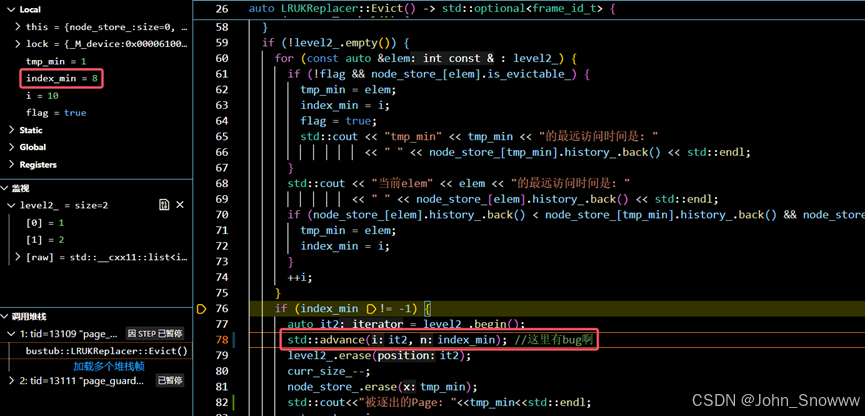
②对map的理解有问题。Find找的是对应的key,而不是value。
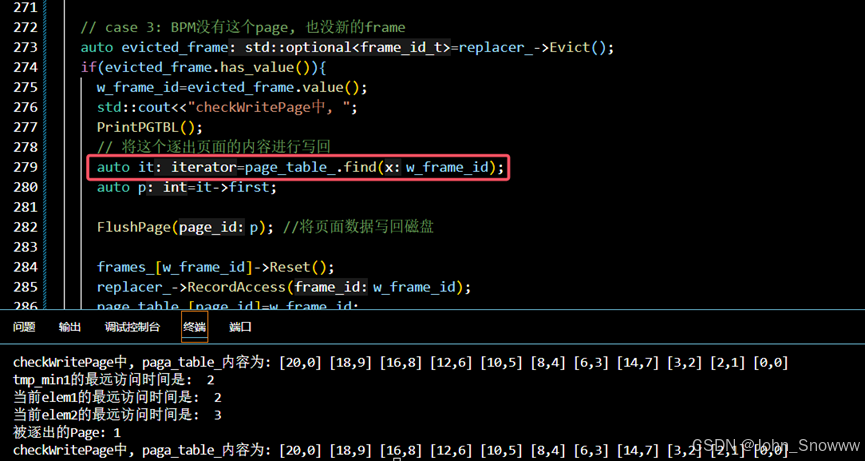
③这里虽然成功写入了data,但是is_dirty没有设置。
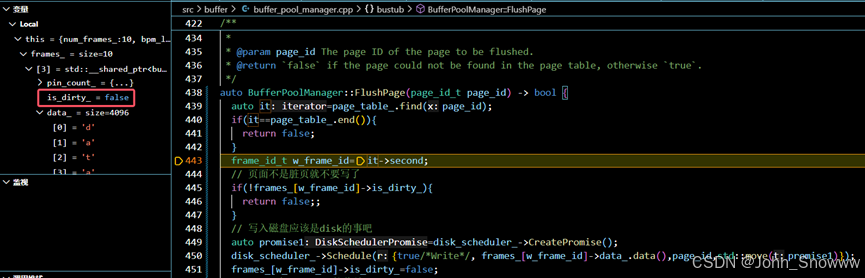

④离谱bug我不知道如何是好?奇怪的是我把读取的数据打印出来之后,就可以通过测试了,真是奇怪也哉。