prometheus部署和告警设置
prometheus概念
普罗米修斯是一个开源的,可以容器化部署(pod),部署在k8s集群中,也可以直接部署在宿主机的二进制的方式部署。
在k8s集群当中,一般都是用普罗米修斯来对集群进行监控。
- 节点监控:监控集群所有节点的状态
- pod监控:监控集群部署所有的服务
普罗米修斯:开源的服务监控系统和时序数据库
数据通过时序数据库来进行收集,展示数据模型,存储,以及提供插叙的接口。
核心组件:prometheus server 从静态配置的监控目标,以及基于服务发现,自动从目标中拉取数据,保存到数据中,以趋势化的图形来展示数据的变化。
任何被监控的目标都必须涵盖在监控系统当中,才能进行时序数据的采集、存储、告警和展示。
普罗米修斯支持自动发现,以及模板的直接使用。
普罗米修斯的特点
1、多维数据模型:由度量名称和键值对表示的时间序列的数据,每一个数据都有一个样本。
- 时间序列数据:按照时间的顺序,记录系统、设备等等变化的数据。
2、内置时间序列数据库,所有的数据查询,展示都是依靠这个数据库。
3、promql:查询语句,用来实现多维数据的基础。
4、基于http协议的pull方式,采集时间序列数据。
5、可以通过pushGateway组件收集数据
6、既支持静态配置,也可以自动发现目标来收集数据。
7、因为普罗米修斯本身采集的数据直观化不是很好,可以外接一个图形化的解析工具grafana,更直观的分析趋势数据。
8、普罗米修斯本身设计的目的不是精确的展示数据,只是提供一种趋势的变化和走向。
存储引擎
TSDB作为数据的存储引擎:
- 存储的数量十分庞大
- 大部分都是写入操作
- 写入操作是按照时序添加到数据库
- 几乎不涉及更新数据,因为数据是实时变化,只需要记录即可。
- 高并发的性能很强
普罗米修斯组件
1、prometheus server:服务核心组件,通过pull的方式获取数据,存储时间序列的数据。基于告警规则生成告警通知。
- retrieval:负责在获取的目标主机抓取数据。
- storage:存储,采集到数据保存到磁盘,数据保存默认是15天。
- promql:查询语言的模块,时序趋势图如何获取,依靠查询语句来获取。
2、client library:客户端库,就是在客户端用于测量系统的工具。
3、node-exporter:用来收集服务器物理指标状态,包括负载、cpu、内存、硬盘(读写)、网络等等。
4、service discovery:服务发现,动态的监控目标,通过文件、DNS解析等等自动发现集群内的服务。
5、告警功能,altermanager:独立的告警模块,支持电子邮件、钉钉、企业微信。
6、pushgateway:类似一个中转站,通过这种方式代理收集数据,发送到prometheus server,不需要单独配置,自动功能,获取数据的方式也是pull。
7、grafana:数据展示
工作流程
1、获取数据,prometheus server 通过pushgateway,把采集目标的数据拉取到server中。
2、通过人工预设(promql)或者第三方下载的模板,对数据进行统计,形成一个趋势的时间序列的图形,把数据保存到TSDB中。
3、通过 altermanager,设置监控项的阈值,超过阈值之后提供告警的服务。
4、通过自带的wei ui界面可以展示时序数据的走向,推荐使用 grafana 来展示趋势的数据。
prometheus的局限性和zabbix的对比
prometheus的局限性:
1、prometheus是一个指标监控系统,不适合存储时间和日志,只是记录数据的变化,展示的是趋势化的监控,并非精确的数据。
2、prometheus不是为了存储大量的历史数据而设计的,而是为了展示近期查询的数据。
3、prometheus集群机制不成熟,单节点部署,没有高可用。
prometheus和zabbix的对比:
1、zabbix是大而全的监控系统,是一款非常成熟的系统,有web界面,告警功能等等,上手的难度也很低。但是定制化的使用难度比较大。
2、数据存储
- zabbix使用第三方数据库来保存数据,目前支持mysql、postgresql、oracle等等,支持数据类型比较多,日志、文件都可以存储
- prometheus使用自带的TSDB存储数据,不包含文本和日志,只支持时间序列的值。
3、查询功能
- zabbix在查询方面功能较弱,只能在页面做一些有限操作。
- prometheus自带数据库,有自己的promql,语句也非常灵活,在页面可以随时调整语句的结构,收集数据。
4、告警
从告警的层面来说,二者没有本质的区别。
总结:
如果对于传统的服务器监控、已经传统方式部署的服务(不是基于容器化部署的)推荐使用zabbix。各种的模版和自定义的监控项非常成熟,对于监控要求不高的,可以使用zabbix,如果是监控容器化部署的服务不推荐使用zabbix。
prometheus和k8s集群的配合度更高,适配性更强,定制化程度也很高,上手难度在于如何实现promql的数据查询。监控微服务推荐使用prometheus。
prometheus的pod部署
1、部署node-exporter
node-exporter:节点收集数据。daemonset 在每个节点部署一个pod。

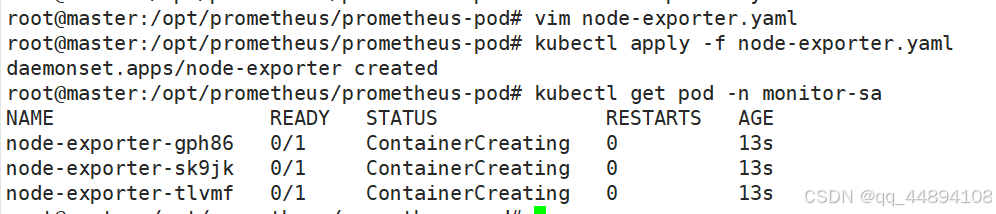
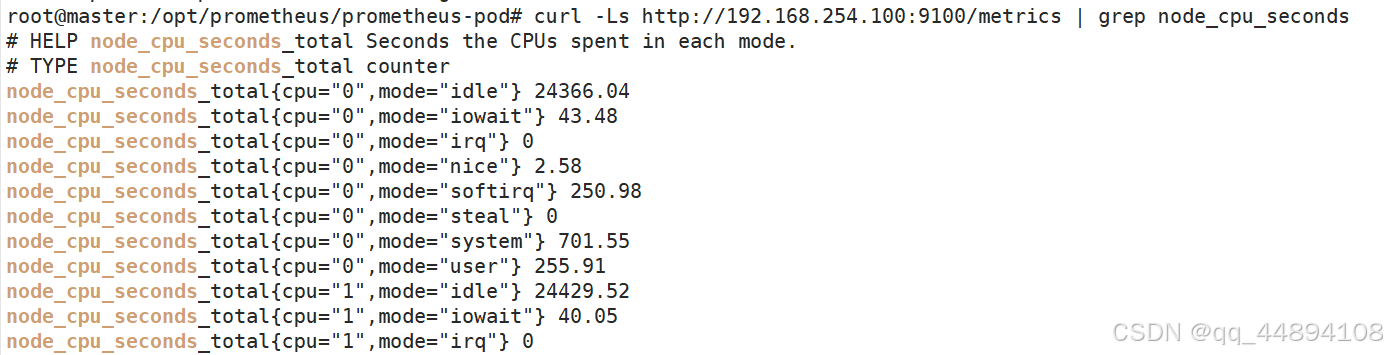
通过 node-exporter 采集cpu的数据,node-exporter 默认的监听端口是 9100,可以执行 curl http://主机ip:9100/metrics 获取到主机的所有监控数据。
2、部署prometheus的组件
创建 sa 账号,对 sa 做 rbac 授权

部署Prometheus
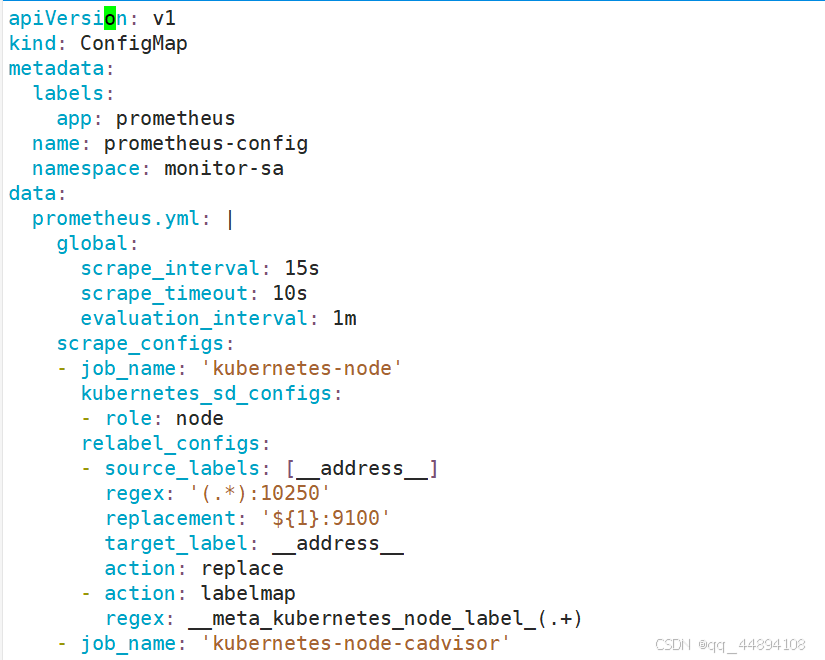
部署Prometheus的deployment和service

网页访问http://192.168.254.100:30296/prometheus,网页访问http://192.168.254.100:30296/
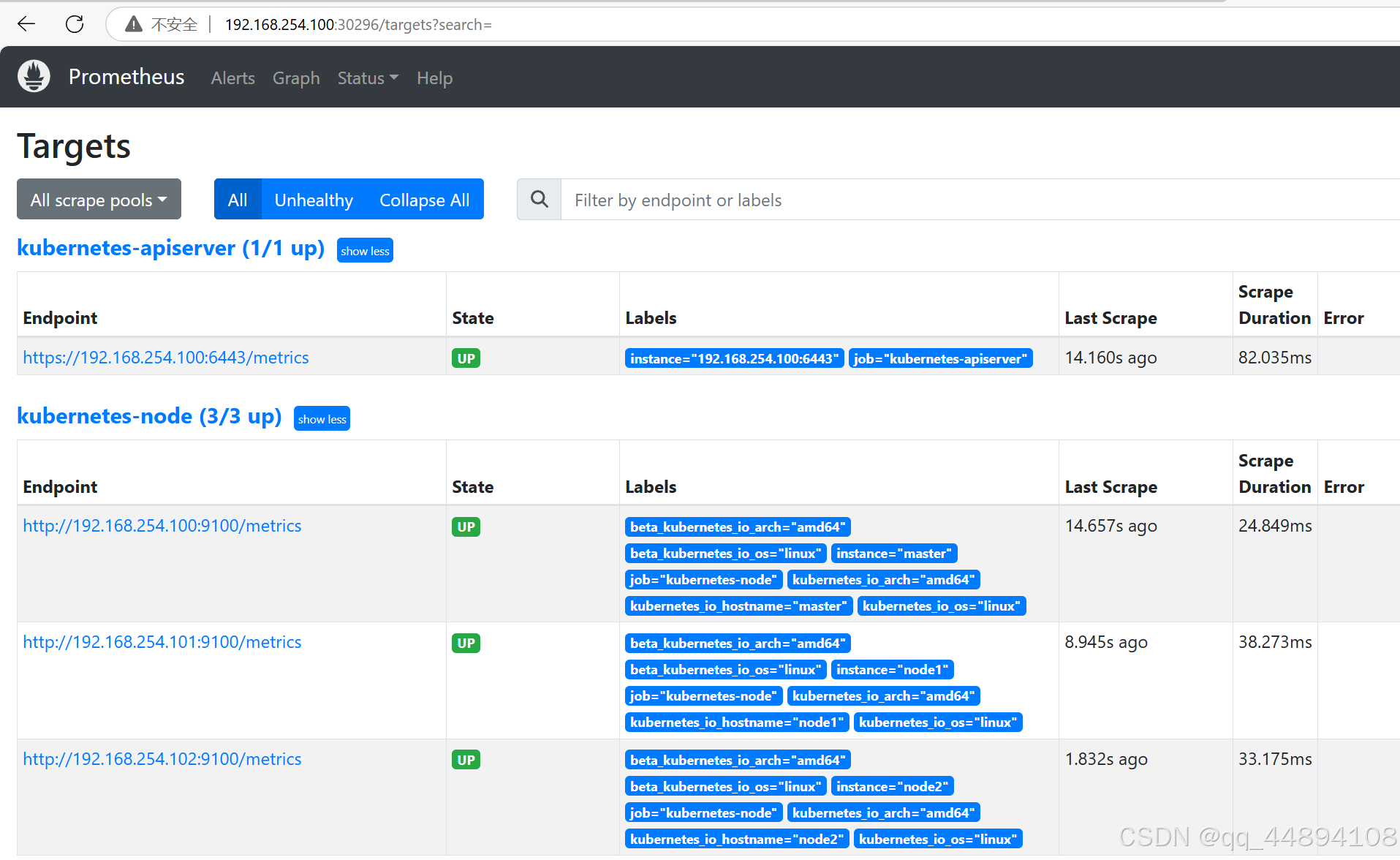
查询 K8S 集群中一分钟之内每个 Pod 的 CPU 使用率
sum by (name)( rate(container_cpu_usage_seconds_total{image!="", name!=""}[1m] ) )
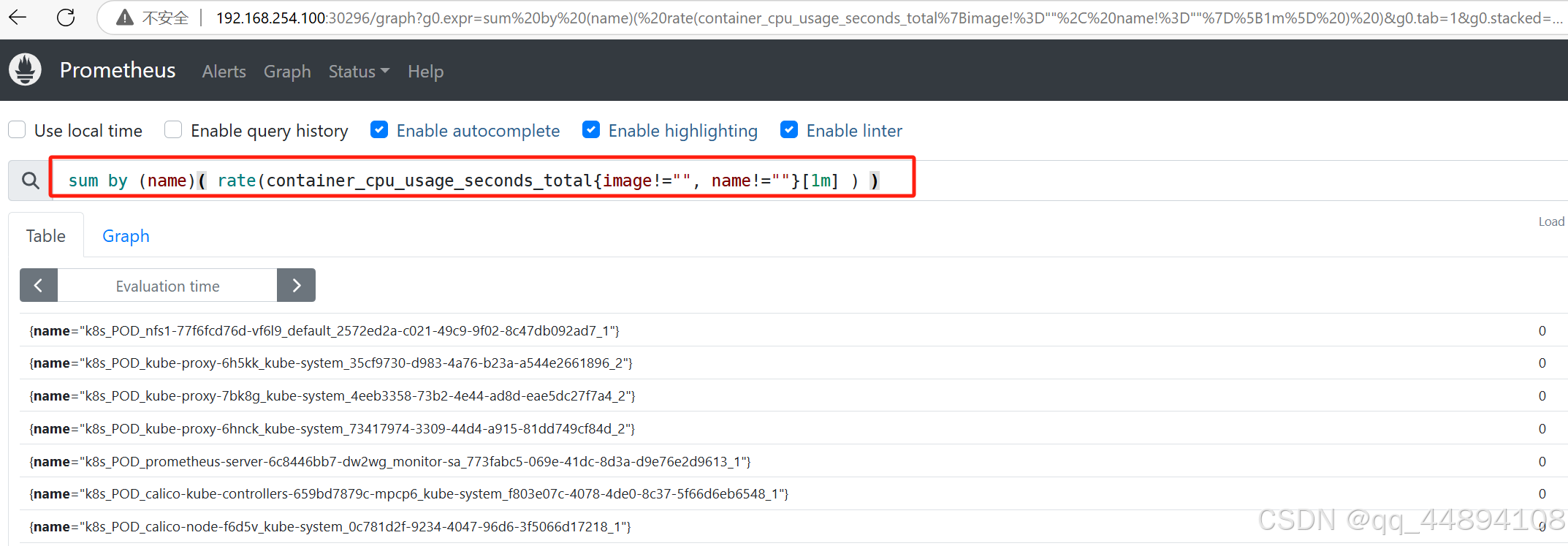
3、部署grafana图形化界面
部署grafana

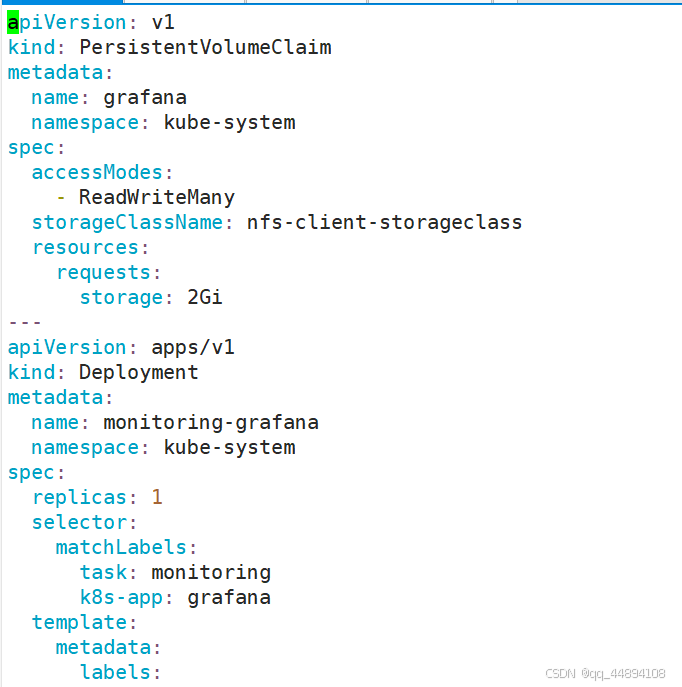
Grafana 配置
(1)浏览器访问http://192.168.80.11:32087 ,登陆 grafana
(2)开始配置 grafana 的 web 界面:选择 Add data source
【Name】设置成 Prometheus
【Type】选择 Prometheus
【URL】设置成 http://prometheus.monitor-sa.svc:9090
#使用service的集群内部端口配置服务端地址
点击 【Save & Test】
(3)导入监控模板
在web 界面点击+号,import,导入提前准备好的模板。
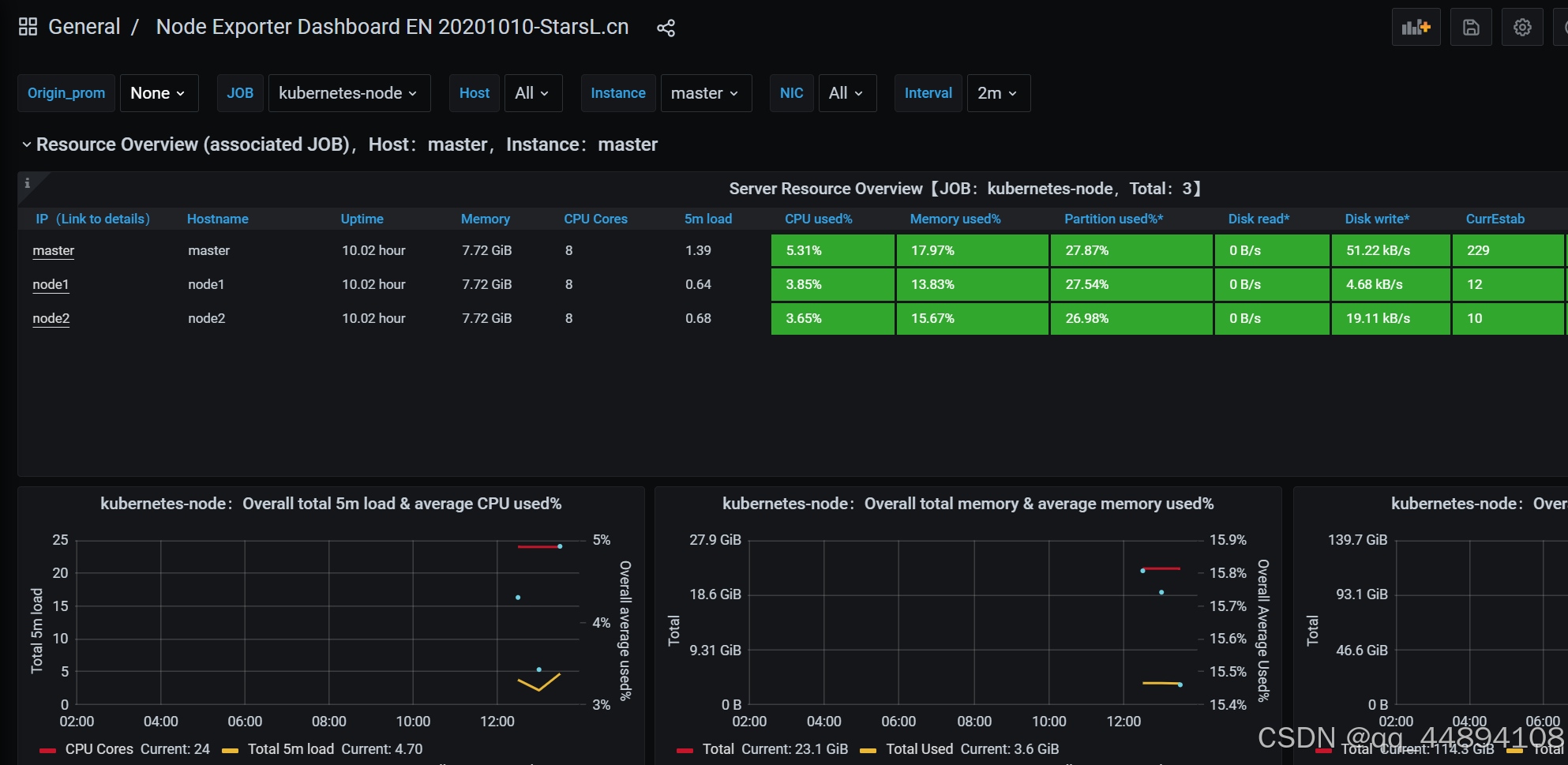
prometheus告警设置
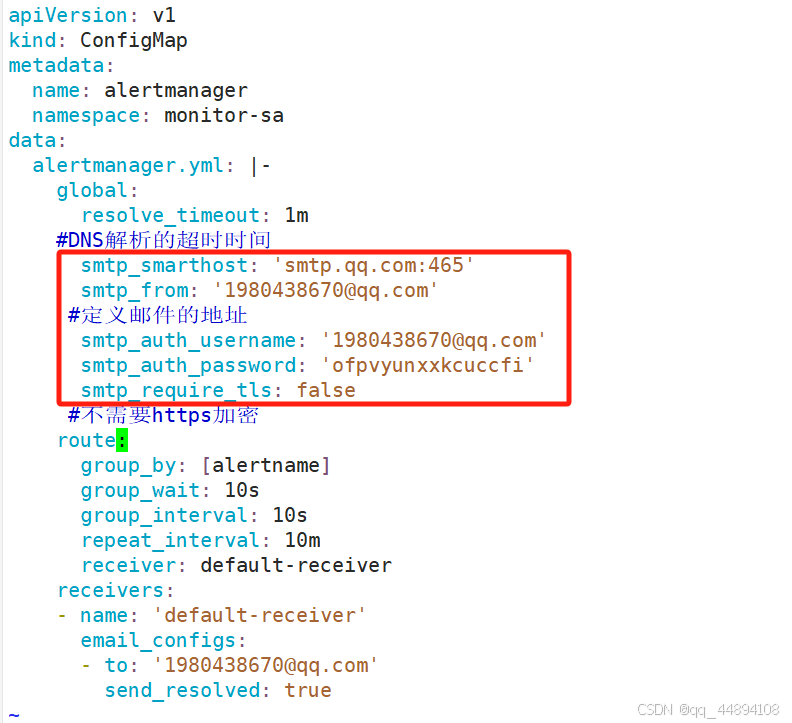
1、设置监控的告警邮箱,以及告警的设置。部署alter-mail.yaml,以configmap的形式传给pod。
2、创建 sa 账号,对 sa 做 rbac 授权
kubectl create serviceaccount monitor -n monitor-sa
#创建 sa 账号,对 sa 做 rbac 授权
kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
#把 sa 账号 monitor 通过 clusterrolebing 绑定到 clusterrole 上
3、创建 prometheus 和告警规则配置文件 prometheus-alertmanager-cfg.yaml
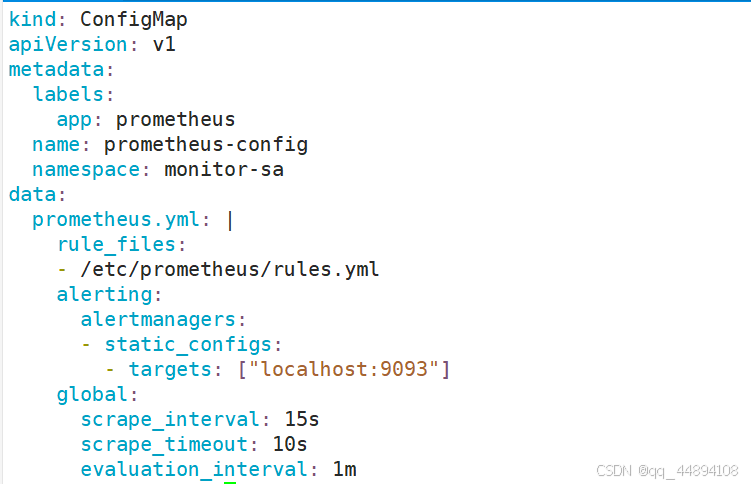
4、删除之前的配置
kubectl delete -f Prometheus-configmap.yaml
kubectl delete -f prometheus-server.yaml
5、部署prometheus-alertmanager-cfg.yaml和alter-mail.yaml

6、更新配置,部署新的prometheus 和 alertmanager
首先生成一个 secret 资源 etcd-certs,这个在部署 prometheus 需要,用于监控 etcd 相关资源
kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
再部署prometheus 和 alertmanager,prometheus-server-alert.yaml
然后运行kubectl apply -f prometheus-server-alert.yaml

7、部署 prometheus 和 alertmanager 的service,prometheus-service-alter.yaml


8、这时候我们登录用web登录普罗米修斯发现告警已经生成并且已经发qq邮件给我们
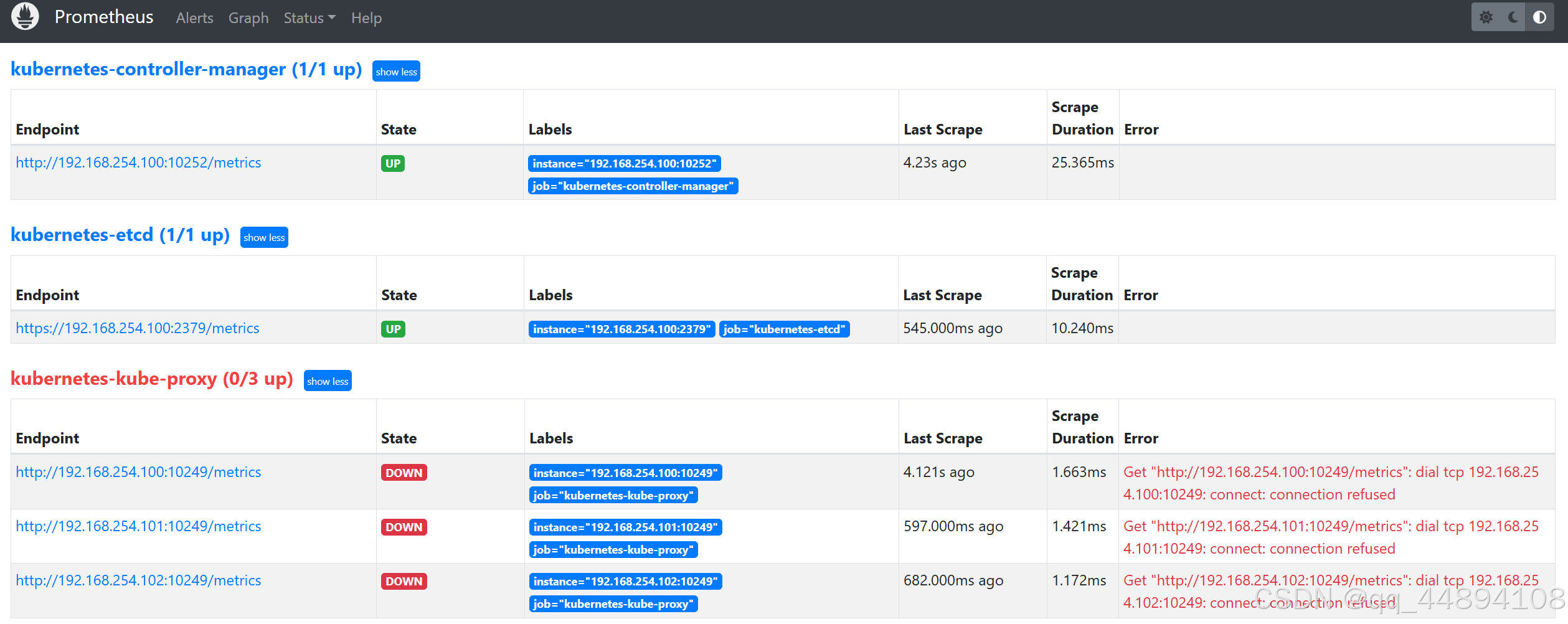
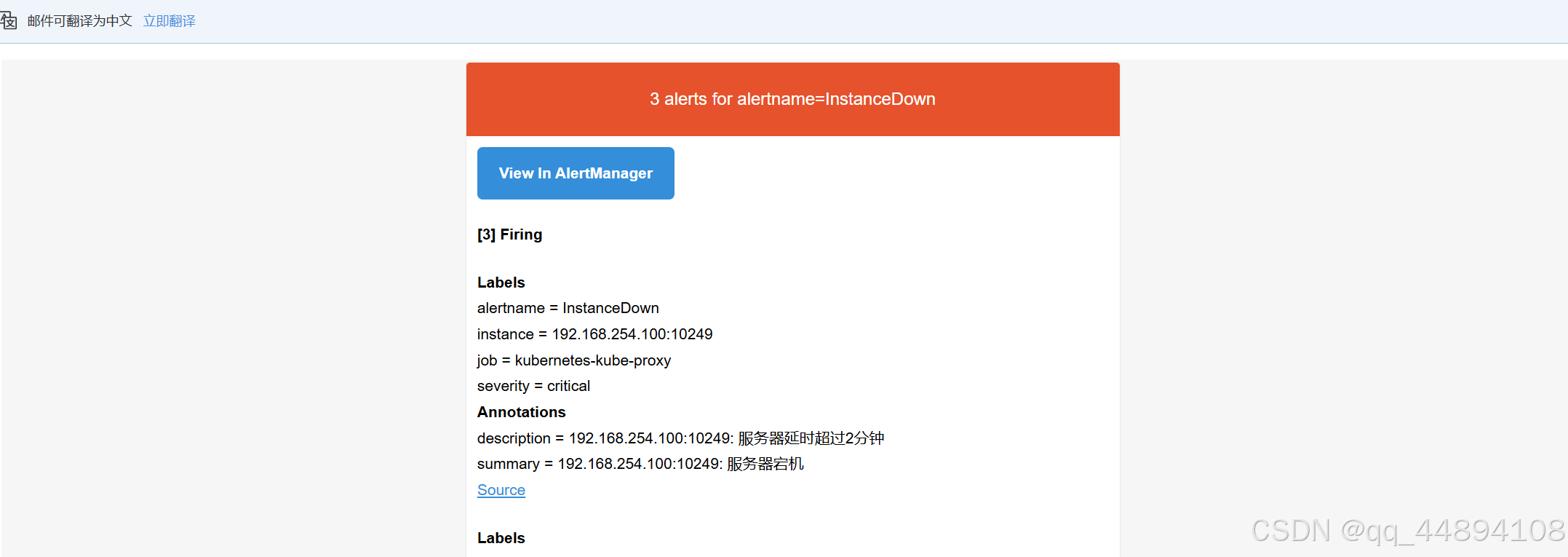
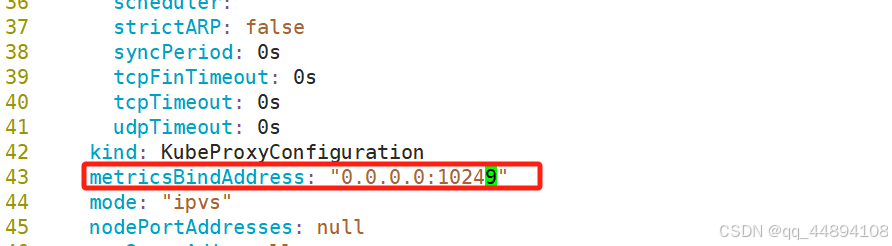
上面的告警是因为 kube-proxy 默认端口10249是监听在 127.0.0.1 上的,需要改成监听到物理节点上,,直接修改即可
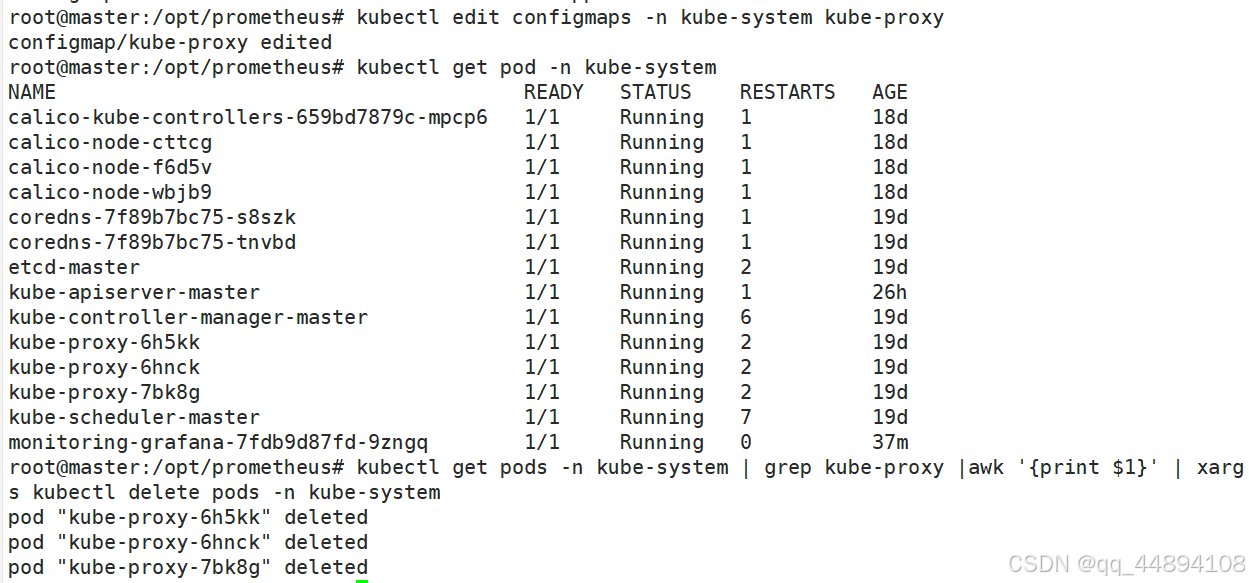
kubectl get pods -n kube-system | grep kube-proxy |awk '{print $1}' | xargs kubectl delete pods -n kube-system #重新启动 kube-proxy