Mysql——索引
Mysql——索引
- 索引
- 优缺点:
- 索引结构
- 索引分类
- 聚集索引选取规则:
- 语法
- 使用规则
- 索引失效情况
- 覆盖索引
- SQL 优化
- order by优化
- group by优化
索引
索引是帮助 MySQL 高效获取数据的一种数据结构。
优缺点:
- 优点:
提高数据检索效率,降低数据库的IO成本
通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗 - 缺点:
索引列也是要占用空间的
索引大大提高了查询效率,但降低了更新的速度,比如 INSERT、UPDATE、DELETE
索引结构
MySQL 索引数据结构对经典的 B+Tree 进行了优化。在原来 B-Tree 的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的 B+Tree,提高区间访问的性能。
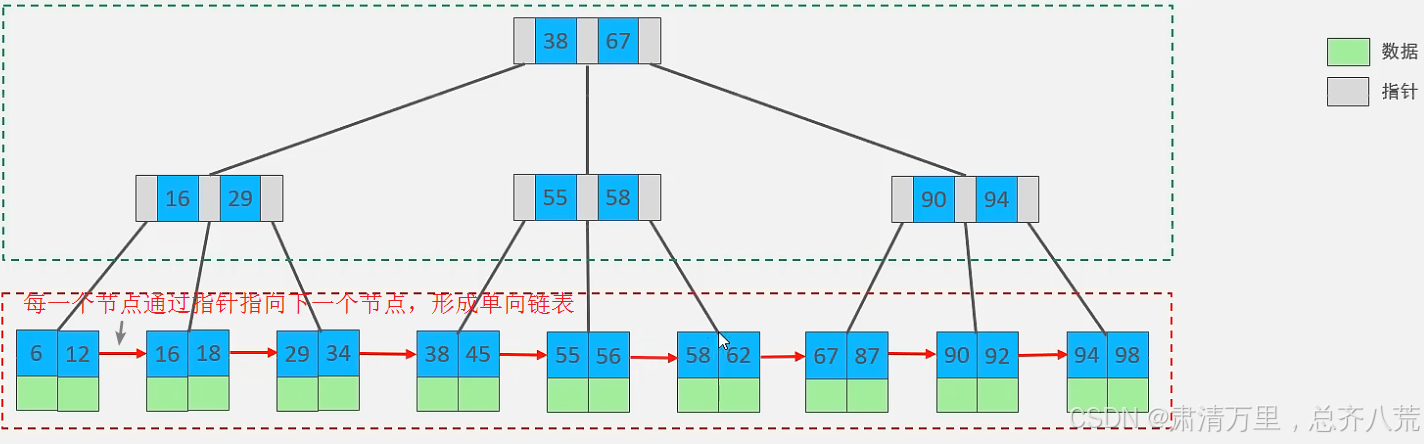
演示地址
索引分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 默认自动创建, | 只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
在 InnoDB 存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered Index) | 将数据存储与索引放一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个(叶子节点存储整行的数据) |
| 二级索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个(叶子节点存储id) |
聚集索引选取规则:
如果存在主键,主键索引就是聚集索引
如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引
如果表没有主键或没有合适的唯一索引,则 InnoDB 会自动生成一个 rowid 作为隐藏的聚集索引
语法
创建索引:
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name, ...);
如果不加 CREATE 后面不加索引类型参数,则创建的是常规索引
查看索引:
SHOW INDEX FROM table_name;
删除索引:
DROP INDEX index_name ON table_name;
案例:
-- name字段为姓名字段,该字段的值可能会重复,为该字段创建索引
create index idx_user_name on tb_user(name);
-- phone手机号字段的值非空,且唯一,为该字段创建唯一索引
create unique index idx_user_phone on tb_user (phone);
-- 为profession, age, status创建联合索引
create index idx_user_pro_age_stat on tb_user(profession, age, status);
-- 为email建立合适的索引来提升查询效率
create index idx_user_email on tb_user(email);
-- 删除索引
drop index idx_user_email on tb_user;
使用规则
- 最左前缀法则
如果索引关联了多列(联合索引),要遵守最左前缀法则,最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。
create index idx_stu_age_sex_country on stu (country,age,sex);
EXPLAIN SELECT * FROM stu WHERE country = 'China' AND age = 14 AND sex = 'Male'
如果跳跃某一列,索引将部分失效(后面的字段索引失效)。
联合索引中,出现范围查询(<, >),范围查询右侧的列索引失效。可以用>=或者<=来规避索引失效问题。
create index idx_stu_name_age_phone on stu (name,age,phone);
EXPLAIN SELECT * FROM stu WHERE name = 'Student16' AND age >= 16 AND phone = '12328557947'
create index idx_stu_age_sex_country on stu (country,age,sex);
EXPLAIN SELECT * FROM stu WHERE country = 'China' AND age = 14 AND sex = 'Male'
索引失效情况
- 在索引列上进行运算操作,索引将失效。如:
explain select * from stu where substring(phone, 10, 2) = '15';
- 字符串类型字段使用时,不加引号,索引将失效。如:
explain select * from stu where phone = 17799990015;
- 模糊查询中,如果仅仅是尾部模糊匹配,索引不会是失效;
- 前后都有 % 也会失效。
- 如果是头部模糊匹配,索引失效。如:
explain select * from stu where phone like '%16754'
- 用 or 分割开的条件,如果 or 其中一个条件的列没有索引,那么涉及的索引都不会被用到。
explain select * from stu where phone = '11955716754' or name = 'Student35' OR id_card_num = '313703455'
如果 MySQL 评估使用索引比全表更慢,则不使用索引。
覆盖索引
如果在聚集索引中直接能找到对应的行,则直接返回行数据,只需要一次查询,哪怕是select *;如果在辅助索引中找聚集索引,如select id, name from xxx where name=‘xxx’;,也只需要通过辅助索引(name)查找到对应的id,返回name和name索引对应的id即可,只需要一次查询;如果是通过辅助索引查找其他字段,则需要回表查询,如
select id, name, gender from xxx where name=‘xxx’;
所以尽量不要用select *,容易出现回表查询,降低效率,除非有联合索引包含了所有字段
SQL 优化
order by优化
- Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区 sort buffer 中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序
- Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高
如果order by字段全部使用升序排序或者降序排序,则都会走索引,但是如果一个字段升序排序,另一个字段降序排序,则不会走索引,explain的extra信息显示的是Using index, Using filesort,如果要优化掉Using filesort,则需要另外再创建一个索引,如:
create index idx_stu_age_phone on stu(age , phone );
EXPLAIN SELECT age,phone FROM stu ORDER BY age ASC,phone DESC
create index idx_stu_age_phone on stu(age ASC, phone DESC);
此时使用select id, age, phone from tb_user order by age asc, phone desc;会全部走索引
总结:
- 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则
- 尽量使用覆盖索引
- 多字段排序,一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)
group by优化
- 在分组操作时,可以通过索引来提高效率
SELECT address,count(1) FROM stu GROUP BY address
- 分组操作时,索引的使用也是满足最左前缀法则的
EXPLAIN SELECT address,count(1),school FROM stu GROUP BY address,school
#### update优化(避免行锁升级为表锁)
InnoDB 的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则会从行锁升级为表锁。
如以下两条语句:
```sql
//这句由于id有主键索引,所以只会锁这一行;
update user set no = '123' where id = 7;
//这句由于name没有索引,所以会把整张表都锁住进行数据更新,解决方法是给name字段添加索引
update student set no = '123' where name = 'test';,