RK3588开发板本地部署DeepSeek-R1
前言
最近deepseek闹的比较火,看网上已经有博主将deepseek部署到了RK3588上,自己手头刚好有RK3588的板子,于是就参考网上的教程部署了一套本地的deepseek,体验一下国人的AI。下面记录了详细的部署过程,有感兴趣的小伙伴可以试试看。
一、模型文件转换
以下操作在ubuntu主机上进行,这里选择的是ubuntu22.04.
1.下载模型文件
以DeepSeek-R1-Distill-Qwen-1.5B为例,可以从"huggingface.co"拉取模型文件,但是由于网络的原因要么下载的慢要么就是无法访问,这里通过hf-mirror或modelscope获得更快的下载速度。
$ git lfs install #如果检查未安装可以执行'apt-get install git-lfs'进行安装
$ git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B.git
2.RKNN-LLM工具包
$ git clone https://github.com/airockchip/rknn-llm.git
$ cd rknn-llm/rkllm-toolkit
$ pip3 install rkllm_toolkit-1.1.4-cp310-cp310-linux_x86_64.whl
注意:安装过程会通过网络现在软件包,如果出现超时可以重新执行命令。
3.执行模型转换
进入"rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export"目录,编辑export_rkllm.py文件,修改变量modelpath的值为模型文件的路径。
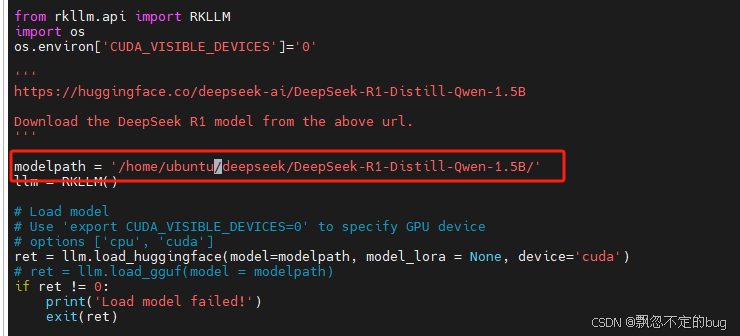
保存后执行下面命令进行模型转换。
python3 export_rkllm.py
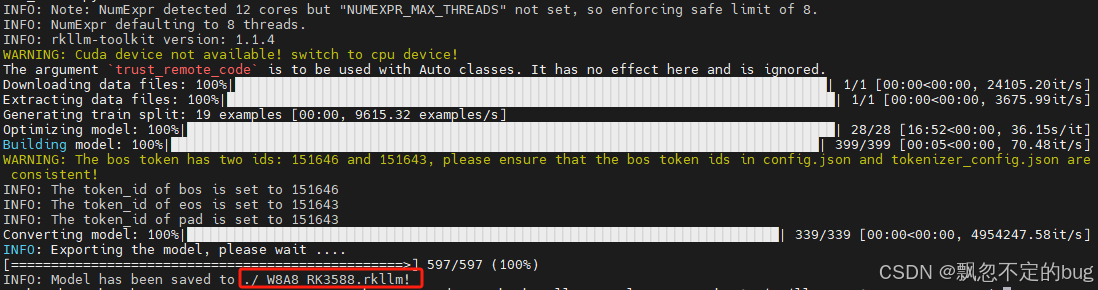
注意:这里不建议在虚拟机上执行,很可能会由于性能的问题导致转换过程失败。
转换完成后.rkllm格式的模型文件默认放在export_rkllm.py所在目录。
如果不想转换模型可以下载官方模型(密码:rkllm)。
二、模型验证
说明:以下操作在RK3588开发板上,操作系统为ubuntu20.04.
1.编译RKNN-LLM
复制rknn-llm到开发板上,进入"rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy"目录,编辑build-linux.sh修改里面的编译工具链,保存后运行build-linux.sh进行编译。
这个过程也可以在ubuntu主机上进行,注意修改主机上的交叉编译工具链地址即可。
编译完成后在"rknn-llm/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/install/demo_Linux_aarch64"中会多出一个llm_demo程序和对应的库。
2.测试验证
复制已经转换好的模型文件到开发板上。执行下面命令。
$ export LD_LIBRARY_PATH=./lib:$LD_LIBRARY_PATH
$ ./llm_demo /home/ubuntu/deepseek/_W8A8_RK3588.rkllm 2048 4096
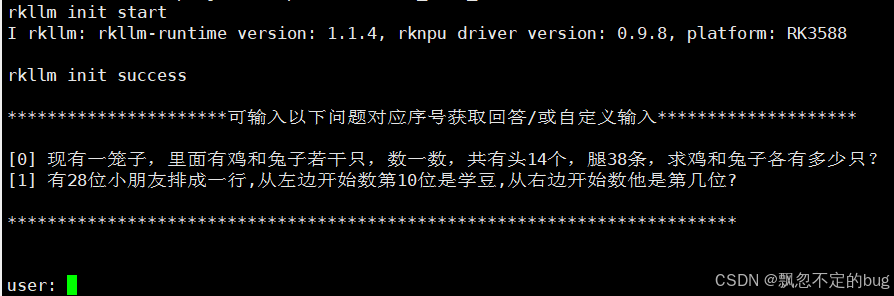
通过下面命令可以查看npu的使用情况。
cat /sys/kernel/debug/rknpu/load
除了使用llm_demo外也可以通过提供的pyhon脚本实现客户端和服务端的访问。
服务端:
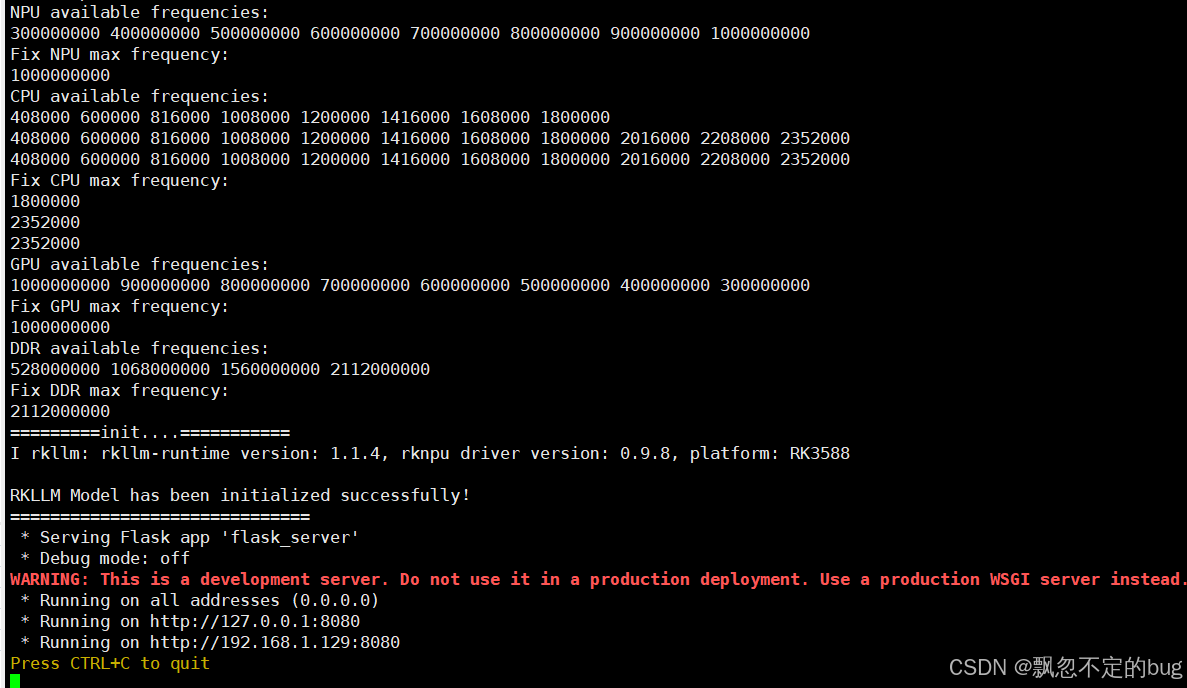
进入rknn-llm/examples/rkllm_server_demo/rkllm_server目录,执行下面命令:
ulimit -n 102400
python3 flask_server.py --rkllm_model_path /home/ubuntu/deepseek/module/DeepSeek-R1-Distill-Qwen-1.5B_FP16_RK3588.rkllm --target_platform rk3588
提示未安装flask时,可利用下面命令安装
pip3 install flask
客户端:
新打开一个终端,进入rknn-llm/examples/rkllm_server_demo/目录,执行以下命令:
python3 chat_api_flask.py
运行后如果不能正常对话,可以尝试修改chat_api_flask.py中的server_url字段,将上面log中的IP地址替换原有的IP。
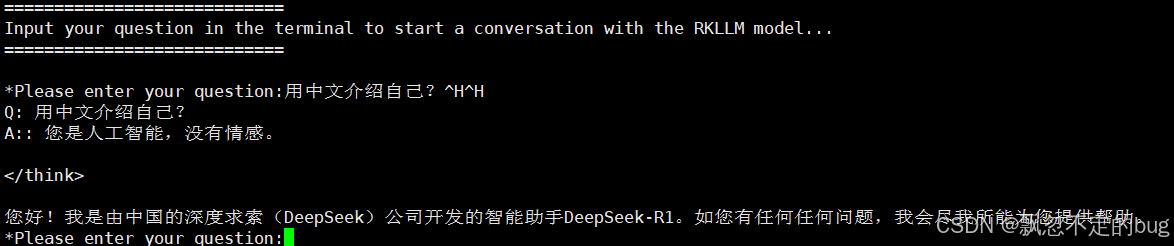
网上有帖子说npu的使用率可以达到80%,cpu仅消耗10%~20%,而我实际测试的结果npu只用了50%多,CPU用了200%左右。用python的方式要好一点npu 60%多,cpu降低到70%左右。不清楚什么情况,有兴趣的朋友可在评论区讨论。
三、NPU驱动
执行ll_demo时若提示npu版本低,可参见下面方法升级npu驱动。新的npu驱动位于"rknn-llm/rknpu-driver"中。复制其中的压缩包到内核源码的顶层目录下执行下面命令进行解压。
tar -xjvf rknpu_driver_0.9.8_20241009.tar.bz2
注意:一定要解压到内核源码的顶层目录下,因为压缩包解压后是以drivers目录为起点的。
注意:一定要解压到内核源码的顶层目录下,因为压缩包解压后是以drivers目录为起点的。
编译错误1:

阅读源码可以看到这个是和rk3576相关的,所以这里直接注释掉。
编译错误2:

内核版本问题,5.10的内核中没有这两个函数,将驱动中这两个函数进行替换,修改如下:
diff --git a/drivers/rknpu/rknpu_gem.c b/drivers/rknpu/rknpu_gem.c
index a5c5354ed85c..d6886fe31f64 100644
--- a/drivers/rknpu/rknpu_gem.c
+++ b/drivers/rknpu/rknpu_gem.c
@@ -995,7 +995,7 @@ static int rknpu_gem_mmap_pages(struct rknpu_gem_object *rknpu_obj,
struct drm_device *drm = rknpu_obj->base.dev;
int ret = -EINVAL;
- vm_flags_set(vma, VM_MIXEDMAP);
+ vma->vm_flags |= VM_MIXEDMAP;
ret = __vm_map_pages(vma, rknpu_obj->pages, rknpu_obj->num_pages,
vma->vm_pgoff);
@@ -1088,7 +1088,7 @@ static int rknpu_gem_mmap_cache(struct rknpu_gem_object *rknpu_obj,
return -EINVAL;
}
- vm_flags_set(vma, VM_MIXEDMAP);
+ vma->vm_flags |= VM_MIXEDMAP;
vm_size = vma->vm_end - vma->vm_start;
@@ -1144,8 +1144,8 @@ static int rknpu_gem_mmap_buffer(struct rknpu_gem_object *rknpu_obj,
* vm_pgoff (used as a fake buffer offset by DRM) to 0 as we want to map
* the whole buffer.
*/
- vm_flags_set(vma, VM_DONTCOPY | VM_DONTEXPAND | VM_DONTDUMP | VM_IO);
- vm_flags_clear(vma, VM_PFNMAP);
+ vma->vm_flags |= VM_DONTCOPY | VM_DONTEXPAND | VM_DONTDUMP | VM_IO;
+ vma->vm_flags &= ~VM_PFNMAP;
vma->vm_pgoff = 0;
vm_size = vma->vm_end - vma->vm_start;