链表理论基础
一、链表的基本知识
链表是一种特殊的数据结构,下面通过一个生活中的例子来帮助理解:想象你在银行办理业务时,首先需要抽号。每个顾客拿到号码后,会随意坐在一旁等待叫号。当叫到你时,你才会去办理业务。这里,抽到的号码就像是链表中的“节点”,每个顾客(节点)持有一个号码,并通过叫号顺序(指针)指向下一个顾客(节点)。整个过程就像是链表的遍历:每个节点通过“指针”连接下一个节点,直到最后一个顾客,指向为 NULL,表示结束。每位顾客坐的位置是无序的,但是办理业务时却是有序的,这表明他们在逻辑上有序的。

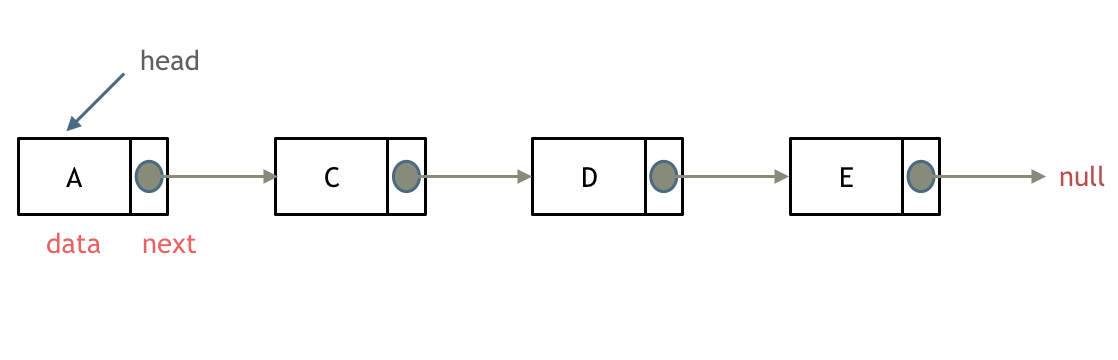
那么什么是链表?链表(Linked List)是一种线性数据结构,它由一系列节点(Node)组成,每个节点包含两部分:数据域(Data)和指向下一个节点的指针域(Next)。链表的特点是节点在内存中不是连续存储的,每个节点通过指针链接到下一个节点,从而形成一个链式结构。这些节点在逻辑上是有序的。
链表的入口节点称为链表的头结点也就是head。
二、循环链表
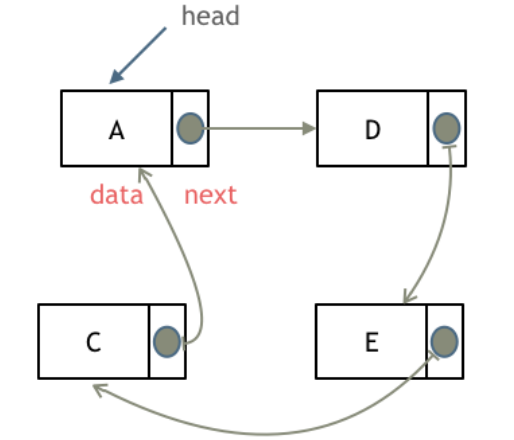
循环链表(Circular Linked List) 是一种链表变体,它与普通的链表(如单向链表、双向链表)最大的区别在于,最后一个节点的指针指向头节点,形成一个循环结构。这种结构可以是单向循环链表,也可以是双向循环链表。
循环链表可以用来解决约瑟夫环问题。
2.1循环链表的特点
- 没有空指针(NULL):在普通的链表中,最后一个节点的
next指针指向NULL,表示链表的结束。而在循环链表中,最后一个节点的next指针指向头节点,形成一个闭环。 - 遍历便利:循环链表的一个显著特点是可以从任意节点开始,循环遍历整个链表,无需担心链表的结束。通过一个指针就能遍历整个链表。
- 适用于循环操作:循环链表适合用于需要循环往复访问元素的场景,例如:模拟游戏中的轮流操作、缓存数据的循环访问等。
2.2 循环链表的优势
- 无限循环遍历:由于链表是循环的,可以在遍历过程中无休止地循环遍历所有节点,适用于需要周期性或轮换访问数据的场景。
- 容易处理环状数据:在某些应用中(比如游戏、调度算法等),我们需要不断循环地访问数据,循环链表提供了自然的支持。
- 插入和删除:和普通链表一样,循环链表在插入和删除节点时也具有较高的灵活性,尤其是当操作发生在链表的开头或末尾时,不需要移动其他节点。
2.3 循环链表的缺点
- 指针操作复杂:循环链表在实现时需要特别注意指针的操作,尤其是在插入或删除节点时,要确保不会破坏循环结构。
- 不容易检测链表结束:由于循环链表没有
NULL作为终止标志,遍历时必须依赖其他方式来判断是否回到了起始节点,从而避免陷入死循环。
2.4 应用场景
- 循环队列/缓冲区:在环形缓冲区中,数据是不断循环使用的,适合用循环链表来实现。
- 操作系统调度:某些操作系统的任务调度算法使用循环链表来实现轮询任务调度。
- 游戏中的回合制系统:如多人在线游戏中,玩家按顺序轮流行动,循环链表可用来存储玩家信息,保证轮流操作。
三、链表的存储方式
了解完链表的类型,再来说一说链表在内存中的存储方式。
数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
如图所示:
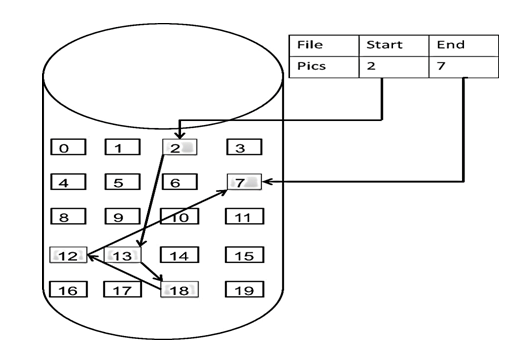
这个链表起始节点为2, 终止节点为7, 各个节点分布在内存的不同地址空间上,通过指针串联在一起。
四、链表的代码定义
接下来说一说链表的定义。
链表节点的定义,很多同学在面试的时候都写不好。
这是因为平时在刷leetcode的时候,链表的节点都默认定义好了,直接用就行了,所以同学们都没有注意到链表的节点是如何定义的。
而在面试的时候,一旦要自己手写链表,就写的错漏百出。
这里我给出C/C++的定义链表节点方式,如下所示:
// 单链表
struct ListNode {
int val; // 节点上存储的元素
ListNode *next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数
// ----------------------------------------------------------------
ListNode(int x) : val(x), next(NULL) {}代码解读
1. ListNode(int x)
这是构造函数的 函数声明部分。
ListNode 是结构体的名称,表示你正在定义一个 ListNode 类型的对象。
(int x) 是构造函数的参数,表示构造函数接收一个整数 x,通常这个 x 用来初始化节点的 val 字段。这个 x 只是构造函数的输入参数,用于给节点的 val 字段赋值。
2. : val(x), next(NULL)
这一部分是 构造函数的初始化列表。它在构造函数体执行之前先执行,主要用于初始化成员变量。
val(x):初始化 val 成员变量,将传入的参数 x 赋值给 val。即,x 的值会被传递给 val,从而在创建 ListNode 对象时,节点的 val 被初始化为 x。
next(NULL):初始化 next 成员变量,将 next 指针初始化为 NULL,表示当前节点没有指向下一个节点(即该节点是链表中的最后一个节点,或者尚未与其他节点连接)。
3. {}
这是构造函数的 空函数体,表示构造函数完成了所有初始化任务后不需要其他的操作。在这个例子中,所有初始化操作都通过初始化列表完成,因此函数体可以是空的。
整体解读
构造函数的作用:构造函数用于在创建 ListNode 类型的对象时自动初始化该对象的成员变量。此构造函数将 x 作为输入,赋值给 val,并将 next 初始化为 NULL,表示当前节点不连接任何其他节点。
};C语言中的链表初始化
在C语言中,你需要手动管理结构体的初始化,例如:
struct ListNode {
int val;
struct ListNode* next;
};
struct ListNode* createNode(int x) {
struct ListNode* newNode = (struct ListNode*)malloc(sizeof(struct ListNode));
if (newNode) {
newNode->val = x;
newNode->next = NULL;
}
return newNode;
}
这里,C语言没有构造函数,所以我们需要通过显式的malloc和字段初始化来创建和初始化链表节点。每次创建节点时,都需要手动调用createNode函数来初始化节点。
五、链表的操作
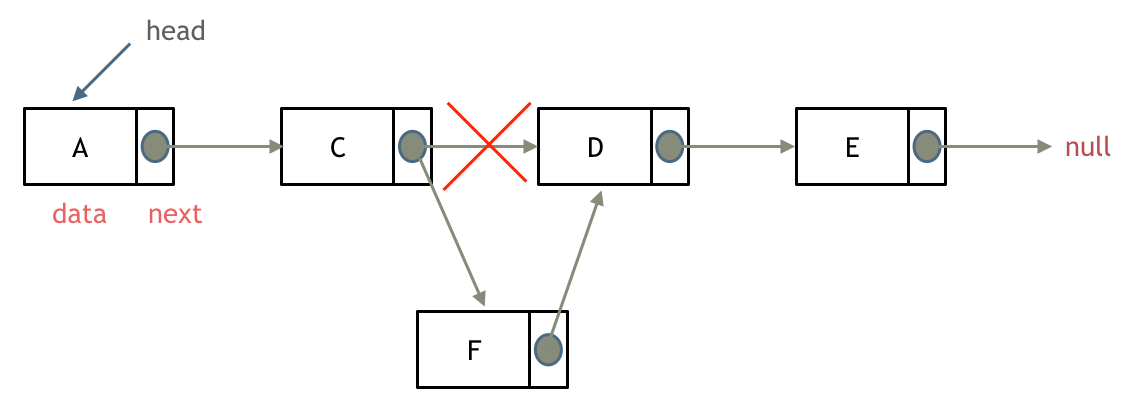
5.1 添加节点
5.2 删除节点
删除D节点,如图所示:
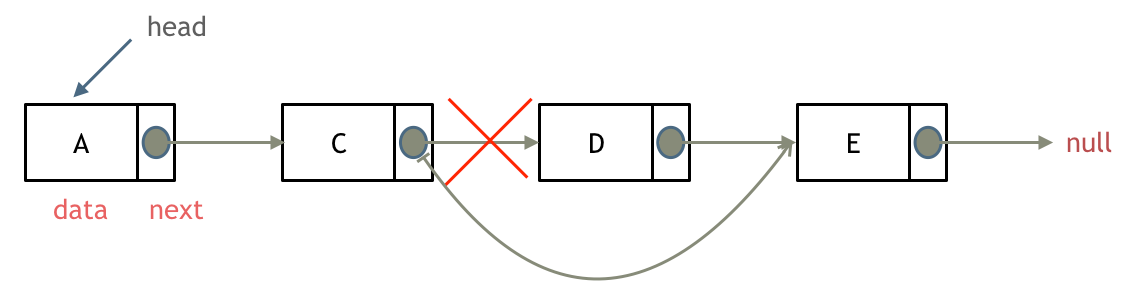
只要将C节点的next指针 指向E节点就可以了。
那有同学说了,D节点不是依然存留在内存里么?只不过是没有在这个链表里而已。
是这样的,所以在C++里最好是再手动释放这个D节点,释放这块内存。
其他语言例如Java、Python,就有自己的内存回收机制,就不用自己手动释放了。
可以看出链表的增添和删除都是O(1)操作,也不会影响到其他节点。
但是要注意,要是删除第五个节点,需要从头节点查找到第四个节点通过next指针进行删除操作,查找的时间复杂度是O(n)。
六、性能分析
再把链表的特性和数组的特性进行一个对比,如图所示:
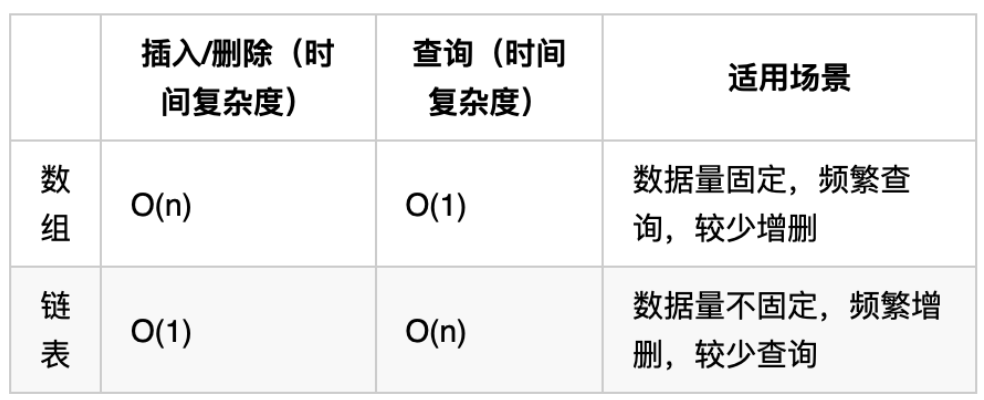
普通数组在定义时长度是固定的,如果需要改变数组的长度,就必须重新定义一个新的数组【std::vector除外,这是动态数组】。相比之下,链表的长度是动态的,可以根据需要随时增减节点,非常适合数据量不确定、需要频繁增删但查询较少的场景。