通义千问报告(Qwen Technical Report)阅读记录
通义千问报告(Qwen Technical Report)阅读记录

Qwen Technical Report:https://arxiv.org/abs/2309.16609
一.用到的技术
1.数据处理和增强
- MinHash 和 LSH算法 (数据过滤技术)
- ChatML-style format
- self-instruct approach
- least-to-most prompting
- byte pair encoding (BPE) tokenizer
2.模型设计
-
基于Transformer-based LLaMA开发
-
Untied input embedding and output projection
-
positional embedding RoPE (https://www.jianshu.com/p/e8be3dbfb4c5)
-
remove biases of most layers but adds biases in the QKV layer of attention
-
Pre-Norm & RMSNorm
-
Activation function SwiGLU
-
Flash Attention
3.训练策略
- 对齐方法
- supervised finetuning (SFT)
- Reinforcement Learning from human feedback (RLHF):
- proximal policy optimization(PPO)
- preference model pretraining (PMP)
- KL divergence
- LoRA
- Q-LoRA
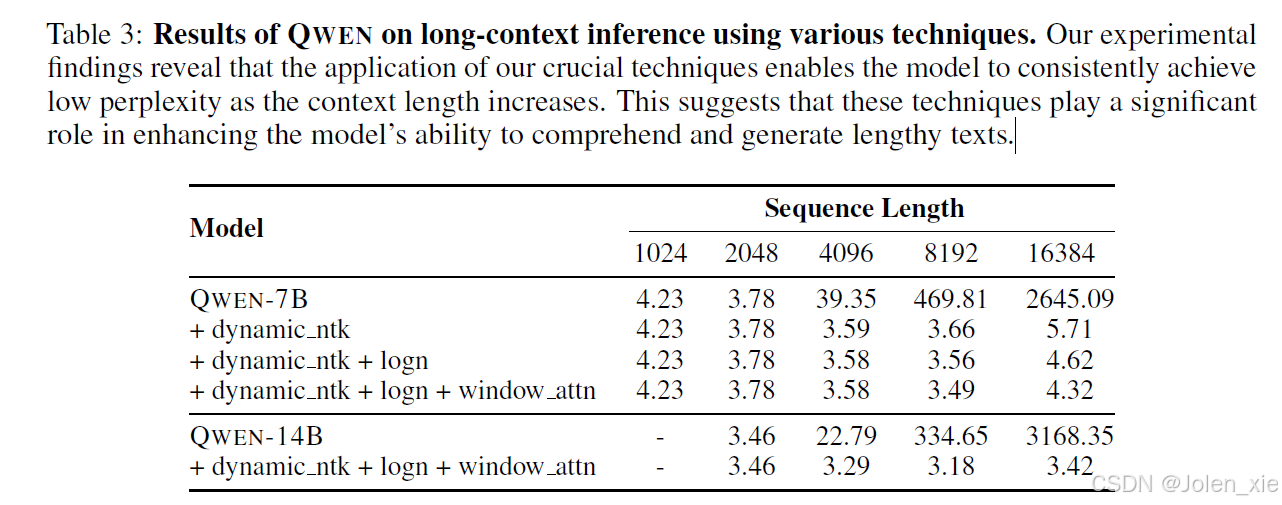
- 上下文长度处理
-
NTK-aware interpolation
-
LogN-Scaling
-
window attention
-
ReAct prompting
4.实验结果
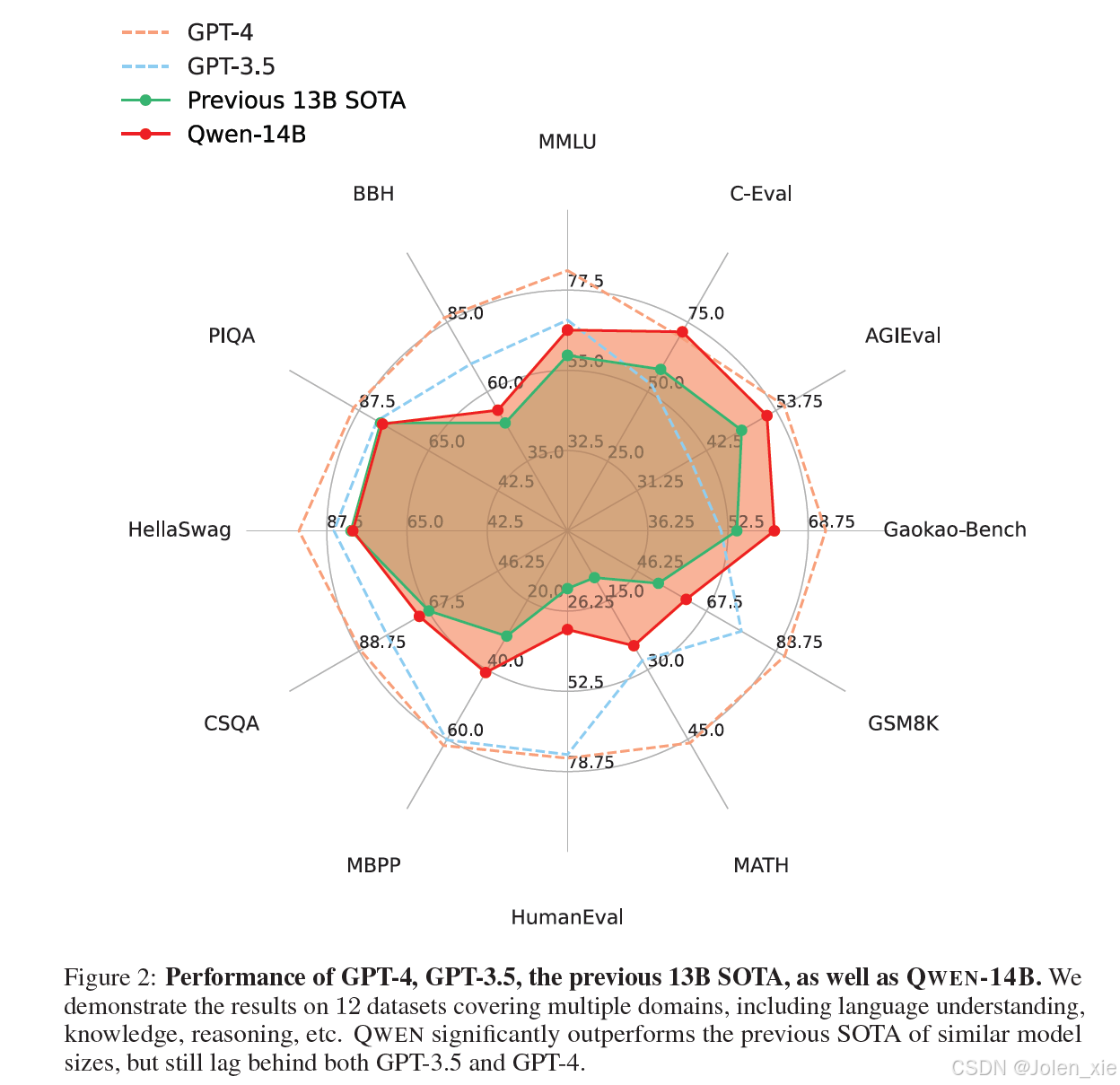
二、重要技术学习
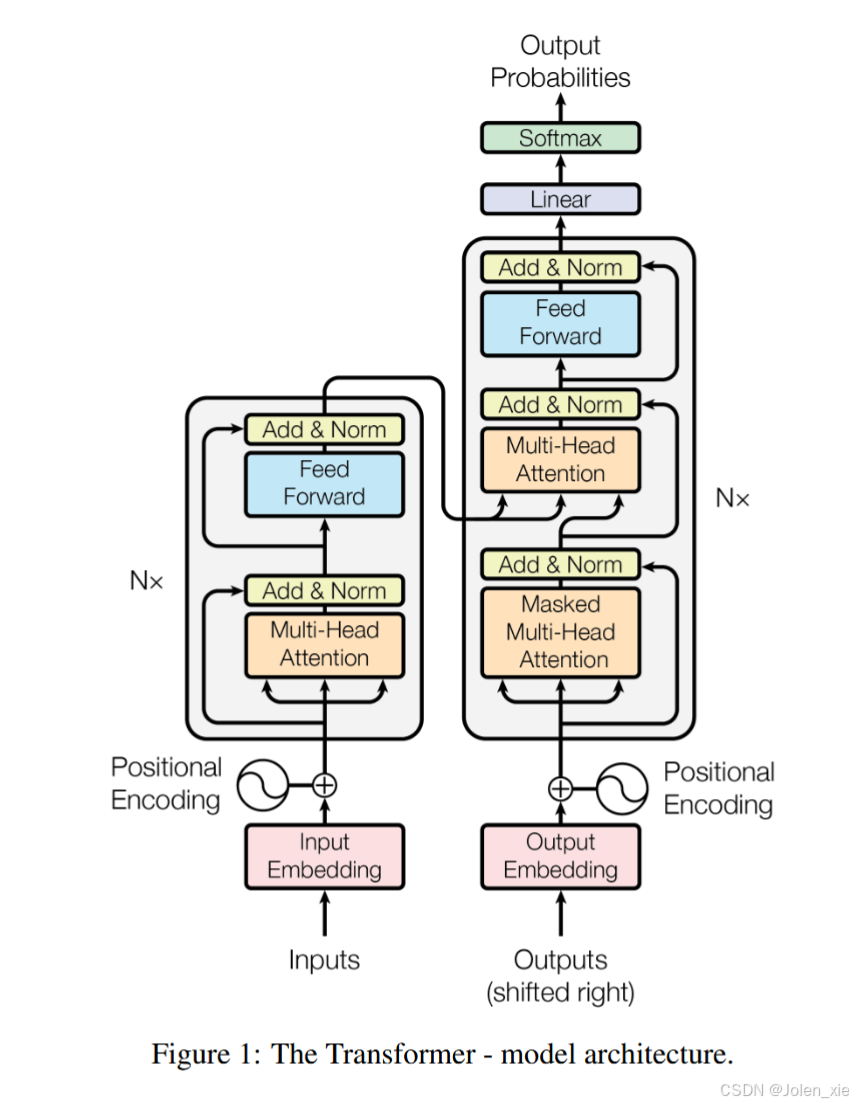
1. Transformer结构
https://arxiv.org/abs/1706.03762
Transformer是一种深度学习模型架构,主要用于处理序列到序列的任务(Sequence-to-Sequence),如自然语言处理(NLP)任务。它由Google的研究团队Vaswani等人在2017年在论文《Attention is All You Need》中提出。Transformer模型的核心思想是使用自注意力机制(Self-Attention)来捕捉序列中不同位置之间的依赖关系。在Transformer出现之前,许多NLP任务主要依赖于循环神经网络(RNN)和长短期记忆网络(LSTM)。这些模型在处理序列数据时表现良好,但由于其顺序处理的特性,训练速度较慢,且在处理长序列时容易出现梯度消失或爆炸的问题。
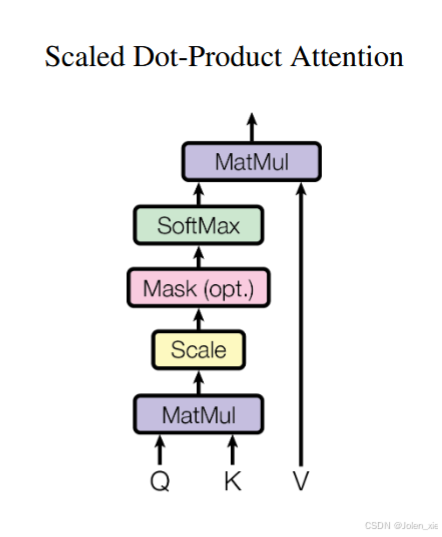
1.1 自注意力机制(Self-Attention)
自注意力机制是Transformer的核心组件。通过计算序列中每个位置与其他位置之间的关联权重及注意力分数(Attention Score),动态聚合全局信息,决定每个位置在生成输出时应该关注哪些位置的信息,从而捕捉序列内部的依赖关系。
-
输入向量通过线性变换生成 Query(Q)、Key(K)、Value(V) 矩阵。
-
计算注意力分数: Attention ( Q , K , V ) = softmax ( Q K T d k ) V \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right) V Attention(Q,K,V)=softmax(dkQKT)V,其中 $d_k $为键向量的维度,缩放因子 d k \sqrt{d_k} dk防止点积过大导致梯度不稳定。

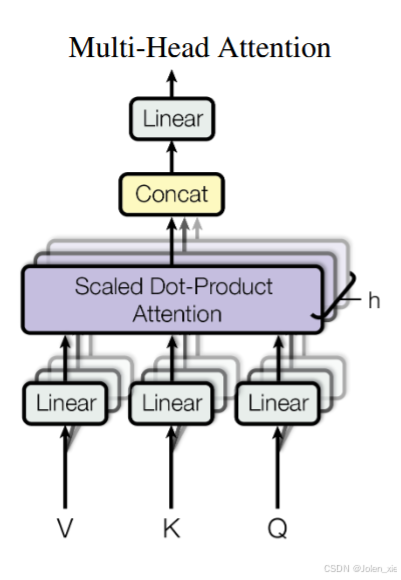
1.2 多头注意力(Multi-Head Attention)
多头注意力机制将注意力计算过程重复多次,每次使用不同的线性变换对查询、键和值进行投影,然后将多个注意力头的输出拼接起来并进行线性变换。这样可以让模型从不同的表示子空间中捕捉序列的语义关系。
KaTeX parse error: Expected 'EOF', got '&' at position 30: …ead }(Q, K, V) &̲ =\operatorname…
W
O
∈
R
h
d
v
×
d
m
o
d
e
l
W^O∈R^{hd_v×d_{model}}
WO∈Rhdv×dmodel是输出线性变换矩阵
1.3 位置编码(Positional Encoding)
Transformer本身不感知序列顺序,需通过位置编码(如正弦/余弦函数或可学习向量)为输入添加位置信息。选择余弦函数的原因:(1)具有连续性和唯一性,(2)取值在[-1,1]之间不会过多改变词嵌入本身数据语义,(3)区分出低频和高频区域,当i小的时候属于高频纬度,波形快速变化,局部特征提取更优秀,当i大时属于低频区域,感知远距离变化,具有全局特征提取能力。对于位置 pos 和维度 i,编码公式为:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d model ) P E ( p o s , 2 i + 1 ) = cos ( pos 1000 0 2 i / d model ) \begin{gathered} P E_{(p o s, 2 i)}=\sin \left(\frac{p o s}{10000^{2 i / d_{\text {model }}}}\right) \\ P E_{(p o s, 2 i+1)}=\cos \left(\frac{\text { pos }}{10000^{2 i / d_{\text {model }}}}\right) \end{gathered} PE(pos,2i)=sin(100002i/dmodel pos)PE(pos,2i+1)=cos(100002i/dmodel pos )
d m o d e l d_{model} dmodel:模型维度,如512
pos:词在序列中的位置
i:编码向量的维度索引, 0 ≤ i < d m o d e l / 2 0 \leq i<d_{m o d e l / 2} 0≤i<dmodel/2
1.4 前馈神经网络(Feed-Forward Neural Network)
一个简单的两层全连接神经网络,中间包含一个非线性激活函数, FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \operatorname{FFN}(x)=\max \left(0, x W_1+b_1\right) W_2+b_2 FFN(x)=max(0,xW1+b1)W2+b2
主要作用是:
(1)引入非线性:自注意力机制是线性操作,只能学习到输入序列中元素之间的线性关系。前馈神经网络通过引入非线性激活函数(如ReLU),使模型能够学习到更复杂的非线性模式,增强了模型的表达能力。
(2)特征增强:进一步提取和组合多头注意力机制输出的特征,增强模型的表达能力
(3)维度变换:FFN通过两层全连接网络,将输入从 d m o d e l d_{model} dmodel 维度映射到 d f f d_{ff} dff维度,再映射回 维度 d m o d e l d_{model} dmodel ,从而实现对特征的重新编码
1.5 编码器-解码器结构
在编码器和解码器中用到了layer normalization、残存结构和masked Multi-Head Attention。
- 层归一化(Layer normalization):层归一化在每个样本的特征维度上进行归一化,而不是在整个批次的样本上进行。这使得层归一化在处理变长序列(如自然语言处理中的句子)时表现良好,因为它不依赖于批次的大小,从而提高模型训练稳定性。
- 残差结构(Residual structure):减轻梯度消失问题,使得网络更深,训练更加稳定。
- 掩蔽多头注意力(Masked Multi-Head Attention):用于生成序列时确保模型只关注当前时间步及之前的时间步。在解码器中,为了防止模型在生成当前单词时看到未来的单词,使用掩蔽机制。具体来说,在计算注意力权重时,将未来位置的权重设置为负无穷(-∞),使得这些位置的注意力权重在经过softmax后变为0。因此,确保在生成序列时,当前时间步的输出只依赖于当前及之前的时间步,防止模型在生成时“看到”未来的信息,使得模型能够逐步生成输出序列,适用于自回归生成任务。
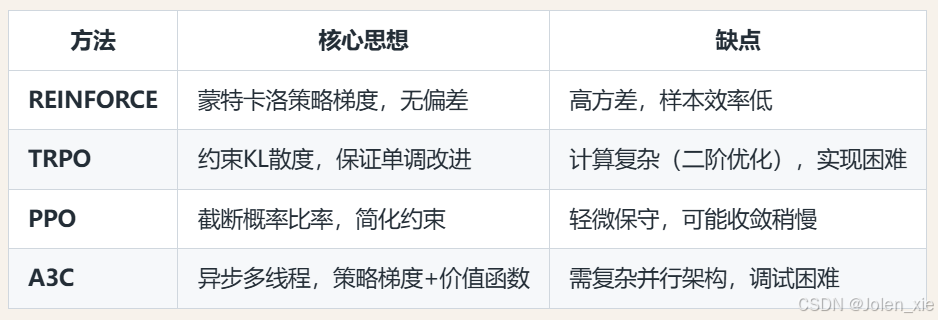
2. 近端策略优化(Proximal Policy Optimization,PPO)
PPO的目标是在策略更新过程中,最大化奖励的同时避免策略的剧烈变化。其核心设计是通过约束新旧策略的差异(用KL散度或截断函数),防止因单次更新过大导致策略崩溃。这种方法可以有效地避免策略更新时的剧烈波动,从而提高训练的稳定性。
2.1 针对的问题:
传统的基于策略梯度的强化学习算法(如A2C、A3C)在更新策略时可能会导致策略发生较大的变化,使得更新后的策略性能不稳定,甚至出现性能急剧下降的情况。为了解决这个问题,研究人员提出了信任区域策略优化(Trust Region Policy Optimization,TRPO)算法,通过限制策略更新的步长来保证策略更新的稳定性,但TRPO算法的计算复杂度较高,实现起来较为困难。
2.2 策略网络和价值网络
- 策略网络:用于生成动作的概率分布。给定状态,策略网络输出在该状态下采取各个动作的概率。
- 价值网络:用于估计状态的价值,帮助评估当前策略的好坏。
2.3 重要性采样
PPO使用重要性采样来计算新旧策略之间的比率。给定旧策略 π o l d \pi_{old} πold 和新策略 π \pi π,重要性比率定义为:
r t = π ( a t ∣ s t ) π o l d ( a t ∣ s t ) r_t=\frac{\pi\left(a_t \mid s_t\right)}{\pi_{\mathrm{old}}\left(a_t \mid s_t\right)} rt=πold(at∣st)π(at∣st)
其中, a t a_t at是在状态 s t s_t st下采取的动作
2.4 目标函数
PPO的目标函数是基于重要性比率的,通常表示为:
L C L I P ( θ ) = E t [ min ( r t A ^ t , clip ( r t , 1 − ϵ , 1 + ϵ ) A ^ t ) ] L^{C L I P}(\theta)=\mathbb{E}_t\left[\min \left(r_t \hat{A}_t, \operatorname{clip}\left(r_t, 1-\epsilon, 1+\epsilon\right) \hat{A}_t\right)\right] LCLIP(θ)=Et[min(rtA^t,clip(rt,1−ϵ,1+ϵ)A^t)]
其中: A ^ t \hat{A}_t A^t 是优势函数(Advantage Function),用于衡量当前策略相对于基线策略的好坏。 ϵ \epsilon ϵ是一个超参数,控制策略更新的幅度。这个目标函数的“剪切”部分确保了新策略与旧策略之间的变化不会超过一定范围,从而提高了训练的稳定性。
2.5 算法步骤
PPO算法的基本步骤如下:
- 收集经验:使用当前策略与环境交互,收集状态、动作、奖励和下一个状态的样本。
- 计算优势:使用收集到的经验计算优势函数 At*A*t。
- 更新策略
- 计算重要性比率 r t r_t rt。
- 使用剪切目标函数 L C L I P L^{CLIP} LCLIP 进行策略更新。
- 更新价值网络:使用收集到的经验更新价值网络,以提高状态价值的估计。
- 重复:重复上述步骤,直到达到预定的训练轮数或性能标准。
2.6 优点
-
稳定性:通过限制策略更新的幅度,PPO在训练过程中表现出更高的稳定性,减少了策略更新时的剧烈波动。
-
简单易用:PPO的实现相对简单,不需要复杂的超参数调整,适合于多种强化学习任务。
-
样本效率:PPO在样本效率上表现良好,能够在较少的样本上进行有效的学习。
3. 基于人类反馈的强化学习(Reinforcement Learning from human feedback,RLHF)
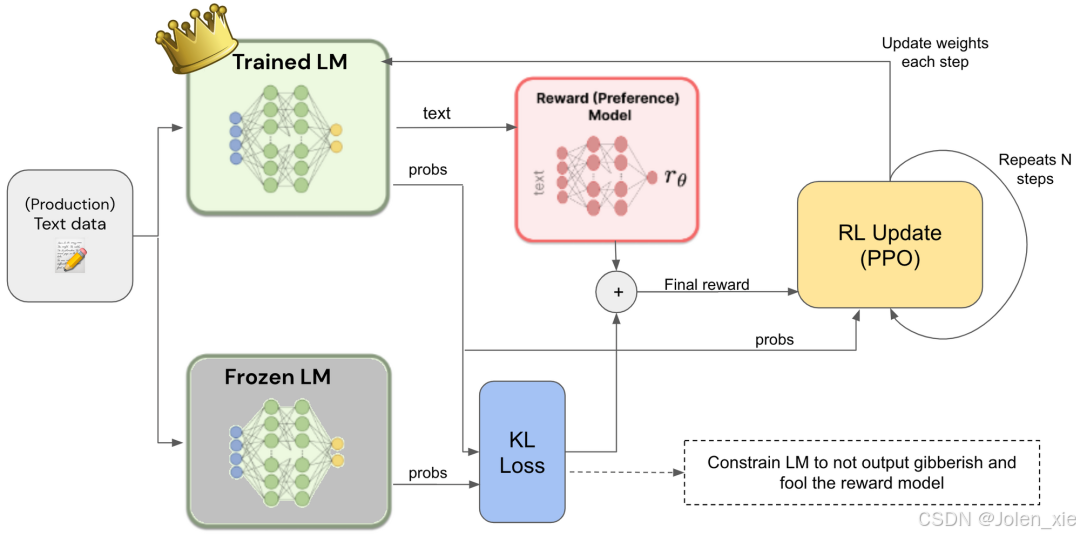
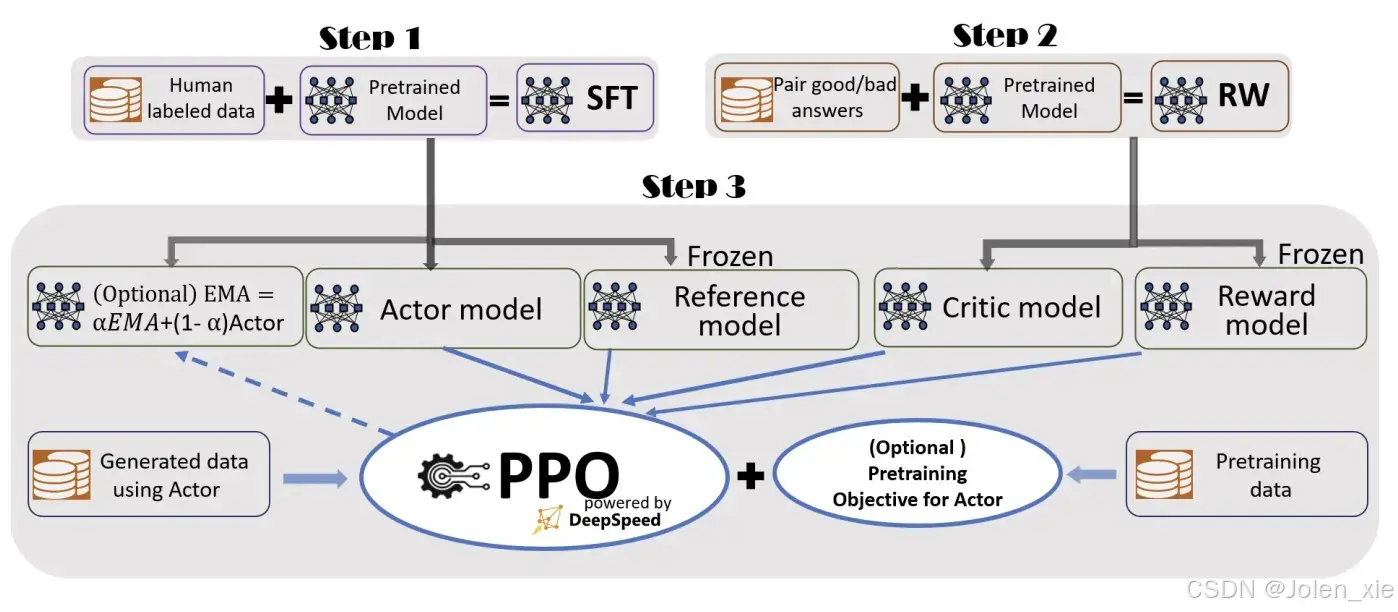
核心步骤:
-
初始模型训练:
使用大规模无监督数据对模型进行预训练,让模型学习到语言的基本模式、语法和语义信息。例如,在自然语言处理中,使用Transformer架构的模型在大量文本数据上进行自监督学习。
-
收集人类反馈:
让初始模型生成多个可能的输出(例如多个回答或动作),由人类根据质量对结果进行排序或打分。例如,在对话系统中,模型生成多个不同的回复,标注者需要判断哪个回复更好,从而形成偏好数据。
-
训练奖励模型(Reward Model):
使用人类反馈数据训练一个奖励模型(Reward model, RM),奖励模型的输入是智能体的输出,输出是一个奖励分数,目标是让RM能模拟人类的偏好,对模型输出的质量进行评分。
-
强化学习优化:
将奖励模型作为强化学习的奖励信号,通过策略梯度(如PPO算法)优化初始模型,使得智能体生成的输出能够获得更高的奖励分数。
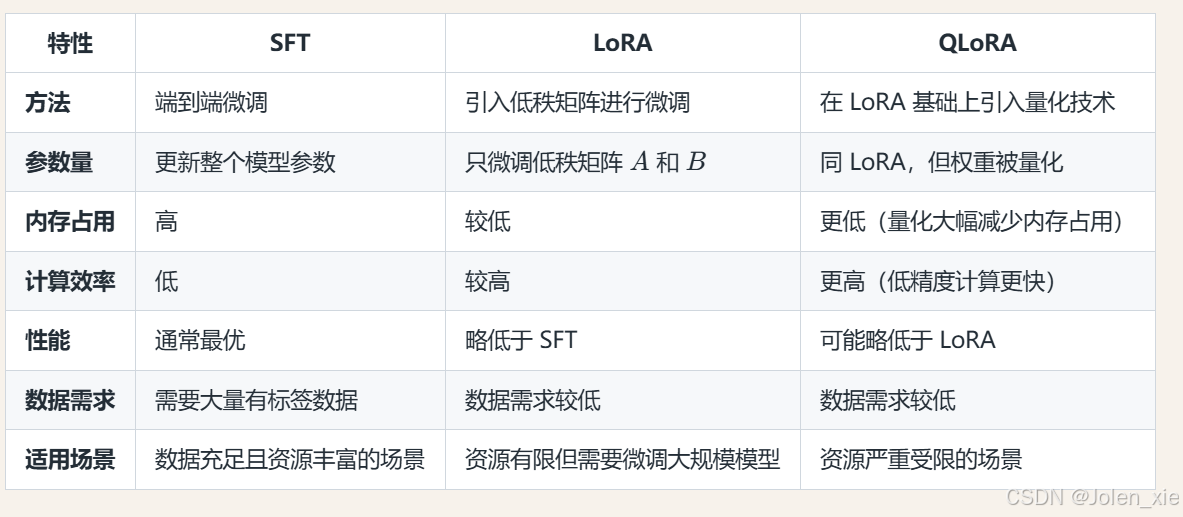
4. SFT、LoRA and QLoRA
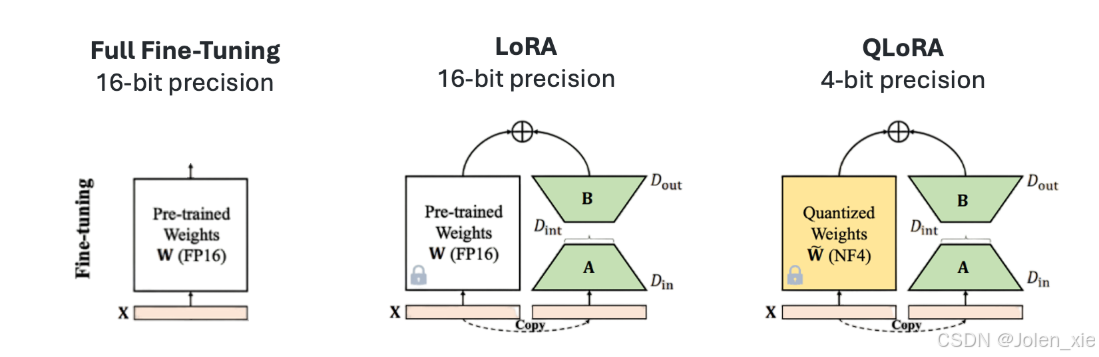
1. 监督微调(Full fine-tuning,SFT)
它涉及在指令数据集上重新训练预训练模型的所有参数。这种方法通常提供最好的结果,但需要大量的计算资源(需要几个高端gpu来微调8B模型)。因为它修改了整个模型,所以它也是最具破坏性的方法,可能导致对以前的技能和知识的灾难性遗忘。
2. 低秩适配(Low-Rank Adaptation,LoRA)
它不是重新训练整个模型,而是冻结权重并在每个目标层引入小适配器(低秩矩阵)。这使得LoRA可以训练大量的参数,这些参数比完全微调(小于1%)要低得多,从而减少了内存使用和训练时间。这种方法是非破坏性的,因为原始参数被冻结,适配器可以随意切换或组合。
3. 量化低秩适配 (Quantization-aware Low-Rank Adaptation,QLoRA )
与标准LoRA相比,它提供了高达33%的额外内存减少,这使得它在GPU内存受限时特别有用。这种效率的提高是以更长的训练时间为代价的,QLoRA的训练时间通常比常规LoRA多39%。
三、感悟与心得
1. 当前,数据工程比模型工程更加关键
在整个报告中,多次提到了对数据处理和优化的事情(1)通用模型需要更广泛和多样的数据样本,包括web文本、百科全书、书本、代码等;(2)多种语言结合。同时,为了保证数据和训练的有效性,(1)需要多种技术进行清洗,如对于公共web数据,我们从HTML中提取文本,并使用语言识别工具来确定语言;为了增加数据的多样性,我们采用了重复数据删除技术,包括规范化后的精确匹配重复数据删除和使用MinHash和LSH算法的模糊重复数据删除;为了过滤掉低质量的数据,我们结合了基于规则和基于机器学习的方法共同决定数据质量;手动人工审查。(2)聊天数据输入的格式metadat会影响模型对话的风格,报告使用了human-style conversations、ChatML-style format。
2. 针对不同任务选择不同的训练方式很重要
通义千问有多个版本,包括:Qwen-PMP、Qwen-Chat、Code-Qwen、Math-Qwen-Chat、Qwen-VL。针对不同的任务,会选择不同的CONTEXT LENGTH、学习率,其中基础模型选择的上下文长度是2048,由于代码解释需要很长的上下文理解能力,所以code-Qwen用的是8192,而数学领域的问题很有针对性,不需要太强的上下文思考,所以CONTEXT LENGTH是1024.由于长度越长,复杂度二次方增加,也用了NTK-aware interpolation技术和LogN-Scaling、window attention技术去减少复杂度。
3. 模型设计
目前,模型设计主要还是集中在Transformer中Attention结构和无效结构剪枝,主要目的是
(1)减轻复杂度,如Embedding解耦、bias的优化、前向忘了中hidden size从4倍减少到8/3倍、注意力计算方式替换
(2)提升上下文推理能力,如更好的positional embedding、normalization位置和方法更换、激活函数更换