学习路程二 LangChain基本介绍
前面简单调用了一下deepseek的方法,发现有一些疑问和繁琐的问题,需要更多的学习,然后比较流行的就是LangChain这个东西了。
目前大部分企业都是基于 LangChain 、qwen-Agent、lammaIndex框架进行大模型应用开发。LangChain 提供了 Chain、Tool 、RAG等架构的实现,可以基于 LangChain 进行个性化定制,实现从用户输入到数据库再到大模型最后输出的整体架构连接。
所以也跟主流,开始了解学习LangChain,记录下学习过程。
一、关于LangChain的一些基础了解
1.1 基本介绍
LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。其作者是Harrison Chase(哈里森·蔡斯),最初是于 2022 年 10 月开源的一个项目,在 GitHub 上获得大量关注之后迅速转变为一家人工智能初创公司。
LangChain提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
LangChain官网:https://python.langchain.com/en/latest/
1.2 大模型(LLM)
大语言模型(Large Language Model): 通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI 的 GPT-3 模型。这些模型可以通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。大型语言模型在自然语言处理、文本生成和智能对话等领域有广泛应用。
按照输入数据类型的不同,大模型的分类:
- 语言大模型(NLP):是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。例如:GPT 系列(OpenAI)、Bard(Google)、文心一言(百度)。
- 视觉大模型(CV):是指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割、姿态估计、人脸识别等。例如:VIT 系列(Google)、文心UFO、华为盘古 CV、INTERN(商汤)。
- 多模态大模型: 是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了 NLP 和 CV 的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。例如:DingoDB 多模向量数据库(九章云极 DataCanvas)、DALL-E(OpenAI)、悟空画画(华为)、midjourney。
按照应用领域的不同,大模型主要可以分为 L0、L1、L2 三个层级:
- 通用大模型 L0:是指可以在多个领域和任务上通用的大模型。它们利用大算力、使用海量的开放数据与具有巨量参数的深度学习算法,在大规模无标注数据上进行训练,以寻找特征并发现规律,进而形成可“举一反三”的强大泛化能力,可在不进行微调或少量微调的情况下完成多场景任务,相当于 AI 完成了“通识教育”。
- 行业大模型 L1:是指那些针对特定行业或领域的大模型。它们通常使用行业相关的数据进行预训练或微调,以提高在该领域的性能和准确度,相当于 AI 成为“行业专家”。
- 垂直大模型 L2:是指那些针对特定任务或场景的大模型。它们通常使用任务相关的数据进行预训练或微调,以提高在该任务上的性能和效果。
1.2 LangChain与大模型(LLM)的关系
LangChain本身并不开发大模型(LLM),它是为各种LLMs提供通用的接口,降低开发者的学习成本,方便开发者快速地开发复杂的LLMs应用。
官方定义:LangChain是一个基于语言模型开发应用程序的框架。它可以实现以下应用程序:
- 数据感知:将语言模型连接到其他数据源
- 自主性:允许语言模型与其环境进行交互
LangChain的主要价值在于:
- 组件化:为使用语言模型提供抽象层,以及每个抽象层的一组实现。组件是模块化且易于使用的,无论您是否使用LangChain框架的其余部分。
- 现成的链:结构化的组件集合,用于完成特定的高级任务。
1.3 应用场景
LangChain为构建基于大型语言模型的应用提供了一个强大的框架,将逐步的运用到各个领域中,如,智能客服、文本生成、知识图谱构建等。随着更多的工具和资源与LangChain进行集成,大语言模型对人的生产力将会有更大的提升。
常用的业务场景:
-
智能客服:结合聊天模型、自主智能代理和问答功能,开发智能客服系统,帮助用户解决问题,提高客户满意度。
-
个性化推荐:利用智能代理与文本嵌入模型,分析用户的兴趣和行为,为用户提供个性化的内容推荐。
-
知识图谱构建:通过结合问答、文本摘要和实体抽取等功能,自动从文档中提取知识,构建知识图谱。
-
自动文摘和关键信息提取:利用LangChain的文本摘要和抽取功能,从大量文本中提取关键信息,生成简洁易懂的摘要。
-
代码审查助手:通过代码理解和智能代理功能,分析代码质量,为开发者提供自动化代码审查建议。
-
搜索引擎优化:结合文本嵌入模型和智能代理,分析网页内容与用户查询的相关性,提高搜索引擎排名。
-
数据分析与可视化:通过与API交互和查询表格数据功能,自动分析数据,生成可视化报告,帮助用户了解数据中的洞察信息。
-
智能编程助手:结合代码理解和智能代理功能,根据用户输入的需求自动生成代码片段,提高开发者的工作效率。
-
在线教育平台:利用问答和聊天模型功能,为学生提供实时的学术支持,帮助他们解决学习中遇到的问题。
-
自动化测试:结合智能代理和代理模拟功能,开发自动化测试场景,提高软件测试的效率和覆盖率。
二、LangChain工作流程
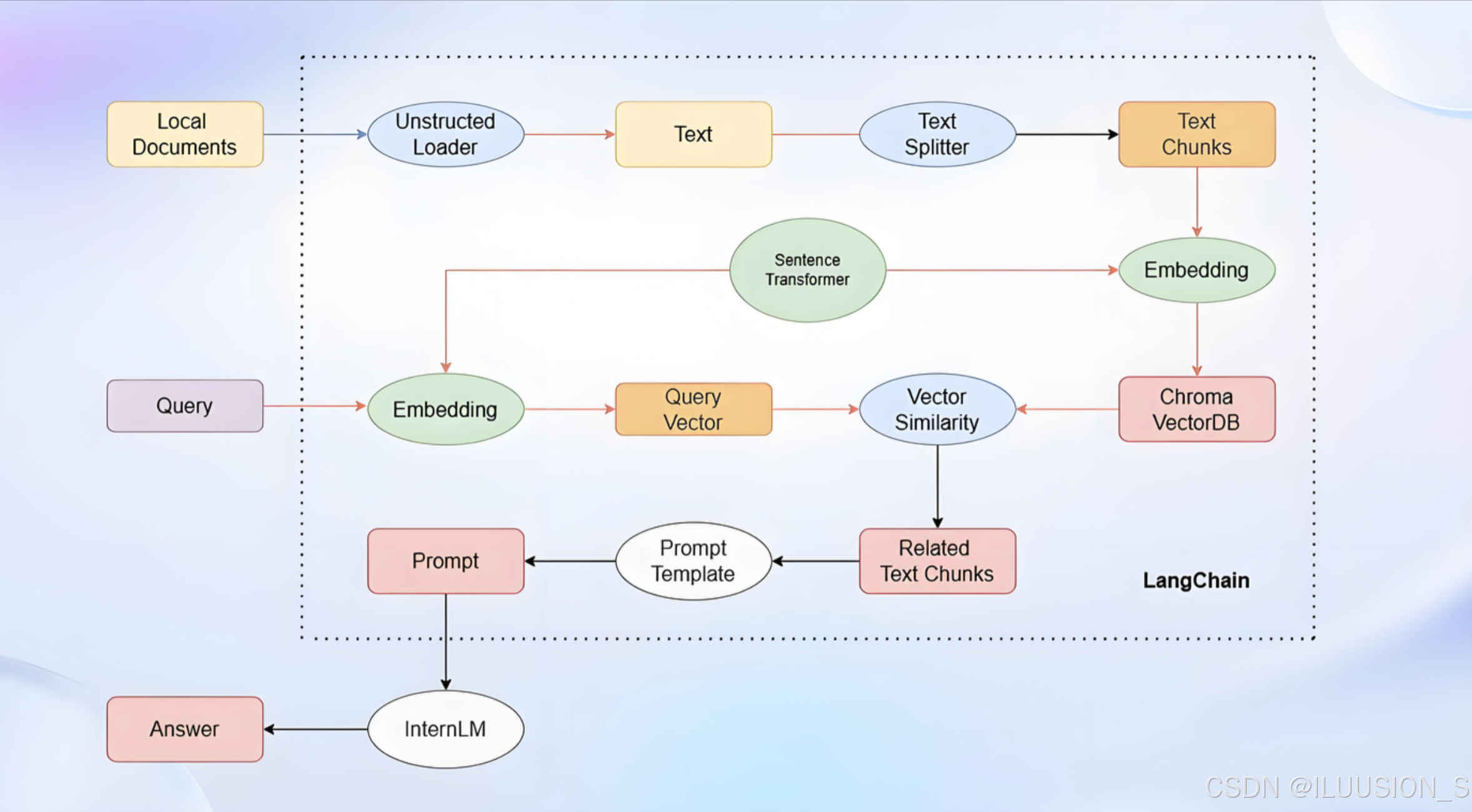
从上面图看LangChain工作流程可以大致简单分为
- 本地文档的加载,分割,向量化,存储起来
- 用户提问的问题进行向量化
- 将向量化的问题和向量化后的文档内容进行向量相似度对比。查找出最相似的内容。
- 将结果通过提示工程模版的要求返回给LLM,再形成答案返回出去
三、核心组件
要使用 LangChain,首先要导入必要的组件和工具,例如 LLMs, chat models, agents, chains, 内存功能。这些组件组合起来创建一个可以理解、处理和响应用户输入的应用程序。
- Model I/O:管理语言模型(Models),及其输入(Prompts)和格式化输出(Output Parsers)
- data connection:与特定任务的数据接口,管理主要用于建设私域知识(库)的向量数据存储(Vector Stores)、内容数据获取(Document Loaders)和转化(Transformers),以及向量数据查询(Retrievers)
- memory:在一个链的运行之间保持应用状态,用于存储和获取 对话历史记录 的功能模块
- chains:构建调用序列,用于串联 Memory ↔ Model I/O ↔ Data Connection,以实现 串行化 的连续对话、推测流程
- agents:给定高级指令,让链选择使用哪些工具,基于 Chains 进一步串联工具(Tools),从而将大语言模型的能力和本地、云服务能力结合
- callbacks:记录并流式传输任何链的中间步骤,可连接到 LLM 申请的各个阶段,便于进行日志记录、追踪等数据导流