人工智能之不同数据类型及其特点梳理
在机器学习和深度学习领域,理解不同类型的数据及其特点对于选择合适的模型至关重要。下面介绍三种主要的数据类型——表格类数据、图像/视频类数据和时序类数据,并探讨它们的特点以及适用的算法和技术。通过具体的案例代码,更直观地体验每一个概念。
一、表格类数据
下图是一个波士顿房价的表格数据,每一行样本代表一座房子,每一列代表房子的一个属性,最后一列 MEDV 代表是房子的房价。
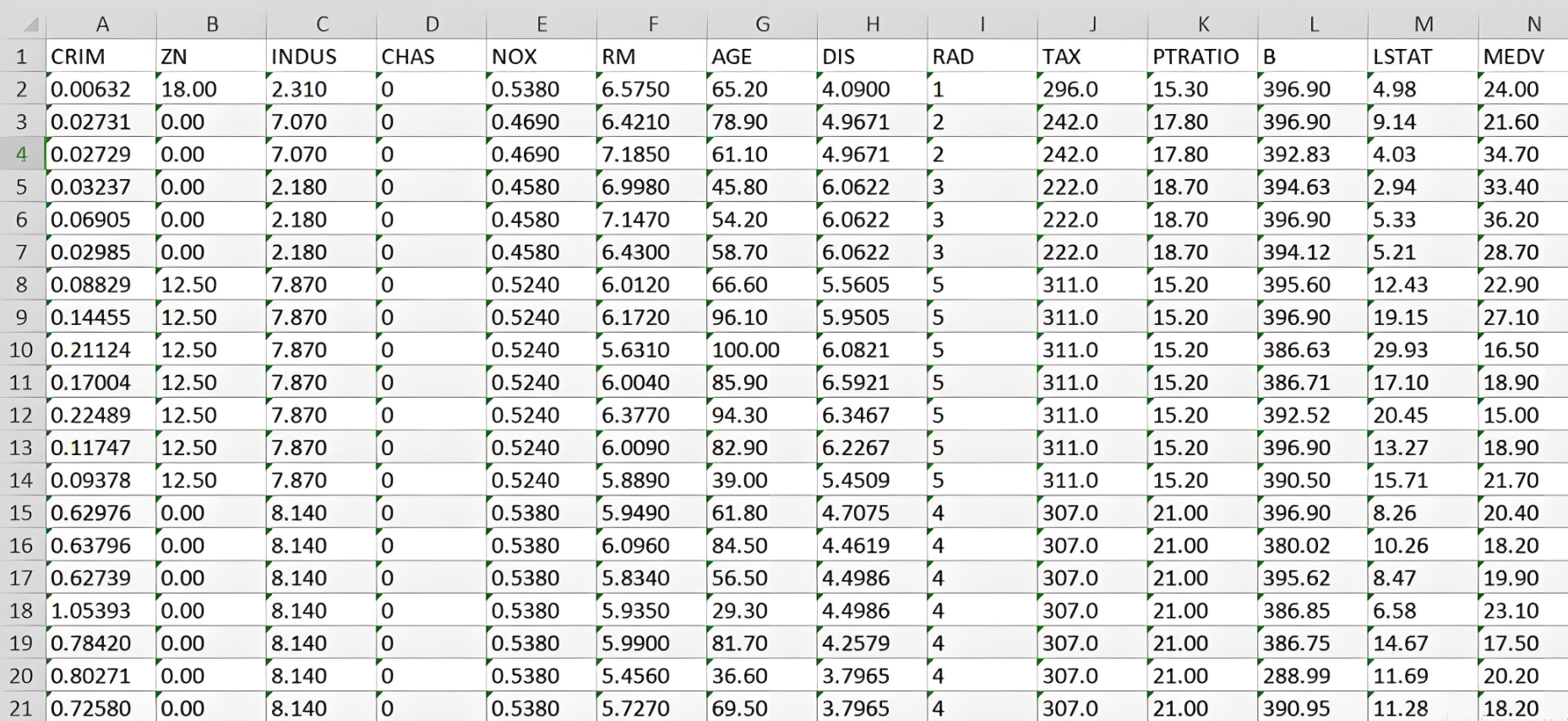
1.1 特点
- 特征互相独立:每个特征代表一个独立的变量,且这些变量之间没有顺序关系。
- 无顺序之别:数据点可以任意排列而不影响其含义。
1.2 常用算法
- 机器学习算法:如决策树、随机森林、支持向量机、集成学习等,适用于处理表格类数据,因为这些算法不需要考虑输入特征之间的空间或时间关系。
- 全连接算法:神经网络中的全连接层,可以直接应用于表格数据,每个输入特征与下一层的所有节点相连。
1.3 示例代码
使用Scikit-Learn进行线性回归
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import pandas as pd
# 加载糖尿病数据集
diabetes = load_diabetes()
# 将数据转换为Pandas DataFrame
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
# 添加目标变量到DataFrame中
df['target'] = diabetes.target
# 输出前几行数据查看
print(df.head())
X, y = diabetes.data, diabetes.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建并训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 使用模型进行预测
y_pred = model.predict(X_test)
print(y_pred[:5])
输出原始数据前 5 行,以及预测结果前 5 条,\表示换行显示,所有的特征列age sex bmi bp s1 s2 s3 s4 s5 s6 ,最后的target是标签列
age sex bmi bp s1 s2 s3 \
0 0.038076 0.050680 0.061696 0.021872 -0.044223 -0.034821 -0.043401
1 -0.001882 -0.044642 -0.051474 -0.026328 -0.008449 -0.019163 0.074412
2 0.085299 0.050680 0.044451 -0.005670 -0.045599 -0.034194 -0.032356
3 -0.089063 -0.044642 -0.011595 -0.036656 0.012191 0.024991 -0.036038
4 0.005383 -0.044642 -0.036385 0.021872 0.003935 0.015596 0.008142
s4 s5 s6 target
0 -0.002592 0.019907 -0.017646 151.0
1 -0.039493 -0.068332 -0.092204 75.0
2 -0.002592 0.002861 -0.025930 141.0
3 0.034309 0.022688 -0.009362 206.0
4 -0.002592 -0.031988 -0.046641 135.0
[139.5475584 179.51720835 134.03875572 291.41702925 123.78965872]
二、图像/视频类数据
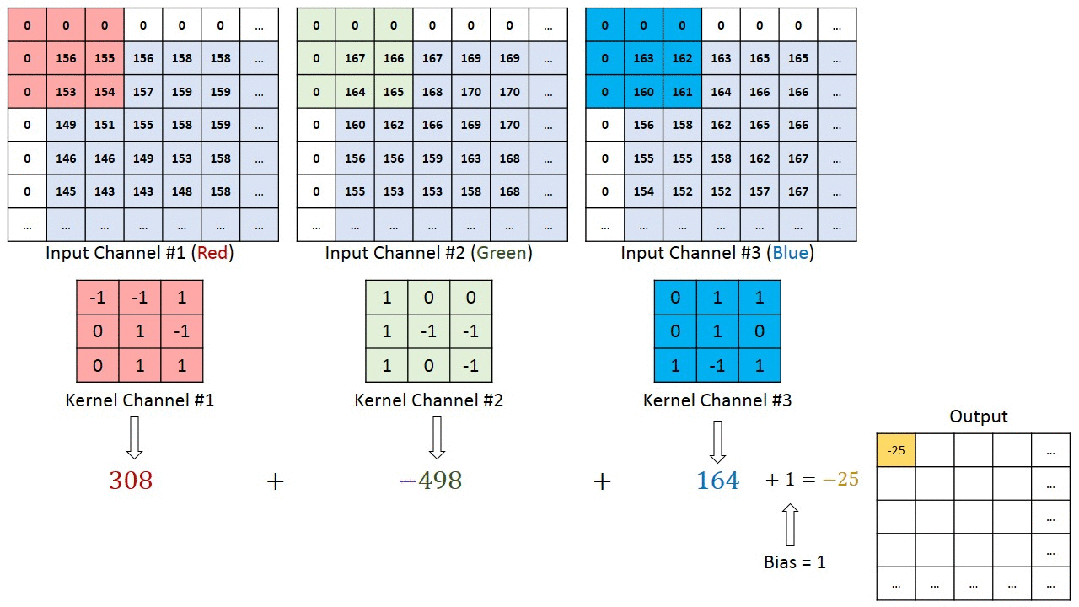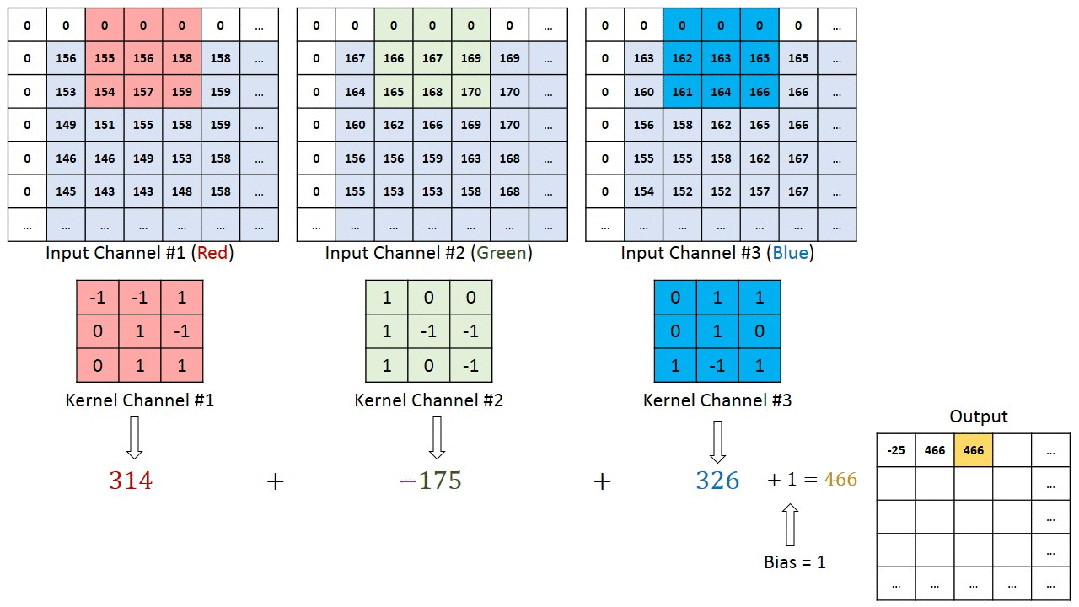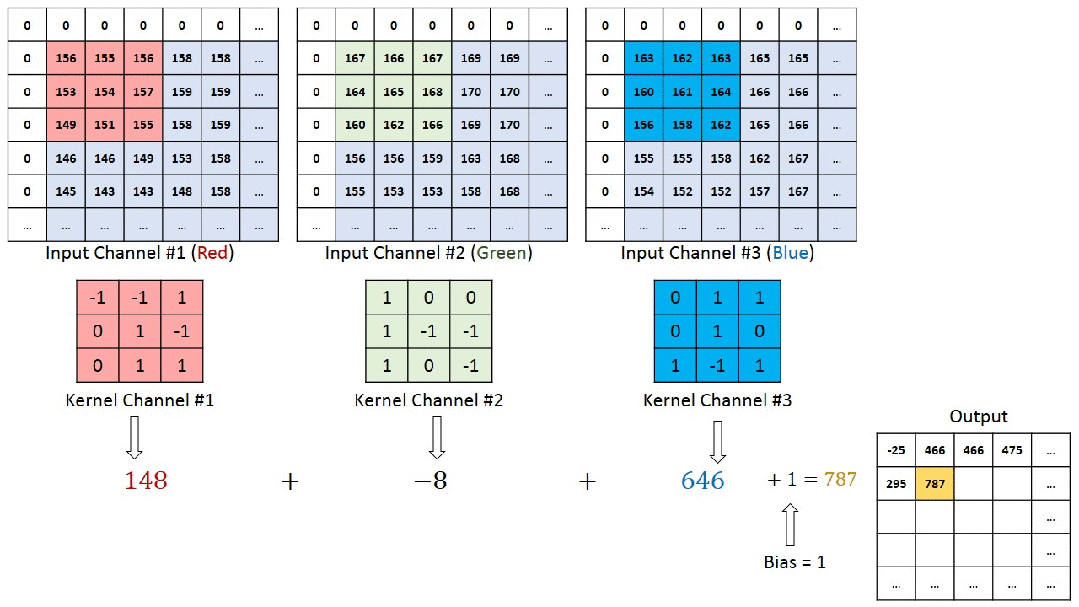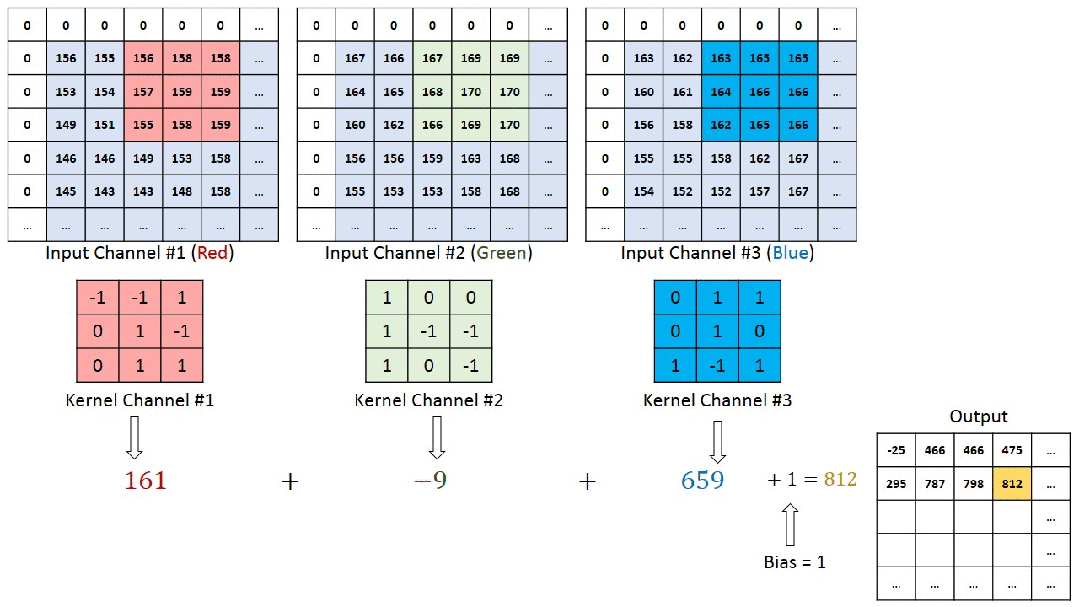
2.1 特点
- 二维信号:图像数据通常以二维矩阵的形式表示,其中H(高度)和W(宽度)维度具有明确的顺序意义。
- 通道信息:除了H和W,图像还有颜色通道(如RGB),而视频则包含时间维度。
2.2 常用算法
- 卷积神经网络(CNNs):专门设计用于处理具有网格结构的数据(如图像)。CNN能够自动提取图像中的局部特征,并通过多层网络捕捉到更复杂的模式。
2.3 示例代码
下面使用Keras构建简单的CNN模型,TensorFlow 是一个开源的机器学习框架。Keras 则是一个高级神经网络 API,自 TensorFlow 2.0 起,Keras 已经被整合为 TensorFlow 的官方高级 API,用于构建和训练深度学习模型。
import tensorflow as tf
from tensorflow.keras import layers, models
# 构建简单CNN模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 假设已经有了训练数据x_train, y_train
# model.fit(x_train, y_train, epochs=5)
三、时序类数据
股票价格,当前的价格依赖于之前的价格

3.1 特点
- 顺序之别:时序数据在一个维度上存在明显的顺序关系,即时间维度或时间步。
- 应用场景广泛:包括语言、语音识别、金融时间序列分析等领域。
3.2 常用算法
- 一维卷积网络:适用于捕捉时序数据中的局部模式。
- 循环神经网络(RNNs):特别适合处理长序列数据,因为它能够记住过去的信息来影响当前的输出。
- 自注意力机制:允许模型关注输入序列的不同部分,提高对复杂模式的捕捉能力。
3.3 示例代码
使用PyTorch实现简单的RNN
import torch
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.rnn(x)
out = self.fc(out[:, -1, :]) # 获取最后一个时间步的输出
return out
# 初始化模型
model = SimpleRNN(input_size=10, hidden_size=20, output_size=1)
# 假设已有输入数据x
# output = model(x)
通过对这三种数据类型的梳理,了解它们各自的特点,如何根据数据特性选择合适的技术和算法。