BFS 解决 拓扑排序(典型算法思想)—— OJ例题算法解析思路
目录
一、207. 课程表 - 力扣(LeetCode)
算法代码:
代码思路解析
数据结构的准备
构建图(建图)
进行拓扑排序(使用 BFS)
层序遍历(BFS)处理
判断是否有环
总结
算法步骤概述
二、210. 课程表 II - 力扣(LeetCode)
算法代码:
代码思路解析
总结
算法步骤概述
三、LCR 114. 火星词典 - 力扣(LeetCode)
算法代码:
代码思路解析
初始化数据结构
构建图与初始化入度哈希表
进行拓扑排序
判断是否存在环
添加依赖关系的辅助函数
总结
算法步骤概述
初始化
构建字母依赖关系
拓扑排序
结果验证
一、207. 课程表 - 力扣(LeetCode)

算法代码:
class Solution {
public:
bool canFinish(int n, vector<vector<int>>& p) {
unordered_map<int, vector<int>> edges; // 邻接表
vector<int> in(n); // 存储每⼀个结点的⼊度
// 1. 建图
for (auto& e : p) {
int a = e[0], b = e[1];
edges[b].push_back(a);
in[a]++;
}
// 2. 拓扑排序 - bfs
queue<int> q;
// 把所有⼊度为 0 的点加⼊到队列中
for (int i = 0; i < n; i++) {
if (in[i] == 0)
q.push(i);
}
// 层序遍历
while (!q.empty()) {
int t = q.front();
q.pop();
// 修改相连的边
for (int e : edges[t]) {
in[e]--;
if (in[e] == 0)
q.push(e);
}
}
// 3. 判断是否有环
for (int i : in)
if (i)
return false;
return true;
}
};代码思路解析
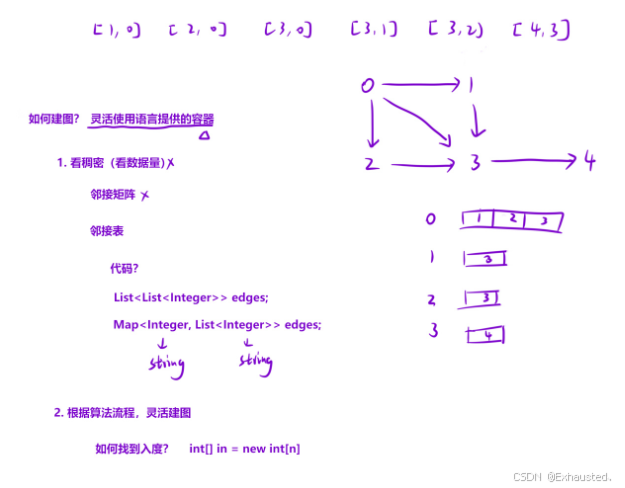
-
数据结构的准备
-
使用
unordered_map<int, vector<int>> edges来表示课程之间的依赖关系,构建邻接表。这里的edges[b]是指课程b需要的前置课程(依赖课程)列表。 -
使用
vector<int> in(n)来记录每个课程的入度(即有多少课程依赖于该课程)。
-
-
构建图(建图)
-
遍历给定的课程依赖关系
p,每个元素e代表从课程a到课程b的依赖关系(表示要完成b,需要先完成a)。 -
对于每个依赖关系:
-
将课程
a添加到课程b的依赖列表中(即edges[b].push_back(a))。 -
更新课程
a的入度(即in[a]++),表示课程a被依赖了一次。
-
-
-
进行拓扑排序(使用 BFS)
-
创建一个队列
queue<int> q来存放入度为 0 的课程(即没有依赖的课程)。 -
遍历所有课程,将所有入度为 0 的课程加入队列。这样的课程是可以直接完成的,因为它们没有前置课程。
-
-
层序遍历(BFS)处理
-
当队列不为空时,从队列中取出一个课程
t,并对其所有依赖的课程进行处理:-
遍历
edges[t]中的所有课程e,将它们的入度减 1,因为课程t已经被完成。 -
如果课程
e的入度变为 0,说明它已经没有其他依赖课程,可以加入队列。
-
-
-
判断是否有环
-
遍历入度数组
in,检查是否还有课程的入度不为 0。如果有,说明存在环(即某些课程无法完成),返回false。 -
如果所有课程的入度都是 0,说明所有课程都可以完成,返回
true。
-
总结
这段代码实现了一个基于拓扑排序的算法来判断课程安排是否能够完成。通过使用邻接表构建课程依赖关系和入度数组,结合 BFS 来有效处理和更新课程状态,最终检查是否存在环,决定所有课程是否可以完成。
算法步骤概述
-
构建图: 使用邻接表和入度数组建立课程依赖关系。
-
拓扑排序(BFS): 使用队列处理可以完成的课程,逐步减少依赖关系。
-
环检测: 通过检查入度数组,判断是否所有课程都可以完成。
二、210. 课程表 II - 力扣(LeetCode)

算法代码:
class Solution {
public:
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
// 1. 准备⼯作
vector<vector<int>> edges(numCourses); // 邻接表存储图
vector<int> in(numCourses); // 存储每⼀个点的⼊度
// 2. 建图
for (auto& p : prerequisites) {
int a = p[0], b = p[1]; // b -> a
edges[b].push_back(a);
in[a]++;
}
// 3. 拓扑排序
vector<int> ret; // 统计排序后的结果
queue<int> q;
for (int i = 0; i < numCourses; i++) {
if (in[i] == 0)
q.push(i);
}
while (q.size()) {
int t = q.front();
q.pop();
ret.push_back(t);
for (int a : edges[t]) {
in[a]--;
if (in[a] == 0)
q.push(a);
}
}
if (ret.size() == numCourses)
return ret;
else
return {};
}
};代码思路解析
-
准备工作
-
初始化一个邻接表
vector<vector<int>> edges(numCourses),用于存储每门课程的依赖关系(即哪些课程是先修课程)。 -
初始化一个入度数组
vector<int> in(numCourses),用于记录每门课程的入度(即有多少门课程依赖于当前课程)。
-
-
建立图
-
遍历给定的先修课程列表
prerequisites,每个元素p表示课程b是课程a的先修课程(即要完成课程a必须先完成课程b)。 -
对于每个先修关系:
-
将课程
a添加到课程b的依赖列表中(即edges[b].push_back(a)),表示完成课程b后可以完成课程a。 -
更新课程
a的入度(即in[a]++),表示课程a被依赖了一次。
-
-
-
进行拓扑排序
-
创建一个结果向量
vector<int> ret,用于存储排序后的课程顺序。 -
创建一个队列
queue<int> q,用于存储入度为 0 的课程(即没有依赖的课程)。 -
遍历所有课程,将所有入度为 0 的课程加入队列。这些课程可以直接开始学习,因为它们没有前置课程。
-
-
执行层序遍历(BFS)
-
当队列不为空时,进行以下操作:
-
从队列中取出一个课程
t,并将其加入结果向量ret。 -
遍历
edges[t]中的所有课程a,将它们的入度减 1,表示已完成课程t的学习。 -
如果课程
a的入度减到 0,则说明课程a的所有先修课程已完成,可以将其加入队列。
-
-
-
检测是否完成所有课程
-
在完成了所有可能的课程后,检查结果向量
ret的大小是否等于numCourses。 -
如果相等,返回排序后的课程顺序
ret,否则返回一个空向量,表示无法完成所有课程(存在循环依赖)。
-
总结
这段代码利用拓扑排序算法有效地解决了课程学习顺序的问题。通过邻接表和入度数组的构建,结合 BFS 的方式,对课程进行排序并输出可行的学习顺序。若无法完成所有课程,返回空向量以表明存在循环依赖。
算法步骤概述
-
准备和初始化
-
创建邻接表和入度数组。
-
-
建立课程依赖关系
-
遍历先修课程列表,填充邻接表和更新入度。
-
-
拓扑排序过程
-
使用队列处理所有入度为 0 的课程,并更新其依赖课程的入度。
-
-
结果验证
-
检查结果数量是否等于课程总数,决定是否返回有效的学习顺序。
-
三、LCR 114. 火星词典 - 力扣(LeetCode)

算法代码:
class Solution {
unordered_map<char, unordered_set<char>> edges; // 邻接表来存储图
unordered_map<char, int> in; // 统计⼊度
bool cheak; // 处理边界情况
public:
string alienOrder(vector<string>& words) {
// 1. 建图 + 初始化⼊度哈希表
for (auto& s : words) {
for (auto ch : s) {
in[ch] = 0;
}
}
int n = words.size();
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
add(words[i], words[j]);
if (cheak)
return "";
}
}
// 2. 拓扑排序
queue<char> q;
for (auto& [a, b] : in) {
if (b == 0)
q.push(a);
}
string ret;
while (q.size()) {
char t = q.front();
q.pop();
ret += t;
for (char ch : edges[t]) {
if (--in[ch] == 0)
q.push(ch);
}
}
// 3. 判断
for (auto& [a, b] : in)
if (b != 0)
return "";
return ret;
}
void add(string& s1, string& s2) {
int n = min(s1.size(), s2.size());
int i = 0;
for (; i < n; i++) {
if (s1[i] != s2[i]) {
char a = s1[i], b = s2[i]; // a -> b
if (!edges.count(a) || !edges[a].count(b)) {
edges[a].insert(b);
in[b]++;
}
break;
}
}
if (i == s2.size() && i < s1.size())
cheak = true;
}
};代码思路解析

-
初始化数据结构
-
使用
unordered_map<char, unordered_set<char>> edges来表示字母之间的依赖关系,构建邻接表。 -
使用
unordered_map<char, int> in来记录每个字母的入度,即有多少字母依赖于该字母。 -
布尔变量
cheak用于处理特殊情况,帮助判断是否存在非法的字母顺序。
-
-
构建图与初始化入度哈希表
-
第一步构建空图和入度:
-
遍历给定的单词列表
words,对每个单词中的每个字母进行处理,把每个字母加入入度哈希表in,并初始化入度为 0。
-
-
第二步建立依赖关系:
-
使用两个嵌套循环遍历所有单词,比较每对相邻的单词
words[i]和words[j]:-
调用
add(words[i], words[j])方法,尝试为两个单词添加依赖关系。 -
如果在
add方法中发现了非法的字母顺序(例如,前一个单词比后一个单词更长且它们相同),则将cheak设置为 true,并返回空字符串。
-
-
-
-
进行拓扑排序
-
使用队列
queue<char> q存储入度为 0 的字母(即没有任何字母依赖于这些字母)。 -
遍历入度哈希表,将所有入度为 0 的字母加入队列。
-
BFS 过程:
-
当队列不为空时,进行以下操作:
-
从队列中取出一个字母
t,并将其添加到结果字符串ret中。 -
遍历字母
t的所有依赖字母,对其入度减 1。如果某个依赖字母的入度减为 0,表示该字母可以被添加到队列。
-
-
-
-
判断是否存在环
-
在完成拓扑排序后,再次遍历入度哈希表,检查是否有字母的入度不为 0。如果有,则表示存在循环依赖,返回空字符串。
-
如果所有字母的入度都为 0,返回构建的字母顺序字符串
ret。
-
-
添加依赖关系的辅助函数
-
add(string& s1, string& s2)方法负责比较两个单词的字母,并根据字母的不同情况来添加依赖关系:-
遍历两个单词的字母,找到第一个不同的字母
s1[i]和s2[i],并记录它们的依赖关系(a -> b)。 -
如果后一个单词比前一个单词短,但前一个单词的前面部分与后一个单词相同,则标记
cheak为 true,表示存在无效顺序。
-
-
总结
这段代码通过构建邻接表和入度数组,结合拓扑排序算法有效地解决了外星字母顺序的问题。通过 BFS 处理字母的依赖关系,最终依赖关系被整理为合法的字母顺序,如果存在循环依赖则返回空字符串。
算法步骤概述
-
初始化
-
创建邻接表和入度哈希表。
-
-
构建字母依赖关系
-
遍历单词列表,添加字母及其依赖关系,检查无效情况。
-
-
拓扑排序
-
使用队列处理入度为 0 的字母,同时更新依赖关系。
-
-
结果验证
-
检查入度状态以判断是否存在循环依赖,返回字母顺序字符串。
-