JDK源码系列(二)
一、ArrayList类
ArrayList类结构
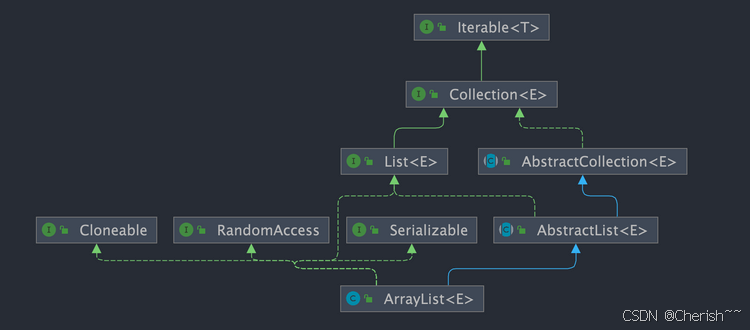
ArrayList是一个用数组实现的集合,支持随机访问,元素有序且可以重复
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
}- List:表明它是一个列表,支持添加、删除、查找等操作,并且可以通过下标进行访问。
- RandomAccess:这是一个标志接口,表明实现这个接口的List集合是支持快速访问的。在ArrayList中,我们可以通过元素的序号快速获取元素对象,这就是快速随机访问。
- Cloneable:表明它具有拷贝能力,可以进行深拷贝或浅拷贝。
- Serializable:表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
ArrayList核心源码解读
字段属性
//默认初始容量大小
private static final int DEFAULT_CAPACITY = 10;
//空的数组实例
private static final Object[] EMPTY_ELEMENTDATA = {};
//这也是一个空的数组实例,和EMPTY_ELEMENTDATA空数组相比是用于了解添加第一个元素时数组膨胀多少
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//存储 ArrayList集合的元素,集合的长度即这个数组的长度
//1、当 elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA 时将会清空 ArrayList
//2、当添加第一个元素时,elementData 长度会扩展为 DEFAULT_CAPACITY=10
transient Object[] elementData;
//表示集合中所包含的元素个数
private int size;类构造器
无参构造
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}此无参构造函数将创建一个DEFAULTCAPACITY_EMPTY_ELEMENTDATA声明的数组,注意此时初始容量为0,而不是10。
注意:根据默认构造函数创建的集合,ArrayList list = new ArrayList(); 此时集合长度是 0。
重载:有参构造ArrayList(int initialCapacity)
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}初始化集合大小创建ArrayList集合。当大于0时,给定多少那就创建多大的数组。当等于0时,创建一个空数组。当小于0时,抛出异常。
重载:ArrayList(Collection<? extends E> c)
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}将已有的集合复制到ArrayList集合中。
添加元素
public boolean add(E e) {
ensureCapacityInternal(size + 1); //添加元素之前,首先要确定集合的大小(是否需要扩容)
elementData[size++] = e;
return true;
}如上述代码所示,在通过调用add方法添加元素之前,我们要首先调用ensureCapacityInternal方法来确定集合的大小,如果集合满了,则要进行扩容操作:
private void ensureCapacityInternal(int minCapacity) {//这里的minCapacity 是集合当前大小+1
//elementData 是实际用来存储元素的数组,注意数组的大小和集合的大小不是相等的,前面的size是指集合大小
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {//如果数组为空,则从size+1的值和默认值10中取最大的
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;//不为空,则返回size+1
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}在ensureExplicitCapacity方法中,首先对修改次数modCount加一,这里的modCount给ArrayList的迭代器使用的,在并发操作被修改时,提供快速失败行为(保证modCount在迭代期间不变,否则抛出ConcurrentModificationException异常,源码867行),接着判断minCapacity是否大于当前ArrayList内部数组长度,大于的话调用下面grow方法对内部elementData扩容。
private void grow(int minCapacity) {
int oldCapacity = elementData.length;//得到原始数组的长度
int newCapacity = oldCapacity + (oldCapacity >> 1);//新数组的长度等于原数组长度的1.5倍
if (newCapacity - minCapacity < 0)//当新数组长度仍然比minCapacity小,则为保证最小长度,新数组等于minCapacity
newCapacity = minCapacity;
//MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8 = 2147483639
if (newCapacity - MAX_ARRAY_SIZE > 0)//当得到的新数组长度比 MAX_ARRAY_SIZE 大时,调用 hugeCapacity 处理大数组(将数组容量设置为Inteyger.MAX_VALUE)
newCapacity = hugeCapacity(minCapacity);
//调用 Arrays.copyOf 将原数组拷贝到一个大小为newCapacity的新数组(注意是拷贝引用)
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) //
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ? //minCapacity > MAX_ARRAY_SIZE,则新数组大小为Integer.MAX_VALUE
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}扩容的核心方法就是调用前面的Arrays.copyOf方法,创建一个更大的数组,然后将原数组元素拷贝过去。
对ArrayList集合添加元素的总结:
- 当通过ArrayList()构造一个空集合时,初始长度是0;第一次添加元素,会创建一个长度为10的数组,并将该元素赋值到数组的第一个位置。
- 第二次添加元素时,集合不为空,而且由于集合的长度size + 1是小于数组的长度10,所以直接添加元素到数组的第二个位置,不用扩容。
- 第十一次添加元素,此时size + 1 = 11,而数组长度是10,这时候创建一个长度为10 + 10 * 0.5 = 15的数组(扩容1.5倍),然后将原数组元素引用拷贝到新数组。并将第十一次添加的元素赋值到新数组下标为10的位置。
- 第 Integer.MAX_VALUE - 7次添加元素时,创建一个大小为Integer.MAX_VALUE的数组,再进行元素添加。
- 第Integer.MAX_VALUE + 1 次添加元素时,抛出 OutOfMemoryError 异常。
注意:可以向集合中添加 null ,因为数组可以有 null 值存在。
删除元素
public E remove(int index) {
rangeCheck(index); //判断给定索引的范围,超过集合大小则抛出异常
modCount++;
E oldValue = elementData(index); //得到索引处的删除元素
int numMoved = size - index - 1;
if (numMoved > 0) //size-index-1 > 0 表示 0<= index < (size-1),即索引不是最后一个元素
//通过 System.arraycopy()将数组elementData 的下标index+1之后长度为 numMoved 的元素拷贝到从index开始的位置
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; //更新 size 的同时将数组最后一个元素置为 null,便于垃圾回收
return oldValue;
}remove(int index)方法表示删除索引index处的元素,首先通过rangeCheck(int index)方法判断给定索引的范围,超过集合大小则抛出异常。接着通过System.arraycopy方法对数组进行自身拷贝。
/*
* src:源数组
srcPos:源数组要复制的起始位置
dest:目的数组
destPos:目的数组放置的起始位置
length:复制的长度
注意:src 和 dest都必须是同类型或者可以进行转换类型的数组。
*/
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);修改元素
public E set(int index, E element) {
rangeCheck(index);//判断索引合法性
E oldValue = elementData(index);//获得原数组指定索引的元素
elementData[index] = element;//将指定所引处的元素替换为 element
return oldValue;//返回原数组索引元素
}通过调用set(int index,E element)方法在指定索引index处的元素替换为element,并返回原数组的元素。
通过调用rangeCheck(index)来检查索引合法性
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}当索引为负数时,会抛出 java.lang.ArrayIndexOutOfBoundsException 异常。当索引大于集合长度时,会抛出 IndexOutOfBoundsException 异常。
查找元素
public E get(int index) {
rangeCheck(index);
return elementData(index);
}同理,首先还是判断给定索引的合理性,然后直接返回处于该下标位置的数组元素。
二、LinkedList类
LinkedList类定义
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
//...
}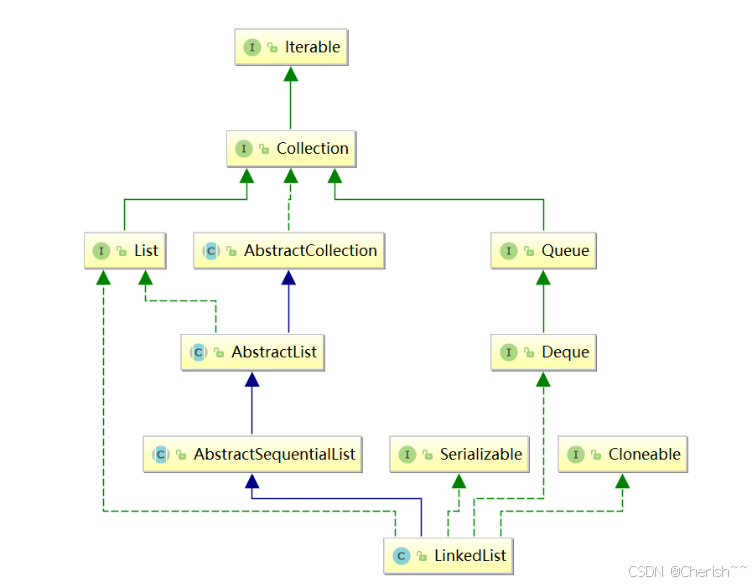
- 和ArrayList集合一样,LinkedList集合也实现了Cloneable接口和Serializable接口,分别用来支持克隆以及序列化。
- List:表明它是一个列表,支持添加、删除、查找等操作,并且可以通过下标进行访问。
-
Deque:继承自Queue接口,具有双端队列的特性,支持从两端插入和删除元素,方便实现栈和队列等数据结构。
注意:由于LinkedList底层数据结构是链表,内存地址不连续,只能通过指针来定位,不支持随机快速访问,所以不能实现RandomAccess接口。
LinkedList源码分析
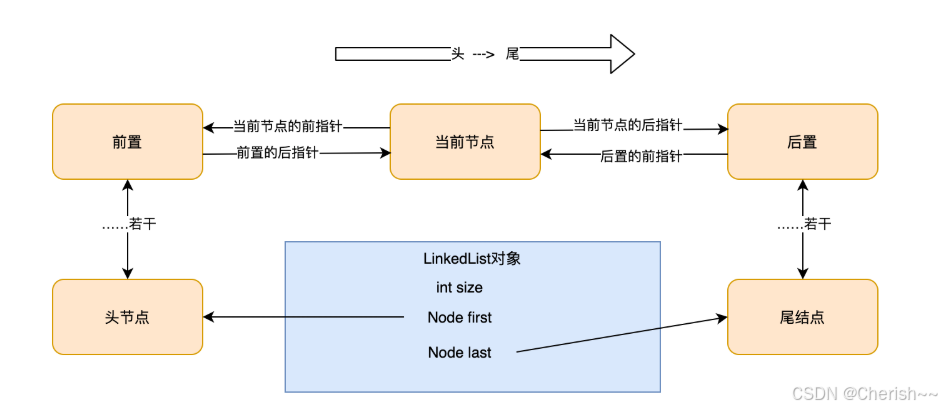
LinkedList中的元素是通过Node定义的:
private static class Node<E> {
E item;// 节点值
Node<E> next; // 指向的下一个节点(后继节点)
Node<E> prev; // 指向的前一个节点(前驱结点)
// 初始化参数顺序分别是:前驱结点、本身节点值、后继节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
初始化
// 创建一个空的链表对象
public LinkedList() {
}
// 接收一个集合类型作为参数,会创建一个与传入集合相同元素的链表对象
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}LinkedList有两个构造函数,第一个是默认的空的构造函数,第二个是将已有元素的集合Collection的实例添加到LinkedList中,调用的是addAll()方法。
注意 :LinkedList是没有初始化链表大小的构造函数,因为链表不像数组,一个定义好的数组是必须要有确定的大小,然后去分配内存空间,而链表不同,它没有确定的大小,通过指针的移动来指向下一个内存地址的分配。
添加元素
addFirst(E e)
将指定元素添加到链表头
//将指定的元素附加到链表头节点
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first; //将头节点赋值给 f
final Node<E> newNode = new Node<>(null, e, f); //将指定元素构造成一个新节点,此节点的指向下一个节点的引用为头节点
first = newNode; //将新节点设为头节点,那么原先的头节点 f 变为第二个节点
if (f == null) //如果第二个节点为空,也就是原先链表是空
last = newNode; //将这个新节点也设为尾节点(前面已经设为头节点了)
else
f.prev = newNode;//将原先的头节点的上一个节点指向新节点
size++; //节点数加1
modCount++; //和ArrayList中一样,iterator和listIterator方法返回的迭代器和列表迭代器实现使用。
}addLast(E e)和add(E e)
将指定元素添加到链表尾
//将元素添加到链表末尾
public void addLast(E e) {
linkLast(e);
}
//将元素添加到链表末尾
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last; //将l设为尾节点
final Node<E> newNode = new Node<>(l, e, null); //构造一个新节点,节点上一个节点引用指向尾节点l
last = newNode; //将尾节点设为创建的新节点
if (l == null) //如果尾节点为空,表示原先链表为空
first = newNode; //将头节点设为新创建的节点(尾节点也是新创建的节点)
else
l.next = newNode; //将原来尾节点下一个节点的引用指向新节点
size++; //节点数加1
modCount++; //和ArrayList中一样,iterator和listIterator方法返回的迭代器和列表迭代器实现使用。
}add(int index, E element)
将指定的元素插入此列表中的指定位置
//将指定的元素插入此列表中的指定位置
public void add(int index, E element) {
//判断索引 index >= 0 && index <= size中时抛出IndexOutOfBoundsException异常
checkPositionIndex(index);
if (index == size)//如果索引值等于链表大小
linkLast(element);//将节点插入到尾节点
else
linkBefore(element, node(index));
}
void linkLast(E e) {
final Node<E> l = last;//将l设为尾节点
final Node<E> newNode = new Node<>(l, e, null);//构造一个新节点,节点上一个节点引用指向尾节点l
last = newNode;//将尾节点设为创建的新节点
if (l == null)//如果尾节点为空,表示原先链表为空
first = newNode;//将头节点设为新创建的节点(尾节点也是新创建的节点)
else
l.next = newNode;//将原来尾节点下一个节点的引用指向新节点
size++;//节点数加1
modCount++;//和ArrayList中一样,iterator和listIterator方法返回的迭代器和列表迭代器实现使用。
}
Node<E> node(int index) {
if (index < (size >> 1)) {//如果插入的索引在前半部分
Node<E> x = first;//设x为头节点
for (int i = 0; i < index; i++)//从开始节点到插入节点索引之间的所有节点向后移动一位
x = x.next;
return x;
} else {//如果插入节点位置在后半部分
Node<E> x = last;//将x设为最后一个节点
for (int i = size - 1; i > index; i--)//从最后节点到插入节点的索引位置之间的所有节点向前移动一位
x = x.prev;
return x;
}
}
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;//将pred设为插入节点的上一个节点
final Node<E> newNode = new Node<>(pred, e, succ);//将新节点的上引用设为pred,下引用设为succ
succ.prev = newNode;//succ的上一个节点的引用设为新节点
if (pred == null)//如果插入节点的上一个节点引用为空
first = newNode;//新节点就是头节点
else
pred.next = newNode;//插入节点的下一个节点引用设为新节点
size++;
modCount++;
}addAll(Collection<? extends E> c)
按照指定集合的迭代器返回的顺序,将指定集合中的所有元素追加到此列表的末尾
addAll有两个重载函数:
- addAll(Collection<? extends E>)型
- addAll(int, Collection<? extends E>)型
我们平时习惯调用的 addAll(Collection<? extends E>) 型会转化为 addAll(int, Collection<? extends E>) 型。addAll(c):
//按照指定集合的••迭代器返回的顺序,将指定集合中的所有元素追加到此列表的末尾。
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
//真正核心的地方就是这里了,记得我们传过来的是size,c
public boolean addAll(int index, Collection<? extends E> c) {
//检查index这个是否为合理。这个很简单,自己点进去看下就明白了。
checkPositionIndex(index);
//将集合c转换为Object数组 a
Object[] a = c.toArray();
//数组a的长度numNew,也就是由多少个元素
int numNew = a.length;
if (numNew == 0)
//集合c是个空的,直接返回false,什么也不做。
return false;
//集合c是非空的,定义两个节点(内部类),每个节点都有三个属性,item、next、prev。
Node<E> pred, succ;
//构造方法中传过来的就是index==size
if (index == size) {
//linkedList中三个属性:size、first、last。 size:链表中的元素个数。 first:头节点 last:尾节点,就两种情况能进来这里
//情况一、:构造方法创建的一个空的链表,那么size=0,last、和first都为null。linkedList中是空的。什么节点都没有。succ=null、pred=last=null
//情况二、:链表中有节点,size就不是为0,first和last都分别指向第一个节点,和最后一个节点,在最后一个节点之后追加元素,就得记录一下最后一个节点是什么,所以把last保存到pred临时节点中。
succ = null;
pred = last;
} else {
//情况三、index!=size,说明不是前面两种情况,而是在链表中间插入元素,那么就得知道index上的节点是谁,保存到succ临时节点中,然后将succ的前一个节点保存到pred中,这样保存了这两个节点,就能够准确的插入节点了
//举个简单的例子,有2个位置,1、2、如果想插数据到第二个位置,双向链表中,就需要知道第一个位置是谁,原位置也就是第二个位置上是谁,然后才能将自己插到第二个位置上。如果这里还不明白,先看一下开头对于各种链表的删除,add操作是怎么实现的。
succ = node(index);
pred = succ.prev;
}
//前面的准备工作做完了,将遍历数组a中的元素,封装为一个个节点。
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
//pred就是之前所构建好的,可能为null、也可能不为null,为null的话就是属于情况一、不为null则可能是情况二、或者情况三
Node<E> newNode = new Node<>(pred, e, null);
//如果pred==null,说明是情况一,构造方法,是刚创建的一个空链表,此时的newNode就当作第一个节点,所以把newNode给first头节点
if (pred == null)
first = newNode;
else
//如果pred!=null,说明可能是情况2或者情况3,如果是情况2,pred就是last,那么在最后一个节点之后追加到newNode,如果是情况3,在中间插入,pred为原index节点之前的一个节点,将它的next指向插入的节点,也是对的
pred.next = newNode;
//然后将pred换成newNode,注意,这个不在else之中,请看清楚了。
pred = newNode;
}
if (succ == null) {
//如果succ==null,说明是情况一或者情况二,
//情况一、构造方法,也就是刚创建的一个空链表,pred已经是newNode了,last=newNode,所以linkedList的first、last都指向第一个节点。
//情况二、在最后节后之后追加节点,那么原先的last就应该指向现在的最后一个节点了,就是newNode。
last = pred;
} else {
//如果succ!=null,说明可能是情况三、在中间插入节点,举例说明这几个参数的意义,有1、2两个节点,现在想在第二个位置插入节点newNode,根据前面的代码,pred=newNode,succ=2,并且1.next=newNode,1已经构建好了,pred.next=succ,相当于在newNode.next = 2; succ.prev = pred,相当于 2.prev = newNode, 这样一来,这种指向关系就完成了。first和last不用变,因为头节点和尾节点没变
pred.next = succ;
//。。
succ.prev = pred;
}
//增加了几个元素,就把 size = size +numNew 就可以了
size += numNew;
modCount++;
return true;
}说明:参数中的index表示在索引下标为index的结点(实际上是第index + 1个结点)的前面插入。
在addAll函数中,addAll函数中还会调用到node函数,get函数也会调用到node函数,此函数是根据索引下标找到该结点并返回,具体代码如下:
Node<E> node(int index) {
// 判断插入的位置在链表前半段或者是后半段
if (index < (size >> 1)) { // 插入位置在前半段
Node<E> x = first;
for (int i = 0; i < index; i++) // 从头结点开始正向遍历
x = x.next;
return x; // 返回该结点
} else { // 插入位置在后半段
Node<E> x = last;
for (int i = size - 1; i > index; i--) // 从尾结点开始反向遍历
x = x.prev;
return x; // 返回该结点
}
}说明:在根据索引查找节点时,有一个小优化,结点在前半段则从头开始遍历;在后半段则从尾开始遍历,这样就保证了只需要遍历最多一半节点就可以找到指定索引的节点。
修改元素
通过调用 set(int index, E element) 方法,用指定的元素替换此列表中指定位置的元素
public E set(int index, E element) {
//判断索引 index >= 0 && index <= size中时抛出IndexOutOfBoundsException异常
checkElementIndex(index);
Node<E> x = node(index);//获取指定索引处的元素
E oldVal = x.item;
x.item = element;//将指定位置的元素替换成要修改的元素
return oldVal;//返回指定索引位置原来的元素
}这里主要是通过 node(index) 方法获取指定索引位置的节点,然后修改此节点位置的元素即可。
获取元素
LinkedList获取元素相关的方法一共有 3 个:
getFirst():获取链表的第一个元素。getLast():获取链表的最后一个元素。get(int index):获取链表指定位置的元素。
// 获取链表的第一个元素
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
// 获取链表的最后一个元素
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
// 获取链表指定位置的元素
public E get(int index) {
// 下标越界检查,如果越界就抛异常
checkElementIndex(index);
// 返回链表中对应下标的元素
return node(index).item;
}删除元素
LinkedList删除元素相关的方法一共有 5 个:
removeFirst():删除并返回链表的第一个元素。removeLast():删除并返回链表的最后一个元素。remove(E e):删除链表中首次出现的指定元素,如果不存在该元素则返回 false。remove(int index):删除指定索引处的元素,并返回该元素的值。void clear():移除此链表中的所有元素。
// 删除并返回链表的第一个元素
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
// 删除并返回链表的最后一个元素
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
// 删除链表中首次出现的指定元素,如果不存在该元素则返回 false
public boolean remove(Object o) {
// 如果指定元素为 null,遍历链表找到第一个为 null 的元素进行删除
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
// 如果不为 null ,遍历链表找到要删除的节点
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
// 删除链表指定位置的元素
public E remove(int index) {
// 下标越界检查,如果越界就抛异常
checkElementIndex(index);
return unlink(node(index));
}这里的核心在于 unlink(Node<E> x) 这个方法:
E unlink(Node<E> x) {
// 断言 x 不为 null
// assert x != null;
// 获取当前节点(也就是待删除节点)的元素
final E element = x.item;
// 获取当前节点的下一个节点
final Node<E> next = x.next;
// 获取当前节点的前一个节点
final Node<E> prev = x.prev;
// 如果前一个节点为空,则说明当前节点是头节点
if (prev == null) {
// 直接让链表头指向当前节点的下一个节点
first = next;
} else { // 如果前一个节点不为空
// 将前一个节点的 next 指针指向当前节点的下一个节点
prev.next = next;
// 将当前节点的 prev 指针置为 null,,方便 GC 回收
x.prev = null;
}
// 如果下一个节点为空,则说明当前节点是尾节点
if (next == null) {
// 直接让链表尾指向当前节点的前一个节点
last = prev;
} else { // 如果下一个节点不为空
// 将下一个节点的 prev 指针指向当前节点的前一个节点
next.prev = prev;
// 将当前节点的 next 指针置为 null,方便 GC 回收
x.next = null;
}
// 将当前节点元素置为 null,方便 GC 回收
x.item = null;
size--;
modCount++;
return element;
}- 首先获取待删除节点 x 的前驱和后继节点;
- 判断待删除节点是否为头节点或尾节点:
- 如果 x 是头节点,则将 first 指向 x 的后继节点 next
- 如果 x 是尾节点,则将 last 指向 x 的前驱节点 prev
- 如果 x 不是头节点也不是尾节点,执行下一步操作
- 将待删除节点 x 的前驱的后继指向待删除节点的后继 next,断开 x 和 x.prev 之间的链接;
- 将待删除节点 x 的后继的前驱指向待删除节点的前驱 prev,断开 x 和 x.next 之间的链接;
- 将待删除节点 x 的元素置空,修改链表长度。