DeepSeek 细节之 MLA (Multi-head Latent Attention)
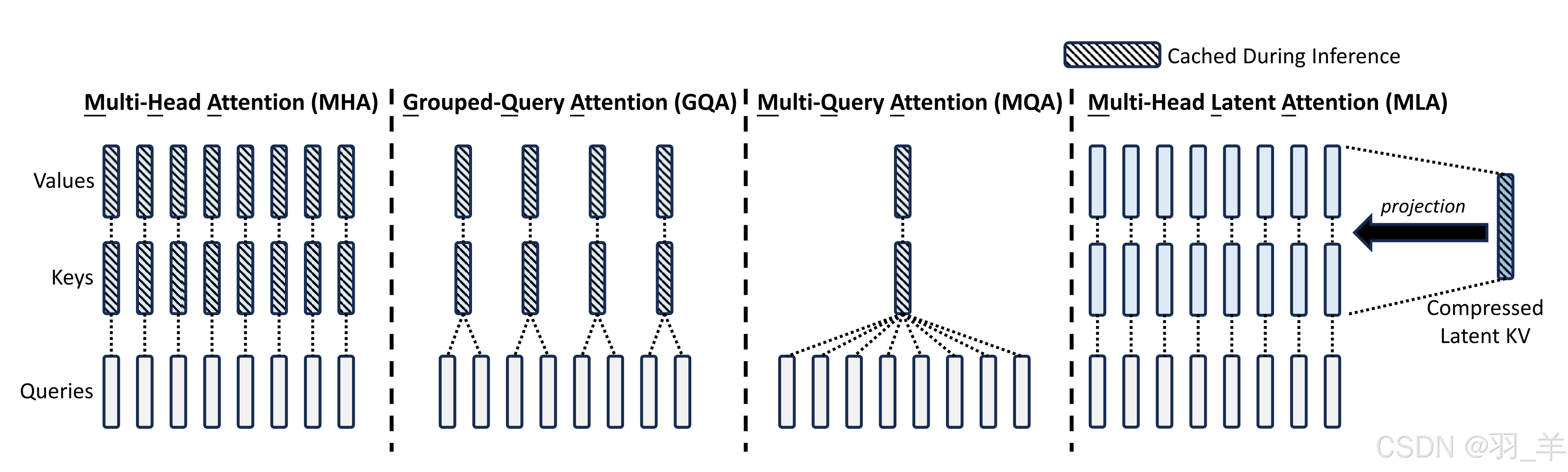
DeepSeek 系统模型的基本架构仍然基于Transformer框架,为了实现高效推理和经济高效的训练,DeepSeek 还采用了MLA(多头潜在注意力)。 MHA(多头注意力)通过多个注意力头并行工作捕捉序列特征,但面临高计算成本和显存占用;MLA(多头潜在注意力)则通过低秩压缩优化键值矩阵,降低显存占用并提高推理效率。
MHA(Muti Head Attention)
多头注意力机制 (MHA)通过多个注意力头并行工作来捕捉序列特征,但这种方法会导致计算成本高和显存占用大的问题。并且随着上下文窗口或批量大小的增加,多头注意力 (MHA)模型中与 KV 缓存大小相关的内存成本显着增长。
KV Cache 缓存的到底是什么呢
- 基于 transformer 中的注意力计算公式
![]()
- 预测下一个 token 时,其只能看到待预测 token 之前的所有 token,故在最终生成整个序列的过程中,会涉及到如下计算过程
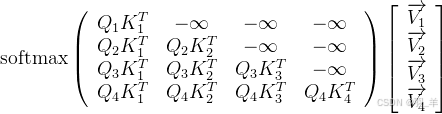
- 然后把上面的softmax结果和对应的V值一相乘,便可得到
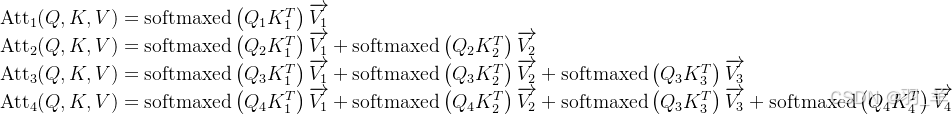
- 可以很明显的看到,上述计算过程中,有不少的重复计算,比如 K1V1, K2V2, K3V3 等,如果序列长度越长,类似这样的 KV 计算将越来越多
为了加快推理速度,很自然的就想起将这些 KV 对缓存到显存中,等到计算时命中了缓存就不用再重复计算了,自然也就加快了推理的速度。但是这种以空间换时间的做法,就带来了显存消耗巨大的问题,如下图所示,在模型推理时,KV Cache在显存占用量可达30%以上

自此针对于 KV cache 优化的工作也就应运而生了
GQA(Grouped-Query Attention) 、MQA(Muti Query Attention)
- GQA是query数不变,但多个query(比如2个)组成一个group以共享一个key value
- MQA则query也不变,但所有query(比如8个)共享一个key、一个value
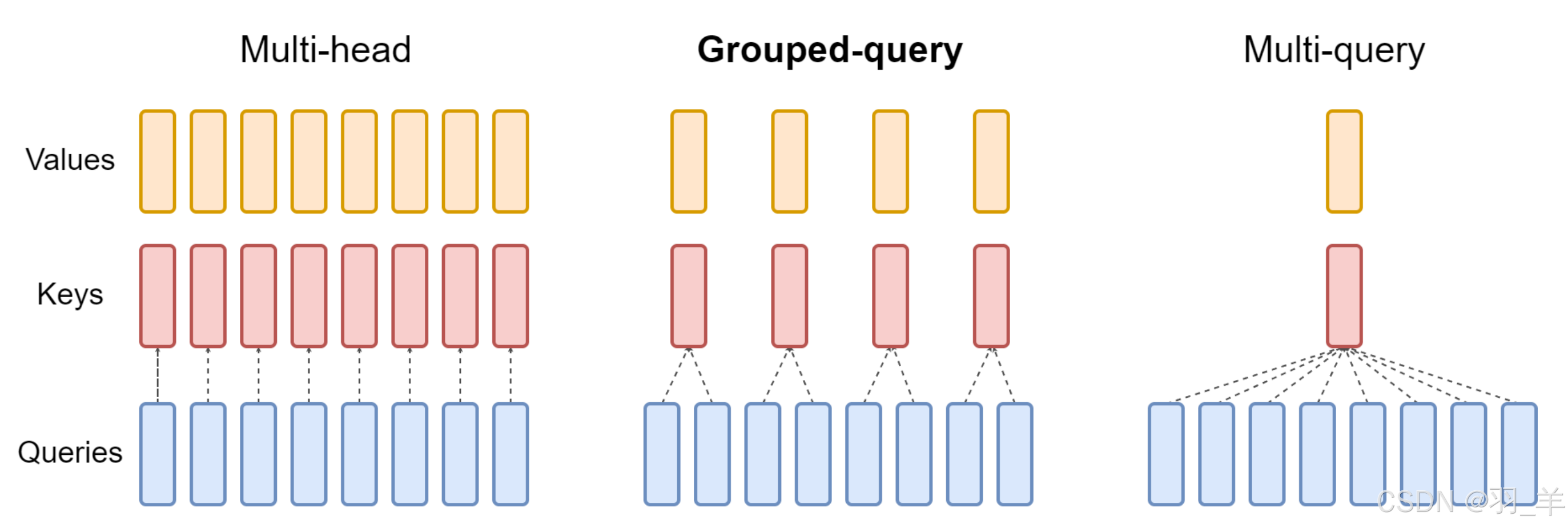
MQA虽然较大降低了KV cache计算量,但性能相比MHA下降太多了,至于GQA的话则取了个折中:不好的是缓存下降的不够多、好的是相比MHA性能没有下降太多
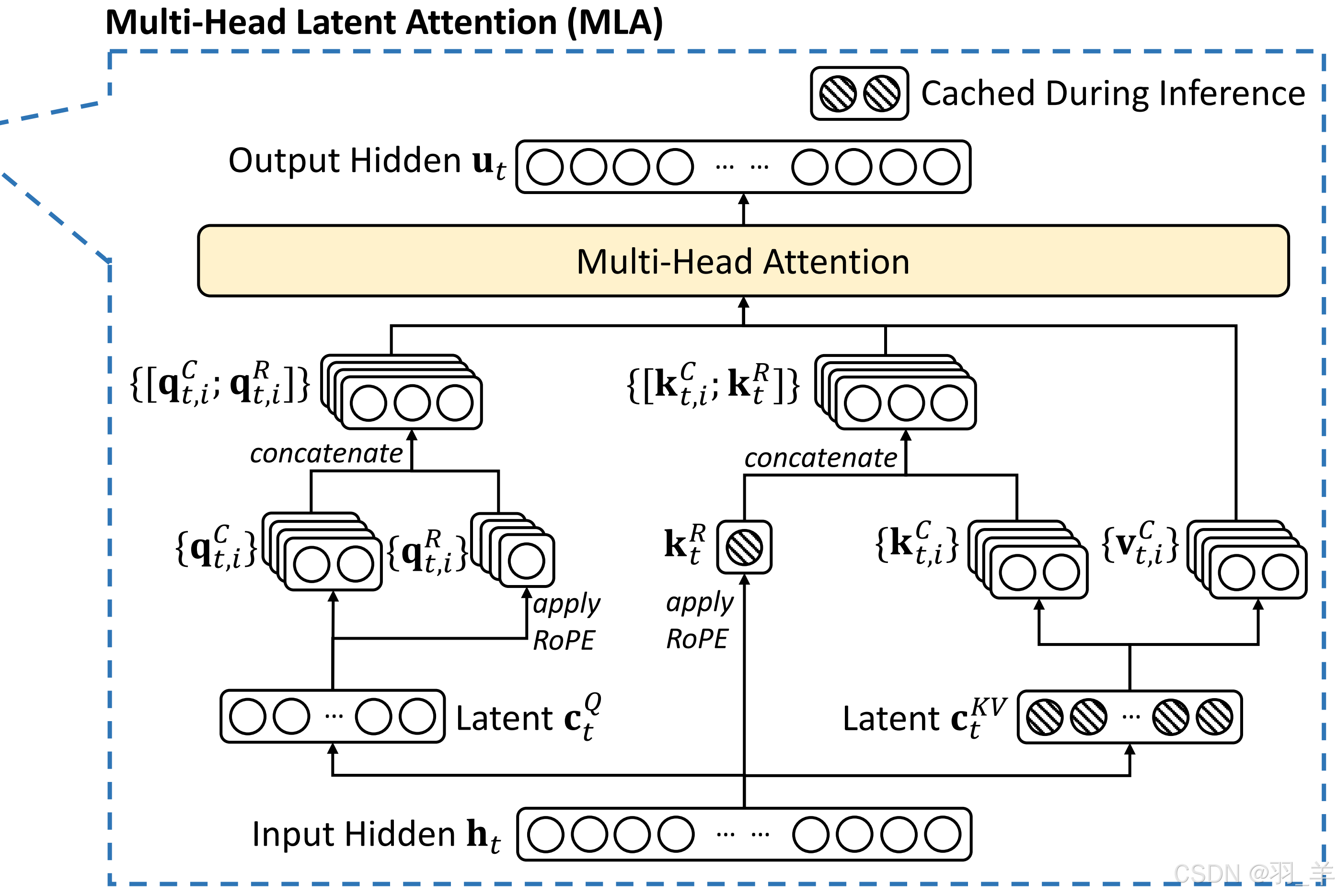
MLA(Multi-head Latent Attent):致力于在推理中降低
- MLA 致力于在推理中降低隐层维度,而不是直接减少 cache 的数量,而是类似 Lora 的方法,用多个小矩阵乘法来近似替代大矩阵
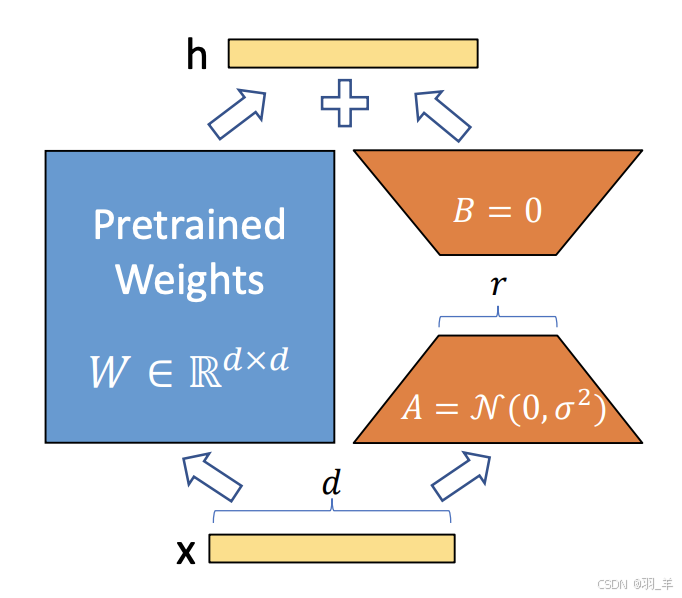
- 对 Key 和 Value 进行了一个低秩联合压缩(即Low-Rank Key-Value Joint Compression,通过低秩转换为一个压缩的 KV,使得存储的 KV 的维度显著减小,在 MHA GQA中大量存在于keys values中的 KV 缓存——带阴影表示,到了MLA中时,只有一小部分的被压缩Compressed的Latent KV了
- MLA的两个部分:一部分做压缩、一部分做RoPE编码,一文通透DeepSeek V2——通俗理解多头潜在注意力MLA:改进MHA,从而压缩KV缓存,提高推理速度一文中有详细的推导过程可供参考
- MLA 先对Q K V的进行压缩:先对KV联合压缩后升维,再对Q压缩后升维
- MLA 对 query 和 key 进行 RoPE 编码,并对其中的Key位置编码的部分进行 Cache,从而在推理时不需要对Key进行位置编码的计算,提高了推理效率
参考文献
- 一文通透DeepSeek V2——通俗理解多头潜在注意力MLA:改进MHA,从而压缩KV缓存,提高推理速度
- 一文搞懂DeepSeek - 多头注意力(MHA)和多头潜在注意力(MLA)
- DeepSeek V3推理: MLA与MOE解析
- 一文通透让Meta恐慌的DeepSeek-V3:在MoE、GRPO、MLA基础上提出Multi-Token预测(含FP8训练详解)