基于大数据的网络文学推荐分析系统的设计与实现【海量书籍、自动爬虫】
文章目录
- ==有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主==
- 项目介绍
- 项目展示
- 总结
- 每文一语
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
项目介绍
随着互联网技术的迅猛发展,网络文学已成为当代读者获取精神文化和娱乐的重要途径。然而,面对浩如烟海的网络文学作品,读者往往容易陷入信息过载,难以及时、精准地找到符合个人兴趣的优质内容。为解决这一痛点,本项目设计并实现了一套基于大数据技术的网络文学推荐与分析系统,旨在帮助用户更高效地探索和发现感兴趣的文学作品。
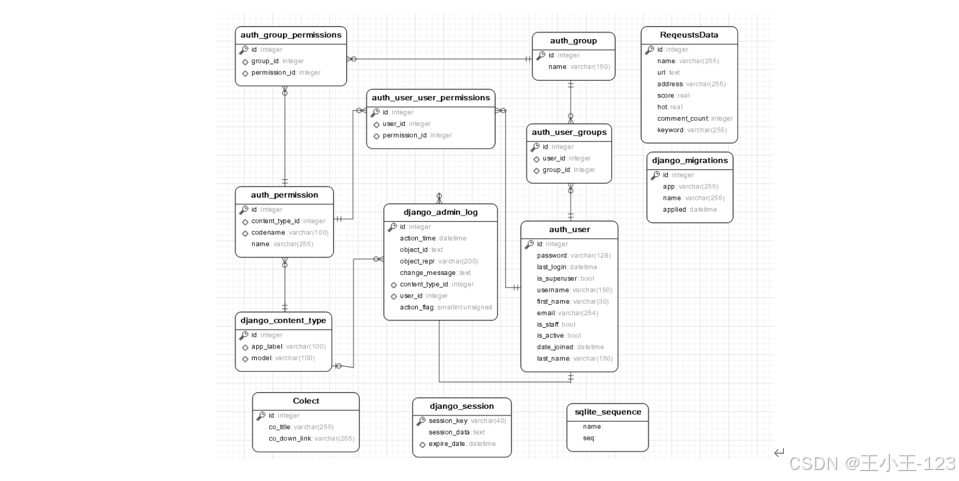
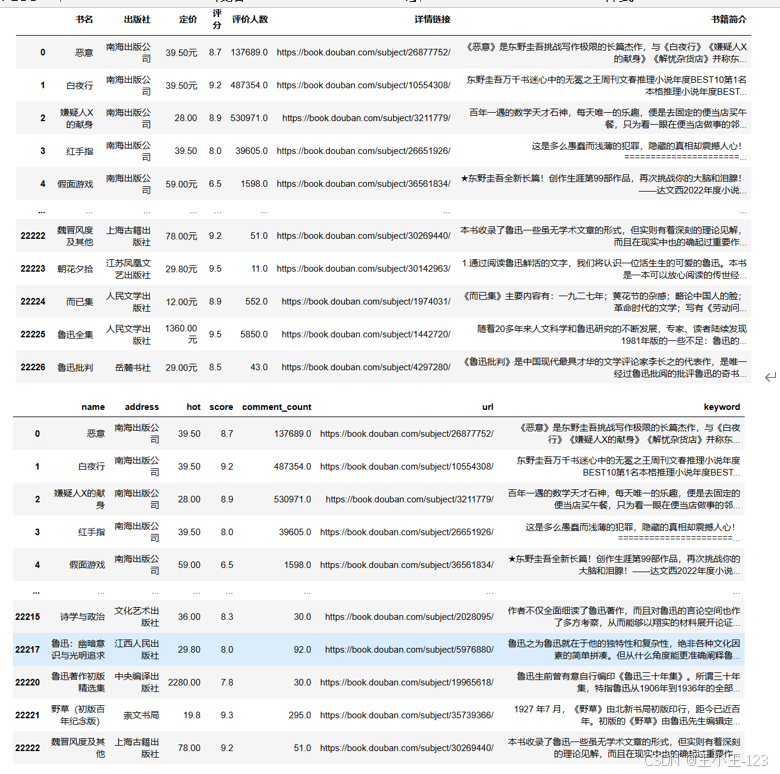
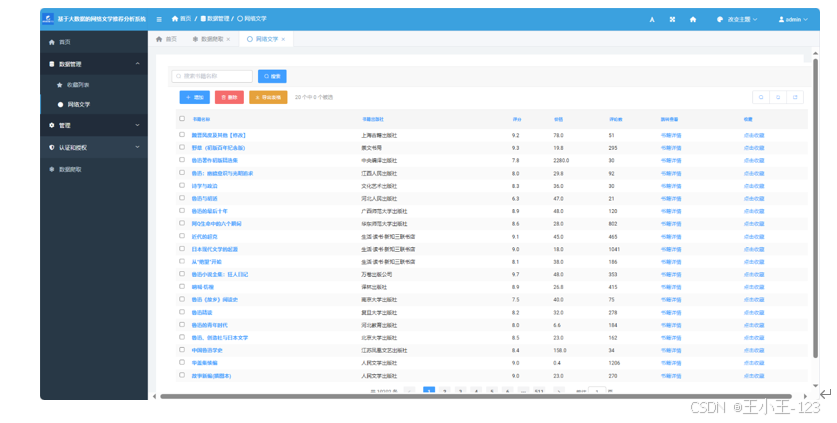
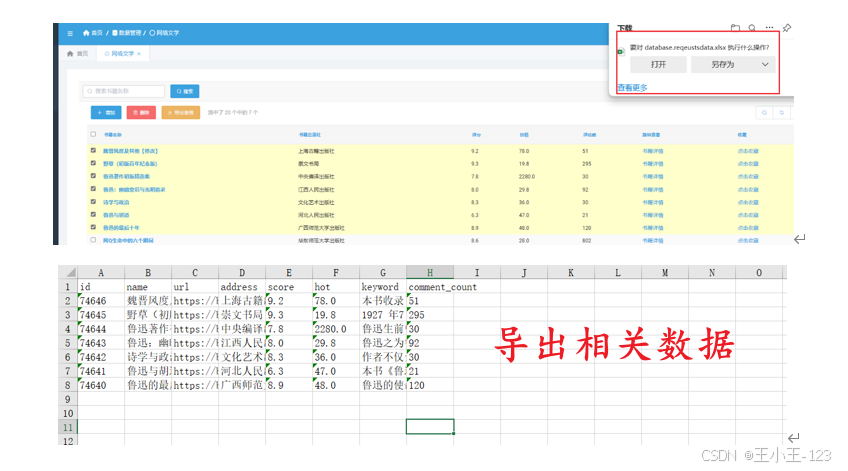
本系统核心功能包括数据自动采集、多维度可视化分析以及个性化推荐服务。系统利用Python爬虫技术,对豆瓣图书网站进行大规模数据抓取,针对网络环境中的反爬虫机制,结合请求头伪装、Cookies管理以及智能延时策略,有效保证了数据采集的连续性与稳定性。经过数据清洗与预处理,系统对采集的数万条图书信息进行了去重、缺失值填充与字段规范化,建立了结构化的高质量数据库,为后续分析与推荐打下坚实基础。
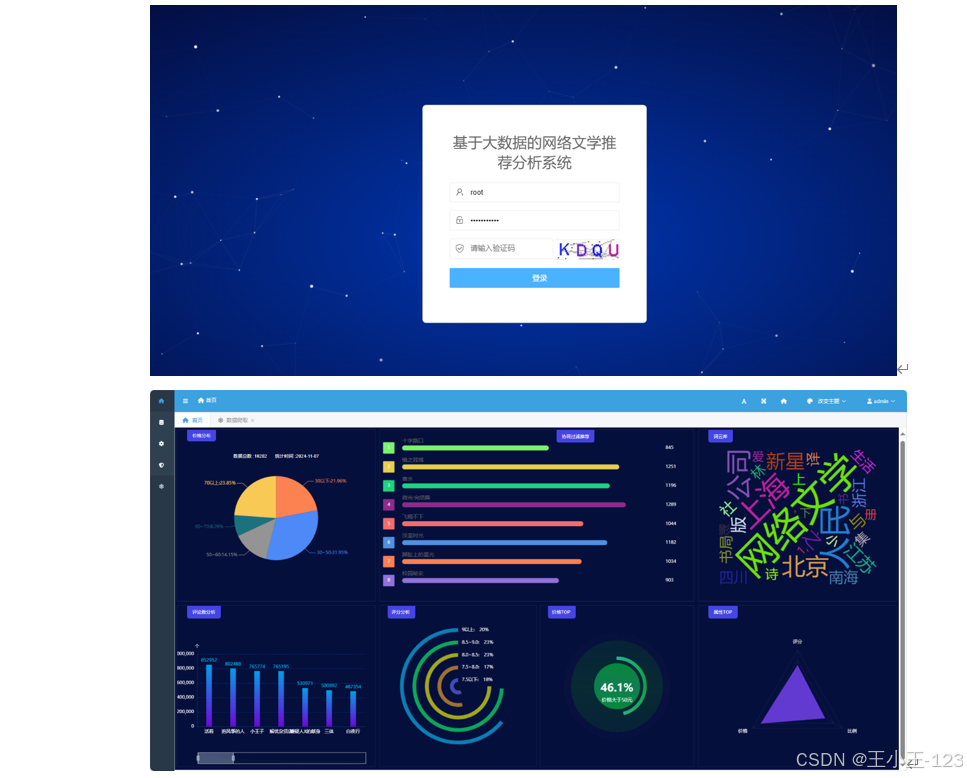
在系统架构方面,项目采用前后端分离模式,前端利用HTML、JavaScript及CSS等Web开发技术实现用户交互界面;后端则基于Django框架开发,负责数据处理、业务逻辑和接口管理。同时,系统集成了Echarts可视化库,通过饼图、折线图、柱状图、词云图等多种数据可视化方式,直观展示书籍的多维度分析结果,包括书名、价格区间、热度走势、用户评分分布等信息,帮助用户快速把握网络文学的整体格局与热点趋势。
在推荐算法部分,系统采用基于用户行为的协同过滤算法,通过分析用户收藏、浏览及评分等行为数据,计算用户之间的相似度,从而生成个性化的图书推荐列表。该推荐机制有效提升了用户与系统的互动体验,增强了推荐的针对性和精准度。
经过系统的试运行与多轮测试验证,结果表明,该系统不仅实现了数据采集的自动化和分析结果的可视化,更能为不同兴趣偏好的用户提供个性化的网络文学推荐,具有较高的实用价值和推广潜力。未来,项目计划进一步优化推荐算法,引入自然语言处理(NLP)技术以更深入挖掘文本语义,提升推荐的智能化水平;同时,也将优化用户界面设计,提升系统的易用性与用户体验。
总体而言,该系统不仅适用于图书馆、在线书店等文学资源管理与推荐平台,也为网络文学产业的健康发展提供了技术支持,具备良好的应用前景和社会价值。

项目展示
总结
系统的需求分析、设计、开发及测试,完成了整个系统的功能实现。通过细致的需求调研与分析,明确了系统的主要功能模块,并制定了合理的开发进度,分阶段有序推进。系统采用模块化设计,重点开发并优化了数据采集、用户管理、推荐算法以及数据可视化等核心部分。各阶段工作均按计划完成,为后续的系统测试和完善奠定了坚实基础。
项目实施过程中也遇到了一些困难。例如,在数据采集环节,网络爬虫受到反爬机制限制。针对这一问题,我通过增加访问延时、伪装请求头等技术手段,有效突破了反爬策略,确保了数据采集的顺利进行。此外,初期选用的基于用户的协同过滤算法在处理冷启动问题以及应对大规模数据时存在局限,需要进一步优化。
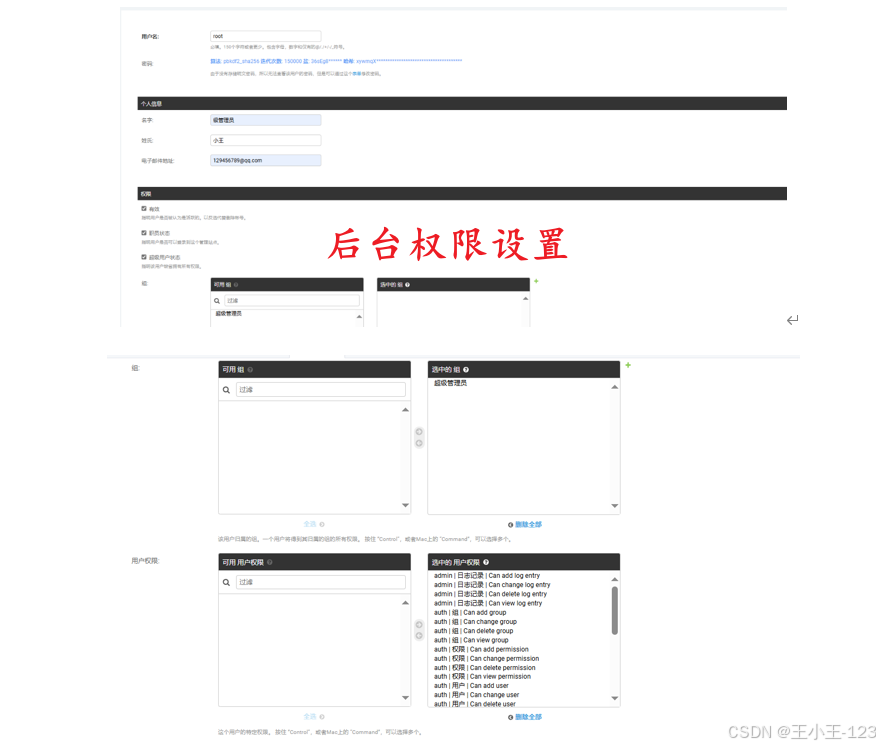
经过开发与多轮测试,系统在功能、稳定性及用户体验方面均取得了良好效果。系统实现了数据管理、个性化推荐、可视化展示及权限管理等功能,用户可以通过友好的界面和丰富的交互,便捷地获取所需信息。各功能模块集成度高,系统整体运行稳定,同时通过权限控制提升了数据的安全性。
展望未来,系统仍有进一步完善的空间。一方面,在推荐算法方面,可以引入深度学习或混合推荐模型,提升推荐的准确度和个性化水平。另一方面,系统可增加更多互动功能,如用户评论分析、个性化兴趣记录等,增强其实用性。此外,为提升系统的可扩展性,后续计划接入更多数据源,并探索云端部署,实现大规模数据处理和分布式推荐服务。
每文一语
学习永远都是一门艺术