JAVA面试宝典 -《分布式ID生成器:Snowflake优化变种》
🚀 分布式ID生成器:Snowflake优化变种
一场订单高峰,一次链路追踪,一条消息投递…你是否想过,它们背后都依赖着一个“低调却关键”的存在——唯一ID。本文将带你深入理解分布式ID生成器的核心原理与工程实践,重点解构 Snowflake 及其优化变种,揭示高并发场景下的稳定“发号器”设计。
文章目录
- 🚀 分布式ID生成器:Snowflake优化变种
- 1️⃣ 为什么需要分布式ID?
- ❌ UUID 的问题
- ❌ 数据库自增ID的局限
- ❌ 传统方案对比
- 2️⃣ Snowflake 原理详解
- 🧱 Snowflake 结构(64位拆解)
- 💻 Java 实现(简化版)
- 🎯 业务使用建议
- 🎯 特性总结
- 3️⃣ 时钟回拨问题与应对
- 🧩 常见解决策略:
- 1.拒绝服务法(默认做法):
- 2.时间等待法:
- 3.标记法 + 修正位:
- 4.双保险机制:
- 5.解决方案对比
- 🧠 总结建议
- 4️⃣ 美团 Leaf:号段模式 ID
- 🧱Segment 模式:
- 关键组件说明:
- 🧱Snowflake 模式:
- 关键组件说明:
- ✅架构对比图示
- 📌 对比总结
- 🧠 推荐选型建议
- 5️⃣ 基于 Redis 的 ID 生成
- 通过 INCR 命令实现:
- ✨优点
- ⚠ 注意事项
- 6️⃣ UUID 与数据库自增ID对比
- 推荐做法:
- 7️⃣ 跨机房部署策略
- 🧠 推荐策略:
- 8️⃣ 实战落地建议
- ☁ 部署建议:
- 🧩 总结与互动
1️⃣ 为什么需要分布式ID?
在微服务系统中,订单号、日志追踪ID、消息投递ID,都必须具备以下特性:
全局唯一(避免冲突)
趋势递增(数据库分页友好)
高性能生成(高并发不掉链子)
❌ UUID 的问题
UUID.randomUUID().toString();
// 输出:550e8400-e29b-41d4-a716-446655440000- 无序,不适合做数据库主键;
- 太长(36位字符),不利于存储和传输;
- 不可读,不利于排查和追踪。
❌ 数据库自增ID的局限
- 依赖单点,存在性能瓶颈与扩展困难;
- 分库分表难协调;
- 难以保障全局唯一。
❌ 传统方案对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| UUID | 简单,无中心化 | 无序,索引效率低 | 小规模系统 |
| 数据库自增 | 简单,有序 | 扩展性差,有单点风险 | 单机系统 |
| Redis自增 | 性能好 | 持久化风险,成本高 | 缓存层ID补充 |
性能对比(单机每秒生成ID数):
数据库自增:约5,000
UUID:约100,000
Snowflake:约1,000,000+
✅ 引出主角:Snowflake 算法!
2️⃣ Snowflake 原理详解
Snowflake 是 Twitter 开源的分布式高性能ID生成器,生成的是 64位长整型 ID,支持高并发下毫秒级唯一ID生成。
🧱 Snowflake 结构(64位拆解)
| 位数 | 含义 | 位宽 | 描述 |
|---|---|---|---|
| 1 | 符号位 | 1 | 固定为 0 |
| 2 | 时间戳 | 41 | 与自定义 epoch 相差的毫秒数 |
| 3 | 数据中心 ID | 5 | 可部署 32 个数据中心 |
| 4 | 机器 ID | 5 | 每个数据中心支持 32 台机器 |
| 5 | 序列号 | 12 | 每毫秒可生成 4096 个 ID |
0 | 41 bits timestamp | 5 bits dataCenterId | 5 bits machineId | 12 bits sequence💻 Java 实现(简化版)
public class SnowflakeIdGenerator {private final long epoch = 1609459200000L; // 自定义起始时间戳private final long dataCenterIdBits = 5L;private final long workerIdBits = 5L;private final long sequenceBits = 12L;private final long dataCenterIdShift = sequenceBits + workerIdBits;private final long timestampShift = sequenceBits + workerIdBits + dataCenterIdBits;private final long maxSequence = -1L ^ (-1L << sequenceBits);private long dataCenterId;private long workerId;private long lastTimestamp = -1L;private long sequence = 0L;public synchronized long nextId() {long current = System.currentTimeMillis();if (current == lastTimestamp) {sequence = (sequence + 1) & maxSequence;if (sequence == 0) {// 等待下一毫秒while (current <= lastTimestamp) {current = System.currentTimeMillis();}}} else {sequence = 0;}lastTimestamp = current;return ((current - epoch) << timestampShift)| (dataCenterId << dataCenterIdShift)| (workerId << sequenceBits)| sequence;}
}🎯 业务使用建议
- 趋势递增:ID在业务中按时间排序,利于分页
- 索引友好:64位整数比UUID更节省空间
- 雪崩风险:避免在整点时刻集中触发ID生成
- 业务编码:可在ID中嵌入业务类型前缀
🎯 特性总结
- 高性能:单机每毫秒可生成 4096 个 ID;
- 趋势递增:可用于索引、分表;
- 分布式无中心化。
3️⃣ 时钟回拨问题与应对
什么是时钟回拨?
假设当前时间是 13:00,系统突然因为 NTP 同步变成 12:59,如果 Snowflake 用的是系统时间,那么后续生成的 ID 可能重复或异常递减。
🧩 常见解决策略:
1.拒绝服务法(默认做法):
if (current < lastTimestamp) throw new RuntimeException("Clock moved backwards");2.时间等待法:
while (current < lastTimestamp) {current = System.currentTimeMillis();
}3.标记法 + 修正位:
增加标记字段表示回拨状态,优先写入缓存防止使用。
4.双保险机制:
- 使用本地时钟偏移记录;
- 配合外部 NTP 校时同步;
- 多 ID 实现(Snowflake + Redis 组合备用)。
5.解决方案对比
| 方案 | 原理概述 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| ❶ 拒绝服务法 | 一旦发现当前时间小于上一次生成 ID 的时间,则直接抛异常 | 简单暴力,避免产生错误 ID | 影响服务可用性,强依赖时间准确性 | 非核心服务、稳定时间环境 |
| ❷ 时间等待法 | 检测到回拨则 sleep() 等待系统时间恢复 | 保证 ID 单调递增,不抛错 | 线程阻塞、吞吐下降;等待时间难以控制 | 容忍轻微等待场景,如异步写单、批处理 |
| ❸ 标记法 + 修正位 | 检测回拨后增加特殊标识位或偏移位标记异常时间段 | 保留生成能力,且可追踪异常 ID | ID 结构更复杂,客户端需识别异常时间段 | 高并发高可用服务,需自行处理异常标记 |
| ❹ 双保险机制 | 除本地时间外,结合外部 NTP 同步/Redis记录最大时间戳等机制 | 精度高、灵活、安全性强 | 系统复杂度增加,外部依赖(如 ZooKeeper/NTP) | 核心 ID 服务、订单中心、支付系统 |
🧠 总结建议
| 项目类型 | 推荐方案 |
|---|---|
| 核心金融/支付系统 | 双保险 + 标记机制 |
| 秒杀、日志等强一致 | 时间等待法 + 限流 |
| 弱一致服务 | 标记位/拒绝服务法 |
| 内部服务、低并发 | 拒绝服务法或 Redis校时 |
⛑ 类比比喻:时钟回拨就像员工误调闹钟提前上班,记录的工时会乱套。
4️⃣ 美团 Leaf:号段模式 ID
Leaf 提供两种模式:Segment 模式(数据库号段) 和 Snowflake 模式。
🧱Segment 模式:
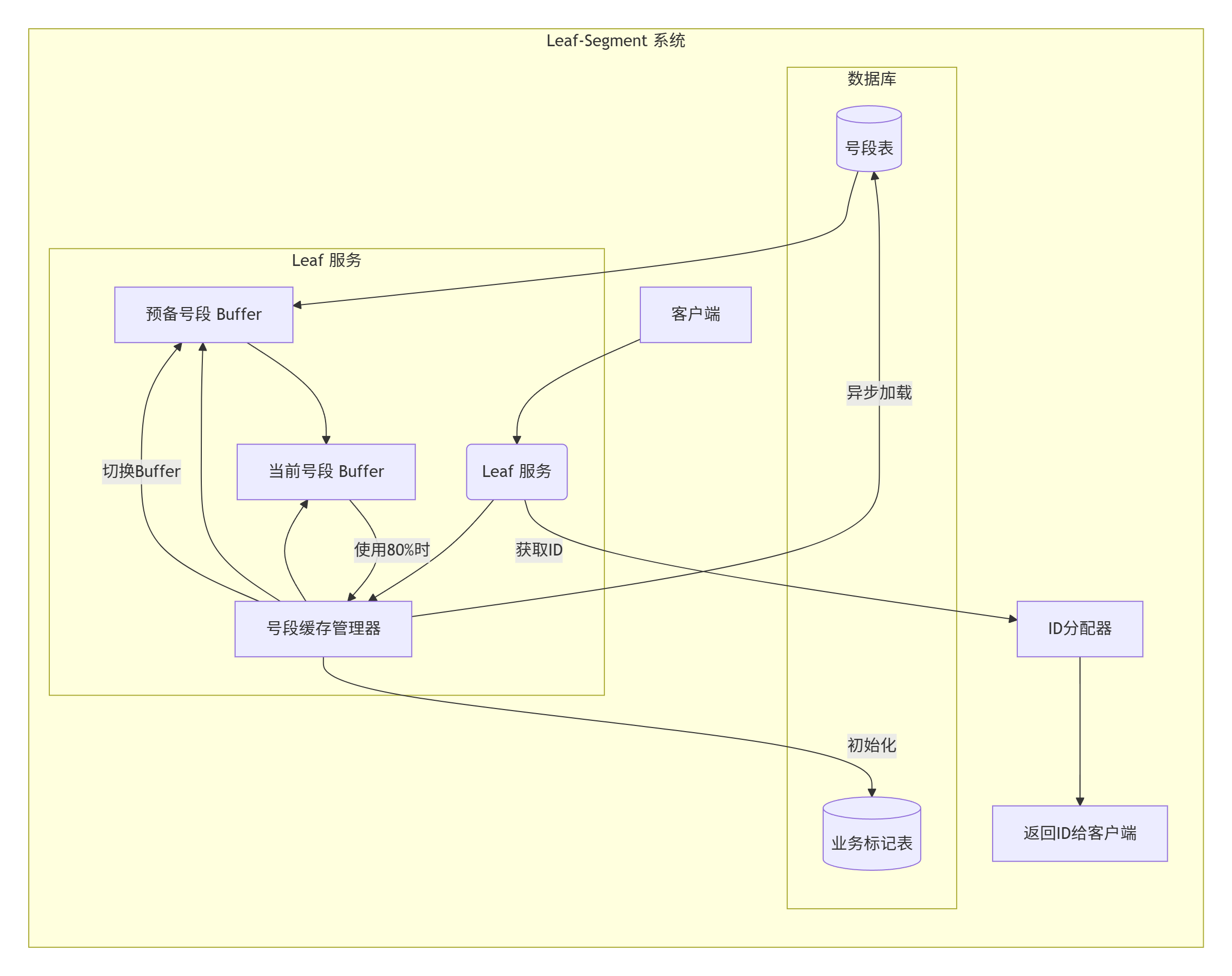
关键组件说明:
- 号段缓存管理器:管理两个Buffer的切换
- 当前号段Buffer:正在使用的ID段
- 预备号段Buffer:预加载的备用ID段
- 号段表:存储各业务的最大ID值
- 业务标记表:记录各业务的号段配置
- ID分配器:从当前Buffer分配ID
🧱Snowflake 模式:
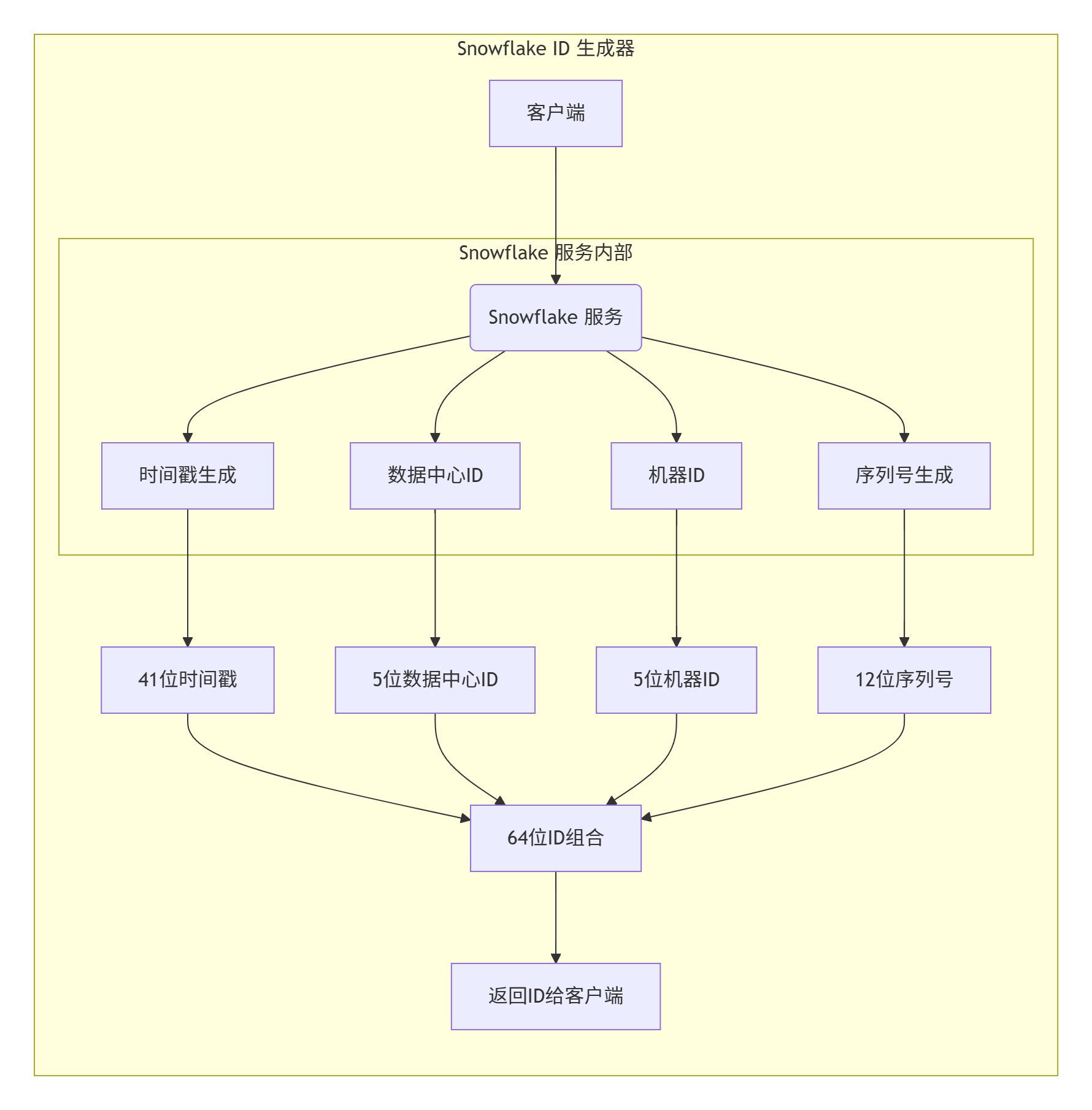
关键组件说明:
- 时间戳生成:精确到毫秒的当前时间
- 数据中心ID:区分不同机房/区域
- 机器ID:区分同一机房的不同机器
- 序列号:解决同一毫秒内的并发冲突
- ID组合:将四部分组合成64位整数
✅架构对比图示
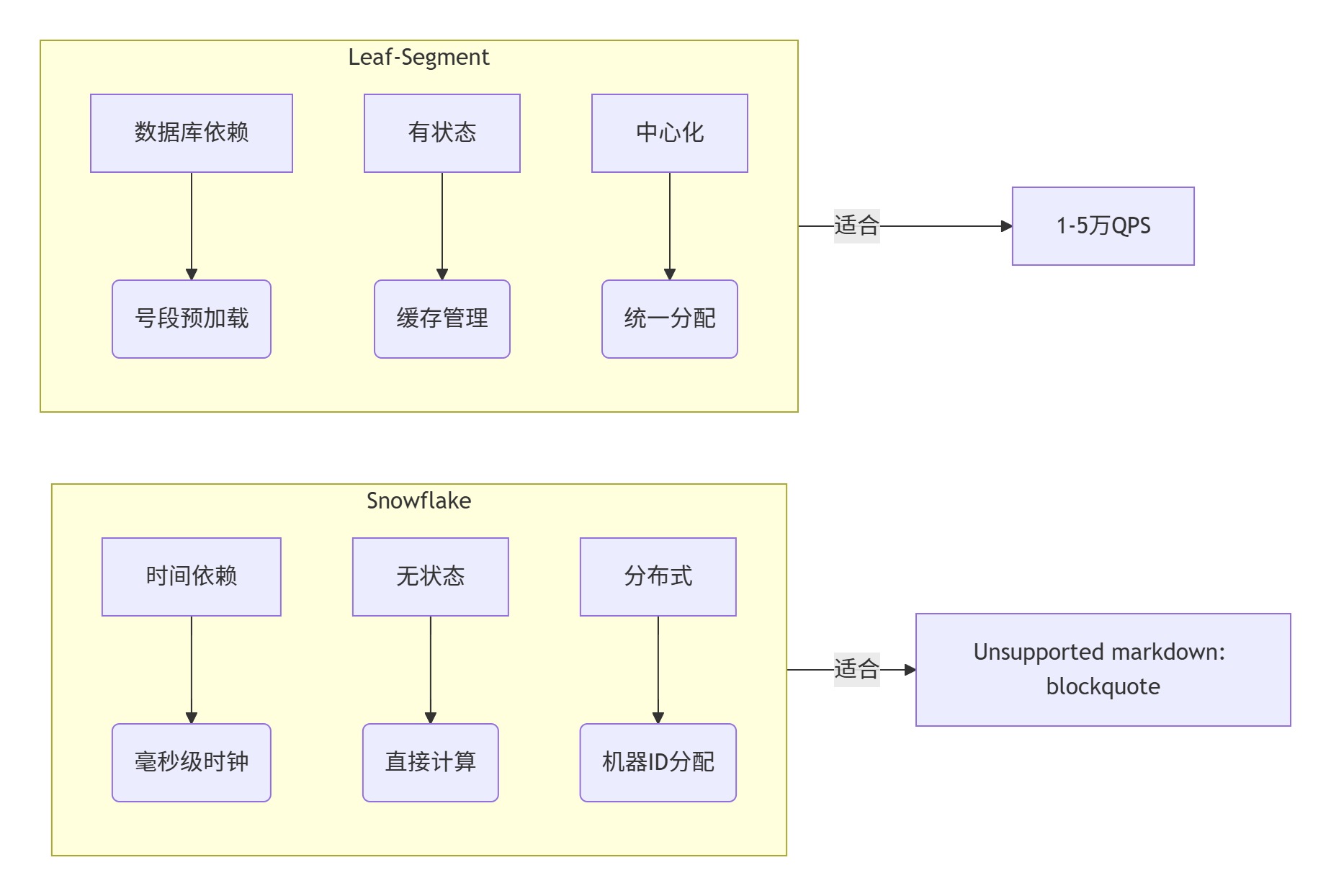
📌 对比总结
| 维度 | Segment 模式 | Snowflake 模式 |
|---|---|---|
| 中心化依赖 | ✅ 依赖 DB / Leaf Server | ❌ 去中心化,节点自生成 |
| 可用性(宕机影响) | ❗ Leaf Server 挂掉无法分配号段 | ✅ 节点独立运行 |
| 时钟安全性 | ✅ 不依赖系统时间 | ❗ 时钟回拨将导致重复 ID |
| ID 有序性 | ✅ 单调递增 | ✅ 趋势递增,但可能存在跳跃 |
| 实现难度 | ✅ 简单,易扩展 | ❗ 需要位运算、时钟安全等细节处理 |
| 跨语言支持 | ✅ Leaf 提供 HTTP 接口 | ❗ 需每种语言自行实现或提供 SDK |
| 最佳使用场景 | 单据号、订单号、分页要求有序的数据 | 日志链路、消息唯一标识、非强排序业务 |
🧠 推荐选型建议
| 业务场景 | 推荐方案 |
|---|---|
| 支付订单、发票号等需单调递增 | ✅ Segment 模式 |
| 日志追踪ID、MQ消息ID等 | ✅ Snowflake 模式 |
| 全局 ID 服务、集群稳定性高 | ✅ Snowflake 模式 |
| 分布式系统中异地双中心部署 | ✅ Segment + Redis |
5️⃣ 基于 Redis 的 ID 生成
通过 INCR 命令实现:
String key = "order:20230715";
Long id = redisTemplate.opsForValue().increment(key);
String fullId = "ORD" + LocalDate.now().format(DateTimeFormatter.BASIC_ISO_DATE) + id;✨优点
- 实现简单;
- 自带原子性;
- 支持 Redis 集群高可用。
⚠ 注意事项
- Redis 持久化(AOF + RDB)开启;
- 主从同步时 ID 不一致可能造成问题;
- 可以搭配 UUID/时间戳前缀降低冲突概率。
6️⃣ UUID 与数据库自增ID对比
| 特性 | UUID | 自增ID |
|---|---|---|
| 唯一性 | 高 | 本地唯一 |
| 可读性 | 差(无语义) | 好 |
| 排序性 | 无序 | 有序 |
| 分布式支持 | 天生支持 | 不支持 |
| 索引性能 | 差(随机分布) | 好(递增) |
| 应用场景 | 分布式服务标识、业务追踪 | 小型单体服务主键 |
推荐做法:
- 主键用分布式 Snowflake ID;
- 业务追踪用 UUID;
- 索引字段避免用 UUID!
7️⃣ 跨机房部署策略
在多 IDC、多区域部署时,应考虑 ID 生成器的:
- 数据中心ID 配置是否冲突;
- 时间戳是否同步;
- 网络分区是否影响写入。
🧠 推荐策略:
- 手动划分 dataCenterId 区段;
- 使用 ZooKeeper 分配 workerId;
- Leaf 主数据中心提供服务,其他副本可降级使用 Redis 方案;
- ID 服务尽量内嵌 SDK 本地生成,减少跨机房通信。
8️⃣ 实战落地建议
| 场景 | 推荐方案 |
|---|---|
| 订单、支付、日志链路 | Snowflake |
| 业务唯一编码(人可读) | Leaf + 前缀规则 |
| 用户ID/设备ID | Redis + ID段缓存 |
| 高一致性服务下 ID | 数据库号段/Leaf |
☁ 部署建议:
- 单独部署 ID 生成服务(Leaf/ID Center);
- 对外以 RPC 接口形式暴露;
- 接入方 SDK 本地缓存 ID;
- 加入监控 + 限流机制防雪崩。
🧩 总结与互动
一个优秀的分布式 ID 方案,应满足:
✅ 高可用,稳定生成;
✅ 趋势递增,适配数据库;
✅ 跨服务、跨机房、跨时区都不重;
✅ 不受时钟回拨影响;
💬 你在项目中用的是什么分布式 ID 方案?踩过哪些坑?欢迎评论区留言讨论交流!