AAAI-2025 | 同济大学面向嘈杂环境的音频视觉导航!BeDAViN:大规模音频-视觉数据集与多声源架构研究


- 作者:Zhanbo Shi, Lin Zhang, Linfei Li, Ying Shen
- 单位:同济大学计算机学院
- 论文标题:Towards Audio-visual Navigation in Noisy Environments: A Large-scale Benchmark Dataset and An Architecture Considering Multiple Sound-Sources
- 论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/33608
- 代码链接:https://github.com/ZhanboShiAI/ENMuS
主要贡献
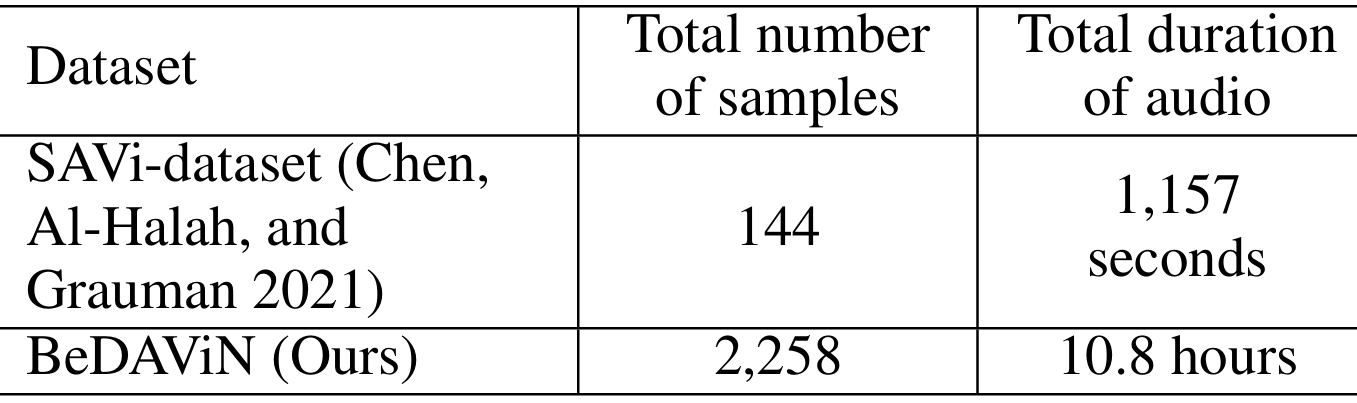
- 构建大规模基准数据集 BeDAViN:包含 2,258 个音频样本,涵盖 20 种声音事件类别和 4 种噪声类别,总时长 10.8 小时,是现有音频数据集的 33 倍以上,能够模拟多样化的多声源场景。
- 提出 ENMuS3^33 框架:针对多声源场景的具身导航框架,包含声音事件描述符和多尺度场景记忆Transformer两个关键组件,前者可提取目标声源的空间和语义特征,后者能有效跟踪目标对象,显著提升在嘈杂环境中的导航性能。
- 实验验证:在 BeDAViN 数据集上进行的大量实验表明,ENMuS3^33 在不同场景下的导航成功率和效率均大幅优于现有SOTA方法,成功率提升了一个数量级。
研究背景
- 具身导航的重要性:具身导航是具身智能(Embodied AI)的一个基本且关键的组成部分,要求自主智能体通过与未见过的环境交互来解决复杂的导航任务。近年来,具身导航技术被广泛应用于家庭服务、仓储和物流等领域。
- 现有研究的局限性:
- 数据集限制:现有的音频-视觉导航数据集样本有限,难以模拟多样化的多声源场景。
- 框架限制:大多数现有的导航框架是为单声源场景设计的,在多声源场景下的性能大幅下降。
- 多声源场景的挑战:现实世界中的环境通常存在多个声源和背景噪声,这对音频-视觉导航提出了更高的要求。
BeDAViN: 音频-视觉导航基准
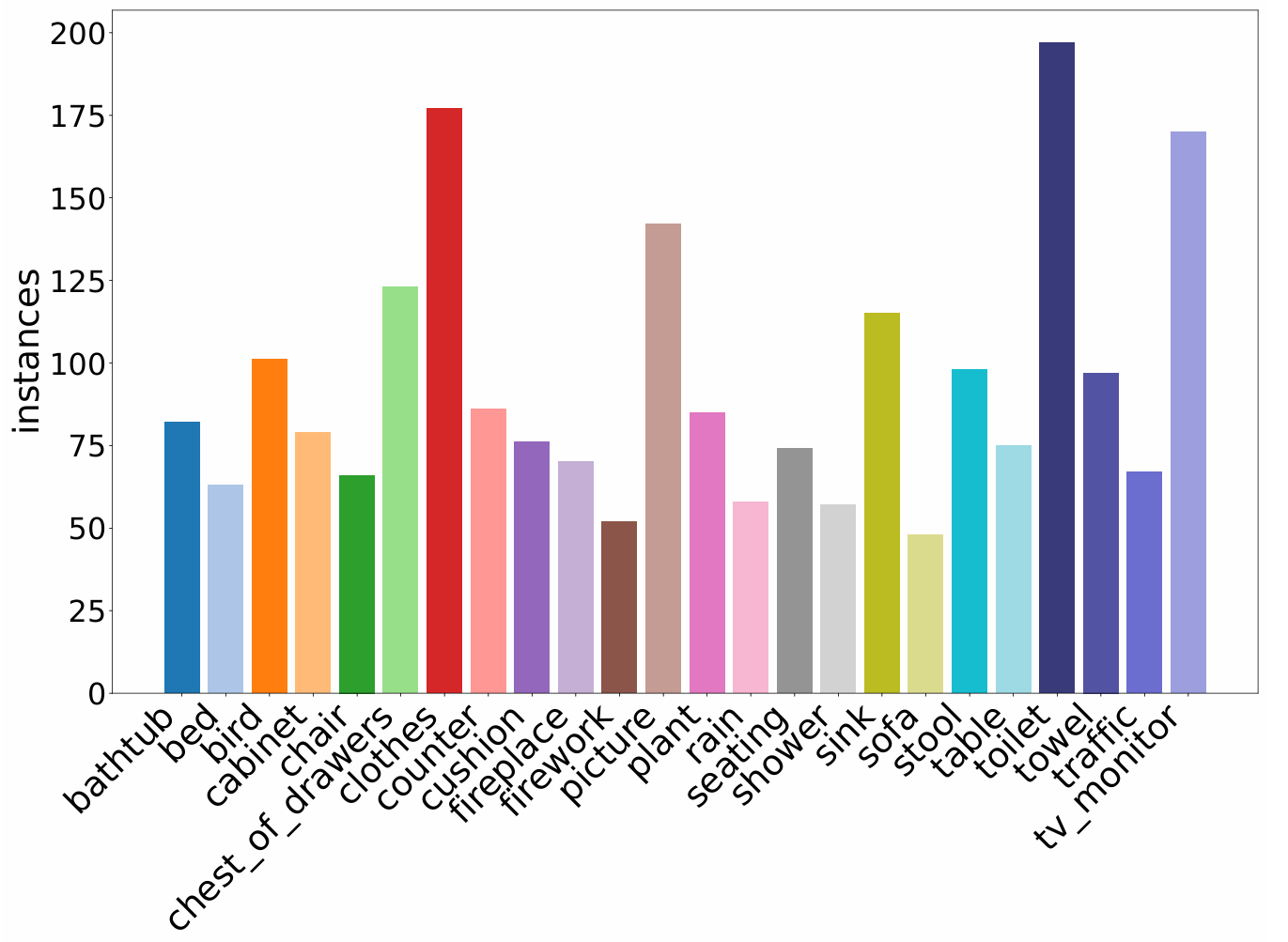
- 数据集规模:包含2258个音频样本,总时长10.8小时,覆盖24种声音事件类别(如电视声音、交通噪声、烤面包机声音等)。

- 数据收集:
- 手动录制:使用Tascam DR-40X设备在室内环境中录制了158个24位双声道音频文件。
- 公共数据集补充:从AudioSet和FSD50K等公共数据集中选取了与手动录制样本类似的音频片段,并从freesound.org补充了一些未被系统收集的类别(如毛巾、靠垫、植物等)的音频片段。
- 导航场景生成:生成了150万条导航场景,每个场景包含模拟导航过程的一组参数,如场景选择、智能体起始位置和旋转、目标物体位置、目标音频文件名和时长等。
ENMuS3^33: 多源具身导航框架
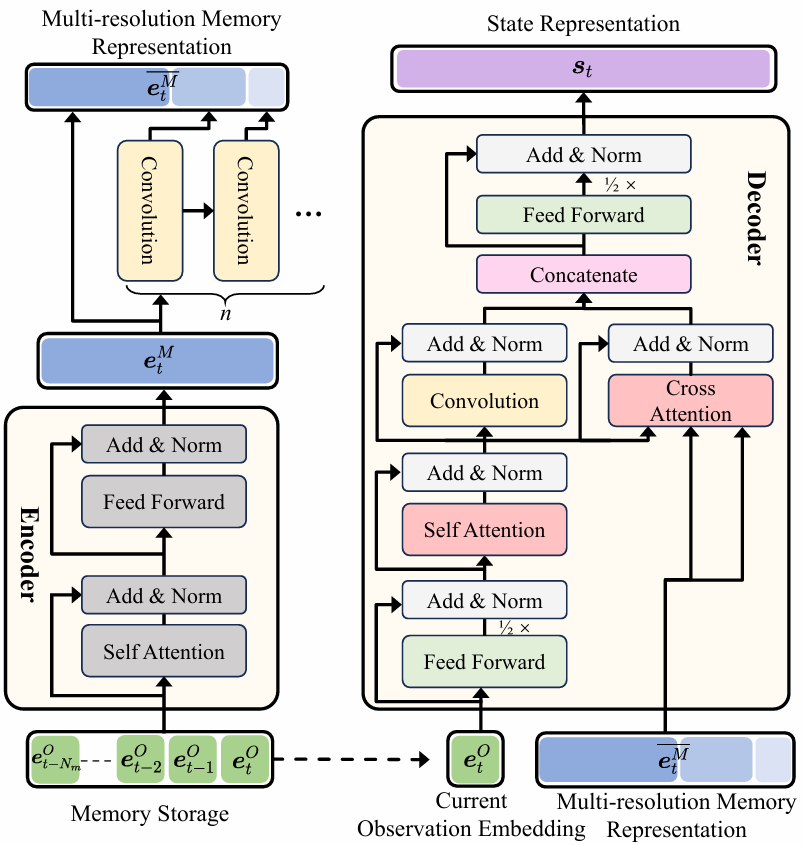
- 框架概述:ENMuS3^33框架通过观察编码器(Observation Encoder)将局部观察映射为观察嵌入(embedding),然后利用多尺度场景记忆Transformer构建多分辨率记忆表示,最终通过解码器预测智能体的下一步动作。
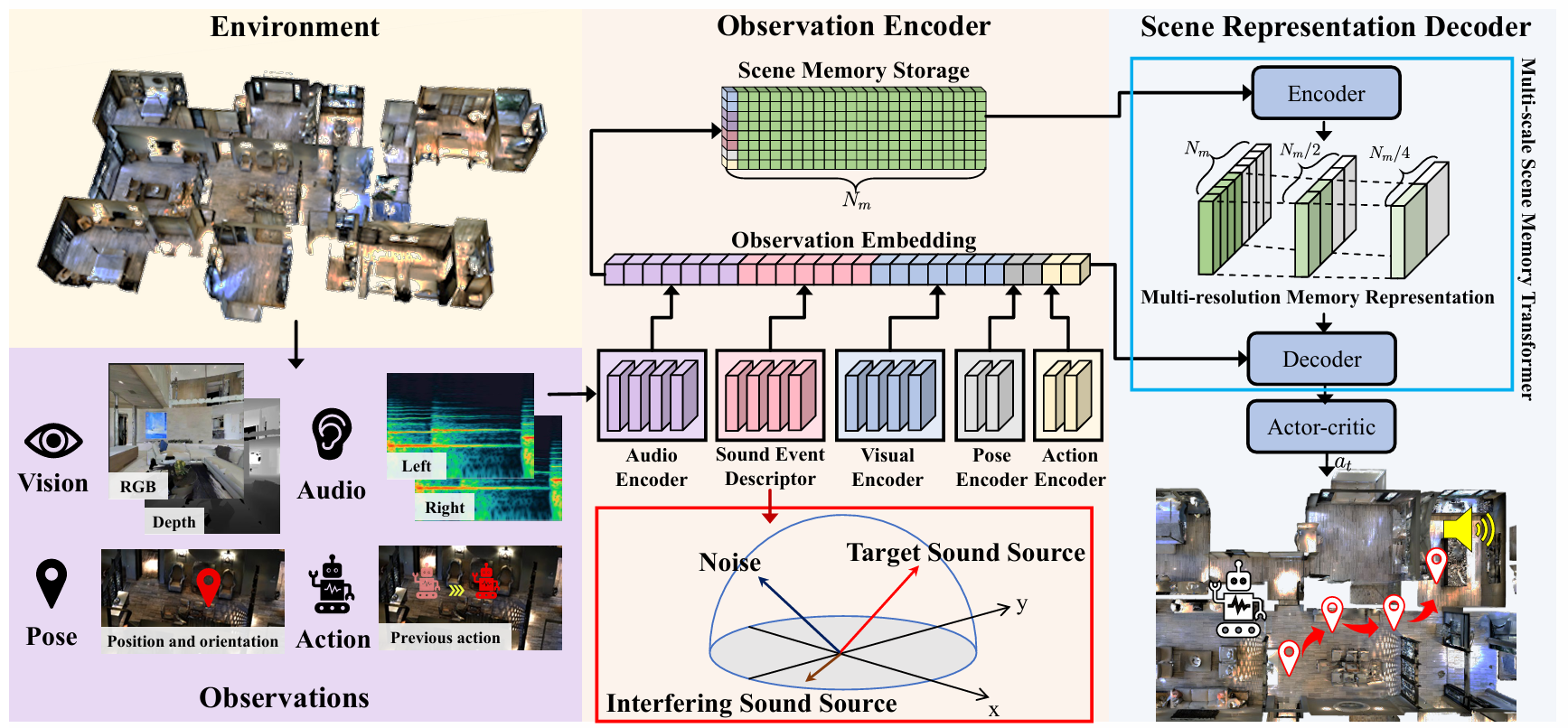
- 关键组件:
- 声音事件描述符:从双声道音频波形中提取目标声源的空间和语义特征,能够区分多个声源并确定目标声源的方向(DoA)。
- 多尺度场景记忆Transformer:利用全局交互和局部特征,提高在嘈杂环境中的导航效率。
- 观察编码器:
- 音频编码器:将双声道波形转换为左、右声道频谱图,计算双耳相位差(IPD)和双耳水平差(ILD),生成低级音频表示。
- 声音事件描述符:处理音频编码器的输出,生成类别级输出,包含周围活跃声源的估计类别及其方向。
- 视觉/姿态/动作编码器:使用ResNet生成视觉表示,使用线性网络生成姿态和动作的表示。
- 场景记忆存储:存储最近的NmN_mNm个场景观察,以便智能体利用历史信息进行长时导航任务。
- 场景表示解码器:通过多尺度场景记忆Transformer解码当前观察嵌入和场景记忆存储,预测智能体的下一步动作。
实验
- 实验设置:
- 环境和模拟器:采用 Matterport3D 虚拟室内场景作为训练和测试环境,修改 SoundSpaces 平台以添加干扰声音和背景噪声的生成流程。
- 场景配置:在三种场景下进行实验,分别是单声源场景(只有目标物体发声)、多声源场景(环境中存在多个类别的声音事件,特定类别的声音事件为目标声源)和嘈杂场景(基于多声源场景并添加持续的背景噪声)。测试结果在 10 个复杂程度不同的 Matterport3D 场景中取平均值,每个场景包含 100 个剧集。
- 评估指标:采用成功率(SR)、按路径长度加权的成功率(SPL)、按动作数量加权的成功率(SNA)以及剧集结束时到目标的平均距离(DTG)来评估不同音频视觉导航方案的性能。
- 基线方法:将 ENMuS3^33与随机策略、目标跟随策略、ObjectGoal 方法、Av-Nav 方法、SAVi 方法以及 SMT + Audio 方法进行比较,所有方法都使用相同的奖励函数和必要的相同输入。
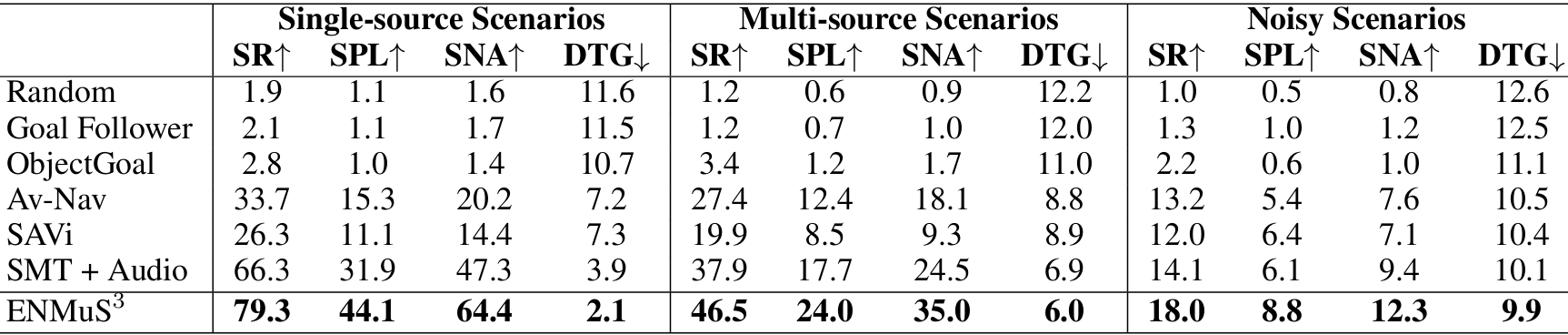
- 定量实验结果:
- 如表所示,ENMuS3^33在所有场景下的表现均显著优于其他方法。在单声源场景中,ENMuS3^33的成功率比现有SOTA方法高出 13.1%,在多声源场景和嘈杂场景中分别高出 7.1% 和 3.1%。
- 此外,ENMuS3^33在 SPL 和 SNA 指标上也有显著提升,表明其多尺度场景记忆Transformer能够利用全局交互和局部特征找到更短的路径,从而提高导航效率。
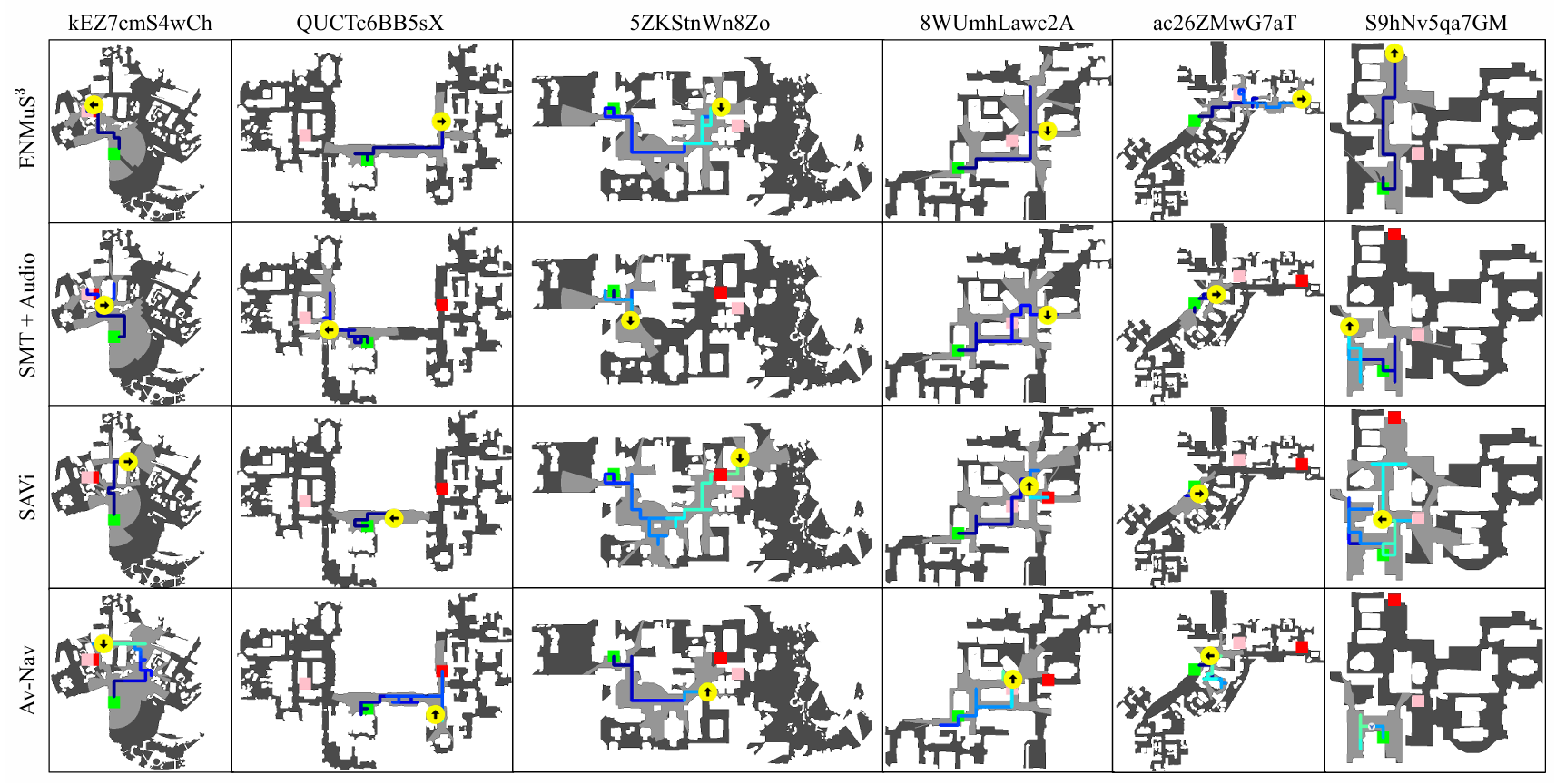
- 定性实验结果:
- 上图展示了 ENMuS3^33与其他方法在多声源场景下的导航轨迹。可以看出,ENMuS3^33能够以更高效的路径完成导航任务,例如在 S9hNv5qa7GM 场景中,ENMuS3^33几乎沿着最短路径到达目标,显示出其多尺度场景记忆Transformer在嘈杂环境中跟踪目标的强大能力。
- 在目标物体距离智能体初始位置较远的情况下,如 ac26ZMwG7aT 场景,ENMuS3^33 能够借助声音事件描述符成功到达目标,而其他方法则容易在起始点附近的区域停滞不前。
结论与未来工作
- 结论:
- 为了促进在嘈杂环境中的音频视觉导航,本研究引入了 BeDAViN 大规模基准数据集,并提出了 ENMuS3^33框架。
- BeDAViN 能够模拟不同声源配置的多样化场景,为在多声源环境中训练和测试智能体提供了支持。
- ENMuS3^33通过其声音事件描述符和多尺度场景记忆Transformer,显著增强了智能体在复杂嘈杂环境中定位和跟踪目标声源的能力。
- 未来工作:
- 由于现有音频视觉导航方法主要在仿真环境中开发,未来的研究将致力于将 ENMuS3^33部署到现实世界的应用中。
