Pixel Reasoner:通过好奇心驱动的强化学习激励像素空间推理
文章目录
- 速览
- 摘要
- 1 引言
- 2 问题表述
- 3 预热启动指令微调
- 4 好奇心驱动的强化学习
- 5 实验
- 5.1 主要结果
- 5.2 激励像素空间推理的关键因素
- 6 相关工作
- 7 结论
- 附录
- A 局限性
- B 好奇心驱动奖励的推导
- C 数据和训练细节
- C.1 视觉操作协议
- C.2 指令微调数据
- C.3 训练细节
- D 额外分析
- D.1 统计
- D.2 案例分析
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
滑铁卢大学 (University of Waterloo);香港科技大学 (Hong Kong University of Science and Technology, HKUST);中国科学技术大学 (University of Science and Technology of China, USTC);Vector 研究所 (Vector Institute)
arxiv’25’5
代码开源:https://tiger-ai-lab.github.io/Pixel-Reasoner/
速览
🤔动机
本研究旨在通过好奇心驱动的强化学习,使视觉–语言模型能够在像素空间中主动执行“放大”“选帧”等操作,突破依赖纯文本表示而无法标注关键视觉区域及捕捉微小物体的瓶颈,实现更精细的视觉推理。
🤨挑战
要让 MLLM 在推理中“再看一眼”视觉信息,需跨越两大挑战:
- 视觉操作零-shot 能力缺失:现有 VLM 无法直接执行新引入的“放大”“选帧”等视觉操作,必须通过精心设计的指令微调阶段来教授这些技能并保留模型的自我纠错能力;
- 学习陷阱:在微调后,由于视觉操作早期失败带来的负反馈较多,且大量查询并不严格依赖视觉操作,模型倾向于绕过这些尚未熟练的技能,导致像素空间推理能力培养中断。
🤩方法
为应对上述区域锚定学习与归因分配两大挑战,论文提出了两项关键性解决方案:
- 首先,构建了一个数据集,包含单遍轨迹(single-pass trajectories)和错误诱导自我纠正轨迹(error-induced self-correction trajectories)。其中单遍轨迹就是包含了裁剪和选帧这种视觉操作的图文思维链,自纠正轨迹就是故意引入一些错误操作,培养模型在面对意外输入或执行错误时,依然能够及时识别并纠正,增强其鲁棒性;
- 其次,使用单遍轨迹、错误诱导自我纠正轨迹和纯文本推理轨迹进行预热启动,就是SFT,这里需要注意的是,这篇论文是在这里进行了损失掩码(执行视觉操作的输出 token、自我纠正轨迹中标记为错误的视觉操作对应的 token);
- 最后,为打破模型尝试绕过视觉操作的循环,作者提出了一种受传统强化学习中好奇心驱动探索启发的奖励机制,通过对尝试像素空间操作的行为专门给予内在激励—而非仅依赖于对正确性的外在奖励—以抵消早期操作失败带来的负面反馈并持续促进模型对新兴视觉技能的探索。
这里的奖励项设计的挺好的,主要是一开始为了让模型愿意去调用工具,会给稍微多一些的奖励,当模型学的差不多了,又为了避免奖励劫持(就是模型一直去调用工具而不管准确性了),这时候就会少给或者不给奖励。
😮实验
实验上主要是做了与sota大模型的对比,其中分为不会调用工具的和会调用工具的模型,然后在消融实验那里分别证明了一下强化微调、好奇心、热启动与子纠正数据的有效性,我感觉从结果上来看,性能主要是由强化微调提升的,数据集倒是没有提多少,后面还给出了一些训练的曲线。
摘要
链式思考推理 (Chain-of-thought reasoning) 显著改善了大型语言模型 (LLMs) 在各领域的性能。然而,该推理过程仅局限于文本空间,限制了其在视觉密集任务中的有效性。为了解决这一限制,我们引入了像素空间推理 (reasoning in the pixel-space) 的概念。在这一新框架中,视觉-语言模型 (VLMs) 装备了一系列视觉推理操作,如放大 (zoom-in) 和选帧 (select-frame)。这些操作使 VLMs 能够直接检查、质询并从视觉证据中推断,从而增强视觉任务的推理保真度。在 VLMs 中培养此类像素空间推理能力面临显著挑战,包括模型最初能力的不平衡以及其对新引入像素空间操作的抗拒。我们通过两阶段训练方法来解决这些挑战。第一阶段在合成的推理轨迹上进行指令微调,以使模型熟悉新颖的视觉操作。随后,在强化学习 (RL) 阶段,我们利用一种由好奇心驱动的奖励机制来平衡像素空间推理与文本推理之间的探索。借助这些视觉操作,VLMs 可以与复杂视觉输入(如信息丰富的图像或视频)互动,以主动收集必要信息。我们证明该方法在各类视觉推理基准上显著提升了 VLM 性能。我们的 7B 模型 Pixel-Reasoner 在 V* 基准上取得了 84%,在 TallyQA-Complex 上取得了 74%,在 InfographicsVQA 上取得了 84%,标志着迄今所有开源模型中最高的准确率。这些结果凸显了像素空间推理的重要性及我们框架的有效性。
1 引言
最近的进展表明视觉-语言模型(VLMs)在开发复杂推理能力方面取得了显著进步。领先的模型如 OpenAI GPT4o/GPT-o1 [Hurst et al., 2024]、Jaech et al., 2024a、Gemini-2.5 [Team et al., 2023]、VL-Rethinker [Wang et al., 2025] 在各种多模态推理基准上表现优异,如 MathVista [Lu et al., 2023]、MMM U [Yue et al., 2024]、MEGA-Bench [Chen et al., 2024] 等。一种支撑这些最先进 VLMs 的常见范式是先处理多模态查询以提取相关线索,然后在纯文本格式下进行链式思考(CoT)推理 [Wei et al., 2022]。
尽管取得了成功,现有的文本推理范式存在内在局限:仅依赖文本标记来表达中间推理步骤会限制视觉-语言模型在视觉密集任务中可达到的深度和准确性。缺乏与视觉输入的直接交互──例如绘制线条或标记、突出显示区域或放大──阻碍了模型与信息丰富图像的互动。因此,VLMs 往往难以捕捉细粒度的视觉细节,包括微小物体、微妙的空间关系、嵌入的文本以及视频中的细腻动作。
这些局限性促使我们对 VLMs 在推理过程中如何更无缝地使用视觉模态进行根本性重新思考。这引出了我们的研究问题:
VLMs 是否能够更直接地在视觉模态内部执行推理步骤,将计算视觉操作作为行动来指导推理?
我们引入了像素空间推理的概念,提出了一种新范式:推理不仅限于口头化的格式,而是主动地将操作直接应用于视觉输入。模型不再单纯地将视觉观察转化为文本线索,而是在整个推理过程中积极操控并交互视觉信息——使用诸如“ZOOM-IN”或“SELECT-FRAME”等操作。这些视觉操作作为推理链中的关键步骤,使模型能够以更高保真度检查、质询并从视觉证据中推断。我们将此问题框定为开发一个配备一系列视觉操作的 VLM。该新框架涉及策略性地选择并将合适的视觉操作应用于视觉输入,逐步优化其理解、深化其推理并最终得出结论。为了灌输这种全新的像素空间推理能力,我们遵循常见的后训练范式:指令微调与强化学习 (RL)。然而,培养像素空间推理能力仍面临重大挑战。
首先,现有的 VLMs 在执行预定义视觉操作时表现出有限的零样本能力,因此需要细致的指令微调来建立对这些新视觉操作的基础理解。此初始训练阶段还必须保留模型固有的自我校正能力,从而为后续强化学习阶段的试错做好准备。
其次,经过预热的模型在其成熟的文本推理能力与新兴的像素空间推理能力之间存在显著差距,这造成了阻碍像素空间推理有效习得的“学习陷阱”。一方面,模型在视觉操作上的初始不熟练会比在文本推理上获得更多负反馈。另一方面,大量训练查询可能并不严格需要视觉操作,使得模型能够绕过这些尚未充分发展的技能。这些因素都困住了像素空间推理的培养,导致利用视觉操作并提升像素空间推理的努力过早停止。
为了应对这些挑战,我们的方法结合了预热启动指令微调阶段和强化学习阶段。对于指令微调,我们合成了 7,500 条推理轨迹,以促进对视觉操作的熟练掌握和自我校正规则能力的培养。在这一细致的预热指令微调之后,我们的 RL 方法利用一种好奇心驱动的奖励机制,在像素空间推理的探索与利用之间取得平衡,以激励像素级推理。RL 阶段从多个公开图像和视频数据集 [Feng et al., 2025]、[Xu et al., 2025] 中收集了另 7,500 个示例。
我们的最终模型 Pixel-Reasoner 构建于 Qwen2.5-VL-7B 之上 [Bai et al., 2025],能够在多个视觉推理基准(使用信息丰富的图像/视频)上展现显著提升:如 V* [Wu and Xie, 2024]、TallyQA [Acharya et al., 2019]、MVBench [Li et al., 2024a] 和 InfographicsVQA [Mathew et al., 2021]。在这些基准上,Pixel-Reasoner 展示了已知最佳的开源性能,甚至超越了专有模型,如 Gemini-2.5-Pro [Team et al., 2024a] 和 GPT-4o [Hurst et al., 2024]。我们进一步进行了全面的消融研究,以深入了解我们的框架如何有效地培养像素空间推理能力。我们的贡献如下所示:
- 我们首次提出了像素空间推理的概念。
- 我们识别出了在培养这一新颖推理能力时的“学习陷阱”。
- 我们提出了一种新颖的两阶段后训练方法,包括细致的指令微调阶段和好奇心驱动的强化学习阶段。
- 我们在视觉密集型基准任务中,通过像素空间推理实现了最先进的结果。

2 问题表述
我们引入像素空间推理(pixel-space reasoning),这是一种新范式,使模型能够将操作直接应用于视觉输入,而不仅仅依赖文本推理。形式化地,考虑一个视觉-语言查询 x=[V,L]x = [V, L]x=[V,L],其中 VVV 表示视觉输入(如图像或视频),LLL 为文本查询。模型 πθ\pi_\thetaπθ 通过在像素和文本空间中迭代推理构建解答 y=[y1,…,yn]y = [y_1, \dots, y_n]y=[y1,…,yn]。在每个步骤 ttt,模型根据初始查询 xxx 和所有先前的推理步骤 Yt−1=[y1,…,yt−1]Y_{t-1} = [y_1, \dots, y_{t-1}]Yt−1=[y1,…,yt−1] 生成推理段 yt∼πθ(⋅∣x,Yt−1)y_t \sim \pi_\theta(\cdot \mid x, Y_{t-1})yt∼πθ(⋅∣x,Yt−1)。与主要的文本推理范式不同,像素空间推理允许每个推理步骤 yty_tyt 为下列两种类型之一:
- 文本思考(Textual Thinking):纯在文本领域中进行推理的步骤,如计算某个方程或利用领域知识得出结论等。
- 视觉操作(Visual Operations):激活视觉操作以直接操控或从视觉输入中提取信息的步骤。视觉操作 yty_tyt 涉及调用预定义函数 fff,并产生执行结果 et=f(yt)e_t = f(y_t)et=f(yt)。例如,模型可以生成 yty_tyt 来触发一个带有指定参数(如
"target_frame")的选帧操作 fSFf_{SF}fSF,以检索特定帧的视觉令牌 ete_tet。随后,将推理步骤更新为 yt←concat(yt,et)y_t \leftarrow \mathrm{concat}(y_t, e_t)yt←concat(yt,et),将执行结果 ete_tet 纳入后续推理。
该迭代推理过程在生成指定的结束标记时终止。我们的目标是通过强化学习 (RL) 培养像素空间推理能力,旨在优化视觉-语言模型 (VLM) 策略 πθ\pi_\thetaπθ,以最大化在数据集 D\mathcal{D}D 上的期望奖励:
maxθE[r(x,y)∣x∼D,y∼πθ(y∣x)]\max_\theta \mathbb{E}\bigl[r(x,y)\mid x\sim \mathcal{D},\,y\sim \pi_\theta(y\mid x)\bigr] θmaxE[r(x,y)∣x∼D,y∼πθ(y∣x)]
r(x,y)r(x,y)r(x,y) 的一种常见做法是采用二元正确性奖励,用于评估给定查询 xxx 的生成解答 yyy 的正确性 [DeepSeek-AI et al., 2025;Liu et al., 2025]:
r(x,y)={1,如果解答 y包含对查询 x的正确答案,0,否则.r(x,y) = \begin{cases} 1, & \text{如果解答 } y \text{ 包含对查询 } x \text{ 的正确答案},\\ 0, & \text{否则}. \end{cases} r(x,y)={1,0,如果解答 y 包含对查询 x 的正确答案,否则.
在本工作中,我们关注两类视觉输入:图像和视频。我们特别考虑两种视觉操作:用于检查目标图像指定区域细节的 ZOOM-IN,以及用于分析视频序列中特定帧的 SELECT-FRAME。有关这些视觉操作的详细协议,详见附录。
3 预热启动指令微调
我们的目标是利用现有视觉-语言模型(VLMs)培养一种新颖的像素空间推理范式。然而,诸如 Qwen2.5-VL-Instruct 等经过指令微调的模型在执行新颖视觉操作时表现出有限的零样本能力(如附录分析所示),这很可能是因为这些操作在标准训练数据中缺失。为了为后续强化学习阶段中视觉操作的应用奠定基础,本节介绍我们的数据筛选与指令微调方法。
收集种子数据集
我们设计的数据整理流程旨在收集高质量的像素空间推理轨迹。这些轨迹将作为策略的专家示范,展示视觉操作的有效利用。因此,我们首先选取了三个数据集:SA1B [Kirillov et al., 2023]、FineWeb [Ma et al., 2024] 和 STARQA [Wu et al., 2024]。这些数据集涵盖多样的模态和内容,包含具有丰富分割掩码的自然场景、多样的网页以及需要情境化推理的真实世界视频。在这三个数据集中,高度的视觉复杂性为细粒度分析提供了丰富的视觉信息,其显式标注也作为轨迹合成的重要参考视觉线索。有关这些数据集的详细描述,请参见附录。
定位参考视觉线索
为了确保视觉操作在解决视觉-语言查询时确实必要,我们选择或合成了明确需要在丰富视觉信息中定位细粒度视觉线索的查询。FineWeb 和 STARQA 数据集已提供与参考视觉线索配对的视觉-语言查询及其答案。对于 SA1B 数据集,我们首先利用 GPT-4o 识别图像中的特定目标视觉细节,如小物体或特定属性。随后,我们提示 GPT-4o 根据所识别的细节和对应图像生成自然语言查询,构建出需要定位该特定线索的细粒度视觉问题。
合成专家轨迹
基于已整理的需要细粒度视觉分析的视觉–语言查询,我们随后使用 GPT-4o 合成专家轨迹。如图 3(a) 所示,我们观察到直接从 GPT-4o 蒸馏有时会产生“绕过轨迹”(bypassing trajectories)。在这些情况下,GPT-4o 可能会绕过错误的视觉操作,仅通过其文本推理能力得出正确的最终答案。这样的轨迹存在误导策略的风险,因为它忽视了执行视觉操作时可能出现的问题结果。
为了缓解此问题并确保对合成轨迹的完全控制,我们采用基于模板的合成方法。如图 3(b) 所示,该模板将像素空间推理轨迹结构化为以下序列:对整个视觉输入的初步分析、触发特定视觉操作以提取细粒度细节、对这些细粒度视觉线索的后续分析,最终得出答案。要根据此模板合成轨迹,我们利用与每个视觉–语言查询关联的参考视觉线索。首先,我们提示 GPT-4o 生成总结整个视觉输入的文本描述;然后,利用该参考视觉线索,我们再次提示 GPT-4o 针对该线索进行更详细的文本分析。通过将这些文本思考片段与针对参考视觉线索的视觉操作相结合,我们获得了能够有效交错文本推理与所需视觉操作的像素空间推理轨迹。

除了帮助策略理解视觉操作有效利用的单遍轨迹(single-pass trajectories)之外,我们还合成了错误诱导的自我纠正轨迹(error-induced self-correction trajectories)。这些措施旨在保持并增强该策略在执行过程中对意外输入或错误做出恰当反应的能力。如图 4 所示,我们通过故意选择不正确或不当的视觉线索(例如无关的视频帧或过大的图像区域)来合成此类轨迹,以引导至正确答案。随后,我们在引入正确的参考视觉线索之前,插入针对这些干扰视觉线索的视觉操作和文本思考片段,从而模拟错误诱导轨迹中的自我纠正行为。

预热启动指令微调
我们在训练数据中包含两类主要的像素空间推理轨迹:单遍轨迹(single-pass trajectories)和错误诱导的自我纠正轨迹(error-induced self-correction trajectories)。同时,对于不需要细粒度视觉分析的视觉-语言查询,我们也加入了文本推理轨迹。这种混合数据构成使得策略能够在必要时有选择地运用像素空间推理。我们采用标准的监督式微调(Supervised Fine-Tuning, SFT)损失进行训练。然而,我们会对以下两类token应用损失掩码(loss masks):一是代表视觉操作执行输出的token,二是在自我纠正轨迹中专门标记为错误的视觉操作所对应的token。对这些错误操作进行掩码,可以防止策略学习去执行不正确的动作。
250710:这里感觉不太理解啊,代表视觉操作执行输出的token,是指那些 ”我要进行放大操作,bbox[]“ 或者是 ”执行视觉操作后返回的图像的内容,然后编码为了token,但是这部分不是模型需要输出的“ 吗,如果是这样的话,我感觉模型也要学一下吧?还有就是你不是专门想让模型去学自纠正吗,为什么还要掩码,掩码了还能学到吗?
250710:好像有一种可以说的通的,就是那些错误的操作作为上下文,但是不参与反向传播的梯度计算,目的是为了鼓励模型一次性就能预测正确的操作,而不是先预测一个错误的,再纠正和回来。那就会有一个疑问,既然都不参与反向传播了,那为什么还专门构建这个错误示例,模型怎么学到自纠正的能力?其实很简单,这部分虽然不参与梯度计算,但是它前向传播时是作为上下文的,目的是为了让模型在之后预测的时候,万一第一个操作调用错了,它根据这个上下文可以自我纠正会正确的以得到最终答案是正确的。简而言之就是,让模型遇到这种错误操作的上下文时可以有自我纠正的能力。
4 好奇心驱动的强化学习
预热启动模型通常在能力上存在差距:成熟的文本推理与新兴的像素空间推理之间的不平衡。这种内在失衡造成了“学习陷阱”,阻碍了像素空间推理的发展,其来源有两个协同问题。首先,模型在视觉操作上的初始掌握有限,常常导致失败或错误输出,从而比基于文本的推理获得更多负面反馈。其次,大量训练查询并不严格要求视觉处理即可得出正确答案,使模型能够忽略视觉操作的结果或回退到更擅长的文本推理。这种交互作用助长了恶性循环:初始失败削弱了继续尝试的意愿,导致探索和掌握视觉操作的努力过早中止。如图 5 所示,当在没有适当激励的情况下使用标准强化学习训练预热模型时 [DeepSeek-AI et al., 2025;Wang et al., 2025],策略会学会绕过这些新兴的视觉操作。
为打破这一循环,我们提出了一种好奇心驱动的奖励机制,以激励对像素空间推理的持续探索,其灵感来源于传统强化学习中的好奇心驱动探索 [Pathak et al., 2017]。该好奇奖励不再仅依赖于对正确性的外在奖励,而是专门激励尝试像素空间操作的行为。通过对这类主动实践给予内在奖励,我们旨在增强模型新生的视觉技能,对抗早期操作失败及其带来的负面反馈所导致的探索消极。这类似于孩子出于好奇反复尝试某个困难的动作任务,从每次尝试中学习,而不是立即退回到更简单、已掌握的技能。
具体地,我们将该目标形式化为受约束的优化问题。设 1PR(y)\mathbf{1}_{PR}(y)1PR(y) 为响应 yyy 是否使用像素空间推理的指示函数,nvo(y)n_{vo}(y)nvo(y) 表示视觉操作的数量。目标是最大化
maxθE[r(x,y)∣x∼D,y∼πθ(y∣x)](1)\max_\theta \mathbb{E}\bigl[r(x,y)\mid x\sim \mathcal{D},\,y\sim \pi_\theta(y\mid x)\bigr] \tag{1} θmaxE[r(x,y)∣x∼D,y∼πθ(y∣x)](1)
并满足以下约束
RaPR(x)=˙E[1PR(y)∣y∼πθ(y∣x)]≥H,nvo(y)≤N(2)\begin{aligned} & RaPR(x)\dot{=}\mathbb{E}\bigl[\mathbf{1}_{PR}(y)\mid y\sim \pi_\theta(y\mid x)\bigr]\ge H, & n_{vo}(y)\le N \end{aligned} \tag{2} RaPR(x)=˙E[1PR(y)∣y∼πθ(y∣x)]≥H,nvo(y)≤N(2)
其中,第一个约束涉及像素空间推理率(Rate of Pixel‐space Reasoning,简称 RaPR,发音“rapper”),即对查询 xxx 的所有执行轨迹 yyy 上 1PR(y)\mathbf{1}_{PR}(y)1PR(y) 的期望值。我们要求该比率不低于预设阈值 HHH,以鼓励策略在大量查询上持续尝试像素空间推理,作为探索这一较不熟悉推理路径的指导原则。第二个约束对任意单次响应中的视觉操作数量施加上限 NNN,确保在鼓励探索的同时保持计算效率,避免因过度或耗时的视觉处理而导致响应过于复杂或耗时。
250710:那个“点”标在等号上,表示这并不是一个普通的“相等”关系,而是一个定义式(definitional equality)。
该受约束的优化问题可以通过拉格朗日松弛(Lagrangian Relaxation)转化为无约束问题 [Lemaréchal, 2001],从而得到单一的奖励函数。该技术常用于受约束的强化学习 [Achiam et al., 2017;Wang et al., 2022;2023]。转换后得到如下修正奖励函数 r′(x,y)r'(x,y)r′(x,y),详见附录:
r′(x,y)=r(x,y)+α⋅rcuriosity(x,y)+β⋅rpenalty(y),(3)r'(x,y) = r(x,y) + \alpha \cdot r_{\text{curiosity}}(x,y) + \beta \cdot r_{\text{penalty}}(y), \tag{3} r′(x,y)=r(x,y)+α⋅rcuriosity(x,y)+β⋅rpenalty(y),(3)
其中
rcuriosity(x,y)=max(H−RaPR(x),0)⋅1PR(y),(4)r_{\text{curiosity}}(x,y) = \max\bigl(H - \mathrm{RaPR}(x),\,0\bigr)\cdot \mathbf{1}_{PR}(y), \tag{4} rcuriosity(x,y)=max(H−RaPR(x),0)⋅1PR(y),(4)
rpenalty(y)=min(N−nvo(y),0).(5)r_{\text{penalty}}(y) = \min\bigl(N - n_{vo}(y),\,0\bigr). \tag{5} rpenalty(y)=min(N−nvo(y),0).(5)
修正后的奖励函数包含两个附加项。第一个项 rcuriosity(x,y)r_{\mathrm{curiosity}}(x,y)rcuriosity(x,y) 是好奇心机制的核心。它提供内在奖励,直接鼓励模型满足对像素空间操作的“好奇心”,特别是在该查询的像素空间尝试历史较少时。类似于婴儿对未知环境或新奇交互的探索,当像素空间推理触发率 RaPR(x)\mathrm{RaPR}(x)RaPR(x) 低于目标阈值 HHH 时,该项会为响应 yyy 的像素空间推理行为提供奖励。此好奇心奖励有效降低了尝试视觉操作的激活能,使模型更加“好学”并愿意探索不那么确定的推理路径。
250710:我感觉这里的好奇心奖励设计的不错,🤩max(H−RaPR(x),0)\max\bigl(H - \mathrm{RaPR}(x),\,0\bigr)max(H−RaPR(x),0) 🤩当模型一开始可能进行像素空间推理的少,所以一开始给的好奇心奖励也很高,后期模型掌握的不错了,我就不需要你额外的好奇心了,因为你已经学到大概什么时候需要像素空间推理了。
第二个项 rpenalty(y)r_{\mathrm{penalty}}(y)rpenalty(y) 作为响应级的效率惩罚,通过考虑视觉操作数量 nvo(y)n_{vo}(y)nvo(y) 相对于期望上限 NNN 来惩罚冗余的视觉操作。
系数 α≥0\alpha \ge 0α≥0 和 β≥0\beta \ge 0β≥0 是非负的拉格朗日乘子。这些乘子可以自动调优,例如通过对偶梯度下降 [Bishop and Nasrabadi, 2006;Wang et al., 2020],也可以设置为预定义的超参数 [Wang et al., 2022]。在我们的实验中,为简便起见,我们采用了后者方法。我们在附录中给出了具体示例,以说明这些超参数如何反映我们对策略的期望属性。
该奖励方案提供了一种动态机制,能够在训练过程中自动调节探索奖励。如图 6 所示,随着策略在像素空间推理中不断探索,好奇心奖励会自然减弱。这防止了策略“奖励劫持”——即过度依赖探索奖励而忽视最终正确性。

5 实验
本节首先概述训练和评估设置,然后检验像素空间推理的有效性,并研究培养像素空间推理的关键因素。
训练数据与评估设置
利用第 3 节中描述的数据整理流程,我们汇集了一个包含 7,500 条轨迹的数据集,用于预热启动指令微调。该数据集包括使用 GPT-4o 合成的 5,500 条像素空间推理轨迹,涵盖图像、网页和视频等领域。同时,我们还加入了 2,000 条文本空间推理轨迹,以平衡视觉操作的使用。在强化学习阶段,我们从我们的 SFT 数据集、InfographicVQA [Mathew et al., 2021] 以及公开可用的数据集 [Xu et al., 2025;Wu et al., 2024] 中构建了 15,000 个查询。有关数据集组成的详细情况,请参见附录。
我们使用贪心解码,在四个具有代表性的多模态基准上评估了我们的模型及其他基线:TallyQA、V*、InfographicVQA 和 MVBench。该组合涵盖了从细粒度目标识别到静态与动态场景下的高层次推理的多种视觉理解任务。具体而言,V* (V-Star) [Wu and Xie, 2024] 评估多模态大语言模型(MLLMs)处理高分辨率、视觉复杂图像并关注细粒度视觉细节的能力;TallyQA [Acharya et al., 2019] 包含需要对物体数量进行推理的问题,通常要求模型在复杂场景中定位、区分并统计物体;MVBench [Li et al., 2024a] 是一项综合基准,旨在评估 MLLMs 在 20 个具有挑战性的视频任务中的时序理解能力,需超越静态图像分析进行推理;InfographicVQA [Mathew et al., 2021] 评估模型理解融合文本与视觉内容的复杂信息图图像(包括图表、示意图和标注图像)的能力。要在该基准上取得成功,模型必须解析布局、读取嵌入文本并将视觉元素与语义意义相链接。
比较模型与实现
我们对比了多种不同类别的模型:
-
不使用工具的模型:我们包括 GPT-4o [Hurst et al., 2024]、Gemini-2.0-Flash [Team et al., 2024b] 和 Gemini-2.5-Pro [Team et al., 2024a]。这些模型无法访问外部工具,仅通过链式思考回答问题。我们还包括 Owen2.5-VL [Bai et al., 2025] 和 Gemma3 [Team et al., 2025],以展示通用 VLM 的性能。此外,我们还与基于 RL 的 VLM 模型 Video-R1 [Feng et al., 2025] 进行比较,因为其算法与我们相似。我们还包含 LongLlaVA [Wang et al., 2024],因其旨在扩展图像输入以处理高分辨率图像(V*)和长视频序列(MVBench)。
-
使用工具的模型:我们包括 Visual Sketchpad [Hu et al., 2024a],该方法赋能 GPT-4o 使用如 zoom-in、depth 等多种工具;Instruction-Guided Visual Masking [Zheng et al., 2024],用于在给定图像中高亮目标区域;以及 Visual-Program-Distillation (VPD) [Hu et al., 2024b],旨在将工具推理蒸馏到闭源 VLM(如 PaLI)中。这些模型主要针对 V* 基准。我们还包括 SEAL [Wu and Xie, 2024](原 V* 基准论文提出),该方法利用视觉引导搜索工具增强高分辨率图像理解。
Pixel-Reasoner 在 8 × A800 (80G) GPU 上进行训练,分别使用 Open-R1 与 OpenRLHF 完成指令微调和强化学习阶段。我们采用带选择性样本中继以应对优势消失问题的 GRPO [DeepSeek-AI et al., 2025;Wang et al., 2025]。训练细节见附录,我们也将开源代码、模型和数据以支持可复现性。
5.1 主要结果
表 1 显示,Pixel-Reasoner 在所有四项基准上取得了开源模型中的最高成绩。值得注意的是,作为仅有 7B 参数的模型,Pixel-Reasoner 不仅在所有基准上超越了诸如 27B Gemma3 等参数远大的开源模型,还击败了依赖外部工具的专项模型(如 IVM-Enhance (GPT-4V))。此外,Pixel-Reasoner 的卓越性能还体现在超越领先的专有模型上:在 V*-Star 基准上以 84.3 相较于 79.2 的成绩领先 Gemini-2.5-Pro 5.1 个百分点,并在所有列出模型中取得整体最高分。我们观察到强化学习(RL)训练对实现这一优异结果至关重要。我们的消融模型 “Warm-Start Model (w/o RL)” 在多个基准上的表现均不及原始 Qwen2.5-VL 检查点;经过 RL 训练后,其性能飙升至最先进水平。这反映了 RL 训练在培养像素级推理能力方面的必要性。
250710:这里就挺有意思的,说明这篇论文所提的方法挺有效果的,而VLM3^33那篇主要是用数据集提的性能。
该性能表现进一步强调了我们所提出的像素空间推理范式的巨大潜力。当将 Pixel-Reasoner 与消融基线 “RL w/o Curiosity” 和 “RL w/o Warm-Start” 进行比较时,这一潜力尤为明显。由于激励不足且在使用视觉操作方面熟练度有限,这些基线最终退回到文本空间推理,导致在各基准上平均性能下降 2.5 个百分点。这些实证结果验证了像素空间推理的有效性——通过使模型主动参与视觉操作,这一新推理范式促进了更精确的视觉理解,从而增强了推理能力。
250710:但是又感觉这个消融数据不是很合理啊,(RL w/o Correction-Data)他没有那个自纠正数据性能下降那么多,但是这里为什么又不讲,而且单从数据上来看,自纠正数据比设计的好奇心奖励更有用,但是自修正数据不是用于第一阶段热启动吗,为什么它比 (RL w/o Warm-Start) 的影响还要大,这只是一部分数据,而且热启动里面也会用到自纠正数据,就很不合理啊。

5.2 激励像素空间推理的关键因素
本节探讨通过强化学习 (RL) 培养像素空间推理的两个关键因素:首先,策略在使用视觉操作方面的熟练度为后续 RL 阶段奠定基础;其次,激励机制在 RL 过程中鼓励采用像素空间推理的作用。为了深入理解表 1 中的结果,我们分析了不同基线的训练动态,如图 7 所示。具体来说,左侧面板展示了训练 rollout 中采用像素空间推理策略的比例;中间面板表明了执行视觉操作时的错误率;右侧面板比较了两种推理范式的预期正确率,突出显示了两者随训练时间变化的能力差异。此外,附录提供了绕过像素空间推理的轨迹示例,以阐明所谓的“学习陷阱”。
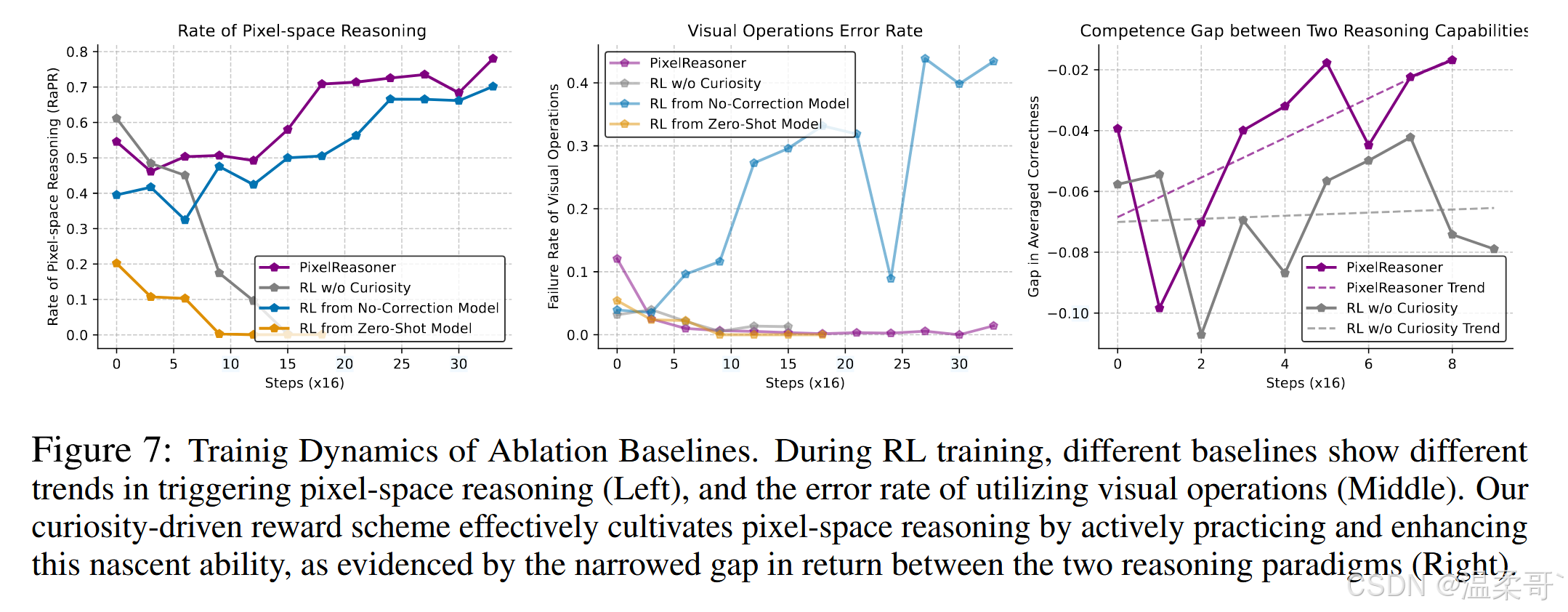
有效利用视觉操作需要指令微调
一个关键发现是,精细的预热启动指令微调对于提升策略对视觉操作的掌握及其自我纠正能力至关重要。为验证这一点,我们分析了三种不同指令微调模型的 RL 训练动态:
- 预热启动模型 (Warm-Start Model):经历了我们提出的预热启动指令微调阶段。
- 无自我纠正模型 (No-Correction Model):仅使用单遍专家轨迹进行指令微调,但不包含错误诱导的自我纠正轨迹。
- 零样本模型 (Zero-Shot Model):Qwen2.5-VL-Instruct,通过零样本提示获取可用的视觉操作。
-
零样本模型(Zero-Shot Model)(橙线):起始 RaPR 仅约 20%,并在强化学习过程中逐步下降至零。由于最初很少触发视觉操作,模型缺乏实践机会,使得新生的像素空间推理获得的期望回报低于其更成熟的文本推理,从而进一步减少 RaPR。这说明在视觉操作上的初始能力不足会形成恶性循环,阻碍像素空间推理的发展。由于几乎不使用视觉操作,其视觉操作错误率也保持极低。
-
无自我纠正模型(No-Correction Model)(蓝线):仅使用单遍专家轨迹进行训练,初期 RaPR 有所上升,表明模型倾向于尝试视觉操作。然而,这一趋势很快被视觉操作失败率的显著且持续上升所掩盖。错误率升高反映了模型无法有效应对视觉任务中的意外或错误结果,这直接源于指令微调阶段缺乏错误诱导的自我纠正轨迹。因此,策略在越来越依赖像素空间推理的同时,却忽视了视觉操作的结果,更倾向于文本推理。有趣的是,我们观察到这些推理轨迹会产生视觉操作的错误信息,但仍能得出正确答案,这表明出现了“奖励劫持”:策略通过表面化执行视觉操作获得好奇心奖励,同时本质上依赖文本推理来获取正确性奖励。
-
预热启动模型(Warm-Start Model)(紫线,标记为 “PixelReasoner”):作为强化学习的基础并获得适当激励,该模型能够在不产生过高视觉操作错误率的前提下,成功培养像素空间推理能力。这突出显示了预热启动阶段全面指令微调的重要性。
培养新颖推理能力需要激励
为了评估激励的影响,我们比较了从预热启动模型(Warm-Start Model)出发进行强化学习(RL)训练时,有无好奇心驱动激励的训练动态。
-
不含好奇心的标准 RL(灰线):曲线显示视觉操作利用率 (RaPRRaPRRaPR) 在 240240240 次梯度步中从约 0.550.550.55 持续下降至 000。这种下降的原因在于,没有特定的探索动力,策略倾向于其更成熟的文本推理,而非最初较不成熟的像素空间推理。随着使用量的减少,视觉操作的失败率保持较低。
-
我们的模型(紫线):同样以预热启动模型为起点,但加入了好奇心驱动的探索奖励,展示了更复杂且最终成功的轨迹。最初,Pixel-Reasoner 的 RaPRRaPRRaPR 在前 505050 次梯度步内有所下降,然后在约 150150150 步期间保持平台期。在此阶段,策略在好奇心奖励的驱动下继续探索像素空间推理,尽管其相对于文本推理仍处于劣势(如图 7(右)所示)。直到 200200200 次梯度步后,策略才开始有效利用像素空间推理的优势。其 RaPRRaPRRaPR 主动且显著增加,同时视觉操作的失败率保持低且稳定。这表明,稳健的预热启动指令微调与好奇心驱动激励的结合,使策略不仅能够探索,也能掌握新的像素空间推理能力。此外,由于训练查询中视觉密集任务比例较高,Pixel-Reasoner 最终展现出约 80%80\%80% 的较高 RaPRRaPRRaPR。我们在附录中提供了测试集的曲线。
6 相关工作
视觉-语言模型的后训练
后训练技术(如指令微调和强化学习)对于将大型视觉-语言模型(VLMs)适配到超越初始预训练的复杂任务至关重要。LLaVA [Liu et al., 2023]、Llava-OV [Li et al., 2024b]、Infinity-MM [Gu et al., 2024] 和 MAmmoTH-VL [Guo et al., 2024] 的研究表明,扩大指令微调数据集规模并增加任务多样性,能够显著提升 VLM 在各类多模态基准上的泛化能力。
近年来,越来越多的工作将强化学习 (RL) 应用于多模态领域 [Deng et al., 2025;Huang et al., 2025;Feng et al., 2025]。这些方法通常采用多阶段流水线:先在昂贵的数据蒸馏上进行监督微调 (SFT),再通过 RL 进一步精炼模型的推理能力。VL-Rethinker [Wang et al., 2025] 探讨了更直接的 RL 方法以促进 VLM 的“慢思考”能力,并引入选择性样本重放(SSR)来对抗 GRPO 中的优势消失问题。
带工具的视觉-语言模型
最近的研究尝试通过外部工具增强 VLM,或使其能够在输入图像上执行像素级操作。Chain-of-Manipulation [Qi et al., 2025]、Visual-Program-Distillation (VPD) [Hu et al., 2024b] 聚焦于训练模型有效利用工具或将基于工具的推理蒸馏到闭源模型中;Visual Sketchpad [Hu et al., 2024a] 为 GPT-4o 等模型配备了诸如深度感知与 Python 作图等工具。类似 o3 的模型 [Jaech et al., 2024b] 展示了通过动态应用缩放、翻转等操作来“以图像思考”并提升视觉理解的能力。特定工具如 Instruction-Guided Visual Masking [Zheng et al., 2024] 和视觉引导搜索 [Wu and Xie, 2024] 也已被整合进这些框架中。
7 结论
在本文中,我们首次展示了如何在现有视觉-语言模型中激励像素空间推理。我们的预热启动指令微调和好奇心驱动强化学习对于实现最先进的性能都是必不可少的。然而,目前的工作仍仅限于两种主要的视觉操作,难以满足更广泛任务的需求。我们的框架可以轻松扩展至其它操作,如深度图、图像搜索等。未来,研究社区可以共同努力,丰富视觉操作,从而进一步增强 VLM 中的像素空间推理能力。
附录
A 局限性
在本工作中,我们对视觉-语言推理进行了根本性重新思考,并引入了像素空间推理的概念。尽管我们展示了方法在培养像素空间推理方面的有效性,但这一改进仍受到跨任务和内容数据有限的制约。此外,我们仅聚焦于两种特定的视觉操作,以处理图像和视频这两种主要媒体格式。未来,我们将致力于引入更多视觉操作,并评估像素空间推理在更丰富、多样化任务集合上的有效性。
B 好奇心驱动奖励的推导
主要目标是最大化期望正确性回报,将其形式化为受约束优化问题。设 r(x,y)r(x,y)r(x,y) 为查询 xxx 和回答 yyy 的原始正确性奖励,生成回答的策略记为 πθ(y∣x)\pi_\theta(y\mid x)πθ(y∣x)。优化问题为:
maxθE[r(x,y)∣x∼D,y∼πθ(y∣x)](6)\max_\theta \mathbb{E}\bigl[r(x,y)\mid x\sim\mathcal{D},\,y\sim\pi_\theta(y\mid x)\bigr] \tag{6} θmaxE[r(x,y)∣x∼D,y∼πθ(y∣x)](6)
subject to
C1(θ;x)≡RaPR(x)−H≥0,(7)C_1(\theta;x)\equiv \mathrm{RaPR}(x)-H\ge0, \tag{7} C1(θ;x)≡RaPR(x)−H≥0,(7)
C2(y)≡N−nvo(y)≥0.(8)C_2(y)\equiv N - n_{vo}(y)\ge0. \tag{8} C2(y)≡N−nvo(y)≥0.(8)
其中:
- RaPR(x)≜E[1PR(y)∣y∼πθ(y∣x)]\mathrm{RaPR}(x)\triangleq \mathbb{E}[\mathbf{1}_{PR}(y)\mid y\sim\pi_\theta(y\mid x)]RaPR(x)≜E[1PR(y)∣y∼πθ(y∣x)] 是查询 xxx 的像素空间推理率(Rate of Pixel-space Reasoning);
- HHH 是对 RaPR(x)\mathrm{RaPR}(x)RaPR(x) 的预设最小阈值;
- nvo(y)n_{vo}(y)nvo(y) 是回答 yyy 中视觉操作的数量;
- NNN 是对 nvo(y)n_{vo}(y)nvo(y) 的预设上限。
约束 (7) 是针对给定查询 xxx 的期望水平约束,而约束 (8) 则适用于每个单独的回答 yyy。
为了将这些约束纳入目标,一种常用技术是拉格朗日松弛(Lagrangian Relaxation)。对于最大化问题,通常会从原始目标函数 r(x,y)r(x,y)r(x,y) 中减去与约束违反程度成正比的项(当约束写作 g(x)≤0g(x)\le0g(x)≤0 时)。如果我们将约束重写为
- g1(θ;x)≡H−RaPR(x)≤0g_1(\theta; x)\equiv H - \mathrm{RaPR}(x)\le0g1(θ;x)≡H−RaPR(x)≤0
- g2(y)≡nvo(y)−N≤0g_2(y)\equiv n_{vo}(y) - N\le0g2(y)≡nvo(y)−N≤0
则对单次样本的标准拉格朗日修正奖励为:
rLagrangian(x,y;θ)=r(x,y)−λ1(H−RaPR(x))−λ2(nvo(y)−N)(9)r_{\mathrm{Lagrangian}}(x,y;\theta) = r(x,y) -\lambda_1\bigl(H - \mathrm{RaPR}(x)\bigr) -\lambda_2\bigl(n_{vo}(y) - N\bigr) \tag{9} rLagrangian(x,y;θ)=r(x,y)−λ1(H−RaPR(x))−λ2(nvo(y)−N)(9)
其中 λ1,λ2≥0\lambda_1,\lambda_2 \ge 0λ1,λ2≥0 是拉格朗日乘子。整体优化目标则是在 θ\thetaθ 上最大化 E[rLagrangian(x,y;θ)]\mathbb{E}[r_{\mathrm{Lagrangian}}(x,y;\theta)]E[rLagrangian(x,y;θ)],并在乘子上最小化该期望。
然而,直接应用此标准形式存在两个问题:
- 过度满足(Over‐satisfaction)问题:项 −λ2(nvo(y)−N)-\lambda_2\bigl(n_{vo}(y)-N\bigr)−λ2(nvo(y)−N) 在 nvo(y)<Nn_{vo}(y)<Nnvo(y)<N(即约束被“过度满足”)时会变为正值,可能鼓励策略使用远少于所需的视觉操作。
- 期望级别作用:项 −λ1(H−RaPR(x))-\lambda_1\bigl(H - \mathrm{RaPR}(x)\bigr)−λ1(H−RaPR(x)) 作用于期望层面,无法正确奖励单个响应 y∼πθy\sim\pi_\thetay∼πθ。
因此,我们采用以下修正奖励函数:
r′(x,y)=r(x,y)+α⋅max(H−RaPR(x),0)⋅1PR(y)+β⋅min(N−nvo(y),0)(10)r'(x,y) = r(x,y) +\alpha \cdot \max\bigl(H - \mathrm{RaPR}(x),\,0\bigr)\cdot \mathbf{1}_{PR}(y) +\beta \cdot \min\bigl(N - n_{vo}(y),\,0\bigr) \tag{10} r′(x,y)=r(x,y)+α⋅max(H−RaPR(x),0)⋅1PR(y)+β⋅min(N−nvo(y),0)(10)
其中 α≥0,β≥0\alpha \ge 0,\ \beta \ge 0α≥0, β≥0 为固定超参数。
该形式具有多重优点。首先,截断机制(clipping)有效解决了过度满足(over‐satisfaction)问题,同时保持与原受约束目标的等价性 [Wang et al., 2022]。截断确保仅在相应约束被违反时才激活惩罚,否则惩罚值为零,从而避免了过度满足。
其次,该结构允许 α\alphaα、β\betaβ 被视为固定超参数。在标准拉格朗日方法(式 (9))中,乘子通常是动态调整的;例如,Karush–Kuhn–Tucker (KKT) 条件意味着对于无效约束(即松弛满足的约束),相应的乘子为零。通过截断,当约束被满足时将惩罚项置零,从而避免了根据约束满足程度对 α\alphaα、β\betaβ 进行动态调整的需求。
此外,指示函数 1PR(y)\mathbf{1}_{PR}(y)1PR(y) 的引入将查询级别的期望约束转化为响应级别的奖励。直观地,该项充当针对性的激励:仅在像素空间推理的平均触发率低于期望阈值时,为执行像素空间推理的特定行为提供奖励。乘子 α≥0\alpha \ge 0α≥0 调节这一激励强度,并对策略因未能利用像素空间推理所可能获得的额外奖励提供一种隐式惩罚。
C 数据和训练细节

C.1 视觉操作协议
我们包含两种主要的视觉操作:裁剪图像(CropImage)和选取帧(SelectFrames)。
-
CropImage:该操作允许模型通过提供一个边界框来放大图像的特定区域。输入包括一个二维边界框
bbox_2d——数值坐标列表 [x1,y1,x2,y2][x_1, y_1, x_2, y_2][x1,y1,x2,y2](需在图像尺寸范围内)——以及一个target_image索引(从 1 开始,1 表示原始图像)。此操作可帮助模型聚焦于细粒度细节。 -
SelectFrames:该操作使模型能够从视频中选择帧子集。输入
target_frames是一个整数列表,指定在 16 帧序列中要提取的帧索引,且不超过 8 帧。此功能允许模型关注与查询相关的关键时间节点。
C.2 指令微调数据
种子数据集详情
我们基于两个关键属性选择数据集:需要细粒度分析的高视觉复杂度,以及能够作为视觉操作目标或锚点的显式标注。基于这些标准,我们的数据来源包括:
- SA1B [Kirillov et al., 2023]:一个大规模高分辨率自然场景数据集,提供丰富的视觉细节和复杂性。
- FineWeb [Ma et al., 2024]:包含网页截图与问答实例,并附带精确的答案区域边界框标注,为视觉分析提供显式的空间目标。
- STARQA [Wu et al., 2024]:提供带问答对和注释时间窗口的视频数据,指示答案相关的视觉内容,为潜在的视频特定操作提供视觉与时间上下文。
详细数据流程示意
如图 8 所示,在获取种子数据的参考视觉线索后,我们将整张高分辨率图像或视频及对应的局部参考视觉线索输入 GPT-4o。接着,采用基于模板的方法提取整体视觉输入的初步分析和细粒度局部分析,然后将整体分析、局部参考视觉线索及其对应的部分分析拼接,形成单遍轨迹。随后,我们利用参考视觉线索生成错误视觉线索,并将这些错误操作插入到单遍轨迹中,以合成自我纠正轨迹。
单遍轨迹与自我纠正数据合成细节
- 单遍轨迹(Single-pass):轨迹中不插入任何错误操作。
- 重新裁剪一次(Recrop once):随机选取一个与参考视觉线索无交集的边界框(bbox),并将其插入至正确视觉操作之前。
- 重新裁剪两次(Recrop twice):随机选取两个与参考视觉线索无交集的边界框,按顺序插入至正确视觉操作之前。
- 过度放大(Further zoom-in):选取一个包含参考视觉线索但尺寸过大的不准确边界框,并将其插入至正确视觉操作之前。
- 重新选择(Reselect):随机采样一些帧索引,这些索引与参考视觉线索的帧索引无交集,并将其插入至正确视觉操作之前。
C.3 训练细节
实现细节
在指令微调阶段,我们改编了 Open-R1 代码以实现带损失屏蔽的监督微调 (SFT) 损失。强化学习阶段基于 OpenRLHF 实现。我们采用 GRPO [DeepSeek-AI et al., 2025] 并结合选择性样本重放 (SSR) [Wang et al., 2025],以应对显著的优势消失问题。如图 9 所示,我们的奖励方案在正确性奖励之外,还加入了好奇心奖励和效率惩罚,增加了奖励的方差。然而,随着训练进行,遭遇奖励均一化的查询比例稳步上升至 90%,导致“全部回答错误”查询比例大幅上升,明显影响了整体性能。在 RL 训练中,我们采用近似 on-policy 的范式:每 512 个查询(定义为一个 episode)后,同步行为策略与改进策略。SSR 重放缓冲区在每个 episode 期间持续保留,随后清空。每个查询采样 8 条响应,训练批量大小设置为 256 对查询-响应。
我们的 7B 模型在 4×8 台 A800 (80G) GPU 上训练 20 小时。

训练超参数
- 指令微调阶段:批量大小为 128,学习率为 1×10−61\times10^{-6}1×10−6,采用 10% 的预热步数。
- 强化学习阶段:使用余弦学习率调度,初始学习率 1×10−61\times10^{-6}1×10−6,3% 的预热迭代。每个训练查询采样 8 条轨迹,设置超参数为 α=0.5\alpha=0.5α=0.5、β=0.05\beta=0.05β=0.05、H=0.3H=0.3H=0.3 和 N=1N=1N=1。
该配置反映了我们的目标:阈值 H=0.3H=0.3H=0.3 鼓励策略在约 30% 的响应中采用像素空间推理;N=1N=1N=1 则通过限制每次响应最多一次视觉操作来提升效率。在此参数下,单次响应能够获得的最大探索奖励约为: 0.5×(0.3−18)≈0.0875,0.5 \times \bigl(0.3 - \tfrac{1}{8}\bigr) \approx 0.0875,0.5×(0.3−81)≈0.0875, 而每增加一次视觉操作(超过第一次)则会产生 −0.05-0.05−0.05 的惩罚。
D 额外分析
D.1 统计
- Qwen2.5-VL-Instruct 在利用新视觉操作的零样本能力方面表现有限。 我们在系统提示中为 Qwen2.5-VL-Instruct 加入了视觉操作协议。最初,它在 20.2% 的训练 rollouts 中调用视觉操作,其中 40.6% 发生错误,36.2% 导致答案不正确。因此,在使用像素空间推理时的平均准确率为 23.2%,而在使用文本推理时为 49.5%。
- Pixel-Reasoner 在评估基准上的 RaPR。 我们的 Pixel-Reasoner 会自适应触发像素空间推理:在 V-Star 上占比 78.53%,在 TallyQA-Complex 上占比 57.78%,在 InfographicsVQA 上占比 58.95%,在 MVBench 上占比 66.95%。
D.2 案例分析
我们在图 11 和图 10 中展示了成功的推理轨迹,并提供了具体示例来说明当策略陷入“学习陷阱”时的失败模式。



关于详细的提示词可以去看附录的最后一部分