深度学习-3.深度前反馈网络
Deep Learning - Lecture 3 Deep Feedforward Networks
- 介绍
- 深度前馈网络
- 深度前馈网络概述
- 网络为什么要“深”?
- 全连接层(Fully connected layers)
- 激活层:激活函数
- 深度前馈网络
- 用于回归和分类任务的深度网络
- 软件中的深度前馈网络
- Keras 函数式 API
- 参数估计:自动微分与反向传播
- 自动微分
- 反向模式自动微分示例
- 软件中的深度前馈网络
- 总结
- 引用
本节目标:
- 定义深度前馈网络的结构。
- 能够为隐藏层和输出层选择不同的激活函数,并说明选择的理由。
- 解释如何使用自动求导来获取损失函数的导数。
- 能够在软件中实现深度前馈网络。
介绍
在机器学习中,我们希望能够对非线性函数进行建模 —— 深度前馈网络能够实现非线性函数近似
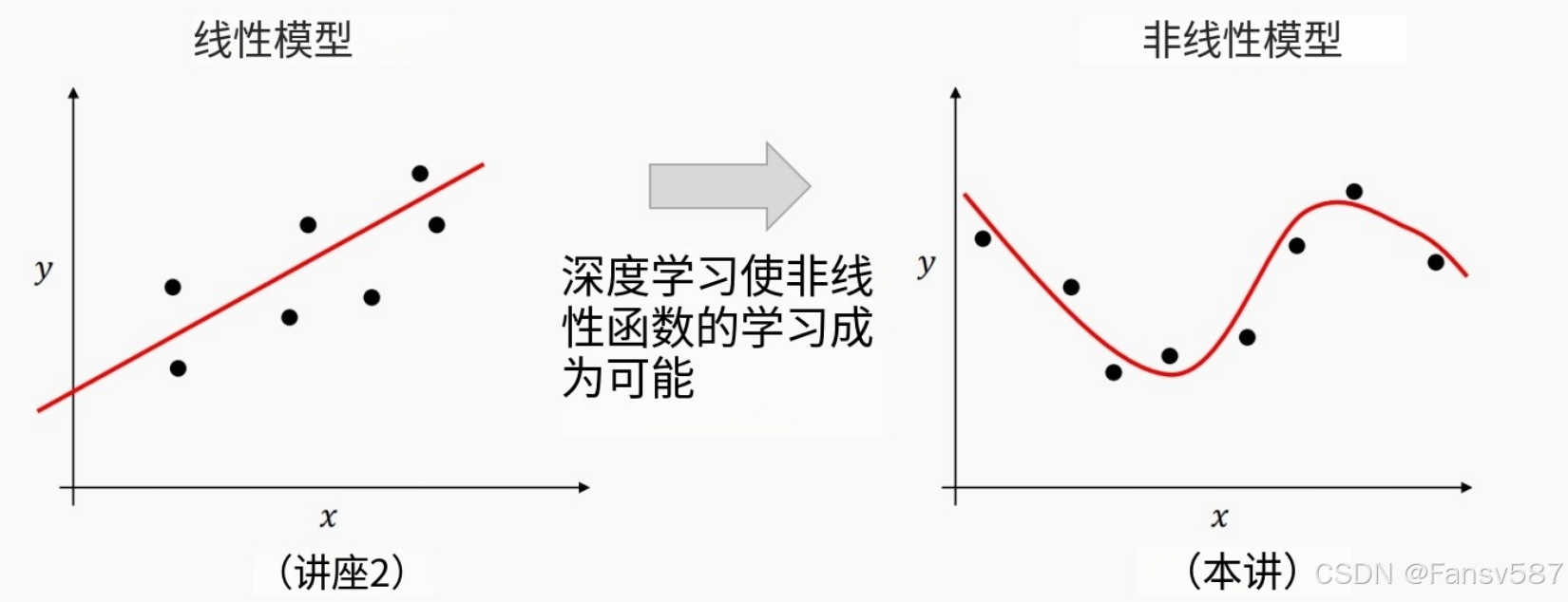
基函数扩展(Basis Function Expansion)
基函数扩展概念:为了对非线性函数进行建模,我们将输入 x x x 通过基函数扩展,以创建从特征到输出的线性映射。
- 线性模型:给出线性模型公式 y ^ = θ x \hat{y}=\theta x y^=θx 。
- 带基函数扩展的非线性模型:公式为 y ^ = ∑ i = 1 n θ i ϕ i ( x ) \hat{y}=\sum_{i = 1}^{n}\theta_i\phi_i(x) y^=∑i=1nθiϕi(x) ,其中 ϕ i \phi_i ϕi 是基函数,可被视为一种“特征”。
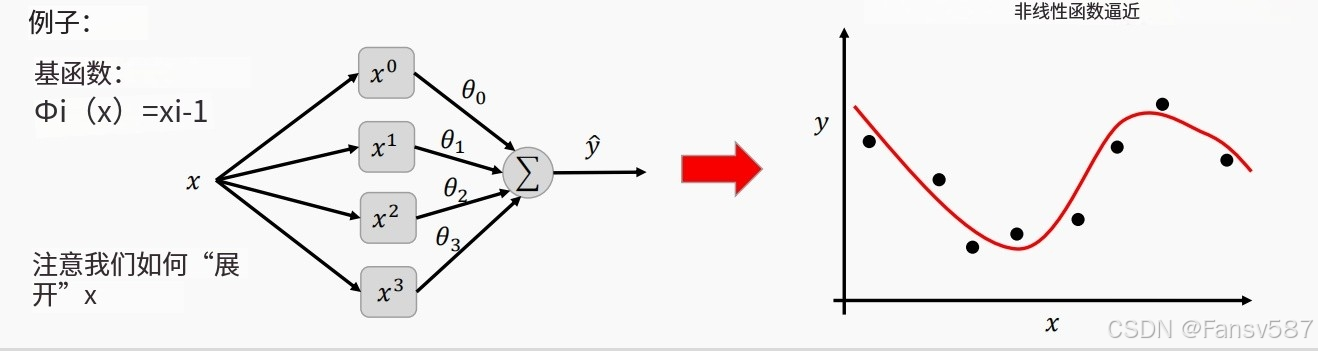
如上图,假设基函数为 ϕ i ( x ) = x i − 1 \phi_i(x)=x^{i - 1} ϕi(x)=xi−1 ,在扩展图中,输入 x x x 被扩展为 x 0 , x 1 , x 2 , x 3 x^0, x^1, x^2, x^3 x0,x1,x2,x3 ,并分别与参数 θ 0 , θ 1 , θ 2 , θ 3 \theta_0, \theta_1, \theta_2, \theta_3 θ0,θ1,θ2,θ3 相乘后求和得到 y ^ \hat{y} y^ 。
深度学习中自动学习基函数
在传统(经典)机械学习中,手工制作的特征由人固定,不会自主学习。意思就是模型的各个特征值都是预先人为设定好的,模型在训练过程中不会对其进行调整和学习,模型训练学习的只是那些参数。


上图中的橙色阴影框表示能够从数据中学习的组件,表明深度学习中的这些简单函数组件可以从数据中自动学习和调整,以实现基函数扩展。
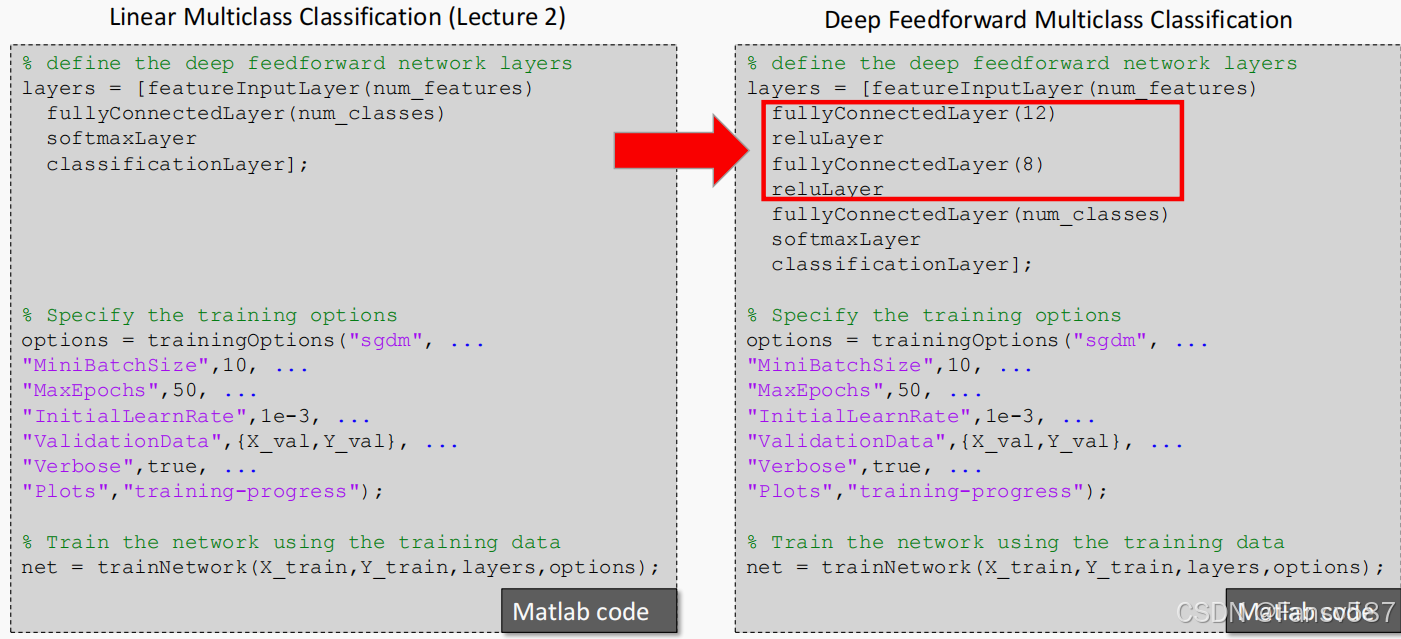
matlab中的线性多分类和深度前馈网络代码对比
深度前馈网络
深度前馈网络概述
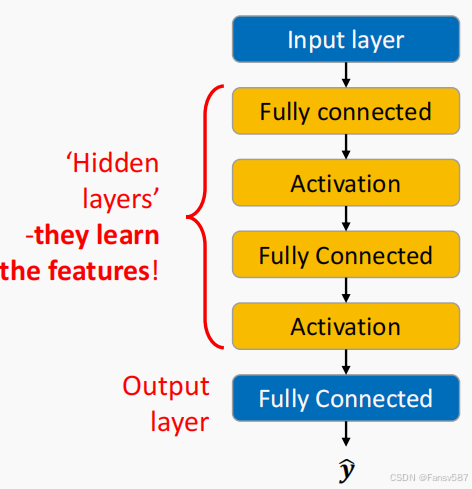
- 网络组成:深度前馈网络由全连接层和非线性激活函数组成。
- 全连接层功能:全连接层对输入进行线性基扩展。也就是说,它通过线性变换将输入数据映射到一个新的特征空间。
- 激活函数功能:激活函数对全连接层进行非线性激活。这赋予了网络学习和表示非线性关系的能力,使网络能够处理更复杂的任务。
- 隐藏层功能:隐藏层执行可学习的特征提取。它们从输入数据中自动学习和提取有用的特征,以帮助网络进行更好的预测。
- 输出层类型:
- 对于回归任务,输出层是全连接层。这是因为回归任务通常需要预测一个连续的值,全连接层可以直接输出预测结果。
- 对于二分类任务,输出层使用sigmoid函数。sigmoid函数将输出值映射到0到1之间,可解释为属于某一类别的概率。
- 对于多分类任务,输出层使用softmax函数。softmax函数将输出值转换为概率分布,使得所有类别的概率之和为1,从而可以确定每个样本属于各个类别的概率。
网络为什么要“深”?
多层感知机与深度前馈网络结构对比如下:
- 多层感知机(Multilayer Perceptron):即仅有一个隐藏层的前馈网络,结构为输入层、全连接隐藏层、激活函数层、全连接输出层。
- 深度前馈网络(Deep Feedforward Network):结构包含输入层、多个全连接隐藏层与激活函数层交替、全连接输出层。
感知机和感知器一个意思,不知道的可以看我的博客:更多的分类方法,感知机介绍在最下面
核心问题阐述
一个带有单层隐藏层的前馈网络(多层感知机)就足以表示任何函数,它是一个“通用近似器”。
那么进而提出疑问:既然如此,为什么还要构建更深层次的网络?
答案:单层隐藏层网络的局限性
- 可能无法正确学习和泛化。
- 规模可能大得不切实际。
- 函数复杂度与神经元数量的关系
对于复杂函数的近似,单层隐藏层网络需要大量神经元来捕捉函数的特征。比如,要拟合一个高度非线性、变化复杂的函数,单层隐藏层中的神经元数量可能需要呈指数级增长才能达到较好的近似效果。以图像识别任务为例,图像中包含的特征丰富多样,从简单的边缘、纹理到复杂的物体形状、结构等,单层隐藏层网络若想完整地提取和表示这些特征,就需要足够多的神经元。但随着神经元数量的大幅增加,网络的参数数量也会剧增,这会导致网络规模急剧膨胀。 - 计算资源与时间成本
大量的神经元意味着更高的计算复杂度。在训练过程中,每一次参数更新都需要对这些神经元进行计算,参数数量的增多会使计算量呈指数级上升,这不仅需要强大的计算硬件支持(如高性能的GPU),还会耗费大量的计算时间。例如在大规模数据集上训练这样的网络,可能需要数天甚至数月的时间才能完成训练,这在实际应用中是难以接受的。 - 模型存储与管理困难
网络规模的增大还会带来模型存储的问题。众多的参数需要占用大量的存储空间,这对于存储设备的容量是一个挑战。同时,在模型的部署和管理方面,大型的单层隐藏层网络也会变得更加复杂,增加了维护和优化的难度。
- 函数复杂度与神经元数量的关系
引用出自Goodfellow等人2016年所著书籍的第6章第6.4.1节的结论:“Empirically, greater depth does seem to result in better generalization for a wide variety of tasks”(根据经验,对于各种各样的任务,更深的层次似乎确实能带来更好的泛化能力)
这表明在实际应用中,深度网络在泛化性能上具有优势。
全连接层(Fully connected layers)
功能概述:全连接层对输入执行线性基函数扩展,仅能对线性函数建模。(所以后面还需要非线性激活函数)。全连接层本身的变换是线性的,为了让网络能够处理非线性问题。
单个单元的数学表达式:在全连接层 l l l中,一个“单元”由仿射函数(线性部分 + 偏差)描述,公式为 z j ( l ) = ∑ i w j i ( l ) x i ( l − 1 ) + b j ( l ) z_j^{(l)} = \sum_{i} w_{ji}^{(l)} x_i^{(l - 1)} + b_j^{(l)} zj(l)=i∑wji(l)xi(l−1)+bj(l)其中 z j ( l ) z_j^{(l)} zj(l)是第 l l l层第 j j j个单元的输出, w j i ( l ) w_{ji}^{(l)} wji(l)是连接第 l − 1 l - 1 l−1层第 i i i个单元到第 l l l层第 j j j个单元的权重, x i ( l − 1 ) x_i^{(l - 1)} xi(l−1)是第 l − 1 l - 1 l−1层第 i i i个单元的输入, b j ( l ) b_j^{(l)} bj(l)是第 l l l层第 j j j个单元的偏差。
所有单元的数学表达式:有了一个单元的,全连接层中所有“单元”的输出可以推导出,由矩阵乘法表示为
z
(
l
)
=
W
(
l
)
x
(
l
−
1
)
\mathbf{z}^{(l)} = \mathbf{W}^{(l)} \mathbf{x}^{(l - 1)}
z(l)=W(l)x(l−1)以矩阵形式展示了具体计算过程:
(
z
1
z
2
⋮
z
m
)
=
(
b
1
w
m
,
1
⋯
w
1
,
n
b
2
w
m
,
1
⋯
w
2
,
n
⋮
⋮
⋯
⋮
b
J
w
m
,
1
⋯
w
m
,
n
)
(
x
1
x
2
⋮
x
n
)
\begin{pmatrix} z_1 \\ z_2 \\ \vdots \\ z_m \end{pmatrix} = \begin{pmatrix} b_1 & w_{m,1} & \cdots & w_{1,n} \\ b_2 & w_{m,1} & \cdots & w_{2,n} \\ \vdots & \vdots & \cdots & \vdots \\ b_J & w_{m,1} & \cdots & w_{m,n} \end{pmatrix} \begin{pmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{pmatrix}
z1z2⋮zm
=
b1b2⋮bJwm,1wm,1⋮wm,1⋯⋯⋯⋯w1,nw2,n⋮wm,n
x1x2⋮xn
权重矩阵
W
(
l
)
\mathbf{W}^{(l)}
W(l)的列数等于输入
x
(
l
−
1
)
\mathbf{x}^{(l - 1)}
x(l−1)的数量,行数等于单元的数量。
激活层:激活函数
功能概述:激活函数 h h h为网络引入非线性,从而使模型能够对非线性函数进行建模。因为仅由全连接层组成的网络只能处理线性关系,激活函数的加入打破了这种线性限制,提升了网络的表达能力。
计算过程:全连接层的输出为 z ( l ) = W ( l ) x ( l − 1 ) \mathbf{z}^{(l)} = \mathbf{W}^{(l)} \mathbf{x}^{(l - 1)} z(l)=W(l)x(l−1),经过激活函数处理后得到 x ( l ) = h ( z ( l ) ) \mathbf{x}^{(l)} = h(\mathbf{z}^{(l)}) x(l)=h(z(l)),即激活函数将全连接层的输出作为输入,产生新的输出进入下一层网络。
如下是两个示例
- 修正线性单元(Rectified linear unit, ReLU):公式为 h ( z j ) = max ( 0 , z j ) h(z_j) = \max(0, z_j) h(zj)=max(0,zj) ,ReLU函数在正半轴上梯度为1,不会出现梯度消失问题,有助于网络训练。
- 双曲正切函数(Hyperbolic Tangent):公式为 h ( z j ) = tanh ( z j ) h(z_j) = \tanh(z_j) h(zj)=tanh(zj) ,其函数曲线呈现出S形,范围在 -1 到 1 之间。不过这个函数在某些区域,梯度会趋近于0,可能导致在反向传播过程中梯度消失,影响网络训练。(之后的LSTM网络等会解决这个问题。)
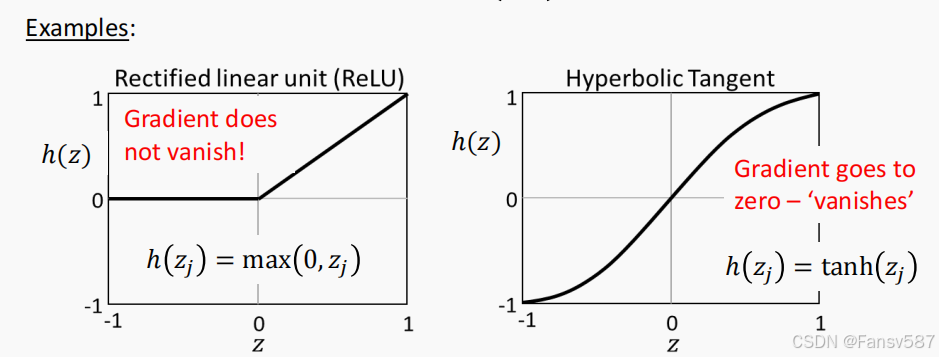
更多的激活函数可以看我的:常见的激活函数
深度前馈网络
- 激活函数 h h h为网络引入非线性,使模型能够对非线性函数进行建模。
- 全连接层的计算表达式为 z ( l ) = W ( l ) x ( l − 1 ) \mathbf{z}^{(l)} = \mathbf{W}^{(l)} \mathbf{x}^{(l - 1)} z(l)=W(l)x(l−1) 表示第 l l l层全连接层的输入 x ( l − 1 ) \mathbf{x}^{(l - 1)} x(l−1)经过权重矩阵 W ( l ) \mathbf{W}^{(l)} W(l)变换得到输出 z ( l ) \mathbf{z}^{(l)} z(l)
- 激活函数的计算表达式为 x ( l ) = h ( z ( l ) ) \mathbf{x}^{(l)} = h(\mathbf{z}^{(l)}) x(l)=h(z(l)) ,即全连接层的输出 z ( l ) \mathbf{z}^{(l)} z(l)经过激活函数 h h h处理后,得到新的输出 x ( l ) \mathbf{x}^{(l)} x(l) ,作为下一层的输入。
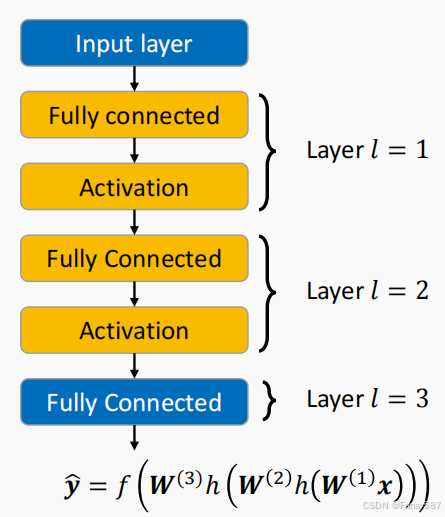
由此,我们得到深度前馈网络整体表达式,其是一个简单函数链,整体表达式为:
y
^
=
f
(
W
(
L
)
h
(
…
h
(
W
(
2
)
h
(
W
(
1
)
x
)
)
)
)
\hat{\mathbf{y}} = f\left(\mathbf{W}^{(L)}h\left(\ldots h\left(\mathbf{W}^{(2)}h\left(\mathbf{W}^{(1)}\mathbf{x}\right)\right)\right)\right)
y^=f(W(L)h(…h(W(2)h(W(1)x))))
其中,对于回归任务,最终输出函数
f
f
f是恒等函数;
对于分类任务,
f
f
f是softmax函数。
网络结构图如下:
用于回归和分类任务的深度网络
深度前馈网络在回归和分类任务中的结构具有相似性。
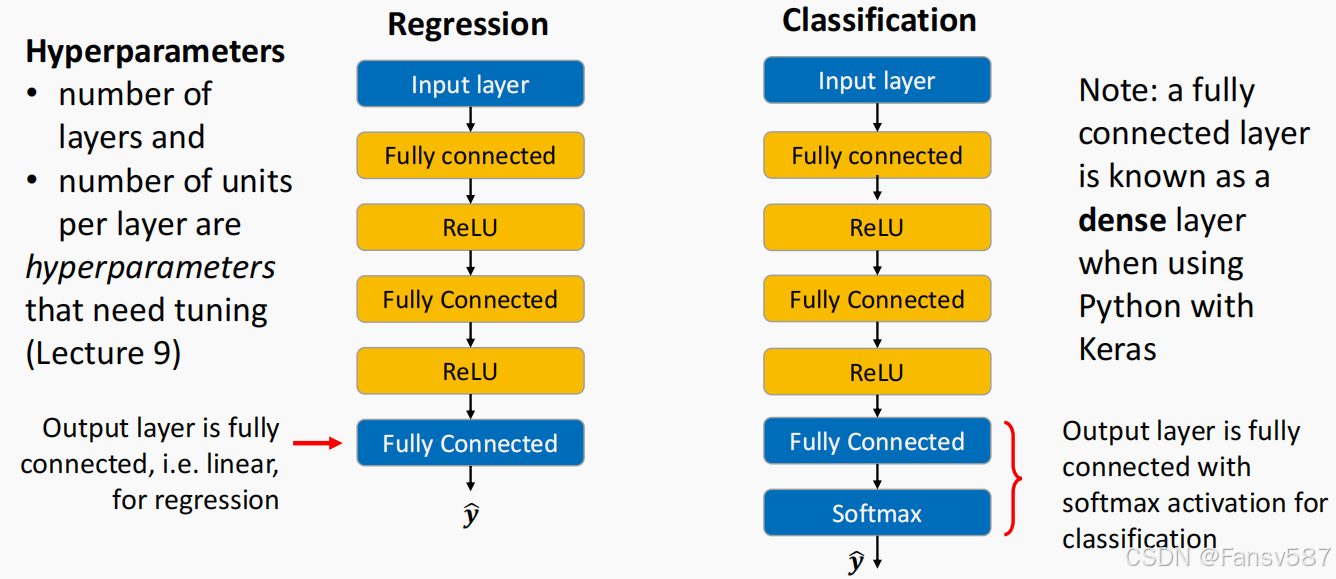
- 超参数:层数和每层的单元数是需要调整的超参数。超参数不能通过训练过程自动学习,需人为预先设定或通过特定调优方法确定,以优化网络性能。
- 输出层差异:
- 回归任务:输出层是全连接层,即线性层。回归任务旨在预测连续值,线性的全连接层可直接输出预测结果。
- 分类任务:输出层是带有softmax激活函数的全连接层。softmax函数将输出转换为概率分布,使所有类别的概率之和为1,从而可判断样本属于各个类别的概率,适用于多分类场景。
- 术语说明:在使用Python的Keras库时,全连接层也被称为“dense layer”(密集层)。
软件中的深度前馈网络
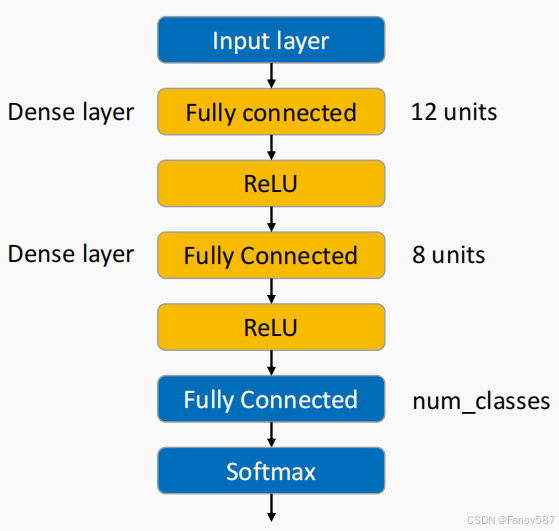
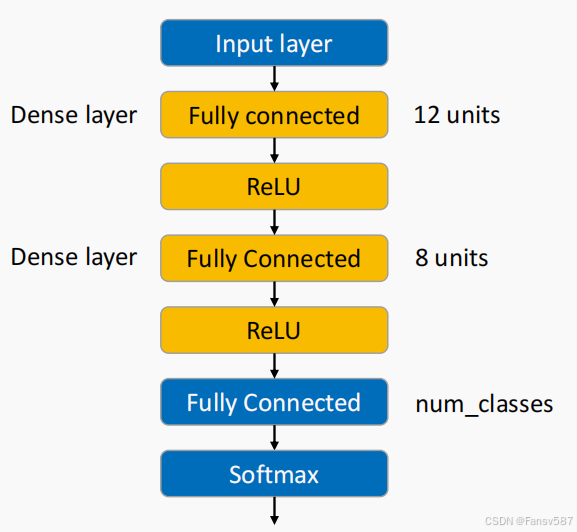
网络结构示意图如上,展示了多分类深度前馈网络的结构:
- 输入层(Input layer):接收输入数据。
- 全连接层(Dense layer / Fully connected):有两层,第一层有12个单元,第二层有8个单元,每层后都接有ReLU激活函数。
- 全连接输出层(Fully Connected):单元数为
num_classes,对应分类任务中的类别数。 - Softmax层(Softmax):对输出层结果进行处理,将其转换为概率分布,用于多分类任务。
Matlab示例代码(使用Matlab Deep Learning Toolbox)
% define the deep feedforward network layers
layers = [featureInputLayer(num_features)
fullyConnectedLayer(12)
reluLayer
fullyConnectedLayer(8)
reluLayer
fullyConnectedLayer(num_classes)
softmaxLayer
classificationLayer];
代码依次定义了特征输入层、含12个单元的全连接层、ReLU层、含8个单元的全连接层、ReLU层、对应类别数的全连接层、Softmax层和分类层。
Python示例代码(Keras - TensorFlow)
# import libraries and data
from keras.models import Sequential
from keras.layers import Dense
# define the deep feedforward network in keras
model = Sequential()
model.add(Dense(12,
input_shape=(num_features,), activation="relu"))
model.add(Dense(8, activation="relu"))
model.add(Dense(num_classes, activation="softmax"))
Keras 函数式 API
Keras 函数式 API 比顺序类(Sequential class)更灵活,例如可以处理具有共享层、多个输入或输出的模型。
示意图:
Python示例代码
- 函数式API代码(Python with Keras - TensorFlow (functional method)):
import keras
from keras.layers import Dense
x = Dense(12, activation="relu")(x)
x = Dense(8, activation="relu")(x)
yhat = Dense(num_classes, activation="softmax")(x)
先导入Keras库和Dense层,然后通过函数式API的方式定义网络层,将每一层的输出作为下一层的输入,逐步构建网络。
- 顺序API代码(Python with Keras - TensorFlow (sequential method)):
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(12, input_shape=(num_features,), activation="relu"))
model.add(Dense(8, activation="relu"))
model.add(Dense(num_classes, activation="softmax"))
先导入Sequential模型和Dense层,然后使用Sequential类依次添加各个层来构建网络,每一层通过add方法顺序添加。
参数估计:自动微分与反向传播
现代深度学习软件的一个关键特性是使用自动微分(automatic differentiation,即auto - diff)来获取损失函数的梯度。
随机梯度下降公式
公式为
w
j
i
(
l
)
←
w
j
i
(
l
)
−
ϵ
∂
L
∂
w
j
i
(
l
)
w_{ji}^{(l)} \leftarrow w_{ji}^{(l)} - \epsilon \frac{\partial L}{\partial w_{ji}^{(l)}}
wji(l)←wji(l)−ϵ∂wji(l)∂L
其中
L
L
L是损失函数。该公式表示在随机梯度下降算法中,权重
w
j
i
(
l
)
w_{ji}^{(l)}
wji(l)根据损失函数对其的梯度进行更新,
ϵ
\epsilon
ϵ是学习率。
几个常用的深度学习计算框架

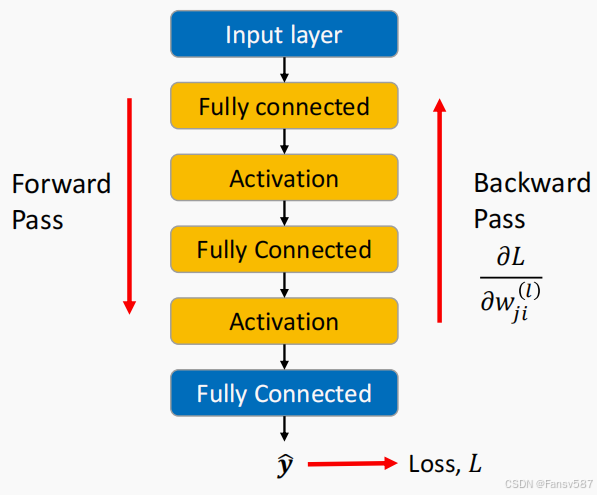
下图是深度前馈网络中两个传播方向的示意图
- 前向传播(Forward Pass):从输入层开始,依次经过全连接层、激活层、全连接层、激活层,最后到全连接输出层,得到预测值 y ^ \hat{y} y^,并计算出损失 L L L。
- 反向传播(Backward Pass):从输出层开始反向传播,计算损失函数对权重
w
j
i
(
l
)
w_{ji}^{(l)}
wji(l)的梯度
∂
L
∂
w
j
i
(
l
)
\frac{\partial L}{\partial w_{ji}^{(l)}}
∂wji(l)∂L,用于更新权重。
自动微分
自动微分是一类通过递归计算来计算数值导数的方法。
关键步骤
- 构建计算图:可以构建一个计算图来描述网络损失函数,该图由节点 v i v_i vi组成(节点是简单的数学运算)。(计算图是一种有向图,用于表示数学表达式或算法的计算过程)
- 定义伴随变量:在一个节点处定义“伴随变量(adjoint)”为 v ˉ i = ∂ f ∂ v i = ∑ j : child of i v ˉ j ∂ v j ∂ v i \bar{v}_i = \frac{\partial f}{\partial v_i} = \sum_{j: \text{child of } i} \bar{v}_j \frac{\partial v_j}{\partial v_i} vˉi=∂vi∂f=j:child of i∑vˉj∂vi∂vj 这里, v ˉ i \bar{v}_i vˉi表示关于节点 v i v_i vi的伴随变量, f f f是最终的目标函数(如损失函数),求和是对节点 i i i的所有子节点 j j j进行的。
- 反向模式自动微分:反向模式自动微分先正向通过计算图,然后反向计算伴随变量。这种方式在计算神经网络的梯度时非常高效,因为它可以避免重复计算,尤其是在输入维度远大于输出维度的情况下。
示例
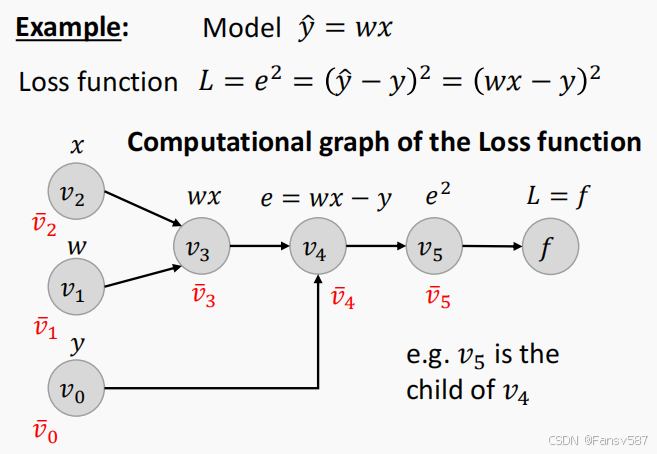
- 模型与损失函数:给出一个简单模型 y ^ = w x \hat{y} = wx y^=wx,其损失函数为 L = e 2 = ( y ^ − y ) 2 = ( w x − y ) 2 L = e^2 = (\hat{y} - y)^2 = (wx - y)^2 L=e2=(y^−y)2=(wx−y)2,其中 x x x是输入, w w w是权重, y y y是真实值, y ^ \hat{y} y^是预测值, e e e是预测误差。
- 计算图:多个节点 v 0 v_0 v0到 v 5 v_5 v5,分别代表不同的运算步骤,如 v 3 v_3 v3代表 w x wx wx, v 4 v_4 v4代表 e = w x − y e = wx - y e=wx−y, v 5 v_5 v5代表 e 2 e^2 e2,最终 L = f L = f L=f。
反向模式自动微分示例
使用反向模式自动微分来寻找损失函数关于权重 w w w的导数,即求解 ∂ L ∂ w \frac{\partial L}{\partial w} ∂w∂L,其中模型为 y ^ = w x \hat{y} = wx y^=wx,损失函数为 L = e 2 = ( y ^ − y ) 2 = ( w x − y ) 2 L = e^2 = (\hat{y} - y)^2 = (wx - y)^2 L=e2=(y^−y)2=(wx−y)2。

正向和反向计算过程
- 正向计算:按顺序计算各节点的值,如 v 0 = y v_0 = y v0=y, v 1 = w v_1 = w v1=w, v 2 = x v_2 = x v2=x, v 3 = v 1 v 2 v_3 = v_1v_2 v3=v1v2, v 4 = v 3 − v 0 v_4 = v_3 - v_0 v4=v3−v0, v 5 = v 4 2 v_5 = v_4^2 v5=v42。
- 反向伴随计算:伴随变量的计算公式 v ˉ i = ∂ f ∂ v i = ∑ j : child of i v ˉ j ∂ v j ∂ v i \bar{v}_i = \frac{\partial f}{\partial v_i} = \sum_{j: \text{child of } i} \bar{v}_j \frac{\partial v_j}{\partial v_i} vˉi=∂vi∂f=j:child of i∑vˉj∂vi∂vj
- 注意公式里是所有子节点求和,子节点就是图中左边的结构图。所以v1和v2都是从v3这里求偏导,而v3和v0都是从v4。
- 从输出端开始反向计算伴随变量的值,如 v ˉ 5 = 1 \bar{v}_5 = 1 vˉ5=1, v ˉ 4 = v ˉ 5 × 2 v 4 = 2 e \bar{v}_4 = \bar{v}_5 \times 2v_4 = 2e vˉ4=vˉ5×2v4=2e, v ˉ 3 = v ˉ 4 × 1 = 2 e \bar{v}_3 = \bar{v}_4 \times 1 = 2e vˉ3=vˉ4×1=2e, v ˉ 2 = v ˉ 3 × v 1 = 2 e w \bar{v}_2 = \bar{v}_3 \times v_1 = 2ew vˉ2=vˉ3×v1=2ew, v ˉ 1 = v ˉ 3 × v 2 = 2 e x \bar{v}_1 = \bar{v}_3 \times v_2 = 2ex vˉ1=vˉ3×v2=2ex。
- 通过反向伴随计算得到 v ˉ 1 = ∂ f ∂ v 1 = v ˉ 3 ∂ v 3 ∂ v 1 = v ˉ 3 × v 2 \bar{v}_1 = \frac{\partial f}{\partial v_1} = \bar{v}_3 \frac{\partial v_3}{\partial v_1} = \bar{v}_3 \times v_2 vˉ1=∂v1∂f=vˉ3∂v1∂v3=vˉ3×v2,即 ∂ L ∂ w = 2 e x \frac{\partial L}{\partial w} = 2ex ∂w∂L=2ex
这种计算方式更加直观更加高效,比第二讲里好多了。

软件中的深度前馈网络
Matlab Deep Learning Toolbox
% define the deep feedforward network layers
layers = [featureInputLayer(num_features)
fullyConnectedLayer(12)
reluLayer
fullyConnectedLayer(8)
reluLayer
fullyConnectedLayer(num_classes)
softmaxLayer
classificationLayer];
% Specify the training options
options = trainingOptions("sgdm", ...
"MiniBatchSize",10, ...
"MaxEpochs",50, ...
"InitialLearnRate",1e-3, ...
"ValidationData",{X_val,Y_val}, ...
"Verbose",true, ...
"Plots","training-progress");
% Train the network using the training data
net = trainNetwork(X_train,Y_train,layers,options);
Python with Keras-Tensorflow
# import libraries and data
from keras.models import Sequential
from keras.layers import Dense
# define the deep feedforward network in keras
model = Sequential()
model.add(Dense(12,
input_shape=(num_features,), activation="relu"))
model.add(Dense(8, activation="relu"))
model.add(Dense(num_classes, activation="softmax"))
# analyze model
model.summary()
# compile the keras model
model.compile(loss="categorical_crossentropy",
optimizer="sgd", metrics=["accuracy"])
# fit the keras model on the dataset
history = model.fit(X_train, Y_train, epochs=20,
batch_size=10, validation_data=(X_val, Y_val))
总结
- 网络构建基础:深度前馈网络建立在简单线性函数的深度链上。这意味着网络由多层简单的线性变换依次连接构成,通过这种层次结构来学习复杂的模式。
- 隐藏层特点:隐藏层的输出通常会经过修正线性单元(ReLU)激活函数。ReLU函数能够为网络引入非线性,使得网络可以学习和表示更复杂的非线性关系,增强了模型的表达能力。
- 输出层差异:
- 回归任务:输出单元是全连接的(即线性的)。回归任务旨在预测连续的数值,线性的输出层可以直接输出预测值。
- 多分类任务:采用Softmax激活函数。Softmax函数将输出转换为概率分布,使得所有类别的概率之和为1,从而可以判断样本属于各个类别的概率。
- 训练方法:反向传播用于训练深度前馈网络(将损失函数的梯度通过网络反向传播)。反向传播算法利用自动微分的原理,高效地计算损失函数关于网络参数的梯度,进而更新参数以最小化损失,优化网络性能。
引用
- Baydin, A. G., Pearlmutter, B. A., Radul, A. A., & Siskind, J. M. (2018). Automatic differentiation in machine learning: a survey. Journal of Machine Learning Research, 18, 1 - 43.