商品中心—11.商品B端搜索系统的实现文档二
大纲
1.商品数据管理以及binlog监听
2.基于ES的商品B端搜索系统架构设计
3.商品B端搜索系统实现步骤介绍
4.步骤一:ES生产集群部署
5.步骤二:IK分词器改造和部署
6.步骤三:为商品数据设计和创建索引
7.步骤四:为商品数据生成索引
8.步骤四:基于索引实现搜索功能
9.步骤五:大数据量写入ES和搜索性能的调优
10.elasticsearch-analysis-ik⼯程的表结构
11.elasticsearch-analysis-ik⼯程的执行步骤
12.elasticsearch-analysis-ik⼯程的代码
13.demo-product-es⼯程的介绍
14.demo-product-es⼯程的商品索引
15.demo-product-es⼯程的suggest索引
16.demo-product-es⼯程的搜索相关接⼝
9.步骤五:大数据量写入ES和搜索性能的调优
(1)单线程将百万商品数据写入ES
(2)多线程将百万商品数据写入ES
(3)数据写入到ES的存储层原理简析
(4)将数据写入到ES的性能影响因素
(5)全量数据写入ES的性能调优方案
(6)百万商品数据写入ES的调优性能
(7)亿级商品数据的搜索性能测试
(8)ES搜索性能优化的方案分析
(1)单线程将百万商品数据写入ES
一.创建索引
PUT /demo_plan_sku_index_01
{ "settings": {"number_of_shards": 3,"number_of_replicas": 1},"mappings": {"properties": {"skuId": {"type": "keyword"},"skuName": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"},"category": {"type": "keyword"},"basePrice": {"type": "integer"},"vipPrice": {"type": "integer"},"saleCount": {"type": "integer"},"commentCount": {"type": "integer"},"skuImgUrl": {"type": "keyword","index": false},"createTime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"updateTime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"}}}
}二.请求接口
/api/mockData/mockData1三.请求参数
写入demo_plan_sku_index_01索引,每次批量插入1000条商品数据,一共执行1000次批量插入。
{"indexName":"demo_plan_sku_index_01","batchSize":1000,"batchTimes":1000
}四.请求响应
该次测试耗时62s,写入了100万条数据。每个线程每秒可以写入1.6万条数据,所以单线程每秒差不多执行了16个BulkRequest批量写入。60ms可以执行一次BulkRequest批量写入,每个BulkRequest会包含1000条数据。100万条数据大概会占用几百MB,所以很多数据都可以驻留在ES机器的OS Cache里,有利搜索。

{ "success": true,"data": {"totalCount": 1000000,"elapsedSeconds": 62,"perSecond": 16130},"errorCode": null,"errorMessage": null
}(2)多线程将百万商品数据写入ES
一.创建索引
//demo_plan_sku_index_02和demo_plan_sku_index_03一样的
PUT /demo_plan_sku_index_02
{"settings": {"number_of_shards": 3,"number_of_replicas": 1},"mappings": {"properties": {"skuId": {"type": "keyword"},"skuName": { "type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"},"category": {"type":"keyword"},"basePrice": {"type": "integer"},"vipPrice": {"type": "integer"},"saleCount": {"type": "integer"},"commentCount": {"type": "integer"},"skuImgUrl": {"type": "keyword","index": false},"createTime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"updateTime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"}}}
}二.请求接口
/api/mockData/mockData2三.请求参数
操作demo_plan_sku_index_02索引,每次批量插⼊1000条商品数据,⼀共执⾏1000次批量插⼊,使⽤30个线程同时执⾏。
{"indexName": "demo_plan_sku_index_02","batchSize": 1000,"batchTimes": 1000,"threadCount": 30
}操作demo_plan_sku_index_03索引,每次批量插⼊1000条商品数据,⼀共执⾏1000次批量插⼊,使⽤60个线程同时执⾏。
{"indexName": "demo_plan_sku_index_03","batchSize": 1000,"batchTimes": 1000,"threadCount": 60
}四.请求响应
该次测试耗时11秒,每秒写入9万条数据,总共使用11秒完成100万条数据的写入。由于有30个线程在并发地一起跑,所以每个线程每秒可以写入3000条数据。即每个线程每秒能将3个BulkRequest批量写入到ES,每个BulkRequest的写入需要300ms左右。
对比单线程写入百万数据到ES时,每个线程每秒可以写入1.6万条数据。而这里多线程写入百万数据到ES时,每个线程每秒才写入3000天数据。
可见,并不是线程数量越多越好。线程数量越多会导致对CPU负载和消耗越大,要耗费更多时间进行线程上下文切换。CPU负载高了之后,线程处理同样的任务,吞吐量和速率会下降。CPU只要不超过80%,其实都可以接受。

//下面是30个线程时的响应
{"success": true,"data": {"totalCount": 1000000,"elapsedSeconds": 11,"perSecond": 90909},"errorCode": null,"errorMessage": null
}
//下面是60个线程时的响应
{"success": true,"data": {"totalCount": 1000000,"elapsedSeconds": 10,"perSecond": 100000},"errorCode": null,"errorMessage": null
}总结:多线程 + Bulk批量写入,10秒就可以完成百万级数据的写入。会有一个最佳的线程数,超过这个临界点,线程数越多反而效果会下降。
(3)数据写入到ES的存储层原理简析
首先ES会将收到的写入请求,将数据写到一个叫index buffer的JVM缓冲区中。然后会有一个线程,每隔1秒定时将这个JVM缓冲区的数据refresh刷新到OS Page Cache。当数据刷到OS Page Cache时,就可以被ES搜索到了。过一段时间后,OS Page Cache的数据会被flush到ES的磁盘文件里。
为了保证数据不丢失,会把数据也写入到内存translog里面,默认内存translog会每隔5秒进行刷盘到translog磁盘文件。
写入到单节点的数据还会进行副本复制到其他节点。
(4)将数据写入到ES的性能影响因素
因素一:refresh间隔,默认会每隔1秒刷新JVM缓冲的数据到OS Page Cache。这会影响数据写入的速度,在写入全量数据的场景,可以将间隔调大一点。比如120秒,通过减少频繁的refresh来提升性能。
因素二:副本复制会影响写入的速度。在写入全量数据的场景,同样没必要进行副本的复制。可以先将数据都写入到一个节点,之后再慢慢进行副本的复制。
因素三:index buffer的大小。在写入全量数据的场景,可以调大index buffer的大小。
因素四:translog的刷盘策略。在写入全量数据的场景,可以调整translog为异步刷盘,并且刷盘间隔调大一些。存放translog的内存大小也调大一些,让其存放更多的数据才去进行刷盘。
(5)全量数据写入ES的性能调优方案
下面这些参数的调整是针对写入全量数据的场景,全量写入完毕后应恢复原来的值。
一.调整refresh_interval参数(可以动态配置)。在全量写⼊数据的场景下,对"写⼊后1s就要能搜索到"的要求没有那么⾼。所以可以把这个值设置为120s,来减少频繁的refresh和lucene段合并⾏为。

二.调整number_of_replicas参数(可以动态配置)。ElasticSearch的副本数是可以动态调整的,写⼊时可以先把副本数设置为0,缩短数据写⼊的流程。批量导⼊完成之后,重新设置回副本数。

三.调整index_buffer_size参数。把JVM缓冲区的大小调大,可以让数据先写入到内存。避免JVM缓存区内存太小,很快写满而需要频繁刷盘。

四.调整translog参数(可以动态配置)。把translog的相关参数调大,避免尽量触发translog刷盘策略。

综上可知:首先在elasticsearch.yml中修改ES的配置,然后重启ES集群的三个节点。
$ vi /app/elasticsearch/elasticsearch-7.9.3/config/elasticsearch.yml
# 写⼊优化参数
indices.memory.index_buffer_size: 30%
indices.memory.min_index_buffer_size: 128m然后在创建索引时对索引进行如下配置:
{"settings": {"number_of_shards": 3,"number_of_replicas": 0,"index.refresh_interval": "120s","index.translog.durability": "async","index.translog.sync_interval": "120s","index.translog.flush_threshold_size": "2048mb"}
}(6)百万商品数据写入ES的调优性能
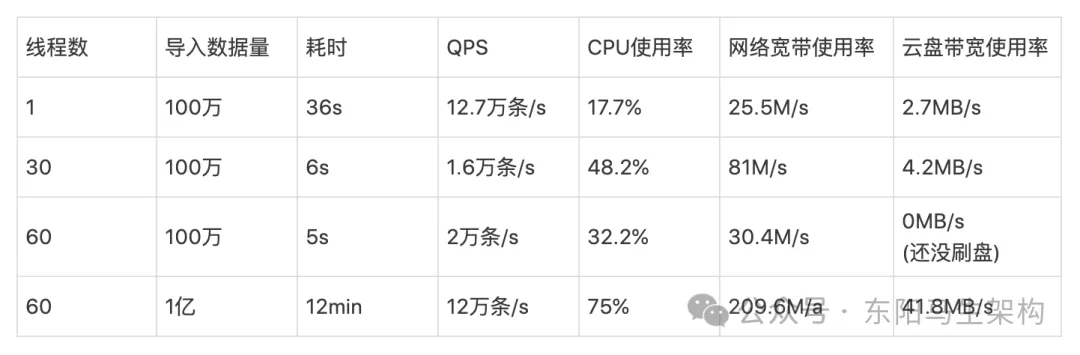
可见,调优后的写入性能提升了一倍多。完成全量数据写入ES后,就可以动态调整索引的settings来恢复默认的配置。
(7)亿级商品数据的搜索性能测试
一.全文搜索测试
请求接口:
/api/product/fullTextSearch请求参数:
{"pageNum": 1,"pageSize": 100,"indexName": "demo_plan_sku_index","highLightField": "skuName","queryTexts": {"skuName": "华为⼿机"}
}比如搜索"华为手机",那么首先会对搜索词使用ik_smart进行分词,分成"华为"和"手机",之后再去倒排索引里对"华为"和"手机"这两分词进行搜索。
在上亿的商品数据里进行全文检索,耗时几百ms算是很快了,符合标准。查询多次的耗时详情如下,其中匹配的文档数有35万。

二.结构化搜索测试
请求接口:
/api/product/structuredSearch请求参数:
{"pageNum": 1,"pageSize": 100,"indexName": "career_plan_sku_index","queryDsl": {"query": {"bool": {"must": [{"term": {"category": {"value": "⼿机"}}}],"filter": [{"range": {"basePrice": {"gte": 1000,"lte": 3000}}}]}},"sort": [{"basePrice": {"order":"desc"}}]}
}比如搜索手机分类下的商品按某价格区间倒序排列,刚开始需要花几秒。因为首先根据分类和价格区间去索引里查找数据,之后还需要按照价格排序。排序的过程可能会导致大量数据从磁盘读入内存,再写入临时磁盘文件进行排序,排序之后还需要分页提取。所以第一次整个过程比较慢。
后续再次搜索时,大量数据已经读入内存,不用再去进行磁盘IO了,所以会变快。查询多次的耗时详情如下,其中匹配的文档数有35万。

(8)ES搜索性能优化的方案分析
ES的性能是特别棒的,在合理的机器配置下,其实是不怎么需要做优化的。当我们的业务遇到查询瓶颈时再根据业务场景的特点从以下⼏点看看哪个能再去优化。而且ES比较适合全文检索,根据分词进行匹配打分排序,在上亿数据量之下也有非常好的搜索效果。但是ES面对结构化搜索则不稳定,使用多个条件来进行查询、按照指定条件进行排序,可能性能很差。因为其中可能会命中大量数据,然后产生大量的临时磁盘IO。
一.ES的查询缓存会保存在OS内存中。所以需要给操作系统的内存保留足够空间,不过一般都会把机器内存的一半给JVM,另一半给OS Cache。
二.磁盘IO性能和CPU性能。对于普通的搜索,磁盘IO的性能最影响搜索性能。对与计算⽐较多的搜索,CPU的性能会是⼀个瓶颈。
三.建立预索引Pre-Index。适⽤于数字类型的字段和经常做范围搜索的场景,比如可以把数字类型的字段转换成keyword类型的字段,把range查询转换为terms查询。
四.把long类型的skuID设置为keyword类型
五.强制合并一些只读的索引,避免从多个磁盘文件去搜索。
总结:最关键的其实是给OS Cache多预留一些内存,尽量让节点的数据都能加载到内存里。比如节点是32G内存的,16G给JVM,16G给OS Cache,然后节点的数据也控制好在16G内。否则如果OS Cache才16G,但节点的数据已经几百G了,那搜索时必然会进行大量的磁盘IO。也就是要想让ES提升搜索性能,主要靠将数据驻留在OS Cache里。所以要用大内存机器部署ES节点,尽量让每个节点上的主shard的数据量和OS Cache的内存量差不多。这样在搜索时,尽可能去OS Cache里查询数据,从而避免进行磁盘IO。
10.elasticsearch-analysis-ik⼯程的表结构
⼀共有两张表:extension_word扩展词库表,stop_word停⽤词库表。
CREATE TABLE `extension_word` (`id` int(11) NOT NULL AUTO_INCREMENT,`word` varchar(64) NOT NULL,`create_time` datetime NOT NULL,`update_time` datetime NOT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `stop_word` (`id` int(11) NOT NULL AUTO_INCREMENT,`word` varchar(64) NOT NULL,`create_time` datetime NOT NULL,`update_time` datetime NOT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;11.elasticsearch-analysis-ik⼯程的执行步骤
步骤一:读取数据库连接配置⽂件
步骤二:连接数据库
步骤三:查询扩展词库表和停⽤词库表
步骤四:添加到字典中
步骤五:使⽤⼀个线程周期性执⾏上⾯2-4步
12.elasticsearch-analysis-ik⼯程的代码
(1)添加的DictLoader类
(2)修改自带的Dictionary类
(1)添加的DictLoader类
代码位置:
org.wltea.analyzer.dic.DictLoader//加载MySQL中的词库内容,单例
public class DictLoader {private static final Logger LOGGER = ESPluginLoggerFactory.getLogger(DictLoader.class.getName());private static final DictLoader INSTANCE = new DictLoader();private final String url;private final String username;private final String password;private final AtomicBoolean extensionWordFistLoad = new AtomicBoolean(false);private final AtomicReference<String> extensionWordLastLoadTimeRef = new AtomicReference<>(null);private final AtomicBoolean stopWordFistLoad = new AtomicBoolean(false);private final AtomicReference<String> stopWordLastLoadTimeRef = new AtomicReference<>(null);//单例类,构造函数是私有的private DictLoader() {//创建一个Properties配置数据对象,用来获取MySQL JDBC连接的配置Properties mysqlConfig = new Properties();//PathUtils会从指定目录下,对指定的文件名进行拼接,然后返回全路径名//所以这里会把"IK分词器配置目录 + jdbc.properties"拼接成"jdbc.properties的成全路径名"Path configPath = PathUtils.get(Dictionary.getSingleton().getDictRoot(), "jdbc.properties");try {//根据全路径名构建输入流,然后加载到mysqlConfig对象中,这样就可以从mysqlConfig对象读取配置值了mysqlConfig.load(new FileInputStream(configPath.toFile()));this.url = mysqlConfig.getProperty("jdbc.url");this.username = mysqlConfig.getProperty("jdbc.username");this.password = mysqlConfig.getProperty("jdbc.password");} catch (IOException e) {throw new IllegalStateException("加载jdbc.properties配置文件发生异常");}try {//加载MySQL驱动的类Class.forName("com.mysql.cj.jdbc.Driver");} catch (ClassNotFoundException e) {throw new IllegalStateException("加载数据库驱动时发生异常");}}public static DictLoader getInstance() {return INSTANCE;}public void loadMysqlExtensionWords() {//每次从MySQL里加载词库时会执行一条SQL语句//这时就必须要有一个和MySQL之间建立的网络连接,才能发送SQL语句出去//由于这里会每分钟执行一次SQL语句//所以每次执行SQL语句的时候就创建一个数据库的网络连接Connection,执行完SQL后再把该Connection释放即可Connection connection = null;Statement statement = null;ResultSet resultSet = null;String sql;//第一次执行时会通过CAS操作把extensionWordFistLoad变量由false改成true,并且查全量词汇//之后的执行,extensionWordFistLoad变量已经变为true,所以CAS操作会不成功,于是只查增量词汇if (extensionWordFistLoad.compareAndSet(false, true)) {//首次加载会从数据库查全量的词汇sql = "SELECT word FROM extension_word";} else {//后面按照最近的修改时间来加载增量的词sql = "SELECT word FROM extension_word WHERE update_time >= '" + extensionWordLastLoadTimeRef.get() + "'";}//每次生成了加载词库的SQL后,都会去设置一个本次加载的时间SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");String nowString = dateFormat.format(new Date());//设置最近一次加载词库的时间,extensionWordLastLoadTimeRef也是Atomic变量,线程安全的extensionWordLastLoadTimeRef.set(nowString);//加载扩展词词库内容try {//使用传统的JDBC编程获取连接connection = DriverManager.getConnection(url, username, password);//创建statementstatement = connection.createStatement();//执行SQL语句获取结果集resultSet = statement.executeQuery(sql);LOGGER.info("从MySQL加载extensionWord, sql={}", sql);Set<String> extensionWords = new HashSet<>();while (resultSet.next()) {String word = resultSet.getString("word");if (word != null) {extensionWords.add(word);//为了方便看日志,可以把加载到的扩展词全都打印出来了LOGGER.info("从MySQL加载extensionWord, word={}", word);}}//放到字典里Dictionary.getSingleton().addWords(extensionWords);} catch (Exception e) {LOGGER.error("从MySQL加载extensionWord发生异常", e);} finally {//把结果集resultSet、statement、连接connection都进行释放if (resultSet != null) {try {resultSet.close();} catch (SQLException e) {LOGGER.error(e);}}if (statement != null) {try {statement.close();} catch (SQLException e) {LOGGER.error(e);}}if (connection != null) {try {connection.close();} catch (SQLException e) {LOGGER.error(e);}}}}public void loadMysqlStopWords() {Connection connection = null;Statement statement = null;ResultSet resultSet = null;String sql;if (stopWordFistLoad.compareAndSet(false, true)) {sql = "SELECT word FROM stop_word";} else {sql = "SELECT word FROM stop_word WHERE update_time >= '" + stopWordLastLoadTimeRef.get() + "'";}SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");String nowString = dateFormat.format(new Date());stopWordLastLoadTimeRef.set(nowString);//加载词库内容try {connection = DriverManager.getConnection(url, username, password);statement = connection.createStatement();resultSet = statement.executeQuery(sql);LOGGER.info("从MySQL加载stopWord, sql={}", sql);Set<String> stopWords = new HashSet<>();while (resultSet.next()) {String word = resultSet.getString("word");if (word != null) {stopWords.add(word);LOGGER.info("从MySQL加载stopWord,word={}", word);}}// 放到字典里Dictionary.getSingleton().addStopWords(stopWords);} catch (Exception e) {LOGGER.error("从MySQL加载extensionWord发生异常", e);} finally {if (resultSet != null) {try {resultSet.close();} catch (SQLException e) {LOGGER.error(e);}}if (statement != null) {try {statement.close();} catch (SQLException e) {LOGGER.error(e);}}if (connection != null) {try {connection.close();} catch (SQLException e) {LOGGER.error(e);}}}}
}(2)修改自带的Dictionary类
代码位置:
org.wltea.analyzer.dic.Dictionary#initialpublic class Dictionary {...//词典单例实例private static Dictionary singleton;private static ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);...//词典初始化//由于IK Analyzer的词典采用Dictionary类的静态方法进行词典初始化//只有当Dictionary类被实际调用时才会开始载入词典,这将延长首次分词操作的时间//该方法提供了一个在应用加载阶段就初始化字典的手段public static synchronized void initial(Configuration cfg) {if (singleton == null) {synchronized (Dictionary.class) {if (singleton == null) {singleton = new Dictionary(cfg);singleton.loadMainDict();singleton.loadSurnameDict();singleton.loadQuantifierDict();singleton.loadSuffixDict();singleton.loadPrepDict();singleton.loadStopWordDict();//在这里开启一个线程,每隔一段时间去mysql里面加载一下词库里的内容new Thread(() -> {while (true) {try {DictLoader.getInstance().loadMysqlExtensionWords();DictLoader.getInstance().loadMysqlStopWords();TimeUnit.SECONDS.sleep(60);} catch (InterruptedException e) {e.printStackTrace();}}}).start();if (cfg.isEnableRemoteDict()) {//建立监控线程for (String location : singleton.getRemoteExtDictionarys()) {//10秒是初始延迟可以修改的,60是间隔时间,单位秒pool.scheduleAtFixedRate(new Monitor(location), 10, 60, TimeUnit.SECONDS);}for (String location : singleton.getRemoteExtStopWordDictionarys()) {pool.scheduleAtFixedRate(new Monitor(location), 10, 60, TimeUnit.SECONDS);}}}}}}...
}13.demo-product-es⼯程的介绍
(1)该⼯程⾥⾯有两个搜索相关的接⼝
(2)该工程有两个对⽤户输⼊进⾏处理的接⼝
(3)该工程有三个初始化数据的接⼝
(1)该⼯程⾥⾯有两个搜索相关的接⼝
一.全⽂搜索接⼝
二.结构化查询接⼝
(2)该工程有两个对⽤户输⼊进⾏处理的接⼝
一.输⼊内容⾃动补全接⼝
二.输⼊内容拼写纠错接⼝
(3)该工程有三个初始化数据的接⼝
一.单线程批量插⼊商品数据接⼝
二.多线程批量插⼊商品数据接⼝
三.单线程批量插⼊suggest数据接⼝
该⼯程依赖了ElasticSearch的rest⾼级客户端库:elasticsearch-rest-high-level-client,所有对ElasticSearch的操作都是通过rest⾼级客户端库来完成的。
14.demo-product-es⼯程的商品索引
(1)索引结构
(2)数据类型说明
(3)使⽤的数据类型说明
商品索引⽤来存储所有的商品信息。
(1)索引结构
商品模型的字段以满⾜测试需要为主不复杂,⼀共有10个字段。商品的索引名为:demo_plan_sku_index_序号。因为需要做多次不同的测试,有的测试是使⽤不同的索引,⽽且在实现接⼝时并没有把接⼝写死,可以指定操作那个索引,所以索引后⾯加了⼀个序号。
索引的mappings如下:
PUT /demo_plan_sku_index_15 { "settings": {"number_of_shards": 3,"number_of_replicas": 1},"mappings": {"properties": {"skuId": {"type": "keyword"},"skuName": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"},"category": {"type": "keyword"},"basePrice": {"type": "integer"},"vipPrice": {"type": "integer"},"saleCount": {"type": "integer"},"commentCount": {"type": "integer"},"skuImgUrl": {"type": "keyword","index": false},"createTime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"updateTime": {"type": "date","format": "yyyy-MM-dd HH:mm:ss"}}}
}(2)数据类型说明
elasticsearch相关⽂档链接:
数据类型⽂档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/mapping-types.htmltext数据类型⽂档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/text.htmlkeyword数据类型⽂档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/keyword.html数字类型⽂档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/number.html时间类型⽂档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/number.html(3)使⽤的数据类型说明
一.skuName商品名称
商品名称是⼀个字符串。我们要对商品名称进⾏全⽂检索,所以skuName字段使⽤了text类型。⽤analyzer指定使⽤ik_max_word分词器,这样在保存数据时商品名称会被尽可能多的分为多个词。⽤search_analyzer指定搜索时使⽤ik_smart分词器,这样尽可能做更符合⽤户期望的分词。
二.skuId商品id
商品id⼀般是⼀个long类型的数字。我们可以使⽤ElasticSearch的数字类型,但是我们使⽤的是keyword类型。因为⽂档⾥建议:如果没有要范围查询场景,且期望查询速度更快,数字类型的字段应使⽤keyword类型。对于商品id来说,正好是⽂档中所说的情况。
⽂档链接:
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/number.html三.category商品分类
商品分类是⼀个字符串。我们不会对商品分类做全⽂检索,⽽是对商品分类做term精准匹配的操作,所以使⽤keyword类型。
四.basePrice商品价 | vipPrice商品会员价 | saleCount商品销量 | commentCount商品评论数
这⼏个字段都是数字。对于数字类型字段,⽂档中提到应在满⾜使⽤场景要求的情况下使⽤占⽤空间更⼩的类型,这⾥我们都使⽤Integer类型。
⽂档链接:
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/number.html五.skuImgUrl商品图⽚
商品图⽚是⼀个图⽚的url地址。我们不会对这个字段做任何搜索操作,也不需要索引这个字段,所以使⽤了index:false 指定了不要索引这个字段。
⽂档链接:
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/keyword.html六.createTime创建时间和updateTime修改时间
这两个字段是时间类型的字段,对应的ElasticSearch类型为date,然后使⽤了format指定了时间的格式。
15.demo-product-es⼯程的suggest索引
(1)索引结构
(2)数据类型说明
suggest索引⽤来存储和⽤户输⼊⾃动补全、拼写纠错、搜索推荐相关的数据的索引。这里的搜索推荐指的是:当没有⽤户要搜索的商品时推荐其他的商品。
(1)索引结构
⼀共有两个字段:word1是⽤来做⾃动补全的,word2是⽤来做拼写纠错和搜索推荐的。
索引的mapping如下:
PUT /demo_plan_sku_suggest_15
{"settings": {"number_of_shards": 3,"number_of_replicas": 1,"analysis": {"analyzer": {"ik_and_pinyin_analyzer": {"type": "custom","tokenizer": "ik_smart","filter": "my_pinyin"}},"filter": {"my_pinyin": {"type": "pinyin","keep_first_letter": true,"keep_full_pinyin": true,"keep_original": true,"remove_duplicated_term": true}}}},"mappings": {"properties": {"word1": {"type": "completion","analyzer": "ik_and_pinyin_analyzer"},"word2": {"type": "text"}}}
}(2)数据类型说明
word1⽤来做⾃动补全的,ElasticSearch中有专⻔对应的completion数据类型。
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/mapping-types.html在上⾯创建索引时我们⾃⼰定义了⼀个analyzer:ik_and_pinyin_analyzer,这个analyzer同时使⽤了ik分词器和pinyin分词器,这样⽤户输⼊汉字或者拼⾳的时候都能做⾃动补全。
16.demo-product-es⼯程的搜索相关接⼝
(1)全⽂搜索接⼝
(2)结构化查询接口
(3)用户输入自动补全处理接口
(4)输⼊内容拼写纠错接⼝
(5)输入内容推荐接口
(6)单线程批量插⼊商品数据接⼝
(7)多线程批量插⼊商品数据接⼝
(8)单线程批量插⼊suggest数据接⼝
(1)全⽂搜索接⼝
一.描述
按照⽤户输⼊的关键词在商品索引中以match query的⽅式搜索符合条件的商品。
二.controller实现
代码位置:
com.dem.elasticsearch.controller.ProductSearchController#fullTextSearch//商品全文检索接口
@GetMapping("/fullTextSearch")
public JsonResult fullTextSearch(@RequestBody FullTextSearchRequest request) throws IOException {SearchResponse searchResponse = productService.fullTextSearch(request);Map<String, Object> resultMap = new HashMap<>();SearchHit[] hits = searchResponse.getHits().getHits();long totalCount = searchResponse.getHits().getTotalHits().value;resultMap.put("hits", hits);resultMap.put("totalCount", totalCount);resultMap.put("pageNum", request.getPageNum());resultMap.put("pageSize", request.getPageSize());return JsonResult.buildSuccess(resultMap);
}三.参数说明

四.返回值说明

五.Service实现
代码位置:
com.demo.elasticsearch.service.impl.ProductServiceImpl#fullTextSearch@Override
public SearchResponse fullTextSearch(FullTextSearchRequest request) throws IOException {SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.trackTotalHits(true);//1.构建match条件request.getQueryTexts().forEach((field, text) -> {searchSourceBuilder.query(QueryBuilders.matchQuery(field, text));});//2.设置搜索高亮配置(现在基本面向移动端,所以高亮处理也没太必要)HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.field(request.getHighLightField());highlightBuilder.preTags("<span stype=color:red>"); //搜索结果里,商品标题和搜索词匹配的部分会显示为红色highlightBuilder.postTags("</span>");highlightBuilder.numOfFragments(0);searchSourceBuilder.highlighter(highlightBuilder);//3.设置搜索分页参数int from = (request.getPageNum() - 1) * request.getPageSize();searchSourceBuilder.from(from);searchSourceBuilder.size(request.getPageSize());//4.封装搜索请求SearchRequest searchRequest = new SearchRequest(request.getIndexName());searchRequest.source(searchSourceBuilder);//5.查询ElasticSearchSearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);//6.对结果进行高亮处理SearchHits hits = searchResponse.getHits();for (SearchHit hit : hits) {HighlightField highlightField = hit.getHighlightFields().get(request.getHighLightField());Map<String, Object> sourceAsMap = hit.getSourceAsMap();Text[] fragments = highlightField.fragments();StringBuilder builder = new StringBuilder();for (Text fragment : fragments) {builder.append(fragment.string());}sourceAsMap.put(request.getHighLightField(), builder.toString());}return searchResponse;
}六.ElasticSearch相关文档
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/query-dsl-match-query.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/highlighting.html
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.9/java-rest-high-search.html
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.9/java-rest-high-search.html#java-rest-high-search-response-search-hits
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.9/java-rest-high-search.html#java-rest-high-search-response-highlighting(2)结构化查询接口
一.描述
按照⽤户指定的过滤条件、排序⽅式以term query的⽅式搜索服务条件的商品。代码⾥没有写任何固定的根据某个字段做term query,或者根据某个字段的范围区间过滤、或者根据某个字段排序的逻辑,⽽是通过传递⼀个queryDSL脚本作为参数,解析这个queryDSL脚本来执⾏查询操作,这样接⼝更加抽象可以满⾜不同场景的搜索,只要前端拼接参数。
二.Controller实现
代码位置:
com.demo.elasticsearch.service.impl.ProductServiceImpl#structuredSearch//商品结构化搜索接口
@GetMapping("/structuredSearch")
public JsonResult structuredSearch(@RequestBody StructuredSearchRequest request) throws IOException {SearchResponse searchResponse = productService.structuredSearch(request);Map<String, Object> resultMap = new HashMap<>();SearchHit[] hits = searchResponse.getHits().getHits();long totalCount = searchResponse.getHits().getTotalHits().value;resultMap.put("hits", hits);resultMap.put("totalCount", totalCount);resultMap.put("pageNum", request.getPageNum());resultMap.put("pageSize", request.getPageSize());return JsonResult.buildSuccess(resultMap);
}三.参数说明

四.返回值说明

五.Service实现
代码位置:
com.demo.elasticsearch.service.impl.ProductServiceImpl#structuredSearch@Override
public SearchResponse structuredSearch(StructuredSearchRequest request) throws IOException {SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.trackTotalHits(true);//1.解析queryDSLString queryDsl = JSON.toJSONString(request.getQueryDsl());SearchModule searchModule = new SearchModule(Settings.EMPTY, false, Collections.emptyList());NamedXContentRegistry namedXContentRegistry = new NamedXContentRegistry(searchModule.getNamedXContents());XContent xContent = XContentFactory.xContent(XContentType.JSON);XContentParser xContentParser = xContent.createParser(namedXContentRegistry, LoggingDeprecationHandler.INSTANCE, queryDsl);searchSourceBuilder.parseXContent(xContentParser);//2.设置搜索分页参数int from = (request.getPageNum() - 1) * request.getPageSize();searchSourceBuilder.from(from);searchSourceBuilder.size(request.getPageSize());//3.封装搜索请求SearchRequest searchRequest = new SearchRequest(request.getIndexName());searchRequest.source(searchSourceBuilder);//4.查询ElasticSearchreturn restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
}(3)用户输入自动补全处理接口
一.描述
当⽤户在搜索框输⼊内容时,前端可以捕获焦点事件,调⽤此接⼝返回⽤户⼀组根据⽤户输⼊补全了的搜索词。
二.Controller实现
代码位置:
com.demo.elasticsearch.controller.CommonSearchController#autoComplete//输入内容自动补全接口
@GetMapping("/autoComplete")
public JsonResult autoComplete(@RequestBody AutoCompleteRequest request) throws IOException {List<String> completedWords = commonSearchService.autoComplete(request);return JsonResult.buildSuccess(completedWords);
}三.参数说明

四.返回值说明

五.Service实现
代码位置:
com.demo.elasticsearch.service.impl.CommonSearchServiceImpl#autoComplete@Override
public List<String> autoComplete(AutoCompleteRequest request) throws IOException {//1.构建CompletionSuggestion条件CompletionSuggestionBuilder completionSuggestionBuilder = SuggestBuilders.completionSuggestion(request.getFieldName());completionSuggestionBuilder.prefix(request.getText());completionSuggestionBuilder.skipDuplicates(true);completionSuggestionBuilder.size(request.getCount());SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC));searchSourceBuilder.suggest(new SuggestBuilder().addSuggestion(MY_SUGGEST, completionSuggestionBuilder));//2.封装搜索请求SearchRequest searchRequest = new SearchRequest();searchRequest.indices(request.getIndexName());searchRequest.source(searchSourceBuilder);//3.查询ElasticSearchSearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);//4.获取响应中的补全的词的列表CompletionSuggestion completionSuggestion = searchResponse.getSuggest().getSuggestion(MY_SUGGEST);List<CompletionSuggestion.Entry.Option> options = completionSuggestion.getEntries().get(0).getOptions();List<String> result = new ArrayList<>();for (CompletionSuggestion.Entry.Option option : options) {result.add(option.getText().string());}return result;
}六.ElasticSearch相关文档
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/search-suggesters.html#completion-suggester(4)输⼊内容拼写纠错接⼝
一.描述
当⽤户在搜索框输⼊内容时,前端可以捕获焦点事件,调⽤此接⼝对⽤户的输⼊进⾏纠错。
二.Controller实现
代码位置:
com.demo.elasticsearch.controller.CommonSearchController#spellingCorrection//输入内容拼写纠错接口
@GetMapping("/spellingCorrection")
public JsonResult spellingCorrection(@RequestBody SpellingCorrectionRequest request) throws IOException {String correctedWord = commonSearchService.spellingCorrection(request);return JsonResult.buildSuccess(correctedWord);
}三.参数说明

四.返回值说明

五.Service实现
代码位置:
com.demo.elasticsearch.service.impl.CommonSearchServiceImpl#spellingCorrection@Override
public String spellingCorrection(SpellingCorrectionRequest request) throws IOException {//1.构建PhraseSuggestion条件PhraseSuggestionBuilder phraseSuggestionBuilder = new PhraseSuggestionBuilder(request.getFieldName());phraseSuggestionBuilder.text(request.getText());phraseSuggestionBuilder.size(1);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC));searchSourceBuilder.suggest(new SuggestBuilder().addSuggestion(MY_SUGGEST, phraseSuggestionBuilder));//2.封装搜索请求SearchRequest searchRequest = new SearchRequest();searchRequest.indices(request.getIndexName());searchRequest.source(searchSourceBuilder);//3.查询ElasticSearchSearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);//4.获取响应中纠错后的词PhraseSuggestion phraseSuggestion = searchResponse.getSuggest().getSuggestion(MY_SUGGEST);List<PhraseSuggestion.Entry.Option> options = phraseSuggestion.getEntries().get(0).getOptions();return Optional.ofNullable(options).filter(e -> !e.isEmpty()).map(e -> e.get(0)).map(e -> e.getText().string()).orElse("");
}六.ElasticSearch相关文档
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/search-suggesters.html#phrase-suggester(5)输入内容推荐接口
一.描述
当按照⽤户的搜索词进行搜索却发现没有搜索到数据时,可以调⽤该接⼝返回推荐搜索词给⽤户。
代码位置:
com.demo.elasticsearch.controller.CommonSearchController#recommendWhenMissing@GetMapping("/recomendWhenMissing")
public JsonResult recommendWhenMissing(@RequestBody RecommendWhenMissingRequest request) throws IOException {String recommendWord = commonSearchService.recommendWhenMissing(request);return JsonResult.buildSuccess(recommendWord);
}三.参数说明

四.返回值说明

五.Service实现
代码位置:
com.demo.elasticsearch.service.impl.CommonSearchServiceImpl#recommendWhenMissing@Override
public String recommendWhenMissing(RecommendWhenMissingRequest request) throws IOException {//1.构建TermSuggestion条件TermSuggestionBuilder termSuggestionBuilder = new TermSuggestionBuilder(request.getFieldName());termSuggestionBuilder.text(request.getText());termSuggestionBuilder.analyzer(IK_SMART);termSuggestionBuilder.minWordLength(2);termSuggestionBuilder.stringDistance(TermSuggestionBuilder.StringDistanceImpl.NGRAM);SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC));searchSourceBuilder.suggest(new SuggestBuilder().addSuggestion(MY_SUGGEST, termSuggestionBuilder));//2.封装搜索请求SearchRequest searchRequest = new SearchRequest();searchRequest.indices(request.getIndexName());searchRequest.source(searchSourceBuilder);//3.查询ElasticSearchSearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);//4.获取响应中推荐给用户的词TermSuggestion termSuggestion = searchResponse.getSuggest().getSuggestion(MY_SUGGEST);List<TermSuggestion.Entry.Option> options = termSuggestion.getEntries().get(0).getOptions();return Optional.ofNullable(options).map(e -> e.get(0)).map(e -> e.getText().string()).orElse("");
}六.ElasticSearch相关文档
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/search-suggesters.html#term-suggester(6)单线程批量插⼊商品数据接⼝
一.描述
⽤来初始化数据以及测试在单线程下ElasticSearch Bulk插⼊⽂档的性能。
二.Controller实现
代码位置:
com.demo.elasticsearch.controller.MockDataController#mockData1//单线程向ES写入模拟的商品索引数据
//真正在生产环境下,不可能使用单个线程处理一个一个batch写入来实现大批量数据的写入
//实现这个方法主要是用来和接下来的多线程批量写入的方法进行性能对比
//https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.9/java-rest-high-document-bulk.html
@PostMapping("/mockData1")
public JsonResult mockData1(@RequestBody MockData1Dto request) throws IOException {if (!request.validateParams()) {return JsonResult.buildError("参数有误");}//索引名字String indexName = request.getIndexName();//一次批量写入多少数据int batchSize = request.getBatchSize();//进行批量写入的次数int batchTimes = request.getBatchTimes();//1.从txt文件里面加载10w条商品数据,大小才13M,可以全部一次读出来List<Map<String, Object>> skuList = loadSkusFromTxt();long startTime = System.currentTimeMillis();//2.每次随机取出batchSize个商品数据,然后批量写入,一共执行batchTimes次for (int i = 0; i < batchTimes; i++) {//把指定的batchSize条数据打包成一个BulkRequest对象BulkRequest bulkRequest = buildSkuBulkRequest(indexName, batchSize, skuList);//然后调用ES的restHighLevelClient.bulk()接口,将BulkRequest对象写入到ES里去restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);log.info("写入[{}]条商品数据", batchSize);}long endTime = System.currentTimeMillis();//3.记录统计信息int totalCount = batchSize * batchTimes;long elapsedSeconds = (endTime - startTime) / 1000;long perSecond = totalCount / elapsedSeconds;log.info("此次共导入[{}]条商品数据,耗时[{}]秒,平均每秒导入[{}]条数据", totalCount, elapsedSeconds, perSecond);Map<String, Object> result = new LinkedHashMap<>();result.put("startTime", DateUtil.format(new Date(startTime), DatePattern.NORM_DATETIME_PATTERN));result.put("endTime", DateUtil.format(new Date(endTime), DatePattern.NORM_DATETIME_PATTERN));result.put("totalCount", totalCount);result.put("elapsedSeconds", elapsedSeconds);result.put("perSecond", perSecond);return JsonResult.buildSuccess(result);
}三.参数说明

四.返回值说明

五.ElasticSearch相关文档
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.9/java-rest-high-document-bulk.html(7)多线程批量插⼊商品数据接⼝
一.描述
⽤来初始化数据以及测试在多线程下ElasticSearch Bulk插⼊⽂档的性能。
二.Controller实现
代码位置:
com.demo.elasticsearch.controller.MockDataController#mockData2//多线程向ES写入模拟的商品索引数据
@PostMapping("/mockData2")
public JsonResult mockData2(@RequestBody MockData2Dto request) throws IOException, InterruptedException {if (!request.validateParams()) {return JsonResult.buildError("参数有误");}String indexName = request.getIndexName();//需要进行多少次batch批量写入int batchTimes = request.getBatchTimes();//每次batch批量写入多少条数据int batchSize = request.getBatchSize();//可以同时执行batch批量写入的线程数量int threadCount = request.getThreadCount();//读取10万条数据到内存List<Map<String, Object>> skuList = loadSkusFromTxt();//CountDownLatch:一个线程完成任务后才进行countDown,最后countDown到0时才能结束CountDownLatch countDownLatch = new CountDownLatch(batchTimes);//Semaphore:一个线程可以尝试从semaphore获取一个信号,如果获取不到就阻塞等待,获取到了,信号就是这个线程的了//当一个线程执行完其任务之后,会把信号还回去,所以最多只能有threadCount个线程可以获取到信号量Semaphore semaphore = new Semaphore(threadCount);//虽然semaphore可以控制线程池中同时进行的任务数,但是maximumPoolSize也不能设置的和semaphore一样的大小//因为线程池用了SynchronousQueue队列,可能会出现实际需要执行的任务数比semaphore允许数多一两个的情况//不过实际执行任务的线程数最终不会达到threadCount * 2ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(threadCount,threadCount * 2,60,TimeUnit.SECONDS,new SynchronousQueue<>());long startTime = System.currentTimeMillis();//batch数量可以是比线程数量多for (int i = 0; i < batchTimes; i++) {//通过semaphore保证一直最多有threadCount个线程同时在执行批量写入的操作//先获取一个信号量,获取到了就提交任务到线程池执行批量写入的操作,获取不到就阻塞等待有空余的信号量semaphore.acquireUninterruptibly();threadPoolExecutor.submit(() -> {try {BulkRequest bulkRequest = buildSkuBulkRequest(indexName, batchSize, skuList);restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);log.info("线程[{}]写入[{}]条商品数据", Thread.currentThread().getName(), batchSize);} catch (IOException e) {e.printStackTrace();} finally {//从下面两行代码就可以看到,当一个线程刚刚释放完semaphore后,还要执行下一行代码,还没释放线程//这时新一个任务可能就获取到semaphore并提交到线程池了//所以线程池实际需要执行的任务数可能会比semaphore的允许数threadCount多一点semaphore.release();countDownLatch.countDown();}});}long endTime = System.currentTimeMillis();//在这里等待一下最后一个批次的批量写入操作执行完countDownLatch.await();//现在的使用方式,在这里需要手动的把线程池给关掉threadPoolExecutor.shutdown();int totalCount = batchSize * batchTimes;long elapsedSeconds = (endTime - startTime) / 1000;long perSecond = totalCount / elapsedSeconds;log.info("此次共导入[{}]条商品数据,耗时[{}]秒,平均每秒导入[{}]条数据", totalCount, elapsedSeconds, perSecond);Map<String, Object> result = new LinkedHashMap<>();result.put("startTime", DateUtil.format(new Date(startTime), DatePattern.NORM_DATETIME_PATTERN));result.put("endTime", DateUtil.format(new Date(endTime), DatePattern.NORM_DATETIME_PATTERN));result.put("totalCount", totalCount);result.put("elapsedSeconds", elapsedSeconds);result.put("perSecond", perSecond);return JsonResult.buildSuccess(result);
}三.参数说明

四.返回值说明

(8)单线程批量插⼊suggest数据接⼝
一.描述
初始化⽤来处理⽤户输⼊时使⽤的数据。
二.Controller实现
//单线程写入模拟的suggest数据
//https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.9/java-rest-high-document-bulk.html
@PostMapping("/mockData3")
public JsonResult mockData3(@RequestBody MockData3Dto request) throws IOException {if (!request.validateParams()) {return JsonResult.buildError("参数有误");}String indexName = request.getIndexName();int batchTimes = request.getBatchTimes();int batchSize = request.getBatchSize();//1.从txt文件里面加载10w个商品名称List<String> skuNameList = loadSkuNamesFromTxt();long startTime = System.currentTimeMillis();//2.从第1条数据开始导入int index = 0;for (int i = 0; i < batchTimes; i++) {BulkRequest bulkRequest = new BulkRequest(indexName);for (int j = 1; j <= batchSize; j++) {String skuName = skuNameList.get(index);IndexRequest indexRequest = new IndexRequest().source(XContentType.JSON, "word1", skuName, "word2", skuName);System.out.println(skuName);bulkRequest.add(indexRequest);index++;}log.info("开始写入[{}]条suggest数据", batchSize);restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);log.info("完成写入[{}]条suggest数据", batchSize);}long endTime = System.currentTimeMillis();//3.记录统计信息int totalCount = batchSize * batchTimes;long elapsedSeconds = (endTime - startTime) / 1000;long perSecond = totalCount / elapsedSeconds;log.info("此次共导入[{}]条suggest数据,耗时[{}]秒,平均每秒导入[{}]条数据", totalCount, elapsedSeconds, perSecond);Map<String, Object> result = new LinkedHashMap<>();result.put("startTime", DateUtil.format(new Date(startTime), DatePattern.NORM_DATETIME_PATTERN));result.put("endTime", DateUtil.format(new Date(endTime), DatePattern.NORM_DATETIME_PATTERN));result.put("totalCount", totalCount);result.put("elapsedSeconds", elapsedSeconds);result.put("perSecond", perSecond);return JsonResult.buildSuccess(result);
}三.参数说明

四.返回值说明
