Flink On Yarn HA 重启次数
前言
之前写的Flink HA 总结 中有提到重启次数 yarn.application-attempts 不生效,会一直重启,但是没有解决,本文补充一下该问题的解决方法。
版本
- Flink 1.15.3
- Yarn 3.1.1
解决方法
添加参数:
yarn.application-attempt-failures-validity-interval: 600000
或
yarn.application-attempt-failures-validity-interval: -1
参数解释:
- yarn.application-attempt-failures-validity-interval :以毫秒为单位的时间窗口,定义了重新启动AM时应用程序尝试失败的次数。不考虑此窗口之外的失败。将此值设置为-1,以便全局计数。
- 即该间隔内失败次数超过 yarn.application-attempts 之后任务才失败,否则重新计算,单位毫秒,默认 10s。
- 设置该参数为 600000ms 即十分钟后,只要我们在十分钟之内 kill 掉对应的 jobmananger 进程次数达到 yarn.application-attempts 值任务就会失败。
- 设置为 -1,就没有时间限制了
- 该参数在 Yarn 源码中默认值是 -1
官方文档
该参数在HA的文档中并未提及,且网上的资料中也很少提及该参数,通过搜索源码,发现了官方文档的地址:
https://nightlies.apache.org/flink/flink-docs-master/zh/docs/deployment/config/#yarn
另外在官网 https://nightlies.apache.org/flink/flink-docs-master/zh/docs/deployment/resource-providers/yarn/ :

这里不仅说了 Yarn HA 不能设置 high-availability.cluster-id ,而且也提及了尝试失败有效性间隔:
容器关闭行为
- YARN 2.3.0 <版本<2.4.0。如果应用程序主机失败,则重新启动所有容器。
- YARN 2.4.0 <版本<2.6.0。TaskManager容器在应用程序主故障期间保持活动状态。具有以下优点:启动时间更快并且用户不必再等待再次获得容器资源。
- YARN 2.6.0 <= version:将尝试失败有效性间隔设置为Flink的Akka超时值。尝试失败有效性间隔表示只有在系统在一个间隔期间看到最大应用程序尝试次数后才会终止应用程序。这避免了持久的工作会耗尽它的应用程序尝试。
注意:Hadoop YARN 2.4.0有一个主要的bug(修复在2.5.0中),它阻止容器从重新启动的Application Master/JobManager容器重新启动。有关详细信息,请参阅FLINK-4142。我们建议至少在YARN上使用Hadoop 2.5.0进行高可用性设置
相关参考:
- https://github.com/Jonathan-Wei/Flink-Docs-CN/blob/master/06-bu-shu-cao-zuo/gao-ke-yong-ha.md
- https://geek.zshipu.com/post/bi/flink/2048-%E7%AC%AC13%E8%AE%B2%E5%A6%82%E4%BD%95%E5%AE%9E%E7%8E%B0%E7%94%9F%E4%BA%A7%E7%8E%AF%E5%A2%83%E4%B8%AD%E7%9A%84-Flink-%E9%AB%98%E5%8F%AF%E7%94%A8%E9%85%8D%E7%BD%AE/
- https://blog.51cto.com/u_16213590/9822924
相关源码
Flink
YarnConfigOptions
/*** Set the number of retries for failed YARN ApplicationMasters/JobManagers in high availability* mode. This value is usually limited by YARN. By default, it's 1 in the standalone case and 2* in the high availability case.** <p>>Note: This option returns a String since Integer options must have a static default* value.*/public static final ConfigOption<String> APPLICATION_ATTEMPTS =key("yarn.application-attempts").stringType().noDefaultValue().withDescription(Description.builder().text("Number of ApplicationMaster restarts. By default, the value will be set to 1. "+ "If high availability is enabled, then the default value will be 2. "+ "The restart number is also limited by YARN (configured via %s). "+ "Note that that the entire Flink cluster will restart and the YARN Client will lose the connection.",link("https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml","yarn.resourcemanager.am.max-attempts")).build());/** The config parameter defining the attemptFailuresValidityInterval of Yarn application. */public static final ConfigOption<Long> APPLICATION_ATTEMPT_FAILURE_VALIDITY_INTERVAL =key("yarn.application-attempt-failures-validity-interval").longType().defaultValue(10000L).withDescription(Description.builder().text("Time window in milliseconds which defines the number of application attempt failures when restarting the AM. "+ "Failures which fall outside of this window are not being considered. "+ "Set this value to -1 in order to count globally. "+ "See %s for more information.",link("https://hortonworks.com/blog/apache-hadoop-yarn-hdp-2-2-fault-tolerance-features-long-running-services/","here")).build());
YarnClusterDescriptor : 设置尝试失败有效性间隔
private void activateHighAvailabilitySupport(ApplicationSubmissionContext appContext)throws InvocationTargetException, IllegalAccessException {ApplicationSubmissionContextReflector reflector =ApplicationSubmissionContextReflector.getInstance();reflector.setKeepContainersAcrossApplicationAttempts(appContext, true);reflector.setAttemptFailuresValidityInterval(appContext,flinkConfiguration.getLong(YarnConfigOptions.APPLICATION_ATTEMPT_FAILURE_VALIDITY_INTERVAL));}
Yarn
ApplicationSubmissionContext

public static ApplicationSubmissionContext newInstance(ApplicationId applicationId, String applicationName, String queue,Priority priority, ContainerLaunchContext amContainer,boolean isUnmanagedAM, boolean cancelTokensWhenComplete,int maxAppAttempts, Resource resource, String applicationType,boolean keepContainers, long attemptFailuresValidityInterval) {ApplicationSubmissionContext context =newInstance(applicationId, applicationName, queue, priority,amContainer, isUnmanagedAM, cancelTokensWhenComplete, maxAppAttempts,resource, applicationType, keepContainers);context.setAttemptFailuresValidityInterval(attemptFailuresValidityInterval);return context;}
RMAppImpl

这里可以参考:https://johnjianfang.blogspot.com/2015/04/the-number-of-maximum-attempts-of-yarn.html
验证失败次数
在Flink HA 总结中提到:
> yarn.application-attempts: ApplicationMaster 重新启动的次数。默认情况下,该值将设置为1。如果启用了高可用性,则默认值将为2。重启次数也受到YARN的限制(通过yarn.resourcemanager.am.max-attempts配置)。请注意,整个Flink集群将重新启动,yarn客户端将失去连接。
下面我们来验证一下
默认值
两次

yarn.application-attempts = 5
依旧是两次, 只是因为重启次数也受到YARN的限制(通过yarn.resourcemanager.am.max-attempts配置)
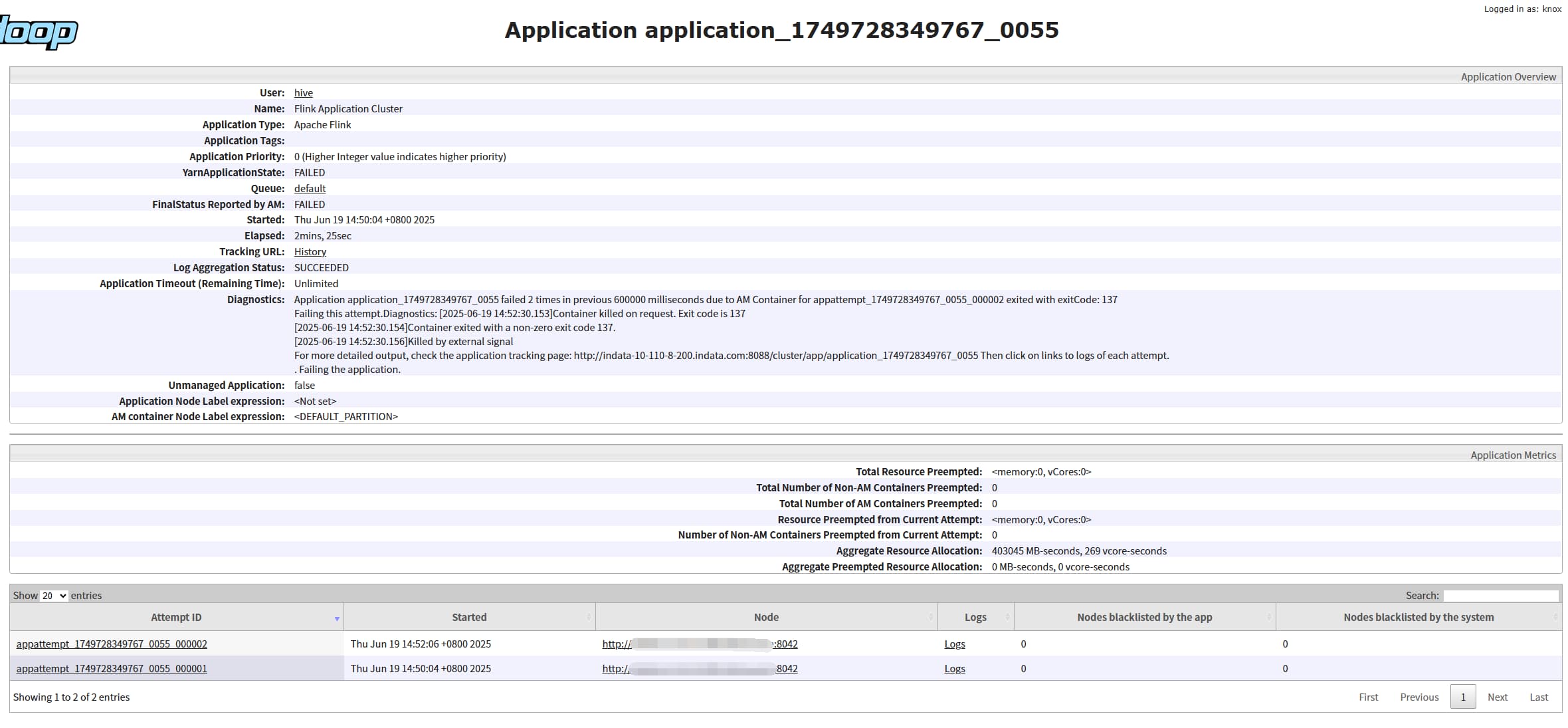

yarn.application-attempts = 5 ,yarn.resourcemanager.am.max-attempts = 10
再次测试:5次

再次测试默认值
因为开始测试默认值是两次,受到 yarn.resourcemanager.am.max-attempts = 2 的影响,在我们将 yarn.resourcemanager.am.max-attempts 设置为 10 后,再次测试默认值依旧是两次。

总结
- yarn.application-attempts 默认值两次
- 同时受到 yarn.resourcemanager.am.max-attempts 限制,取两者最低值
- 重启次数包含初始启动的次数,比如设置为 5,则会重启 4次(4次重试+1次初始尝试)