langChainv0.3学习笔记(中级篇)
目录
- 检索器组件
- 使用向量存储作为检索器
- 使用 MultiQueryRetriever生成多个查询以检索数据
- 使用上下文压缩进行检索
- 更多内置压缩器
- LLMChainFilter
- LLMListwiseRerank
- EmbeddingsFilter
- 将压缩器和文档转换器串联在一起
- 创建自定义检索器
- 为检索结果添加分数
- SelfQueryRetriever
- MultiVectorRetriever
- 结合多个检索器的结果
- 重新排序检索结果以减轻Lost in the Middle
- 为每个文档生成多个嵌入
- 拆分较小的块
- 将摘要与文档关联以进行检索
- 假设查询
- 使用父文档检索器
- 检索完整文档
- 检索较大块
- 使用时间加权向量存储检索器
- 低衰减率
- 高衰减率
- 虚拟时间
- “自查询”检索
- 使用 LCEL 从头构建
- 混合搜索
- 输出解析器组件
- 使用输出解析器将LLM响应解析为结构化格式
- 解析 JSON 输出
- 解析 XML 输出
- 解析 YAML 输出
- 在解析错误发生时重试
- 使用输出修复解析器
- 创建自定义输出解析器
- 可运行的 Lambda 和生成器
- 从解析基类继承
- 解析原始模型输出
- LangChain表达式 (LCEL)
- "Runnable"协议
- LangChain表达式 (LCEL) 速查表
- 调用一个Runnable
- 批量Runnable
- 流式Runnable
- 组合Runnable
- 并行调用Runnable
- 将任何函数转换为Runnable
- 合并输入和输出字典
- 将输入字典包含在输出字典中
- 添加默认调用参数
- 添加fallbacks选项
- 添加重试
- 配置Runnable执行
- 将默认配置添加到Runnable
- 使Runnable属性可配置
- 使链组件可配置
- 根据输入动态构建链
- 生成事件流
- 按照完成的批次输出
- 返回输出字典的子集
- 声明性地创建可运行的批处理版本
- 获取可运行的图形表示
- 获取链中的所有提示
- 添加生命周期监听器
- 链式运行Runnable
- 流式运行可执行项
- 使用流事件
- 聊天模型
- 链
- 事件过滤
- 非流式组件
- 传播回调
- 并行调用运行接口
- 使用 RunnableParallels 格式化
- 使用 itemgetter 作为简写
- 并行化步骤
- 并行性
- 为 Runnable 添加默认调用参数
- 运行自定义函数
- 使用构造函数
- 方便的 @chain 装饰器
- 链中的自动强制转换
- 传递运行元数据
- 流式处理
- 异步版本
- 将参数从一个步骤传递到下一个步骤
- 检索示例
- 在运行时配置可运行项行为
- 可配置字段:`configurable_fields`
- 使用 HubRunnables
- 可配置的替代方案:`configurable_alternatives`
- 在提示词之间切换
- 使用提示词和大型语言模型
- 保存配置
- 添加消息历史——记忆
- 如何存储和加载消息
- 你想要包装的可运行对象是什么?
- 消息输入,消息输出
- 字典输入,消息输出
- 消息输入,字典输出
- 单键字典用于所有消息输入和消息输出
- 自定义
- 在子链之间进行路由
- 使用自定义函数(推荐)
- 使用 RunnableBranch
- 通过语义相似性进行路由
- 创建动态(自构建)链
- 检查可运行项
- 获取图形
- 打印图形
- 获取提示词
- 为可运行对象添加后备方案
- 针对大型语言模型API错误的后备方案
- 序列的回退
- 长输入的回退
- 回退到更好的模型
- 将运行时机密传递给可运行对象
langChainv0.3学习笔记(初级篇)介绍了langChain中的一些简单概念,包括聊天模型,Message组件,文档加载器、切分器,嵌入组件,向量化搜索等,以上组件可以很轻易的帮助我们构建一个RAG程序!
但,一个工程师(不再是程序员)应该追求“知起所有然”,因此中级篇我们将深入学习LangChain,对于一个工作流APP,LangChain能帮助我们,对于一个Agent LangGraph能帮助我们,但LangGraph底层是LangChain,学习LangChain对加深LangGraph有益无害。
检索器组件
检索器是一个接口,给定非结构化查询返回文档。 它比向量存储更为通用。 检索器不需要能够存储文档,只需返回(或检索)它们。 检索器可以从向量存储创建,但也足够广泛,包括维基百科搜索和亚马逊Kendra。
检索器接受字符串查询作为输入,并返回文档列表作为输出。
使用向量存储作为检索器
向量存储检索器是一个使用向量存储来检索文档的检索器。它是一个轻量级的包装器,围绕向量存储类构建,使其符合检索器接口。 它使用向量存储实现的搜索方法,如相似性搜索和MMR,来查询向量存储中的文本。
可以使用其 .as_retriever 方法从向量存储构建检索器。
FAISS是内存中向量存储,需要
- linux安装:pip install faiss-gpu
- windows安装: pip install faiss-cpu
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitterloader = TextLoader("state_of_the_union.txt")documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(texts, embeddings)
我们可以实例化一个检索器:
retriever = vectorstore.as_retriever()
这将创建一个检索器(具体来说是一个 VectorStoreRetriever),我们可以像往常一样使用它:
docs = retriever.invoke("what did the president say about ketanji brown jackson?")
如果我们目前没有嵌入模型apikey,我们可以使用词向量模型:
import spacy# 下载一个支持向量化的 spaCy 预训练模型
nlp = spacy.load("en_core_web_md") # 或者 "en_core_web_lg"text = "This is an example sentence."
vector = nlp(text).vector # 获取整个文本的向量
print(vector.shape) # (300,)
spaCy 的 en_core_web_md(300 维) 或 en_core_web_lg(300 维)模型可以直接用于向量化。
经过实验FAISS在windows上好像有点问题,因此切换成Chroma:
import spacy
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import CharacterTextSplitter
from langchain.embeddings.base import Embeddings# 加载 spaCy 模型
nlp = spacy.load("zh_core_web_sm")
text = """西游记
吴承恩
文章类型:小说
上卷第一回灵根育孕源流出心性修持大道生"""# 创建一个 Dummy Embeddings 类(后续用于查询时计算查询向量)
class DummyEmbeddings(Embeddings):def embed_query(self, text: str) -> list[float]:return nlp(text).vector.tolist()def embed_documents(self, texts: list[str]) -> list[list[float]]:return [nlp(t).vector.tolist() for t in texts]dummy_embedding = DummyEmbeddings()# 使用 from_embeddings 方法构造 FAISS 索引
store = Chroma.from_texts([text, """丹崖上,彩凤双鸣;削壁前,麒麟独卧。峰头时听锦鸡鸣
,石窟每观龙出入。林中有寿鹿仙狐,树上有灵禽玄鹤。瑶草奇花
不谢,青松翠柏长春。"""], dummy_embedding)# 查询示例:使用相似搜索(查询时会调用 dummy_embedding.embed_query)
query = "麒麟"
results = store.similarity_search(query, k=1)
print(results)# [Document(metadata={}, page_content='丹崖上,彩凤双鸣;削壁前,麒麟独卧。峰头时听锦鸡鸣\n,石窟每观龙出入。林中有寿鹿仙狐,树上有灵禽玄鹤。瑶草奇花\n不谢,青松翠柏长春。')]
# 查询示例:使用相似搜索(查询时会调用 dummy_embedding.embed_query)
retriever = store.as_retriever()print(retriever.invoke("麒麟"))
[Document(metadata={}, page_content='丹崖上,彩凤双鸣;削壁前,麒麟独卧。峰头时听锦鸡鸣\n,石窟每观龙出入。林中有寿鹿仙狐,树上有灵禽玄鹤。瑶草奇花\n不谢,青松翠柏长春。'), Document(metadata={}, page_content='西游记\n吴承恩\n文章类型:小说\n上卷第一回灵根育孕源流出心性修持大道生')]
Number of requested results 4 is greater than number of elements in index 2, updating n_results = 2
默认情况下,向量存储检索器使用相似性搜索。如果底层向量存储支持最大边际相关性搜索,您可以将其指定为搜索类型。
这有效地指定了在底层向量存储上使用的方法(例如,similarity_search、max_marginal_relevance_search等)。
retriever = vectorstore.as_retriever(search_type="mmr")docs = retriever.invoke("what did the president say about ketanji brown jackson?")
我们还可以使用 search_kwargs 将参数传递给底层向量存储的搜索方法。例如,我们可以设置一个相似性得分阈值,仅返回得分高于该阈值的文档。
retriever = vectorstore.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.5}
)docs = retriever.invoke("what did the president say about ketanji brown jackson?")
我们还可以限制检索器返回的文档数量 k。
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})docs = retriever.invoke("what did the president say about ketanji brown jackson?")
len(docs)
使用 MultiQueryRetriever生成多个查询以检索数据
基于距离的向量数据库检索将查询嵌入(表示)到高维空间,并根据距离度量找到相似的嵌入文档。但是,检索可能会因查询措辞的细微变化而产生不同的结果,或者如果嵌入未能很好地捕捉数据的语义。提示工程/调优有时会手动解决这些问题,但可能会很繁琐。
**MultiQueryRetriever 通过使用大型语言模型(LLM)**从给定用户输入查询生成多个不同视角的查询,自动化提示调优的过程。对于每个查询,它检索一组相关文档,并在所有查询中取唯一的并集,以获取更大的一组潜在相关文档。通过对同一问题生成多个视角,MultiQueryRetriever 可以减轻基于距离的检索的一些局限性,并获得更丰富的结果集。
首先构建一个向量存储:
# Build a sample vectorDB
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter# Load blog post
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)# VectorDB
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
简单使用:指定用于查询生成的大型语言模型,检索器将完成其余工作。
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
# Set logging for the queries
import logginglogging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectordb.as_retriever(), llm=llm
)unique_docs = retriever_from_llm.invoke(question)
len(unique_docs)
INFO:langchain.retrievers.multi_query:Generated queries: ['1. How can Task Decomposition be achieved through different methods?', '2. What strategies are commonly used for Task Decomposition?', '3. What are the various ways to break down tasks in Task Decomposition?']
从日志可以看到,MultiQueryRetriever 的作用是将用户输入的查询泛化为多个不同表达方式的查询,以增强检索效果。
他将问题:“任务分解的方法有哪些?”,泛化为:
1. 任务分解可以通过哪些不同的方法实现?
2. 任务分解通常采用哪些策略?
3. 任务分解有哪些不同的拆解方式?
这些问题都是对原始问题的不同表述,目的是增加搜索匹配的可能性,避免因措辞不同而遗漏相关内容。
MultiQueryRetriever 会将这些扩展后的问题分别传递给 retriever(即 vectordb.as_retriever()),每个查询都会得到一批相关文档,可能有重复。所以 MultiQueryRetriever 会合并这些文档,并去重,最终得到 unique_docs(唯一的文档集合)。
len(unique_docs) 表示最终返回的去重后的文档数量。
在后台,MultiQueryRetriever 使用特定的 提示词 生成查询。要自定义此提示词:
- 创建一个带有问题输入变量的 提示词模板;
- 实现一个 输出解析器,如下所示,将结果拆分为查询列表。
提示词和输出解析器必须共同支持生成查询列表。
from typing import Listfrom langchain_core.output_parsers import BaseOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field# Output parser will split the LLM result into a list of queries
class LineListOutputParser(BaseOutputParser[List[str]]):"""Output parser for a list of lines."""def parse(self, text: str) -> List[str]:lines = text.strip().split("\n")return list(filter(None, lines)) # Remove empty linesoutput_parser = LineListOutputParser()QUERY_PROMPT = PromptTemplate(input_variables=["question"],template="""You are an AI language model assistant. Your task is to generate five different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to helpthe user overcome some of the limitations of the distance-based similarity search. Provide these alternative questions separated by newlines.Original question: {question}""",
)
llm = ChatOpenAI(temperature=0)# Chain
llm_chain = QUERY_PROMPT | llm | output_parser# Other inputs
question = "What are the approaches to Task Decomposition?"# Run
retriever = MultiQueryRetriever(retriever=vectordb.as_retriever(), llm_chain=llm_chain, parser_key="lines"
) # "lines" is the key (attribute name) of the parsed output# Results
unique_docs = retriever.invoke("What does the course say about regression?")
len(unique_docs)
INFO:langchain.retrievers.multi_query:Generated queries: ['1. Can you provide insights on regression from the course material?', '2. How is regression discussed in the course content?', '3. What information does the course offer regarding regression?', '4. In what way is regression covered in the course?', "5. What are the course's teachings on regression?"]
使用上下文压缩进行检索
检索的一个挑战是,通常在将数据导入系统时,你并不知道文档存储系统将面临的具体查询。这意味着与查询最相关的信息可能会埋藏在包含大量无关文本的文档中。将整个文档传递给你的应用程序可能会导致更昂贵的LLM调用和更差的响应。
上下文压缩旨在解决这个问题。这个想法很简单:你可以使用给定查询的上下文来压缩检索到的文档,而不是立即按原样返回它们,以便只返回相关信息。这里的“压缩”既指压缩单个文档的内容,也指整体过滤掉文档。
要使用上下文压缩检索器,你需要:
- 一个基础检索器
- 一个文档压缩器
上下文压缩检索器将查询传递给基础检索器,获取初始文档并将其传递给文档压缩器。文档压缩器接收文档列表,通过减少文档内容或完全删除文档来缩短列表。
让我们开始初始化一个简单的向量存储检索器,并存储2023年国情咨文(分块)。我们可以看到,给定一个示例问题,我们的检索器返回一到两个相关文档和一些不相关文档。即使是相关文档中也包含很多不相关的信息。
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitterdef pretty_print_docs(docs):print(f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]))documents = TextLoader("state_of_the_union.txt").load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
retriever = FAISS.from_documents(texts, OpenAIEmbeddings()).as_retriever()docs = retriever.invoke("What did the president say about Ketanji Brown Jackson")
pretty_print_docs(docs)
Document 1:Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
----------------------------------------------------------------------------------------------------
Document 2:A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system. We can do both. At our border, we’ve installed new technology like cutting-edge scanners to better detect drug smuggling. We’ve set up joint patrols with Mexico and Guatemala to catch more human traffickers. We’re putting in place dedicated immigration judges so families fleeing persecution and violence can have their cases heard faster. We’re securing commitments and supporting partners in South and Central America to host more refugees and secure their own borders.
----------------------------------------------------------------------------------------------------
Document 3:And for our LGBTQ+ Americans, let’s finally get the bipartisan Equality Act to my desk. The onslaught of state laws targeting transgender Americans and their families is wrong. As I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential. While it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year. From preventing government shutdowns to protecting Asian-Americans from still-too-common hate crimes to reforming military justice. And soon, we’ll strengthen the Violence Against Women Act that I first wrote three decades ago. It is important for us to show the nation that we can come together and do big things. So tonight I’m offering a Unity Agenda for the Nation. Four big things we can do together. First, beat the opioid epidemic.
----------------------------------------------------------------------------------------------------
Document 4:Tonight, I’m announcing a crackdown on these companies overcharging American businesses and consumers. And as Wall Street firms take over more nursing homes, quality in those homes has gone down and costs have gone up. That ends on my watch. Medicare is going to set higher standards for nursing homes and make sure your loved ones get the care they deserve and expect. We’ll also cut costs and keep the economy going strong by giving workers a fair shot, provide more training and apprenticeships, hire them based on their skills not degrees. Let’s pass the Paycheck Fairness Act and paid leave. Raise the minimum wage to $15 an hour and extend the Child Tax Credit, so no one has to raise a family in poverty. Let’s increase Pell Grants and increase our historic support of HBCUs, and invest in what Jill—our First Lady who teaches full-time—calls America’s best-kept secret: community colleges.
现在让我们用 ContextualCompressionRetriever 包装我们的基础检索器。我们将添加一个 LLMChainExtractor,它将遍历最初返回的文档,并仅提取与查询相关的内容。
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import OpenAIllm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever
)compressed_docs = compression_retriever.invoke("What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
Document 1:I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson.
更多内置压缩器
LLMChainFilter
LLMChainFilter 是一个稍微简单但更强大的压缩器,它使用 LLM 链来决定过滤掉哪些最初检索到的文档,以及返回哪些文档,而不操纵文档内容。
from langchain.retrievers.document_compressors import LLMChainFilter_filter = LLMChainFilter.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=_filter, base_retriever=retriever
)compressed_docs = compression_retriever.invoke("What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
LLMListwiseRerank
LLMListwiseRerank 使用 零样本列表文档重排序,其功能类似于 LLMChainFilter,作为一种强大但更昂贵的选项。建议使用更强大的 LLM。
请注意,LLMListwiseRerank 需要实现 with_structured_output 方法的模型。
from langchain.retrievers.document_compressors import LLMListwiseRerank
from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-4o-mini", temperature=0)_filter = LLMListwiseRerank.from_llm(llm, top_n=1)
compression_retriever = ContextualCompressionRetriever(base_compressor=_filter, base_retriever=retriever
)compressed_docs = compression_retriever.invoke("What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
EmbeddingsFilter
对每个检索到的文档进行额外的LLM调用是昂贵且缓慢的。嵌入过滤器通过对文档和查询进行嵌入,提供了一种更便宜和更快速的选项,仅返回与查询具有足够相似嵌入的文档。
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain_openai import OpenAIEmbeddingsembeddings = OpenAIEmbeddings()
embeddings_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
compression_retriever = ContextualCompressionRetriever(base_compressor=embeddings_filter, base_retriever=retriever
)compressed_docs = compression_retriever.invoke("What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
将压缩器和文档转换器串联在一起
使用文档压缩器管道,我们还可以轻松地将多个压缩器按顺序组合在一起。除了压缩器,我们还可以将基础文档转换器添加到我们的管道中,这些转换器不执行任何上下文压缩,而只是对一组文档进行某种转换。例如,文本分割器可以用作文档转换器,将文档拆分成更小的部分,而嵌入冗余过滤器可以根据文档之间的嵌入相似性过滤掉冗余文档。
下面我们创建一个压缩器管道,首先将文档拆分成更小的块,然后移除冗余文档,最后根据与查询的相关性进行过滤。
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain_community.document_transformers import EmbeddingsRedundantFilter
from langchain_text_splitters import CharacterTextSplittersplitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0, separator=". ")
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings)
relevant_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
pipeline_compressor = DocumentCompressorPipeline(transformers=[splitter, redundant_filter, relevant_filter]
)compression_retriever = ContextualCompressionRetriever(base_compressor=pipeline_compressor, base_retriever=retriever
)compressed_docs = compression_retriever.invoke("What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
Document 1:One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson
----------------------------------------------------------------------------------------------------
Document 2:As I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential. While it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year
----------------------------------------------------------------------------------------------------
Document 3:A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder
----------------------------------------------------------------------------------------------------
Document 4:Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system. We can do both
创建自定义检索器
许多大型语言模型应用涉及使用 检索器 从外部数据源检索信息。
检索器负责检索与给定用户 查询 相关的 文档 列表。
检索到的文档通常被格式化为提示词,输入到大型语言模型中,使其能够利用这些信息生成适当的响应(例如,根据知识库回答用户问题)。
要创建自己的检索器,您需要扩展 BaseRetriever 类并实现以下方法:
_get_relevant_documents获取与查询相关的文档。(必需)_aget_relevant_documents实现以提供异步原生支持。 (可选)
在 _get_relevant_documents 内部的逻辑可以涉及对数据库或使用请求访问网络的任意调用。
通过从 BaseRetriever 继承,检索器将自动成为 LangChain Runnable,并将获得标准的 Runnable 功能!也可以使用 RunnableLambda 或 RunnableGenerator 来实现检索器。
将检索器实现为 BaseRetriever 与 RunnableLambda(自定义 可运行函数)的主要好处在于,BaseRetriever 是一个众所周知的 LangChain 实体,因此某些监控工具可能会为检索器实现专门的行为。 另一个区别是,BaseRetriever 在某些 API 中的行为与 RunnableLambda 会略有不同;例如,astream_events API 中的 start 事件将是 on_retriever_start 而不是 on_chain_start。 一个 BaseRetriever 在某些 API 中的行为会与 RunnableLambda 略有不同;例如,start 事件 astream_events API 中将是 on_retriever_start 而不是 on_chain_start。
让我们实现一个玩具检索器,返回所有文本包含用户查询文本的文档。
from typing import Listfrom langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from langchain_core.retrievers import BaseRetrieverclass ToyRetriever(BaseRetriever):"""A toy retriever that contains the top k documents that contain the user query.This retriever only implements the sync method _get_relevant_documents.If the retriever were to involve file access or network access, it could benefitfrom a native async implementation of `_aget_relevant_documents`.As usual, with Runnables, there's a default async implementation that's providedthat delegates to the sync implementation running on another thread."""documents: List[Document]"""List of documents to retrieve from."""k: int"""Number of top results to return"""def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]:"""Sync implementations for retriever."""matching_documents = []for document in self.documents:if len(matching_documents) > self.k:return matching_documentsif query.lower() in document.page_content.lower():matching_documents.append(document)return matching_documents# Optional: Provide a more efficient native implementation by overriding# _aget_relevant_documents# async def _aget_relevant_documents(# self, query: str, *, run_manager: AsyncCallbackManagerForRetrieverRun# ) -> List[Document]:# """Asynchronously get documents relevant to a query.# Args:# query: String to find relevant documents for# run_manager: The callbacks handler to use# Returns:# List of relevant documents# """
测试:
documents = [Document(page_content="Dogs are great companions, known for their loyalty and friendliness.",metadata={"type": "dog", "trait": "loyalty"},),Document(page_content="Cats are independent pets that often enjoy their own space.",metadata={"type": "cat", "trait": "independence"},),Document(page_content="Goldfish are popular pets for beginners, requiring relatively simple care.",metadata={"type": "fish", "trait": "low maintenance"},),Document(page_content="Parrots are intelligent birds capable of mimicking human speech.",metadata={"type": "bird", "trait": "intelligence"},),Document(page_content="Rabbits are social animals that need plenty of space to hop around.",metadata={"type": "rabbit", "trait": "social"},),
]
retriever = ToyRetriever(documents=documents, k=3)
retriever.invoke("that")[Document(page_content='Cats are independent pets that often enjoy their own space.', metadata={'type': 'cat', 'trait': 'independence'}),Document(page_content='Rabbits are social animals that need plenty of space to hop around.', metadata={'type': 'rabbit', 'trait': 'social'})]
它是一个Runnable ,因此将受益于标准的运行接口!
await retriever.ainvoke("that")retriever.batch(["dog", "cat"])async for event in retriever.astream_events("bar", version="v1"):print(event)
为检索结果添加分数
检索器将返回一系列 文档 对象,这些对象默认不包含有关检索过程的信息(例如,与查询的相似度分数)。
首先,我们用一些数据填充一个向量存储。
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_pinecone import PineconeVectorStoredocs = [Document(page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",metadata={"year": 1993, "rating": 7.7, "genre": "science fiction"},),Document(page_content="Leo DiCaprio gets lost in a dream within a dream within a dream within a ...",metadata={"year": 2010, "director": "Christopher Nolan", "rating": 8.2},),Document(page_content="A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea",metadata={"year": 2006, "director": "Satoshi Kon", "rating": 8.6},),Document(page_content="A bunch of normal-sized women are supremely wholesome and some men pine after them",metadata={"year": 2019, "director": "Greta Gerwig", "rating": 8.3},),Document(page_content="Toys come alive and have a blast doing so",metadata={"year": 1995, "genre": "animated"},),Document(page_content="Three men walk into the Zone, three men walk out of the Zone",metadata={"year": 1979,"director": "Andrei Tarkovsky","genre": "thriller","rating": 9.9,},),
]vectorstore = PineconeVectorStore.from_documents(docs, index_name="sample", embedding=OpenAIEmbeddings()
)
为了从向量存储检索器获取分数,我们将底层向量存储的 .similarity_search_with_score 方法包装在一个短函数中,该函数将分数打包到相关文档的元数据中。
我们在函数上添加 @chain 装饰器,以创建一个Runable:
from typing import Listfrom langchain_core.documents import Document
from langchain_core.runnables import chain@chain
def retriever(query: str) -> List[Document]:docs, scores = zip(*vectorstore.similarity_search_with_score(query))for doc, score in zip(docs, scores):doc.metadata["score"] = scorereturn docsresult = retriever.invoke("dinosaur")
result
(Document(page_content='A bunch of scientists bring back dinosaurs and mayhem breaks loose', metadata={'genre': 'science fiction', 'rating': 7.7, 'year': 1993.0, 'score': 0.84429127}),
...
)
SelfQueryRetriever
SelfQueryRetriever 将使用大型语言模型生成一个潜在结构化的查询——例如,它可以在通常的语义相似性驱动选择的基础上构建检索过滤器。
如果你在一个普通的向量数据库(如 FAISS、Pinecone)中查询,检索通常是基于语义相似性的。但 SelfQueryRetriever 允许你自动生成更复杂的过滤条件,从而在数据库中进行更加精准的搜索。
假设你有一个存储电影信息的数据库,其中每个电影条目都有以下字段:
{"title": "Inception","genre": "Sci-Fi","release_year": 2010,"rating": 8.8
}
如果你用普通的 Retriever 查询:
“推荐一些科幻电影?”
普通 Retriever 可能只是基于语义相似性找到一些包含“科幻”关键词的电影,但无法进一步筛选,比如按评分或年份排序。
而 SelfQueryRetriever 会让 LLM 生成一个结构化查询,比如:
{"genre": "Sci-Fi","rating": { "$gte": 8.0 }
}
这个查询表示:
- ✅ 只找 “genre” 是 “Sci-Fi” 的电影
- ✅ 只返回 评分大于等于 8.0 的电影
这样,查询结果就会更加精准! 🎯
这一步相当于 LLM 在充当一个智能翻译器,把你的问题翻译成数据库能理解的结构化查询!
SelfQueryRetriever 包含一个短方法 _get_docs_with_query(1 - 2 行),该方法执行 vectorstore 搜索。我们可以子类化 SelfQueryRetriever 并重写此方法以传播相似性分数。
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_openai import ChatOpenAI
from typing import Any, Dictmetadata_field_info = [AttributeInfo(name="genre",description="The genre of the movie. One of ['science fiction', 'comedy', 'drama', 'thriller', 'romance', 'action', 'animated']",type="string",),AttributeInfo(name="year",description="The year the movie was released",type="integer",),AttributeInfo(name="director",description="The name of the movie director",type="string",),AttributeInfo(name="rating", description="A 1-10 rating for the movie", type="float"),
]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0)class CustomSelfQueryRetriever(SelfQueryRetriever):def _get_docs_with_query(self, query: str, search_kwargs: Dict[str, Any]) -> List[Document]:"""Get docs, adding score information."""docs, scores = zip(*self.vectorstore.similarity_search_with_score(query, **search_kwargs))for doc, score in zip(docs, scores):doc.metadata["score"] = scorereturn docs
调用此检索器现在将包括文档元数据中的相似性分数。
MultiVectorRetriever
MultiVectorRetriever 允许您将多个向量与单个文档关联。
在传统的向量检索中(例如 FAISS 或 Pinecone),通常是一个文档对应一个向量,检索时只会基于这个向量的语义相似性进行匹配。
但有些情况下,单个向量无法完全表示整个文档的所有重要信息,导致检索效果变差。📝 假设有这样一个文档:
"人工智能(AI)是一门跨学科领域,涵盖了机器学习、神经网络、自然语言处理等多个方向。"
如果我们用一个向量表示整个文档,那么:
-
查询:“什么是机器学习?” 可能无法很好匹配
-
查询:“自然语言处理的应用有哪些?” 也可能匹配度不高
这是因为单个向量可能过于笼统,无法精确表达文档的所有关键内容。
MultiVectorRetriever 允许你为同一个文档生成多个向量,然后分别存入向量数据库,以便在检索时有更高的召回率。 使用 MultiVectorRetriever 生成多个向量:
- 向量 1 —— 代表 “人工智能的定义”
- 向量 2 —— 代表 “机器学习的概念”
- 向量 3 —— 代表 “自然语言处理的应用”
这样,当用户搜索 “什么是机器学习?” 时,查询可以匹配到机器学习的相关片段,而不需要整个文档的向量来匹配。
首先,我们准备一些虚假数据。我们生成虚假的“完整文档”并将其存储在文档存储中;
from langchain.storage import InMemoryStore
from langchain_text_splitters import RecursiveCharacterTextSplitter# The storage layer for the parent documents
docstore = InMemoryStore()
fake_whole_documents = [("fake_id_1", Document(page_content="fake whole document 1")),("fake_id_2", Document(page_content="fake whole document 2")),
]
docstore.mset(fake_whole_documents)
接下来,我们将向我们的向量存储添加一些虚假的“子文档”。我们可以通过填充其元数据中的 “doc_id” 键将这些子文档链接到父文档。
docs = [Document(page_content="A snippet from a larger document discussing cats.",metadata={"doc_id": "fake_id_1"},),Document(page_content="A snippet from a larger document discussing discourse.",metadata={"doc_id": "fake_id_1"},),Document(page_content="A snippet from a larger document discussing chocolate.",metadata={"doc_id": "fake_id_2"},),
]vectorstore.add_documents(docs)
为了传播分数,我们子类化 MultiVectorRetriever 并重写其 _get_relevant_documents 方法。在这里我们将进行两个更改:
- 我们将使用上述底层向量存储的 similarity_search_with_score 方法将相似性分数添加到相应“子文档”的元数据中;
- 我们将在检索到的父文档的元数据中包含这些子文档的列表。这将显示检索到的文本片段及其对应的相似性分数。
from collections import defaultdictfrom langchain.retrievers import MultiVectorRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRunclass CustomMultiVectorRetriever(MultiVectorRetriever):def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]:"""Get documents relevant to a query.Args:query: String to find relevant documents forrun_manager: The callbacks handler to useReturns:List of relevant documents"""results = self.vectorstore.similarity_search_with_score(query, **self.search_kwargs)# Map doc_ids to list of sub-documents, adding scores to metadataid_to_doc = defaultdict(list)for doc, score in results:doc_id = doc.metadata.get("doc_id")if doc_id:doc.metadata["score"] = scoreid_to_doc[doc_id].append(doc)# Fetch documents corresponding to doc_ids, retaining sub_docs in metadatadocs = []for _id, sub_docs in id_to_doc.items():docstore_docs = self.docstore.mget([_id])if docstore_docs:if doc := docstore_docs[0]:doc.metadata["sub_docs"] = sub_docsdocs.append(doc)return docs
调用此检索器时,我们可以看到它识别了正确的父文档,包括来自子文档的相关片段及其相似性分数。
retriever = CustomMultiVectorRetriever(vectorstore=vectorstore, docstore=docstore)retriever.invoke("cat")
结合多个检索器的结果
该 EnsembleRetriever 支持对多个检索器的结果进行集成。它通过一组 BaseRetriever 对象进行初始化。EnsembleRetrievers 根据 Reciprocal Rank Fusion, RRF 算法对组成检索器的结果进行重新排序。
RRF(Reciprocal Rank Fusion, 互惠排名融合) 是一种简单但高效的排名融合算法,用于结合多个信息检索(IR)系统的排名结果,从而得到一个更稳定、准确的最终排名。
📌 核心思想:
-
每个 IR 系统返回一个排名列表,即文档的排序。
-
排名靠前的文档更重要,但不同 IR 系统可能给出不同的排序。
-
RRF 通过一个反排名函数(Reciprocal Rank Function)来融合这些排名,使得不同系统的贡献可以被有效整合。
通过利用不同算法的优势,EnsembleRetriever 可以实现比任何单一算法更好的性能。最常见的模式是将稀疏检索器(如 BM25)与密集检索器(如嵌入相似度)结合,因为它们的优势是互补的。这也被称为“混合搜索”。稀疏检索器擅长根据关键词查找相关文档,而密集检索器则擅长根据语义相似性查找相关文档。
from langchain.retrievers import EnsembleRetriever
from langchain_community.retrievers import BM25Retriever
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddingsdoc_list_1 = ["I like apples","I like oranges","Apples and oranges are fruits",
]# initialize the bm25 retriever and faiss retriever
bm25_retriever = BM25Retriever.from_texts(doc_list_1, metadatas=[{"source": 1}] * len(doc_list_1)
)
bm25_retriever.k = 2doc_list_2 = ["You like apples","You like oranges",
]embedding = OpenAIEmbeddings()
faiss_vectorstore = FAISS.from_texts(doc_list_2, embedding, metadatas=[{"source": 2}] * len(doc_list_2)
)
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2})# initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
)docs = ensemble_retriever.invoke("apples")
docs[Document(page_content='I like apples', metadata={'source': 1}),Document(page_content='You like apples', metadata={'source': 2}),Document(page_content='Apples and oranges are fruits', metadata={'source': 1}),Document(page_content='You like oranges', metadata={'source': 2})]
我们还可以使用 可配置字段 在运行时配置各个检索器。下面我们专门更新 FAISS 检索器的 “top-k” 参数:
from langchain_core.runnables import ConfigurableFieldfaiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2}
).configurable_fields(search_kwargs=ConfigurableField(id="search_kwargs_faiss",name="Search Kwargs",description="The search kwargs to use",)
)ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
)
然后将faiss的运行时k改为1,此处的search_kwargs_faiss是上文的id:
config = {"configurable": {"search_kwargs_faiss": {"k": 1}}}
docs = ensemble_retriever.invoke("apples", config=config)
docs[Document(page_content='I like apples', metadata={'source': 1}),Document(page_content='You like apples', metadata={'source': 2}),Document(page_content='Apples and oranges are fruits', metadata={'source': 1})]
这仅从 FAISS 检索器返回一个源,因为我们在运行时传入了相关配置。
重新排序检索结果以减轻Lost in the Middle
在RAG应用中,随着检索文档数量的增加(例如,超过十个),性能显著下降的情况已被记录。简而言之:模型容易在长上下文中遗漏相关信息。
相比之下,对向量存储的查询通常会按相关性降序返回文档(例如,通过嵌入的余弦相似度来衡量)。
为了减轻“Lost in the Middle”的效果,您可以在检索后重新排序文档,使得最相关的文档位于极端位置(例如,上下文的第一和最后部分),而最不相关的文档位于中间。在某些情况下,这可以帮助LLMs更好地呈现最相关的信息。
LongContextReorder文档转换器实现了这一重新排序过程。
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings# Get embeddings.
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")texts = ["Basquetball is a great sport.","Fly me to the moon is one of my favourite songs.","The Celtics are my favourite team.","This is a document about the Boston Celtics","I simply love going to the movies","The Boston Celtics won the game by 20 points","This is just a random text.","Elden Ring is one of the best games in the last 15 years.","L. Kornet is one of the best Celtics players.","Larry Bird was an iconic NBA player.",
]# Create a retriever
retriever = Chroma.from_texts(texts, embedding=embeddings).as_retriever(search_kwargs={"k": 10}
)
query = "What can you tell me about the Celtics?"# Get relevant documents ordered by relevance score
docs = retriever.invoke(query)
docs
正常情况下,文档是按与查询的相关性降序返回的。LongContextReorder 文档转换器将实现上述重新排序:
from langchain_community.document_transformers import LongContextReorder# Reorder the documents:
# Less relevant document will be at the middle of the list and more
# relevant elements at beginning / end.
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)# Confirm that the 4 relevant documents are at beginning and end.
reordered_docs
下面展示如何将重新排序的文档纳入一个简单的问答链中:
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAIllm = OpenAI()prompt_template = """
Given these texts:
-----
{context}
-----
Please answer the following question:
{query}
"""prompt = PromptTemplate(template=prompt_template,input_variables=["context", "query"],
)# Create and invoke the chain:
chain = create_stuff_documents_chain(llm, prompt)
response = chain.invoke({"context": reordered_docs, "query": query})
print(response)
为每个文档生成多个嵌入
通常,将每个文档存储多个向量是非常有用的。这在多个用例中是有益的。例如,我们可以嵌入文档的多个块,并将这些嵌入与父文档关联,从而允许对块的检索命中返回更大的文档。
LangChain 实现了一个基础的 MultiVectorRetriever,简化了这个过程。大部分复杂性在于如何为每个文档创建多个向量。
为每个文档创建多个向量的方法包括:
- 较小的块:将文档拆分为较小的块,并嵌入这些块(这就是 ParentDocumentRetriever)。
- 摘要:为每个文档创建摘要,将其与文档一起嵌入(或替代文档)。
- 假设性问题:创建每个文档适合回答的假设性问题,将这些问题与文档一起嵌入(或替代文档)。
拆分较小的块
from langchain.storage import InMemoryByteStore
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitterloaders = [TextLoader("paul_graham_essay.txt"),TextLoader("state_of_the_union.txt"),
]
docs = []
for loader in loaders:docs.extend(loader.load())
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs)# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings()
)
通常情况下,检索较大信息块是有用的,但嵌入较小的块。这允许嵌入尽可能准确地捕捉语义含义,同时将尽可能多的上下文传递给下游。
我们将区分向量存储,它索引(子)文档的嵌入,以及文档存储,它存放“父”文档并将其与标识符关联。
import uuidfrom langchain.retrievers.multi_vector import MultiVectorRetriever# The storage layer for the parent documents
store = InMemoryByteStore()
id_key = "doc_id"# The retriever (empty to start)
retriever = MultiVectorRetriever(vectorstore=vectorstore,byte_store=store,id_key=id_key,
)doc_ids = [str(uuid.uuid4()) for _ in docs]
接下来,我们通过拆分原始文档生成“子”文档。
# The splitter to use to create smaller chunks
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)sub_docs = []
for i, doc in enumerate(docs):_id = doc_ids[i]_sub_docs = child_text_splitter.split_documents([doc])for _doc in _sub_docs:_doc.metadata[id_key] = _idsub_docs.extend(_sub_docs)
最后,我们在向量存储和文档存储中索引文档:
retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
仅向量存储将检索小块:
retriever.vectorstore.similarity_search("justice breyer")[0]Document(page_content='Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.', metadata={'doc_id': '064eca46-a4c4-4789-8e3b-583f9597e54f', 'source': 'state_of_the_union.txt'})
而检索器将返回较大的父文档:
len(retriever.invoke("justice breyer")[0].page_content)
9875
检索器在向量数据库上执行的默认搜索类型是相似性搜索。LangChain向量存储还支持通过Max Marginal Relevance进行搜索。这可以通过检索器的search_type参数进行控制:
from langchain.retrievers.multi_vector import SearchTyperetriever.search_type = SearchType.mmrlen(retriever.invoke("justice breyer")[0].page_content)
MMR(Maximal Marginal Relevance,最大边际相关性) 是一种用于优化搜索结果排序的算法,主要用于去重和提高多样性。
📌 核心思想:
-
传统的信息检索(IR)系统主要根据**相关性(Relevance)**排序,但有时多个高相关文档的内容可能高度相似,导致搜索结果缺乏多样性。
-
MMR 通过在保证相关性的同时,最大化结果的多样性,避免搜索结果中出现大量相似的内容。
将摘要与文档关联以进行检索
摘要可能能够更准确地提炼出一个块的内容,从而导致更好的检索。在这里,我们展示如何创建摘要,然后嵌入这些摘要。
import getpass
import osos.environ["AZURE_OPENAI_API_KEY"] = getpass.getpass()from langchain_openai import AzureChatOpenAIllm = AzureChatOpenAI(azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],azure_deployment=os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"],openai_api_version=os.environ["AZURE_OPENAI_API_VERSION"],
)import uuidfrom langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplatechain = ({"doc": lambda x: x.page_content}| ChatPromptTemplate.from_template("Summarize the following document:\n\n{doc}")| llm| StrOutputParser()
)
我们可以对文档进行 批处理得到文档概要:
summaries = chain.batch(docs, {"max_concurrency": 5})
然后我们可以像之前一样初始化一个 MultiVectorRetriever,在我们的向量存储中索引摘要,并在我们的文档存储中保留原始文档:
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="summaries", embedding_function=OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryByteStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(vectorstore=vectorstore,byte_store=store,id_key=id_key,
)
doc_ids = [str(uuid.uuid4()) for _ in docs]summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]})for i, s in enumerate(summaries)
]retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
查询向量存储将返回摘要:
sub_docs = retriever.vectorstore.similarity_search("justice breyer")sub_docs[0]
而检索器将返回更大的源文档:
retrieved_docs = retriever.invoke("justice breyer")len(retrieved_docs[0].page_content)
假设查询
大型语言模型还可以用于生成一系列假设性问题,这些问题可以针对特定文档提出,可能与 RAG 应用中的相关查询具有密切的语义相似性。这些问题可以嵌入并与文档关联,以改善检索。
下面,我们使用 with_structured_output 方法将大型语言模型的输出结构化为字符串列表。
from typing import Listfrom pydantic import BaseModel, Fieldclass HypotheticalQuestions(BaseModel):"""Generate hypothetical questions."""questions: List[str] = Field(..., description="List of questions")chain = ({"doc": lambda x: x.page_content}# Only asking for 3 hypothetical questions, but this could be adjusted| ChatPromptTemplate.from_template("Generate a list of exactly 3 hypothetical questions that the below document could be used to answer:\n\n{doc}")| ChatOpenAI(max_retries=0, model="gpt-4o").with_structured_output(HypotheticalQuestions)| (lambda x: x.questions)
)
在单个文档上调用链演示了它输出一个问题列表:
chain.invoke(docs[0])["What impact did the IBM 1401 have on the author's early programming experiences?","How did the transition from using the IBM 1401 to microcomputers influence the author's programming journey?","What role did Lisp play in shaping the author's understanding and approach to AI?"]
然后我们可以对所有文档进行批处理,并像之前一样组装我们的向量存储和文档存储:
# Batch chain over documents to generate hypothetical questions
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5})# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="hypo-questions", embedding_function=OpenAIEmbeddings()
)
# The storage layer for the parent documents
store = InMemoryByteStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(vectorstore=vectorstore,byte_store=store,id_key=id_key,
)
doc_ids = [str(uuid.uuid4()) for _ in docs]# Generate Document objects from hypothetical questions
question_docs = []
for i, question_list in enumerate(hypothetical_questions):question_docs.extend([Document(page_content=s, metadata={id_key: doc_ids[i]}) for s in question_list])retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
查询底层向量存储将检索与输入查询在语义上相似的假设问题:
sub_docs = retriever.vectorstore.similarity_search("justice breyer")sub_docs
调用检索器将返回相应的文档:
retrieved_docs = retriever.invoke("justice breyer")
len(retrieved_docs[0].page_content)
使用父文档检索器
在进行文档检索时,通常会有相互矛盾的需求:
- 你可能希望文档较小,以便它们的嵌入能够最 准确地反映其含义。如果文档过长,嵌入可能会 失去意义。
- 你希望文档足够长,以便每个块的上下文得以 保留。
ParentDocumentRetriever通过拆分和存储 小块数据来实现这种平衡。在检索过程中,它首先获取小块 数据,但随后查找这些块的父ID并返回更大的数据块。
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitterloaders = [TextLoader("paul_graham_essay.txt"),TextLoader("state_of_the_union.txt"),
]
docs = []
for loader in loaders:docs.extend(loader.load())
检索完整文档
在此模式下,我们希望检索完整文档。因此,我们只指定一个子分割器。
# This text splitter is used to create the child documents
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings()
)
# The storage layer for the parent documents
store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore,docstore=store,child_splitter=child_splitter,
)
retriever.add_documents(docs, ids=None)
这应该产生两个键,因为我们添加了两个文档。
list(store.yield_keys())['9a63376c-58cc-42c9-b0f7-61f0e1a3a688','40091598-e918-4a18-9be0-f46413a95ae4']
现在让我们调用向量存储搜索功能 - 我们应该看到它返回小块(因为我们存储的是小块)。
sub_docs = vectorstore.similarity_search("justice breyer")print(sub_docs[0].page_content)
在 ParentDocumentRetriever 结构中,通常需要两个存储组件:
-
向量存储(vectorstore):存储子文档的向量,用于相似性搜索。
-
文档存储(docstore,即 InMemoryStore):存储原始的长文档(父文档),用于在检索子文档后还原完整文档。
现在让我们从整体检索器中检索。这应该返回大文档 - 因为它返回的是小块所在的文档。
retrieved_docs = retriever.invoke("justice breyer")len(retrieved_docs[0].page_content)38540
检索较大块
有时,完整文档可能太大,不想按原样检索。在这种情况下,我们真正想做的是首先将原始文档分割成较大块,然后再分割成较小块。我们然后对较小块进行索引,但在检索时我们检索较大块(但仍然不是完整文档)。
# This text splitter is used to create the parent documents
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
# This text splitter is used to create the child documents
# It should create documents smaller than the parent
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name="split_parents", embedding_function=OpenAIEmbeddings()
)
# The storage layer for the parent documents
store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore,docstore=store,child_splitter=child_splitter,parent_splitter=parent_splitter,
)retriever.add_documents(docs)
我们可以看到现在有比两个文档多得多 - 这些是较大块。
len(list(store.yield_keys()))66
让我们确保底层的向量存储仍然检索小块。
sub_docs = vectorstore.similarity_search("justice breyer")print(sub_docs[0].page_content)
Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
从similarity_search的查询结果来看,底层向量库存储的的确是小块,那么我们就可以放心调用invoke将检索传递下去:
retrieved_docs = retriever.invoke("justice breyer")
len(retrieved_docs[0].page_content)
1849
使用时间加权向量存储检索器
该检索器使用语义相似性和时间衰减的组合。
评分算法为:
semantic_similarity + (1.0 - decay_rate) ^ hours_passed
值得注意的是,hours_passed 指的是自检索器中的对象最后被访问以来经过的小时数,而不是自创建以来的小时数。这意味着经常被访问的对象保持“新鲜”。
from datetime import datetime, timedeltaimport faiss
from langchain.retrievers import TimeWeightedVectorStoreRetriever
from langchain_community.docstore import InMemoryDocstore
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
低衰减率
低 decay rate(在这里,为了极端,我们将其设置得接近0)意味着记忆将被“记住”更长时间。decay rate 为0意味着记忆永远不会被遗忘,使得这个检索器等同于向量查找。
# Define your embedding model
embeddings_model = OpenAIEmbeddings()
# Initialize the vectorstore as empty
embedding_size = 1536
index = faiss.IndexFlatL2(embedding_size)
vectorstore = FAISS(embeddings_model, index, InMemoryDocstore({}), {})
retriever = TimeWeightedVectorStoreRetriever(vectorstore=vectorstore, decay_rate=0.0000000000000000000000001, k=1
)yesterday = datetime.now() - timedelta(days=1)
retriever.add_documents([Document(page_content="hello world", metadata={"last_accessed_at": yesterday})]
)
retriever.add_documents([Document(page_content="hello foo")])['c3dcf671-3c0a-4273-9334-c4a913076bfa']# "Hello World" is returned first because it is most salient, and the decay rate is close to 0., meaning it's still recent enough
retriever.get_relevant_documents("hello world")[Document(page_content='hello world', metadata={'last_accessed_at': datetime.datetime(2023, 12, 27, 15, 30, 18, 457125), 'created_at': datetime.datetime(2023, 12, 27, 15, 30, 8, 442662), 'buffer_idx': 0})]
高衰减率
使用高 decay rate(例如,几个9),recency score 很快就会降到0!如果你将其设置为1,所有对象的 recency 都为0,再次使其等同于向量查找。
# Define your embedding model
embeddings_model = OpenAIEmbeddings()
# Initialize the vectorstore as empty
embedding_size = 1536
index = faiss.IndexFlatL2(embedding_size)
vectorstore = FAISS(embeddings_model, index, InMemoryDocstore({}), {})
retriever = TimeWeightedVectorStoreRetriever(vectorstore=vectorstore, decay_rate=0.999, k=1
)yesterday = datetime.now() - timedelta(days=1)
retriever.add_documents([Document(page_content="hello world", metadata={"last_accessed_at": yesterday})]
)
retriever.add_documents([Document(page_content="hello foo")])['eb1c4c86-01a8-40e3-8393-9a927295a950']# "Hello Foo" is returned first because "hello world" is mostly forgotten
retriever.get_relevant_documents("hello world")[Document(page_content='hello foo', metadata={'last_accessed_at': datetime.datetime(2023, 12, 27, 15, 30, 50, 57185), 'created_at': datetime.datetime(2023, 12, 27, 15, 30, 44, 720490), 'buffer_idx': 1})]
虚拟时间
使用LangChain中的一些工具,你可以模拟时间组件。
import datetimefrom langchain_core.utils import mock_now# Notice the last access time is that date time
with mock_now(datetime.datetime(2024, 2, 3, 10, 11)):print(retriever.get_relevant_documents("hello world"))[Document(page_content='hello world', metadata={'last_accessed_at': MockDateTime(2024, 2, 3, 10, 11), 'created_at': datetime.datetime(2023, 12, 27, 15, 30, 44, 532941), 'buffer_idx': 0})]Edit this page
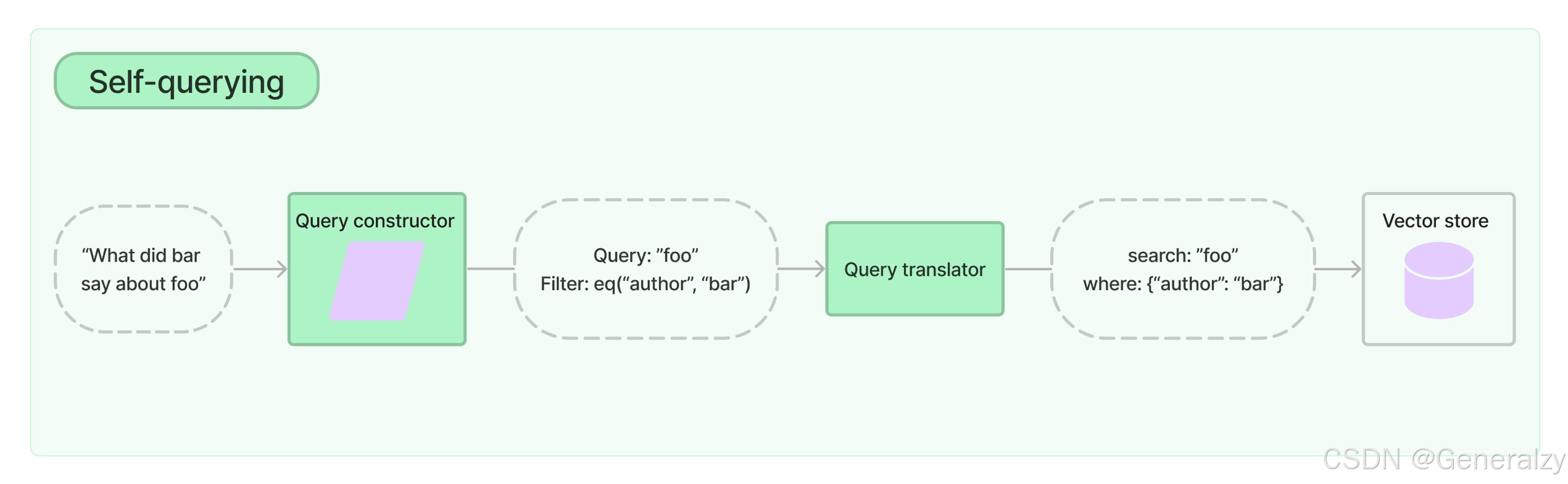
“自查询”检索
自查询检索器顾名思义,具有自我查询的能力。具体来说,给定任何自然语言查询,检索器使用查询构建的 LLM 链来编写结构化查询,然后将该结构化查询应用于其底层的向量存储。这使得检索器不仅可以使用用户输入的查询与存储文档的内容进行语义相似性比较,还可以从用户查询中提取存储文档元数据的过滤器并执行这些过滤器。
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddingsdocs = [Document(page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",metadata={"year": 1993, "rating": 7.7, "genre": "science fiction"},),Document(page_content="Leo DiCaprio gets lost in a dream within a dream within a dream within a ...",metadata={"year": 2010, "director": "Christopher Nolan", "rating": 8.2},),Document(page_content="A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea",metadata={"year": 2006, "director": "Satoshi Kon", "rating": 8.6},),Document(page_content="A bunch of normal-sized women are supremely wholesome and some men pine after them",metadata={"year": 2019, "director": "Greta Gerwig", "rating": 8.3},),Document(page_content="Toys come alive and have a blast doing so",metadata={"year": 1995, "genre": "animated"},),Document(page_content="Three men walk into the Zone, three men walk out of the Zone",metadata={"year": 1979,"director": "Andrei Tarkovsky","genre": "thriller","rating": 9.9,},),
]
vectorstore = Chroma.from_documents(docs, OpenAIEmbeddings())
现在我们可以实例化我们的检索器。为此,我们需要提前提供一些关于文档支持的元数据字段的信息以及文档内容的简短描述。
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_openai import ChatOpenAImetadata_field_info = [AttributeInfo(name="genre",description="The genre of the movie. One of ['science fiction', 'comedy', 'drama', 'thriller', 'romance', 'action', 'animated']",type="string",),AttributeInfo(name="year",description="The year the movie was released",type="integer",),AttributeInfo(name="director",description="The name of the movie director",type="string",),AttributeInfo(name="rating", description="A 1-10 rating for the movie", type="float"),
]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm,vectorstore,document_content_description,metadata_field_info,
)
现在我们可以实际尝试使用我们的检索器!
# This example only specifies a filter
retriever.invoke("I want to watch a movie rated higher than 8.5")[Document(page_content='Three men walk into the Zone, three men walk out of the Zone', metadata={'director': 'Andrei Tarkovsky', 'genre': 'thriller', 'rating': 9.9, 'year': 1979}),Document(page_content='A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea', metadata={'director': 'Satoshi Kon', 'rating': 8.6, 'year': 2006})
我们还可以使用自查询检索器来指定 k:要获取的文档数量。
我们可以通过将 enable_limit=True 传递给构造函数来实现这一点。
retriever = SelfQueryRetriever.from_llm(llm,vectorstore,document_content_description,metadata_field_info,enable_limit=True,
)# This example only specifies a relevant query
retriever.invoke("What are two movies about dinosaurs")
使用 LCEL 从头构建
为了了解底层发生了什么,并获得更多自定义控制,我们可以从头开始重建我们的检索器。
首先,我们需要创建一个查询构建链。这个链将接受用户查询并生成一个 StructuredQuery 对象,该对象捕获用户指定的过滤器。langChain提供了一些帮助函数来创建提示和输出解析器。
from langchain.chains.query_constructor.base import (StructuredQueryOutputParser,get_query_constructor_prompt,
)prompt = get_query_constructor_prompt(document_content_description,metadata_field_info,
)
output_parser = StructuredQueryOutputParser.from_components()
query_constructor = prompt | llm | output_parser
让我们看看我们的提示词:
print(prompt.format(query="dummy question"))Your goal is to structure the user's query to match the request schema provided below.<< Structured Request Schema >>
When responding use a markdown code snippet with a JSON object formatted in the following schema:\`\`\`json
{"query": string \ text string to compare to document contents"filter": string \ logical condition statement for filtering documents
}
\`\`\`
....
以及我们的完整链条产生的结果:
query_constructor.invoke({"query": "What are some sci-fi movies from the 90's directed by Luc Besson about taxi drivers"}
)StructuredQuery(query='taxi driver', filter=Operation(operator=<Operator.AND: 'and'>, arguments=[Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='genre', value='science fiction'), Operation(operator=<Operator.AND: 'and'>, arguments=[Comparison(comparator=<Comparator.GTE: 'gte'>, attribute='year', value=1990), Comparison(comparator=<Comparator.LT: 'lt'>, attribute='year', value=2000)]), Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='director', value='Luc Besson')]), limit=None)
查询构造器是自查询检索器的关键元素。要构建一个优秀的检索系统,您需要确保查询构造器能够良好工作。通常这需要调整提示词、提示词中的示例、属性描述等。
下一个关键元素是结构化查询翻译器。这个对象负责将通用的 StructuredQuery 对象翻译成您使用的向量存储语法中的元数据过滤器。LangChain 附带了许多内置翻译器。
from langchain_community.query_constructors.chroma import ChromaTranslatorretriever = SelfQueryRetriever(query_constructor=query_constructor,vectorstore=vectorstore,structured_query_translator=ChromaTranslator(),
)retriever.invoke("What's a movie after 1990 but before 2005 that's all about toys, and preferably is animated"
)
混合搜索
LangChain中的标准搜索是通过向量相似度完成的。然而,一些向量存储实现(如Astra DB、ElasticSearch、Neo4J、AzureSearch、Qdrant等)也支持更高级的搜索,结合了向量相似度搜索和其他搜索技术(全文搜索、BM25等)。这通常被称为“混合”搜索。
步骤 1:确保您使用的向量存储支持混合搜索
目前,在LangChain中没有统一的方法来执行混合搜索。每个向量存储可能有自己实现的方法。通常,这作为一个关键字参数在similarity_search中传递。
通过阅读文档或源代码,确定您使用的向量存储是否支持混合搜索,如果支持,了解如何使用它。
步骤 2:将该参数添加为链的可配置字段
这将使您能够轻松调用链并在运行时配置任何相关标志。
步骤 3:使用该可配置字段调用链
现在,在运行时您可以使用可配置字段调用此链。
使用Astra DB的Cassandra/CQL接口作为这个例子。(需要密钥)
pip install "cassio>=0.1.7"
import cassiocassio.init(database_id="Your database ID",token="Your application token",keyspace="Your key space",
)
使用标准索引分析器创建 Cassandra VectorStore。索引分析器用于启用术语匹配。
from cassio.table.cql import STANDARD_ANALYZER
from langchain_community.vectorstores import Cassandra
from langchain_openai import OpenAIEmbeddingsembeddings = OpenAIEmbeddings()
vectorstore = Cassandra(embedding=embeddings,table_name="test_hybrid",body_index_options=[STANDARD_ANALYZER],session=None,keyspace=None,
)vectorstore.add_texts(["In 2023, I visited Paris","In 2022, I visited New York","In 2021, I visited New Orleans",]
)
如果我们进行标准相似性搜索,我们会得到所有文档:
vectorstore.as_retriever().invoke("What city did I visit last?")[Document(page_content='In 2022, I visited New York'),
Document(page_content='In 2023, I visited Paris'),
Document(page_content='In 2021, I visited New Orleans')]
Astra DB vectorstore body_search 参数可用于根据术语 new 过滤搜索。
vectorstore.as_retriever(search_kwargs={"body_search": "new"}).invoke("What city did I visit last?"
)
[Document(page_content='In 2022, I visited New York'),
Document(page_content='In 2021, I visited New Orleans')]
现在可以创建将用于问答的链。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import (ConfigurableField,RunnablePassthrough,
)
from langchain_openai import ChatOpenAItemplate = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)model = ChatOpenAI()retriever = vectorstore.as_retriever()
在这里,我们标记检索器为具有可配置字段。所有 vectorstore 检索器都有 search_kwargs 作为字段。这只是一个字典,包含 vectorstore 特定字段。
configurable_retriever = retriever.configurable_fields(search_kwargs=ConfigurableField(id="search_kwargs",name="Search Kwargs",description="The search kwargs to use",)
)
现在可以使用我们的可配置检索器创建链。
chain = ({"context": configurable_retriever, "question": RunnablePassthrough()}| prompt| model| StrOutputParser()
)chain.invoke("What city did I visit last?")
这里{"context": configurable_retriever, "question": RunnablePassthrough()},是一个 Runnable 组合,将不同的输入组件并行运行,然后把结果合并成一个字典。RunnablePassthrough() 只是一个透传组件,它不做任何处理,直接返回原始输入 “What city did I visit last?”。
之所以不写成{"context": configurable_retriever, "question": "我的问题"},在 LangChain 的 Runnable 体系中,所有的组件(如 configurable_retriever、prompt、model 等)都应该是 可执行的(即 Runnable 对象)。但 普通的字符串(“我的问题”)不是 Runnable,所以不能直接用在 Runnable 链中。
RunnablePassthrough() 也会执行 invoke(),但它只是直接返回输入的内容,即 “我的问题”。
在 LangChain 中,Runnable 组件可以用 字典(dict) 作为输入的第一步,这是一种 “并行执行”(Parallel Execution) 机制,允许多个 Runnable 组件同时运行,并将它们的输出合并为字典传递给下一个步骤。
最终,它们的输出被组合成:
{"context": <检索到的文档>, "question": "What city did I visit last?"
}
我们现在可以使用可配置选项调用链。search_kwargs 是可配置字段的 ID。该值是用于 Astra DB 的搜索 kwargs。
chain.invoke("What city did I visit last?",config={"configurable": {"search_kwargs": {"body_search": "new"}}},
)
输出解析器组件
输出解析器负责获取模型的输出并将其转换为更适合下游任务的格式。 在使用大型语言模型生成结构化数据或规范化聊天模型和大型语言模型的输出时非常有用。
LangChain 有许多不同类型的输出解析器。这是 LangChain 支持的输出解析器列表。下表包含各种信息:
- 名称: 输出解析器的名称
- 支持流式处理: 输出解析器是否支持流式处理。
- 有格式说明: 输出解析器是否有格式说明。通常在以下情况下可用: (a) 所需的模式未在提示中指定,而是在其他参数中(如 OpenAI 函数调用),或 (b) 当 OutputParser 包装另一个 OutputParser 时。
- 调用 LLM: 此输出解析器是否自己调用大型语言模型。通常只有那些试图纠正格式错误输出的输出解析器才会这样做。
- 输入类型: 预期的输入类型。大多数输出解析器适用于字符串和消息,但某些(如 OpenAI 函数)需要带有特定关键字参数的消息。
- 输出类型: 解析器返回的对象的输出类型。
- 描述: 我们对这个输出解析器的评论以及何时使用它。
| 名称 | 支持流式处理 | 有格式说明 | 调用大型语言模型 | 输入类型 | 输出类型 | 描述 |
|---|---|---|---|---|---|---|
| JSON | ✅ | ✅ | str | 消息 | JSON对象 | 返回指定的JSON对象。您可以指定一个Pydantic模型,它将返回该模型的JSON。可能是获取不使用函数调用的结构化数据的最可靠输出解析器。 | |
| XML | ✅ | ✅ | str | 消息 | dict | 返回标签的字典。当需要XML输出时使用。与擅长编写XML的模型(如Anthropic的模型)一起使用。 | |
| CSV | ✅ | ✅ | str | 消息 | List[str] | 返回以逗号分隔的值的列表。 | |
| OutputFixing | ✅ | str | 消息 | 包装另一个输出解析器。如果该输出解析器出错,则会将错误消息和错误输出传递给大型语言模型,并请求其修复输出。 | |||
| RetryWithError | ✅ | str | 消息 | 包装另一个输出解析器。如果该输出解析器出错,则会将原始输入、错误输出和错误消息传递给大型语言模型,并请求其修复。与OutputFixingParser相比,这个还会发送原始说明。 | |||
| Pydantic | ✅ | str | 消息 | pydantic.BaseModel | 接受用户定义的Pydantic模型,并以该格式返回数据。 | ||
| YAML | ✅ | str | 消息 | pydantic.BaseModel | 接受用户定义的Pydantic模型,并以该格式返回数据。使用YAML进行编码。 | ||
| PandasDataFrame | ✅ | str | 消息 | dict | 对于使用pandas DataFrame进行操作非常有用。 | ||
| 枚举 | ✅ | str | 消息 | Enum | 将响应解析为提供的枚举值之一。 | ||
| 日期时间 | ✅ | str | 消息 | datetime.datetime | 将响应解析为日期时间字符串。 | ||
| 结构化 | ✅ | str | 消息 | Dict[str, str] | 一种输出解析器,返回结构化信息。它的功能不如其他输出解析器强大,因为它只允许字段为字符串。当您使用较小的LLM时,这可能会很有用。 |
使用输出解析器将LLM响应解析为结构化格式
语言模型输出文本。但有时您希望获得比仅仅文本更结构化的信息。虽然一些大模型供应商支持内置方式返回结构化输出,但并非所有都支持。
输出解析器是帮助结构化语言模型响应的类。输出解析器必须实现两个主要方法:
- “Get format instructions”: 一个返回字符串的方法,包含有关语言模型输出应如何格式化的说明。
- “Parse”: 一个接受字符串(假定为来自语言模型的响应)并将其解析为某种结构的方法。
然后是一个可选的方法:
3. “Parse with prompt”:一个接受字符串(假定为来自语言模型的响应)和一个提示(假定为生成该响应的提示)并将其解析为某种结构的方法。提示主要是在输出解析器希望以某种方式重试或修复输出时提供的,并需要提示中的信息来做到这一点。
下面我们将介绍主要的输出解析器类型,PydanticOutputParser。
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI
from pydantic import BaseModel, Field, model_validatormodel = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0.0)# Define your desired data structure.
class Joke(BaseModel):setup: str = Field(description="question to set up a joke")punchline: str = Field(description="answer to resolve the joke")# You can add custom validation logic easily with Pydantic.@model_validator(mode="before")@classmethoddef question_ends_with_question_mark(cls, values: dict) -> dict:setup = values["setup"]if setup[-1] != "?":raise ValueError("Badly formed question!")return values# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=Joke)prompt = PromptTemplate(template="Answer the user query.\n{format_instructions}\n{query}\n",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)# And a query intended to prompt a language model to populate the data structure.
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": "Tell me a joke."})
parser.invoke(output)
Joke(setup='Why did the tomato turn red?', punchline='Because it saw the salad dressing!')
输出解析器实现了Runable,这是LangChain表达式 (LCEL)的基本构建块。这意味着它们支持invoke、ainvoke、stream、astream、batch、abatch、astream_log调用。
输出解析器接受一个字符串或BaseMessage作为输入,并可以返回任意类型。
parser.invoke(output)Joke(setup='Why did the chicken cross the road?', punchline='To get to the other side!')
我们也可以将解析器直接添加到我们的Runnable序列中,而不是手动调用它:
chain = prompt | model | parser
chain.invoke({"query": "Tell me a joke."})Joke(setup='Why did the chicken cross the road?', punchline='To get to the other side!')
虽然所有解析器都支持流式接口,但只有某些解析器可以通过部分解析的对象进行流式处理,因为这高度依赖于输出类型。无法构建部分对象的解析器将简单地返回完全解析的输出。
例如,SimpleJsonOutputParser可以通过部分输出进行流式处理:
from langchain.output_parsers.json import SimpleJsonOutputParserjson_prompt = PromptTemplate.from_template("Return a JSON object with an `answer` key that answers the following question: {question}"
)
json_parser = SimpleJsonOutputParser()
json_chain = json_prompt | model | json_parserlist(json_chain.stream({"question": "Who invented the microscope?"}))
[{},{'answer': ''},{'answer': 'Ant'},{'answer': 'Anton'},{'answer': 'Antonie'},{'answer': 'Antonie van'},{'answer': 'Antonie van Lee'},{'answer': 'Antonie van Leeu'},{'answer': 'Antonie van Leeuwen'},{'answer': 'Antonie van Leeuwenho'},{'answer': 'Antonie van Leeuwenhoek'}]
而PydanticOutputParser则不能:
list(chain.stream({"query": "Tell me a joke."}))[Joke(setup='Why did the chicken cross the road?', punchline='To get to the other side!')]
解析 JSON 输出
JsonOutputParser 是一个内置选项,用于提示和解析 JSON 输出。它的功能与 PydanticOutputParser 类似,还支持流式返回部分 JSON 对象。
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Fieldmodel = ChatOpenAI(temperature=0)# Define your desired data structure.
class Joke(BaseModel):setup: str = Field(description="question to set up a joke")punchline: str = Field(description="answer to resolve the joke")# And a query intented to prompt a language model to populate the data structure.
joke_query = "Tell me a joke."# Set up a parser + inject instructions into the prompt template.
parser = JsonOutputParser(pydantic_object=Joke)prompt = PromptTemplate(template="Answer the user query.\n{format_instructions}\n{query}\n",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)chain = prompt | model | parserchain.invoke({"query": joke_query})
{'setup': "Why couldn't the bicycle stand up by itself?",'punchline': 'Because it was two tired!'}
上文,我们将 format_instructions 从解析器直接传递到提示中。您可以并且应该尝试在提示的其他部分添加自己的格式提示,以增强或替换默认指令:
parser.get_format_instructions()
'The output should be formatted as a JSON instance that conforms to the JSON schema below.\n\nAs an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}\nthe object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.\n\nHere is the output schema:\n\`\`\`\n{"properties": {"setup": {"title": "Setup", "description": "question to set up a joke", "type": "string"}, "punchline": {"title": "Punchline", "description": "answer to resolve the joke", "type": "string"}}, "required": ["setup", "punchline"]}\n\`\`\`'
如上所述,JsonOutputParser 和 PydanticOutputParser 之间的一个关键区别是 JsonOutputParser 输出解析器支持流式部分块。
for s in chain.stream({"query": joke_query}):print(s)
{}
{'setup': ''}
{'setup': 'Why'}
{'setup': 'Why couldn'}
{'setup': "Why couldn't"}
{'setup': "Why couldn't the"}
{'setup': "Why couldn't the bicycle"}
也可以在不使用 Pydantic 的情况下使用 JsonOutputParser。这将提示模型返回 JSON,但不会提供关于模式应是什么的具体信息。
Pydantic 的表单校验其实在这里充当了prompt!
joke_query = "Tell me a joke."parser = JsonOutputParser()prompt = PromptTemplate(template="Answer the user query.\n{format_instructions}\n{query}\n",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)chain = prompt | model | parserchain.invoke({"query": joke_query}){'response': "Sure! Here's a joke for you: Why couldn't the bicycle stand up by itself? Because it was two tired!"}
解析 XML 输出
来自不同提供商的大型语言模型通常在特定数据上训练时具有不同的优势。这也意味着某些模型在生成 JSON 以外格式的输出时可能“更好”且更可靠。
使用Anthropic的Claude-2模型(https://docs.anthropic.com/claude/docs),这是一个针对XML标签进行优化的模型。(需要apikey)pip install -qU langchain langchain-anthropic
import os
from getpass import getpassif "ANTHROPIC_API_KEY" not in os.environ:os.environ["ANTHROPIC_API_KEY"] = getpass()from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import XMLOutputParser
from langchain_core.prompts import PromptTemplatemodel = ChatAnthropic(model="claude-2.1", max_tokens_to_sample=512, temperature=0.1)actor_query = "Generate the shortened filmography for Tom Hanks."output = model.invoke(f"""{actor_query}
Please enclose the movies in <movie></movie> tags"""
)print(output.content)
Here is the shortened filmography for Tom Hanks, with movies enclosed in XML tags:<movie>Splash</movie>
<movie>Big</movie>
<movie>A League of Their Own</movie>
<movie>Sleepless in Seattle</movie>
输出效果很好!但将 XML 解析为更易于使用的格式会更好。我们可以使用 XMLOutputParser 来为提示添加默认格式说明,并将输出的 XML 解析为字典:
parser = XMLOutputParser()# We will add these instructions to the prompt below
parser.get_format_instructions()
这是xml的prompt:
'The output should be formatted as a XML file.\n1. Output should conform to the tags below. \n2. If tags are not given, make them on your own.\n3. Remember to always open and close all the tags.\n\nAs an example, for the tags ["foo", "bar", "baz"]:\n1. String "<foo>\n <bar>\n <baz></baz>\n </bar>\n</foo>" is a well-formatted instance of the schema. \n2. String "<foo>\n <bar>\n </foo>" is a badly-formatted instance.\n3. String "<foo>\n <tag>\n </tag>\n</foo>" is a badly-formatted instance.\n\nHere are the output tags:\n\`\`\`\nNone\n\`\`\`'
prompt = PromptTemplate(template="""{query}\n{format_instructions}""",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)chain = prompt | model | parseroutput = chain.invoke({"query": actor_query})
print(output)
我们还可以添加一些标签,以便根据我们的需求定制输出。您可以并且应该在提示的其他部分尝试添加自己的格式提示,以增强或替换默认说明:
parser = XMLOutputParser(tags=["movies", "actor", "film", "name", "genre"])# We will add these instructions to the prompt below
parser.get_format_instructions()
prompt = PromptTemplate(template="""{query}\n{format_instructions}""",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)chain = prompt | model | parseroutput = chain.invoke({"query": actor_query})print(output)
{'movies': [{'actor': [{'name': 'Tom Hanks'}, {'film': [{'name': 'Forrest Gump'}, {'genre': 'Drama'}]}, {'film': [{'name': 'Cast Away'}, {'genre': 'Adventure'}]}, {'film': [{'name': 'Saving Private Ryan'}, {'genre': 'War'}]}]}]}
这个输出解析器还支持部分块的流式处理。
for s in chain.stream({"query": actor_query}):print(s){'movies': [{'actor': [{'name': 'Tom Hanks'}]}]}
{'movies': [{'actor': [{'film': [{'name': 'Forrest Gump'}]}]}]}
{'movies': [{'actor': [{'film': [{'genre': 'Drama'}]}]}]}
{'movies': [{'actor': [{'film': [{'name': 'Cast Away'}]}]}]}
解析 YAML 输出
使用 Pydantic 和 YamlOutputParser 来声明我们的数据模型,并为模型提供更多上下文,以便生成正确类型的 YAML:
from langchain.output_parsers import YamlOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field# Define your desired data structure.
class Joke(BaseModel):setup: str = Field(description="question to set up a joke")punchline: str = Field(description="answer to resolve the joke")model = ChatOpenAI(temperature=0)# And a query intented to prompt a language model to populate the data structure.
joke_query = "Tell me a joke."# Set up a parser + inject instructions into the prompt template.
parser = YamlOutputParser(pydantic_object=Joke)prompt = PromptTemplate(template="Answer the user query.\n{format_instructions}\n{query}\n",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)chain = prompt | model | parserchain.invoke({"query": joke_query})
Joke(setup="Why couldn't the bicycle find its way home?", punchline='Because it lost its bearings!')
解析器将自动解析输出的 YAML,并使用数据创建 Pydantic 模型。
在解析错误发生时重试
虽然在某些情况下,仅通过查看输出就可以修复任何解析错误,但在输出不仅格式不正确,或部分完成时则不行
from langchain.output_parsers import OutputFixingParser
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI, OpenAI
from pydantic import BaseModel, Fieldtemplate = """Based on the user question, provide an Action and Action Input for what step should be taken.
{format_instructions}
Question: {query}
Response:"""class Action(BaseModel):action: str = Field(description="action to take")action_input: str = Field(description="input to the action")parser = PydanticOutputParser(pydantic_object=Action)prompt = PromptTemplate(template="Answer the user query.\n{format_instructions}\n{query}\n",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)prompt_value = prompt.format_prompt(query="who is leo di caprios gf?")
bad_response = '{"action": "search"}'
如果我们尝试按原样解析此响应,将会出现错误:
parser.parse(bad_response)--------------------------------------------------------------------------
``````output
ValidationError Traceback (most recent call last)
``````output
File ~/workplace/langchain/libs/langchain/langchain/output_parsers/pydantic.py:30, in PydanticOutputParser.parse(self, text)29 json_object = json.loads(json_str, strict=False)
---> 30 return self.pydantic_object.parse_obj(json_object)32 except (json.JSONDecodeError, ValidationError) as e:
如果我们尝试使用 OutputFixingParser 来修复这个错误,它会感到困惑 - 也就是说,它不知道实际应该为 action input 放什么。
fix_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())fix_parser.parse(bad_response)
# Action(action='search', action_input='input')
相反,我们可以使用 RetryOutputParser,它将提示(以及原始输出)传入,以再次尝试获得更好的响应。
from langchain.output_parsers import RetryOutputParserretry_parser = RetryOutputParser.from_llm(parser=parser, llm=OpenAI(temperature=0))retry_parser.parse_with_prompt(bad_response, prompt_value)# Action(action='search', action_input='leo di caprio girlfriend')
我们还可以通过自定义链轻松添加 RetryOutputParser,该链将原始 LLM/ChatModel 输出转换为更可用的格式。
from langchain_core.runnables import RunnableLambda, RunnableParallelcompletion_chain = prompt | OpenAI(temperature=0)main_chain = RunnableParallel(completion=completion_chain, prompt_value=prompt
) | RunnableLambda(lambda x: retry_parser.parse_with_prompt(**x))main_chain.invoke({"query": "who is leo di caprios gf?"})Action(action='search', action_input='leo di caprio girlfriend')
在 LangChain 里,Runnable 组件用于 构建流式、可组合的执行链。
-
RunnableLambda:自定义 Python 处理逻辑,在链中执行任意 Python 代码。这里RunnableParallel(…) 并行执行:completion_chain(执行 LLM 生成回答)和prompt_value=prompt(格式化 prompt,准备输入)
-
RunnableParallel:并行执行多个 Runnable 组件,然后把它们的结果合并成一个字典。这里
RunnableLambda(lambda x: retry_parser.parse_with_prompt(**x))解析 RunnableParallel 的输出,并解析成可执行的 Action。
使用输出修复解析器
这个输出解析器包装了另一个输出解析器,如果第一个解析器失败,它会调用另一个大型语言模型来修复任何错误。
但我们可以做其他事情,而不仅仅是抛出错误。具体来说,我们可以将格式错误的输出和格式化的指令一起传递给模型,并要求它进行修复。
在这个例子中,我们将使用上面的 Pydantic 输出解析器。如果我们传递一个不符合模式的结果,会发生以下情况:
from typing import Listfrom langchain_core.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Fieldclass Actor(BaseModel):name: str = Field(description="name of an actor")film_names: List[str] = Field(description="list of names of films they starred in")actor_query = "Generate the filmography for a random actor."parser = PydanticOutputParser(pydantic_object=Actor)misformatted = "{'name': 'Tom Hanks', 'film_names': ['Forrest Gump']}"
parser.parse(misformatted)
---------------------------------------------------------------------------
``````output
JSONDecodeError Traceback (most recent call last)
``````output
File ~/workplace/langchain/libs/langchain/langchain/output_parsers/pydantic.py:29, in PydanticOutputParser.parse(self, text)28 json_str = match.group()
---> 29 json_object = json.loads(json_str, strict=False)30 return self.pydantic_object.parse_obj(json_object)
``````output
File ~/.pyenv/versions/3.10.1/lib/python3.10/json/__init__.py:359, in loads(s, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, **kw)358 kw['parse_constant'] = parse_constant
现在我们可以构建并使用 OutputFixingParser。这个输出解析器接受另一个输出解析器作为参数,同时也接受一个大型语言模型(LLM),用于尝试纠正任何格式错误。
from langchain.output_parsers import OutputFixingParsernew_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())new_parser.parse(misformatted)
# Actor(name='Tom Hanks', film_names=['Forrest Gump'])
创建自定义输出解析器
实现自定义解析器有两种方法:
- 使用 LCEL 中的 RunnableLambda 或 RunnableGenerator – langChain强烈推荐这种方法用于大多数用例
- 通过从一个基础类继承来进行输出解析 – 这是一种较为复杂的方法
这两种方法之间的区别主要是表面的,主要体现在触发的回调(例如,on_chain_start 与 on_parser_start)以及在像 LangSmith 这样的追踪平台中,如何可视化可运行的 lambda 与解析器。
可运行的 Lambda 和生成器
推荐的解析方式是使用 可运行的 lambda 和 可运行的生成器!在这里,我们将进行一个简单的解析,将模型输出的大小写反转。
例如,如果模型输出:“Meow”,解析器将生成 “mEOW”。
from typing import Iterablefrom langchain_anthropic.chat_models import ChatAnthropic
from langchain_core.messages import AIMessage, AIMessageChunkmodel = ChatAnthropic(model_name="claude-2.1")def parse(ai_message: AIMessage) -> str:"""Parse the AI message."""return ai_message.content.swapcase()chain = model | parse
chain.invoke("hello")
当使用 | 语法组合时,LCEL 会自动将函数 parse 升级为 RunnableLambda(parse)。
如果你不喜欢这样,你可以手动导入 RunnableLambda,然后运行 parse = RunnableLambda(parse)。
注意这对流式处理无效,因为解析器在解析输出之前会聚合输入。
for chunk in chain.stream("tell me about yourself in one sentence"):print(chunk, end="|", flush=True)i'M cLAUDE, AN ai ASSISTANT CREATED BY aNTHROPIC TO BE HELPFUL, HARMLESS, AND HONEST.|
如果我们想实现一个流式解析器,我们可以让解析器接受一个可迭代的输入,并生成 结果,随着它们的可用性而生成。
from langchain_core.runnables import RunnableGeneratordef streaming_parse(chunks: Iterable[AIMessageChunk]) -> Iterable[str]:for chunk in chunks:yield chunk.content.swapcase()streaming_parse = RunnableGenerator(streaming_parse)
chain = model | streaming_parse
chain.invoke("hello")
从解析基类继承
实现解析器的另一种方法是从 BaseOutputParser、BaseGenerationOutputParser 或其他基解析器继承,具体取决于你需要做什么。
最简单的输出解析器类型扩展了 BaseOutputParser 类,并且必须实现以下方法:
- parse:接收模型的字符串输出并进行解析。
- (可选)_type:标识解析器的名称。
当聊天模型或大型语言模型的输出格式不正确时,可以抛出 OutputParserException 来指示解析失败是由于输入不良。使用此异常允许使用解析器的代码以一致的方式处理异常。
因为 BaseOutputParser 实现了 Runnable 接口,所以以这种方式创建的任何自定义解析器将成为有效的 LangChain 可运行对象,并将受益于自动异步支持、批处理接口、日志支持等。
这是一个简单的解析器,可以解析布尔值的字符串表示(例如,YES 或 NO),并将其转换为相应的 boolean 类型。
from langchain_core.exceptions import OutputParserException
from langchain_core.output_parsers import BaseOutputParser# The [bool] desribes a parameterization of a generic.
# It's basically indicating what the return type of parse is
# in this case the return type is either True or False
class BooleanOutputParser(BaseOutputParser[bool]):"""Custom boolean parser."""true_val: str = "YES"false_val: str = "NO"def parse(self, text: str) -> bool:cleaned_text = text.strip().upper()if cleaned_text not in (self.true_val.upper(), self.false_val.upper()):raise OutputParserException(f"BooleanOutputParser expected output value to either be "f"{self.true_val} or {self.false_val} (case-insensitive). "f"Received {cleaned_text}.")return cleaned_text == self.true_val.upper()@propertydef _type(self) -> str:return "boolean_output_parser"parser = BooleanOutputParser()
parser.invoke("YES")
# True
让我们测试更改参数化。
parser = BooleanOutputParser(true_val="OKAY")
parser.invoke("OKAY")True
解析器可以处理来自大型语言模型(字符串)或聊天模型(AIMessage)的输出!
from langchain_anthropic.chat_models import ChatAnthropicanthropic = ChatAnthropic(model_name="claude-2.1")
anthropic.invoke("say OKAY or NO")AIMessage(content='OKAY')chain = anthropic | parser
chain.invoke("say OKAY or NO")True
解析原始模型输出
有时模型输出中除了原始文本之外还有其他重要的元数据。一个例子是工具调用,其中传递给被调用函数的参数在一个单独的属性中返回。如果您需要更细粒度的控制,可以子类化 BaseGenerationOutputParser 类。
该类需要一个单一的方法 parse_result。该方法接受原始模型输出(例如,Generation 或 ChatGeneration 的列表)并返回解析后的输出。
支持 Generation 和 ChatGeneration 使得解析器能够处理常规大型语言模型以及聊天模型。
from typing import Listfrom langchain_core.exceptions import OutputParserException
from langchain_core.messages import AIMessage
from langchain_core.output_parsers import BaseGenerationOutputParser
from langchain_core.outputs import ChatGeneration, Generationclass StrInvertCase(BaseGenerationOutputParser[str]):"""An example parser that inverts the case of the characters in the message.This is an example parse shown just for demonstration purposes and to keepthe example as simple as possible."""def parse_result(self, result: List[Generation], *, partial: bool = False) -> str:"""Parse a list of model Generations into a specific format.Args:result: A list of Generations to be parsed. The Generations are assumedto be different candidate outputs for a single model input.Many parsers assume that only a single generation is passed it in.We will assert for thatpartial: Whether to allow partial results. This is used for parsersthat support streaming"""if len(result) != 1:raise NotImplementedError("This output parser can only be used with a single generation.")generation = result[0]if not isinstance(generation, ChatGeneration):# Say that this one only works with chat generationsraise OutputParserException("This output parser can only be used with a chat generation.")return generation.message.content.swapcase()chain = anthropic | StrInvertCase()
chain.invoke("Tell me a short sentence about yourself")
LangChain表达式 (LCEL)
LangChain 表达式语言(LCEL)简介
LangChain 表达式语言(LCEL)是一种 声明式方式,用于连接 LangChain 组件。它从一开始就被设计为支持原型直接投入生产,无需修改代码,适用于从最简单的 “提示词 + 大型语言模型” 到包含数百个步骤的复杂工作流。
以下是 LCEL 的优势:
🔹 一流的流式支持
使用 LCEL 构建的链能够 最大化减少首次响应时间(即第一个输出块出现的时间)。对于某些链,例如直接从大型语言模型流式传输数据到输出解析器,LCEL 可以以与模型供应商相同的速度返回解析后的增量输出,提高交互体验。
🔹 强大的异步支持
任何基于 LCEL 的链都可以:
- 在 同步 API 中调用(适用于 Jupyter Notebook 进行原型开发)。
- 在 异步 API 中调用(适用于 LangServe 服务器的高并发环境)。
这意味着你可以在原型和生产环境中复用相同的代码,同时保持出色的性能,并支持多个并发请求。
🔹 自动优化并行执行
当 LCEL 发现链中存在 可并行执行的步骤(例如从多个检索器获取文档),它会自动优化执行,无论是在同步还是异步接口中,都能 减少延迟,提高效率。
🔹 内置重试与回退机制
LCEL 支持为任意部分的执行配置重试与回退机制,提高稳定性。这在大规模应用中尤为重要。目前,团队还在为 流式响应 添加重试/回退支持,以便在不增加延迟的情况下提升可靠性。
🔹 访问中间结果
在复杂链路中,访问中间步骤的结果 可以:
- 提供实时反馈,让用户了解当前进度。
- 辅助调试,帮助开发者定位问题。
LCEL 允许 流式传输中间结果,并且每个 LangServe 服务器都支持此功能。
🔹 自动生成输入 & 输出模式
LCEL 可以自动推断链的结构,并生成 Pydantic 和 JSONSchema 模式。这些模式可用于:
- 输入/输出数据验证,确保数据格式正确。
- 集成 LangServe,提高 API 兼容性和安全性。
🔹 无缝集成 LangSmith 进行跟踪 & 调试
随着工作流变得复杂,理解每个步骤的执行情况变得至关重要。LCEL 自动记录所有步骤到 LangSmith,实现:
- 可观测性:查看执行路径、数据流向。
- 可调试性:快速定位错误,提高开发效率。
LCEL 提供 流式支持、并行执行、异步兼容、重试机制、输入验证、调试跟踪 等能力,使 LangChain 更高效、更稳定、更易于维护。🚀
"Runnable"协议
LangChain 的 Runnable 协议
为简化 自定义链 的创建,LangChain 引入了 Runnable 协议。许多 LangChain 组件都实现了这一协议,包括:
- 聊天模型、大型语言模型(LLM)
- 输出解析器
- 检索器
- 提示词模板
此外,LangChain 还提供了一些用于 处理 Runnable 对象的通用方法,让自定义链的创建和调用变得更加直观。
🔹 Runnable 标准接口
所有 Runnable 组件都遵循以下 标准接口,便于定义和调用:
| 方法 | 作用 |
|---|---|
stream | 流式返回 响应的块 |
invoke | 在 单个输入 上调用链 |
batch | 在 输入列表 上调用链 |
🔹 异步支持
LangChain 还提供了 异步版本,可与 asyncio 的 await 语法一起使用,提高并发性能:
| 异步方法 | 作用 |
|---|---|
astream | 异步流式 返回响应的块 |
ainvoke | 异步调用 链 |
abatch | 异步批量调用 链 |
astream_log | 实时流式返回 中间步骤,包含最终响应 |
astream_events (测试版) | 流式返回链中发生的事件(langchain-core 0.1.14 引入) |
🔹 Runnable 组件的输入 & 输出
不同类型的 Runnable 组件,其 输入格式 和 输出格式 可能有所不同:
| 组件 | 输入类型 | 输出类型 |
|---|---|---|
| 提示词 | dict | PromptValue |
| 聊天模型 | 字符串 / 聊天消息列表 / PromptValue | 聊天消息 |
| 大型语言模型(LLM) | 字符串 / 聊天消息列表 / PromptValue | 字符串 |
| 输出解析器 | LLM / 聊天模型的输出 | 解析后的数据 |
| 检索器 | 字符串 | 文档列表 |
| 工具 | 字符串 / 字典(取决于工具) | 取决于工具 |
🔹 Runnable 的输入 & 输出模式
所有 Runnable 组件都自动暴露 输入模式 和 输出模式,用于检查输入 & 输出的格式:
| 模式 | 作用 |
|---|---|
input_schema | 自动生成的 输入 Pydantic 模型 |
output_schema | 自动生成的 输出 Pydantic 模型 |
这些模式可以 帮助开发者验证数据结构,确保调用链的稳定性,同时也可用于 API 设计和数据校验。
✅ Runnable 让 LangChain 组件具备标准化的调用方式,支持同步 & 异步执行。
✅ 支持流式处理,减少响应延迟,提高用户体验。
✅ 不同组件的输入 & 输出格式不同,但都提供了模式校验,提升可维护性。
✅ 支持 Pydantic 自动模式推导,有助于输入验证和 API 兼容性。
这使得 LangChain 组件更易组合、复用、扩展,帮助开发者快速搭建强大的 AI 应用! 🚀
LangChain表达式 (LCEL) 速查表
调用一个Runnable
Runnable.invoke() / Runnable.ainvoke()
from langchain_core.runnables import RunnableLambdarunnable = RunnableLambda(lambda x: str(x))
runnable.invoke(5)# Async variant:
# await runnable.ainvoke(5)
批量Runnable
Runnable.batch() / Runnable.abatch()
from langchain_core.runnables import RunnableLambdarunnable = RunnableLambda(lambda x: str(x))
runnable.batch([7, 8, 9])# Async variant:
# await runnable.abatch([7, 8, 9])
['7', '8', '9']
流式Runnable
Runnable.stream() / Runnable.astream()
from langchain_core.runnables import RunnableLambdadef func(x):for y in x:yield str(y)runnable = RunnableLambda(func)for chunk in runnable.stream(range(5)):print(chunk)# Async variant:
# async for chunk in await runnable.astream(range(5)):
# print(chunk)
组合Runnable
管道操作符 |
from langchain_core.runnables import RunnableLambdarunnable1 = RunnableLambda(lambda x: {"foo": x})
runnable2 = RunnableLambda(lambda x: [x] * 2)chain = runnable1 | runnable2chain.invoke(2)
并行调用Runnable
RunnableParallel
from langchain_core.runnables import RunnableLambda, RunnableParallelrunnable1 = RunnableLambda(lambda x: {"foo": x})
runnable2 = RunnableLambda(lambda x: [x] * 2)chain = RunnableParallel(first=runnable1, second=runnable2)chain.invoke(2)
将任何函数转换为Runnable
RunnableLambda
from langchain_core.runnables import RunnableLambdadef func(x):return x + 5runnable = RunnableLambda(func)
runnable.invoke(2)
合并输入和输出字典
RunnablePassthrough.assign
from langchain_core.runnables import RunnableLambda, RunnablePassthroughrunnable1 = RunnableLambda(lambda x: x["foo"] + 7)chain = RunnablePassthrough.assign(bar=runnable1)chain.invoke({"foo": 10})
将输入字典包含在输出字典中
RunnablePassthrough
from langchain_core.runnables import (RunnableLambda,RunnableParallel,RunnablePassthrough,
)runnable1 = RunnableLambda(lambda x: x["foo"] + 7)chain = RunnableParallel(bar=runnable1, baz=RunnablePassthrough())chain.invoke({"foo": 10})
添加默认调用参数
Runnable.bind
from typing import Optionalfrom langchain_core.runnables import RunnableLambdadef func(main_arg: dict, other_arg: Optional[str] = None) -> dict:if other_arg:return {**main_arg, **{"foo": other_arg}}return main_argrunnable1 = RunnableLambda(func)
bound_runnable1 = runnable1.bind(other_arg="bye")bound_runnable1.invoke({"bar": "hello"})
添加fallbacks选项
Runnable.with_fallbacks
from langchain_core.runnables import RunnableLambdarunnable1 = RunnableLambda(lambda x: x + "foo")
runnable2 = RunnableLambda(lambda x: str(x) + "foo")chain = runnable1.with_fallbacks([runnable2])chain.invoke(5)
添加重试
Runnable.with_retry
from langchain_core.runnables import RunnableLambdacounter = -1def func(x):global countercounter += 1print(f"attempt with {counter=}")return x / counterchain = RunnableLambda(func).with_retry(stop_after_attempt=2)chain.invoke(2)
attempt with counter=0
attempt with counter=1
配置Runnable执行
RunnableConfig
from langchain_core.runnables import RunnableLambda, RunnableParallelrunnable1 = RunnableLambda(lambda x: {"foo": x})
runnable2 = RunnableLambda(lambda x: [x] * 2)
runnable3 = RunnableLambda(lambda x: str(x))chain = RunnableParallel(first=runnable1, second=runnable2, third=runnable3)chain.invoke(7, config={"max_concurrency": 2})
# {'first': {'foo': 7}, 'second': [7, 7], 'third': '7'}
将默认配置添加到Runnable
Runnable.with_config
from langchain_core.runnables import RunnableLambda, RunnableParallelrunnable1 = RunnableLambda(lambda x: {"foo": x})
runnable2 = RunnableLambda(lambda x: [x] * 2)
runnable3 = RunnableLambda(lambda x: str(x))chain = RunnableParallel(first=runnable1, second=runnable2, third=runnable3)
configured_chain = chain.with_config(max_concurrency=2)chain.invoke(7)
# {'first': {'foo': 7}, 'second': [7, 7], 'third': '7'}
使Runnable属性可配置
Runnable.with_configurable_fields
from typing import Any, Optionalfrom langchain_core.runnables import (ConfigurableField,RunnableConfig,RunnableSerializable,
)class FooRunnable(RunnableSerializable[dict, dict]):output_key: strdef invoke(self, input: Any, config: Optional[RunnableConfig] = None, **kwargs: Any) -> list:return self._call_with_config(self.subtract_seven, input, config, **kwargs)def subtract_seven(self, input: dict) -> dict:return {self.output_key: input["foo"] - 7}runnable1 = FooRunnable(output_key="bar")
configurable_runnable1 = runnable1.configurable_fields(output_key=ConfigurableField(id="output_key")
)configurable_runnable1.invoke({"foo": 10}, config={"configurable": {"output_key": "not bar"}}
)
# {'not bar': 3}
configurable_runnable1.invoke({"foo": 10})
# {'bar': 3}
使链组件可配置
Runnable.with_configurable_alternatives
from typing import Any, Optionalfrom langchain_core.runnables import RunnableConfig, RunnableLambda, RunnableParallelclass ListRunnable(RunnableSerializable[Any, list]):def invoke(self, input: Any, config: Optional[RunnableConfig] = None, **kwargs: Any) -> list:return self._call_with_config(self.listify, input, config, **kwargs)def listify(self, input: Any) -> list:return [input]class StrRunnable(RunnableSerializable[Any, str]):def invoke(self, input: Any, config: Optional[RunnableConfig] = None, **kwargs: Any) -> list:return self._call_with_config(self.strify, input, config, **kwargs)def strify(self, input: Any) -> str:return str(input)runnable1 = RunnableLambda(lambda x: {"foo": x})configurable_runnable = ListRunnable().configurable_alternatives(ConfigurableField(id="second_step"), default_key="list", string=StrRunnable()
)
chain = runnable1 | configurable_runnablechain.invoke(7, config={"configurable": {"second_step": "string"}})
"{'foo': 7}"
根据输入动态构建链
from langchain_core.runnables import RunnableLambda, RunnableParallelrunnable1 = RunnableLambda(lambda x: {"foo": x})
runnable2 = RunnableLambda(lambda x: [x] * 2)chain = RunnableLambda(lambda x: runnable1 if x > 6 else runnable2)chain.invoke(7)
# {'foo': 7}
生成事件流
Runnable.astream_events
# | echo: falseimport nest_asyncionest_asyncio.apply()from langchain_core.runnables import RunnableLambda, RunnableParallelrunnable1 = RunnableLambda(lambda x: {"foo": x}, name="first")async def func(x):for _ in range(5):yield xrunnable2 = RunnableLambda(func, name="second")chain = runnable1 | runnable2async for event in chain.astream_events("bar", version="v2"):print(f"event={event['event']} | name={event['name']} | data={event['data']}")
event=on_chain_start | name=RunnableSequence | data={'input': 'bar'}
event=on_chain_start | name=first | data={}
event=on_chain_stream | name=first | data={'chunk': {'foo': 'bar'}}
event=on_chain_start | name=second | data={}
event=on_chain_end | name=first | data={'output': {'foo': 'bar'}, 'input': 'bar'}
event=on_chain_stream | name=second | data={'chunk': {'foo': 'bar'}}
event=on_chain_stream | name=RunnableSequence | data={'chunk': {'foo': 'bar'}}
event=on_chain_stream | name=second | data={'chunk': {'foo': 'bar'}}
event=on_chain_stream | name=RunnableSequence | data={'chunk': {'foo': 'bar'}}
event=on_chain_stream | name=second | data={'chunk': {'foo': 'bar'}}
event=on_chain_stream | name=RunnableSequence | data={'chunk': {'foo': 'bar'}}
event=on_chain_stream | name=second | data={'chunk': {'foo': 'bar'}}
event=on_chain_stream | name=RunnableSequence | data={'chunk': {'foo': 'bar'}}
event=on_chain_stream | name=second | data={'chunk': {'foo': 'bar'}}
event=on_chain_stream | name=RunnableSequence | data={'chunk': {'foo': 'bar'}}
event=on_chain_end | name=second | data={'output': {'foo': 'bar'}, 'input': {'foo': 'bar'}}
event=on_chain_end | name=RunnableSequence | data={'output': {'foo': 'bar'}}
按照完成的批次输出
Runnable.batch_as_completed / Runnable.abatch_as_completed
import timefrom langchain_core.runnables import RunnableLambda, RunnableParallelrunnable1 = RunnableLambda(lambda x: time.sleep(x) or print(f"slept {x}"))for idx, result in runnable1.batch_as_completed([5, 1]):print(idx, result)# Async variant:
# async for idx, result in runnable1.abatch_as_completed([5, 1]):
# print(idx, result)
slept 1
1 None
slept 5
0 None
返回输出字典的子集
Runnable.pick
from langchain_core.runnables import RunnableLambda, RunnablePassthroughrunnable1 = RunnableLambda(lambda x: x["baz"] + 5)
chain = RunnablePassthrough.assign(foo=runnable1).pick(["foo", "bar"])chain.invoke({"bar": "hi", "baz": 2})
# {'foo': 7, 'bar': 'hi'}
声明性地创建可运行的批处理版本
Runnable.map
from langchain_core.runnables import RunnableLambdarunnable1 = RunnableLambda(lambda x: list(range(x)))
runnable2 = RunnableLambda(lambda x: x + 5)chain = runnable1 | runnable2.map()chain.invoke(3)
# [5, 6, 7]
获取可运行的图形表示
Runnable.get_graph
from langchain_core.runnables import RunnableLambda, RunnableParallelrunnable1 = RunnableLambda(lambda x: {"foo": x})
runnable2 = RunnableLambda(lambda x: [x] * 2)
runnable3 = RunnableLambda(lambda x: str(x))chain = runnable1 | RunnableParallel(second=runnable2, third=runnable3)chain.get_graph().print_ascii()
+-------------+ | LambdaInput | +-------------+ * * * +------------------------------+ | Lambda(lambda x: {'foo': x}) | +------------------------------+ * * * +-----------------------------+ | Parallel<second,third>Input | +-----------------------------+ **** *** **** **** ** **
+---------------------------+ +--------------------------+
| Lambda(lambda x: [x] * 2) | | Lambda(lambda x: str(x)) |
+---------------------------+ +--------------------------+ **** *** **** **** ** ** +------------------------------+ | Parallel<second,third>Output | +------------------------------+
获取链中的所有提示
Runnable.get_prompts
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambdaprompt1 = ChatPromptTemplate.from_messages([("system", "good ai"), ("human", "{input}")]
)
prompt2 = ChatPromptTemplate.from_messages([("system", "really good ai"),("human", "{input}"),("ai", "{ai_output}"),("human", "{input2}"),]
)
fake_llm = RunnableLambda(lambda prompt: "i am good ai")
chain = prompt1.assign(ai_output=fake_llm) | prompt2 | fake_llmfor i, prompt in enumerate(chain.get_prompts()):print(f"**prompt {i=}**\n")print(prompt.pretty_repr())print("\n" * 3)
添加生命周期监听器
Runnable.with_listeners
import timefrom langchain_core.runnables import RunnableLambda
from langchain_core.tracers.schemas import Rundef on_start(run_obj: Run):print("start_time:", run_obj.start_time)def on_end(run_obj: Run):print("end_time:", run_obj.end_time)runnable1 = RunnableLambda(lambda x: time.sleep(x))
chain = runnable1.with_listeners(on_start=on_start, on_end=on_end)
chain.invoke(2)# start_time: 2024-05-17 23:04:00.951065+00:00
# end_time: 2024-05-17 23:04:02.958765+00:00
链式运行Runnable
关于LangChain表达式的一点是,任何两个可运行对象可以“链式”组合成序列。前一个可运行对象的 .invoke() 调用的输出作为输入传递给下一个可运行对象。这可以使用管道操作符 (|) 或更明确的 .pipe() 方法来完成,二者效果相同。
生成的 RunnableSequence 本身就是一个可运行对象,这意味着它可以像其他任何可运行对象一样被调用、流式处理或进一步链式组合。以这种方式链式运行可运行对象的优点是高效的流式处理(序列会在输出可用时立即流式输出),以及使用像LangSmith这样的工具进行调试和追踪。
import getpass
import os
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplateos.environ["AZURE_OPENAI_API_KEY"] = getpass.getpass()from langchain_openai import AzureChatOpenAImodel = AzureChatOpenAI(azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"],azure_deployment=os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"],openai_api_version=os.environ["AZURE_OPENAI_API_VERSION"],
)prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")chain = prompt | model | StrOutputParser()
提示和模型都是可运行的,提示调用的输出类型与聊天模型的输入类型相同,因此我们可以将它们链在一起。然后我们可以像调用其他可运行的那样调用结果序列:
chain.invoke({"topic": "bears"})
我们甚至可以将这个链与更多的可运行项结合起来,创建另一个链。这可能涉及使用其他类型的可运行项进行一些输入/输出格式化,具体取决于链组件所需的输入和输出。
例如,假设我们想将生成笑话的链与另一个链组合,该链评估生成的笑话是否有趣。
我们需要小心如何将输入格式化为下一个链。在下面的示例中,链中的字典会自动解析并转换为RunnableParallel,它并行运行所有值并返回一个包含结果的字典。
这恰好是下一个提示模板所期望的相同格式。以下是它的实际应用:
from langchain_core.output_parsers import StrOutputParseranalysis_prompt = ChatPromptTemplate.from_template("is this a funny joke? {joke}")composed_chain = {"joke": chain} | analysis_prompt | model | StrOutputParser()composed_chain.invoke({"topic": "bears"})
为什么要用 {“joke”: chain}?如果直接这样写:
prompt | model | StrOutputParser() | analysis_prompt | model | StrOutputParser()
那么 analysis_prompt 不会知道 它需要的 {joke} 应该来自前一个链的输出。
函数也会被强制转换为可运行项,因此您也可以向链中添加自定义逻辑。下面的链产生与之前相同的逻辑流程:
composed_chain_with_lambda = (chain| (lambda input: {"joke": input})| analysis_prompt| model| StrOutputParser()
)composed_chain_with_lambda.invoke({"topic": "beets"})
但以这种方式使用函数可能会干扰流式处理等操作。
我们也可以使用.pipe()方法组合相同的序列。以下是它的样子:
from langchain_core.runnables import RunnableParallelcomposed_chain_with_pipe = (RunnableParallel({"joke": chain}).pipe(analysis_prompt).pipe(model).pipe(StrOutputParser())
)composed_chain_with_pipe.invoke({"topic": "battlestar galactica"})
或者简写为:
composed_chain_with_pipe = RunnableParallel({"joke": chain}).pipe(analysis_prompt, model, StrOutputParser()
)
流式运行可执行项
流式处理 对于基于大型语言模型的应用程序在用户端的响应性至关重要。
重要的 LangChain 原语,如 聊天模型、输出解析器、提示词、检索器 和 代理 实现了 LangChain 的运行接口。
该接口提供了两种流式内容的通用方法:
- 同步
stream和异步astream:一种默认实现的流式处理,从链中流式传输最终输出。 - 异步
astream_events和异步astream_log:这些提供了一种从链中流式传输中间步骤和最终输出的方法。
大型语言模型及其聊天变体是基于LLM的应用中的主要瓶颈。
大型语言模型生成完整响应可能需要几秒钟。这远远慢于应用程序对最终用户感觉响应的~200-300毫秒阈值。
使应用程序感觉更具响应性的关键策略是显示中间进度;即,从模型逐个令牌流式输出。
比如我们使用oepnai作为基座模型:
import getpass
import osos.environ["OPENAI_API_KEY"] = getpass.getpass()from langchain_openai import ChatOpenAImodel = ChatOpenAI(model="gpt-4o-mini")
让我们从 同步 stream API 开始:
chunks = []
for chunk in model.stream("what color is the sky?"):chunks.append(chunk)print(chunk.content, end="|", flush=True)
输出示例:
The| sky| appears| blue| during| the| day|.
另外,如果您在 异步环境 中工作,可以考虑使用 异步 astream API:
chunks = []
async for chunk in model.astream("what color is the sky?"):chunks.append(chunk)print(chunk.content, end="|", flush=True)
输出相同:
The| sky| appears| blue| during| the| day|.
让我们检查一下其中的一个块:
chunks[0]
输出:
AIMessageChunk(content='The', id='run-b36bea64-5511-4d7a-b6a3-a07b3db0c8e7')
我们得到了一个叫做 AIMessageChunk 的对象。这个块代表了一个 AIMessage 的一部分。
消息块的设计是可叠加的 —— 可以简单地将它们相加,以获取到目前为止的响应状态:
chunks[0] + chunks[1] + chunks[2] + chunks[3] + chunks[4]
输出:
AIMessageChunk(content='The sky appears blue during', id='run-b36bea64-5511-4d7a-b6a3-a07b3db0c8e7')
几乎所有的 LLM 应用都涉及比仅仅调用语言模型更多的步骤。
让我们使用 LangChain 表达式(LCEL) 构建一个简单的链,结合一个提示、模型和解析器,并验证 流式处理 是否有效。
我们将使用 StrOutputParser 来解析模型的输出。这是一个简单的解析器,从 AIMessageChunk 中提取 content 字段,给我们模型返回的 token。
<!--IMPORTS:[{"imported": "StrOutputParser", "source": "langchain_core.output_parsers", "docs": "https://python.langchain.com/api_reference/core/output_parsers/langchain_core.output_parsers.string.StrOutputParser.html", "title": "How to stream runnables"}, {"imported": "ChatPromptTemplate", "source": "langchain_core.prompts", "docs": "https://python.langchain.com/api_reference/core/prompts/langchain_core.prompts.chat.ChatPromptTemplate.html", "title": "How to stream runnables"}]-->
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
parser = StrOutputParser()
chain = prompt | model | parserasync for chunk in chain.astream({"topic": "parrot"}):print(chunk, end="|", flush=True)
Here|'s| a| joke| about| a| par|rot|:|A man| goes| to| a| pet| shop| to| buy| a| par|rot|.| The| shop| owner| shows| him| two| stunning| pa|rr|ots| with| beautiful| pl|um|age|.|"|There|'s| a| talking| par|rot| an|d a| non|-|talking| par|rot|,"| the| owner| says|.| "|The| talking| par|rot| costs| $|100|,| an|d the| non|-|talking| par|rot| is| $|20|."|The| man| says|,| "|I|'ll| take| the| non|-|talking| par|rot| at| $|20|."|He| pays| an|d leaves| with| the| par|rot|.| As| he|'s| walking| down| the| street|,| the| par|rot| looks| up| at| him| an|d says|,| "|You| know|,| you| really| are| a| stupi|d man|!"|The| man| is| stun|ne|d an|d looks| at| the| par|rot| in| dis|bel|ief|.| The| par|rot| continues|,| "|Yes|,| you| got| r|ippe|d off| big| time|!| I| can| talk| just| as| well| as| that| other| par|rot|,| an|d you| only| pai|d $|20| |for| me|!"|
请注意,即使我们在上面的链的末尾使用了 parser,我们仍然得到了流式输出。parser 针对每个流式块单独操作。许多 LCEL 原语 也支持这种变换风格的直通流式处理,这在构建应用时非常方便。
自定义函数可以设计为 返回生成器,能够在流上操作。
某些可运行对象,如 提示词模板 和 聊天模型,无法处理单个块,而是聚合所有先前的步骤。
这些可运行对象可能会 中断流式处理过程。
Note
LangChain 表达式语言允许您将链的构建与其使用模式(例如,同步 / 异步、批处理 / 流式等)分开。
如果这与您正在构建的内容无关,您也可以依赖标准的命令式编程方法:
在每个组件上单独调用invoke、batch或stream,将结果分配给变量,然后根据需要在下游使用它们。
如果您想在生成时 流式传输 JSON,该怎么办?
如果您依赖 json.loads 来解析部分 JSON,解析将失败,因为 部分 JSON 不是有效的 JSON。
您可能会完全不知道该怎么办,并声称 无法流式传输 JSON。
好吧,事实证明有一种方法可以做到 —— 解析器需要在 输入流上操作,并尝试“自动完成”部分 JSON,使其成为有效状态。
from langchain_core.output_parsers import JsonOutputParserchain = (model | JsonOutputParser()
)# 注意:旧版本 LangChain 存在 bug,JsonOutputParser 可能无法从某些模型流式获取结果
async for text in chain.astream("output a list of the countries france, spain and japan and their populations in JSON format. "'Use a dict with an outer key of "countries" which contains a list of countries. '"Each country should have the key `name` and `population`"
):print(text, flush=True)
示例输出:
{}
{'countries': []}
{'countries': [{}]}
{'countries': [{'name': ''}]}
{'countries': [{'name': 'France'}]}
{'countries': [{'name': 'France', 'population': 67}]}
{'countries': [{'name': 'France', 'population': 67413}]}
{'countries': [{'name': 'France', 'population': 67413000}]}
{'countries': [{'name': 'France', 'population': 67413000}, {}]}
{'countries': [{'name': 'France', 'population': 67413000}, {'name': ''}]}
{'countries': [{'name': 'France', 'population': 67413000}, {'name': 'Spain'}]}
{'countries': [{'name': 'France', 'population': 67413000}, {'name': 'Spain', 'population': 47}]}
{'countries': [{'name': 'France', 'population': 67413000}, {'name': 'Spain', 'population': 47351}]}
{'countries': [{'name': 'France', 'population': 67413000}, {'name': 'Spain', 'population': 47351567}]}
{'countries': [{'name': 'France', 'population': 67413000}, {'name': 'Spain', 'population': 47351567}, {}]}
{'countries': [{'name': 'France', 'population': 67413000}, {'name': 'Spain', 'population': 47351567}, {'name': ''}]}
{'countries': [{'name': 'France', 'population': 67413000}, {'name': 'Spain', 'population': 47351567}, {'name': 'Japan'}]}
{'countries': [{'name': 'France', 'population': 67413000}, {'name': 'Spain', 'population': 47351567}, {'name': 'Japan', 'population': 125}]}
{'countries': [{'name': 'France', 'population': 67413000}, {'name': 'Spain', 'population': 47351567}, {'name': 'Japan', 'population': 125584}]}
{'countries': [{'name': 'France', 'population': 67413000}, {'name': 'Spain', 'population': 47351567}, {'name': 'Japan', 'population': 125584000}]}
现在,让我们 中断流式处理。我们将使用之前的示例,并在最后添加一个提取函数,从最终的 JSON 中提取国家名称。
⚠️ warning
链中的任何步骤如果操作的是最终输入而不是输入流,都可能通过stream或astream中断流式功能。
from langchain_core.output_parsers import JsonOutputParserdef _extract_country_names(inputs):"""一个不支持输入流的函数,会打断流式处理。"""if not isinstance(inputs, dict):return ""if "countries" not in inputs:return ""countries = inputs["countries"]if not isinstance(countries, list):return ""country_names = [country.get("name") for country in countries if isinstance(country, dict)]return country_nameschain = model | JsonOutputParser() | _extract_country_namesasync for text in chain.astream("output a list of the countries france, spain and japan and their populations in JSON format. "'Use a dict with an outer key of "countries" which contains a list of countries. '"Each country should have the key `name` and `population`"
):print(text, end="|", flush=True)# 输出结果
# ['France', 'Spain', 'Japan']|
使用生成器函数实现流式处理
💡 tip
生成器函数(使用yield的函数)允许编写操作输入流的代码。
from langchain_core.output_parsers import JsonOutputParserasync def _extract_country_names_streaming(input_stream):"""支持输入流的函数。"""country_names_so_far = set()async for input in input_stream:if not isinstance(input, dict):continueif "countries" not in input:continuecountries = input["countries"]if not isinstance(countries, list):continuefor country in countries:name = country.get("name")if not name:continueif name not in country_names_so_far:yield namecountry_names_so_far.add(name)chain = model | JsonOutputParser() | _extract_country_names_streamingasync for text in chain.astream("output a list of the countries france, spain and japan and their populations in JSON format. "'Use a dict with an outer key of "countries" which contains a list of countries. '"Each country should have the key `name` and `population`",
):print(text, end="|", flush=True)# 输出
# France|Spain|Japan|
📝 note
由于上面的代码依赖于 JSON 自动补全,您可能会看到部分国家名称(例如Sp和Spain),这并不是提取结果所希望的!我们关注的是流式处理的概念,而不一定是链的结果。
某些内置组件(如检索器)不支持流式输出。如果尝试对它们执行 stream 会怎样?
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddingstemplate = """Answer the question based only on the following context:
{context}Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)vectorstore = FAISS.from_texts(["harrison worked at kensho", "harrison likes spicy food"],embedding=OpenAIEmbeddings(),
)
retriever = vectorstore.as_retriever()chunks = [chunk for chunk in retriever.stream("where did harrison work?")]
print(chunks)# 输出
# [[Document(page_content='harrison worked at kensho'),
# Document(page_content='harrison likes spicy food')]]
✅ 这很好! 并不是所有组件都必须实现流式处理。
在某些情况下,流式处理要么不必要,要么困难,或者根本没有意义。
💡 tip
使用非流式组件构建的 LCEL 链,在很多情况下仍然能够进行流式处理。流式部分输出将在链中最后一个非流式步骤之后开始。
混合链中的流式处理
retrieval_chain = ({"context": retriever.with_config(run_name="Docs"),"question": RunnablePassthrough(),}| prompt| model| StrOutputParser()
)for chunk in retrieval_chain.stream("Where did harrison work? Write 3 made up sentences about this place."
):print(chunk, end="|", flush=True)
输出示例:
Base|d on| the| given| context|,| Harrison| worke|d at| K|ens|ho|.|
Here| are| 3| made| up| sentences| about| this| place|:|
1.| Kensho| was| a| cutting-edge| technology| company| known| for| AI| and| data| analytics|.|
...
使用流事件
事件流式处理是一个测试版 API。该 API 可能会根据反馈有所变化。
Note
本指南演示了 V2 API,并要求langchain-core >= 0.2。有关与旧版本 LangChain 兼容的 V1 API,请参见这里.
import langchain_corelangchain_core.__version__
为了使 astream_events API 正常工作:
- 尽可能在代码中使用
async(例如,异步工具等) - 如果定义自定义函数/可运行程序,请传播回调
- 在不使用 LCEL 的情况下使用可运行对象时,请确保在大型语言模型(LLMs)上调用
.astream()而不是.ainvoke(),以强制 LLM 流式传输令牌。
下面是一个参考表,显示了各种可运行对象可能发出的某些事件。
Note
当流式处理正确实现时,输入到可运行对象的内容在输入流完全消耗之前是未知的。这意味着inputs通常仅在end事件中包含,而不是在start事件中。
| 事件类型 | 名称 | 块 | 输入 | 输出 |
|---|---|---|---|---|
on_chat_model_start | [模型名称] | {"messages": [[SystemMessage, HumanMessage]]} | ||
on_chat_model_stream | [模型名称] | ✅ | AIMessageChunk(content="hello") | |
on_chat_model_end | [模型名称] | {"messages": [[SystemMessage, HumanMessage]]} | AIMessageChunk(content="hello world") | |
on_llm_start | [模型名称] | {'输入': '你好'} | ||
on_llm_stream | [模型名称] | ✅ | '你好' | |
on_llm_end | [模型名称] | '你好,人类!' | ||
on_chain_start | 格式化文档 | |||
on_chain_stream | 格式化文档 | ✅ | "你好,世界!再见,世界!" | |
on_chain_end | 格式化文档 | [文档(...)] | "你好,世界!再见,世界!" | |
on_tool_start | 一些工具 | {"x": 1, "y": "2"} | ||
on_tool_end | 一些工具 | {"x": 1, "y": "2"} | ||
on_retriever_start | [检索器名称] | {"查询": "你好"} | ||
on_retriever_end | [检索器名称] | {"查询": "你好"} | [文档(...), ..] | |
on_prompt_start | [模板名称] | {"question": "hello"} | ||
on_prompt_end | [模板名称] | {"question": "hello"} | ChatPromptValue(messages: [SystemMessage, ...]) |
聊天模型
我们先来看看聊天模型产生的事件:
events = []
async for event in model.astream_events("hello", version="v2"):events.append(event)
前几个事件
events[:3]
[{"event": "on_chat_model_start","data": {"input": "hello"},"name": "ChatAnthropic","tags": [],"run_id": "a81e4c0f-...","metadata": {}},{"event": "on_chat_model_stream","data": {"chunk": AIMessageChunk(content="Hello", id="...")},"run_id": "...","name": "ChatAnthropic","tags": [],"metadata": {}},{"event": "on_chat_model_stream","data": {"chunk": AIMessageChunk(content="!", id="...")},"run_id": "...","name": "ChatAnthropic","tags": [],"metadata": {}}
]
最后两个事件
events[-2:]
[{"event": "on_chat_model_stream","data": {"chunk": AIMessageChunk(content="?", id="...")},"run_id": "...","name": "ChatAnthropic","tags": [],"metadata": {}},{"event": "on_chat_model_end","data": {"output": AIMessageChunk(content="Hello! How can I assist you today?",id="...")},"run_id": "...","name": "ChatAnthropic","tags": [],"metadata": {}}
]
链
让我们重新审视一下解析流式 JSON 的示例链,以探索流式事件 API。
chain = model | JsonOutputParser()
events = [eventasync for event in chain.astream_events("output a list of the countries france, spain and japan and their populations in JSON format. "'Use a dict with an outer key of "countries" which contains a list of countries. '"Each country should have the key `name` and `population`",version="v2",)
]
如果你查看前几个事件,你会注意到有 3 个不同的开始事件,而不是 2 个开始事件。这三个开始事件对应于:
- 链(模型 + 解析器)
- 模型
- 解析器
events[:3]
[{"event": "on_chain_start","data": {"input": "..."},"name": "RunnableSequence","tags": [],"run_id": "...","metadata": {}},{"event": "on_chat_model_start","data": {"input": {"messages": [[HumanMessage(content="...")]]}},"name": "ChatAnthropic","tags": ["seq:step:1"],"run_id": "...","metadata": {}},{"event": "on_chat_model_stream","data": {"chunk": AIMessageChunk(content="{", id="...")},"run_id": "...","name": "ChatAnthropic","tags": ["seq:step:1"],"metadata": {}}
]
如果你查看最后 3 个事件,你认为会看到什么?中间的呢?
让我们使用这个 API 从模型和解析器中输出流事件。我们忽略开始事件、结束事件和来自链的事件。
num_events = 0async for event in chain.astream_events(...):kind = event["event"]if kind == "on_chat_model_stream":print(f"Chat model chunk: {repr(event['data']['chunk'].content)}")if kind == "on_parser_stream":print(f"Parser chunk: {event['data']['chunk']}")num_events += 1if num_events > 30:print("...")break
输出:
Chat model chunk: '{'
Parser chunk: {}
Chat model chunk: '\n '
Chat model chunk: '"'
Chat model chunk: 'countries'
Chat model chunk: '":'
Chat model chunk: ' ['
Parser chunk: {'countries': []}
...
因为模型和解析器都支持流式处理,我们实时看到来自两个组件的流式事件!这不是很酷吗?🦜
事件过滤
由于此API产生了许多事件,因此能够对事件进行过滤是很有用的。
您可以通过组件的 name、组件的 tags 或组件的 type 进行过滤。
按名称过滤
chain = model.with_config({"run_name": "model"}) | JsonOutputParser().with_config({"run_name": "my_parser"}
)max_events = 0
async for event in chain.astream_events("output a list of the countries france, spain and japan and their populations in JSON format. "'Use a dict with an outer key of "countries" which contains a list of countries. '"Each country should have the key `name` and `population`",version="v2",include_names=["my_parser"],
):print(event)max_events += 1if max_events > 10:# Truncate outputprint("...")break
输出:
{'event': 'on_parser_start', 'data': {'input': 'output a list of the countries france, spain and japan and their populations in JSON format. Use a dict with an outer key of "countries" which contains a list of countries. Each country should have the key `name` and `population`'}, 'name': 'my_parser', 'tags': ['seq:step:2'], 'run_id': 'e058d750-f2c2-40f6-aa61-10f84cd671a9', 'metadata': {}}
{'event': 'on_parser_stream', 'data': {'chunk': {}}, 'run_id': 'e058d750-f2c2-40f6-aa61-10f84cd671a9', 'name': 'my_parser', 'tags': ['seq:step:2'], 'metadata': {}}
{'event': 'on_parser_stream', 'data': {'chunk': {'countries': []}}, 'run_id': 'e058d750-f2c2-40f6-aa61-10f84cd671a9', 'name': 'my_parser', 'tags': ['seq:step:2'], 'metadata': {}}
{'event': 'on_parser_stream', 'data': {'chunk': {'countries': [{}]}}, 'run_id': 'e058d750-f2c2-40f6-aa61-10f84cd671a9', 'name': 'my_parser', 'tags': ['seq:step:2'], 'metadata': {}}
{'event': 'on_parser_stream', 'data': {'chunk': {'countries': [{'name': ''}]}}, 'run_id': 'e058d750-f2c2-40f6-aa61-10f84cd671a9', 'name': 'my_parser', 'tags': ['seq:step:2'], 'metadata': {}}
{'event': 'on_parser_stream', 'data': {'chunk': {'countries': [{'name': 'France'}]}}, 'run_id': 'e058d750-f2c2-40f6-aa61-10f84cd671a9', 'name': 'my_parser', 'tags': ['seq:step:2'], 'metadata': {}}
{'event': 'on_parser_stream', 'data': {'chunk': {'countries': [{'name': 'France', 'population': 67}]}}, 'run_id': 'e058d750-f2c2-40f6-aa61-10f84cd671a9', 'name': 'my_parser', 'tags': ['seq:step:2'], 'metadata': {}}
{'event': 'on_parser_stream', 'data': {'chunk': {'countries': [{'name': 'France', 'population': 67413}]}}, 'run_id': 'e058d750-f2c2-40f6-aa61-10f84cd671a9', 'name': 'my_parser', 'tags': ['seq:step:2'], 'metadata': {}}
{'event': 'on_parser_stream', 'data': {'chunk': {'countries': [{'name': 'France', 'population': 67413000}]}}, 'run_id': 'e058d750-f2c2-40f6-aa61-10f84cd671a9', 'name': 'my_parser', 'tags': ['seq:step:2'], 'metadata': {}}
{'event': 'on_parser_stream', 'data': {'chunk': {'countries': [{'name': 'France', 'population': 67413000}, {}]}}, 'run_id': 'e058d750-f2c2-40f6-aa61-10f84cd671a9', 'name': 'my_parser', 'tags': ['seq:step:2'], 'metadata': {}}
{'event': 'on_parser_stream', 'data': {'chunk': {'countries': [{'name': 'France', 'population': 67413000}, {'name': ''}]}}, 'run_id': 'e058d750-f2c2-40f6-aa61-10f84cd671a9', 'name': 'my_parser', 'tags': ['seq:step:2'], 'metadata': {}}
...
按类型过滤
chain = model.with_config({"run_name": "model"}) | JsonOutputParser().with_config({"run_name": "my_parser"}
)max_events = 0
async for event in chain.astream_events('output a list of the countries france, spain and japan and their populations in JSON format. Use a dict with an outer key of "countries" which contains a list of countries. Each country should have the key `name` and `population`',version="v2",include_types=["chat_model"],
):print(event)max_events += 1if max_events > 10:# Truncate outputprint("...")break
输出:
{'event': 'on_chat_model_start', 'data': {'input': 'output a list of the countries france, spain and japan and their populations in JSON format. Use a dict with an outer key of "countries" which contains a list of countries. Each country should have the key `name` and `population`'}, 'name': 'model', 'tags': ['seq:step:1'], 'run_id': 'db246792-2a91-4eb3-a14b-29658947065d', 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='{', id='run-db246792-2a91-4eb3-a14b-29658947065d')}, 'run_id': 'db246792-2a91-4eb3-a14b-29658947065d', 'name': 'model', 'tags': ['seq:step:1'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='\n ', id='run-db246792-2a91-4eb3-a14b-29658947065d')}, 'run_id': 'db246792-2a91-4eb3-a14b-29658947065d', 'name': 'model', 'tags': ['seq:step:1'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='"', id='run-db246792-2a91-4eb3-a14b-29658947065d')}, 'run_id': 'db246792-2a91-4eb3-a14b-29658947065d', 'name': 'model', 'tags': ['seq:step:1'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='countries', id='run-db246792-2a91-4eb3-a14b-29658947065d')}, 'run_id': 'db246792-2a91-4eb3-a14b-29658947065d', 'name': 'model', 'tags': ['seq:step:1'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='":', id='run-db246792-2a91-4eb3-a14b-29658947065d')}, 'run_id': 'db246792-2a91-4eb3-a14b-29658947065d', 'name': 'model', 'tags': ['seq:step:1'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' [', id='run-db246792-2a91-4eb3-a14b-29658947065d')}, 'run_id': 'db246792-2a91-4eb3-a14b-29658947065d', 'name': 'model', 'tags': ['seq:step:1'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='\n ', id='run-db246792-2a91-4eb3-a14b-29658947065d')}, 'run_id': 'db246792-2a91-4eb3-a14b-29658947065d', 'name': 'model', 'tags': ['seq:step:1'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='{', id='run-db246792-2a91-4eb3-a14b-29658947065d')}, 'run_id': 'db246792-2a91-4eb3-a14b-29658947065d', 'name': 'model', 'tags': ['seq:step:1'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='\n ', id='run-db246792-2a91-4eb3-a14b-29658947065d')}, 'run_id': 'db246792-2a91-4eb3-a14b-29658947065d', 'name': 'model', 'tags': ['seq:step:1'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='"', id='run-db246792-2a91-4eb3-a14b-29658947065d')}, 'run_id': 'db246792-2a91-4eb3-a14b-29658947065d', 'name': 'model', 'tags': ['seq:step:1'], 'metadata': {}}
...
按标签
chain = (model | JsonOutputParser()).with_config({"tags": ["my_chain"]})max_events = 0
async for event in chain.astream_events('output a list of the countries france, spain and japan and their populations in JSON format. Use a dict with an outer key of "countries" which contains a list of countries. Each country should have the key `name` and `population`',version="v2",include_tags=["my_chain"],
):print(event)max_events += 1if max_events > 10:# Truncate outputprint("...")break
{'event': 'on_chain_start', 'data': {'input': 'output a list of the countries france, spain and japan and their populations in JSON format. Use a dict with an outer key of "countries" which contains a list of countries. Each country should have the key `name` and `population`'}, 'name': 'RunnableSequence', 'tags': ['my_chain'], 'run_id': 'fd68dd64-7a4d-4bdb-a0c2-ee592db0d024', 'metadata': {}}
{'event': 'on_chat_model_start', 'data': {'input': {'messages': [[HumanMessage(content='output a list of the countries france, spain and japan and their populations in JSON format. Use a dict with an outer key of "countries" which contains a list of countries. Each country should have the key `name` and `population`')]]}}, 'name': 'ChatAnthropic', 'tags': ['seq:step:1', 'my_chain'], 'run_id': 'efd3c8af-4be5-4f6c-9327-e3f9865dd1cd', 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='{', id='run-efd3c8af-4be5-4f6c-9327-e3f9865dd1cd')}, 'run_id': 'efd3c8af-4be5-4f6c-9327-e3f9865dd1cd', 'name': 'ChatAnthropic', 'tags': ['seq:step:1', 'my_chain'], 'metadata': {}}
{'event': 'on_parser_start', 'data': {}, 'name': 'JsonOutputParser', 'tags': ['seq:step:2', 'my_chain'], 'run_id': 'afde30b9-beac-4b36-b4c7-dbbe423ddcdb', 'metadata': {}}
{'event': 'on_parser_stream', 'data': {'chunk': {}}, 'run_id': 'afde30b9-beac-4b36-b4c7-dbbe423ddcdb', 'name': 'JsonOutputParser', 'tags': ['seq:step:2', 'my_chain'], 'metadata': {}}
{'event': 'on_chain_stream', 'data': {'chunk': {}}, 'run_id': 'fd68dd64-7a4d-4bdb-a0c2-ee592db0d024', 'name': 'RunnableSequence', 'tags': ['my_chain'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='\n ', id='run-efd3c8af-4be5-4f6c-9327-e3f9865dd1cd')}, 'run_id': 'efd3c8af-4be5-4f6c-9327-e3f9865dd1cd', 'name': 'ChatAnthropic', 'tags': ['seq:step:1', 'my_chain'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='"', id='run-efd3c8af-4be5-4f6c-9327-e3f9865dd1cd')}, 'run_id': 'efd3c8af-4be5-4f6c-9327-e3f9865dd1cd', 'name': 'ChatAnthropic', 'tags': ['seq:step:1', 'my_chain'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='countries', id='run-efd3c8af-4be5-4f6c-9327-e3f9865dd1cd')}, 'run_id': 'efd3c8af-4be5-4f6c-9327-e3f9865dd1cd', 'name': 'ChatAnthropic', 'tags': ['seq:step:1', 'my_chain'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='":', id='run-efd3c8af-4be5-4f6c-9327-e3f9865dd1cd')}, 'run_id': 'efd3c8af-4be5-4f6c-9327-e3f9865dd1cd', 'name': 'ChatAnthropic', 'tags': ['seq:step:1', 'my_chain'], 'metadata': {}}
{'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' [', id='run-efd3c8af-4be5-4f6c-9327-e3f9865dd1cd')}, 'run_id': 'efd3c8af-4be5-4f6c-9327-e3f9865dd1cd', 'name': 'ChatAnthropic', 'tags': ['seq:step:1', 'my_chain'], 'metadata': {}}
...
非流式组件
还记得有些组件由于不在 输入流 上操作而无法很好地流式处理吗?
虽然这些组件在使用 astream 时可能会中断最终输出的流式处理,但 astream_events 仍会从支持流式处理的中间步骤中产生流式事件!
# Function that does not support streaming.
# It operates on the finalizes inputs rather than
# operating on the input stream.
def _extract_country_names(inputs):"""A function that does not operates on input streams and breaks streaming."""if not isinstance(inputs, dict):return ""if "countries" not in inputs:return ""countries = inputs["countries"]if not isinstance(countries, list):return ""country_names = [country.get("name") for country in countries if isinstance(country, dict)]return country_nameschain = (model | JsonOutputParser() | _extract_country_names
) # This parser only works with OpenAI right now
正如预期的那样,astream API 工作不正常,因为 _extract_country\names 不在流上操作。
async for chunk in chain.astream("output a list of the countries france, spain and japan and their populations in JSON format. "'Use a dict with an outer key of "countries" which contains a list of countries. '"Each country should have the key `name` and `population`",
):print(chunk, flush=True)# 输出:
['France', 'Spain', 'Japan']
现在,让我们确认使用 astream_events 时,我们仍然能看到来自模型和解析器的流式输出。
num_events = 0async for event in chain.astream_events("output a list of the countries france, spain and japan and their populations in JSON format. "'Use a dict with an outer key of "countries" which contains a list of countries. '"Each country should have the key `name` and `population`",version="v2",
):kind = event["event"]if kind == "on_chat_model_stream":print(f"Chat model chunk: {repr(event['data']['chunk'].content)}",flush=True,)if kind == "on_parser_stream":print(f"Parser chunk: {event['data']['chunk']}", flush=True)num_events += 1if num_events > 30:# Truncate the outputprint("...")break
输出示例:
Chat model chunk: '{'
Parser chunk: {}
Chat model chunk: '\n '
Chat model chunk: '"'
Chat model chunk: 'countries'
Chat model chunk: '":'
Chat model chunk: ' ['
Parser chunk: {'countries': []}
Chat model chunk: '\n '
Chat model chunk: '{'
Parser chunk: {'countries': [{}]}
Chat model chunk: '\n '
Chat model chunk: '"'
Chat model chunk: 'name'
Chat model chunk: '":'
Chat model chunk: ' "'
Parser chunk: {'countries': [{'name': ''}]}
Chat model chunk: 'France'
Parser chunk: {'countries': [{'name': 'France'}]}
Chat model chunk: '",'
Chat model chunk: '\n '
Chat model chunk: '"'
Chat model chunk: 'population'
Chat model chunk: '":'
Chat model chunk: ' '
Chat model chunk: '67'
Parser chunk: {'countries': [{'name': 'France', 'population': 67}]}
...
传播回调
如果您在工具中使用可运行的调用,您需要将回调传播到可运行的对象;否则,将不会生成流事件。
note: 使用 RunnableLambdas 或 @chain 装饰器时,回调会在后台自动传播。
from langchain_core.runnables import RunnableLambda
from langchain_core.tools import tooldef reverse_word(word: str):return word[::-1]reverse_word = RunnableLambda(reverse_word)@tool
def bad_tool(word: str):"""Custom tool that doesn't propagate callbacks."""return reverse_word.invoke(word)async for event in bad_tool.astream_events("hello", version="v2"):print(event)
示例输出:
{'event': 'on_tool_start', 'data': {'input': 'hello'}, 'name': 'bad_tool', 'tags': [], 'run_id': 'ea900472-a8f7-425d-b627-facdef936ee8', 'metadata': {}}
{'event': 'on_chain_start', 'data': {'input': 'hello'}, 'name': 'reverse_word', 'tags': [], 'run_id': '77b01284-0515-48f4-8d7c-eb27c1882f86', 'metadata': {}}
{'event': 'on_chain_end', 'data': {'output': 'olleh', 'input': 'hello'}, 'run_id': '77b01284-0515-48f4-8d7c-eb27c1882f86', 'name': 'reverse_word', 'tags': [], 'metadata': {}}
{'event': 'on_tool_end', 'data': {'output': 'olleh'}, 'run_id': 'ea900472-a8f7-425d-b627-facdef936ee8', 'name': 'bad_tool', 'tags': [], 'metadata': {}}
这是一个正确传播回调的重新实现。您会注意到现在我们也从 reverse_word 可运行对象中获得事件。
@tool
def correct_tool(word: str, callbacks):"""A tool that correctly propagates callbacks."""return reverse_word.invoke(word, {"callbacks": callbacks})async for event in correct_tool.astream_events("hello", version="v2"):print(event)
示例输出:
{'event': 'on_tool_start', 'data': {'input': 'hello'}, 'name': 'correct_tool', 'tags': [], 'run_id': 'd5ea83b9-9278-49cc-9f1d-aa302d671040', 'metadata': {}}
{'event': 'on_chain_start', 'data': {'input': 'hello'}, 'name': 'reverse_word', 'tags': [], 'run_id': '44dafbf4-2f87-412b-ae0e-9f71713810df', 'metadata': {}}
{'event': 'on_chain_end', 'data': {'output': 'olleh', 'input': 'hello'}, 'run_id': '44dafbf4-2f87-412b-ae0e-9f71713810df', 'name': 'reverse_word', 'tags': [], 'metadata': {}}
{'event': 'on_tool_end', 'data': {'output': 'olleh'}, 'run_id': 'd5ea83b9-9278-49cc-9f1d-aa302d671040', 'name': 'correct_tool', 'tags': [], 'metadata': {}}
如果您从 Runnable Lambdas 或 @chains 中调用可运行对象,则回调将自动代表您传递。
from langchain_core.runnables import RunnableLambdaasync def reverse_and_double(word: str):return await reverse_word.ainvoke(word) * 2reverse_and_double = RunnableLambda(reverse_and_double)await reverse_and_double.ainvoke("1234")async for event in reverse_and_double.astream_events("1234", version="v2"):print(event)
示例输出:
{'event': 'on_chain_start', 'data': {'input': '1234'}, 'name': 'reverse_and_double', 'tags': [], 'run_id': '03b0e6a1-3e60-42fc-8373-1e7829198d80', 'metadata': {}}
{'event': 'on_chain_start', 'data': {'input': '1234'}, 'name': 'reverse_word', 'tags': [], 'run_id': '5cf26fc8-840b-4642-98ed-623dda28707a', 'metadata': {}}
{'event': 'on_chain_end', 'data': {'output': '4321', 'input': '1234'}, 'run_id': '5cf26fc8-840b-4642-98ed-623dda28707a', 'name': 'reverse_word', 'tags': [], 'metadata': {}}
{'event': 'on_chain_stream', 'data': {'chunk': '43214321'}, 'run_id': '03b0e6a1-3e60-42fc-8373-1e7829198d80', 'name': 'reverse_and_double', 'tags': [], 'metadata': {}}
{'event': 'on_chain_end', 'data': {'output': '43214321'}, 'run_id': '03b0e6a1-3e60-42fc-8373-1e7829198d80', 'name': 'reverse_and_double', 'tags': [], 'metadata': {}}
并且使用 @chain 装饰器:
from langchain_core.runnables import chain@chain
async def reverse_and_double(word: str):return await reverse_word.ainvoke(word) * 2await reverse_and_double.ainvoke("1234")async for event in reverse_and_double.astream_events("1234", version="v2"):print(event)
示例输出:
{'event': 'on_chain_start', 'data': {'input': '1234'}, 'name': 'reverse_and_double', 'tags': [], 'run_id': '1bfcaedc-f4aa-4d8e-beee-9bba6ef17008', 'metadata': {}}
{'event': 'on_chain_start', 'data': {'input': '1234'}, 'name': 'reverse_word', 'tags': [], 'run_id': '64fc99f0-5d7d-442b-b4f5-4537129f67d1', 'metadata': {}}
{'event': 'on_chain_end', 'data': {'output': '4321', 'input': '1234'}, 'run_id': '64fc99f0-5d7d-442b-b4f5-4537129f67d1', 'name': 'reverse_word', 'tags': [], 'metadata': {}}
{'event': 'on_chain_stream', 'data': {'chunk': '43214321'}, 'run_id': '1bfcaedc-f4aa-4d8e-beee-9bba6ef17008', 'name': 'reverse_and_double', 'tags': [], 'metadata': {}}
{'event': 'on_chain_end', 'data': {'output': '43214321'}, 'run_id': '1bfcaedc-f4aa-4d8e-beee-9bba6ef17008', 'name': 'reverse_and_double', 'tags': [], 'metadata': {}}
并行调用运行接口
在LangGraph中,我们知道一种叫"super step"的节点,这类型节点可以并行执行,而他的底层是RunnableParallels。
RunnableParallel 原语本质上是一个字典,其值是运行接口(或可以被强制转换为运行接口的事物,如函数)。它并行运行所有值,并且每个值都使用 RunnableParallel 的整体输入进行调用。最终返回值是一个字典,包含每个值在其适当键下的结果。
使用 RunnableParallels 格式化
RunnableParallels 对于并行化操作非常有用,但也可以用于操纵一个运行接口的输出,以匹配序列中下一个运行接口的输入格式。您可以使用它们来拆分或分叉链,以便多个组件可以并行处理输入。稍后,其他组件可以连接或合并结果,以合成最终响应。这种类型的链创建了一个计算图,如下所示:
Input/ \/ \Branch1 Branch2\ /\ /Combine
下面,提示的输入预计是一个包含键 "context" 和 "question" 的映射。用户输入的只是问题。因此,我们需要使用检索器获取上下文,并将用户输入传递到 "question" 键下。
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddingsvectorstore = FAISS.from_texts(["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
template = """Answer the question based only on the following context:
{context}Question: {question}
"""# The prompt expects input with keys for "context" and "question"
prompt = ChatPromptTemplate.from_template(template)model = ChatOpenAI()retrieval_chain = ({"context": retriever, "question": RunnablePassthrough()}| prompt| model| StrOutputParser()
)retrieval_chain.invoke("where did harrison work?")
返回:
'Harrison worked at Kensho.'
tip 请注意,当将 RunnableParallel 与另一个 Runnable 组合时,我们甚至不需要将字典包装在 RunnableParallel 类中——类型转换会为我们处理。在链的上下文中,这些是等效的:
{"context": retriever, "question": RunnablePassthrough()}RunnableParallel({"context": retriever, "question": RunnablePassthrough()})RunnableParallel(context=retriever, question=RunnablePassthrough())
这里RunnablePassthrough 的作用是直接传递输入,不做任何修改或处理,相当于一个“透明通道”或者“直通器”。
换句话说,当你用 RunnablePassthrough 包裹一个输入时,它会原样返回输入内容,不会对数据进行任何转换、格式化或计算。
具体用途举例
- 在组合多个 Runnable(运行接口)时,用来占位或者保留某个输入字段的原始数据。
- 作为并行执行时某个分支的“无操作”环节,方便后续链条中对输入进行拆分和传递。
- 保证某个字段的数据能完整传递给下一个环节,避免被自动处理或变更。
from langchain_core.runnables import RunnablePassthroughpassthrough = RunnablePassthrough()result = passthrough.invoke("hello world")
print(result) # 输出: "hello world"
它就是一个“原样输出输入”的Runnable,实现无变更传递功能。
-
保持数据结构完整,方便组合和传递
当你有一组并行或串联的 runnable 时,有些字段你想保持原样传递,不做处理,
RunnablePassthrough就起到了“占位符”的作用。例如,你的并行字典里:
{"context": retriever,"question": RunnablePassthrough() }这里
"question"直接传进下一个链路,而不改变。你不想对这个字段做额外处理,但它又必须参与后续流程。 -
简化管道设计
- 避免写冗余代码,比如写一个空的处理函数。
- 让管道结构更清晰,明确哪些字段会被“原样传递”,哪些字段会被转换。
-
与其他 Runnable 组合,保证兼容性
在类型转换或组合操作中,
RunnablePassthrough可以当作一个默认的“可调用对象”存在,保证接口一致。 -
方便链式操作的输入输出格式匹配
很多复杂流水线的输入输出格式必须对应,
RunnablePassthrough能帮助你做“映射”,保证数据流转的正确性。
使用 itemgetter 作为简写
请注意,当与 RunnableParallel 结合使用时,您可以使用 Python 的 itemgetter 作为简写来从映射中提取数据。
在下面的示例中,我们使用 itemgetter 从映射中提取特定键:
<!--IMPORTS:[{"imported": "FAISS", "source": "langchain_community.vectorstores", "docs": "https://python.langchain.com/api_reference/community/vectorstores/langchain_community.vectorstores.faiss.FAISS.html", "title": "How to invoke runnables in parallel"}, {"imported": "StrOutputParser", "source": "langchain_core.output_parsers", "docs": "https://python.langchain.com/api_reference/core/output_parsers/langchain_core.output_parsers.string.StrOutputParser.html", "title": "How to invoke runnables in parallel"}, {"imported": "ChatPromptTemplate", "source": "langchain_core.prompts", "docs": "https://python.langchain.com/api_reference/core/prompts/langchain_core.prompts.chat.ChatPromptTemplate.html", "title": "How to invoke runnables in parallel"}, {"imported": "RunnablePassthrough", "source": "langchain_core.runnables", "docs": "https://python.langchain.com/api_reference/core/runnables/langchain_core.runnables.passthrough.RunnablePassthrough.html", "title": "How to invoke runnables in parallel"}, {"imported": "ChatOpenAI", "source": "langchain_openai", "docs": "https://python.langchain.com/api_reference/openai/chat_models/langchain_openai.chat_models.base.ChatOpenAI.html", "title": "How to invoke runnables in parallel"}, {"imported": "OpenAIEmbeddings", "source": "langchain_openai", "docs": "https://python.langchain.com/api_reference/openai/embeddings/langchain_openai.embeddings.base.OpenAIEmbeddings.html", "title": "How to invoke runnables in parallel"}]-->
from operator import itemgetterfrom langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddingsvectorstore = FAISS.from_texts(["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()template = """Answer the question based only on the following context:
{context}Question: {question}Answer in the following language: {language}
"""
prompt = ChatPromptTemplate.from_template(template)chain = ({"context": itemgetter("question") | retriever,"question": itemgetter("question"),"language": itemgetter("language"),}| prompt| model| StrOutputParser()
)chain.invoke({"question": "where did harrison work", "language": "italian"})
返回:
'Harrison ha lavorato a Kensho.'
并行化步骤
RunnableParallels 使得并行执行多个 Runnables 变得简单,并将这些 Runnables 的输出作为映射返回。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel
from langchain_openai import ChatOpenAImodel = ChatOpenAI()
joke_chain = ChatPromptTemplate.from_template("tell me a joke about {topic}") | model
poem_chain = (ChatPromptTemplate.from_template("write a 2-line poem about {topic}") | model
)map_chain = RunnableParallel(joke=joke_chain, poem=poem_chain)map_chain.invoke({"topic": "bear"})
返回示例:
{'joke': AIMessage(content="Why don't bears like fast food? Because they can't catch it!", ...),'poem': AIMessage(content='In the quiet of the forest, the bear roams free\nMajestic and wild, a sight to see.', ...)
}
并行性
RunnableParallel 也适用于并行运行独立进程,因为映射中的每个 Runnable 都是并行执行的。例如,我们可以看到之前的 joke_chain、poem_chain 和 map_chain 的运行时间大致相同,即使 map_chain 同时执行了其他两个。
%%timeit
joke_chain.invoke({"topic": "bear"})
# 610 ms ± 64 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)%%timeit
poem_chain.invoke({"topic": "bear"})
# 599 ms ± 73.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)%%timeit
map_chain.invoke({"topic": "bear"})
# 643 ms ± 77.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
为 Runnable 添加默认调用参数
有时我们希望在 Runnable 内部的 RunnableSequence 中调用具有常量参数的可运行项,这些参数不是序列中前一个可运行项的输出的一部分,也不是用户输入的一部分。我们可以使用 Runnable.bind() 方法提前设置这些参数。
假设我们有一个简单的提示 + 模型链:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAIprompt = ChatPromptTemplate.from_messages([("system","Write out the following equation using algebraic symbols then solve it. Use the format\n\nEQUATION:...\nSOLUTION:...\n\n",),("human", "{equation_statement}"),]
)model = ChatOpenAI(temperature=0)runnable = ({"equation_statement": RunnablePassthrough()} | prompt | model | StrOutputParser()
)print(runnable.invoke("x raised to the third plus seven equals 12"))
输出:
EQUATION: x^3 + 7 = 12SOLUTION:
Subtract 7 from both sides:
x^3 = 5Take the cube root of both sides:
x = ∛5
并希望使用某些 stop 词调用模型,以便在某些提示技术中缩短输出。虽然我们可以将一些参数传递给构造函数,但其他运行时参数使用 .bind() 方法,如下所示:
runnable = ({"equation_statement": RunnablePassthrough()}| prompt| model.bind(stop="SOLUTION")| StrOutputParser()
)print(runnable.invoke("x raised to the third plus seven equals 12"))
输出:
EQUATION: x^3 + 7 = 12
您可以绑定到 Runnable 的内容将取决于您在调用时可以传递的额外参数。
另一个常见用例是工具调用。虽然您通常应该使用 .bind_tools() 方法来调用工具模型,但如果您想要更低级别的控制,也可以直接绑定特定于大模型供应商的参数:
tools = [{"type": "function","function": {"name": "get_current_weather","description": "Get the current weather in a given location","parameters": {"type": "object","properties": {"location": {"type": "string","description": "The city and state, e.g. San Francisco, CA",},"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},},"required": ["location"],},},}
]model = ChatOpenAI(model="gpt-4o-mini").bind(tools=tools)
model.invoke("What's the weather in SF, NYC and LA?")
输出示例:
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_z0OU2CytqENVrRTI6T8DkI3u', 'function': {'arguments': '{"location": "San Francisco, CA", "unit": "celsius"}', 'name': 'get_current_weather'}, 'type': 'function'}, {'id': 'call_ft96IJBh0cMKkQWrZjNg4bsw', 'function': {'arguments': '{"location": "New York, NY", "unit": "celsius"}', 'name': 'get_current_weather'}, 'type': 'function'}, {'id': 'call_tfbtGgCLmuBuWgZLvpPwvUMH', 'function': {'arguments': '{"location": "Los Angeles, CA", "unit": "celsius"}', 'name': 'get_current_weather'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 84, 'prompt_tokens': 85, 'total_tokens': 169}, 'model_name': 'gpt-4o-mini', 'system_fingerprint': 'fp_77a673219d', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-d57ad5fa-b52a-4822-bc3e-74f838697e18-0', tool_calls=[{'name': 'get_current_weather', 'args': {'location': 'San Francisco, CA', 'unit': 'celsius'}, 'id': 'call_z0OU2CytqENVrRTI6T8DkI3u'}, {'name': 'get_current_weather', 'args': {'location': 'New York, NY', 'unit': 'celsius'}, 'id': 'call_ft96IJBh0cMKkQWrZjNg4bsw'}, {'name': 'get_current_weather', 'args': {'location': 'Los Angeles, CA', 'unit': 'celsius'}, 'id': 'call_tfbtGgCLmuBuWgZLvpPwvUMH'}])
❓什么是“绑定停止序列”(stop sequence)
当你调用 LLM 时,可以告诉它:
“如果你输出了某个词/标记,比如
SOLUTION,就停下来,不要继续生成。”
这称为设置 stop 参数,常用于截断模型输出。例如:
model.bind(stop="SOLUTION")
就相当于对 OpenAI API 发送请求时添加了:
{"stop": "SOLUTION"
}
不加 .bind(stop="SOLUTION")
你会看到:
EQUATION: x^3 + 7 = 12SOLUTION:
Subtract 7 from both sides:
x^3 = 5Take the cube root of both sides:
x = ∛5
加了 .bind(stop="SOLUTION")
你只会看到:
EQUATION: x^3 + 7 = 12
模型在遇到 SOLUTION 时就自动停下来了,不会再继续往下生成。
运行自定义函数
您可以将任意函数用作 可运行项。这对于格式化或当您需要其他 LangChain 组件未提供的功能时非常有用,作为可运行项使用的自定义函数称为 RunnableLambdas。
请注意,这些函数的所有输入需要是一个单一的参数。如果您有一个接受多个参数的函数,您应该编写一个包装器,接受一个单一的字典输入并将其解包为多个参数。
本指南将涵盖:
- ✅ 如何使用
RunnableLambda构造函数和便利的@chain装饰器显式创建可运行项 - ✅ 在链中使用时将自定义函数强制转换为可运行项
- ✅ 如何在您的自定义函数中接受和使用运行元数据
- ✅ 如何通过让自定义函数返回生成器来进行流式处理
使用构造函数
下面,我们使用 RunnableLambda 构造函数显式包装我们的自定义逻辑:
%pip install -qU langchain langchain_openaiimport os
from getpass import getpassif "OPENAI_API_KEY" not in os.environ:os.environ["OPENAI_API_KEY"] = getpass()
<!--IMPORTS:[{"imported": "ChatPromptTemplate", "source": "langchain_core.prompts", "docs": "https://python.langchain.com/api_reference/core/prompts/langchain_core.prompts.chat.ChatPromptTemplate.html", "title": "How to run custom functions"}, {"imported": "RunnableLambda", "source": "langchain_core.runnables", "docs": "https://python.langchain.com/api_reference/core/runnables/langchain_core.runnables.base.RunnableLambda.html", "title": "How to run custom functions"}, {"imported": "ChatOpenAI", "source": "langchain_openai", "docs": "https://python.langchain.com/api_reference/openai/chat_models/langchain_openai.chat_models.base.ChatOpenAI.html", "title": "How to run custom functions"}]-->
from operator import itemgetterfrom langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAIdef length_function(text):return len(text)def _multiple_length_function(text1, text2):return len(text1) * len(text2)def multiple_length_function(_dict):return _multiple_length_function(_dict["text1"], _dict["text2"])model = ChatOpenAI()prompt = ChatPromptTemplate.from_template("what is {a} + {b}")chain1 = prompt | modelchain = ({"a": itemgetter("foo") | RunnableLambda(length_function),"b": {"text1": itemgetter("foo"), "text2": itemgetter("bar")}| RunnableLambda(multiple_length_function),}| prompt| model
)chain.invoke({"foo": "bar", "bar": "gah"})
AIMessage(content='3 + 9 equals 12.', response_metadata={'token_usage': {'completion_tokens': 8, 'prompt_tokens': 14, 'total_tokens': 22}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-73728de3-e483-49e3-ad54-51bd9570e71a-0')
方便的 @chain 装饰器
您还可以通过添加 @chain 装饰器将任意函数转换为链。这在功能上等同于将函数包装在 RunnableLambda 构造函数中,如上所示。以下是一个示例:
<!--IMPORTS:[{"imported": "StrOutputParser", "source": "langchain_core.output_parsers", "docs": "https://python.langchain.com/api_reference/core/output_parsers/langchain_core.output_parsers.string.StrOutputParser.html", "title": "How to run custom functions"}, {"imported": "chain", "source": "langchain_core.runnables", "docs": "https://python.langchain.com/api_reference/core/runnables/langchain_core.runnables.base.chain.html", "title": "How to run custom functions"}]-->
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import chainprompt1 = ChatPromptTemplate.from_template("Tell me a joke about {topic}")
prompt2 = ChatPromptTemplate.from_template("What is the subject of this joke: {joke}")@chain
def custom_chain(text):prompt_val1 = prompt1.invoke({"topic": text})output1 = ChatOpenAI().invoke(prompt_val1)parsed_output1 = StrOutputParser().invoke(output1)chain2 = prompt2 | ChatOpenAI() | StrOutputParser()return chain2.invoke({"joke": parsed_output1})custom_chain.invoke("bears")
'The subject of the joke is the bear and his girlfriend.'
上面使用 @chain 装饰器将 custom_chain 转换为可运行的,我们通过 .invoke() 方法调用它。
链中的自动强制转换
在使用管道操作符 (|) 的链中使用自定义函数时,您可以省略 RunnableLambda 或 @chain 构造函数,并依赖强制转换。以下是一个简单的示例,函数接受模型的输出并返回前五个字母:
prompt = ChatPromptTemplate.from_template("tell me a story about {topic}")model = ChatOpenAI()chain_with_coerced_function = prompt | model | (lambda x: x.content[:5])chain_with_coerced_function.invoke({"topic": "bears"})'Once '
请注意,我们不需要将自定义函数 (lambda x: x.content[:5]) 包装在 RunnableLambda 构造函数中,因为管道操作符左侧的 model 已经是一个可运行的。自定义函数被 强制转换 为可运行的。
传递运行元数据
可运行的 lambda 可以选择性地接受一个 RunnableConfig 参数,您可以使用它将回调、标签和其他配置信息传递给嵌套运行。
<!--IMPORTS:[{"imported": "RunnableConfig", "source": "langchain_core.runnables", "docs": "https://python.langchain.com/api_reference/core/runnables/langchain_core.runnables.config.RunnableConfig.html", "title": "How to run custom functions"}, {"imported": "get_openai_callback", "source": "langchain_community.callbacks", "docs": "https://python.langchain.com/api_reference/community/callbacks/langchain_community.callbacks.manager.get_openai_callback.html", "title": "How to run custom functions"}]-->
import jsonfrom langchain_core.runnables import RunnableConfigdef parse_or_fix(text: str, config: RunnableConfig):fixing_chain = (ChatPromptTemplate.from_template("Fix the following text:\n\n\`\`\`text\n{input}\n\`\`\`\nError: {error}"" Don't narrate, just respond with the fixed data.")| model| StrOutputParser())for _ in range(3):try:return json.loads(text)except Exception as e:text = fixing_chain.invoke({"input": text, "error": e}, config)return "Failed to parse"from langchain_community.callbacks import get_openai_callbackwith get_openai_callback() as cb:output = RunnableLambda(parse_or_fix).invoke("{foo: bar}", {"tags": ["my-tag"], "callbacks": [cb]})print(output)print(cb)
输出示例:
{'foo': 'bar'}
Tokens Used: 62Prompt Tokens: 56Completion Tokens: 6
Successful Requests: 1
Total Cost (USD): $9.6e-05
<!--IMPORTS:[{"imported": "get_openai_callback", "source": "langchain_community.callbacks", "docs": "https://python.langchain.com/api_reference/community/callbacks/langchain_community.callbacks.manager.get_openai_callback.html", "title": "How to run custom functions"}]-->
from langchain_community.callbacks import get_openai_callbackwith get_openai_callback() as cb:output = RunnableLambda(parse_or_fix).invoke("{foo: bar}", {"tags": ["my-tag"], "callbacks": [cb]})print(output)print(cb)
输出示例:
{'foo': 'bar'}
Tokens Used: 62Prompt Tokens: 56Completion Tokens: 6
Successful Requests: 1
Total Cost (USD): $9.6e-05
流式处理
RunnableLambda 最适合不需要支持流式处理的代码。
如果您需要支持流式处理(即能够对输入块进行操作并生成输出块),请使用RunnableGenerator,如下例所示。
您可以在链中使用生成器函数(即使用 yield 关键字的函数,并且表现得像迭代器)。
这些生成器的签名应为:
Iterator[Input] -> Iterator[Output]- 或者对于异步生成器:
AsyncIterator[Input] -> AsyncIterator[Output]
这些对于以下情况很有用:
- 实现自定义输出解析器
- 修改前一步的输出,同时保留流式处理能力
这是一个用于逗号分隔列表的自定义输出解析器的示例。首先,我们创建一个生成这样的列表的链:
from typing import Iterator, Listprompt = ChatPromptTemplate.from_template("Write a comma-separated list of 5 animals similar to: {animal}. Do not include numbers"
)str_chain = prompt | model | StrOutputParser()for chunk in str_chain.stream({"animal": "bear"}):print(chunk, end="", flush=True)
输出示例:
lion, tiger, wolf, gorilla, panda
接下来,我们定义一个自定义函数,该函数将聚合当前流式输出,并在模型生成列表中的下一个逗号时返回它:
# This is a custom parser that splits an iterator of llm tokens
# into a list of strings separated by commas
def split_into_list(input: Iterator[str]) -> Iterator[List[str]]:# hold partial input until we get a commabuffer = ""for chunk in input:# add current chunk to bufferbuffer += chunk# while there are commas in the bufferwhile "," in buffer:# split buffer on commacomma_index = buffer.index(",")# yield everything before the commayield [buffer[:comma_index].strip()]# save the rest for the next iterationbuffer = buffer[comma_index + 1 :]# yield the last chunkyield [buffer.strip()]
list_chain = str_chain | split_into_listfor chunk in list_chain.stream({"animal": "bear"}):print(chunk, flush=True)
输出示例:
['lion']
['tiger']
['wolf']
['gorilla']
['raccoon']
调用它会返回一个完整的值数组:
list_chain.invoke({"animal": "bear"})
返回:
['lion', 'tiger', 'wolf', 'gorilla', 'raccoon']
异步版本
如果您在 async 环境中工作,这里是上述示例的 async 版本:
from typing import AsyncIteratorasync def asplit_into_list(input: AsyncIterator[str],
) -> AsyncIterator[List[str]]: # async defbuffer = ""async for (chunk) in input: # `input` is a `async_generator` object, so use `async for`buffer += chunkwhile "," in buffer:comma_index = buffer.index(",")yield [buffer[:comma_index].strip()]buffer = buffer[comma_index + 1 :]yield [buffer.strip()]
list_chain = str_chain | asplit_into_listasync for chunk in list_chain.astream({"animal": "bear"}):print(chunk, flush=True)
输出示例:
['lion']
['tiger']
['wolf']
['gorilla']
['panda']
await list_chain.ainvoke({"animal": "bear"})
返回:
['lion', 'tiger', 'wolf', 'gorilla', 'panda']
将参数从一个步骤传递到下一个步骤
在组合多个步骤的链时,有时您希望将前一步的数据原样传递,以便作为后续步骤的输入。
RunnablePassthrough 类允许您做到这一点,通常与 RunnableParallel 一起使用,以将数据传递到您构建的链中的后续步骤。
%pip install -qU langchain langchain-openai
import os
from getpass import getpassif "OPENAI_API_KEY" not in os.environ:os.environ["OPENAI_API_KEY"] = getpass()
from langchain_core.runnables import RunnableParallel, RunnablePassthroughrunnable = RunnableParallel(passed=RunnablePassthrough(),modified=lambda x: x["num"] + 1,
)runnable.invoke({"num": 1})
返回:
{'passed': {'num': 1}, 'modified': 2}
解释:
passed键被调用了RunnablePassthrough(),简单地传递了{'num': 1}modified键使用了一个 lambda 表达式,将num加 1,结果为2
检索示例
在下面的示例中,我们看到一个更真实的用例,其中我们在链中使用 RunnablePassthrough 和 RunnableParallel 来正确格式化输入到提示中。
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
vectorstore = FAISS.from_texts(["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()template = """Answer the question based only on the following context:
{context}Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
retrieval_chain = ({"context": retriever, "question": RunnablePassthrough()}| prompt| model| StrOutputParser()
)retrieval_chain.invoke("where did harrison work?")
返回:
'Harrison worked at Kensho.'
说明:
- 提示的输入期望是一个包含键
"context"和"question"的映射。 - 用户只提供了问题
"where did harrison work?" - 使用检索器获取上下文,使用
RunnablePassthrough将用户的问题传递到"question"键下。
✅
RunnablePassthrough允许我们将原始输入原样传递,用于链中需要组合输入参数的场景。
在运行时配置可运行项行为
有时您可能想要尝试多种不同的方式在您的链中进行操作,甚至向最终用户展示这些方式。 这可以包括调整温度等参数,甚至将一个模型替换为另一个模型。 为了使这一体验尽可能简单,我们定义了两种方法。
- 一个 configurable_fields 方法。它允许您配置可运行项的特定字段。
- 这与可运行项上的
.bind方法相关,但允许您在运行时为链中的特定步骤指定参数,而不是事先指定。 - 一个 configurable_alternatives 方法。通过这个方法,您可以列出任何特定可运行项的替代选项,这些选项可以在运行时设置,并将其替换为指定的替代选项。
可配置字段:configurable_fields
让我们通过一个示例来演示如何在运行时配置聊天模型字段,例如温度:
安装依赖:
%pip install --upgrade --quiet langchain langchain-openai
设置 OpenAI Key:
import os
from getpass import getpassif "OPENAI_API_KEY" not in os.environ:os.environ["OPENAI_API_KEY"] = getpass()
定义模型:
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import ConfigurableField
from langchain_openai import ChatOpenAImodel = ChatOpenAI(temperature=0).configurable_fields(temperature=ConfigurableField(id="llm_temperature",name="LLM Temperature",description="The temperature of the LLM",)
)
运行:
model.invoke("pick a random number")
# 输出: '17'
上面,我们将 temperature 定义为一个 ConfigurableField,可以在运行时设置。为此,我们使用 with_config 方法,如下所示:
model.with_config(configurable={"llm_temperature": 0.9}).invoke("pick a random number")
# 输出: '12'
请注意,字典中传递的 llm_temperature 条目与 ConfigurableField 的 id 具有相同的键。
我们也可以这样做,以影响链中仅一个步骤:
prompt = PromptTemplate.from_template("Pick a random number above {x}")
chain = prompt | modelchain.invoke({"x": 0})
AIMessage(content='27', response_metadata={'token_usage': {'completion_tokens': 1, 'prompt_tokens': 14, 'total_tokens': 15}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-ecd4cadd-1b72-4f92-b9a0-15e08091f537-0')
chain.with_config(configurable={"llm_temperature": 0.9}).invoke({"x": 0})
AIMessage(content='35', response_metadata={'token_usage': {'completion_tokens': 1, 'prompt_tokens': 14, 'total_tokens': 15}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-a916602b-3460-46d3-a4a8-7c926ec747c0-0')
使用 HubRunnables
这对于允许切换提示词非常有用
<!--IMPORTS:[{"imported": "HubRunnable", "source": "langchain.runnables.hub", "docs": "https://python.langchain.com/api_reference/langchain/runnables/langchain.runnables.hub.HubRunnable.html", "title": "How to configure runtime chain internals"}]-->
from langchain.runnables.hub import HubRunnableprompt = HubRunnable("rlm/rag-prompt").configurable_fields(owner_repo_commit=ConfigurableField(id="hub_commit",name="Hub Commit",description="The Hub commit to pull from",)
)prompt.invoke({"question": "foo", "context": "bar"})
ChatPromptValue(messages=[HumanMessage(content="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: foo \nContext: bar \nAnswer:")])
prompt.with_config(configurable={"hub_commit": "rlm/rag-prompt-llama"}).invoke({"question": "foo", "context": "bar"}
)
ChatPromptValue(messages=[HumanMessage(content="[INST]<<SYS>> You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.<</SYS>> \nQuestion: foo \nContext: bar \nAnswer: [/INST]")])
可配置的替代方案:configurable_alternatives
configurable_alternatives() 方法允许我们用替代方案替换链中的步骤。
安装 Anthropic 支持:
%pip install --upgrade --quiet langchain-anthropic
设置 API Key:
import os
from getpass import getpassif "ANTHROPIC_API_KEY" not in os.environ:os.environ["ANTHROPIC_API_KEY"] = getpass()
定义替代模型:
<!--IMPORTS:[{"imported": "ChatAnthropic", "source": "langchain_anthropic", "docs": "https://python.langchain.com/api_reference/anthropic/chat_models/langchain_anthropic.chat_models.ChatAnthropic.html", "title": "How to configure runtime chain internals"}, {"imported": "PromptTemplate", "source": "langchain_core.prompts", "docs": "https://python.langchain.com/api_reference/core/prompts/langchain_core.prompts.prompt.PromptTemplate.html", "title": "How to configure runtime chain internals"}, {"imported": "ConfigurableField", "source": "langchain_core.runnables", "docs": "https://python.langchain.com/api_reference/core/runnables/langchain_core.runnables.utils.ConfigurableField.html", "title": "How to configure runtime chain internals"}, {"imported": "ChatOpenAI", "source": "langchain_openai", "docs": "https://python.langchain.com/api_reference/openai/chat_models/langchain_openai.chat_models.base.ChatOpenAI.html", "title": "How to configure runtime chain internals"}]-->
from langchain_anthropic import ChatAnthropic
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import ConfigurableField
from langchain_openai import ChatOpenAIllm = ChatAnthropic(model="claude-3-haiku-20240307", temperature=0
).configurable_alternatives(# This gives this field an id# When configuring the end runnable, we can then use this id to configure this fieldConfigurableField(id="llm"),# This sets a default_key.# If we specify this key, the default LLM (ChatAnthropic initialized above) will be useddefault_key="anthropic",# This adds a new option, with name `openai` that is equal to `ChatOpenAI()`openai=ChatOpenAI(),# This adds a new option, with name `gpt4` that is equal to `ChatOpenAI(model="gpt-4")`gpt4=ChatOpenAI(model="gpt-4"),# You can add more configuration options here
)
prompt = PromptTemplate.from_template("Tell me a joke about {topic}")
chain = prompt | llm# By default it will call Anthropic
chain.invoke({"topic": "bears"})
AIMessage(content="Here's a bear joke for you:\n\nWhy don't bears wear socks? \nBecause they have bear feet!\n\nHow's that? I tried to come up with a simple, silly pun-based joke about bears. Puns and wordplay are a common way to create humorous bear jokes. Let me know if you'd like to hear another one!", response_metadata={'id': 'msg_018edUHh5fUbWdiimhrC3dZD', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 13, 'output_tokens': 80}}, id='run-775bc58c-28d7-4e6b-a268-48fa6661f02f-0')
使用 OpenAI 输出:
# We can use `.with_config(configurable={"llm": "openai"})` to specify an llm to use
chain.with_config(configurable={"llm": "openai"}).invoke({"topic": "bears"})
AIMessage(content="Why don't bears like fast food?\n\nBecause they can't catch it!", response_metadata={'token_usage': {'completion_tokens': 15, 'prompt_tokens': 13, 'total_tokens': 28}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_c2295e73ad', 'finish_reason': 'stop', 'logprobs': None}, id='run-7bdaa992-19c9-4f0d-9a0c-1f326bc992d4-0')
回到默认模型输出:
# If we use the `default_key` then it uses the default
chain.with_config(configurable={"llm": "anthropic"}).invoke({"topic": "bears"})
AIMessage(content="Here's a bear joke for you:\n\nWhy don't bears wear socks? \nBecause they have bear feet!\n\nHow's that? I tried to come up with a simple, silly pun-based joke about bears. Puns and wordplay are a common way to create humorous bear jokes. Let me know if you'd like to hear another one!", response_metadata={'id': 'msg_01BZvbmnEPGBtcxRWETCHkct', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 13, 'output_tokens': 80}}, id='run-59b6ee44-a1cd-41b8-a026-28ee67cdd718-0')
在提示词之间切换
llm = ChatAnthropic(model="claude-3-haiku-20240307", temperature=0)prompt = PromptTemplate.from_template("Tell me a joke about {topic}"
).configurable_alternatives(ConfigurableField(id="prompt"),default_key="joke",poem=PromptTemplate.from_template("Write a short poem about {topic}"),
)chain = prompt | llm
默认生成 joke:
chain.invoke({"topic": "bears"})
切换到生成 poem:
chain.with_config(configurable={"prompt": "poem"}).invoke({"topic": "bears"})
使用提示词和大型语言模型
我们还可以配置多个选项!这是一个同时使用提示词和大型语言模型的示例:
llm = ChatAnthropic(model="claude-3-haiku-20240307", temperature=0
).configurable_alternatives(# 给该字段设置 IDConfigurableField(id="llm"),# 设置默认键值default_key="anthropic",# 添加名为 `openai` 的新选项,等于 `ChatOpenAI()`openai=ChatOpenAI(),# 添加名为 `gpt4` 的新选项,等于 `ChatOpenAI(model="gpt-4")`gpt4=ChatOpenAI(model="gpt-4"),# 可继续添加更多配置选项
)
prompt = PromptTemplate.from_template("Tell me a joke about {topic}"
).configurable_alternatives(# 给该字段设置 IDConfigurableField(id="prompt"),# 设置默认键值default_key="joke",# 添加名为 `poem` 的新选项poem=PromptTemplate.from_template("Write a short poem about {topic}"),# 可继续添加更多配置选项
)
chain = prompt | llm
使用 OpenAI 和诗歌 Prompt
chain.with_config(configurable={"prompt": "poem", "llm": "openai"}).invoke({"topic": "bears"}
)
输出:
AIMessage(content="In the forest deep and wide,\nBears roam with grace and pride...\n(略)",response_metadata={'token_usage': {'completion_tokens': 133, 'prompt_tokens': 13, 'total_tokens': 146},'model_name': 'gpt-3.5-turbo','system_fingerprint': 'fp_c2295e73ad','finish_reason': 'stop','logprobs': None},id='run-5eec0b96-d580-49fd-ac4e-e32a0803b49b-0'
)
仅配置使用 OpenAI
chain.with_config(configurable={"llm": "openai"}).invoke({"topic": "bears"})
输出:
AIMessage(content="Why don't bears wear shoes?\nBecause they have bear feet!",response_metadata={'token_usage': {'completion_tokens': 13, 'prompt_tokens': 13, 'total_tokens': 26},'model_name': 'gpt-3.5-turbo','system_fingerprint': 'fp_c2295e73ad','finish_reason': 'stop','logprobs': None},id='run-c1b14c9c-4988-49b8-9363-15bfd479973a-0'
)
保存配置
我们还可以轻松地将配置好的链保存为它们自己的对象:
openai_joke = chain.with_config(configurable={"llm": "openai"})
openai_joke.invoke({"topic": "bears"})
输出:
AIMessage(content="Why did the bear break up with his girlfriend?\nBecause he couldn't bear the relationship anymore!",response_metadata={'token_usage': {'completion_tokens': 20, 'prompt_tokens': 13, 'total_tokens': 33},'model_name': 'gpt-3.5-turbo','system_fingerprint': 'fp_c2295e73ad','finish_reason': 'stop','logprobs': None},id='run-391ebd55-9137-458b-9a11-97acaff6a892-0'
)
添加消息历史——记忆
在构建聊天机器人时,将对话状态传入和传出链是至关重要的。
RunnableWithMessageHistory 类允许我们为某些类型的链添加消息历史。它包装另一个可运行对象,并管理其聊天消息历史。具体来说,它在将之前的消息传递给可运行对象之前加载对话中的先前消息,并在调用可运行对象后将生成的响应保存为消息。
该类还通过使用 session_id 保存每个对话来支持多个对话——然后在调用可运行对象时期望在配置中传递 session_id,并使用它查找相关的对话历史。

在实践中,这看起来像:
<!--IMPORTS:[{"imported": "RunnableWithMessageHistory", "source": "langchain_core.runnables.history", "docs": "https://python.langchain.com/api_reference/core/runnables/langchain_core.runnables.history.RunnableWithMessageHistory.html", "title": "How to add message history"}]-->
from langchain_core.runnables.history import RunnableWithMessageHistorywith_message_history = RunnableWithMessageHistory(# The underlying runnablerunnable, # A function that takes in a session id and returns a memory objectget_session_history, # Other parameters that may be needed to align the inputs/outputs# of the Runnable with the memory object...
)with_message_history.invoke(# The same input as before{"ability": "math", "input": "What does cosine mean?"},# Configuration specifying the `session_id`,# which controls which conversation to loadconfig={"configurable": {"session_id": "abc123"}},
)
为了正确设置这一点,有两个主要事项需要考虑:
- 如何存储和加载消息?(这在上面的示例中是
get_session_history) - 你正在包装的底层 Runnable 是什么,它的输入/输出是什么?(这在上面的示例中是
runnable,以及你传递给RunnableWithMessageHistory的任何其他参数,以对齐输入/输出)
如何存储和加载消息
这其中一个关键部分是存储和加载消息。在构造 RunnableWithMessageHistory 时,你需要传入一个 get_session_history 函数。该函数应接受一个 session_id 并返回一个 BaseChatMessageHistory 对象。
什么是 session_id?
session_id 是与这些输入消息对应的会话(对话)线程的标识符。这使你能够同时与同一链维护多个对话/线程。
什么是 BaseChatMessageHistory?
BaseChatMessageHistory 是一个可以加载和保存消息对象的类。它将被 RunnableWithMessageHistory 调用以实现这一功能。这些类通常使用 会话 ID 初始化。
让我们创建一个 get_session_history 对象来用于这个示例。为了简单起见,我们将使用一个简单的 SQLiteMessage。
! rm memory.db
<!--IMPORTS:[{"imported": "SQLChatMessageHistory", "source": "langchain_community.chat_message_histories", "docs": "https://python.langchain.com/api_reference/community/chat_message_histories/langchain_community.chat_message_histories.sql.SQLChatMessageHistory.html", "title": "How to add message history"}]-->
from langchain_community.chat_message_histories import SQLChatMessageHistorydef get_session_history(session_id):return SQLChatMessageHistory(session_id, "sqlite:///memory.db")
你想要包装的可运行对象是什么?
RunnableWithMessageHistory 只能包装某些类型的可运行对象。具体来说,它可以用于任何输入为以下之一的可运行对象:
- 一系列 BaseMessages
- 一个字典,键为一系列 BaseMessages
- 一个字典,键为最新的消息(作为字符串或 BaseMessages 的序列),另一个键为历史消息
并返回作为输出之一:
- 可以被视为 AIMessage 内容的字符串
- 一系列 BaseMessage
- 一个字典,键包含一系列 BaseMessage
首先我们构建一个可运行的对象(这里接受一个字典作为输入并返回一个消息作为输出):
pip install -qU langchain-openai
import getpass
import osos.environ["OPENAI_API_KEY"] = getpass.getpass()from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-4o-mini")
# 引入消息和带历史的可运行对象
from langchain_core.messages import HumanMessage
from langchain_core.runnables.history import RunnableWithMessageHistory
消息输入,消息输出
最简单的形式就是给 ChatModel 添加内存。聊天模型接受一系列消息作为输入并输出一条消息。这使得使用 RunnableWithMessageHistory 变得非常简单 - 不需要额外的配置!
runnable_with_history = RunnableWithMessageHistory(model,get_session_history,
)runnable_with_history.invoke([HumanMessage(content="hi - im bob!")],config={"configurable": {"session_id": "1"}},
)# 返回
AIMessage(content="It's nice to meet you, Bob! I'm Claude, an AI assistant created by Anthropic. How can I help you today?", ...)
runnable_with_history.invoke([HumanMessage(content="whats my name?")],config={"configurable": {"session_id": "1"}},
)# 返回
AIMessage(content='I\'m afraid I don\'t actually know your name - you introduced yourself as Bob, ...', ...)
info
请注意,在这种情况下,上下文通过提供的 session_id 的聊天历史得以保留,因此模型知道用户的名字。
我们现在可以尝试使用一个新的会话 ID,看看它是否不记得。
runnable_with_history.invoke([HumanMessage(content="whats my name?")],config={"configurable": {"session_id": "1a"}},
)# 返回
AIMessage(content="I'm afraid I don't actually know your name. As an AI assistant, I don't have personal information about you unless you provide it to me directly.", ...)
info
当我们传递一个不同的 session_id 时,我们开始一个新的聊天历史,因此模型不知道用户的名字是什么。
字典输入,消息输出
除了简单地包装一个原始模型,下一步是包装一个提示 + 大型语言模型。这现在将输入更改为字典(因为提示的输入是一个字典)。这增加了两个复杂性。
首先:一个字典可以有多个键,但我们只想保存一个作为输入。为了做到这一点,我们现在需要指定一个键来保存为输入。
第二:一旦我们加载了消息,我们需要知道如何将它们保存到字典中。这相当于知道在字典中保存它们的哪个键。因此,我们需要指定一个键来保存加载的消息。
将所有内容放在一起,最终看起来像:
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderprompt = ChatPromptTemplate.from_messages([("system","You're an assistant who speaks in {language}. Respond in 20 words or fewer",),MessagesPlaceholder(variable_name="history"),("human", "{input}"),]
)runnable = prompt | modelrunnable_with_history = RunnableWithMessageHistory(runnable,get_session_history,input_messages_key="input",history_messages_key="history",
)runnable_with_history.invoke({"language": "italian", "input": "hi im bob!"},config={"configurable": {"session_id": "2"}},
)# 返回
AIMessage(content='Ciao Bob! È un piacere conoscerti. Come stai oggi?', ...)
请注意,我们已指定 input_messages_key(将被视为最新输入消息的键)和 history_messages_key(用于添加历史消息的键)。
runnable_with_history.invoke({"language": "italian", "input": "whats my name?"},config={"configurable": {"session_id": "2"}},
)# 返回
AIMessage(content='Bob, il tuo nome è Bob.', ...)
info
请注意,在这种情况下,上下文通过提供的 session_id 的聊天历史得以保留,因此模型知道用户的名字。
我们现在可以尝试使用一个新的会话 ID,看看它是否不记得。
runnable_with_history.invoke({"language": "italian", "input": "whats my name?"},config={"configurable": {"session_id": "2a"}},
)# 返回
AIMessage(content='Mi dispiace, non so il tuo nome. Come posso aiutarti?', ...)
info
当我们传递一个不同的 session_id 时,我们开始一个新的聊天历史,因此模型不知道用户的名字。
消息输入,字典输出
当您使用模型生成字典中的一个键时,这种格式非常有用。
from langchain_core.messages import HumanMessage
from langchain_core.runnables import RunnableParallelchain = RunnableParallel({"output_message": model})runnable_with_history = RunnableWithMessageHistory(chain,get_session_history,output_messages_key="output_message",
)runnable_with_history.invoke([HumanMessage(content="hi - im bob!")],config={"configurable": {"session_id": "3"}},
)# 返回
{'output_message': AIMessage(content="It's nice to meet you, Bob! I'm Claude, an AI assistant created by Anthropic. How can I help you today?", ...)}
请注意,我们已指定 output_messages_key(将被视为要保存的输出的键)。
runnable_with_history.invoke([HumanMessage(content="whats my name?")],config={"configurable": {"session_id": "3"}},
)# 返回
{'output_message': AIMessage(content='I\'m afraid I don\'t actually know your name - you introduced yourself as Bob, ...', ...)}
info
请注意,在这种情况下,上下文通过提供的 session_id 的聊天历史得以保留,因此模型知道用户的名字。
我们现在可以尝试使用一个新的会话 ID,看看它是否不记得。
runnable_with_history.invoke([HumanMessage(content="whats my name?")],config={"configurable": {"session_id": "3a"}},
)# 返回
{'output_message': AIMessage(content="I'm afraid I don't actually know your name. As an AI assistant, I don't have personal information about you unless you provide it to me directly.", ...)}
info
当我们传递一个不同的 session_id 时,我们开始一个新的聊天历史,因此模型不知道用户的名字。
单键字典用于所有消息输入和消息输出
这是“字典输入,消息输出”的特定情况。在这种情况下,由于只有一个单键,我们不需要指定太多 - 我们只需要指定 input_messages_key。
from operator import itemgetterrunnable_with_history = RunnableWithMessageHistory(itemgetter("input_messages") | model,get_session_history,input_messages_key="input_messages",
)runnable_with_history.invoke({"input_messages": [HumanMessage(content="hi - im bob!")]},config={"configurable": {"session_id": "4"}},
)# 返回
AIMessage(content="It's nice to meet you, Bob! I'm Claude, an AI assistant created by Anthropic. How can I help you today?", ...)
请注意,我们已经指定了 input_messages_key(被视为最新输入消息的键)。
runnable_with_history.invoke({"input_messages": [HumanMessage(content="whats my name?")]},config={"configurable": {"session_id": "4"}},
)# 返回
AIMessage(content='I\'m afraid I don\'t actually know your name - you introduced yourself as Bob, ...', ...)
info
请注意,在这种情况下,上下文通过提供的 session_id 的聊天历史得以保留,因此模型知道用户的名字。
我们现在可以尝试使用新的会话 ID,看看它是否不记得。
runnable_with_history.invoke({"input_messages": [HumanMessage(content="whats my name?")]},config={"configurable": {"session_id": "4a"}},
)# 返回
AIMessage(content="I'm afraid I don't actually know your name. As an AI assistant, I don't have personal information about you unless you provide it to me directly.", ...)
info
当我们传递不同的 session_id 时,我们开始一个新的聊天历史,因此模型不知道用户的名字是什么。
自定义
我们通过传递一组 ConfigurableFieldSpec 对象到 history_factory_config 参数来定制跟踪消息历史的配置参数。下面,我们使用两个参数:user_id 和 conversation_id。
<!--IMPORTS:[{"imported": "ConfigurableFieldSpec", "source": "langchain_core.runnables", "docs": "https://python.langchain.com/api_reference/core/runnables/langchain_core.runnables.utils.ConfigurableFieldSpec.html", "title": "How to add message history"}]-->
from langchain_core.runnables import ConfigurableFieldSpecdef get_session_history(user_id: str, conversation_id: str):return SQLChatMessageHistory(f"{user_id}--{conversation_id}", "sqlite:///memory.db")with_message_history = RunnableWithMessageHistory(runnable,get_session_history,input_messages_key="input",history_messages_key="history",history_factory_config=[ConfigurableFieldSpec(id="user_id",annotation=str,name="User ID",description="Unique identifier for the user.",default="",is_shared=True,),ConfigurableFieldSpec(id="conversation_id",annotation=str,name="Conversation ID",description="Unique identifier for the conversation.",default="",is_shared=True,),],
)with_message_history.invoke({"language": "italian", "input": "hi im bob!"},config={"configurable": {"user_id": "123", "conversation_id": "1"}},
)
AIMessage(content='Ciao Bob! È un piacere conoscerti. Come stai oggi?', response_metadata={'id': 'msg_016RJebCoiAgWaNcbv9wrMNW', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 29, 'output_tokens': 23}}, id='run-40425414-8f72-47d4-bf1d-a84175d8b3f8-0', usage_metadata={'input_tokens': 29, 'output_tokens': 23, 'total_tokens': 52})
# remembers
with_message_history.invoke({"language": "italian", "input": "whats my name?"},config={"configurable": {"user_id": "123", "conversation_id": "1"}},
)
AIMessage(content='Bob, il tuo nome è Bob.', response_metadata={'id': 'msg_01Kktiy3auFDKESY54KtTWPX', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 60, 'output_tokens': 12}}, id='run-c7768420-3f30-43f5-8834-74b1979630dd-0', usage_metadata={'input_tokens': 60, 'output_tokens': 12, 'total_tokens': 72})
# New user_id --> does not remember
with_message_history.invoke({"language": "italian", "input": "whats my name?"},config={"configurable": {"user_id": "456", "conversation_id": "1"}},
)
AIMessage(content='Mi dispiace, non so il tuo nome. Come posso aiutarti?', response_metadata={'id': 'msg_0178FpbpPNioB7kqvyHk7rjD', 'model': 'claude-3-haiku-20240307', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 30, 'output_tokens': 23}}, id='run-df1f1768-aab6-4aec-8bba-e33fc9e90b8d-0', usage_metadata={'input_tokens': 30, 'output_tokens': 23, 'total_tokens': 53})
请注意,在这种情况下,上下文为相同的 user_id 保留,但一旦我们更改它,新的聊天历史就开始了,即使 conversation_id 是相同的。
在子链之间进行路由
路由允许您创建非确定性链,其中前一步的输出定义了下一步。路由可以通过允许您定义状态并使用与这些状态相关的信息作为模型调用的上下文,帮助提供与模型交互的结构和一致性。
有两种方式可以执行路由:
- 从 RunnableLambda 有条件地返回可运行组件(推荐)
- 使用 RunnableBranch (遗留版)
我们将通过一个两步序列来说明这两种方法,其中第一步将输入问题分类为关于 LangChain、Anthropic 或 其他,然后路由到相应的提示链。
首先,让我们创建一个链,以识别传入的问题是关于 LangChain、Anthropic 还是 其他:
<!--IMPORTS:[{"imported": "ChatAnthropic", "source": "langchain_anthropic", "docs": "https://python.langchain.com/api_reference/anthropic/chat_models/langchain_anthropic.chat_models.ChatAnthropic.html", "title": "How to route between sub-chains"}, {"imported": "StrOutputParser", "source": "langchain_core.output_parsers", "docs": "https://python.langchain.com/api_reference/core/output_parsers/langchain_core.output_parsers.string.StrOutputParser.html", "title": "How to route between sub-chains"}, {"imported": "PromptTemplate", "source": "langchain_core.prompts", "docs": "https://python.langchain.com/api_reference/core/prompts/langchain_core.prompts.prompt.PromptTemplate.html", "title": "How to route between sub-chains"}]-->
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplatechain = (PromptTemplate.from_template("""Given the user question below, classify it as either being about `LangChain`, `Anthropic`, or `Other`.Do not respond with more than one word.<question>
{question}
</question>Classification:""")| ChatAnthropic(model_name="claude-3-haiku-20240307")| StrOutputParser()
)chain.invoke({"question": "how do I call Anthropic?"})
‘Anthropic’
现在,让我们创建三个子链:
langchain_chain = PromptTemplate.from_template("""You are an expert in langchain. \
Always answer questions starting with "As Harrison Chase told me". \
Respond to the following question:Question: {question}
Answer:"""
) | ChatAnthropic(model_name="claude-3-haiku-20240307")
anthropic_chain = PromptTemplate.from_template("""You are an expert in anthropic. \
Always answer questions starting with "As Dario Amodei told me". \
Respond to the following question:Question: {question}
Answer:"""
) | ChatAnthropic(model_name="claude-3-haiku-20240307")
general_chain = PromptTemplate.from_template("""Respond to the following question:Question: {question}
Answer:"""
) | ChatAnthropic(model_name="claude-3-haiku-20240307")
使用自定义函数(推荐)
您还可以使用自定义函数在不同输出之间进行路由。以下是一个示例:
def route(info):if "anthropic" in info["topic"].lower():return anthropic_chainelif "langchain" in info["topic"].lower():return langchain_chainelse:return general_chain
<!--IMPORTS:[{"imported": "RunnableLambda", "source": "langchain_core.runnables", "docs": "https://python.langchain.com/api_reference/core/runnables/langchain_core.runnables.base.RunnableLambda.html", "title": "How to route between sub-chains"}]-->
from langchain_core.runnables import RunnableLambdafull_chain = {"topic": chain, "question": lambda x: x["question"]} | RunnableLambda(route
)
full_chain.invoke({"question": "how do I use Anthropic?"})
AIMessage(content="As Dario Amodei told me, to use Anthropic, you can start by exploring the company's website and learning about their mission, values, and the different services and products they offer. Anthropic is focused on developing safe and ethical AI systems, so they have a strong emphasis on transparency and responsible AI development. \n\nDepending on your specific needs, you can look into Anthropic's AI research and development services, which cover areas like natural language processing, computer vision, and reinforcement learning. They also offer consulting and advisory services to help organizations navigate the challenges and opportunities of AI integration.\n\nAdditionally, Anthropic has released some open-source AI models and tools that you can explore and experiment with. These can be a great way to get hands-on experience with Anthropic's approach to AI development.\n\nOverall, Anthropic aims to be a reliable and trustworthy partner in the AI space, so I'd encourage you to reach out to them directly to discuss how they can best support your specific requirements.", response_metadata={'id': 'msg_01CtLFgFSwvTaJomrihE87Ra', 'content': [ContentBlock(text="As Dario Amodei told me, to use Anthropic, you can start by exploring the company's website and learning about their mission, values, and the different services and products they offer. Anthropic is focused on developing safe and ethical AI systems, so they have a strong emphasis on transparency and responsible AI development. \n\nDepending on your specific needs, you can look into Anthropic's AI research and development services, which cover areas like natural language processing, computer vision, and reinforcement learning. They also offer consulting and advisory services to help organizations navigate the challenges and opportunities of AI integration.\n\nAdditionally, Anthropic has released some open-source AI models and tools that you can explore and experiment with. These can be a great way to get hands-on experience with Anthropic's approach to AI development.\n\nOverall, Anthropic aims to be a reliable and trustworthy partner in the AI space, so I'd encourage you to reach out to them directly to discuss how they can best support your specific requirements.", type='text')], 'model': 'claude-3-haiku-20240307', 'role': 'assistant', 'stop_reason': 'end_turn', 'stop_sequence': None, 'type': 'message', 'usage': Usage(input_tokens=53, output_tokens=219)})
full_chain.invoke({"question": "how do I use LangChain?"})
AIMessage(content="As Harrison Chase told me, using LangChain involves a few key steps:\n\n1. **Set up your environment**: Install the necessary Python packages, including the LangChain library itself, as well as any other dependencies your application might require, such as language models or other integrations.\n\n2. **Understand the core concepts**: LangChain revolves around a few core concepts, like Agents, Chains, and Tools. Familiarize yourself with these concepts and how they work together to build powerful language-based applications.\n\n3. **Identify your use case**: Determine what kind of task or application you want to build using LangChain, such as a chatbot, a question-answering system, or a document summarization tool.\n\n4. **Choose the appropriate components**: Based on your use case, select the right LangChain components, such as agents, chains, and tools, to build your application.\n\n5. **Integrate with language models**: LangChain is designed to work seamlessly with various language models, such as OpenAI's GPT-3 or Anthropic's models. Connect your chosen language model to your LangChain application.\n\n6. **Implement your application logic**: Use LangChain's building blocks to implement the specific functionality of your application, such as prompting the language model, processing the response, and integrating with other services or data sources.\n\n7. **Test and iterate**: Thoroughly test your application, gather feedback, and iterate on your design and implementation to improve its performance and user experience.\n\nAs Harrison Chase emphasized, LangChain provides a flexible and powerful framework for building language-based applications, making it easier to leverage the capabilities of modern language models. By following these steps, you can get started with LangChain and create innovative solutions tailored to your specific needs.", response_metadata={'id': 'msg_01H3UXAAHG4TwxJLpxwuuVU7', 'content': [ContentBlock(text="As Harrison Chase told me, using LangChain involves a few key steps:\n\n1. **Set up your environment**: Install the necessary Python packages, including the LangChain library itself, as well as any other dependencies your application might require, such as language models or other integrations.\n\n2. **Understand the core concepts**: LangChain revolves around a few core concepts, like Agents, Chains, and Tools. Familiarize yourself with these concepts and how they work together to build powerful language-based applications.\n\n3. **Identify your use case**: Determine what kind of task or application you want to build using LangChain, such as a chatbot, a question-answering system, or a document summarization tool.\n\n4. **Choose the appropriate components**: Based on your use case, select the right LangChain components, such as agents, chains, and tools, to build your application.\n\n5. **Integrate with language models**: LangChain is designed to work seamlessly with various language models, such as OpenAI's GPT-3 or Anthropic's models. Connect your chosen language model to your LangChain application.\n\n6. **Implement your application logic**: Use LangChain's building blocks to implement the specific functionality of your application, such as prompting the language model, processing the response, and integrating with other services or data sources.\n\n7. **Test and iterate**: Thoroughly test your application, gather feedback, and iterate on your design and implementation to improve its performance and user experience.\n\nAs Harrison Chase emphasized, LangChain provides a flexible and powerful framework for building language-based applications, making it easier to leverage the capabilities of modern language models. By following these steps, you can get started with LangChain and create innovative solutions tailored to your specific needs.", type='text')], 'model': 'claude-3-haiku-20240307', 'role': 'assistant', 'stop_reason': 'end_turn', 'stop_sequence': None, 'type': 'message', 'usage': Usage(input_tokens=50, output_tokens=400)})
full_chain.invoke({"question": "whats 2 + 2"})
AIMessage(content='4', response_metadata={'id': 'msg_01UAKP81jTZu9fyiyFYhsbHc', 'content': [ContentBlock(text='4', type='text')], 'model': 'claude-3-haiku-20240307', 'role': 'assistant', 'stop_reason': 'end_turn', 'stop_sequence': None, 'type': 'message', 'usage': Usage(input_tokens=28, output_tokens=5)})
使用 RunnableBranch
RunnableBranch 是一种特殊类型的可运行对象,允许您根据输入定义一组条件和可运行对象。它并不提供您无法在上述自定义函数中实现的功能,因此我们建议使用自定义函数。
RunnableBranch 通过一组(条件,可运行对象)对和一个默认可运行对象进行初始化。它通过将每个条件与调用时的输入进行比较来选择哪个分支。它选择第一个评估为 True 的条件,并使用输入运行与该条件对应的可运行对象。
如果没有提供的条件匹配,它将运行默认可运行对象。
以下是它在实际操作中的示例:
<!--IMPORTS:[{"imported": "RunnableBranch", "source": "langchain_core.runnables", "docs": "https://python.langchain.com/api_reference/core/runnables/langchain_core.runnables.branch.RunnableBranch.html", "title": "How to route between sub-chains"}]-->
from langchain_core.runnables import RunnableBranchbranch = RunnableBranch((lambda x: "anthropic" in x["topic"].lower(), anthropic_chain),(lambda x: "langchain" in x["topic"].lower(), langchain_chain),general_chain,
)
full_chain = {"topic": chain, "question": lambda x: x["question"]} | branch
full_chain.invoke({"question": "how do I use Anthropic?"})
AIMessage(content="As Dario Amodei told me, to use Anthropic, you should first familiarize yourself with our mission and principles. Anthropic is committed to developing safe and beneficial artificial intelligence that can help solve important problems facing humanity. To get started, I recommend exploring the resources on our website, which cover our research, products, and approach to AI development. You can also reach out to our team to learn more about how Anthropic's technology and services can support your specific needs.The key is to engage with us in a way that aligns with our values of transparency, ethical AI, and a commitment to the wellbeing of humanity. We're here to collaborate and help you harness the power of advanced AI responsibly.", response_metadata={...})
full_chain.invoke({"question": "how do I use LangChain?"})
AIMessage(content="As Harrison Chase told me, using LangChain involves several key steps. First, you'll need to install the LangChain library and import the necessary modules. Then, you'll want to define your language model, any data sources you plan to use, and the specific tasks you want to accomplish, such as question answering, text generation, or agent-based reasoning. LangChain provides a flexible framework for building applications that leverage large language models. It includes abstractions for things like retrievers, prompts, and chains, which allow you to compose different components together to create powerful workflows. The documentation on the LangChain website is excellent and covers many common use cases in detail. I'd recommend starting there to get a solid understanding of the core concepts and how to apply them to your specific needs. And of course, feel free to reach out if you have any other questions - I'm always happy to share more insights from my conversations with Harrison.", response_metadata={...})
full_chain.invoke({"question": "whats 2 + 2"})
AIMessage(content='4', response_metadata={...})
通过语义相似性进行路由
一种特别有用的技术是使用嵌入将查询路由到最相关的提示。以下是一个示例。
一种特别有用的技术是使用嵌入将查询路由到最相关的提示。以下是一个示例。```python
<!--IMPORTS:[{"imported": "cosine_similarity", "source": "langchain_community.utils.math", "docs": "https://python.langchain.com/api_reference/community/utils/langchain_community.utils.math.cosine_similarity.html", "title": "如何在子链之间进行路由"}, {"imported": "StrOutputParser", "source": "langchain_core.output_parsers", "docs": "https://python.langchain.com/api_reference/core/output_parsers/langchain_core.output_parsers.string.StrOutputParser.html", "title": "如何在子链之间进行路由"}, {"imported": "PromptTemplate", "source": "langchain_core.prompts", "docs": "https://python.langchain.com/api_reference/core/prompts/langchain_core.prompts.prompt.PromptTemplate.html", "title": "如何在子链之间进行路由"}, {"imported": "RunnableLambda", "source": "langchain_core.runnables", "docs": "https://python.langchain.com/api_reference/core/runnables/langchain_core.runnables.base.RunnableLambda.html", "title": "如何在子链之间进行路由"}, {"imported": "RunnablePassthrough", "source": "langchain_core.runnables", "docs": "https://python.langchain.com/api_reference/core/runnables/langchain_core.runnables.passthrough.RunnablePassthrough.html", "title": "如何在子链之间进行路由"}, {"imported": "OpenAIEmbeddings", "source": "langchain_openai", "docs": "https://python.langchain.com/api_reference/openai/embeddings/langchain_openai.embeddings.base.OpenAIEmbeddings.html", "title": "如何在子链之间进行路由"}]-->
from langchain_community.utils.math import cosine_similarity
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_openai import OpenAIEmbeddingsphysics_template = """你是一位非常聪明的物理教授。\
你擅长以简洁易懂的方式回答物理问题。\
当你不知道问题答案时,会坦诚承认不知道。这里有一个问题:
{query}"""math_template = """你是一位非常优秀的数学家。你擅长回答数学问题。\
你之所以优秀,是因为你能够把复杂的问题拆解成组成部分,\
回答这些部分,再把答案组合起来解决整体问题。这里有一个问题:
{query}"""embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates)def prompt_router(input):query_embedding = embeddings.embed_query(input["query"])similarity = cosine_similarity([query_embedding], prompt_embeddings)[0]most_similar = prompt_templates[similarity.argmax()]print("使用数学模块" if most_similar == math_template else "使用物理模块")return PromptTemplate.from_template(most_similar)chain = ({"query": RunnablePassthrough()}| RunnableLambda(prompt_router)| ChatAnthropic(model="claude-3-haiku-20240307")| StrOutputParser()
)print(chain.invoke("什么是黑洞"))
使用物理模块
作为物理教授,我很乐意简洁且易懂地解释黑洞的概念。黑洞是时空中一个极其致密的区域,重力如此强大以至于连光都无法逃脱。这意味着如果你靠近黑洞,你会被强大的引力拉入并压碎。黑洞的形成是当一颗远比太阳大的巨大恒星生命终结时自身坍缩,这使物质变得极端密集,引力变得极强,形成了“事件视界”——一个无法返回的界限。在事件视界之外,物理定律失效,强大的引力形成了奇点,即时空中密度和曲率无限的点。黑洞非常神秘且引人入胜,关于它们的性质和行为我们仍有很多未知。如果我对黑洞的具体细节不确定,会坦诚承认并鼓励进一步研究。print(chain.invoke("什么是路径积分"))
使用数学模块
路径积分是物理学中一个强大的数学概念,尤其在量子力学领域。它由著名物理学家理查德·费曼提出,作为量子力学的另一种表述方法。路径积分不再考虑粒子从一点到另一点的单一路径,而是认为粒子同时经历所有可能路径。每条路径有一个复数权重,粒子从一点到另一点的概率振幅通过对所有路径加权求和(积分)计算。路径积分的关键思想包括:1. 叠加原理:量子力学中粒子可以同时处于多种状态或路径的叠加态。2. 概率振幅:粒子从一点到另一点的概率振幅通过对所有路径的复数权重求和得到。3. 路径权重:每条路径的权重基于该路径上的作用量(拉格朗日量的时间积分),作用量较小的路径权重大。4. 费曼方法:费曼提出路径积分作为传统波函数方法的替代,提供了更直观的量子现象理解。路径积分方法在量子场论中尤其有用,为计算转移概率和理解量子系统行为提供强大框架,也应用于凝聚态物理、统计力学,甚至金融中的期权定价。路径积分的数学构造涉及泛函分析和测度论的高级概念,是物理学家重要且复杂的工具。
创建动态(自构建)链
有时我们希望在运行时构建链的部分,这取决于链的输入(路由是最常见的例子)。我们可以使用RunnableLambda的一个非常有用的属性来创建动态链,即如果RunnableLambda返回一个Runnable,则该Runnable会被调用。让我们看一个例子。
pip install -qU langchain-openai
import getpass
import osos.environ["OPENAI_API_KEY"] = getpass.getpass()from langchain_openai import ChatOpenAIllm = ChatOpenAI(model="gpt-4o-mini")
# | echo: false
from langchain_anthropic import ChatAnthropicllm = ChatAnthropic(model="claude-3-sonnet-20240229")
from operator import itemgetterfrom langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import Runnable, RunnablePassthrough, chaincontextualize_instructions = ("Convert the latest user question into a standalone question given the chat history. ""Don't answer the question, return the question and nothing else (no descriptive text)."
)
contextualize_prompt = ChatPromptTemplate.from_messages([("system", contextualize_instructions),("placeholder", "{chat_history}"),("human", "{question}"),]
)
contextualize_question = contextualize_prompt | llm | StrOutputParser()qa_instructions = ("Answer the user question given the following context:\n\n{context}."
)
qa_prompt = ChatPromptTemplate.from_messages([("system", qa_instructions), ("human", "{question}")]
)@chain
def contextualize_if_needed(input_: dict) -> Runnable:if input_.get("chat_history"):# 返回另一个 Runnable(运行接口),而非实际结果return contextualize_questionelse:return RunnablePassthrough() | itemgetter("question")@chain
def fake_retriever(input_: dict) -> str:return "egypt's population in 2024 is about 111 million"full_chain = (RunnablePassthrough.assign(question=contextualize_if_needed).assign(context=fake_retriever)| qa_prompt| llm| StrOutputParser()
)result = full_chain.invoke({"question": "what about egypt","chat_history": [("human", "what's the population of indonesia"),("ai", "about 276 million"),],}
)print(result)
# 输出:
# "According to the context provided, Egypt's population in 2024 is estimated to be about 111 million."
这里的关键是 contextualize_if_needed 返回另一个运行接口(Runnable),而不是直接输出。这个返回的运行接口会在完整链执行时被调用。
此外,返回的运行接口仍然支持流式处理、批处理等功能。
for chunk in contextualize_if_needed.stream({"question": "what about egypt","chat_history": [("human", "what's the population of indonesia"),("ai", "about 276 million"),],}
):print(chunk)
输出示例:
WhatisthepopulationofEgypt
?
检查可运行项
一旦您使用LangChain表达式创建了一个可运行项,您可能会想要检查它,以更好地了解发生了什么。此笔记本涵盖了一些执行此操作的方法。
我们将创建一个进行检索的链:
%pip install -qU langchain langchain-openai faiss-cpu tiktoken
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings# 创建一个向量数据库,文本为 "harrison worked at kensho",使用 OpenAI 的嵌入模型
vectorstore = FAISS.from_texts(["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
# 将向量数据库转换为检索器
retriever = vectorstore.as_retriever()# 定义提示模板,仅根据给定上下文回答问题
template = """仅基于以下上下文回答问题:
{context}问题: {question}
"""
prompt = ChatPromptTemplate.from_template(template)# 初始化聊天模型
model = ChatOpenAI()# 构建链条,输入为 context 和 question
chain = ({"context": retriever, "question": RunnablePassthrough()}| prompt| model| StrOutputParser()
)
获取图形
您可以使用 get_graph() 方法获取可运行的图形表示:
chain.get_graph()
打印图形
虽然这不是特别清晰,但您可以使用 print_ascii() 方法以更易于理解的方式显示该图形:
chain.get_graph().print_ascii()
输出示例:
+---------------------------------+ | Parallel<context,question>Input | +---------------------------------+ ** ** *** *** ** **
+----------------------+ +-------------+
| VectorStoreRetriever | | Passthrough |
+----------------------+ +-------------+ ** ** *** *** ** ** +----------------------------------+ | Parallel<context,question>Output | +----------------------------------+ * * * +--------------------+ | ChatPromptTemplate | +--------------------+ * * * +------------+ | ChatOpenAI | +------------+ * * * +-----------------+ | StrOutputParser | +-----------------+ * * * +-----------------------+ | StrOutputParserOutput | +-----------------------+
获取提示词
您可能想查看链中使用的提示词,可以使用 get_prompts() 方法:
chain.get_prompts()
示例输出:
[ChatPromptTemplate(input_variables=['context', 'question'], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['context', 'question'], template='Answer the question based only on the following context:\n{context}\n\nQuestion: {question}\n'))])]
为可运行对象添加后备方案
在使用语言模型时,您可能经常会遇到来自底层 API 的问题,无论是速率限制还是服务中断。因此,当将大型语言模型(LLM)应用于生产环境时,构建健壮的“后备方案”就显得尤为重要。
后备方案:在主模型失败或异常时,自动切换到备用模型或逻辑流程,以确保系统的鲁棒性和连续性。
至关重要的是,后备方案不仅可以应用于大型语言模型级别,还可以应用于整个可运行对象级别。这一点很重要,因为不同的模型通常需要不同的提示词。因此,如果您对OpenAI的调用失败,您不仅想将相同的提示词发送给Anthropic - 您可能想使用不同的提示词模板并发送不同的版本。
针对大型语言模型API错误的后备方案
这可能是后备方案最常见的用例。对大型语言模型API的请求可能因多种原因而失败 - API可能宕机,您可能达到了速率限制,或者其他任何原因。因此,使用后备方案可以帮助防范这些类型的问题。
重要提示:默认情况下,许多大型语言模型包装器会捕获错误并重试。在使用后备方案时,您很可能希望关闭这些功能。否则,第一个包装器将不断重试而不会失败。
pip install --upgrade --quiet langchain langchain-openai
首先,让我们模拟一下如果我们遇到来自OpenAI的RateLimitError会发生什么
from langchain_anthropic import ChatAnthropic
from langchain_openai import ChatOpenAIfrom unittest.mock import patch
import httpx
from openai import RateLimitError# 构造一个 RateLimitError 模拟异常
request = httpx.Request("GET", "/")
response = httpx.Response(200, request=request)
error = RateLimitError("rate limit", response=response, body="")# 设置 OpenAI 模型,不允许重试
openai_llm = ChatOpenAI(model="gpt-4o-mini", max_retries=0)
anthropic_llm = ChatAnthropic(model="claude-3-haiku-20240307")
llm = openai_llm.with_fallbacks([anthropic_llm])# 模拟 OpenAI 抛错
with patch("openai.resources.chat.completions.Completions.create", side_effect=error):try:print(openai_llm.invoke("Why did the chicken cross the road?"))except RateLimitError:print("Hit error")
Hit error
# 启用后备,fallback 到 Anthropic
with patch("openai.resources.chat.completions.Completions.create", side_effect=error):try:print(llm.invoke("Why did the chicken cross the road?"))except RateLimitError:print("Hit error")
我们可以像使用普通大型语言模型一样使用我们的“带回退的LLM”。
<!--IMPORTS:[{"imported": "ChatPromptTemplate", "source": "langchain_core.prompts", "docs": "https://python.langchain.com/api_reference/core/prompts/langchain_core.prompts.chat.ChatPromptTemplate.html", "title": "How to add fallbacks to a runnable"}]-->
from langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_messages([("system","You're a nice assistant who always includes a compliment in your response",),("human", "Why did the {animal} cross the road"),]
)
chain = prompt | llm
with patch("openai.resources.chat.completions.Completions.create", side_effect=error):try:print(chain.invoke({"animal": "kangaroo"}))except RateLimitError:print("Hit error")
content=" I don't actually know why the kangaroo crossed the road, but I can take a guess! Here are some possible reasons:\n\n- To get to the other side (the classic joke answer!)\n\n- It was trying to find some food or water \n\n- It was trying to find a mate during mating season\n\n- It was fleeing from a predator or perceived threat\n\n- It was disoriented and crossed accidentally \n\n- It was following a herd of other kangaroos who were crossing\n\n- It wanted a change of scenery or environment \n\n- It was trying to reach a new habitat or territory\n\nThe real reason is unknown without more context, but hopefully one of those potential explanations does the joke justice! Let me know if you have any other animal jokes I can try to decipher." additional_kwargs={} example=False
序列的回退
我们还可以为“序列”创建回退,而这些序列本身就是“链式调用”的组合。在这个示例中,我们使用两个不同的模型:ChatOpenAI(聊天模型)和普通的 OpenAI(非聊天模型)。由于后者不是聊天模型,因此它可能需要一个不同的提示模板。
# 导入字符串输出解析器,以统一输出类型
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI# 构建聊天提示模板
chat_prompt = ChatPromptTemplate.from_messages([("system", "You're a nice assistant who always includes a compliment in your response"),("human", "Why did the {animal} cross the road"),
])# 使用一个错误的模型名来模拟失败
chat_model = ChatOpenAI(model="gpt-fake")# 构建错误链:提示 -> 模型 -> 输出解析
bad_chain = chat_prompt | chat_model | StrOutputParser()
使用非聊天模型构建正确链(good_chain)
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI# 构建普通 LLM 的提示模板
prompt_template = """Instructions: You should always include a compliment in your response.Question: Why did the {animal} cross the road?"""
prompt = PromptTemplate.from_template(prompt_template)# 使用非聊天模型
llm = OpenAI()# 构建正确链:提示 -> 模型
good_chain = prompt | llm
构建带回退的最终链并调用
# 将错误链与正确链组合为有回退机制的链
chain = bad_chain.with_fallbacks([good_chain])# 执行调用
result = chain.invoke({"animal": "turtle"})
print(result)
输出示例:
Answer: The turtle crossed the road to get to the other side, and I have to say he had some impressive determination.
长输入的回退
大型语言模型的一个主要限制因素是其上下文窗口大小。虽然我们可以在发送提示之前计算其长度,但在面对复杂或不可预期的输入时,可能会超过模型的最大上下文限制。
为解决这个问题,我们可以使用回退机制:当主模型因为上下文过长失败时,自动回退到一个支持更长上下文窗口的模型。
from langchain_openai import ChatOpenAI# 创建两个模型:一个标准上下文窗口,一个长上下文窗口
short_llm = ChatOpenAI() # 默认 gpt-3.5-turbo,约 4K token
long_llm = ChatOpenAI(model="gpt-3.5-turbo-16k") # 长上下文版本# 使用回退机制:当 short_llm 失败时,使用 long_llm
llm = short_llm.with_fallbacks([long_llm])
构造超长输入触发回退机制
# 构造一个超过 4097 tokens 的输入
inputs = "What is the next number: " + ", ".join(["one", "two"] * 3000)# 尝试直接调用 short_llm,观察其失败表现
try:print(short_llm.invoke(inputs))
except Exception as e:print(e)
输出示例(错误信息):
This model's maximum context length is 4097 tokens. However, your messages resulted in 12012 tokens. Please reduce the length of the messages.
使用带回退的模型执行调用
# 使用包含回退机制的 llm,自动切换到长上下文模型
try:print(llm.invoke(inputs))
except Exception as e:print(e)
输出示例:
content='The next number in the sequence is two.' additional_kwargs={} example=False
这个示例中,模型成功处理了超长输入,并返回了合理的输出。
回退到更好的模型
我们经常希望模型输出特定格式(如 JSON、ISO 8601 时间字符串 等)。虽然像 GPT-3.5 这样的模型通常能做到,但在某些情况下它可能输出额外解释或格式错误的内容,导致解析失败。
在这种情况下,可以设置一个回退机制:先尝试使用 GPT-3.5(速度快、成本低),如果解析失败,则自动回退到更可靠的 GPT-4。
示例:要求模型返回标准时间格式字符串
from langchain.output_parsers import DatetimeOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
构造提示模板
prompt = ChatPromptTemplate.from_template("what time was {event} (in %Y-%m-%dT%H:%M:%S.%fZ format - only return this value)"
)
设置解析器 + 回退机制
# 主模型使用 GPT-3.5 + 时间解析器
openai_35 = ChatOpenAI() | DatetimeOutputParser()# 回退模型使用 GPT-4 + 时间解析器
openai_4 = ChatOpenAI(model="gpt-4") | DatetimeOutputParser()# 仅使用 GPT-3.5 的链
only_35 = prompt | openai_35# 使用回退机制的链
fallback_4 = prompt | openai_35.with_fallbacks([openai_4])
执行调用:GPT-3.5 输出无法解析
try:print(only_35.invoke({"event": "the superbowl in 1994"}))
except Exception as e:print(f"Error: {e}")
错误示例:
Error: Could not parse datetime string: The Super Bowl in 1994 took place on January 30th at 3:30 PM local time. Converting this to the specified format (%Y-%m-%dT%H:%M:%S.%fZ) results in: 1994-01-30T15:30:00.000Z
使用回退模型成功解析
try:print(fallback_4.invoke({"event": "the superbowl in 1994"}))
except Exception as e:print(f"Error: {e}")
输出示例:
1994-01-30 15:30:00
将运行时机密传递给可运行对象
在构建 LangChain 工作流时,我们有时需要在运行时传递一些敏感信息(如密钥或密文),但又不希望它们出现在调用日志或追踪记录中。
LangChain 提供了 RunnableConfig 和 configurable.__ 机制来解决这个问题。
我们可以在 RunnableConfig 的 configurable 字段中传入以 __ 开头的键,这些键不会被记录在追踪日志中。
from langchain_core.runnables import RunnableConfig
from langchain_core.tools import tool@tool
def foo(x: int, config: RunnableConfig) -> int:"""Sum x and a secret int"""return x + config["configurable"]["__top_secret_int"]
调用工具时传入机密字段:
foo.invoke({"x": 5},{"configurable": {"__top_secret_int": 2, # 不会被追踪"traced_key": "bar" # 会记录在追踪日志中}}
)
输出结果:
7