Burn 开源程序是下一代深度学习框架,在灵活性、效率和可移植性方面毫不妥协
一、软件介绍
文末提供程序和源码下载
Burn 开源程序是下一代深度学习框架,在灵活性、效率和可移植性方面毫不妥协
二、Performance 性能
因为我们相信深度学习框架的目标是将计算转化为有用的智能,所以我们将性能作为 Burn 的核心支柱。我们努力通过利用下述多种优化技术来实现最高效率。
自动内核融合 💥
Using Burn means having your models optimized on any backend. When possible, we provide a way to automatically and dynamically create custom kernels that minimize data relocation between different memory spaces, extremely useful when moving memory is the bottleneck.
使用 Burn 意味着在任何后端优化您的模型。在可能的情况下,我们提供一种方法 自动动态创建自定义内核,最大限度地减少不同之间的数据重新定位 内存空间,当移动内存是瓶颈时非常有用。
As an example, you could write your own GELU activation function with the high level tensor api (see Rust code snippet below).
例如,您可以使用高级张量 api 编写自己的 GELU 激活函数(参见 Rust 代码片段)。
fn gelu_custom<B: Backend, const D: usize>(x: Tensor<B, D>) -> Tensor<B, D> {let x = x.clone() * ((x / SQRT_2).erf() + 1);x / 2
}
Then, at runtime, a custom low-level kernel will be automatically created for your specific implementation and will rival a handcrafted GPU implementation. The kernel consists of about 60 lines of WGSL WebGPU Shading Language, an extremely verbose lower level shader language you probably don't want to program your deep learning models in!
然后,在运行时,将自动为您的特定 实现,并将与手工制作的 GPU 实现相媲美。内核由大约 60 个 WGSL WebGPU 着色语言行, 一种极其冗长的低级着色器语言,您可能不想对 Deep 进行编程 学习模型!
线程安全构建块 🦞
Burn emphasizes thread safety by leveraging the ownership system of Rust. With Burn, each module is the owner of its weights. It is therefore possible to send a module to another thread for computing the gradients, then send the gradients to the main thread that can aggregate them, and voilà, you get multi-device training.
Burn 通过利用 Rust 的所有权系统来强调线程安全。使用 Burn 时,每个模块都是其权重的所有者。因此,可以将一个模块发送到另一个线程来计算梯度,然后将梯度发送到可以聚合它们的主线程,瞧,您可以获得多设备训练。
This is a very different approach from what PyTorch does, where backpropagation actually mutates the grad attribute of each tensor parameter. This is not a thread-safe operation and therefore requires lower level synchronization primitives, see distributed training for reference. Note that this is still very fast, but not compatible across different backends and quite hard to implement.
这是一种与 PyTorch 截然不同的方法,在 PyTorch 中,反向传播实际上会改变每个张量参数的 grad 属性。这不是线程安全的作,因此需要较低级别的同步基元,请参阅分布式训练作为参考。请注意,这仍然非常快,但不兼容不同的后端,并且很难实现。
智能内存管理 🦀
One of the main roles of a deep learning framework is to reduce the amount of memory necessary to run models. The naive way of handling memory is that each tensor has its own memory space, which is allocated when the tensor is created then deallocated as the tensor gets out of scope. However, allocating and deallocating data is very costly, so a memory pool is often required to achieve good throughput. Burn offers an infrastructure that allows for easily creating and selecting memory management strategies for backends. For more details on memory management in Burn, see this blog post.
深度学习框架的主要作用之一是减少运行模型所需的内存量。处理内存的幼稚方法是每个张量都有自己的内存空间,该空间在创建张量时分配,然后在张量超出范围时释放。但是,分配和取消分配数据的成本非常高,因此通常需要内存池来实现良好的吞吐量。Burn 提供了一个基础设施,允许轻松创建和选择后端的内存管理策略。有关 Burn 中内存管理的更多详细信息,请参阅此博客文章。
Another very important memory optimization of Burn is that we keep track of when a tensor can be mutated in-place just by using the ownership system well. Even though it is a rather small memory optimization on its own, it adds up considerably when training or running inference with larger models and contributes to reduce the memory usage even more. For more information, see this blog post about tensor handling.
Burn 的另一个非常重要的内存优化是,我们只需很好地使用所有权系统即可跟踪何时可以就地改变张量。尽管它本身是一个相当小的内存优化,但在使用大型模型进行训练或运行推理时,它会大大增加,并有助于进一步减少内存使用量。有关更多信息,请参阅这篇关于张量处理的博客文章。
自动内核选择 🎯
A good deep learning framework should ensure that models run smoothly on all hardware. However, not all hardware share the same behavior in terms of execution speed. For instance, a matrix multiplication kernel can be launched with many different parameters, which are highly sensitive to the size of the matrices and the hardware. Using the wrong configuration could reduce the speed of execution by a large factor (10 times or even more in extreme cases), so choosing the right kernels becomes a priority.
一个好的深度学习框架应该确保模型在所有硬件上都能顺利运行。然而,不是 所有硬件在执行速度方面都具有相同的行为。例如,矩阵 乘法内核可以使用许多不同的参数启动,这些参数对 矩阵和硬件的大小。使用错误的配置可能会降低 执行系数大(极端情况下为 10 倍甚至更多),因此选择合适的内核 成为优先事项。
With our home-made backends, we run benchmarks automatically and choose the best configuration for the current hardware and matrix sizes with a reasonable caching strategy.
使用我们自制的后端,我们会自动运行基准测试并选择最佳配置 具有合理缓存策略的当前硬件和矩阵大小。
This adds a small overhead by increasing the warmup execution time, but stabilizes quickly after a few forward and backward passes, saving lots of time in the long run. Note that this feature isn't mandatory, and can be disabled when cold starts are a priority over optimized throughput.
这会通过增加预热执行时间来增加少量开销,但在 很少的向前和向后传球,从长远来看可以节省大量时间。请注意,此功能不是 强制性的,当冷启动优先于优化吞吐量时,可以禁用此属性。
硬件特定功能 🔥
It is no secret that deep learning is mostly relying on matrix multiplication as its core operation, since this is how fully-connected neural networks are modeled.
众所周知,深度学习主要依赖矩阵乘法作为其核心作, 因为这就是完全连接的神经网络的建模方式。
More and more, hardware manufacturers optimize their chips specifically for matrix multiplication workloads. For instance, Nvidia has its Tensor Cores and today most cellphones have AI specialized chips. As of this moment, we support Tensor Cores with our LibTorch, Candle, CUDA, Metal and WGPU/SPIR-V backends, but not other accelerators yet. We hope this issue gets resolved at some point to bring support to our WGPU backend.
越来越多的硬件制造商专门针对矩阵乘法工作负载优化其芯片。例如,Nvidia 有自己的 Tensor Core,今天大多数手机都有 AI 专用芯片。截至目前,我们的 LibTorch、Candle、CUDA、Metal 和 WGPU/SPIR-V 后端支持 Tensor Core,但尚不支持其他加速器。我们希望这个问题在某个时候得到解决,以便为我们的 WGPU 后端提供支持。
自定义后端扩展 🎒
Burn aims to be the most flexible deep learning framework. While it's crucial to maintain compatibility with a wide variety of backends, Burn also provides the ability to extend the functionalities of a backend implementation to suit your personal modeling requirements.
Burn 旨在成为最灵活的深度学习框架。虽然维护 兼容多种后端,Burn 还提供了扩展 功能,以满足您的个人建模需求。
This versatility is advantageous in numerous ways, such as supporting custom operations like flash attention or manually writing your own kernel for a specific backend to enhance performance. See this section in the Burn Book 🔥 for more details.
这种多功能性在许多方面都是有利的,例如支持自定义作(如 flash attention)或为特定后端手动编写自己的内核以提高性能。有关更多详细信息,请参阅 Burn Book 🔥 中的此部分。
三、Backend 后端
Burn 力求在尽可能多的硬件上以最快的速度实现,并具有强大的实现。我们相信这种灵活性对于现代需求至关重要,因为您可以在云中训练模型,然后在客户硬件上部署,这些硬件因用户而异。
Supported Backends 支持的后端
| Backend 后端 | Devices 设备 | Class 类 |
|---|---|---|
| CUDA 奇迹 | NVIDIA GPUs NVIDIA GPU | First-Party 第一方 |
| ROCm | AMD GPUs AMD 图形处理器 | First-Party 第一方 |
| Metal 金属 | Apple GPUs 苹果 GPU | First-Party 第一方 |
| Vulkan 火山 | Most GPUs on Linux & Windows Linux和Windows上的大多数GPU | First-Party 第一方 |
| Wgpu | Most GPUs 大多数 GPU | First-Party 第一方 |
| NdArray NdArray 系列 | Most CPUs 大多数 CPU | Third-Party 第三方 |
| LibTorch LibTorch 浏览器 | Most GPUs & CPUs 大多数GPU和CPU | Third-Party 第三方 |
| Candle 蜡烛 | Nvidia, Apple GPUs & CPUs Nvidia、Apple GPU 和 CPU | Third-Party 第三方 |
Compared to other frameworks, Burn has a very different approach to supporting many backends. By design, most code is generic over the Backend trait, which allows us to build Burn with swappable backends. This makes composing backend possible, augmenting them with additional functionalities such as autodifferentiation and automatic kernel fusion.
与其他框架相比,Burn 支持许多后端的方法非常不同。根据设计,大多数代码都是基于 Backend trait 的泛型,这允许我们使用可交换的后端构建 Burn。这使得组合后端成为可能,并通过自动微分和自动内核融合等附加功能来增强它们。
四、Training & Inference 训练与推理
使用 Burn 可以轻松完成整个深度学习工作流程,因为您可以使用符合人体工程学的仪表板监控训练进度,并在从嵌入式设备到大型 GPU 集群的任何地方运行推理。
Burn was built from the ground up with training and inference in mind. It's also worth noting how Burn, in comparison to frameworks like PyTorch, simplifies the transition from training to deployment, eliminating the need for code changes.
Burn 是从头开始构建的,考虑了训练和推理。还值得注意的是,与 PyTorch 等框架相比,Burn 如何简化从训练到部署的过渡,无需更改代码。
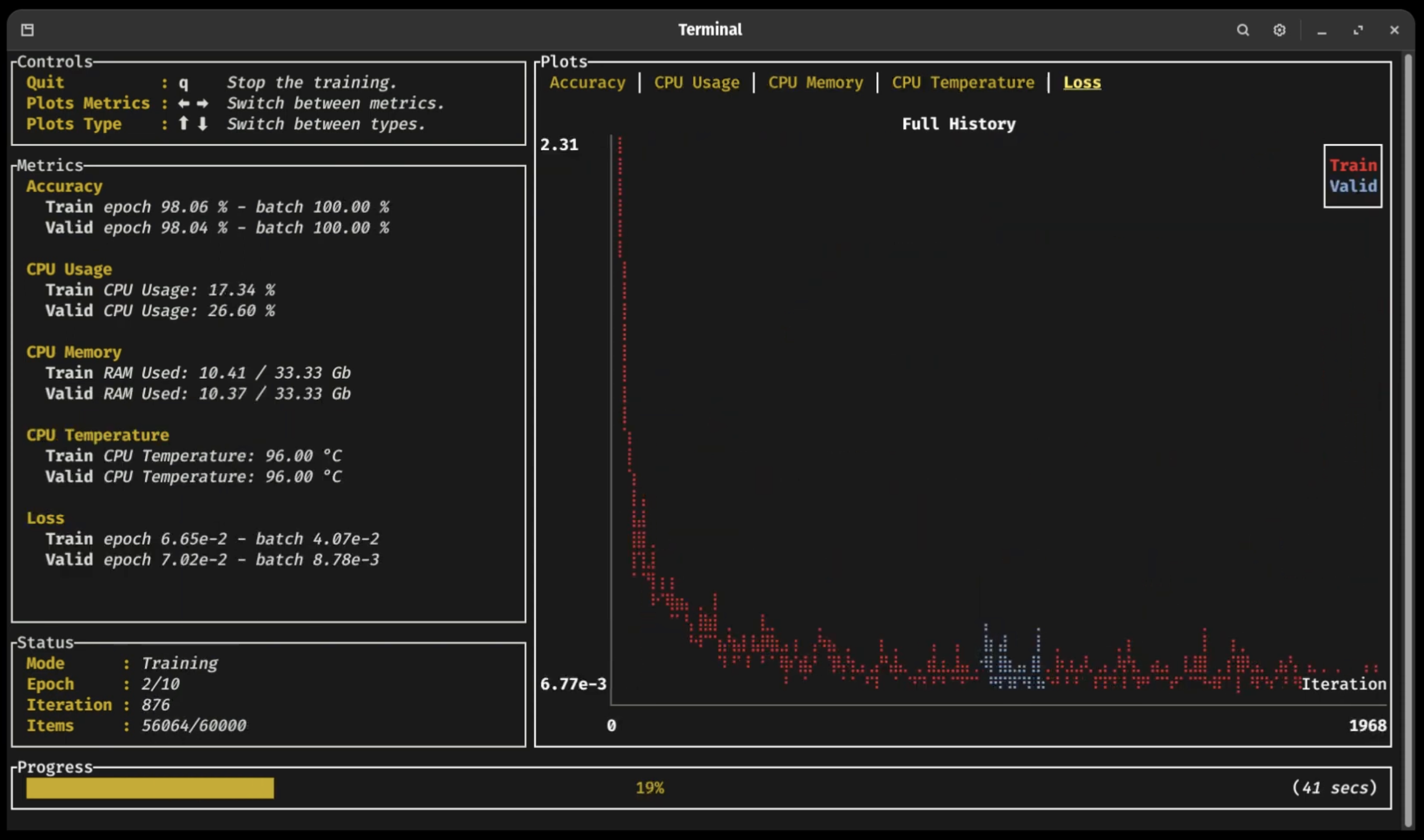
训练仪表板 📈
As you can see in the previous video (click on the picture!), a new terminal UI dashboard based on the Ratatui crate allows users to follow their training with ease without having to connect to any external application.
正如您在上一个视频中看到的(点击图片!),基于 Ratatui 板条箱的新终端 UI 仪表板允许用户轻松跟踪他们的训练,而无需连接到任何外部应用程序。
You can visualize your training and validation metrics updating in real-time and analyze the lifelong progression or recent history of any registered metrics using only the arrow keys. Break from the training loop without crashing, allowing potential checkpoints to be fully written or important pieces of code to complete without interruption 🛡
您可以实时可视化训练和验证指标更新,并分析 仅使用箭头键的任何已注册指标的终身进度或近期历史记录。破 从训练循环中不崩溃,允许完全写入潜在的 checkpoint 或 要不间断🛡地完成的重要代码段
ONNX Support 🐫 ONNX 支持 🐫
ONNX (Open Neural Network Exchange) is an open-standard format that exports both the architecture and the weights of a deep learning model.
ONNX (Open Neural Network Exchange) 是一种开放标准格式,可导出架构 以及深度学习模型的权重。
Burn supports the importation of models that follow the ONNX standard so you can easily port a model you have written in another framework like TensorFlow or PyTorch to Burn to benefit from all the advantages our framework offers.
Burn 支持导入遵循 ONNX 标准的模型,因此您可以轻松移植模型 您已经在另一个框架(如 TensorFlow 或 PyTorch)中编写了 Burn 以从所有 我们的框架提供的优势。
浏览器中🌐的推理
Several of our backends can compile to Web Assembly: Candle and NdArray for CPU, and WGPU for GPU. This means that you can run inference directly within a browser. We provide several examples of this:
我们的几个后端可以编译为 Web Assembly:用于 CPU 的 Candle 和 NdArray,以及用于 GPU 的 WGPU。 这意味着您可以直接在浏览器中运行推理。我们提供了几个示例 这:
- MNIST where you can draw digits and a small convnet tries to find which one it is! 2️⃣ 7️⃣ 😰
MNIST 您可以在其中绘制数字,一个小 convnet 会尝试找到它是哪一个!2️7️⃣ ⃣ 😰 - Image Classification where you can upload images and classify them! 🌄
图像分类,您可以在其中上传图像并对其进行分类!🌄
嵌入式:no_std 支持 ⚙️
Burn's core components support no_std. This means it can run in bare metal environment such as embedded devices without an operating system.
Burn 的核心组件支持 no_std。这意味着它可以在裸机环境中运行,例如没有作系统的嵌入式设备。
As of now, only the NdArray backend can be used in a no_std environment.
截至目前,只有 NdArray 后端可以在 no_std 环境中使用。
Benchmarks 基准
To evaluate performance across different backends and track improvements over time, we provide a dedicated benchmarking suite.
为了评估不同后端的性能并跟踪一段时间内的改进情况,我们提供了专用的基准测试套件。
Run and compare benchmarks using burn-bench.
使用 burn-bench 运行和比较基准测试。
⚠️ Warning When using one of the
wgpubackends, you may encounter compilation errors related to recursive type evaluation. This is due to complex type nesting within thewgpudependency chain. To resolve this issue, add the following line at the top of yourmain.rsorlib.rsfile:
⚠️ 警告 使用其中一个wgpu后端时,您可能会遇到与递归类型评估相关的编译错误。这是由于wgpu依赖项链中的复杂类型嵌套造成的。要解决此问题,请在main.rsorlib.rs文件的顶部添加以下行:#![recursion_limit = "256"]The default recursion limit (128) is often just below the required depth (typically 130-150) due to deeply nested associated types and trait bounds.
由于深度嵌套的关联类型和 trait 边界,默认递归限制 (128) 通常略低于所需的深度(通常为 130-150)。
Getting Started 开始
The Burn Book 🔥
To begin working effectively with Burn, it is crucial to understand its key components and philosophy. This is why we highly recommend new users to read the first sections of The Burn Book 🔥. It provides detailed examples and explanations covering every facet of the framework, including building blocks like tensors, modules, and optimizers, all the way to advanced usage, like coding your own GPU kernels.
要开始有效地使用 Burn,了解其关键组件和理念至关重要。这就是为什么我们强烈建议新用户阅读 The Burn Book 🔥 的第一部分 .它提供了详细的示例和解释,涵盖了框架的各个方面,包括张量、模块和优化器等构建块,一直到高级用法,例如编写您自己的 GPU 内核。
Examples 🙏 例子 🙏The project is constantly evolving, and we try as much as possible to keep the book up to date with new additions. However, we might miss some details sometimes, so if you see something weird, let us know! We also gladly accept Pull Requests 😄
该项目不断发展,我们尽可能地使这本书保持最新状态 新增内容。但是,我们有时可能会错过一些细节,因此如果您看到一些奇怪的东西, 让我们知道!我们也很乐意接受 Pull Request 😄
Let's start with a code snippet that shows how intuitive the framework is to use! In the following, we declare a neural network module with some parameters along with its forward pass.
让我们从一个代码片段开始,它显示了框架的使用是多么直观!在下文中, 我们声明一个带有一些参数的神经网络模块及其前向传递。
use burn::nn;
use burn::module::Module;
use burn::tensor::backend::Backend;#[derive(Module, Debug)]
pub struct PositionWiseFeedForward<B: Backend> {linear_inner: nn::Linear<B>,linear_outer: nn::Linear<B>,dropout: nn::Dropout,gelu: nn::Gelu,
}impl<B: Backend> PositionWiseFeedForward<B> {pub fn forward<const D: usize>(&self, input: Tensor<B, D>) -> Tensor<B, D> {let x = self.linear_inner.forward(input);let x = self.gelu.forward(x);let x = self.dropout.forward(x);self.linear_outer.forward(x)}
} We have a somewhat large amount of examples in the repository that shows how to use the framework in different scenarios.
存储库中提供了大量示例,这些示例展示了如何在不同的场景中使用框架。
Following the book: 在书中:
- Basic Workflow : Creates a custom CNN
Moduleto train on the MNIST dataset and use for inference.
基本工作流程 :创建自定义 CNNModule以在 MNIST 数据集上进行训练并用于推理。 - Custom Training Loop : Implements a basic training loop instead of using the
Learner.
自定义训练循环 :实现基本训练循环,而不是使用Learner. - Custom WGPU Kernel : Learn how to create your own custom operation with the WGPU backend.
自定义 WGPU 内核:了解如何使用 WGPU 后端创建您自己的自定义作。
Additional examples: 其他示例:
- Custom CSV Dataset : Implements a dataset to parse CSV data for a regression task.
自定义 CSV 数据集 :实施一个数据集来解析回归任务的 CSV 数据。 - Regression : Trains a simple MLP on the California Housing dataset to predict the median house value for a district.
回归 :在 California Housing 数据集上训练简单的 MLP,以预测一个地区的房屋中位数。 - Custom Image Dataset : Trains a simple CNN on custom image dataset following a simple folder structure.
自定义图像数据集 :遵循简单的文件夹结构在自定义图像数据集上训练简单的 CNN。 - Custom Renderer : Implements a custom renderer to display the Learner progress.
自定义渲染器 :实现自定义渲染器以显示Learner进度。 - Image Classification Web : Image classification web browser demo using Burn, WGPU and WebAssembly.
图像分类 Web :使用 Burn、WGPU 和 WebAssembly 的图像分类 Web 浏览器演示。 - MNIST Inference on Web : An interactive MNIST inference demo in the browser. The demo is available online.
Web 上的 MNIST 推理 :浏览器中的交互式 MNIST 推理演示。该演示可在线获取。 - MNIST Training : Demonstrates how to train a custom
Module(MLP) with theLearnerconfigured to log metrics and keep training checkpoints.
MNIST 训练 :演示如何训练自定义Module(MLP),并Learner配置以记录指标并保留训练检查点。 - Named Tensor : Performs operations with the experimental
NamedTensorfeature.
命名张量 :使用实验NamedTensor性功能执行作。 - ONNX Import Inference : Imports an ONNX model pre-trained on MNIST to perform inference on a sample image with Burn.
ONNX 导入推理 :导入在 MNIST 上预先训练的 ONNX 模型,以使用 Burn 对示例图像执行推理。 - PyTorch Import Inference : Imports a PyTorch model pre-trained on MNIST to perform inference on a sample image with Burn.
PyTorch Import Inference :导入在 MNIST 上预先训练的 PyTorch 模型,以使用 Burn 对示例图像执行推理。 - Text Classification : Trains a text classification transformer model on the AG News or DbPedia dataset. The trained model can then be used to classify a text sample.
文本分类 :在 AG News 或 DbPedia 数据集上训练文本分类转换器模型。然后,可以使用经过训练的模型对文本样本进行分类。 - Text Generation : Trains a text generation transformer model on the DbPedia dataset.
文本生成 :在 DbPedia 数据集上训练文本生成转换器模型。 - Wasserstein GAN MNIST : Trains a WGAN model to generate new handwritten digits based on MNIST.
Wasserstein GAN MNIST : 训练 WGAN 模型以基于 MNIST 生成新的手写数字。
For more practical insights, you can clone the repository and run any of them directly on your computer!
有关更实用的见解,您可以克隆存储库并直接在 计算机!
Pre-trained Models 🤖 预训练模型 🤖
Why use Rust for Deep Learning? 🦀
为什么使用 Rust 进行深度学习?🦀
Loading Model Records From Previous Versions ⚠️Deprecation Note 弃用说明
Since0.14.0, the internal structure for tensor data has changed. The previousDatastruct was deprecated and officially removed since0.17.0in favor of the newTensorDatastruct, which allows for more flexibility by storing the underlying data as bytes and keeping the data type as a field. If you are usingDatain your code, make sure to switch toTensorData.
自 以来0.14.0,张量数据的内部结构发生了变化。以前的Data结构已被弃用并正式删除,因为0.17.0新的结构体支持新的TensorData结构体,它通过将底层数据存储为字节并将数据类型保留为字段来提供更大的灵活性。如果您在代码Data中使用,请确保切换到TensorData.
从以前的版本 ⚠️ 加载模型记录
In the event that you are trying to load a model record saved in a version older than 0.14.0, make sure to use a compatible version (0.14, 0.15 or 0.16) with the record-backward-compat feature flag.
如果您尝试加载保存在早于 0.14.0 以下版本的 版本的模型记录,请确保使用带有 feature 标志的 record-backward-compat 兼容版本( 0.14 或 0.15 0.16 )。
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>features = [..., "record-backward-compat"]
</code></span></span></span>Otherwise, the record won't be deserialized correctly and you will get an error message. This error will also point you to the backward compatible feature flag.
否则,将无法正确反序列化记录,并且您将收到错误消息。此错误 还将指向 backward compatible feature flag。
The backward compatibility was maintained for deserialization when loading records. Therefore, as soon as you have saved the record again it will be saved according to the new structure and you can upgrade back to the current version
在加载记录时保持了反序列化的向后兼容性。因此,由于 一旦您再次保存了记录,它就会根据新的结构保存,您可以 升级回当前版本
Please note that binary formats are not backward compatible. Thus, you will need to load your record in a previous version and save it in any of the other self-describing record format (e.g., using the NamedMpkFileRecorder) before using a compatible version (as described) with the record-backward-compat feature flag.
请注意,二进制格式不向后兼容。因此,在使用带有功能标志的 record-backward-compat 兼容版本(如所述)之前,您需要以先前版本加载记录并将其保存为任何其他自描述记录格式(例如,使用 )。 NamedMpkFileRecorder
五、软件下载
夸克网盘分享
本文信息来源于GitHub作者地址:https://github.com/tracel-ai/burn