SD3 的采样上篇——Flow Matching
大家好,这里是Goodnote(好评笔记)。本篇介绍 SD3 模型的采样方法上篇——Flow Matching。号称最强模型之一的文生图模型使用的采样方法,是和之前的SD系列模型完全不一样的采样方法。

文章目录
- 写在开头
- 论文
- 推荐阅读
- 前系列扩散回顾(DDPM)
- Flow Matching
- Flow Matching概要
- 1. 背景与目标
- (1) 生成模型的基本目标
- (2) Flow Matching 的核心思想
- 2. Flow Matching 的数学原理
- (1) 时间演化方程
- (2) 损失函数的定义
- 3. Flow Matching 的训练方法
- (1) 参考路径的采样
- (2) 计算真实流场
- (3) 计算学习到的流场 v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t)
- (4) 损失函数
- 4. 引入条件变量
- (1) 条件分布
- (2) 条件流场
- (3) 损失函数
- 5. 训练与生成过程
- (1) 训练阶段
- (2) 生成阶段
- 6. 总结
- Flow Matching公式
- 1. Flow Matching 的基本概念
- 目标
- 直接求解微分方程的问题
- 引入向量场 u t u_t ut
- 2. 正向过程中的定义
- 定义概率路径
- 边界条件
- 3. 条件向量场
- 定义条件向量场
- 向量场具体表达式
- 4. 信噪比(SNR) λ t ′ \lambda_t' λt′的重新参数化
- 5. 原始 Flow Matching 损失函数定义
- 6. 原始条件化损失函数定义
- (1) 条件化损失
- (2) 噪声预测目标
- 7. 权重项与统一目标
- Q&A
- FM和CFM损失函数
- 1. Flow Matching (FM) 的问题
- 2. Conditional Flow Matching (CFM) 的改进
- FM的扩散
- 1. 前向扩散
- 2. 反向扩散
写在开头
SD3 的采样方法是基于 RF(Rectified Flow)做的改进,而 RF(Rectified Flow)是在Flow Matching(FM)的基础上改进的,所以我们按照先后关系进行讲解,即先讲FM,再讲RF和SD3在其基础上做的优化。
原计划一篇文章讲完SD3的采样方法,但是本文讲完Flow Matching(FM),已经1.7w字,所以,RF和SD3在其基础上做的优化放在下一篇:SD3的采样下篇——Rectified Flow。下面正式开始!!!
论文
SD3论文:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
FLUX.1论文:未公开
Flow Matching论文:FLOW MATCHING FOR GENERATIVE MODELING
Rectified Flow论文:Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow 和 Rectified Flow: A Marginal Preserving Approach to Optimal Transport
推荐阅读
深入浅出完整解析Stable Diffusion 3(SD 3)和FLUX.1系列核心基础知识
文生图中从扩散模型到流匹配的演变:从SDXL到Stable Diffusion3(含Flow Matching和Rectified Flow的详解)
貌似RF原作者解读:ICLR2023扩散生成模型新方法:极度简化,一步生成
stable diffusion加噪去噪的直观解释&Rectified Flow
FLUX.1 原理与源码解析
Stable Diffusion 3 来了,深入浅出完整解析SD3的核心算法
Stable Diffusion 3震撼发布,采用Sora同源技术,文字终于不乱码了
前系列扩散回顾(DDPM)
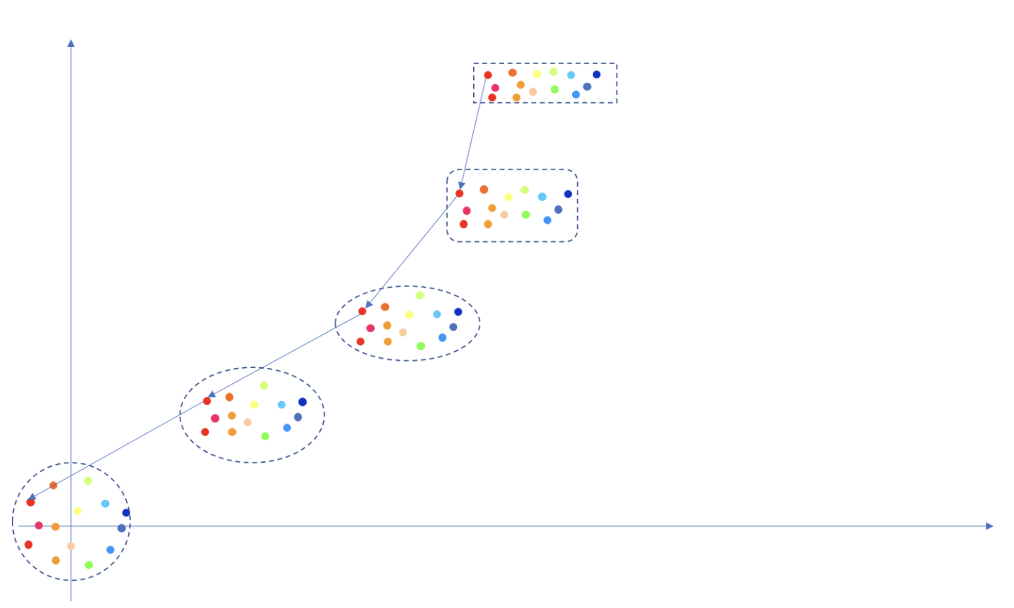
关于之前SD系列扩散模型的扩散核心采样使用DDPM、DDIM等。扩散过程本质上是多次对原始图像前向扩散(加噪),之后在训练过程中学习如何准确的预测加入的真实噪声。进而在推理过程中,对初始的随机噪声进行预测噪声,进而反向扩散(去噪),得到想要图像的过程。可以看作是一种迂回方式。扩散过程如下:

借用某乎上大佬的图(来源)来描述整个扩散过程如下:
-
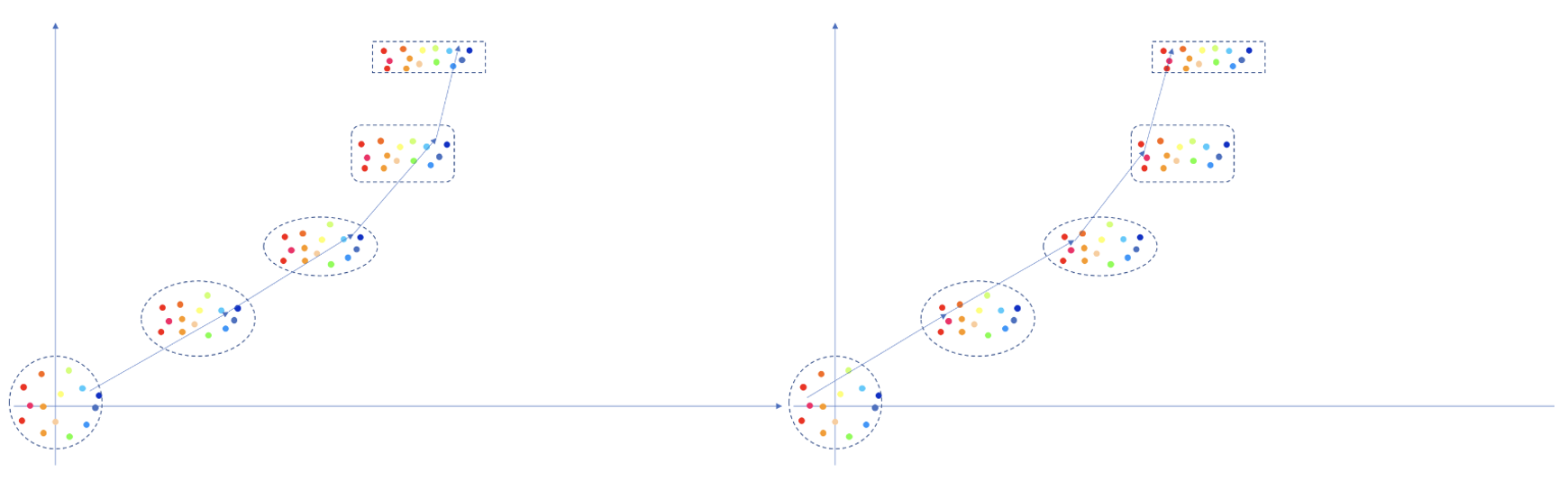
前向扩散:这里的每一个点(注意,是点,不是整个框),其实就对应于图像空间的一张图(上图中的小猫),蓝色箭头就是在不断加噪的过程,每次随机加入一定强度的噪声。一个前向传播的过程如下:
-
反向扩散:依据训练过程中学到的预测噪声能力,将预测出的噪声去除,逐步恢复图像。蓝色箭头就是在不断预测并去除噪声的过程。2个反向传播过程如下:
反向扩散不是严格的从某个点映射到某个点了。而是从高斯噪声空间随机采样一个点,然后依次往回映射。假设模型已经训练好了,这时候其实靠的就是模型的泛化能力了。假如在高斯噪声空间,你采样了个红点附近的噪声,那么模型只能保证你映射回图像的时候也在红点附近。
详细的扩散过程可以参考本系列中的历史文章:
Stable Diffusion 笔记合集 中的《Diffusion Model原理》和 《Stable Diffusion的加噪和去噪详解》。
本文结尾会给出FM的前向传播和反向传播过程,可以理解为 DDPM 是一步一步的逐步生成过程(逐步去噪),但是 FM 是一步到位的(直接通过 ODE 求解生成路径)。
Flow Matching
Flow Matching (FM) 和 Rectified Flow (RF) 是基于 概率流动 的生成建模技术。它们的核心思想是通过对初始分布(通常是高斯分布)和目标分布(如真实图像分布) 之间的 流动过程 建模,生成符合目标分布的数据样本。通过学习流场或流动路径,数据可以从易采样的初始分布逐步演化为复杂的目标分布。
- FM 从初始分布(如高斯分布)到目标分布(如真实图像分布)的流动路径中,学习一个连续的向量场 v(x,t),精确描述概率流动的变化。描述如何从初始分布逐步流动到目标分布。
- RF 对 Flow Matching 的简化和优化,假设路径为直线路径或分段线性路径,并通过梯度修正增强灵活性和效率。
这两种方法都属于基于流动路径的生成建模技术,是现代扩散模型等生成框架的重要理论基础。
Flow Matching (FM) 是一种生成建模技术,通过学习从初始分布(如高斯分布)到目标分布(如真实图像分布)的连续流动路径,描述数据的演化过程。FM 的核心是通过一个时间依赖的向量场 v ( x , t ) v(x, t) v(x,t) 建模这种流动,使得数据分布从起始状态平滑地转变为目标状态。其训练目标是通过优化损失函数,使学习到的流场 v ( x , t ) v(x, t) v(x,t) 精确匹配真实流动的梯度信息,从而确保生成样本的质量。然而,FM 的主要挑战在于复杂流场的学习和数值计算的高成本,特别是在高维数据上易导致不稳定性。
Rectified Flow (RF) 是对 Flow Matching 的简化和优化,通过假设起始分布到目标分布的流动路径为 直线路径或分段线性路径(当直线路径无法很好地描述复杂分布之间的流动时,RF 支持将路径划分为多个时间段),并引入梯度修正项 r ( x , t ) r(x, t) r(x,t),显著降低了计算复杂度并提升数值稳定性。在 RF 中,数据沿着直线路径流动,同时修正项对路径的偏差进行调整,使得生成结果更接近目标分布。RF 的这一改进减少了采样步数需求,并且在混合精度训练中表现更稳定。
与 FM 相比,RF 更适用于高分辨率生成任务和复杂模态的联合建模,如 SD 3 和 FLUX 系列模型,均采用 RF 来优化其扩散过程。
下面将详细介绍Flow Matching (FM) 和 Rectified Flow (RF)【下一节讲】 。
Flow Matching概要
首先我们先来了解一下FM的背景、核心目标、损失函数和训练生成的过程,之后再详细的解释其中的公式等。
Flow Matching(FM)是一种生成建模技术,通过学习从初始分布到目标分布的连续流动过程(流场)来生成数据。FM 的核心思想是建模分布之间的流动路径,使得输入分布“一步”演化为目标分布,同时简化了生成过程的理论框架和实现难度。
1. 背景与目标
(1) 生成模型的基本目标
在生成建模中,我们希望学习一个从初始分布 p 0 ( z ) p_0(z) p0(z) 到目标分布 p t ( z ) p_t(z) pt(z) 的映射,其中:
- 初始分布 p 0 ( z ) p_0(z) p0(z): 一个已知且易于采样的简单分布,例如标准高斯分布。
- 目标分布 p t ( z ) p_t(z) pt(z): 我们希望生成的复杂数据分布,例如自然图像、文本等。
(2) Flow Matching 的核心思想
Flow Matching 通过学习一个时间依赖的向量场 v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t),使得数据点 z z z 在时间 t ∈ [ 0 , T ] t \in [0, T] t∈[0,T] 内从初始分布演化到目标分布。这个演化过程描述了分布之间的“流动”路径。
2. Flow Matching 的数学原理
这里简单介绍下核心,后面详细介绍公式。
(1) 时间演化方程
在时间
t
t
t,数据点
z
z
z 的演化由以下方程描述:
∂
z
∂
t
=
v
Θ
(
z
,
t
)
,
\frac{\partial z}{\partial t} = v_\Theta(z, t),
∂t∂z=vΘ(z,t),
其中
v
Θ
(
z
,
t
)
v_\Theta(z, t)
vΘ(z,t) 是模型学习的流场。
(2) 损失函数的定义
为了使模型学习到的流场
v
Θ
(
z
,
t
)
v_\Theta(z, t)
vΘ(z,t) 与 真实流场
u
t
(
z
)
u_t(z)
ut(z) 一致,我们定义以下损失函数:
L
FM
=
E
t
,
p
t
(
z
)
[
∥
v
Θ
(
z
,
t
)
−
u
t
(
z
)
∥
2
]
,
\mathcal{L}_{\text{FM}} = \mathbb{E}_{t, p_t(z)} \left[ \| v_\Theta(z, t) - u_t(z) \|^2 \right],
LFM=Et,pt(z)[∥vΘ(z,t)−ut(z)∥2],
其中:
- u t ( z ) u_t(z) ut(z) 是参考路径的真实流场。
- p t ( z ) p_t(z) pt(z) 是时间 t t t 时的分布。
3. Flow Matching 的训练方法
(1) 参考路径的采样
为了训练流场 v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t),我们需要构建从初始分布 p 0 ( z ) p_0(z) p0(z) 到目标分布 p t ( z ) p_t(z) pt(z) 的参考路径。具体步骤如下:
-
采样数据点:
- 从初始分布 p 0 ( z ) p_0(z) p0(z) 中采样 z 0 z_0 z0。
- 从目标分布 p t ( z ) p_t(z) pt(z) 中采样 z t z_t zt。
-
采样时间 t t t:
- 从均匀分布 t ∼ Uniform ( 0 , T ) t \sim \text{Uniform}(0, T) t∼Uniform(0,T) 中采样时间点 t t t。
-
构建参考路径:
- 定义插值路径(例如线性插值):
z ( t ) = z 0 + t T ( z t − z 0 ) . z(t) = z_0 + \frac{t}{T}(z_t - z_0). z(t)=z0+Tt(zt−z0).
- 定义插值路径(例如线性插值):
(2) 计算真实流场
参考路径的真实流场 u t ( z ) u_t(z) ut(z) 可以通过对 z ( t ) z(t) z(t) 关于 t t t 的导数计算得到:
u t ( z ) = ∂ z ( t ) ∂ t = z t − z 0 T . u_t(z) = \frac{\partial z(t)}{\partial t} = \frac{z_t - z_0}{T}. ut(z)=∂t∂z(t)=Tzt−z0.
(3) 计算学习到的流场 v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t)
将
z
(
t
)
z(t)
z(t) 和
t
t
t 作为输入,传入神经网络模型
v
Θ
v_\Theta
vΘ:
v
Θ
(
z
,
t
)
=
NeuralNet
(
z
(
t
)
,
t
)
,
v_\Theta(z, t) = \text{NeuralNet}(z(t), t),
vΘ(z,t)=NeuralNet(z(t),t),
输出的是模型预测的流场
v
Θ
(
z
,
t
)
v_\Theta(z, t)
vΘ(z,t)。
(4) 损失函数
训练目标是使模型学习到的流场 v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t) 与 真实流场 u t ( z ) u_t(z) ut(z) 一致,我们定义以下损失函数:
L FM = E t , p t ( z ) ∥ v Θ ( z , t ) − u t ( z ) ∥ 2 2 \mathcal{L}_{\text{FM}} = \mathbb{E}_{t, p_t(z)} \| v_\Theta(z, t) - u_t(z) \|_2^2 LFM=Et,pt(z)∥vΘ(z,t)−ut(z)∥22
-
关键点:
- 这里的流场 v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t) 和 u t ( z ) u_t(z) ut(z) 是基于时间 t t t 和数据分布 p t ( z ) p_t(z) pt(z) 而定义的。
- 不涉及条件变量 ϵ \epsilon ϵ。
- 主要用于无条件生成任务,例如生成自然图像等。
-
公式解释:
- t t t: 时间变量,定义在区间 [ 0 , T ] [0, T] [0,T] 内,描述从初始分布 p 0 ( z ) p_0(z) p0(z) 到目标分布 p T ( z ) p_T(z) pT(z) 的演化。
- z z z: 数据点的位置,属于数据分布 p t ( z ) p_t(z) pt(z)。
- p t ( z ) p_t(z) pt(z): 时间 t t t 时的数据分布,描述无条件下数据的演化过程。
- v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t): 模型学习到的流场(向量场),描述 z z z 在时间 t t t 时的变化方向和速率。
- u t ( z ) u_t(z) ut(z): 真实的流场,是参考路径中 z z z 在时间 t t t 上的变化速率(通常通过插值计算)。
- ∥ ⋅ ∥ 2 2 \| \cdot \|_2^2 ∥⋅∥22: 欧几里得范数的平方,用于衡量模型流场与真实流场之间的误差。
4. 引入条件变量
在某些情况下,我们希望生成的样本满足特定的条件 ϵ \epsilon ϵ。这时,我们需要引入条件流匹配(Conditional Flow Matching, CFM),并调整上述公式。
(1) 条件分布
- 条件初始分布 p 0 ( z ∣ ϵ ) p_0(z \mid \epsilon) p0(z∣ϵ): 在条件 ϵ \epsilon ϵ 下的初始分布。
- 条件目标分布 p t ( z ∣ ϵ ) p_t(z \mid \epsilon) pt(z∣ϵ): 在条件 ϵ \epsilon ϵ 下的目标分布。
(2) 条件流场
真实流场
u
t
(
z
∣
ϵ
)
u_t(z \mid \epsilon)
ut(z∣ϵ):定义了在给定条件
ϵ
\epsilon
ϵ 下,数据点
z
z
z 应该如何流动,通常通过参考路径的导数计算得到。
注意:这里的学习流场未显式依赖于
ϵ
\epsilon
ϵ,但通过
p
t
(
z
∣
ϵ
)
p_t(z \mid \epsilon)
pt(z∣ϵ) 隐式建模条件信息。显示依赖于
ϵ
\epsilon
ϵ 的学习流场会写成
v
Θ
(
z
,
t
,
ϵ
)
v_\Theta(z, t, \epsilon)
vΘ(z,t,ϵ)
(3) 损失函数
条件流匹配的损失函数为:
CFM 的损失函数为:
L CFM = E t , p t ( z ∣ ϵ ) , p ( ϵ ) ∥ v Θ ( z , t ) − u t ( z ∣ ϵ ) ∥ 2 2 \mathcal{L}_{\text{CFM}} = \mathbb{E}_{t, p_t(z \mid \epsilon), p(\epsilon)} \| v_\Theta(z, t) - u_t(z \mid \epsilon) \|_2^2 LCFM=Et,pt(z∣ϵ),p(ϵ)∥vΘ(z,t)−ut(z∣ϵ)∥22
-
关键点:
- 这里引入了条件变量 ϵ \epsilon ϵ,使得流场 u t ( z ∣ ϵ ) u_t(z \mid \epsilon) ut(z∣ϵ) 和数据分布 p t ( z ∣ ϵ ) p_t(z \mid \epsilon) pt(z∣ϵ) 都依赖于 ϵ \epsilon ϵ。
- 条件流场 u t ( z ∣ ϵ ) u_t(z \mid \epsilon) ut(z∣ϵ) 描述了在给定条件 ϵ \epsilon ϵ 下的真实流场演化。
- 模型的学习目标是生成符合条件 ϵ \epsilon ϵ 的样本。
-
公式解释:
- t t t: 时间变量,定义在区间 [ 0 , T ] [0, T] [0,T] 内,描述从条件初始分布 p 0 ( z ∣ ϵ ) p_0(z \mid \epsilon) p0(z∣ϵ) 到条件目标分布 p T ( z ∣ ϵ ) p_T(z \mid \epsilon) pT(z∣ϵ) 的演化。
- z z z: 数据点的位置,属于条件分布 p t ( z ∣ ϵ ) p_t(z \mid \epsilon) pt(z∣ϵ)。
- ϵ \epsilon ϵ: 条件变量,描述外部的控制信号或生成任务的特定条件,例如文本描述或类别标签。
- p t ( z ∣ ϵ ) p_t(z \mid \epsilon) pt(z∣ϵ): 时间 t t t 时,在条件 ϵ \epsilon ϵ 下的数据分布。
- p ( ϵ ) p(\epsilon) p(ϵ): 条件变量的分布,描述不同条件的概率分布。
- v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t): 模型学习到的流场,描述 z z z 在时间 t t t 时的变化方向和速率。注意:这里的流场未显式依赖于 ϵ \epsilon ϵ,但通过 p t ( z ∣ ϵ ) p_t(z \mid \epsilon) pt(z∣ϵ) 隐式建模条件信息。显示的会写成 v Θ ( z , t , ϵ ) v_\Theta(z, t, \epsilon) vΘ(z,t,ϵ)
- u t ( z ∣ ϵ ) u_t(z \mid \epsilon) ut(z∣ϵ): 条件下的真实流场,是条件参考路径中 z z z 在时间 t t t 上的变化速率(通过条件插值路径计算)。
- ∥ ⋅ ∥ 2 2 \| \cdot \|_2^2 ∥⋅∥22: 欧几里得范数的平方,用于衡量模型流场与条件真实流场之间的误差。
-
是否包含 ϵ \epsilon ϵ: 取决于实现设计。
- 显式依赖: v Θ ( z , t , ϵ ) v_\Theta(z, t, \epsilon) vΘ(z,t,ϵ),条件直接作为输入。
- 隐式依赖: v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t),条件通过分布 p t ( z ∣ ϵ ) p_t(z \mid \epsilon) pt(z∣ϵ) 传递。
如果是显式依赖
ϵ
\epsilon
ϵ,则CFM 的损失函数可以写为:
L
CFM
=
E
t
,
p
t
(
z
∣
ϵ
)
,
p
(
ϵ
)
[
∥
v
Θ
(
z
,
t
,
ϵ
)
−
u
t
(
z
∣
ϵ
)
∥
2
]
.
\mathcal{L}_{\text{CFM}} = \mathbb{E}_{t, p_t(z \mid \epsilon), p(\epsilon)} \left[ \| v_\Theta(z, t, \epsilon) - u_t(z \mid \epsilon) \|^2 \right].
LCFM=Et,pt(z∣ϵ),p(ϵ)[∥vΘ(z,t,ϵ)−ut(z∣ϵ)∥2].
说明:因为我们主要讨论的是SD3 模型中的FM,所以后面的训练和推理过程讨论主要针对CFM,即加入条件变量的FM(文生图中的文本条件)。
5. 训练与生成过程
(1) 训练阶段
1.采样条件 ϵ \epsilon ϵ:
- 从 p ( ϵ ) p(\epsilon) p(ϵ) 中采样条件 ϵ \epsilon ϵ。
2.采样数据点:
- 从 p 0 ( z ∣ ϵ ) p_0(z \mid \epsilon) p0(z∣ϵ) 中采样初始数据点 z 0 z_0 z0。
- 从 p t ( z ∣ ϵ ) p_t(z \mid \epsilon) pt(z∣ϵ) 中采样目标数据点 z t z_t zt。
3.采样时间 t t t:
- 从均匀分布 t ∼ Uniform ( 0 , T ) t \sim \text{Uniform}(0, T) t∼Uniform(0,T) 中采样时间点 t t t。
4.计算参考路径和真实流场:
- 构建参考路径:
z ( t ) = z 0 + t T ( z t − z 0 ) . z(t) = z_0 + \frac{t}{T}(z_t - z_0). z(t)=z0+Tt(zt−z0). - 计算真实流场:
u t ( z ∣ ϵ ) = ∂ z ( t ) ∂ t = z t − z 0 T . u_t(z \mid \epsilon) = \frac{\partial z(t)}{\partial t} = \frac{z_t - z_0}{T}. ut(z∣ϵ)=∂t∂z(t)=Tzt−z0.
5.计算学习到的流场 v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t)
- 将
z
(
t
)
z(t)
z(t) 和
t
t
t 作为输入,传入神经网络模型
v
Θ
v_\Theta
vΘ:
v Θ ( z , t ) = NeuralNet ( z ( t ) , t ) , v_\Theta(z, t) = \text{NeuralNet}(z(t), t), vΘ(z,t)=NeuralNet(z(t),t),- 输出的是模型预测的流场 v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t)。
6.最小化损失函数:
- 使用损失函数:
L CFM = E t , p t ( z ∣ ϵ ) , p ( ϵ ) ∥ v Θ ( z , t ) − u t ( z ∣ ϵ ) ∥ 2 . \mathcal{L}_{\text{CFM}} = \mathbb{E}_{t, p_t(z \mid \epsilon), p(\epsilon)}\|v_\Theta(z, t) - u_t(z \mid \epsilon)\|^2. LCFM=Et,pt(z∣ϵ),p(ϵ)∥vΘ(z,t)−ut(z∣ϵ)∥2.- 通过梯度下降优化模型参数 Θ \Theta Θ。
7.梯度计算:
- 对损失函数
L
CFM
\mathcal{L}_{\text{CFM}}
LCFM 关于模型参数
Θ
\Theta
Θ 的梯度:
∇ Θ L CFM = ∂ L CFM ∂ Θ , \nabla_\Theta \mathcal{L}_{\text{CFM}} = \frac{\partial \mathcal{L}_{\text{CFM}}}{\partial \Theta}, ∇ΘLCFM=∂Θ∂LCFM,- 需要使用反向传播自动计算。
8.参数更新:
- 使用优化算法(如 SGD 或 Adam),通过梯度下降更新参数:
Θ ← Θ − η ∇ Θ L CFM , \Theta \gets \Theta - \eta \nabla_\Theta \mathcal{L}_{\text{CFM}}, Θ←Θ−η∇ΘLCFM,- 其中 η \eta η 是学习率。
(2) 生成阶段
1.采样条件 ϵ \epsilon ϵ:
- 从 p ( ϵ ) p(\epsilon) p(ϵ) 中选择或指定条件 ϵ \epsilon ϵ。
2.采样初始数据点:
- 从条件初始分布 p 0 ( z ∣ ϵ ) p_0(z \mid \epsilon) p0(z∣ϵ) 中采样 z 0 z_0 z0。通常, p 0 ( z ∣ ϵ ) p_0(z \mid \epsilon) p0(z∣ϵ) 是一个简单的分布(如条件独立的高斯分布)。
3.时间演化:
-
描述流场的两种情况:
- 显式流场: v Θ ( z , t , ϵ ) v_\Theta(z, t, \epsilon) vΘ(z,t,ϵ),直接依赖条件 ϵ \epsilon ϵ。
- 隐式流场: v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t),条件 ϵ \epsilon ϵ 被隐式建模(通过目标分布的特性传递)。
-
通过微分方程演化(时间演化的具体实现方式):
- 使用微分方程(从初始点
z
0
z_0
z0 开始,演化到时间
t
=
T
t = T
t=T时候的生成样本
z
t
z_t
zt):
∂ z ∂ t = v Θ ( z , t , ϵ ) 或 ∂ z ∂ t = v Θ ( z , t ) , \frac{\partial z}{\partial t} = v_\Theta(z, t, \epsilon) \quad \text{或} \quad \frac{\partial z}{\partial t} = v_\Theta(z, t), ∂t∂z=vΘ(z,t,ϵ)或∂t∂z=vΘ(z,t),
- 使用微分方程(从初始点
z
0
z_0
z0 开始,演化到时间
t
=
T
t = T
t=T时候的生成样本
z
t
z_t
zt):
由于学习流场通常是通过神经网络建模的,无法解析计算积分。因此,求解上述微分方程需要 数值方法,主要包括 欧拉法 和 Runge-Kutta (RK4)方法。
1.时间步长 Δ t \Delta t Δt 的选择:
- 太大会导致不准确,太小则增加计算成本。
- 经验上, Δ t \Delta t Δt 需通过实验调整以平衡精度和效率。
2.方法选择:
- 欧拉法适合快速实验和初步测试,但精度可能不足。
- RK4 方法更适合高质量生成,尤其是在生成复杂分布时。
欧拉法
欧拉法是一种简单的时间离散方法。对于每一步 k k k: z k + 1 = z k + Δ t ⋅ v Θ ( z k , t k , ϵ ) , z_{k+1} = z_k + \Delta t \cdot v_\Theta(z_k, t_k, \epsilon), zk+1=zk+Δt⋅vΘ(zk,tk,ϵ), 其中:
- z k z_k zk:第 k k k 步时的数据点位置。
- t k = k ⋅ Δ t t_k = k \cdot \Delta t tk=k⋅Δt:当前时间。
- Δ t \Delta t Δt:时间步长。
欧拉法的优点是简单易实现,但精度较低,适合初步实验。
Runge-Kutta 方法
Runge-Kutta 方法(如 RK4)是更高阶的数值积分方法,具有更高的精度。以下是 RK4 的公式对于每一步 k k k:1.计算中间变量: k 1 = Δ t ⋅ v Θ ( z k , t k , ϵ ) , k_1 = \Delta t \cdot v_\Theta(z_k, t_k, \epsilon), k1=Δt⋅vΘ(zk,tk,ϵ), k 2 = Δ t ⋅ v Θ ( z k + k 1 2 , t k + Δ t 2 , ϵ ) , k_2 = \Delta t \cdot v_\Theta(z_k + \frac{k_1}{2}, t_k + \frac{\Delta t}{2}, \epsilon), k2=Δt⋅vΘ(zk+2k1,tk+2Δt,ϵ), k 3 = Δ t ⋅ v Θ ( z k + k 2 2 , t k + Δ t 2 , ϵ ) , k_3 = \Delta t \cdot v_\Theta(z_k + \frac{k_2}{2}, t_k + \frac{\Delta t}{2}, \epsilon), k3=Δt⋅vΘ(zk+2k2,tk+2Δt,ϵ),
k 4 = Δ t ⋅ v Θ ( z k + k 3 , t k + Δ t , ϵ ) . k_4 = \Delta t \cdot v_\Theta(z_k + k_3, t_k + \Delta t, \epsilon). k4=Δt⋅vΘ(zk+k3,tk+Δt,ϵ).2.更新位置: z k + 1 = z k + 1 6 ( k 1 + 2 k 2 + 2 k 3 + k 4 ) . z_{k+1} = z_k + \frac{1}{6}(k_1 + 2k_2 + 2k_3 + k_4). zk+1=zk+61(k1+2k2+2k3+k4).
RK4 方法在每一步中需要多次评估流场 v Θ v_\Theta vΘ,计算量更大,但精度更高,适合对生成结果要求较高的场景。
- 获取生成样本:
- 最终的 z t z_t zt 就是符合条件 ϵ \epsilon ϵ 的生成样本。
6. 总结
Flow Matching 技术通过学习一个时间依赖的流场 v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t),实现了从初始分布到目标分布的连续映射。在条件流匹配(CFM)中,进一步引入了条件变量 ϵ \epsilon ϵ,使得生成模型可以在给定条件下生成样本。损失函数 L CFM \mathcal{L}_{\text{CFM}} LCFM 用于衡量模型学习到的流场与真实流场之间的差异,通过最小化该损失函数来训练模型。
Flow Matching公式
下面主要讲解 Flow Matching 在SD3论文:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis 中的公式和推导过程。
1. Flow Matching 的基本概念
目标
希望从噪声分布
p
1
(
x
)
p_1(x)
p1(x)(如高斯分布)到数据分布
p
0
(
x
)
p_0(x)
p0(x) 映射样本,通过定义一个常微分方程(ODE)描述流动过程:
d
y
t
d
t
=
v
Θ
(
y
t
,
t
)
,
\frac{dy_t}{dt} = v_\Theta(y_t, t),
dtdyt=vΘ(yt,t),
- y t y_t yt:在时间 t t t 时的样本状态。描述了从 p 1 ( x ) p_1(x) p1(x) 到 p 0 ( x ) p_0(x) p0(x) 的概率路径。【等同于后续出现的 z t z_t zt】
-
v
Θ
(
y
t
,
t
)
v_\Theta(y_t, t)
vΘ(yt,t):流动向量场,表示在时间
t
t
t 上样本
y
t
y_t
yt 移动的速度。由神经网络参数化,
Θ
\Theta
Θ 是神经网络的参数。
- 作用:控制数据在时间上的变化方向,是整个流动模型的核心。
- Θ \Theta Θ:神经网络的参数,通过训练学习到最优值。
-
t
t
t:时间变量,取值范围为
t
∈
[
0
,
1
]
t \in [0, 1]
t∈[0,1]:
- t = 0 t = 0 t=0:对应起始分布 p 0 ( x ) p_0(x) p0(x)(通常是数据分布)。
- t = 1 t = 1 t=1:对应目标分布 p 1 ( x ) p_1(x) p1(x)(通常是标准正态分布 N ( 0 , I ) \mathcal{N}(0, I) N(0,I))。

直接求解微分方程的问题
直接通过微分求解(如 Chen 等人在 2018 年提出的神经 ODE 方法)计算生成路径,计算成本非常高,尤其在处理高维数据时,需要大量的计算资源。
引入向量场 u t u_t ut
Flow Matching 不再直接求解微分方程,而是引入一个向量场 u t u_t ut,通过对概率路径建模,生成从 p 1 p_1 p1 到 p 0 p_0 p0 的平滑转换。我们就可以用ODE的常用求解器(欧拉方法,K4等)实现从一个高斯噪声到真实数据的生成。
此处(SD3论文)描述的是反向扩散(去除噪声,恢复图像的流程)从 p 1 p_1 p1 到 p 0 p_0 p0 。如下图:

原始FM论文中的定义是与之相反,是从 p 0 p_0 p0 到 p 1 p_1 p1的。如下图:

2. 正向过程中的定义
这个过程类似于扩散模型中的正向扩散(加噪) 过程。它描述了从数据分布 p 0 ( x ) p_0(x) p0(x)(通常是目标分布)到噪声分布 p 1 ( x ) p_1(x) p1(x)(通常是标准正态分布 N ( 0 , I ) \mathcal{N}(0, I) N(0,I) )的过渡。
定义概率路径
为构造概率路径
p
t
p_t
pt,前向过程
z
t
z_t
zt定义:
z
t
=
a
t
x
0
+
b
t
ϵ
,
ϵ
∼
N
(
0
,
I
)
,
z_t = a_t x_0 + b_t \epsilon, \quad \epsilon \sim \mathcal{N}(0, I),
zt=atx0+btϵ,ϵ∼N(0,I),
- z t z_t zt:在时间 t t t 上的中间状态样本(从起始样本 x 0 x_0 x0 和噪声 ϵ \epsilon ϵ 线性插值生成)。
- x 0 x_0 x0:来自起始分布 p 0 ( x ) p_0(x) p0(x) 的样本(通常是数据样本)。
- ϵ \epsilon ϵ:独立采样的标准高斯噪声, ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I)。
-
a
t
,
b
t
a_t, b_t
at,bt:控制数据样本和噪声贡献的权重系数。它们是时间
t
t
t 的函数:
- a t a_t at:表示数据分布在 t t t 时的贡献权重。
- b t b_t bt:表示噪声分布在 t t t 时的贡献权重。
样本 z t z_t zt 是从数据分布 p 0 p_0 p0 到噪声分布 p 1 p_1 p1 的路径 p t p_t pt,是一个
曲线。此过程受权重 a t a_t at 和 b t b_t bt 控制,其中 a t a_t at 和 b t b_t bt 是时间 t t t 的非线性函数。非线性的 a t a_t at 和 b t b_t bt 会导致路径为曲线,而不是简单的直线。
边界条件
-
当 t = 0 t = 0 t=0 时:
a 0 = 1 , b 0 = 0 , z 0 = x 0 ∼ p 0 ( x ) . a_0 = 1, \quad b_0 = 0, \quad z_0 = x_0 \sim p_0(x). a0=1,b0=0,z0=x0∼p0(x).- 样本完全来自数据分布,噪声无贡献。
-
当 t = 1 t = 1 t=1 时:
a 1 = 0 , b 1 = 1 , z 1 = ϵ ∼ N ( 0 , I ) 或者 p 1 . a_1 = 0, \quad b_1 = 1, \quad z_1 = \epsilon \sim \mathcal{N}(0, I)或者p_1. a1=0,b1=1,z1=ϵ∼N(0,I)或者p1.- 样本完全来自噪声分布。
3. 条件向量场
定义条件向量场
u t ( z ∣ ϵ ) : = ∂ ∂ t ψ t ( ψ t − 1 ( z ∣ ϵ ) ∣ ϵ ) , u_t(z \mid \epsilon) := \frac{\partial}{\partial t} \psi_t(\psi_t^{-1}(z \mid \epsilon) \mid \epsilon), ut(z∣ϵ):=∂t∂ψt(ψt−1(z∣ϵ)∣ϵ),
-
u
t
(
z
∣
ϵ
)
u_t(z \mid \epsilon)
ut(z∣ϵ):在给定噪声条件
ϵ
\epsilon
ϵ 下的向量场。
- 作用:描述样本 z t z_t zt 在时间 t t t 上的运动速率。
-
ψ
t
\psi_t
ψt:从
x
0
x_0
x0 到
z
t
z_t
zt 的映射函数:
ψ t ( x 0 ∣ ϵ ) = a t x 0 + b t ϵ . \psi_t(x_0 \mid \epsilon) = a_t x_0 + b_t \epsilon. ψt(x0∣ϵ)=atx0+btϵ.- 作用:通过 a t a_t at 和 b t b_t bt 的权重组合,构建从数据到噪声的过渡路径。
向量场具体表达式
u t ( z t ∣ ϵ ) = a t ′ a t z t − ϵ b t ( a t ′ a t − b t ′ b t ) u_t(z_t \mid \epsilon) = \frac{a_t'}{a_t} z_t - \epsilon b_t \left( \frac{a_t'}{a_t} - \frac{b_t'}{b_t} \right) ut(zt∣ϵ)=atat′zt−ϵbt(atat′−btbt′)
-
a
t
′
a
t
,
b
t
′
b
t
\frac{a_t'}{a_t}, \frac{b_t'}{b_t}
atat′,btbt′:描述
a
t
,
b
t
a_t, b_t
at,bt 的时间变化速率。
- a t ′ , b t ′ a_t', b_t' at′,bt′ 是相对于时间 t t t 的导数。
- 第一项 a t ′ a t z t \frac{a_t'}{a_t} z_t atat′zt:描述样本 本身的变化速度。
- 第二项 − ϵ b t ( a t ′ a t − b t ′ b t ) -\epsilon b_t \left(\frac{a_t'}{a_t} - \frac{b_t'}{b_t}\right) −ϵbt(atat′−btbt′):描述噪声在样本中的动态变化。
4. 信噪比(SNR) λ t ′ \lambda_t' λt′的重新参数化
为了进一步简化,定义信噪比(Signal-to-Noise Ratio,
λ
t
\lambda_t
λt):
λ
t
:
=
log
(
a
t
2
b
t
2
)
,
\lambda_t := \log\left(\frac{a_t^2}{b_t^2}\right),
λt:=log(bt2at2),
-
λ
t
\lambda_t
λt:衡量信号(数据)与噪声的比例。
- 当 t → 0 t \to 0 t→0:信号占主导, λ t → ∞ \lambda_t \to \infty λt→∞。
- 当 t → 1 t \to 1 t→1:噪声占主导, λ t → − ∞ \lambda_t \to -\infty λt→−∞。
- 导数
λ
t
′
\lambda_t'
λt′:
λ t ′ = 2 ( a t ′ a t − b t ′ b t ) . \lambda_t' = 2\left(\frac{a_t'}{a_t} - \frac{b_t'}{b_t}\right). λt′=2(atat′−btbt′).
引入信噪比后,向量场可以重写为:
u t ( z t ∣ ϵ ) = a t ′ a t z t − b t 2 λ t ′ ϵ . u_t(z_t \mid \epsilon) = \frac{a_t'}{a_t} z_t - \frac{b_t}{2} \lambda_t' \epsilon. ut(zt∣ϵ)=atat′zt−2btλt′ϵ.- 第一项 a t ′ a t z t \frac{a_t'}{a_t} z_t atat′zt:表示数据部分的贡献。
- 第二项 − b t 2 λ t ′ ϵ -\frac{b_t}{2} \lambda_t' \epsilon −2btλt′ϵ:表示噪声部分的贡献。
5. 原始 Flow Matching 损失函数定义
L FM = E t , p t ( z ) ∥ v Θ ( z , t ) − u t ( z ) ∥ 2 2 \mathcal{L}_{\text{FM}} = \mathbb{E}_{t, p_t(z)}\|v_\Theta(z, t) - u_t(z)\|_2^2 LFM=Et,pt(z)∥vΘ(z,t)−ut(z)∥22
- L FM \mathcal{L}_{\text{FM}} LFM:衡量学习到的速度场 v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t) 与真实速度场 u t ( z ) u_t(z) ut(z) 的差异。
6. 原始条件化损失函数定义
(1) 条件化损失
为解决边缘化的难点(最后详细介绍),将损失重写为条件化形式:
L
CFM
=
E
t
,
p
t
(
z
∣
ϵ
)
,
p
(
ϵ
)
∥
v
Θ
(
z
,
t
)
−
u
t
(
z
∣
ϵ
)
∥
2
2
\mathcal{L}_{\text{CFM}} = \mathbb{E}_{t, p_t(z \mid \epsilon), p(\epsilon)}\|v_\Theta(z, t) - u_t(z \mid \epsilon)\|_2^2
LCFM=Et,pt(z∣ϵ),p(ϵ)∥vΘ(z,t)−ut(z∣ϵ)∥22
- 条件化损失的优点:
- 通过引入噪声条件 ϵ \epsilon ϵ,消除了对边缘分布 p t ( z ) p_t(z) pt(z) 的直接依赖,更易计算。
(2) 噪声预测目标
最终,将损失转换为噪声预测形式:
L
CFM
=
E
t
,
p
t
(
z
∣
ϵ
)
,
p
(
ϵ
)
(
−
b
t
2
λ
t
′
∥
ϵ
Θ
(
z
,
t
)
−
ϵ
∥
2
)
,
\mathcal{L}_{\text{CFM}} = \mathbb{E}_{t, p_t(z \mid \epsilon), p(\epsilon)}\left(-\frac{b_t}{2} \lambda_t' \|\epsilon_\Theta(z,t) - \epsilon\|^2\right),
LCFM=Et,pt(z∣ϵ),p(ϵ)(−2btλt′∥ϵΘ(z,t)−ϵ∥2),
- ϵ Θ \epsilon_\Theta ϵΘ:神经网络的噪声预测目标,定义为:
ϵ Θ : = − 2 λ t ′ b t ( v Θ − a t ′ a t z ) . \epsilon_\Theta := \frac{-2}{\lambda_t' b_t} \left(v_\Theta - \frac{a_t'}{a_t} z\right). ϵΘ:=λt′bt−2(vΘ−atat′z).
变量解析:
-
ϵ Θ \epsilon_\Theta ϵΘ:
- 这是神经网络预测的噪声目标,用于与真实噪声 ϵ \epsilon ϵ 进行比较。
- 这个量将 ( v Θ , z ) (v_\Theta, z) (vΘ,z) 的关系转化为扩散模型中的标准噪声预测任务。
-
− 2 λ t ′ b t -\frac{2}{\lambda_t' b_t} −λt′bt2:
- 这是一个缩放因子,取决于时间相关的信噪比导数 λ t ′ \lambda_t' λt′ 和权重系数 b t b_t bt。
- 确保噪声预测任务在优化过程中数值稳定。
-
( v Θ − a t ′ a t z ) (v_\Theta - \frac{a_t'}{a_t} z) (vΘ−atat′z):
- 这里表示神经网络预测的速度场 v Θ v_\Theta vΘ 减去通过 a t ′ a t z \frac{a_t'}{a_t} z atat′z 计算的线性项。
- 这部分是为了将速度场预测转化为噪声预测任务,使模型更容易优化。
-
z z z
- 在时间 t t t 上的状态变量(中间样本),描述了从噪声分布 p 1 ( x ) p_1(x) p1(x) 到数据分布 p 0 ( x ) p_0(x) p0(x) 的过渡路径。
7. 权重项与统一目标
为了统一分析,包括经典扩散模型在内的各种目标形式,损失函数可以进一步写成:
进一步引入时间依赖权重
w
t
w_t
wt:
L
w
(
x
0
)
=
−
1
2
E
t
∼
U
(
t
)
,
ϵ
∼
N
(
0
,
I
)
[
w
t
λ
t
′
∥
ϵ
Θ
(
z
t
,
t
)
−
ϵ
∥
2
]
,
\mathcal{L}_w(x_0) = -\frac{1}{2} \mathbb{E}_{t \sim \mathcal{U}(t), \epsilon \sim \mathcal{N}(0, I)} \left[ w_t \lambda_t' \| \epsilon_\Theta(z_t, t) - \epsilon \|^2 \right],
Lw(x0)=−21Et∼U(t),ϵ∼N(0,I)[wtλt′∥ϵΘ(zt,t)−ϵ∥2],
这是加权损失函数,用于生成模型中的流匹配优化目标,旨在通过引入时间和噪声的动态权重 w t w_t wt 来改善优化路径。
参数解释
-
L w ( x 0 ) \mathcal{L}_w(x_0) Lw(x0):
- 整体损失函数,作用是最小化模型 ϵ Θ ( z t , t ) \epsilon_\Theta(z_t, t) ϵΘ(zt,t) 预测的噪声与实际噪声 ϵ \epsilon ϵ 之间的误差。
- 优化目标在时间 t t t 和噪声 ϵ \epsilon ϵ 的分布下进行。
-
t ∼ U ( t ) t \sim \mathcal{U}(t) t∼U(t):
- 时间 t t t 的分布,假设均匀分布( U \mathcal{U} U 表示均匀分布)。
- 时间 t t t 控制 z t z_t zt 在数据分布和噪声分布之间的插值程度。
-
ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I):
- 噪声 ϵ \epsilon ϵ 的分布,假设服从零均值单位协方差的标准正态分布。
- 用于前向过程 z t = a t x 0 + b t ϵ z_t = a_t x_0 + b_t \epsilon zt=atx0+btϵ 中的噪声注入。
-
w t w_t wt:
- 时间依赖的权重函数,控制优化过程中不同时间点的贡献。例如,当 w t = − 1 2 λ t b t 2 w_t = -\frac{1}{2} \lambda_t b_t^2 wt=−21λtbt2 时,损失函数等价于 L C F M \mathcal{L}_{CFM} LCFM。
- 不同的权重选择可以影响生成模型的性能和生成路径的平滑性。
-
λ t ′ \lambda_t' λt′:
- 信噪比的时间导数,定义为:
λ t ′ = 2 ( a t ′ a t − b t ′ b t ) , \lambda_t' = 2 \left( \frac{a_t'}{a_t} - \frac{b_t'}{b_t} \right), λt′=2(atat′−btbt′),
其中 a t , b t a_t, b_t at,bt 是控制数据和噪声分量的插值系数。 - 信噪比导数描述了时间 t t t 上数据与噪声的比例变化。
- 信噪比的时间导数,定义为:
-
ϵ Θ ( z t , t ) \epsilon_\Theta(z_t, t) ϵΘ(zt,t):
- 模型 Θ \Theta Θ 的输出,用于预测前向过程中加入的噪声 ϵ \epsilon ϵ。
- 表达式为:
ϵ Θ ( z t , t ) = − 2 λ t b t ( v Θ ( z t , t ) − a t ′ a t z t ) , \epsilon_\Theta(z_t, t) = \frac{-2}{\lambda_t b_t} \left( v_\Theta(z_t, t) - \frac{a_t'}{a_t} z_t \right), ϵΘ(zt,t)=λtbt−2(vΘ(zt,t)−atat′zt),
其中 v Θ v_\Theta vΘ 是模型拟合的速度场。
-
ϵ \epsilon ϵ:
- 前向过程中实际加入的噪声。
- 优化的目标是让 ϵ Θ ( z t , t ) \epsilon_\Theta(z_t, t) ϵΘ(zt,t) 尽可能接近实际的噪声 ϵ \epsilon ϵ。
-
∥ ϵ Θ ( z t , t ) − ϵ ∥ 2 \| \epsilon_\Theta(z_t, t) - \epsilon \|^2 ∥ϵΘ(zt,t)−ϵ∥2:
- 预测噪声与真实噪声之间的二次误差。
- 是损失函数的核心项,衡量预测和真实值之间的差距。
上面的步骤是完全按照论文中的公式进行讲解的,可以照着SD3论文:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis,进行详细的阅读,如果觉得难以将这些步骤串起来,可以先读懂每个公式,之后按照1 2 5 3 4 6 7 的顺序进行梳理【个人认为这个顺序好理解】,参考此文尝试再次理解。
Q&A
FM和CFM损失函数
论文中提到将FM损失函数写成CFM是为解决边缘化的难点(Flow Matching objective directly is intractable due to the marginalization)。
1. Flow Matching (FM) 的问题
-
FM 的目标函数是:
L F M = E t , p t ( z ) ∥ v Θ ( z , t ) − u t ( z ) ∥ 2 2 , \mathcal{L}_{FM} = \mathbb{E}_{t, p_t(z)} \| v_\Theta(z, t) - u_t(z) \|^2_2, LFM=Et,pt(z)∥vΘ(z,t)−ut(z)∥22,
其中:- v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t) 是神经网络预测的向量场;
- u t ( z ) u_t(z) ut(z) 是目标向量场,描述了从分布 p 1 p_1 p1 到 p 0 p_0 p0 的时间演化。
-
直接优化的困难:
- p t ( z ) p_t(z) pt(z) 是一个边际分布(边际化计算的难度,直接使用它通常不现实),表示在时间 t t t 时的样本分布。
- 计算
p
t
(
z
)
p_t(z)
pt(z) 需要对噪声变量
ϵ
\epsilon
ϵ 积分:
p t ( z ) = E ϵ ∼ N ( 0 , I ) [ p t ( z ∣ ϵ ) ] . p_t(z) = \mathbb{E}_{\epsilon \sim \mathcal{N}(0, I)}[p_t(z \mid \epsilon)]. pt(z)=Eϵ∼N(0,I)[pt(z∣ϵ)].
这个积分在高维数据中是非常难以解析计算的。
2. Conditional Flow Matching (CFM) 的改进
在 FM 中, u t ( z ) u_t(z) ut(z) 是一个边际向量场,其计算依赖于整个数据分布的联合信息,而在高维空间中估计这个向量场非常困难。
CFM 的解决方案:
- 定义条件向量场 u t ( z ∣ ϵ ) u_t(z \mid \epsilon) ut(z∣ϵ),它明确依赖于噪声变量 ϵ \epsilon ϵ。
- CFM 引入了条件分布 p t ( z ∣ ϵ ) p_t(z \mid \epsilon) pt(z∣ϵ),将原本边际分布中的积分直接展开为条件概率形式,从而简化优化目标。
CFM 的目标函数是:
L C F M = E t , p t ( z ∣ ϵ ) , p ( ϵ ) ∥ v Θ ( z , t ) − u t ( z ∣ ϵ ) ∥ 2 2 , \mathcal{L}_{CFM} = \mathbb{E}_{t, p_t(z \mid \epsilon), p(\epsilon)} \| v_\Theta(z, t) - u_t(z \mid \epsilon) \|^2_2, LCFM=Et,pt(z∣ϵ),p(ϵ)∥vΘ(z,t)−ut(z∣ϵ)∥22,
-
改进点:
- 直接在条件分布 p t ( z ∣ ϵ ) p_t(z \mid \epsilon) pt(z∣ϵ) 下优化,避免了计算边际分布 p t ( z ) p_t(z) pt(z) 的复杂性。
- 条件分布 p t ( z ∣ ϵ ) p_t(z \mid \epsilon) pt(z∣ϵ) 是通过前向过程 z t = a t x 0 + b t ϵ z_t = a_t x_0 + b_t \epsilon zt=atx0+btϵ 明确定义的,因此易于采样。
-
数学优势:
- 边际化问题通过条件分布展开变得可计算。
- 训练过程直接依赖于噪声 ϵ \epsilon ϵ 的采样,减少了计算复杂度。
FM的扩散
这里改编某乎上大佬的图(来源)来描述整个扩散过程如下:
1. 前向扩散
如下图红色箭头:
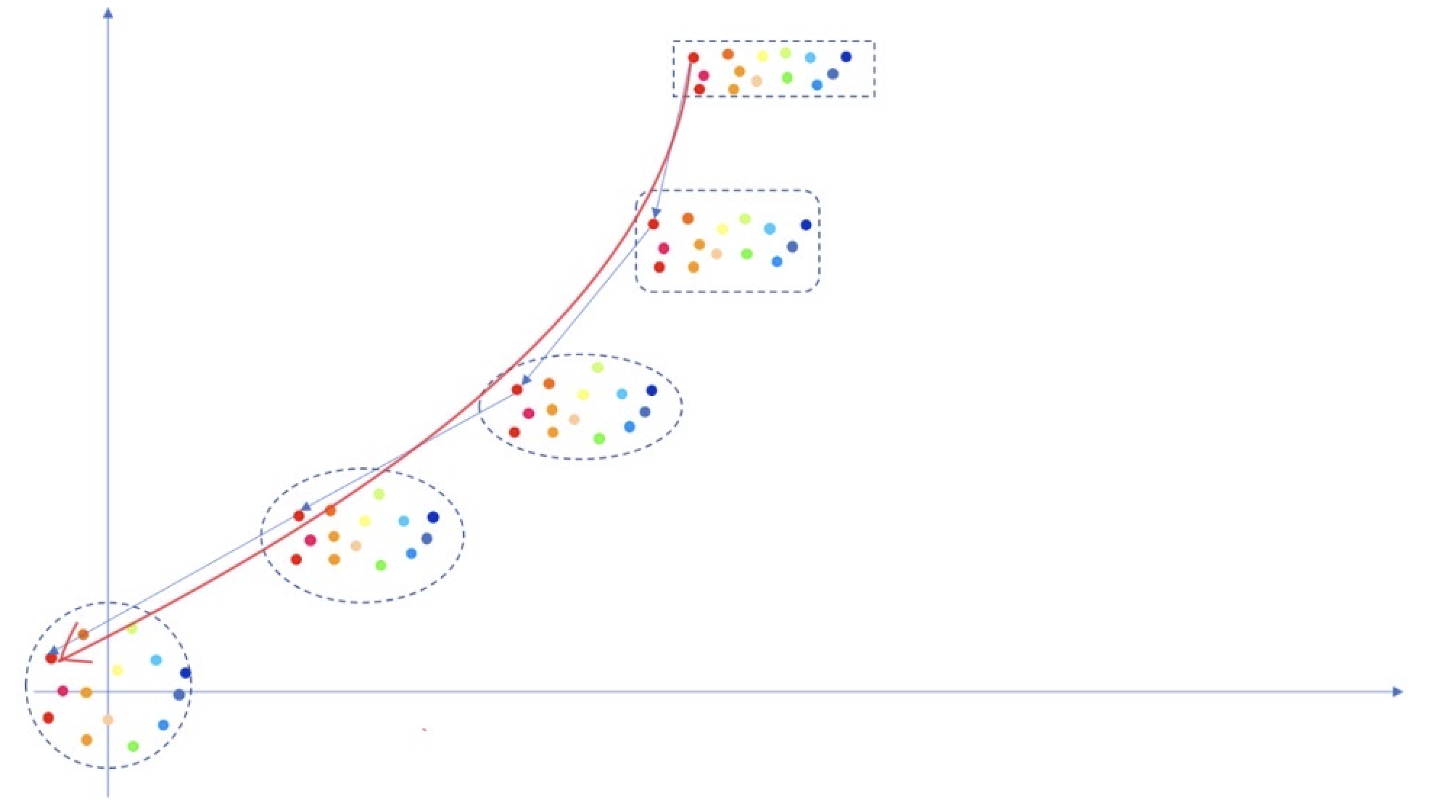
样本
z
t
z_t
zt 是从数据分布
p
0
p_0
p0 到噪声分布
p
1
p_1
p1 的路径
p
t
p_t
pt,路径通常是曲线,由时间
t
∈
[
0
,
1
]
t \in [0, 1]
t∈[0,1] 和插值参数
a
t
,
b
t
a_t, b_t
at,bt 控制的。这个过程是基于公式:
z
t
=
a
t
x
0
+
b
t
ϵ
,
ϵ
∼
N
(
0
,
I
)
,
z_t = a_t x_0 + b_t \epsilon, \quad \epsilon \sim \mathcal{N}(0, I),
zt=atx0+btϵ,ϵ∼N(0,I),
其中
x
0
∼
p
0
x_0 \sim p_0
x0∼p0,即从目标数据分布中采样的样本。
- 红色箭头表示的曲线路径确实符合 z t z_t zt 的概率流从 p 0 p_0 p0 到 p 1 p_1 p1 的行为。
- “一步到位” 在这里是指,整个前向扩散路径是连续的,由 a t , b t a_t, b_t at,bt 的变化定义,不需要离散的逐步加噪(比如 DDPM 中的逐步噪声添加)。
补充说明
前向扩散是一个固定的物理过程,其核心目标是生成一个平滑的理论路径
p
t
(
z
t
)
p_t(z_t)
pt(zt),这个路径并不直接参与优化,而是为训练模型的向量场
v
Θ
v_\Theta
vΘ 提供参考。
2. 反向扩散
如下图红色箭头:
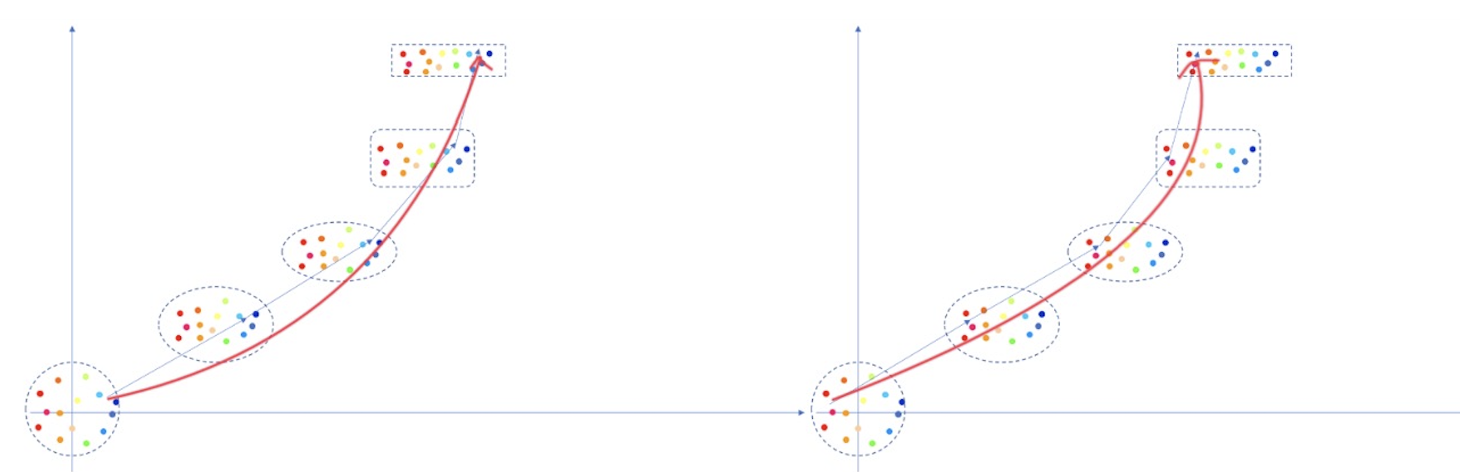
- 学到的向量场 v Θ ( z , t ) v_\Theta(z, t) vΘ(z,t) 控制从噪声分布 p 1 p_1 p1 到数据分布 p 0 p_0 p0 的概率路径。
- 通过 ODE 反向积分,可以沿着学到的路径一步到位恢复图像。
补充:
- 反向过程并非真的“一步完成”,而是利用连续的微分方程描述路径,并通过 ODE 解算器逐步逼近生成结果。
- ODE 解算器(如 Runge-Kutta 方法)会在离散的时间步中计算积分,但相比 DDPM 的数百步去噪,FM 的反向过程所需的离散步数远少得多。
反向扩散公式为:
d
z
t
d
t
=
v
Θ
(
z
t
,
t
)
\frac{dz_t}{dt} = v_\Theta(z_t, t)
dtdzt=vΘ(zt,t)
通过解这个 ODE,从噪声分布
p
1
p_1
p1 的样本
z
1
z_1
z1 流动到目标分布
p
0
p_0
p0 的样本
z
0
z_0
z0。由于路径是连续的,生成过程非常高效。
以上就是 Flow Matching(FM) 采样方法的全部内容,在下一节,我们将详细的讲解在 FM 基础上优化而来的 Rectified Flow(RF)采样方法。