Redis7底层数据结构解析
redisObject
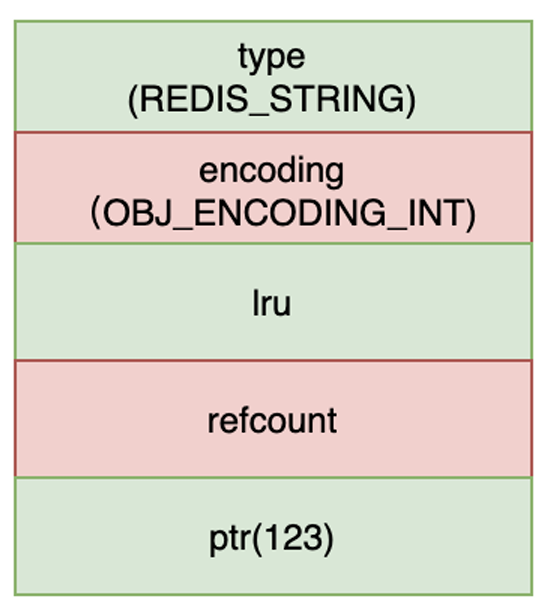
在 Redis 的源码中,Redis 会将底层数据结构(如 SDS、hash table、skiplist 等)统一封装成一个对象,这个对象叫做 redisObject,也简称 robj。
typedef struct redisObject {unsigned type : 4; // 数据类型(string, list, set, zset, hash)unsigned encoding : 4; // 编码方式(raw, int, hashtable, skiplist 等)unsigned lru : 24; // LRU 时间戳或 LFU 信息int refcount; // 引用计数void *ptr; // 指向实际数据的指针
} robj;
string
string数据的类型,会根据value的类型不同,有以下⼏种处理⽅式
-
int : 如果value可以转换成⼀个long类型的数字,那么就⽤int保存value。只有整数才会使⽤int,如果是浮点数,Redis内部其实是先将浮点数转化成字符串,然后保存
-
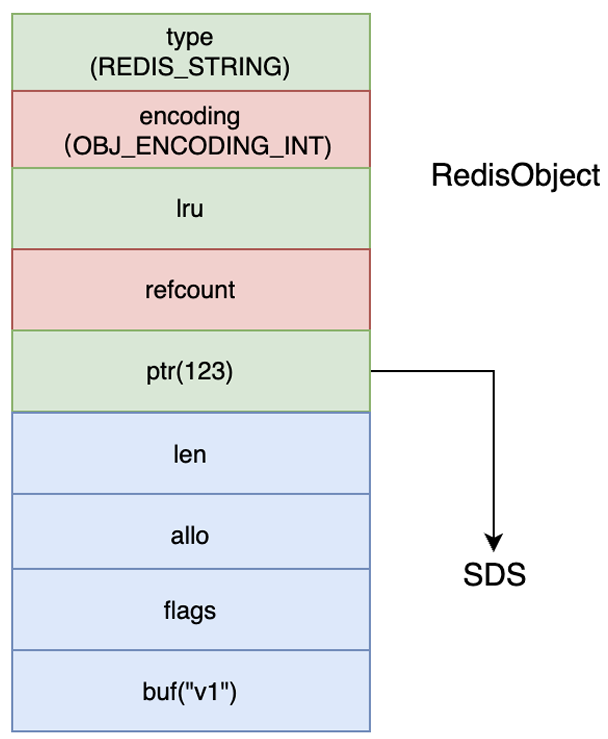
embstr : 如果value是⼀个字符串类型,并且⻓度⼩于44字节的字符串,那么Redis就会⽤embstr保存。代表embstr的底层数据结构是SDS(Simple Dynamic String 简单动态字符串)
embstr字⾯意思就是内嵌字符串。 所谓内嵌的核⼼,其实就是将新创建的SDS对象直接分配在对象⾃⼰的内存后⾯。这样内存读取效率明显更⾼。
SDS其实是⼀段不可修改的字符串,redis定义好了不同长度的sds。这意味着如果使⽤APPEND之类的指令尝试修改⼀个key的值,那么就算value的⻓度没有超过44,Redis也会使⽤⼀个新创建的raw类型,⽽不再使⽤原来的SDS。
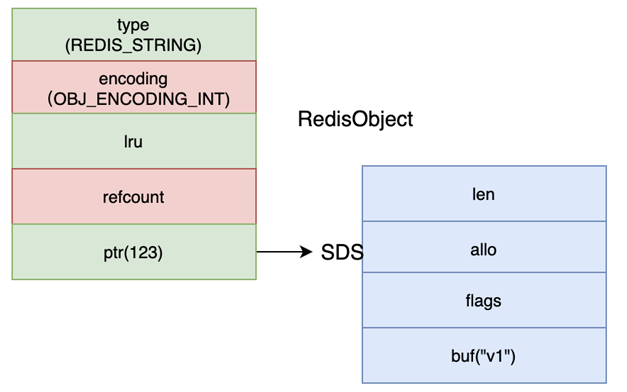
- raw :如果value是⼀个字符串类型,并且⻓度⼤于44字节,就会⽤raw保存。
raw类型其实相当于是兜底的⼀种类型。特殊的数字类型和⼩字符串类型处理完了后,就是raw类型了。raw类型的处理⽅式就是单独创建⼀个SDS,然后将robj的ptr指向这个SDS。\
HASH
如果field-value对的数据⽐较少,就⽤listpack。如果数据⽐较多,就⽤hashtable。
hash-max-listpack-entries 限制value⾥键值对的个数(默认512),hash-max-listpack-value 限制value⾥值的数据⼤⼩(默认64字节)。
-
listpack
listpack是ziplist的升级版,ziplist每个entry会记录前节点的长度(用于反向遍历),在⼤于等于254字节的新节点加⼊到压缩列表的表头节点会触发连锁更新。listpack则改为了记录当前entry的长度,不受到前节点影响,不会触发连锁更新,也就不直接支持反向遍历
ziplist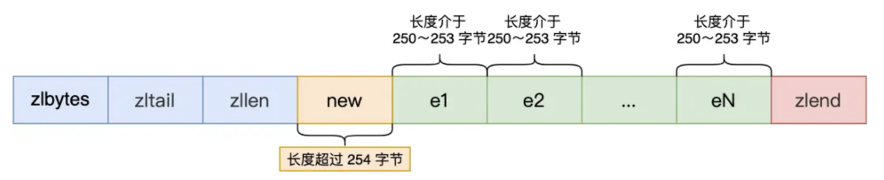
ziplist的entry结构

listpack
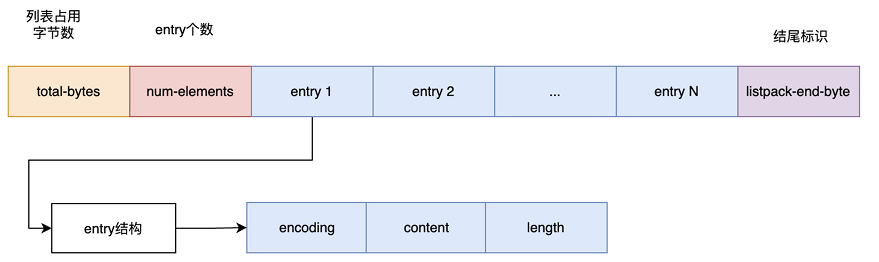
-
hashtable
dict构成了hash的整个value,dictEntry则是field-value,dictEntry内有下一个dictEntry的指针(c语言使用sizeof(struct 结构体名)可以获取结构体所占的长度)
hash底层数据结构总结
- hash底层更多的是使⽤listpack来存储value。
- 如果hash对象保存的键值对超过512个,或者所有键值对的字符串⻓度超过64字节,底层的数据结构就会由listpack升级成为hashtable。
- 对于同⼀个hash数据,listpack结构可以升级为hashtable结构,但是hashtable结构不会降级成为listpack。
List
list类型的数据,在Redis中还是以listpack+quicklist为基础保存的。
list-max-listpack-size -2每个list中包含的节点⼤⼩或个数。正数表示个数,负数-1到-5表示⼤⼩。
-5: max size: 64 Kb <-- not recommended for normal workloads
-4: max size: 32 Kb <-- not recommended
-3: max size: 16 Kb <-- probably not recommended
-2: max size: 8 Kb <-- good
-1: max size: 4 Kb <-- good
- quicklist
listpack可以看成是⼀个数组(Array)结构,查快改慢。与数组形成对⽐的是链表(List)结构。链表的节点之间只通过指针指向相关联的节点,修改只需要调整指针,但是只能沿着指针查找元素
quicklist则是两者结合,整体上是list,而每个quickListNode又有数个listpack
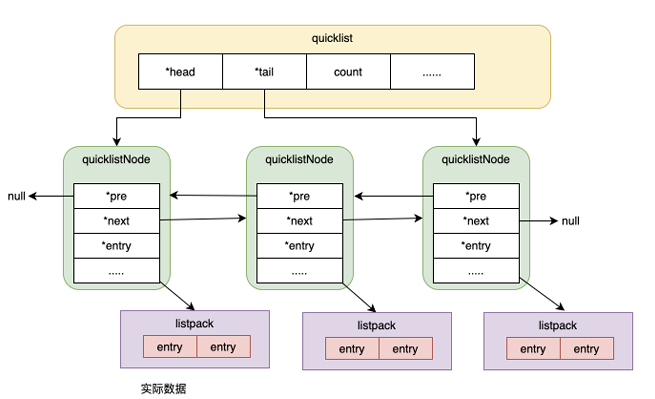
set
Redis底层综合使⽤intset+listpack+hashtable存储set数据。set数据的⼦元素也是<k,v>形式的entry。其中,key就是元素的值,value是null。
如果set的数据不是数字,并且数据的⼤⼩没有超过下⾯设定的阈值,就⽤listpack存储
如果数据⼤⼩超过了其中⼀个阈值,就改为使⽤hashtable存储。
set-max-listpack-entries 128 指素数量不超过 128 个
set-max-listpack-value 64 指字节长度不超过 64 字节
- intset是一个紧凑的有序整数数组结构,支持自动升级为更大整数类型,插入时使用二分查找来保持元素不重复,用于存储 所有是整数 且 数量不大 的集合。
typedef struct intset {uint32_t encoding; // 当前使用的整数编码(int16、int32、int64)uint32_t length; // 当前元素个数int8_t contents[]; // 实际存储整数的区域(变长数组)
} intset;
- 关于这三种数据结构之间如何转换,以set数据类型最为典型的sadd指令为例,会进⼊下⾯这个⽅法进⾏处理。
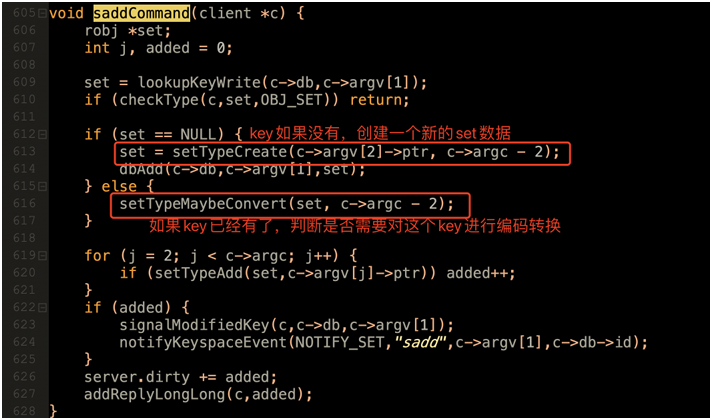
在创建set元素时,就会根据⼦元素的类型,判断是⽤intset还是⽤listpack。
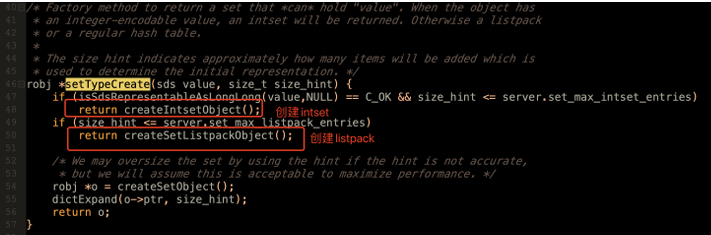
⽽在添加元素时,也会根据参数判断是否需要转换底层编码

ZSET
Redis底层综合使⽤listpack + skiplist两种结构来保存zset类型的数据。
数据的⼤⼩没有超过下⾯设定的阈值,就⽤listpack存储
如果数据⼤⼩超过了其中⼀个阈值,就改为使⽤skiplist存储。
zset-max-listpack-entries 128 指素数量不超过 128 个
zset-max-listpack-value 64 指字节长度不超过 64 字节
- skiplist
skiplist的优化思路是构建多层逐级缩减的⼦索引,⽤更多的索引来提升搜索的性能。
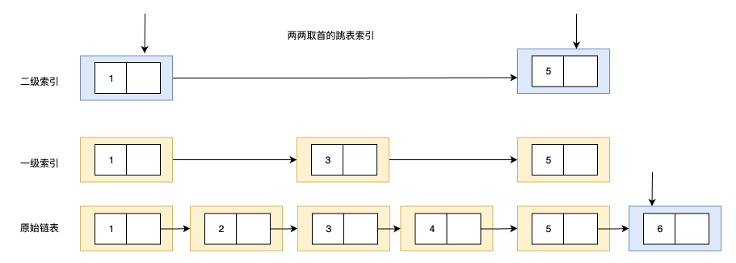
typedef struct zskiplistNode {sds ele; // 成员值(string)double score; // 排序用分数struct zskiplistNode *backward; // 后退指针(用于反向遍历)struct zskiplistLevel {struct zskiplistNode *forward; // 指向下一节点unsigned int span; // 跨越节点数(用于排名计算)} level[]; // 每一层的 forward/跨度信息
} zskiplistNode;
zskiplistLevel 存储了每一层,包括原始链表。
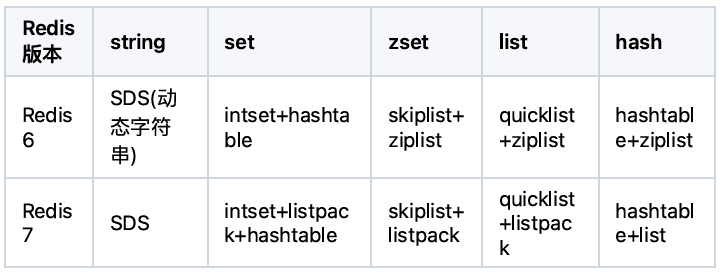
redis6/7数据结构差异