Nature:多模态大模型LLMs如何驱动多组学与生命科学研究新范式?
高通量组学技术的快速进步引发了生物数据的爆炸式增长,远超当前对分子层面规律的解析能力。在自然语言处理领域,大语言模型(LLMs)通过整合海量数据构建统一模型,已显现突破数据困境的潜力。

Nature的这篇文章中,多伦多大学华裔学者提出构建多模态基础模型(Multimodal Foundation Models, MFMs)的设想:
该类模型预训练于包含基因组学、转录组学、表观遗传学、蛋白质组学、代谢组学和空间组学等多种组学数据,具有前所未有的能力描绘细胞的分子状态,为构建细胞、基因和组织的整体图谱提供可能。通过特定情境下的迁移学习,MFMs可广泛应用于新型细胞类型识别、生物标志物发现、基因调控推断乃至模拟扰动实验。MFMs有望重构“数据—模型—实验”闭环,加速生命科学认知进程与精准医学转化。
(本文的思路不仅适用于生命科学,对于大数据驱动的其他领域的研究也非常有启发。)

1 背景
近年来,分析技术(如下一代测序、单细胞测序、冷冻电镜和质谱蛋白质组学)和大规模机器学习方法的突破,共同推动了新机遇的诞生。一方面,高通量测序技术带来关于DNA、RNA及蛋白质产物的大量知识,组学数据生成速度持续加快。全球协作项目如Human Cell Atlas(HCA)、Human Biomolecular Atlas Program(HuBMAP)和Human Tumor Atlas Network(HTAN)已在不同条件和数据模态下积累了数以百万计的细胞数据。此外,平行多组学测量技术使得在同一细胞内获得多模态数据成为可能,亟需能够跨多模态建模的工具。另一方面,预训练大型机器学习模型的发展,使得模型能够处理和解释多种类型的生物数据。
多模态基础模型(MFMs)的设想
我们设想,构建多模态基础模型(MFMs)是一种应对上述挑战的新途径。其核心策略是基于多模态大数据进行自监督预训练,从而获取基础知识和能力,即所谓的“foundation model”。该模型应能够接受不同类型的输入数据,完成多种任务,如健康和疾病状态下的细胞状态与基因功能表征、状态动态预测等。
基础模型的理念
基础模型是通过自监督学习方法在大规模数据集上训练的深度神经网络模型,可通过迁移学习高效适应多种下游任务。在自然语言处理领域,基于transformer的基础模型(如GPT和Llama系列)在海量文本语料上训练,能通过微调或上下文学习迅速适应不同任务。近年来,基础模型已拓展到自然图像、视频及语言-图像跨模态生成。在分子细胞生物学中,基础模型为统一表征复杂生物过程提供了新途径,通过对多组学数据的训练,挖掘不同模态下的隐含规律,有望揭示普适性的生物学原理。
MFMs的期望特性与架构
MFMs应当能够灵活整合多种数据类型和模态(如bulk与单细胞测序、转录组、蛋白组、代谢组和表观基因组等),并在大规模、涵盖多种状态和时点的聚合数据上进行自监督预训练。通过迁移学习(如微调、上下文学习),将所学分子嵌入应用于诸如细胞状态时序建模、新型细胞类型表征、扰动响应预测等多样化任务。transformer架构及其内部的attention机制已成为构建基础模型的主流。生命科学领域的多个开创性工作,如AlphaFold2、RoseTTA fold(蛋白结构预测)、ESM2、ESM3(蛋白生成)、Enformer(基因表达预测)、scGPT、GeneFormer、scBERT(单细胞RNA-seq数据预训练)等,都验证了transformer在分子层面建模的潜力。
“数据驱动+实验室循环”的工作流
MFMs预示着分子细胞生物学从传统假设驱动向数据驱动的范式转变。研究者可先通过高通量手段采集多模态数据,预训练模型,之后使用模型推演生物规律、设计高效实验。该流程即“lab-in-the-loop”理念:实验与模型相辅相成,模型辅助实验设计,实验反哺模型优化。
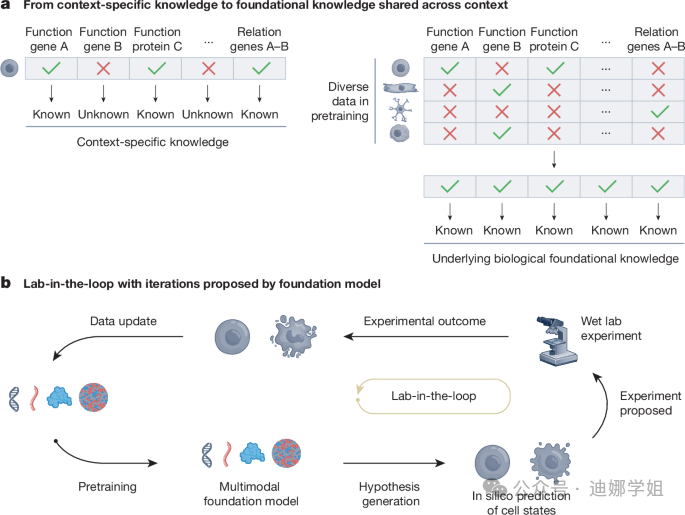
图:“lab-in-the-loop”闭环流程:模型指导实验设计,实验结果反哺模型优化。
二、MFMs的应用前景
组织异质性表征
单细胞组学推动了细胞亚群高分辨率解析,揭示了肿瘤等复杂组织内的异质性。单细胞RNA测序揭示了不同胶质母细胞瘤亚群的转录组差异,表观基因组分析则基于染色质状态区分肿瘤亚克隆,蛋白质组方法通过质谱等技术揭示功能变异。MFMs能够将细胞状态嵌入连续谱中,实现细胞状态的情境化、对比与补全:1)通过整合多组学数据,MFMs可将细胞状态嵌入广阔的连续空间;2)支持不同样本和模态之间的高效整合与对比;3)对缺失模态可通过生成推断进行补全。
基因功能与调控预测
MFMs有望从异质性疾病数据中学习多组学特征,用于生物标志物发现。最新工作已证明单凭基因组序列即可预测基因功能,结合多组学(如染色质可及性、甲基化)能进一步提升推断能力。MFMs还可重建情境特异性的基因调控网络(GRNs),整合不同组学数据获得更全面、精细的调控视角,并可通过迁移学习灵活适应不同细胞类型、发育阶段和疾病状态。
计算扰动(in silico perturbation)
在多组学数据的基础上训练的MFMs可预测假想基因或药物扰动对细胞状态的影响。最新模型如scGPT、CellOracle、Geneformer等已初步实现对扰动后表达谱的预测。整合多模态数据、时空信息与通路、调控网络知识,将使MFMs在计算扰动、药物发现与基因调控机制研究中更具前景。
三、构建MFMs的关键要素
数据资源
构建高质量MFMs需大规模、多样化的多组学数据,包括bulk与单细胞、空间转录组、染色质可及性、蛋白组等。目前已有HuBMAP、ENCODE、IHEC、HCA等重要数据资源,但多模态配对数据仍稀缺。最新单细胞技术(如10X Multiome、CITE-seq、ASAP-seq)正推动配对数据增长。单细胞数据揭示个体层面异质性,将成为MFM训练的关键。
计算组件
-
统一的多模态token:需将不同类型组学数据转化为统一token嵌入,可通过多层次(核苷酸、基因、蛋白)token化实现多分辨率建模。
-
混合多层次注意力机制:结合局部(同模态)与全局(跨模态)自注意力,捕捉多尺度生物信息。
-
自监督与交叉模态训练任务:采用mask、对比学习、跨模态预测等任务训练模型,结合提示(prompt)机制统一任务框架。
-
人类知识整合:将数据库中结构化知识(如通路、基因本体、蛋白互作网络)与文献等非结构化知识嵌入模型,提升归纳偏好与泛化能力。
四、面临的挑战与未来方向
-
数据维度:高质量、多模态配对数据仍稀缺,需推动标准化采集与共享机制;
-
资源消耗:训练成本高,需发展高效模型(如LORA、Adapter-Transformer);
-
评估体系:需开发更客观的无监督指标,用于新细胞状态或未知功能的验证;
-
可解释性与幻觉风险:需引入不确定性量化机制,防止虚假推理结果;
-
伦理与公平性:保证数据与模型覆盖多样性人群,确保医学应用的可推广性。
MFMs与传统机器学习模型的对比:

总结:MFMs有望通过整合多组学数据,推动分子生物学及医学研究的变革,实现前所未有的规模与分辨率。其实现离不开生物学家、数据科学家、人工智能专家与伦理学家的跨界合作。面向未来,MFMs有望推动个性化医疗、疾病建模与新药研发,重塑生命科学与医学研究格局。
---
今天就介绍到这里。
如果觉得有用,欢迎在看、转发和点赞!娜姐继续输出有用的AI辅助科研写作、绘图相关技巧和知识。