Dif-Fusion:第一个基于扩散模型实现的红外光与可见光图像融合的论文
1. 论文介绍
论文主要创新点:提出了第一个基于扩散模型 (Diffusion) 实现的红外光与可见光图像融合模型,但模型不止简单的依赖于 Diffusion,而是一个新颖的 two-stage 的图像融合模型。
Dif-Fusion 利用扩散模型的生成能力,直接在潜在空间中建模多通道数据的分布,避免了传统方法中对颜色信息的损失。
传统的红外与可见光图像融合方法通常将多通道图像转换为单通道进行处理,忽略了颜色信息的保留,导致融合图像色彩失真
问题痛点:
-
现有融合方法(如基于CNN、Transformer)通常忽略颜色保真,导致生成图像偏灰、偏色。
-
很多方法将RGB图像转为灰度处理,忽略了色彩通道的耦合性与重要性。
2. 关键背景知识
相比于多聚焦/多曝光图像融合这种能够获得 ground-truth(即真实融合图像) 的任务,红外光与可见光图像融合中的 ground-truth 是不可获取的。这导致我们无法使用 ground-truth 作为 label 进行训练,这使得这个任务变得困难。因为对于有 ground-truth 的任务(如图像超分/去噪/增强),训练一个 Conditional Diffusion Model(条件扩散模型)是很容易的。
- 多聚焦图像融合的 GT 是 “全聚焦图像”(通过光学设备直接拍摄同一场景的清晰图像);
- 多曝光图像融合的 GT 是 “高动态范围(HDR)图像”(通过相机多次曝光合成或专业设备采集)
-
维度 多聚焦 / 多曝光融合(有 GT) 红外与可见光融合(无 GT) 监督信号 强监督(像素级 GT) 弱监督(自监督、下游任务监督、感知损失) 损失函数 MSE/SSIM 等直接度量像素差异 重构损失、对比损失、任务损失等间接损失 - 该论文的创新在于:首次在无 GT 场景中证明,扩散模型的生成能力可替代传统监督信号,
3. 模型结构
整体架构: 两阶段融合框架
Dif-Fusion 采用两阶段架构,分别为
-
扩散建模阶段(Diffusion Modeling Stage):
-
输入:红外图像(1通道)与可见光图像(3通道)拼接为4通道数据。
-
过程:通过正向扩散过程添加高斯噪声,训练去噪网络学习反向扩散过程,建模多通道数据分布
-
-
特征融合阶段(Feature Fusion Stage):
从去噪网络中提取多通道扩散特征,输入融合模块,生成高保真的三通道融合图像
Dif-Fusion 的总体结构如下:
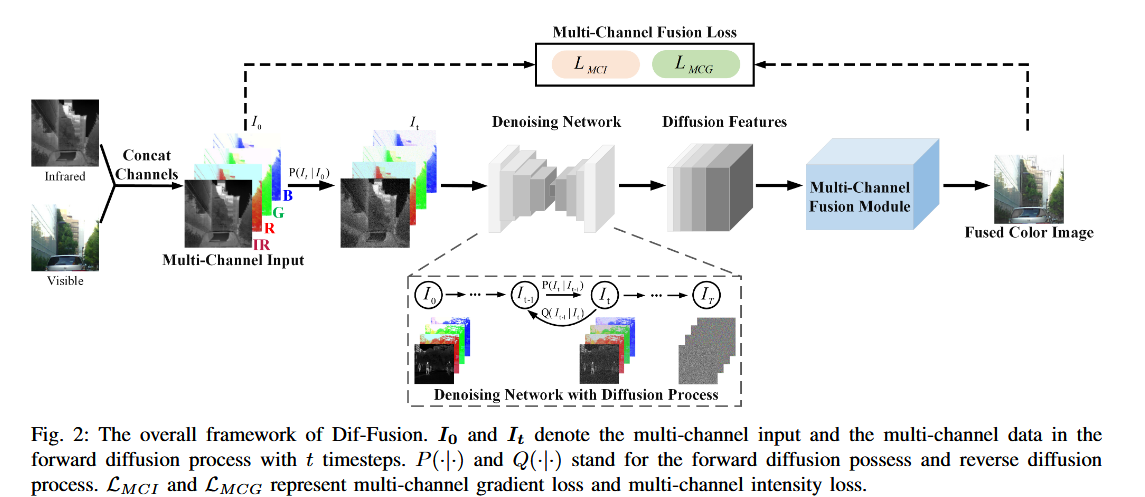
Dif-Fusion 是一个二阶段(two-stage)的图像融合模型,包括两个相互独立的模型:
- 1、Diffusion 模型:将 Diffusion 的噪声预测网络作为一个特征学习和提取器
噪声预测网络工作机制:Diffusion 模型中的噪声预测网络,在前向扩散过程中,图像不断被添加噪声,逐步从清晰态变为噪声态。反向扩散时,网络依据含噪图像预测噪声,进而尝试还原清晰图像 。在这个过程中,网络并非单纯去噪,而是在学习图像特征。对于红外与可见光图像融合任务,它能捕捉到红外图像的热辐射特征、可见光图像的纹理细节特征等。
特征提取优势:相比传统基于卷积神经网络(CNN)的特征提取方式,Diffusion 模型的噪声预测网络具有独特优势。传统 CNN 特征提取往往受限于固定的卷积核与网络结构,对复杂特征的捕捉能力有限。而 Diffusion 模型通过逐步去噪过程,可从不同噪声水平下对图像特征进行深度挖掘,它可以在不同尺度和层次上提取特征,适应红外与可见光图像在特征分布和物理特性上的差异。
- 2、特征融合模型:提取噪声预测网络中的特征,通过两种 loss 的约束,获得融合如下
从 Diffusion 模型的噪声预测网络中提取特征后,特征融合模型开始发挥作用
损失函数约束:
多通道梯度损失![]() :该损失函数聚焦于图像的梯度信息。在图像融合中,梯度代表着边缘和细节。通过约束多通道梯度损失,能确保融合后的图像在边缘和细节上,既保留可见光图像丰富的纹理细节,又兼顾红外图像中目标的热边界信息。
:该损失函数聚焦于图像的梯度信息。在图像融合中,梯度代表着边缘和细节。通过约束多通道梯度损失,能确保融合后的图像在边缘和细节上,既保留可见光图像丰富的纹理细节,又兼顾红外图像中目标的热边界信息。
多通道强度损失![]() :主要关注图像的强度信息,也就是图像的亮度、灰度等。在红外与可见光图像融合时,两种图像的强度分布差异大。通过多通道强度损失约束,可使融合图像在整体亮度和灰度上更协调、自然。例如,避免融合后图像出现局部过亮或过暗区域,让红外热源与可见光背景在强度上能更好融合。
:主要关注图像的强度信息,也就是图像的亮度、灰度等。在红外与可见光图像融合时,两种图像的强度分布差异大。通过多通道强度损失约束,可使融合图像在整体亮度和灰度上更协调、自然。例如,避免融合后图像出现局部过亮或过暗区域,让红外热源与可见光背景在强度上能更好融合。
Diffusion 模型专注于特征学习和提取,无需考虑后续融合的具体策略;特征融合模型则专心依据提取的特征进行融合,并通过损失函数优化。

3.1 Diffusion 模型
多通道扩散模型的特性:输入设计:直接以 三通道可见光图像 + 单通道红外图像作为多通道输入(如 concat 为 4 通道数据),避免传统方法中 “RGB 转 YCbCr 丢弃颜色通道” 的问题,确保颜色信息在特征提取阶段不被丢失
红外光与可见光图像融合的训练集中只有源图像,没有 ground-truth;而多聚焦图像融合既有源图像,也有 ground-truth,因此很容易以 ground-truth 作为 label 训练网络。
Diffusion 的输入是单通道的 Infrared(红外光图像)和三通道的 Visible(可见光图像),输出是三通道的融合图像。在实际操作中,本文将 Infrared 和 Visible 在通道方向合并为四通道图像进行输入,这是条件生成模型的常用手段。
由于没有 ground-truth 的融合图像,作者另辟蹊径,将四通道源图像作为 ground-truth 训练一个自监督的 Diffusion 模型。
前向扩散过程:对四通道源图像加噪,扩散步长 T = 2000
逆向扩散过程:以高斯噪声为label,训练噪声预测网络
3.2.2 损失函数
为了训练特征融合模型,作者使用了两种损失函数:
多通道梯度损失(multi-channel gradient loss):保持融合图像的纹理细节,特别是从可见光图像中继承丰富的纹理信息。
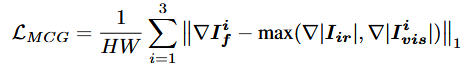
多通道强度损失(multi-channel intensity loss):让融合图像的亮度/整体强度分布尽可能接近输入图像(红外和可见光)中较为突出的强度信息
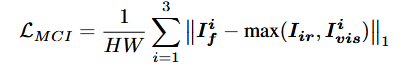
4. 消融实验:验证扩散模型的有效性
5实验与评估
作者引入了 Delta E 作为新的评估指标,用于量化色彩保真度,并在多个公开数据集上与现有方法进行了比较,结果显示 Dif-Fusion 在色彩保真度方面表现优越。
Delta E 将 “色彩保真度” 从模糊的主观描述转化为可计算的客观指标,使不同方法的色彩表现具有可比性。
设计了颜色保真度度量指标 Delta E,用于量化融合图像的颜色失真。
红外与可见光融合的核心挑战之一是保留可见光图像的真实色彩(如道路标识的红色、植被的绿色),而传统指标(如 PSNR、SSIM)侧重亮度和结构,忽略色彩保真度。
Dif-Fusion 的 Delta E 显著低于其他方法,表明其融合图像的色彩与原始可见光图像更接近,尤其是在高饱和色(如红色、绿色)区域表现更佳。