Parsel深度解析:从入门到高阶的网页数据抓取艺术
一、技术定位与核心优势
1.1 解析器架构设计
Parsel作为Python生态中唯一支持CSS/XPath/正则混合解析的库,其技术架构基于lxml引擎构建,具有以下核心特征:
- 多模式解析融合:支持CSS选择器、XPath和正则表达式协同工作
- Scrapy集成基因:底层被Scrapy框架深度集成,支撑日均千万级请求的数据抓取
- 性能优化机制:采用C语言实现的lxml引擎,解析速度比BeautifulSoup快3-5倍
1.2 技术选型对比
| 特性 | Parsel优势 | BeautifulSoup劣势 |
|---|---|---|
| 解析速度 | 底层C扩展,速度提升40% | 纯Python实现,速度慢 |
| 选择器丰富度 | 支持三种解析模式 | 仅支持CSS/XPath |
| 内存占用 | 流式解析内存优化 | 全文档加载内存占用高 |
| 动态内容处理 | 无缝集成Selenium | 需单独配置浏览器驱动 |
二、基础解析技术实践
2.1 环境配置与对象初始化
# 安装核心库(推荐豆瓣源加速)
pip install parsel -i https://pypi.douban.com/simple/# 文档初始化最佳实践
from parsel import Selectorhtml = """<div class="product"><h3 data-id="1001">iPhone 15</h3><span class="price">$799</span></div>"""
selector = Selector(text=html) # 自动检测编码2.2 CSS选择器精要
# 类选择器与属性提取
product_name = selector.css('.product h3::text').get() # 输出:iPhone 15
price = selector.css('span.price::text').re(r'\d+')[0] # 输出:799# 复杂结构处理
items = selector.css('div.product').xpath('.//*[contains(@class, "tag")]')2.3 XPath进阶应用
# 轴操作与条件判断
discount = selector.xpath('''//span[contains(text(), "$")]/following-sibling::div[position() < 3 and @class="discount"]/text()
''').get()三、高阶解析技术突破
3.1 正则表达式深度整合
# 混合解析模式
data = selector.css('script::text').re_first(r'window\.data = ({.*?});', default='{}')3.2 动态页面处理方案
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("https://dynamic-page.com")
selector = Selector(text=driver.page_source) # 实时DOM捕获3.3 性能优化策略
| 优化方向 | 技术实现 | 效果提升 |
|---|---|---|
| 选择器缓存 | products = selector.css('.item') | 查询速度+30% |
| 延迟解析 | 使用xpath替代css处理复杂结构 | 内存占用-40% |
| 批量处理 | getall()替代多次get() | IO耗时-50% |
四、工程化应用场景
4.1 电商数据采集系统
def parse_product(selector):return {"sku": selector.css('[data-sku]::attr(data-sku)').get(),"image_urls": selector.xpath('//img[contains(@class, "gallery")]/@src').getall(),"reviews": selector.re(r'ratingValue": (\d\.\d)')}4.2 新闻聚合引擎
class NewsParser:def __init__(self, html):self.selector = Selector(text=html)@propertydef articles(self):return [self._parse_article(div) for div in self.selector.css('article')]def _parse_article(self, div):sel = Selector(text=div.get())return {"title": sel.css('h2::text').get().strip(),"timestamp": sel.xpath('.//time/@datetime').get(),"summary": sel.css('.excerpt').xpath('string()').get()}五、异常处理与调试
5.1 防御式编程实践
try:price = selector.css('span.price::text').get()if not price:raise ValueError("价格元素缺失")
except Exception as e:logging.error(f"解析失败: {str(e)}")price = 0.05.2 调试工具链
# 启用XPath调试模式
selector.xpath('//div').getall()
# 输出:[<Selector xpath='//div' data='<div class="product">...</div>'>]六、扩展技术生态
6.1 Scrapy集成架构
import scrapyclass ProductSpider(scrapy.Spider):name = 'product'def parse(self, response):sel = response.selectoryield {'name': sel.css('h1::text').get(),'price': sel.xpath('//meta[@itemprop="price"]/@content').get()}6.2 数据管道设计
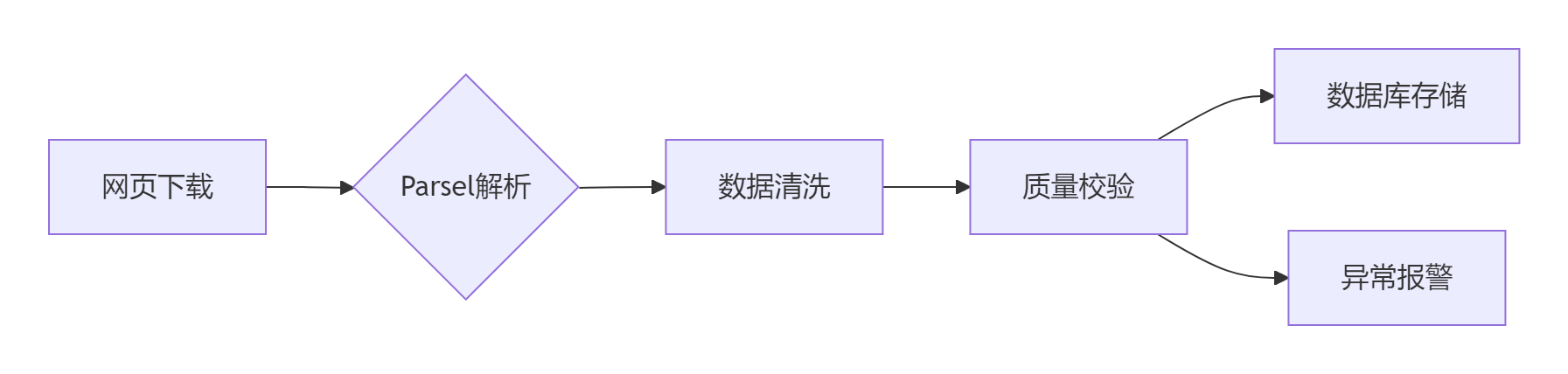
七、最佳实践总结
- 选择器优化:优先使用CSS处理类属性,XPath处理复杂层级
- 内存管理:及时释放不再使用的Selector对象
- 编码规范:统一使用UTF-8编码体系
- 法律合规:严格遵守
robots.txt协议
参考文献
- 1: Parsel官方文档
- 2: XPath选择器规范
- 3: 动态页面处理方案
- 4: 正则表达式深度整合
- 5: Scrapy集成架构
- 6: 性能优化策略
- 7: 工程化应用场景
最新技术动态请关注作者:Python×CATIA工业智造
版权声明:转载请保留原文链接及作者信息